
Datenwissenschaft und ML(Teil 30): Das Power-Paar für die Vorhersage des Aktienmarktes, Convolutional Neural Networks (CNNs) und Recurrent Neural Networks (RNNs)

Inhalt
- Einführung
- Verstehen von RNNs und CNNs
- Die Synergie von CNNs und RNNs
- Merkmalsextraktion mit CNNs
- Zeitliche Modellierung mit RNNs
- Training und Vorhersagen
- Eine Kombination aus CNN und LSTM
- Eine Kombination aus CNN und GRU
- Schlussfolgerung
Einführung
In den vorangegangenen Artikeln haben wir gesehen, wie leistungsstark sowohl Convolutional Neural Networks (CNNs) als auch Recurrent Neural Networks (RNNs) sind und wie sie eingesetzt werden können, um den Markt zu schlagen, indem sie uns wertvolle Handelssignale liefern.
In diesem Beitrag werden wir versuchen, zwei der leistungsfähigsten Techniken CNN und RNN zu kombinieren und ihre prädiktive Wirkung auf den Aktienmarkt zu beobachten. Doch zuvor wollen wir kurz verstehen, was es mit CNN und RNN auf sich hat.
Verständnis rekurrenter neuronaler Netze (RNNs) und gefalteter (Convolutional) neuronaler Netze (CNNs)
Convolutional Neural Networks (CNNs) wurden entwickelt, um Muster und Merkmale in den Daten zu erkennen. Obwohl sie ursprünglich für Bilderkennungsaufgaben entwickelt wurden, sind sie auch für tabellarische Daten geeignet, die speziell für Zeitreihenprognosen entwickelt wurden.
Wie bereits in den vorangegangenen Artikeln erwähnt, werden zunächst Filter auf die Eingabedaten angewandt, und dann werden hochrangige Merkmale extrahiert, die für die Vorhersage nützlich sein können. Bei Börsendaten sind dies unter anderem Trends, saisonale Effekte und Anomalien.

CNN-Architektur
Indem wir die hierarchische Natur von CNNs nutzen, können wir Schichten von Datendarstellungen aufdecken, die jeweils Einblicke in verschiedene Aspekte des Marktes bieten.
Rekurrente neuronale Netze (RNN) sind künstliche neuronale Netze, die darauf ausgelegt sind, Muster in Datenfolgen zu erkennen, z. B. in Zeitreihen, Sprachen oder in Videos.
Im Gegensatz zu herkömmlichen neuronalen Netzen, bei denen davon ausgegangen wird, dass die Eingaben unabhängig voneinander sind, können RNNs Muster aus einer Folge von Daten (Informationen) erkennen und verstehen.
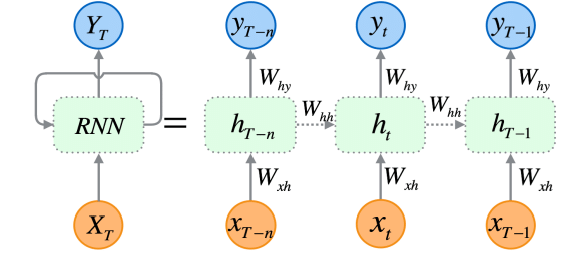
RNNs sind explizit für sequentielle Daten konzipiert. Ihre Architektur ermöglicht es ihnen, einen Speicher für frühere Eingaben zu behalten, wodurch sie sich sehr gut für Zeitreihenprognosen eignen, da sie in der Lage sind, zeitliche Abhängigkeiten innerhalb der Daten zu verstehen, was für genaue Vorhersagen auf dem Aktienmarkt entscheidend ist.
Wie ich in Teil 25 dieser Artikelserie erklärt habe, gibt es drei (häufig verwendete) spezifische Arten von RNNs, darunter ein Vanilla Recurrent Neural Network (RNN), Long-Short Term Memory (LSTM) und Gated Recurrent Unit (GRU).
Da CNNs hervorragend darin sind, Merkmale aus den Daten zu extrahieren und zu erkennen, sind RNNs außergewöhnlich gut darin, diese Merkmale im Zeitverlauf zu interpretieren. Die Idee ist einfach: Wir wollen diese beiden Elemente kombinieren und sehen, ob wir ein leistungsfähiges und robustes Modell entwickeln können, das bessere Prognosen für den Aktienmarkt ermöglicht.
Die Synergie von CNNs und RNNs
Um diese beiden zu integrieren, werden wir die Modelle in drei Schritten erstellen.
- Merkmalsextraktion mit CNNs
- Zeitliche Modellierung mit RNNs
- Trainieren und Vorhersagen erhalten
Gehen wir einen Schritt nach dem anderen durch und erstellen wir dieses robuste Modell, das sowohl aus RNN als auch aus LSTM besteht.
01: Merkmalsextraktion mit CNNs
In diesem ersten Schritt werden die Zeitreihendaten in ein CNN-Modell eingespeist. Das CNN-Modell verarbeitet die Daten, identifiziert signifikante Muster und extrahiert relevante Merkmale.
Verwendung des Tesla-Aktiendatensatzes, der aus Eröffnungs-, Höchst-, Tiefst- und Schlusskursen besteht. Wir beginnen mit der Aufbereitung der Daten in ein 3D-Zeitreihenformat, das von CNNs und RNNs akzeptiert wird.
Lassen Sie uns die Zielvariable für ein Klassifikationsproblem erstellen.
Python-Code
target_var = [] open_price = new_df["Open"] close_price = new_df["Close"] for i in range(len(open_price)): if close_price[i] > open_price[i]: # Closing price is greater than opening price target_var.append(1) # buy signal else: target_var.append(0) # sell signal
Wir normalisieren die Daten mit dem Standard-Scalierer, um sie für ML-Zwecke robust zu machen.
X = new_df.iloc[:, :-1] y = target_var # Scalling the data scaler = StandardScaler() X = scaler.fit_transform(X) # Train-test split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) print(f"x_train = {X_train.shape} - x_test = {X_test.shape}\n\ny_train = {len(y_train)} - y_test = {len(y_test)}")
Ausgänge
x_train = (799, 3) - x_test = (200, 3) y_train = 799 - y_test = 200
Anschließend können wir die Daten im Zeitreihenformat aufbereiten.
# creating the sequence
X_train, y_train = create_sequences(X_train, y_train, time_step)
X_test, y_test = create_sequences(X_test, y_test, time_step) Da es sich um ein Klassifizierungsproblem handelt, kodieren wir die Zielvariable in einem Durchgang.
from tensorflow.keras.utils import to_categorical
y_train_encoded = to_categorical(y_train)
y_test_encoded = to_categorical(y_test)
print(f"One hot encoded\n\ny_train {y_train_encoded.shape}\ny_test {y_test_encoded.shape}") Ausgabe
One hot encoded y_train (794, 2) y_test (195, 2)
Die Merkmalsextraktion erfolgt durch das CNN-Modell selbst. Geben wir dem Modell Rohdaten, die wir gerade vorbereitet haben.
model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2))
02: Zeitliche Modellierung mit RNNs
Die im vorherigen Schritt extrahierten Merkmale werden dann an das RNN-Modell weitergeleitet. Das Modell verarbeitet diese Merkmale unter Berücksichtigung der zeitlichen Abfolge und der Abhängigkeiten innerhalb der Daten.
Anders als bei der CNN-Modellarchitektur, die wir in Teil 27 dieser Artikelserie verwendet haben, wo wir vollständig verbundene neuronale Netzwerkschichten direkt nach der Schicht „Flatten“ verwendet haben. Diesmal ersetzen wir diese regulären Schichten des Neuronalen Netzes (NN) durch Schichten des rekurrenten Neuronalen Netzes (RNN).
Vergessen wir nicht, die im Bild der CNN-Architektur zu sehende „Flatten“-Schicht zu entfernen.
Wir entfernen die Flatten-Schicht in der CNN-Architektur, da diese Schicht in der Regel verwendet wird, um eine 3D-Eingabe in eine 2D-Ausgabe zu konvertieren, während die RNNs (RNN, LSTM und GRU) 3D-Eingabedaten in Form von (Losgröße, Zeitschritte, Merkmale) erwarten.
model.add(MaxPooling1D(pool_size=2)) model.add(SimpleRNN(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # Softmax for binary classification (1 buy, 0 sell signal)
03: Trainieren und Vorhersagen erhalten
Schließlich können wir das Modell, das wir in den beiden vorangegangenen Schritten erstellt haben, trainieren, es validieren, seine Leistung messen und dann die Vorhersagen daraus ableiten.
Python-Code
model.summary()
# Compile the model
optimizer = Adam(learning_rate=0.0001)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
history = model.fit(X_train, y_train_encoded, epochs=1000, batch_size=16, validation_split=0.2, callbacks=[early_stopping])
plt.figure(figsize=(7.5, 6))
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.legend()
plt.savefig("training loss curve-rnn-cnn-clf.png")
plt.show()
# Evaluating the Trained Model
y_pred = model.predict(X_test)
classes_in_y = np.unique(y)
y_pred_binary = classes_in_y[np.argmax(y_pred, axis=1)]
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix RNN + CNN.png") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) Ausgabe
Nach der Auswertung des Modells nach 14 Epochen lag die Genauigkeit des Modells bei den Testdaten bei 54 %.

7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step Classification Report precision recall f1-score support 0 0.70 0.40 0.51 117 1 0.45 0.74 0.56 78 accuracy 0.54 195 macro avg 0.58 0.57 0.54 195 weighted avg 0.60 0.54 0.53 195
Es ist erwähnenswert, dass das Training des endgültigen Modells einige Zeit in Anspruch nahm, als mehr Schichten hinzugefügt wurden, was auf die Komplexität der beiden kombinierten Modelle zurückzuführen ist.
Nach dem Training musste ich das endgültige Modell im ONNX-Format speichern.
Python-Code
onnx_file_name = "rnn+cnn.TSLA.D1.onnx" spec = (tf.TensorSpec((None, time_step, X_train.shape[2]), tf.float16, name="input"),) model.output_names = ['outputs'] onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=13) # Save the ONNX model to a file with open(onnx_file_name, "wb") as f: f.write(onnx_model.SerializeToString())
Vergessen wir nicht, auch die Parameter des Standardisierungs-Skalierers zu speichern.
# Save the mean and scale parameters to binary files scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin") scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
Ich habe das gespeicherte ONNX-Modell in Netron geöffnet, es ist sehr umfangreich.

Ähnlich wie wir zuvor das Convolutional Neural Network (CNN) eingesetzt haben, können wir die gleiche Bibliothek verwenden, um uns bei der Aufgabe zu helfen, dieses massive Modell mühelos in MQL5 zu lesen.
#include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler; //from preprocessing.mqh
Zuvor müssen wir jedoch die Parameter für das ONNX-Modell und den Standardisierungs-Skalierer zu unserem Expert Advisor als Ressourcen hinzufügen.
#resource "\\Files\\rnn+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\rnn+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\rnn+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[]
Das erste, was wir innerhalb der OnInit-Funktion tun müssen, ist, beide zu initialisieren (den Standardisierungs-Skalierer und das CNN-Modell).
int OnInit() { //--- if (!cnn.Init(onnx_model)) //Initialize the Convolutional neural network return INIT_FAILED; scaler = new StandardizationScaler(standardization_mean, standardization_std); //Initialize the saved scaler by populating it with values ... ... return (INIT_SUCCEEDED); }
Um die Vorhersagen zu erhalten, müssen wir die Eingabedaten mithilfe dieses vorgeladenen Skalierers normalisieren, dann wenden wir die normalisierten Daten auf das CNN-Modell an und erhalten das vorhergesagte Signal und die Wahrscheinlichkeiten.
if (NewBar()) //Trade at the opening of a new candle { CopyRates(Symbol(), PERIOD_D1, 1, time_step, rates); for (ulong i=0; i<x_data.Rows(); i++) { x_data[i][0] = rates[i].open; x_data[i][1] = rates[i].high; x_data[i][2] = rates[i].low; } //--- x_data = scaler.transform(x_data); //Normalize the data int signal = cnn.predict_bin(x_data, classes_in_data_); //getting a trading signal from the RNN model vector probabilities = cnn.predict_proba(x_data); //probability for each class Comment("Probability = ",probabilities,"\nSignal = ",signal);
Nachfolgend sehen Sie, wie der Kommentar in der Grafik aussieht.

Der Wahrscheinlichkeitsvektor hängt von den Klassen ab, die in der Zielvariablen Ihrer Trainingsdaten vorhanden waren. Anhand der Trainingsdaten haben wir die Zielvariable so vorbereitet, dass sie 0 für ein Verkaufssignal und 1 für ein Kaufsignal anzeigt. Die Klassenbezeichnungen oder Nummern müssen in aufsteigender Reihenfolge angegeben werden.
input int time_step = 5; input int magic_number = 24092024; input int slippage = 100; MqlRates rates[]; matrix x_data(time_step, 3); //3 columns for open, high and low vector classes_in_data_ = {0, 1}; //unique target variables as they are in the target variable in your training data int OldNumBars = 0; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //---
Die Matrix mit dem Namen x_data ist für die vorübergehende Speicherung der unabhängigen Variablen (Merkmale) des Marktes zuständig. Diese Matrix wird auf 3 Spalten verkleinert, da wir das Modell anhand von 3 Merkmalen (Open, High und Low) trainiert haben, und auf die Anzahl der Zeilen verkleinert, die dem Zeitschrittwert entspricht.
Der Wert des Zeitschritts muss demjenigen entsprechen, der bei der Erstellung der sequenziellen Trainingsdaten verwendet wurde.
Wir können eine einfache Strategie entwickeln, die auf den Signalen des von uns erstellten Modells basiert.
double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { ClosePos(POSITION_TYPE_SELL); //close sell trades when the signal is buy if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions { if (!m_trade.Buy(min_lot, Symbol(), ticks.ask, 0 , 0)) //Open a buy trade printf("Failed to open a buy position err=%d",GetLastError()); } } else if (signal==0) //Bearish signal { ClosePos(POSITION_TYPE_BUY); //close all buy trades when the signal is sell if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions { if (!m_trade.Sell(min_lot, Symbol(), ticks.bid, 0 , 0)) //open a sell trade printf("Failed to open a sell position err=%d",GetLastError()); } } else //There was an error return;
Da das Modell nun geladen und bereit ist, Vorhersagen zu treffen, habe ich einen Test vom 01.01.2020 bis zum 09.09.2024 durchgeführt. Nachfolgend finden Sie das vollständige Bild der Testerkonfiguration (Einstellungen).
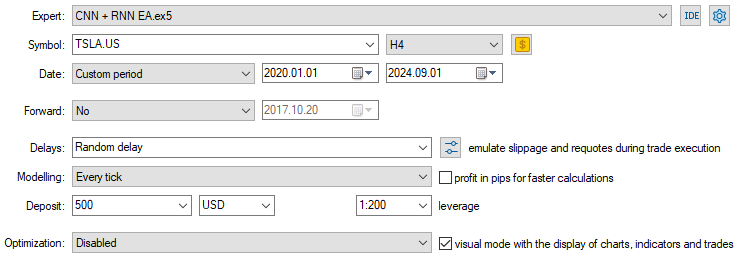
Beachten Sie, dass ich den EA auf einem 4-Stunden-Chart angewendet habe, anstatt auf dem täglichen Zeitrahmen, auf dem die Daten der Tesla-Aktie gesammelt wurden. Das liegt daran, dass wir die Strategie und die Modelle so programmiert haben, dass sie sofort nach dem Öffnen der neuen Kerze in Aktion treten, aber die Tageskerze wird normalerweise geöffnet, wenn der Markt geschlossen ist, sodass der EA den Handel bis zum nächsten Tag verpasst.
Indem wir den EA auf einen niedrigeren Zeitrahmen anwenden (in diesem Fall einen 4-Stunden-Zeitrahmen), stellen wir sicher, dass wir den Markt nach jeweils 4 Stunden kontinuierlich überwachen und einige Handelsaktivitäten durchführen.
Dies hat keinen Einfluss auf die Daten, die dem EA zur Verfügung gestellt werden, da wir die CopyRates-Funktion auf den täglichen Zeitrahmen angewendet haben (Handelsentscheidungen hängen immer noch vom Tages-Chart ab)
Nachstehend sehen Sie das Ergebnis des Testers.
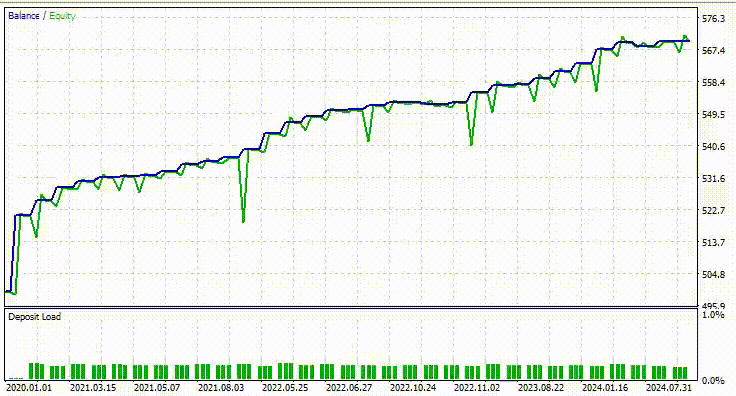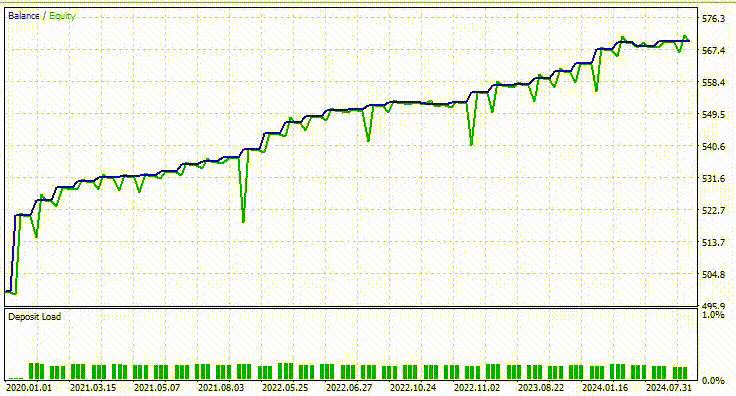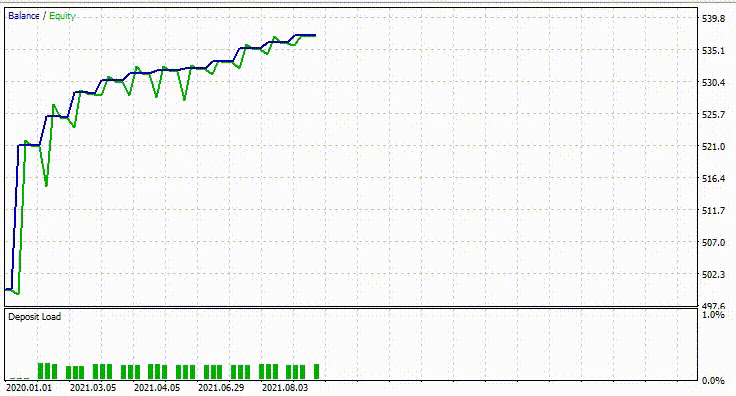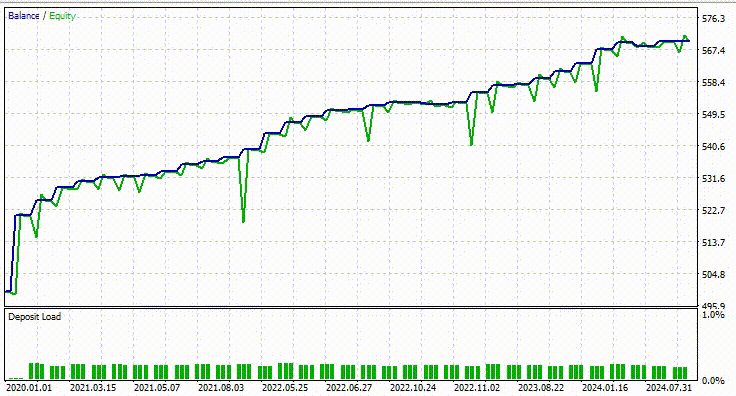
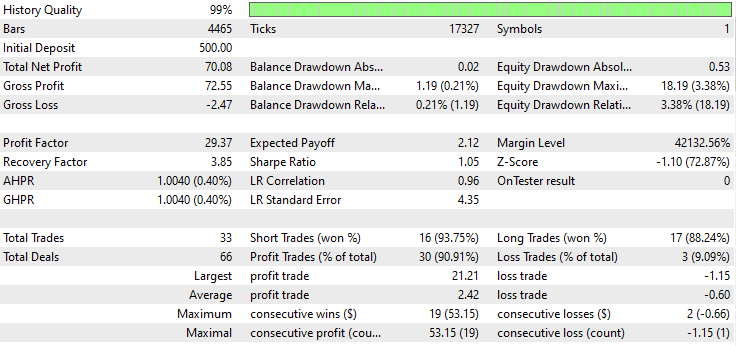
Beeindruckend! 90% der Handelsgeschäfte des EAs sind profitable. Das KI-Modell war nur ein einfaches RNN.
Nun wollen wir sehen, wie gut LSTM und GRU auf demselben Markt abschneiden.
Eine Kombination aus Convolutional Neural Network (CNN) und Long-Short Term Memory (LSTM)
Im Gegensatz zu einem einfachen RNN, das nicht in der Lage ist, Muster in langen Daten- oder Informationssequenzen zu erkennen, kann das LSTM Beziehungen und Muster in langen Informationssequenzen erkennen.
LSTMs sind oft effizienter und genauer als einfache RNNs. Lassen Sie uns ein CNN-Modell mit LSTM erstellen und dann beobachten, wie es bei der Tesla-Aktie abschneidet.
Python-Code
from tensorflow.keras.layers import LSTM # Define the CNN model model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2)) model.add(LSTM(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # For binary classification (e.g., buy/sell signal) model.summary()
Da alle RNNs auf die gleiche Weise implementiert werden können, musste ich nur eine einzige Änderung an dem Codeblock vornehmen, der zur Erstellung eines einfachen RNN verwendet wird.
Nach dem Training und der Validierung des Modells betrug seine Genauigkeit 53 % bei den Testdaten.
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 36ms/step Classification Report precision recall f1-score support 0 0.67 0.44 0.53 117 1 0.45 0.68 0.54 78 accuracy 0.53 195 macro avg 0.56 0.56 0.53 195 weighted avg 0.58 0.53 0.53 195
In der Programmiersprache MQL5 können wir dieselbe Bibliothek verwenden, die wir für das einfache RNN EA benutzt haben.
#resource "\\Files\\lstm+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\lstm+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\lstm+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[] #include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler;
Der Rest des Codes ist derselbe wie bei der CNN + RNN EA.
Ich habe die gleichen Testereinstellungen wie zuvor verwendet, und das Ergebnis ist wie folgt.
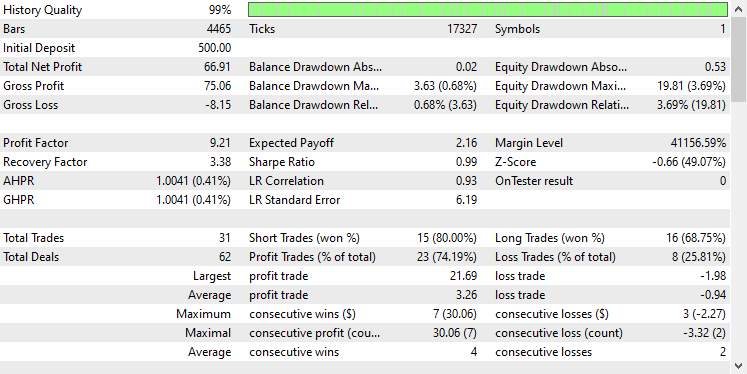
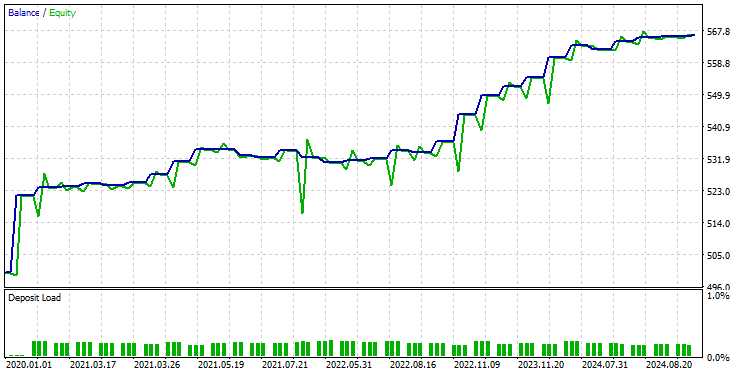
Diesmal liegt die Gesamtgenauigkeit bei ca. 74 %, was zwar niedriger ist als beim Vorgängermodell, aber immer noch hervorragend!
Eine Kombination aus Convolutional Neural Network (CNN) und Gated Recurrent Unit (GRU)
Genau wie das LSTM sind auch GRU-Modelle in der Lage, die Beziehungen zwischen langen Informations- und Datensequenzen zu verstehen, obwohl sie im Vergleich zum LSTM-Modell einen minimalistischen Ansatz verfolgen.
Wir können es genauso implementieren wie andere RNN-Modelle, wir ändern nur die Art des Modells im Code für den Aufbau der CNN-Modellarchitektur.
from tensorflow.keras.layers import GRU # Define the CNN model model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2)) model.add(GRU(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # For binary classification (e.g., buy/sell signal) model.summary()
Nach dem Training und der Validierung des Modells erreichte das Modell eine ähnliche Genauigkeit wie das LSTM, nämlich 53 % Genauigkeit bei den Testdaten.
7/7 ━━━━━━━━━━━━━━━━━━━━ 1s 41ms/step Classification Report precision recall f1-score support 0 0.69 0.39 0.50 117 1 0.45 0.73 0.55 78 accuracy 0.53 195 macro avg 0.57 0.56 0.53 195 weighted avg 0.59 0.53 0.52 195
Wir laden das GRU-Modell im ONNX-Format und seine Skalierungsparameter in Binärdateien.
#resource "\\Files\\gru+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\gru+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\gru+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[] #include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler;
Auch hier ist der Rest des Codes derselbe wie bei dem einfachen RNN EA.
Nachdem ich das Modell mit denselben Einstellungen auf dem Tester getestet hatte, ergab sich folgendes Bild.
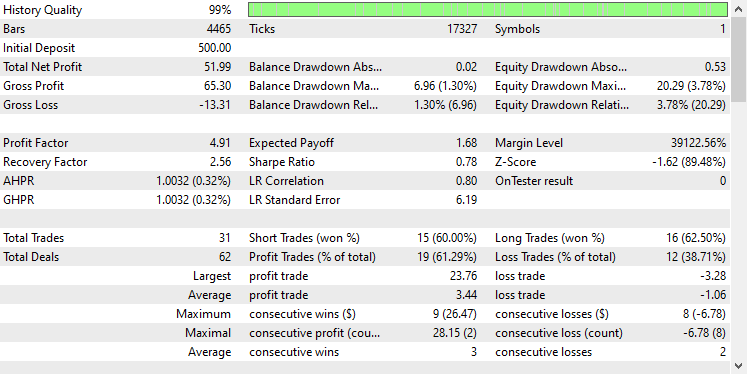
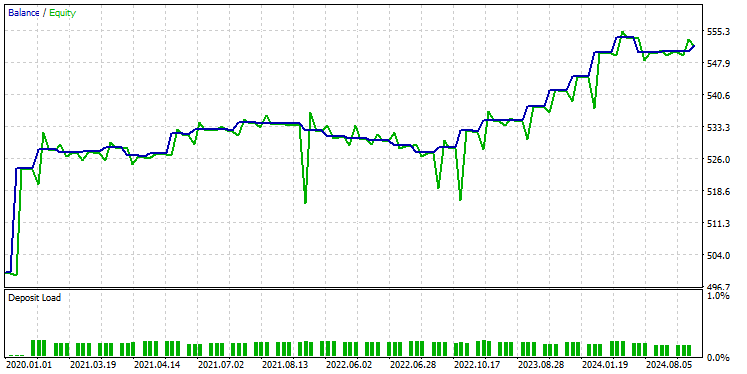
Das GRU-Modell lieferte eine Genauigkeit von etwa 61 %, was zwar nicht so gut ist wie die beiden vorherigen Modelle, aber dennoch ein ordentliches Ergebnis darstellt.
Abschließende Überlegungen
Die Integration von Convolutional Neural Networks (CNNs) mit Recurrent Neural Networks (RNNs) kann ein leistungsfähiger Ansatz für Börsenprognosen sein, der das Potenzial bietet, versteckte Muster und zeitliche Abhängigkeiten in Daten aufzudecken. Diese Kombination ist jedoch relativ ungewöhnlich und bringt gewisse Herausforderungen mit sich. Eines der Hauptrisiken ist die Überanpassung, vor allem bei der Anwendung solch anspruchsvoller Modelle auf relativ einfache Probleme. Eine Überanpassung kann dazu führen, dass das Modell in den Trainingsdaten gut funktioniert, aber nicht auf neue Daten verallgemeinert werden kann.
Darüber hinaus führt die Komplexität der Kombination von CNNs und RNNs zu einem erheblichen Rechenaufwand, insbesondere wenn Sie das Modell durch Hinzufügen weiterer dichterer Schichten oder durch Erhöhung der Anzahl der Neuronen vergrößern wollen. Es ist wichtig, die Komplexität des Modells sorgfältig mit den verfügbaren Ressourcen und dem jeweiligen Problem abzugleichen.
Peace out.
Verfolgen Sie die Entwicklung von Modellen für maschinelles Lernen und vieles mehr in dieser Artikelserie auf diesem GitHub repo.
Tabelle der Anhänge
Dateiname | Dateityp | Beschreibung und Verwendung |
|---|---|---|
Experts\CNN + GRU EA.mq5 Experts\CNN + LSTM EA.mq5 Experts\CNN + RNN EA.mq5 | Expert Advisors | Handelsroboter zum Laden der ONNX-Modelle und Testen der Handelsstrategie im MetaTrader 5. |
ConvNet.mqh preprocessing.mqh | einzubindende Dateien |
|
Files\ *.onnx | ONNX-Modelle | Modelle für maschinelles Lernen, die in diesem Artikel im ONNX-Format behandelt werden |
| Files\*.bin | Binärdateien | Binärdateien zum Laden der Parameter des Normierungsskalers für jedes Modell |
Jupyter Notebook\cnns-rnns.ipynb | python/Jupyter notebook | Der gesamte Python-Code, der in diesem Artikel besprochen wird, ist in diesem Notizbuch zu finden. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/15585
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.