El método de manejo de datos en grupo: implementación del algoritmo combinatorio en MQL5

Introducción
El algoritmo combinatorio de GMDH, a menudo denominado COMBI, es la forma básica de GMDH y sirve de base para algoritmos más complejos dentro de la familia. Al igual que el algoritmo iterativo multicapa (MIA, Multilayered Iterative Algorithm), opera sobre una muestra de datos de entrada representada como una matriz que contiene observaciones sobre un conjunto de variables. La muestra de datos se divide en dos partes: una muestra de entrenamiento y una muestra de prueba. La submuestra de entrenamiento se utiliza para estimar los coeficientes del polinomio, mientras que la submuestra de prueba se utiliza para seleccionar la estructura del modelo óptimo en función del valor mínimo del criterio seleccionado. En este artículo describiremos el cálculo del algoritmo COMBI. Así como presentar su implementación en MQL5 extendiendo la clase «GmdhModel» descrita en el artículo anterior. Más adelante también discutiremos el algoritmo combinatorio selectivo, estrechamente relacionado, y su implementación en MQL5. Y, por último, concluimos proporcionando una aplicación práctica de los algoritmos GMDH, mediante la construcción de modelos predictivos del precio diario del Bitcoin.
El algoritmo COMBI
La diferencia fundamental entre MIA y COMBI radica en su estructura de red. En contraste con la naturaleza multicapa de MIA, el COMBI se caracteriza por una sola capa.

El número de nodos de esta capa viene determinado por el número de entradas. Donde cada nodo representa un modelo candidato definido por una o más de todas las entradas. Para ilustrarlo, consideremos un ejemplo de un sistema que queremos modelar, definido por 2 variables de entrada. Aplicando el algoritmo COMBI, se utilizan todas las combinaciones posibles de estas variables para construir un modelo candidato. El número de combinaciones posibles viene dado por:

Donde:
- 'm' representa el número de variables de entrada.
Para cada una de estas combinaciones se genera un modelo candidato. Los modelos candidatos evaluados en los nodos de la primera y única capa vienen dados por:

Donde:
- 'a' son los coeficientes , 'a1' es el primer coeficiente y 'a2' es el segundo.
- 'x' son las variables de entrada, 'x1' representa la primera variable de entrada, o predictor, y 'x2' es la segunda.
El proceso consiste en resolver un sistema de ecuaciones lineales para obtener estimaciones de los coeficientes de un modelo candidato. Los criterios de rendimiento de cada modelo se utilizan para seleccionar el modelo final que mejor describe los datos.
Implementación de COMBI en MQL5
El código que implementa el algoritmo COMBI se basa en la clase base GmdhModel descrita en el artículo anterior. También depende de una clase intermedia LinearModel, declarada en linearmodel.mqh. Que resume la característica distintiva más fundamental del método COMBI. El hecho de que los modelos COMBI sean exclusivamente lineales.
