Метод группового учета аргументов: реализация комбинаторного алгоритма на MQL5

Введение
Комбинаторный алгоритм (COMBI) является базовой формой метода группового учета аргументов (МГУА) и служит основой для более сложных алгоритмов в рамках семейства. Подобно многослойному итеративному алгоритму, он работает с выборкой исходных данных, представленной в виде матрицы, содержащей наблюдения по набору переменных. Выборка делится на две части: обучающую и тестовую. Обучающая подвыборка используется для оценки коэффициентов полинома, а тестовая — для выбора структуры оптимальной модели на основе минимального значения выбранного критерия. В этой статье мы поговорим о расчетах комбинаторного алгоритма. Также представим его реализацию средствами MQL5. Для этого мы расширим класс GmdhModel, описанный в предыдущей статье. Также мы рассмотрим тесно связанный с ним комбинаторный селективный алгоритм и его реализацию на языке MQL5. И в заключение представим практическое применение алгоритмов МГУА. Для этого построим прогностические модели дневной цены биткоина.
Алгоритм COMBI
Принципиальное различие между многослойным итеративным (MIA) и комбинаторным (COMBI) алгоритмами заключается в их сетевой структуре. В отличие от многослойной структуры MIA, COMBI имеет один слой.

Количество узлов в слое определяется количеством входов. Каждый узел представляет собой модель-кандидат, определяемую одним или несколькими входными параметрами из выборки. Для иллюстрации рассмотрим пример системы, которая определяется двумя входными переменными. В алгоритме COMBI все возможные комбинации этих переменных используются для построения модели-кандидата. Количество возможных комбинаций определяется по формуле:

где:
- m — количество входных переменных.
Для каждой из этих комбинаций генерируется модель-кандидат. Модели-кандидаты, оцениваемые в узлах первого и единственного слоя, определяются следующим образом:

где:
- a — коэффициенты; a1 — первый коэффициент, a2 — второй.
- x — входные переменные, x1 — первая входная переменная или предиктор, а x2 — вторая.
Процесс включает в себя решение системы линейных уравнений для получения оценок коэффициентов модели-кандидата. Критерии эффективности каждой модели используются для выбора окончательной модели, которая наилучшим образом описывает данные.
Реализация алгоритма COMBI средствами MQL5
Код, реализующий алгоритм COMBI, основан на базовом классе GmdhModel, который был описан в предыдущей статье. Он также использует промежуточный класс LinearModel, объявленный в linearmodel.mqh. Это и отражает фундаментальную отличительную характеристику метода COMBI. То есть, тот факт, что модели COMBI являются исключительно линейными.
//+------------------------------------------------------------------+ //| linearmodel.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "gmdh.mqh" //+------------------------------------------------------------------+ //| Class implementing the general logic of GMDH linear algorithms | //+------------------------------------------------------------------+ class LinearModel:public GmdhModel { protected: vector calculatePrediction(vector& x) { if(x.Size()<ulong(inputColsNumber)) return vector::Zeros(ulong(inputColsNumber)); matrix modifiedX(1,x.Size()+ 1); modifiedX.Row(x,0); modifiedX[0][x.Size()] = 1.0; vector comb = bestCombinations[0][0].combination(); matrix xx(1,comb.Size()); for(ulong i = 0; i<xx.Cols(); ++i) xx[0][i] = modifiedX[0][ulong(comb[i])]; vector c,b; c = bestCombinations[0][0].bestCoeffs(); b = xx.MatMul(c); return b; } virtual matrix xDataForCombination(matrix& x, vector& comb) override { matrix out(x.Rows(), comb.Size()); for(ulong i = 0; i<out.Cols(); i++) out.Col(x.Col(int(comb[i])),i); return out; } virtual string getPolynomialPrefix(int levelIndex, int combIndex) override { return "y="; } virtual string getPolynomialVariable(int levelIndex, int coeffIndex, int coeffsNumber, vector& bestColsIndexes) override { return ((coeffIndex != coeffsNumber - 1) ? "x" + string(int(bestColsIndexes[coeffIndex]) + 1) : ""); } public: LinearModel(void) { } vector predict(vector& x, int lags) override { if(lags <= 0) { Print(__FUNCTION__," lags value must be a positive integer"); return vector::Zeros(1); } if(!training_complete) { Print(__FUNCTION__," model was not successfully trained"); return vector::Zeros(1); } vector expandedX = vector::Zeros(x.Size() + ulong(lags)); for(ulong i = 0; i<x.Size(); i++) expandedX[i]=x[i]; for(int i = 0; i < lags; ++i) { vector vect(x.Size(),slice,expandedX,ulong(i),x.Size()+ulong(i)-1); vector res = calculatePrediction(vect); expandedX[x.Size() + i] = res[0]; } vector vect(ulong(lags),slice,expandedX,x.Size()); return vect; } }; //+------------------------------------------------------------------+
Файл combi.mqh содержит определение класса COMBI. Он унаследован от LinearModel и определяет методы fit() для обучения модели.
//+------------------------------------------------------------------+ //| combi.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "linearmodel.mqh" //+------------------------------------------------------------------+ //| Class implementing combinatorial COMBI algorithm | //+------------------------------------------------------------------+ class COMBI:public LinearModel { private: Combination getBest(CVector &combinations) { double proxys[]; int best[]; ArrayResize(best,combinations.size()); ArrayResize(proxys,combinations.size()); for(int k = 0; k<combinations.size(); k++) { best[k]=k; proxys[k]=combinations[k].evaluation(); } MathQuickSortAscending(proxys,best,0,int(proxys.Size()-1)); return combinations[best[0]]; } protected: virtual void removeExtraCombinations(void) override { CVector2d realBestCombinations; CVector n; Combination top; for(int i = 0 ; i<bestCombinations.size(); i++) { top = getBest(bestCombinations[i]); n.push_back(top); } top = getBest(n); CVector sorted; sorted.push_back(top); realBestCombinations.push_back(sorted); bestCombinations = realBestCombinations; } virtual bool preparations(SplittedData &data, CVector &_bestCombinations) override { lastLevelEvaluation = DBL_MAX; return (bestCombinations.push_back(_bestCombinations) && ulong(level+1) < data.xTrain.Cols()); } void generateCombinations(int n_cols,vector &out[]) override { GmdhModel::nChooseK(n_cols,level,out); return; } public: COMBI(void):LinearModel() { modelName = "COMBI"; } bool fit(vector &time_series,int lags,double testsize=0.5,CriterionType criterion=stab) { if(lags < 1) { Print(__FUNCTION__," lags must be >= 1"); return false; } PairMVXd transformed = timeSeriesTransformation(time_series,lags); SplittedData splited = splitData(transformed.first,transformed.second,testsize); Criterion criter(criterion); int pAverage = 1; double limit = 0; int kBest = pAverage; if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } bool fit(matrix &vars,vector &targets,double testsize=0.5,CriterionType criterion=stab) { if(vars.Cols() < 1) { Print(__FUNCTION__," columns in vars must be >= 1"); return false; } if(vars.Rows() != targets.Size()) { Print(__FUNCTION__, " vars dimensions donot correspond with targets"); return false; } SplittedData splited = splitData(vars,targets,testsize); Criterion criter(criterion); int pAverage = 1; double limit = 0; int kBest = pAverage; if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } }; //+------------------------------------------------------------------+
Использование класса COMBI
Обучение модели на выборке данных с использованием класса COMBI не отличается от обучения, которое мы проводили для класса MIA. Создаем экземпляр и вызываем один из методов fit(). Как показано в скриптах COMBI_test.mq5 и COMBI_Multivariable_test.mq5.
//+------------------------------------------------------------------+ //| COMBI_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\combi.mqh> input int NumLags = 2; input int NumPredictions = 6; input CriterionType critType = stab; input double DataSplitSize = 0.33; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector tms = {1,2,3,4,5,6,7,8,9,10,11,12}; if(NumPredictions<1) { Alert("Invalid setting for NumPredictions, has to be larger than 0"); return; } COMBI combi; if(!combi.fit(tms,NumLags,DataSplitSize,critType)) return; string modelname = combi.getModelName()+"_"+EnumToString(critType)+"_"+string(DataSplitSize); combi.save(modelname+".json"); vector in(ulong(NumLags),slice,tms,tms.Size()-ulong(NumLags)); vector out = combi.predict(in,NumPredictions); Print(modelname, " predictions ", out); Print(combi.getBestPolynomial()); } //+------------------------------------------------------------------+
Оба скрипта запускают алгоритм COMBI на одном и том же наборе данных. Этот же набор мы использовали ранее в примерах алгоритма MIA в предыдущей статье.
//+------------------------------------------------------------------+ //| COMBI_Multivariable_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\combi.mqh> input CriterionType critType = stab; input double DataSplitSize = 0.33; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- matrix independent = {{1,2,3},{3,2,1},{1,4,2},{1,1,3},{5,3,1},{3,1,9}}; vector dependent = {6,6,7,5,9,13}; COMBI combi; if(!combi.fit(independent,dependent,DataSplitSize,critType)) return; string modelname = combi.getModelName()+"_"+EnumToString(critType)+"_"+string(DataSplitSize)+"_multivars"; combi.save(modelname+".json"); matrix unseen = {{8,6,4},{1,5,3},{9,-5,3}}; for(ulong row = 0; row<unseen.Rows(); row++) { vector in = unseen.Row(row); Print("inputs ", in, " prediction ", combi.predict(in,1)); } Print(combi.getBestPolynomial()); } //+------------------------------------------------------------------+
По результатам COMBI_test.mq5 сложность обученного полинома можно сравнить со сложностью алгоритма MIA. Ниже приведены полиномы для временного ряда и многомерного набора данных соответственно.
LR 0 14:54:15.354 COMBI_test (BTCUSD,D1) COMBI_stab_0.33 predictions [13,14,15,16,17,18.00000000000001] PN 0 14:54:15.355 COMBI_test (BTCUSD,D1) y= 1.000000e+00*x1 + 2.000000e+00 CI 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [8,6,4] prediction [18.00000000000001] QD 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [9] QQ 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [9,-5,3] prediction [7.00000000000001] MM 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) y= 1.000000e+00*x1 + 1.000000e+00*x2 + 1.000000e+00*x3 - 7.330836e-15
А это полиномы, выявленные методом MIA:
JQ 0 14:43:07.969 MIA_Test (Step Index 500,M1) MIA_stab_0.33_1_0.0 predictions [13.00000000000001,14.00000000000002,15.00000000000004,16.00000000000005,17.0000000000001,18.0000000000001] IP 0 14:43:07.969 MIA_Test (Step Index 500,M1) y = - 9.340179e-01*x1 + 1.934018e+00*x2 + 3.865363e-16*x1*x2 + 1.065982e+00 II 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [1,2,4] prediction [6.999999999999998] CF 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [8.999999999999998] JR 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [9,1,3] prediction [13.00000000000001] NP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_1 = 1.071429e-01*x1 + 6.428571e-01*x2 + 4.392857e+00 LR 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_2 = 6.086957e-01*x2 - 8.695652e-02*x3 + 4.826087e+00 ME 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_3 = - 1.250000e+00*x1 - 1.500000e+00*x3 + 1.125000e+01 DJ 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) IP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_1 = 1.555556e+00*f1_1 - 6.666667e-01*f1_3 + 6.666667e-01 ER 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_2 = 1.620805e+00*f1_2 - 7.382550e-01*f1_3 + 7.046980e-01 ES 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_3 = 3.019608e+00*f1_1 - 2.029412e+00*f1_2 + 5.882353e-02 NH 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) CN 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f3_1 = 1.000000e+00*f2_1 - 3.731079e-15*f2_3 + 1.155175e-14 GP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f3_2 = 8.342665e-01*f2_2 + 1.713326e-01*f2_3 - 3.359462e-02 DO 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) OG 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) y = 1.000000e+00*f3_1 + 3.122149e-16*f3_2 - 1.899249e-15
Модель MIA получилась более сложной. Модель COMBI проще, собственно как и сама линейная последовательность. Это отражает линейную природу метода. Это также подтверждается результатом скрипта COMBI_Multivariable_test.mq5, который представляет собой попытку построить модель для суммирования трех чисел по указанным входным переменным. В данном случае алгоритм COMBI смог успешно определить базовые характеристики системы.
Полный поиск в алгоритме COMBI является одновременно и преимуществом, и недостатком. К положительным сторонам можно отнести оценку всех комбинаций входных данных, что гарантирует нахождение оптимального полинома, описывающего данные. Однако при наличии большого количества входных переменных такой обширный поиск может оказаться весьма затратным с точки зрения вычислений. Это вероятно приведет к увеличению времени обучения. Напомню, что количество моделей-кандидатов определяется как 2 в степени m, и чем больше m, тем большее количество моделей-кандидатов необходимо оценить. Собственно для решения такой проблемы и был разработан комбинаторный селективный алгоритм.
Комбинаторный селективный алгоритм
Комбинаторный селективный алгоритм, который мы будем называть MULTI, позиционируется как усовершенствованный метод COMBI с точки зрения эффективности. Здесь не приходится делать полный поиск за счет использования процессов, аналогичных тем, которые используются в многоуровневых алгоритмах МГУА. Таким образом, MULTI можно рассматривать как многоуровневый подход к одноуровневой природе алгоритма COMBI.

На первом уровне оцениваются все модели, содержащие одну из входных переменных, при этом лучшая из них выбирается в соответствии с внешними критериями и передается на следующий уровень. На последующих уровнях выбираются и добавляются к этим потенциальным моделям различные входные переменные в попытке улучшить их. Добавление новых слоев зависит от того, повысилась ли точность оценки выходных данных, и/или от доступности входных переменных, которые еще не являются частью модели-кандидата. Таким образом, максимальное количество возможных слоев совпадает с общим количеством входных переменных.
Такая оценка моделей-кандидатов часто позволяет избежать необходимости проводить полный поиск, но, с другой стороны, это также создает проблему. Существует вероятность, что алгоритм не сможет найти оптимальный полином, наилучшим образом описывающий набор данных. Это говорит о том, что на этапе обучения нужно было рассмотреть больше моделей-кандидатов. Для вывода оптимального полинома необходима тщательная настройка гиперпараметров. В частности, количество моделей-кандидатов, оцениваемых на каждом уровне.
Реализация комбинаторного селективного алгоритма
Реализация комбинаторного селективного алгоритма представлена в файле multi.mqh. Он содержит определение класса MULTI, который наследуется от LinearModel.
//+------------------------------------------------------------------+ //| multi.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "linearmodel.mqh" //+------------------------------------------------------------------+ //| Class implementing combinatorial selection MULTI algorithm | //+------------------------------------------------------------------+ class MULTI : public LinearModel { protected: virtual void removeExtraCombinations(void) override { CVector2d realBestCombinations; CVector n; n.push_back(bestCombinations[0][0]); realBestCombinations.push_back(n); bestCombinations = realBestCombinations; } virtual bool preparations(SplittedData &data, CVector &_bestCombinations) override { return (bestCombinations.setAt(0,_bestCombinations) && ulong(level+1) < data.xTrain.Cols()); } void generateCombinations(int n_cols,vector &out[]) override { if(level == 1) { nChooseK(n_cols,level,out); return; } for(int i = 0; i<bestCombinations[0].size(); i++) { for(int z = 0; z<n_cols; z++) { vector comb = bestCombinations[0][i].combination(); double array[]; vecToArray(comb,array); int found = ArrayBsearch(array,double(z)); if(int(array[found])!=z) { array.Push(double(z)); ArraySort(array); comb.Assign(array); ulong dif = 1; for(uint row = 0; row<out.Size(); row++) { dif = comb.Compare(out[row],1e0); if(!dif) break; } if(dif) { ArrayResize(out,out.Size()+1,100); out[out.Size()-1] = comb; } } } } } public: MULTI(void):LinearModel() { CVector members; bestCombinations.push_back(members); modelName = "MULTI"; } bool fit(vector &time_series,int lags,double testsize=0.5,CriterionType criterion=stab,int kBest = 3,int pAverage = 1,double limit = 0.0) { if(lags < 1) { Print(__FUNCTION__," lags must be >= 1"); return false; } PairMVXd transformed = timeSeriesTransformation(time_series,lags); SplittedData splited = splitData(transformed.first,transformed.second,testsize); Criterion criter(criterion); if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } bool fit(matrix &vars,vector &targets,double testsize=0.5,CriterionType criterion=stab,int kBest = 3,int pAverage = 1,double limit = 0.0) { if(vars.Cols() < 1) { Print(__FUNCTION__," columns in vars must be >= 1"); return false; } if(vars.Rows() != targets.Size()) { Print(__FUNCTION__, " vars dimensions donot correspond with targets"); return false; } SplittedData splited = splitData(vars,targets,testsize); Criterion criter(criterion); if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } }; //+------------------------------------------------------------------+
Класс MULTI работает аналогично классу COMBI, использует метод fit(). Обратите внимание на большее количество гиперпараметров в методах fit() по сравнению с классом COMBI. kBest и pAverage — два параметра, которые необходимо тщательно настраивать при применении класса MULTI. Обучение модели на наборе данных происходит в скриптах MULTI_test.mq5 и MULTI_Multivariable_test.mq5. Код скриптов представлен ниже.
//+----------------------------------------------------------------------+ //| MULTI_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+----------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\multi.mqh> input int NumLags = 2; input int NumPredictions = 6; input CriterionType critType = stab; input int Average = 1; input int NumBest = 3; input double DataSplitSize = 0.33; input double critLimit = 0; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector tms = {1,2,3,4,5,6,7,8,9,10,11,12}; if(NumPredictions<1) { Alert("Invalid setting for NumPredictions, has to be larger than 0"); return; } MULTI multi; if(!multi.fit(tms,NumLags,DataSplitSize,critType,NumBest,Average,critLimit)) return; vector in(ulong(NumLags),slice,tms,tms.Size()-ulong(NumLags)); vector out = multi.predict(in,NumPredictions); Print(" predictions ", out); Print(multi.getBestPolynomial()); } //+------------------------------------------------------------------+
//+------------------------------------------------------------------+ //| MULTI_Mulitivariable_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\multi.mqh> input CriterionType critType = stab; input double DataSplitSize = 0.33; input int Average = 1; input int NumBest = 3; input double critLimit = 0; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- matrix independent = {{1,2,3},{3,2,1},{1,4,2},{1,1,3},{5,3,1},{3,1,9}}; vector dependent = {6,6,7,5,9,13}; MULTI multi; if(!multi.fit(independent,dependent,DataSplitSize,critType,NumBest,Average,critLimit)) return; matrix unseen = {{1,2,4},{1,5,3},{9,1,3}}; for(ulong row = 0; row<unseen.Rows(); row++) { vector in = unseen.Row(row); Print("inputs ", in, " prediction ", multi.predict(in,1)); } Print(multi.getBestPolynomial()); } //+------------------------------------------------------------------+
Как видите, при запуске скриптов полиномы, полученные из наших простых выборок, в точности совпадают с полиномами, полученными при применении алгоритма COMBI.
IG 0 18:24:28.811 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [1,2,4] prediction [7.000000000000002] HI 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [9] NO 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [9,1,3] prediction [13.00000000000001] PP 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) y= 1.000000e+00*x1 + 1.000000e+00*x2 + 1.000000e+00*x3 - 7.330836e-15 DP 0 18:25:04.454 MULTI_test (BTCUSD,D1) predictions [13,14,15,16,17,18.00000000000001] MH 0 18:25:04.454 MULTI_test (BTCUSD,D1) y= 1.000000e+00*x1 + 2.000000e+00
Модель МГУА для прогнозирования цен на биткоины
В этом разделе попробуем применить метод МГУА, чтобы построить прогностическую модель дневных цен закрытия на биткоин. Реализуем это в скрипте GMDH_Price_Model.mq5, он целиком приложен в конце статьи. Хотя данный пример касается конкретно символа Bitcoin, скрипт можно применить к любому символу и таймфрейму. В скрипте есть несколько параметров, задаваемых пользователем, которые управляют различными аспектами программы.
//--- input parameters input string SetSymbol=""; input ENUM_GMDH_MODEL modelType = Combi; input datetime TrainingSampleStartDate=D'2019.12.31'; input datetime TrainingSampleStopDate=D'2022.12.31'; input datetime TestSampleStartDate = D'2023.01.01'; input datetime TestSampleStopDate = D'2023.12.31'; input ENUM_TIMEFRAMES tf=PERIOD_D1; //time frame input int Numlags = 3; input CriterionType critType = stab; input PolynomialType polyType = linear_cov; input int Average = 10; input int NumBest = 10; input double DataSplitSize = 0.2; input double critLimit = 0; input ulong NumTestSamplesPlot = 20;
Их значение объясняется в следующей таблице.
| Имя входного параметра | Описание |
|---|---|
| SetSymbol | Задает имя символа, цены закрытия которого будут использоваться в качестве обучающих данных. Если оставить поле пустым, будет использоваться символ текущего графика, на котором запускается скрипт. |
| modeltype | Перечисление для выбора алгоритма МГУА |
| TrainingSampleStartDate | Начальная дата для периода в выборке цены закрытия |
| TrainingSampleStopDate | Конечная дата для периода в выборке цены закрытия |
| TestSampleStartDate | Начальная дата периода цен вне выборки |
| TestSampleStopDate | Конечная дата периода цен вне выборки |
| tf | Используемый таймфрейм |
| Numlags | Определяет количество запаздывающих значений, которые будут использоваться для прогнозирования следующей цены закрытия |
| critType | Определяет внешние критерии для процесса построения модели |
| polyType | Тип полинома, который будет использоваться для построения новых переменных из существующих во время обучения, применим только при выборе алгоритма MIA |
| Average | Число лучших частичных моделей, которые следует учитывать при расчете критериев остановки |
| Numbest | Для моделей MIA параметр определяет количество лучших частичных моделей, на основе которых будут построены новые входы последующего слоя Для моделей COMBI это количество моделей-кандидатов, которые будут выбраны на каждом уровне для рассмотрения в последующих итерациях. |
| DataSplitSize | Доля входных данных, которая должна использоваться для оценки моделей |
| critLimit | Минимальное значение, на которое внешний критерий должен улучшаться для продолжения обучения |
| NumTestSamplePlot | Значение определяет количество выборок из набора данных вне выборки, которые будут визуализированы вместе с соответствующими прогнозами. |
Скрипт начинается с выбора подходящей выборки наблюдений для использования в качестве обучающих данных.
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //get relative shift of IS and OOS sets int trainstart,trainstop, teststart, teststop; trainstart=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TrainingSampleStartDate); trainstop=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TrainingSampleStopDate); teststart=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TestSampleStartDate); teststop=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TestSampleStopDate); //check for errors from ibarshift calls if(trainstart<0 || trainstop<0 || teststart<0 || teststop<0) { Print(ErrorDescription(GetLastError())); return; } //---set the size of the sample sets size_observations=(trainstart - trainstop) + 1 ; size_outsample = (teststart - teststop) + 1; //---check for input errors if(size_observations <= 0 || size_outsample<=0) { Print("Invalid inputs "); return; } //---download insample prices for training int try = 10; while(!prices.CopyRates(SetSymbol,tf,COPY_RATES_CLOSE,TrainingSampleStartDate,TrainingSampleStopDate) && try) { try --; if(!try) { Print("error copying to prices ",GetLastError()); return; } Sleep(5000);
Загружается еще одна выборка цен закрытия, которая будет использоваться для визуализации эффективности модели с построением прогнозируемых и фактических цен закрытия.
//---download out of sample prices testing try = 10; while(!testprices.CopyRates(SetSymbol,tf,COPY_RATES_CLOSE|COPY_RATES_TIME|COPY_RATES_VERTICAL,TestSampleStartDate,TestSampleStopDate) && try) { try --; if(!try) { Print("error copying to testprices ",GetLastError()); return; } Sleep(5000); }
В зависимости от выбора пользователя, скрипт будет использовать одну из трех моделей МГУА, которые мы обсудили и реализовали.
//--- train and make predictions switch(modelType) { case Combi: { COMBI combi; if(!combi.fit(prices,Numlags,DataSplitSize,critType)) return; Print("Model ", combi.getBestPolynomial()); MakePredictions(combi,testprices.Col(0),predictions); } break; case Mia: { MIA mia; if(!mia.fit(prices,Numlags,DataSplitSize,polyType,critType,NumBest,Average,critLimit)) return; Print("Model ", mia.getBestPolynomial()); MakePredictions(mia,testprices.Col(0),predictions); } break; case Multi: { MULTI multi; if(!multi.fit(prices,Numlags,DataSplitSize,critType,NumBest,Average,critLimit)) return; Print("Model ", multi.getBestPolynomial()); MakePredictions(multi,testprices.Col(0),predictions); } break; default: Print("Invalid GMDH model type "); return; } //---
В завершение программы отображается графика прогнозируемых цен закрытия вместе с фактическими значениями из данных вне выборки.
//--- ulong TestSamplesPlot = (NumTestSamplesPlot>0)?NumTestSamplesPlot:20; //--- if(NumTestSamplesPlot>=testprices.Rows()) TestSamplesPlot = testprices.Rows()-Numlags; //--- vector testsample(100,slice,testprices.Col(0),Numlags,Numlags+TestSamplesPlot-1); vector testpredictions(100,slice,predictions,0,TestSamplesPlot-1); vector dates(100,slice,testprices.Col(1),Numlags,Numlags+TestSamplesPlot-1); //--- //Print(testpredictions.Size(), ":", testsample.Size()); //--- double y[], y_hat[]; //--- if(vecToArray(testpredictions,y_hat) && vecToArray(testsample,y) && vecToArray(dates,xaxis)) { PlotPrices(y_hat,y); } //--- ChartRedraw(); }
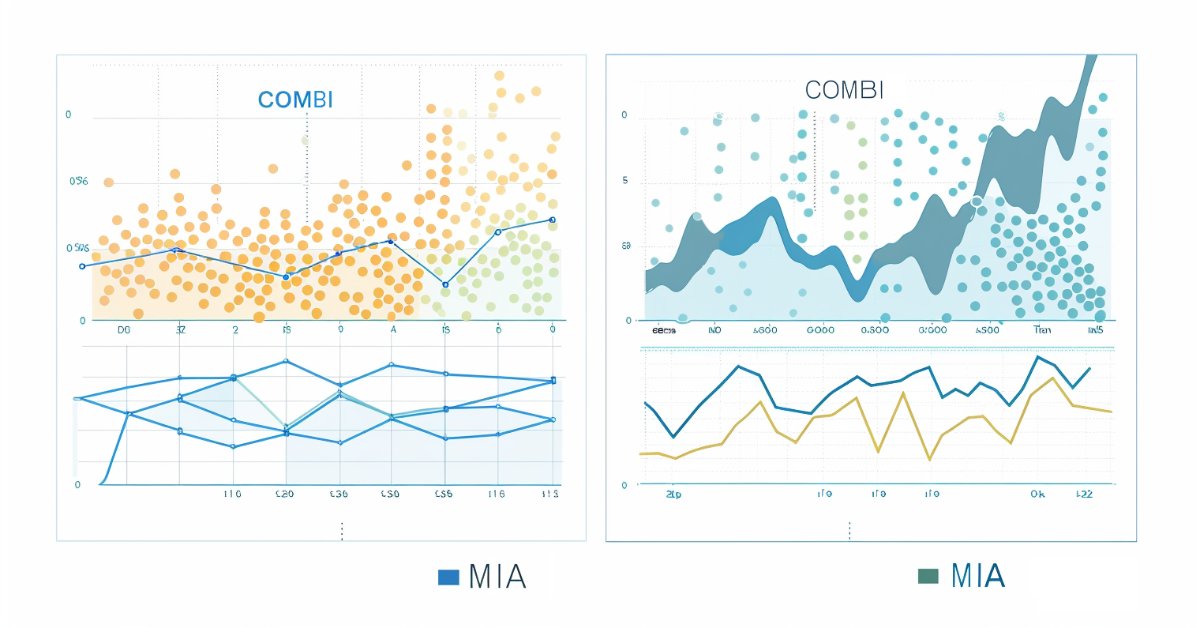
Ниже показаны прогнозов, сделанные с использованием комбинаторного и многослойного итеративного алгоритмов соответственно.


Заключение
В заключение следует отметить, что комбинаторный алгоритм МГУА предлагает основу для моделирования сложных систем. Он особенно хорошо работает в областях, где большую пользу приносят индуктивные подходы, основанные на данных. Его практическое применение ограничено из-за недостаточной эффективности алгоритма при обработке больших наборов данных. Комбинаторный селективный алгоритм в некоторой степени смягчает этот недостаток. Однако рост скорости нивелируется введением большего количества гиперпараметров, которые необходимо тщательно настраивать, чтобы получить максимальные результаты от алгоритма. В целом же применение методов группового учета аргументов (МГУА) в финансовом анализе временных рядов демонстрирует его потенциал в предоставлении ценной информации.
| Файл | Описание |
|---|---|
| Mql5\include\VectorMatrixTools.mqh | Заголовочный файл определений функций, используемых для работы с векторами и матрицами |
| Mql5\include\JAson.mqh | Содержит определение пользовательских типов, используемых для анализа и генерации объектов JSON |
| Mql5\include\GMDH\gmdh_internal.mqh | Заголовочный файл, содержащий определения пользовательских типов, используемых в библиотеке gmdh |
| Mql5\include\GMDH\gmdh.mqh | Файл include с определением базового класса GmdhModel |
| Mql5\include\GMDH\linearmodel.mqh | Включаемый файл, содержащий определение промежуточного класса LinearModel, который является основой для классов COMBI и MULTI |
| Mql5\include\GMDH\combi.mqh | Включаемый файл с определением класса COMBI |
| Mql5\include\GMDH\multi.mqh | Включаемый файл с определением класса MULTI |
| Mql5\include\GMDH\mia.mqh | Содержит класс MIA, реализующий многослойный итерационный алгоритм |
| Mql5\script\COMBI_test.mq5 | Cкрипт, демонстрирующий использование класса COMBI через построение модели простого временного ряда |
| Mql5\script\COMBI_Multivariable_test.mq5 | Скрипт, демонстрирующий применение класса COMBI для построения модели многомерного набора данных |
| Mql5\script\MULTI_test.mq5 | Скрипт, демонстрирующий использование класса MULTI через построение модели простого временного ряда |
| Mql5\script\MULTI_Multivariable_test.mq5 | Скрипт, демонстрирующий применение класса MULTI для построения модели многомерного набора данных |
| Mql5\script\GMDH_Price_Model.mqh | Скрипт, демонстрирующий модель МГУА на ценовом ряде |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/14804
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования