Artículos de programación MQL4 y MQL5
Aprenda el lenguaje de programación de estrategias comerciales MQL5 leyendo numerosos artículos la mayor parte de los cuales han sido escritos por Ustedes - miembros de MQL5.community. Con el fin de buscar rápidamente la respuesta sobre una u otra cuestión de programación, todos los artículos están divididos en categorías: "Integración", "Probador", "Estrategias comerciales", etc.
Siga las nuevas publicaciones y participe en sus discusiones en el foro de MQL5.community!
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Teoría de Categorías en MQL5 (Parte 5): Ecualizadores
La teoría de categorías es un apartado diverso y en expansión de las matemáticas, que solo recientemente ha comenzado a ser trabajado por la comunidad MQL5. Esta serie de artículos tiene por objetivo repasar algunos de sus conceptos para crear una biblioteca abierta y seguir usando este maravilloso apartado en la creación de estrategias comerciales.
Teoría de categorías en MQL5 (Parte 22): Una mirada distinta a las medias móviles
En el presente artículo intentaremos simplificar los conceptos tratados en esta serie centrándonos en solo un indicador, el más común y probablemente el más fácil de entender: la media móvil. También veremos el significado y las posibles aplicaciones de las transformaciones naturales verticales.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 12): Nacimiento del SIMULADOR (II)
Desarrollar un simulador puede resultar mucho más interesante de lo que parece. Así que demos algunos pasos más en esta dirección, porque las cosas están empezando a ponerse interesantes.

Características del Wizard MQL5 que debe conocer (Parte 6): Transformada de Fourier
La transformada de Fourier, introducida por Joseph Fourier, es un medio para descomponer puntos de datos de ondas complejos en componentes de ondas simples. Esta característica puede resultar útil para los tráders, así que hablaremos de ella en este artículo.

Redes neuronales: así de sencillo (Parte 42): Procrastinación del modelo, causas y métodos de solución
La procrastinación del modelo en el contexto del aprendizaje por refuerzo puede deberse a varias razones, y para solucionar este problema deberemos tomar las medidas pertinentes. El artículo analiza algunas de las posibles causas de la procrastinación del modelo y los métodos para superarlas.

Trabajando con los precios en la biblioteca DoEasy (Parte 61): Colección de series de tick de los símbolos
Dado que el programa puede utilizar varios símbolos, entonces, es necesario crear su propia lista para cada uno de estos símbolos. En este artículo, vamos a combinar estas listas en una colección de datos de tick. En realidad, se trata de una lista común a base de la clase de la matriz dinámica de punteros a las instancias de la clase CObject y sus herederos de la Biblioteca estándar.

Redes neuronales: así de sencillo (Parte 51): Actor-crítico conductual (BAC)
Los dos últimos artículos han considerado el algoritmo SAC (Soft Actor-Critic), que incorpora la regularización de la entropía en la función de la recompensa. Este enfoque equilibra la exploración del entorno y la explotación del modelo, pero solo es aplicable a modelos estocásticos. El presente material analizará un enfoque alternativo aplicable tanto a modelos estocásticos como deterministas.
Asesor Experto Grid-Hedge Modificado en MQL5 (Parte III): Optimización de una estrategia de cobertura simple (I)
En la tercera parte, volveremos a los Asesores Expertos Simple Hedge y Simple Grid que hemos desarrollado anteriormente. En esta ocasión, mejoraremos el Simple Hedge Expert Advisor usando el análisis matemático y el enfoque de fuerza bruta para utilizar de manera óptima la estrategia. Este artículo profundizará en la optimización matemática de estrategias, sentando las bases para futuras investigaciones sobre la optimización basada en códigos de partes posteriores.

Algoritmos de optimización de la población: Algoritmo Mind Evolutionary Computation (Computación Evolutiva Mental, (MEC)
En este artículo, analizaremos un algoritmo de la familia MEC llamado algoritmo MEC Simple de evolución mental (Simple MEC, SMEC). El algoritmo se caracteriza por la belleza de la idea expuesta y su sencillez de aplicación.

Redes neuronales: así de sencillo (Parte 75): Mejora del rendimiento de los modelos de predicción de trayectorias
Los modelos que creamos son cada vez más grandes y complejos. Esto aumenta los costes no sólo de su formación, sino también de su funcionamiento. Sin embargo, el tiempo necesario para tomar una decisión suele ser crítico. A este respecto, consideremos los métodos para optimizar el rendimiento del modelo sin pérdida de calidad.

DoEasy. Elementos de control (Parte 2): Continuamos trabajando con la clase CPanel
En este artículo, eliminaremos algunos errores que surgen al trabajar con los elementos gráficos y continuaremos desarrollando el control CPanel. Estos métodos servirán para establecer por defecto los parámetros de fuente usados para todos los objetos de texto en el panel, que a su vez podrán ser colocados en él en el futuro.
Paradigmas de programación (Parte 2): Enfoque orientado a objetos para el desarrollo de EA basados en la dinámica de precios
En este artículo hablaremos sobre el paradigma de la POO y su aplicación en el código MQL5. Este será el segundo artículo de la serie. En él aprenderemos las características de la programación orientada a objetos y analizaremos ejemplos prácticos. La última vez escribimos un Asesor Experto basado en la Acción del Precio (Price Action) utilizando el indicador EMA y datos de velas. Ahora convertiremos su código procedimental en un código orientado a objetos.

Pruebas de permutación de Monte Carlo en MetaTrader 5
En este artículo echaremos un vistazo a cómo podemos realizar pruebas de permutación sobre la base de datos de ticks barajados en cualquier asesor experto utilizando solo MetaTrader 5.

Redes neuronales: así de sencillo (Parte 66): Problemática de la exploración en el entrenamiento offline
El entrenamiento offline del modelo se realiza sobre los datos de una muestra de entrenamiento previamente preparada. Esto nos ofrecerá una serie de ventajas, pero la información sobre el entorno estará muy comprimida con respecto al tamaño de la muestra de entrenamiento, lo que, a su vez, limitará el alcance del estudio. En este artículo, querríamos familiarizarnos con un método que permite llenar la muestra de entrenamiento con los datos más diversos posibles.

Algoritmos de optimización de la población: Algoritmo de salto de rana aleatorio (Shuffled Frog-Leaping, SFL)
El artículo presenta una descripción detallada del algoritmo de salto de rana aleatorio (SFL) y sus capacidades para resolver problemas de optimización. El algoritmo SFL se inspira en el comportamiento de las ranas en su entorno natural y ofrece un enfoque innovador para la optimización de características. El algoritmo SFL supone una herramienta eficaz y flexible que puede gestionar una gran variedad de tipos de datos y alcanzar soluciones óptimas.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 13): Nacimiento del SIMULADOR (III)
Aquí optimizaremos un poco las cosas para facilitar lo que haremos en el próximo artículo. Y también te explicaré cómo puedes visualizar lo que está generando el simulador en términos de aleatoriedad.

Integración de modelos ML con el simulador de estrategias (Conclusión): Implementación de un modelo de regresión para la predicción de precios
Este artículo describe la implementación de un modelo de regresión de árboles de decisión para predecir precios de activos financieros. Se realizaron etapas de preparación de datos, entrenamiento y evaluación del modelo, con ajustes y optimizaciones. Sin embargo, es importante destacar que el modelo es solo un estudio y no debe ser usado en operaciones reales.

Multibot en MetaTrader (Parte II): Plantilla dinámica mejorada
Desarrollando el tema del artículo anterior sobre el multibot, hemos decidido crear una plantilla más flexible y funcional, que tenga grandes posibilidades, y que se pueda utilizar eficazmente en freelance, además de como base para desarrollar asesores de divisa y periodo múltiple con posibilidad de integración con soluciones externas.

Redes neuronales: así de sencillo (Parte 82): Modelos de ecuaciones diferenciales ordinarias (NeuralODE)
En este artículo, hablaremos de otro tipo de modelos que están destinados a estudiar la dinámica del estado ambiental.
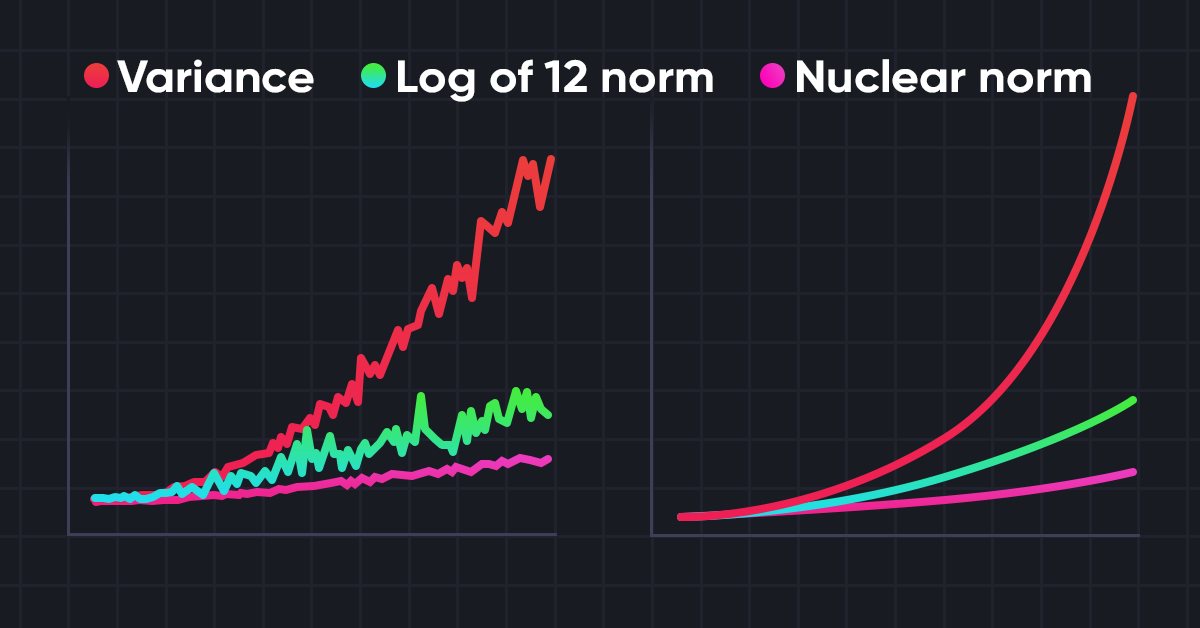
Redes neuronales: así de sencillo (Parte 56): Utilizamos la norma nuclear para incentivar la exploración
La exploración del entorno en tareas de aprendizaje por refuerzo es un problema relevante. Con anterioridad, ya hemos analizado algunos de estos enfoques. Hoy le propongo introducir otro método basado en la maximización de la norma nuclear, que permite a los agentes identificar estados del entorno con un alto grado de novedad y diversidad.

Redes neuronales: así de sencillo (Parte 64): Método de clonación conductual ponderada conservadora (CWBC)
Como resultado de las pruebas realizadas en artículos anteriores, hemos concluido que la optimalidad de la estrategia entrenada depende en gran medida de la muestra de entrenamiento utilizada. En este artículo, nos familiarizaremos con un método bastante sencillo y eficaz para seleccionar trayectorias para el entrenamiento de modelos.

Teoría de categorías en MQL5 (Parte 15): Funtores con grafos
El artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5, analizando los funtores como un puente entre grafos y conjuntos. Volveremos nuevamente a los datos del calendario y, a pesar de sus limitaciones en el uso de un simulador de estrategias, justificaremos el uso de funtores para predecir la volatilidad mediante la correlación.
Cómo desarrollar un agente de aprendizaje por refuerzo en MQL5 con Integración RestAPI (Parte 1): Como usar RestAPIs en MQL5
Este artículo aborda la importancia de las APIs (application programming interface) en la comunicación entre diferentes aplicaciones y sistemas de software. En él, se destaca el papel de las API a la hora de simplificar la interacción entre aplicaciones, ya que les permiten compartir datos y funcionalidades de forma eficiente.

Teoría de categorías en MQL5 (Parte 3)
La teoría de categorías es una rama diversa y en expansión de las matemáticas, relativamente inexplorada aún en la comunidad MQL5. Esta serie de artículos tiene como objetivo destacar algunos de sus conceptos para crear una biblioteca abierta y seguir utilizando esta maravillosa sección para crear estrategias comerciales.

Redes neuronales: así de sencillo (Parte 60): Online Decision Transformer (ODT)
En los 2 últimos artículos nos hemos centrado en el método Decision Transformer, que modela las secuencias de acciones en el contexto de un modelo autorregresivo de recompensas deseadas. En el artículo de hoy, analizaremos otro algoritmo para optimizar este método.
Estimamos la rentabilidad futura usando intervalos de confianza
En este artículo, nos adentraremos en la aplicación de técnicas de bootstrapping como forma de evaluar la rentabilidad futura de una estrategia automatizada.

Redes neuronales: así de sencillo (Parte 80): Modelo generativo y adversarial del Transformador de grafos (GTGAN)
En este artículo, le presentamos el algoritmo GTGAN, introducido en enero de 2024 para resolver problemas complejos de disposición arquitectónica con restricciones gráficas.

Teoría de categorías en MQL5 (Parte 2)
La teoría de categorías es una rama diversa y en expansión de las matemáticas, relativamente inexplorada aún en la comunidad MQL5. Esta serie de artículos tiene como objetivo destacar algunos de sus conceptos para crear una biblioteca abierta y seguir utilizando esta maravillosa sección para crear estrategias comerciales.

Escribimos el primer modelo de caja de cristal (Glass Box) en Python y MQL5
Los modelos de aprendizaje automático son difíciles de interpretar, y entender por qué los modelos no se ajustan a nuestras expectativas puede ayudarnos mucho a conseguir, en última instancia, el resultado deseado al utilizar técnicas tan avanzadas. Sin un conocimiento exhaustivo del funcionamiento interno del modelo, podría resultar difícil encontrar fallos que degraden el rendimiento. De este modo, podremos dedicar tiempo a crear funciones que no afecten a la calidad de la previsión. La conclusión es que, por muy bueno que sea un modelo, nos perderemos todas sus grandes ventajas por culpa de nuestros propios errores. Afortunadamente, existe una solución sofisticada y bien diseñada que permite ver con claridad lo que sucede bajo el capó del modelo.

DoEasy. Elementos de control (Parte 21): Elemento de control SplitContainer. Separador de paneles
En este artículo, crearemos una clase de objeto auxiliar de separador de paneles para el control SplitContainer.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 14): Nacimiento del SIMULADOR (IV)
En este artículo, continuaremos con la fase de desarrollo del simulador. Sin embargo, ahora veremos cómo crear efectivamente un movimiento del tipo "RANDOM WALK" (paseo aleatorio). Este tipo de movimiento es bastante intrigante, ya que sirve de base para todo lo que sucede en el mercado de capitales. Además, comenzarás a comprender algunos conceptos esenciales para quienes realizan análisis de mercado.
Preparación de indicadores de símbolo/periodo múltiple
En este artículo analizaremos los principios de la creación de los indicadores de símbolo/periodo múltiple y la obtención de datos de ellos en asesores e indicadores. Asimismo, veremos los principales matices de uso de los indicadores múltiples en asesores e indicadores, y su representación a través de los búferes del indicador personalizado.

Algoritmos de optimización de la población: Método de Nelder-Mead
En el artículo de hoy, le presentamos un estudio completo del método de Nelder-Mead, en el que se explica cómo el símplex (el espacio de parámetros de la función) se modifica y reordena en cada iteración para alcanzar la solución óptima; asimismo, describiremos una forma de mejorar este método.

Redes neuronales: así de sencillo (Parte 40): Enfoques para utilizar Go-Explore con una gran cantidad de datos
Este artículo analizará el uso del algoritmo Go-Explore durante un largo periodo de aprendizaje, ya que la estrategia de elección aleatoria puede no conducir a una pasada rentable a medida que aumenta el tiempo de entrenamiento.

Teoría de categorías en MQL5 (Parte 19): Inducción cuadrática de la naturalidad
Continuamos analizando las transformaciones naturales considerando la inducción cuadrática de la naturalidad. Pequeñas restricciones en la implementación de las capacidades multidivisa para los asesores ensamblados usando el wizard MQL5 significan que estamos demostrando nuestras capacidades en la clasificación de datos usando un script. Las principales áreas de aplicación son la clasificación de las variaciones de precios y, como consecuencia, su previsión.

Marcado de datos en el análisis de series temporales (Parte 2): Creando conjuntos de datos con marcadores de tendencias utilizando Python
En esta serie de artículos, presentaremos varias técnicas de marcado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El marcado dirigido de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorando la precisión del modelo y ayudando a este a dar un salto de calidad.

Desarrollando un cliente MQTT para MetaTrader 5: metodología de TDD (Parte 3)
El presente artículo supone la tercera parte de la serie que describe las etapas de desarrollo de un cliente MQL5 nativo para el protocolo MQTT. En esta ocasión, hablaremos con detalle sobre la aplicación de un desarrollo basado en pruebas para implementar el intercambio de paquetes CONNECT/CONNACK. Al final de este paso, nuestro cliente DEBERÁ poder comportarse adecuadamente al lidiar con cualquier posible resultado del servidor al intentar conectarse.

Redes neuronales: así de sencillo (Parte 67): Utilizamos la experiencia adquirida para afrontar nuevos retos
En este artículo, seguiremos hablando de los métodos de recopilación de datos en una muestra de entrenamiento. Obviamente, en el proceso de entrenamiento será necesaria una interacción constante con el entorno, aunque con frecuencia se dan situaciones diferentes.

Teoría de categorías (Parte 9): Acciones de monoides
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. En este artículo examinaremos las acciones de los monoides como un medio de transformación de los monoides descritos en el artículo anterior para aumentar sus aplicaciones.

Desarrollo de un sistema de repetición (Parte 34): Sistema de órdenes (III)
En este artículo concluiremos la primera fase de la construcción. Aunque será algo relativamente rápido, explicaré detalles que quizás no se comentaron anteriormente. Pero aquí explicaré algunas cosas que mucha gente no entiende por qué son como son. Uno de estos casos es el del ratón. ¡¡¡¿Sabes por qué tienes que pulsar la tecla Shift o Ctrl en tu teclado?!!!