//+------------------------------------------------------------------+ //| linearmodel.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "gmdh.mqh" //+------------------------------------------------------------------+ //| Class implementing the general logic of GMDH linear algorithms | //+------------------------------------------------------------------+ class LinearModel:public GmdhModel { protected: vector calculatePrediction(vector& x) { if(x.Size()<ulong(inputColsNumber)) return vector::Zeros(ulong(inputColsNumber)); matrix modifiedX(1,x.Size()+ 1); modifiedX.Row(x,0); modifiedX[0][x.Size()] = 1.0; vector comb = bestCombinations[0][0].combination(); matrix xx(1,comb.Size()); for(ulong i = 0; i<xx.Cols(); ++i) xx[0][i] = modifiedX[0][ulong(comb[i])]; vector c,b; c = bestCombinations[0][0].bestCoeffs(); b = xx.MatMul(c); return b; } virtual matrix xDataForCombination(matrix& x, vector& comb) override { matrix out(x.Rows(), comb.Size()); for(ulong i = 0; i<out.Cols(); i++) out.Col(x.Col(int(comb[i])),i); return out; } virtual string getPolynomialPrefix(int levelIndex, int combIndex) override { return "y="; } virtual string getPolynomialVariable(int levelIndex, int coeffIndex, int coeffsNumber, vector& bestColsIndexes) override { return ((coeffIndex != coeffsNumber - 1) ? "x" + string(int(bestColsIndexes[coeffIndex]) + 1) : ""); } public: LinearModel(void) { } vector predict(vector& x, int lags) override { if(lags <= 0) { Print(__FUNCTION__," lags value must be a positive integer"); return vector::Zeros(1); } if(!training_complete) { Print(__FUNCTION__," model was not successfully trained"); return vector::Zeros(1); } vector expandedX = vector::Zeros(x.Size() + ulong(lags)); for(ulong i = 0; i<x.Size(); i++) expandedX[i]=x[i]; for(int i = 0; i < lags; ++i) { vector vect(x.Size(),slice,expandedX,ulong(i),x.Size()+ulong(i)-1); vector res = calculatePrediction(vect); expandedX[x.Size() + i] = res[0]; } vector vect(ulong(lags),slice,expandedX,x.Size()); return vect; } }; //+------------------------------------------------------------------+
El archivo combi.mqh contiene la definición de la clase COMBI. Hereda de LinearModel y define los métodos «fit()» para ajustar un modelo.
//+------------------------------------------------------------------+ //| combi.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "linearmodel.mqh" //+------------------------------------------------------------------+ //| Class implementing combinatorial COMBI algorithm | //+------------------------------------------------------------------+ class COMBI:public LinearModel { private: Combination getBest(CVector &combinations) { double proxys[]; int best[]; ArrayResize(best,combinations.size()); ArrayResize(proxys,combinations.size()); for(int k = 0; k<combinations.size(); k++) { best[k]=k; proxys[k]=combinations[k].evaluation(); } MathQuickSortAscending(proxys,best,0,int(proxys.Size()-1)); return combinations[best[0]]; } protected: virtual void removeExtraCombinations(void) override { CVector2d realBestCombinations; CVector n; Combination top; for(int i = 0 ; i<bestCombinations.size(); i++) { top = getBest(bestCombinations[i]); n.push_back(top); } top = getBest(n); CVector sorted; sorted.push_back(top); realBestCombinations.push_back(sorted); bestCombinations = realBestCombinations; } virtual bool preparations(SplittedData &data, CVector &_bestCombinations) override { lastLevelEvaluation = DBL_MAX; return (bestCombinations.push_back(_bestCombinations) && ulong(level+1) < data.xTrain.Cols()); } void generateCombinations(int n_cols,vector &out[]) override { GmdhModel::nChooseK(n_cols,level,out); return; } public: COMBI(void):LinearModel() { modelName = "COMBI"; } bool fit(vector &time_series,int lags,double testsize=0.5,CriterionType criterion=stab) { if(lags < 1) { Print(__FUNCTION__," lags must be >= 1"); return false; } PairMVXd transformed = timeSeriesTransformation(time_series,lags); SplittedData splited = splitData(transformed.first,transformed.second,testsize); Criterion criter(criterion); int pAverage = 1; double limit = 0; int kBest = pAverage; if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } bool fit(matrix &vars,vector &targets,double testsize=0.5,CriterionType criterion=stab) { if(vars.Cols() < 1) { Print(__FUNCTION__," columns in vars must be >= 1"); return false; } if(vars.Rows() != targets.Size()) { Print(__FUNCTION__, " vars dimensions donot correspond with targets"); return false; } SplittedData splited = splitData(vars,targets,testsize); Criterion criter(criterion); int pAverage = 1; double limit = 0; int kBest = pAverage; if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } }; //+------------------------------------------------------------------+
Usando la clase COMBI
Ajustar un modelo a un conjunto de datos utilizando la clase COMBI es exactamente lo mismo que aplicar la clase MIA. Creamos una instancia y llamamos a uno de los métodos «fit()». Esto se demuestra en los scripts COMBI_test.mq5 y COMBI_Multivariable_test.mq5.
//+------------------------------------------------------------------+ //| COMBI_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\combi.mqh> input int NumLags = 2; input int NumPredictions = 6; input CriterionType critType = stab; input double DataSplitSize = 0.33; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector tms = {1,2,3,4,5,6,7,8,9,10,11,12}; if(NumPredictions<1) { Alert("Invalid setting for NumPredictions, has to be larger than 0"); return; } COMBI combi; if(!combi.fit(tms,NumLags,DataSplitSize,critType)) return; string modelname = combi.getModelName()+"_"+EnumToString(critType)+"_"+string(DataSplitSize); combi.save(modelname+".json"); vector in(ulong(NumLags),slice,tms,tms.Size()-ulong(NumLags)); vector out = combi.predict(in,NumPredictions); Print(modelname, " predictions ", out); Print(combi.getBestPolynomial()); } //+------------------------------------------------------------------+
Ambos aplican el algoritmo COMBI a los mismos conjuntos de datos utilizados en los scripts de ejemplo que demuestran cómo aplicar el algoritmo MIA de un artículo anterior.
//+------------------------------------------------------------------+ //| COMBI_Multivariable_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\combi.mqh> input CriterionType critType = stab; input double DataSplitSize = 0.33; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- matrix independent = {{1,2,3},{3,2,1},{1,4,2},{1,1,3},{5,3,1},{3,1,9}}; vector dependent = {6,6,7,5,9,13}; COMBI combi; if(!combi.fit(independent,dependent,DataSplitSize,critType)) return; string modelname = combi.getModelName()+"_"+EnumToString(critType)+"_"+string(DataSplitSize)+"_multivars"; combi.save(modelname+".json"); matrix unseen = {{8,6,4},{1,5,3},{9,-5,3}}; for(ulong row = 0; row<unseen.Rows(); row++) { vector in = unseen.Row(row); Print("inputs ", in, " prediction ", combi.predict(in,1)); } Print(combi.getBestPolynomial()); } //+------------------------------------------------------------------+
Observando la salida de COMBI_test.mq5 podemos comparar la complejidad del polinomio ajustado con el producido por el algoritmo MIA. A continuación se muestran los polinomios para las series temporales y el conjunto de datos multivariable, respectivamente.
LR 0 14:54:15.354 COMBI_test (BTCUSD,D1) COMBI_stab_0.33 predictions [13,14,15,16,17,18.00000000000001] PN 0 14:54:15.355 COMBI_test (BTCUSD,D1) y= 1.000000e+00*x1 + 2.000000e+00 CI 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [8,6,4] prediction [18.00000000000001] QD 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [9] QQ 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [9,-5,3] prediction [7.00000000000001] MM 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) y= 1.000000e+00*x1 + 1.000000e+00*x2 + 1.000000e+00*x3 - 7.330836e-15
A continuación, los polinomios revelados por el método MIA.
JQ 0 14:43:07.969 MIA_Test (Step Index 500,M1) MIA_stab_0.33_1_0.0 predictions [13.00000000000001,14.00000000000002,15.00000000000004,16.00000000000005,17.0000000000001,18.0000000000001] IP 0 14:43:07.969 MIA_Test (Step Index 500,M1) y = - 9.340179e-01*x1 + 1.934018e+00*x2 + 3.865363e-16*x1*x2 + 1.065982e+00 II 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [1,2,4] prediction [6.999999999999998] CF 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [8.999999999999998] JR 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [9,1,3] prediction [13.00000000000001] NP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_1 = 1.071429e-01*x1 + 6.428571e-01*x2 + 4.392857e+00 LR 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_2 = 6.086957e-01*x2 - 8.695652e-02*x3 + 4.826087e+00 ME 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_3 = - 1.250000e+00*x1 - 1.500000e+00*x3 + 1.125000e+01 DJ 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) IP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_1 = 1.555556e+00*f1_1 - 6.666667e-01*f1_3 + 6.666667e-01 ER 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_2 = 1.620805e+00*f1_2 - 7.382550e-01*f1_3 + 7.046980e-01 ES 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_3 = 3.019608e+00*f1_1 - 2.029412e+00*f1_2 + 5.882353e-02 NH 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) CN 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f3_1 = 1.000000e+00*f2_1 - 3.731079e-15*f2_3 + 1.155175e-14 GP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f3_2 = 8.342665e-01*f2_2 + 1.713326e-01*f2_3 - 3.359462e-02 DO 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) OG 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) y = 1.000000e+00*f3_1 + 3.122149e-16*f3_2 - 1.899249e-15
El modelo MIA es enrevesado, mientras que el modelo COMBI es menos complicado, como la propia serie. Un reflejo de la naturaleza lineal del método. Esto también se confirma a partir de la salida del script COMBI_Multivariable_test.mq5, que representa un intento de construir un modelo para sumar 3 números proporcionando variables de entrada y ejemplos de salida correspondientes. En este caso, el algoritmo COMBI fue capaz de deducir con éxito las características subyacentes del sistema.
La búsqueda exhaustiva del algoritmo COMBI es a la vez una ventaja y un inconveniente. En el lado positivo, la evaluación de todas las combinaciones de las entradas garantiza que se encuentra el polinomio óptimo que describe los datos. Sin embargo, si existen numerosas variables de entrada, esta búsqueda exhaustiva puede resultar costosa desde el punto de vista informático. Posiblemente se traduzca en largos tiempos de entrenamiento. Recordemos, que el número de modelos candidatos viene dado por 2 elevado a la potencia 'm', todo menos 1. Cuanto mayor sea 'm' mayor será el número de modelos candidatos que haya que evaluar. El algoritmo combinatorio selectivo se desarrolló para resolver este problema.
El algoritmo combinatorio selectivo
El algoritmo combinatorio selectivo, que denominaremos MULTI, se presenta como una mejora del método COMBI en términos de eficacia. Se evita la búsqueda exhaustiva empleando procedimientos similares a los utilizados en los algoritmos multicapa del GMDH. Por lo tanto, puede considerarse un enfoque multicapa frente a la naturaleza monocapa del algoritmo COMBI.

En la primera capa se estiman todos los modelos que contienen una de las variables de entrada, seleccionándose el mejor según los criterios externos y pasando a la capa siguiente. En capas posteriores, se seleccionan diferentes variables de entrada y se añaden a estos modelos candidatos, con la esperanza de mejorarlos. De este modo, se añaden nuevas capas en función de si aumenta la precisión en la estimación de los resultados y/o de la disponibilidad de variables de entrada que no formen ya parte de un modelo candidato. Esto significa que el número máximo de capas posibles coincide con el número total de variables de entrada.
Evaluar los modelos candidatos de esta manera suele evitar una búsqueda exhaustiva, pero también introduce un problema. Existe la posibilidad de que el algoritmo no encuentre el polinomio óptimo que mejor describa el conjunto de datos. Una indicación de que deberían haberse considerado más modelos candidatos en la fase de formación. Deducir el polinomio óptimo se convierte en una cuestión de un ajuste cuidadoso de hiperparámetros. En particular, el número de modelos candidatos que se evalúan en cada capa.
Implementación del algoritmo combinatorio selectivo
La implementación del algoritmo combinatorio selectivo se encuentra en multi.mqh. Contiene la definición de la clase MULTI, que hereda de LinearModel.
//+------------------------------------------------------------------+ //| multi.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "linearmodel.mqh" //+------------------------------------------------------------------+ //| Class implementing combinatorial selection MULTI algorithm | //+------------------------------------------------------------------+ class MULTI : public LinearModel { protected: virtual void removeExtraCombinations(void) override { CVector2d realBestCombinations; CVector n; n.push_back(bestCombinations[0][0]); realBestCombinations.push_back(n); bestCombinations = realBestCombinations; } virtual bool preparations(SplittedData &data, CVector &_bestCombinations) override { return (bestCombinations.setAt(0,_bestCombinations) && ulong(level+1) < data.xTrain.Cols()); } void generateCombinations(int n_cols,vector &out[]) override { if(level == 1) { nChooseK(n_cols,level,out); return; } for(int i = 0; i<bestCombinations[0].size(); i++) { for(int z = 0; z<n_cols; z++) { vector comb = bestCombinations[0][i].combination(); double array[]; vecToArray(comb,array); int found = ArrayBsearch(array,double(z)); if(int(array[found])!=z) { array.Push(double(z)); ArraySort(array); comb.Assign(array); ulong dif = 1; for(uint row = 0; row<out.Size(); row++) { dif = comb.Compare(out[row],1e0); if(!dif) break; } if(dif) { ArrayResize(out,out.Size()+1,100); out[out.Size()-1] = comb; } } } } } public: MULTI(void):LinearModel() { CVector members; bestCombinations.push_back(members); modelName = "MULTI"; } bool fit(vector &time_series,int lags,double testsize=0.5,CriterionType criterion=stab,int kBest = 3,int pAverage = 1,double limit = 0.0) { if(lags < 1) { Print(__FUNCTION__," lags must be >= 1"); return false; } PairMVXd transformed = timeSeriesTransformation(time_series,lags); SplittedData splited = splitData(transformed.first,transformed.second,testsize); Criterion criter(criterion); if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } bool fit(matrix &vars,vector &targets,double testsize=0.5,CriterionType criterion=stab,int kBest = 3,int pAverage = 1,double limit = 0.0) { if(vars.Cols() < 1) { Print(__FUNCTION__," columns in vars must be >= 1"); return false; } if(vars.Rows() != targets.Size()) { Print(__FUNCTION__, " vars dimensions donot correspond with targets"); return false; } SplittedData splited = splitData(vars,targets,testsize); Criterion criter(criterion); if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } }; //+------------------------------------------------------------------+
La clase MULTI funciona de forma similar a la clase COMBI con los conocidos métodos «fit()». En relación con la clase COMBI, los lectores deben tener en cuenta el mayor número de hiperparámetros en los métodos «fit()». «kBest» y “pAverage” son dos parámetros que pueden necesitar un ajuste cuidadoso al aplicar la clase MULTI. El ajuste de un modelo a un conjunto de datos se muestra en los scripts MULTI_test.mq5 y MULTI_Multivariable_test.mq5. El código se presenta a continuación.
//+----------------------------------------------------------------------+ //| MULTI_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+----------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\multi.mqh> input int NumLags = 2; input int NumPredictions = 6; input CriterionType critType = stab; input int Average = 1; input int NumBest = 3; input double DataSplitSize = 0.33; input double critLimit = 0; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector tms = {1,2,3,4,5,6,7,8,9,10,11,12}; if(NumPredictions<1) { Alert("Invalid setting for NumPredictions, has to be larger than 0"); return; } MULTI multi; if(!multi.fit(tms,NumLags,DataSplitSize,critType,NumBest,Average,critLimit)) return; vector in(ulong(NumLags),slice,tms,tms.Size()-ulong(NumLags)); vector out = multi.predict(in,NumPredictions); Print(" predictions ", out); Print(multi.getBestPolynomial()); } //+------------------------------------------------------------------+
//+------------------------------------------------------------------+ //| MULTI_Mulitivariable_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\multi.mqh> input CriterionType critType = stab; input double DataSplitSize = 0.33; input int Average = 1; input int NumBest = 3; input double critLimit = 0; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- matrix independent = {{1,2,3},{3,2,1},{1,4,2},{1,1,3},{5,3,1},{3,1,9}}; vector dependent = {6,6,7,5,9,13}; MULTI multi; if(!multi.fit(independent,dependent,DataSplitSize,critType,NumBest,Average,critLimit)) return; matrix unseen = {{1,2,4},{1,5,3},{9,1,3}}; for(ulong row = 0; row<unseen.Rows(); row++) { vector in = unseen.Row(row); Print("inputs ", in, " prediction ", multi.predict(in,1)); } Print(multi.getBestPolynomial()); } //+------------------------------------------------------------------+
Se puede observar, que al ejecutar los scripts, los polinomios inducidos a partir de nuestros conjuntos de datos simples son exactamente los mismos que los obtenidos aplicando el algoritmo COMBI.
IG 0 18:24:28.811 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [1,2,4] prediction [7.000000000000002] HI 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [9] NO 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [9,1,3] prediction [13.00000000000001] PP 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) y= 1.000000e+00*x1 + 1.000000e+00*x2 + 1.000000e+00*x3 - 7.330836e-15 DP 0 18:25:04.454 MULTI_test (BTCUSD,D1) predictions [13,14,15,16,17,18.00000000000001] MH 0 18:25:04.454 MULTI_test (BTCUSD,D1) y= 1.000000e+00*x1 + 2.000000e+00
Un modelo GMDH para los precios de Bitcoin
En esta sección del texto aplicaremos el método GMDH para construir un modelo predictivo de los precios de cierre diarios de Bitcoin. Esto se realiza en el script GMDH_Price_Model.mq5 adjunto al final del artículo. Aunque nuestra demostración trata específicamente del símbolo Bitcoin, el script puede aplicarse a cualquier símbolo y marco temporal. El script tiene varios parámetros mutables por el usuario que controlan varios aspectos del programa.
//--- input parameters input string SetSymbol=""; input ENUM_GMDH_MODEL modelType = Combi; input datetime TrainingSampleStartDate=D'2019.12.31'; input datetime TrainingSampleStopDate=D'2022.12.31'; input datetime TestSampleStartDate = D'2023.01.01'; input datetime TestSampleStopDate = D'2023.12.31'; input ENUM_TIMEFRAMES tf=PERIOD_D1; //time frame input int Numlags = 3; input CriterionType critType = stab; input PolynomialType polyType = linear_cov; input int Average = 10; input int NumBest = 10; input double DataSplitSize = 0.2; input double critLimit = 0; input ulong NumTestSamplesPlot = 20;
Se enumeran y describen en el siguiente cuadro.
| Nombre del parámetro de entrada | Descripción |
|---|---|
| SetSymbol | Establece el nombre de los símbolos de los precios de cierre que se utilizarán como datos de entrenamiento, si se deja en blanco, se asume el símbolo del gráfico al que se aplica el script. |
| modeltype | Se trata de una enumeración que representa la elección del algoritmo GMDH. |
| TrainingSampleStartDate | Fecha de inicio del periodo de precios de cierre de la muestra. |
| TrainingSampleStopDate | Fecha final del periodo de precios de cierre de la muestra. |
| TestSampleStartDate | Fecha de inicio del periodo de precios fuera de muestra. |
| TestSampleStopDate | Fecha final del periodo de precios fuera de muestra. |
| tf | El marco temporal aplicado. |
| Numlags | Define el número de valores retardados que se utilizarán para pronosticar el próximo precio de cierre. |
| critType | Especifica los criterios externos para el proceso de construcción del modelo. |
| polyType | Tipo de polinomio que se utilizará para construir nuevas variables a partir de las existentes durante el entrenamiento, aplicable sólo cuando se selecciona el algoritmo MIA. |
| Average | El número de los mejores modelos parciales basados a considerar en el cálculo de los criterios de parada |
| Numbest | Para modelos MIA define el número de los mejores modelos parciales en base a los cuales se construirán las nuevas entradas de la capa siguiente, mientras que para los modelos COMBI es el número de modelos candidatos que se seleccionarán en cada capa para su consideración en iteraciones posteriores. |
| DataSplitSize | Fracción de los datos de entrada que deben utilizarse para evaluar los modelos. |
| critLimit | El valor mínimo por el cual el criterio externo debe mejorar para continuar el entrenamiento. |
| NumTestSamplePlot | El valor define el número de muestras del conjunto de datos fuera de la muestra que serán visualizadas junto con las predicciones correspondientes. |
El script comienza con la selección de una muestra adecuada de observaciones que se utilizarán como datos de entrenamiento.
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //get relative shift of IS and OOS sets int trainstart,trainstop, teststart, teststop; trainstart=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TrainingSampleStartDate); trainstop=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TrainingSampleStopDate); teststart=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TestSampleStartDate); teststop=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TestSampleStopDate); //check for errors from ibarshift calls if(trainstart<0 || trainstop<0 || teststart<0 || teststop<0) { Print(ErrorDescription(GetLastError())); return; } //---set the size of the sample sets size_observations=(trainstart - trainstop) + 1 ; size_outsample = (teststart - teststop) + 1; //---check for input errors if(size_observations <= 0 || size_outsample<=0) { Print("Invalid inputs "); return; } //---download insample prices for training int try = 10; while(!prices.CopyRates(SetSymbol,tf,COPY_RATES_CLOSE,TrainingSampleStartDate,TrainingSampleStopDate) && try) { try --; if(!try) { Print("error copying to prices ",GetLastError()); return; } Sleep(5000);
Se descarga otra muestra de precios de cierre, que se utilizará para visualizar el rendimiento del modelo con un gráfico de precios de cierre previstos y reales.
//---download out of sample prices testing try = 10; while(!testprices.CopyRates(SetSymbol,tf,COPY_RATES_CLOSE|COPY_RATES_TIME|COPY_RATES_VERTICAL,TestSampleStartDate,TestSampleStopDate) && try) { try --; if(!try) { Print("error copying to testprices ",GetLastError()); return; } Sleep(5000); }
Los parámetros del script definidos por el usuario permiten la aplicación de uno de los tres modelos GMDH que hemos discutido e implementado.
//--- train and make predictions switch(modelType) { case Combi: { COMBI combi; if(!combi.fit(prices,Numlags,DataSplitSize,critType)) return; Print("Model ", combi.getBestPolynomial()); MakePredictions(combi,testprices.Col(0),predictions); } break; case Mia: { MIA mia; if(!mia.fit(prices,Numlags,DataSplitSize,polyType,critType,NumBest,Average,critLimit)) return; Print("Model ", mia.getBestPolynomial()); MakePredictions(mia,testprices.Col(0),predictions); } break; case Multi: { MULTI multi; if(!multi.fit(prices,Numlags,DataSplitSize,critType,NumBest,Average,critLimit)) return; Print("Model ", multi.getBestPolynomial()); MakePredictions(multi,testprices.Col(0),predictions); } break; default: Print("Invalid GMDH model type "); return; } //---
El programa termina mostrando un gráfico de los precios de cierre previstos junto con los valores reales del conjunto de datos fuera de muestra.
//--- ulong TestSamplesPlot = (NumTestSamplesPlot>0)?NumTestSamplesPlot:20; //--- if(NumTestSamplesPlot>=testprices.Rows()) TestSamplesPlot = testprices.Rows()-Numlags; //--- vector testsample(100,slice,testprices.Col(0),Numlags,Numlags+TestSamplesPlot-1); vector testpredictions(100,slice,predictions,0,TestSamplesPlot-1); vector dates(100,slice,testprices.Col(1),Numlags,Numlags+TestSamplesPlot-1); //--- //Print(testpredictions.Size(), ":", testsample.Size()); //--- double y[], y_hat[]; //--- if(vecToArray(testpredictions,y_hat) && vecToArray(testsample,y) && vecToArray(dates,xaxis)) { PlotPrices(y_hat,y); } //--- ChartRedraw(); }
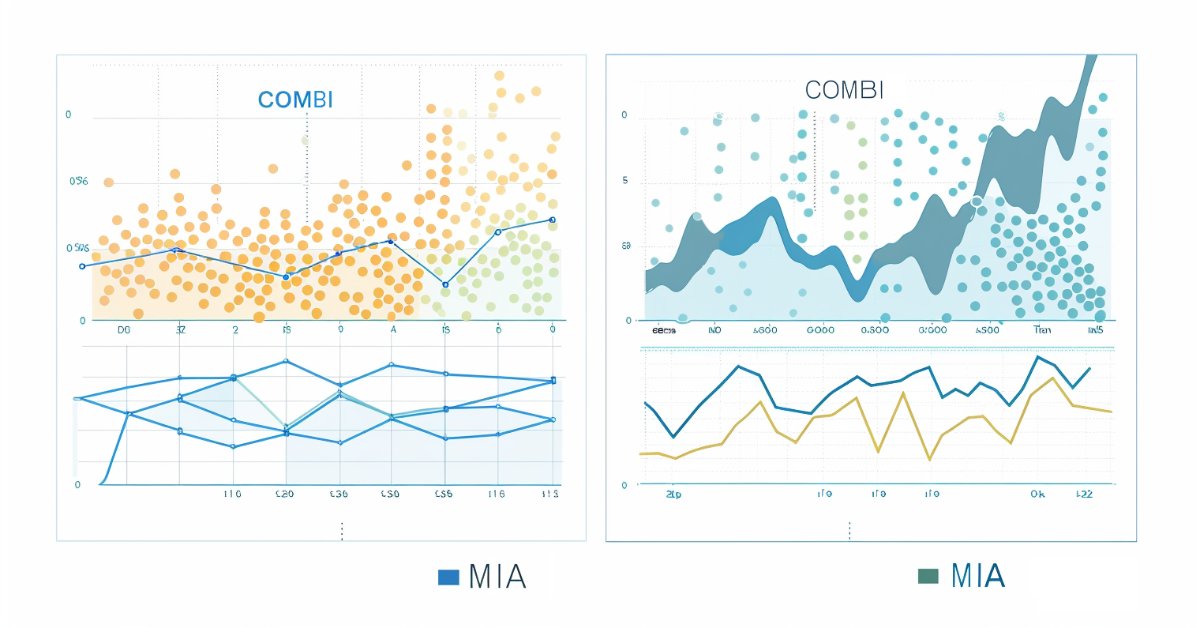
A continuación se muestran los gráficos de las predicciones realizadas con los algoritmos iterativo combinatorio y multicapa, respectivamente.


Conclusión
En conclusión, el algoritmo combinatorio del GMDH ofrece un marco para modelar sistemas complejos, con puntos fuertes particulares en áreas donde los enfoques inductivos basados en datos son ventajosos. Su aplicación práctica es limitada debido a la ineficacia del algoritmo a la hora de manejar grandes conjuntos de datos. El algoritmo combinatorio selectivo mitiga esta deficiencia sólo hasta cierto punto. Las ganancias de velocidad se ven lastradas por la introducción de más hiperparámetros que hay que ajustar para sacar el máximo partido del algoritmo. La aplicación del método GMDH al análisis de series temporales financieras demuestra su potencial para proporcionar información valiosa.
| Archivo | Descripción |
|---|---|
| Mql5\include\VectorMatrixTools.mqh | Archivo de cabecera de definiciones de funciones utilizado para manipular vectores y matrices. |
| Mql5\include\JAson.mqh | Contiene la definición de los tipos personalizados utilizados para analizar y generar objetos JSON. |
| Mql5\include\GMDH\gmdh_internal.mqh | Archivo de cabecera que contiene las definiciones de los tipos personalizados utilizados en la biblioteca GMDH. |
| Mql5\include\GMDH\gmdh.mqh | Archivo de inclusión con la definición de la clase base GmdhModel. |
| Mql5\include\GMDH\linearmodel.mqh | Archivo de inclusión con la definición de la clase intermediaria LinearModel, que es la base para las clases COMBI y MULTI. |
| Mql5\include\GMDH\combi.mqh | Archivo de inclusión con la definición de la clase COMBI. |
| Mql5\include\GMDH\multi.mqh | Archivo de inclusión con la definición de la clase MULTI. |
| Mql5\include\GMDH\mia.mqh | Contiene la clase MIA, que implementa el algoritmo iterativo multicapa. |
| Mql5\script\COMBI_test.mq5 | Un script que demuestra el uso de la clase COMBI construyendo un modelo de una serie temporal simple. |
| Mql5\script\COMBI_Multivariable_test.mq5 | Un script que muestra la aplicación de la clase COMBI para construir un modelo de un conjunto de datos multivariable. |
| Mql5\script\MULTI_test.mq5 | Un script que demuestra el uso de la clase MULTI construyendo un modelo de una serie temporal simple. |
| Mql5\script\MULTI_Multivariable_test.mq5 | Un script que muestra la aplicación de la clase MULTI para construir un modelo de un conjunto de datos multivariable. |
| Mql5\script\GMDH_Price_Model.mqh | Un script que demuestra un modelo GMDH de una serie de precios. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/14804
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso