
Kategorientheorie in MQL5 (Teil 19): Induktion natürlicher Quadrate
Einführung:
In dieser Artikelserie haben wir die Anwendung der Kategorientheorie bei der Klassifizierung diskreter Daten behandelt und anhand einiger Beispiele gezeigt, wie Handelsalgorithmen, vor allem solche, die Trailing Stops verwalten, aber auch solche, die Einstiegssignale und Positionsgrößen verwalten, nahtlos in einen Expert Advisor integriert werden können, um einige ihrer Konzepte umzusetzen. Der MQL5-Assistent in der IDE hat dabei eine wichtige Rolle gespielt, da der gesamte gemeinsame Quellcode mit dem Assistenten zusammengefügt werden muss, um ein testbares System zu erhalten.
In diesem Artikel werden wir uns darauf konzentrieren, wie man natürliche Quadrate, ein Konzept, das wir in unserem letzten Artikel eingeführt haben, mit der Induktion nutzen kann. Die potenziell anwendbaren Vorteile werden anhand von 3 Devisenpaaren demonstriert, die durch Arbitrage miteinander verbunden werden können. Wir versuchen, die Preisänderungsdaten für eines der Paare zu klassifizieren, um festzustellen, ob wir einen Einstiegssignal-Algorithmus für dieses Paar entwickeln können.
Natürliche Quadrate sind die Erweiterung der Natürlichen Transformation in ein kommutatives Diagramm. Wenn wir also zwei getrennte Kategorien mit mehr als einem Funktor zwischen ihnen haben, können wir die Beziehungen zwischen zwei oder mehr Objekten in der Co-Domain-Kategorie bewerten und diese Analyse nicht nur nutzen, um Beziehungen zu anderen ähnlichen Kategorien herzustellen, sondern auch um Prognosen innerhalb der betrachteten Kategorie zu erstellen, wenn die Objekte in einer Zeitreihe liegen.
Verstehen Sie das Setup:
Unsere beiden Kategorien für diesen Artikel haben eine ähnliche Struktur wie die, die wir für den letzten Artikel betrachtet haben, da sie zwei Funktoren zwischen sich haben werden. Das ist jedoch die Hauptähnlichkeit, da wir in diesem Fall mehrere Objekte in beiden Kategorien haben werden, während wir im letzten Fall zwei Objekte in der Domänenkategorie und nur vier in der Codomäne hatten.
In der Domänenkategorie, die eine einzelne Zeitreihe enthält, wird also jeder Preispunkt in dieser Reihe als ein Objekt dargestellt. Diese „Objekte“ werden in ihrer chronologischen Reihenfolge durch Morphismen verknüpft, die sie einfach auf den Zeitrahmen des Diagramms, dem das Skript zugeordnet ist, hochrechnen. Da wir es mit Zeitreihen zu tun haben, bedeutet dies außerdem, dass unsere Kategorie ungebunden ist und daher keine Kardinalität hat. Auch hier gilt, wie schon in unseren Artikeln, dass wir uns nicht für die Gesamtgröße und den Inhalt der Kategorien/Objekte an sich interessieren, sondern für die Morphismen und insbesondere für die Funktoren aus diesen Objekten.
In der Codomain-Kategorie haben wir zwei Preiszeitreihen für die beiden anderen Devisenpaare. Erinnern Sie sich daran, dass für eine trianguläre Arbitrage mindestens drei Devisenpaare erforderlich sind. Es könnten mehr sein, aber in unserem Fall verwenden wir das Minimum, um unsere Implementierung relativ einfach zu halten. Die Domänenkategorie wird also ihre Preisreihen für das erste Paar haben, das USDJPY sein wird. Die beiden anderen Paare, die als Preisreihen in die Kategorie Codomain aufgenommen werden, sind EURJPY und EURUSD.
Die Morphismen, die die Preispunkt-„Objekte“ in der zweiten Kategorie verbinden, sind nur innerhalb einer bestimmten Serie vorhanden, da wir zu Beginn keine Verbindung zwischen den Objekten in jeder Serie haben.
Natürliche Quadrate und Induktion:
Das Konzept der natürlichen Quadrate innerhalb der Kategorientheorie betont also das Kommutativgesetz, das in unserem letzten Artikel als Mittel zur Überprüfung einer Klassifikation verwendet wurde. Betrachten wir zur Erinnerung das folgende Diagramm, das vier Objekte in der Kategorie Codomain darstellt:
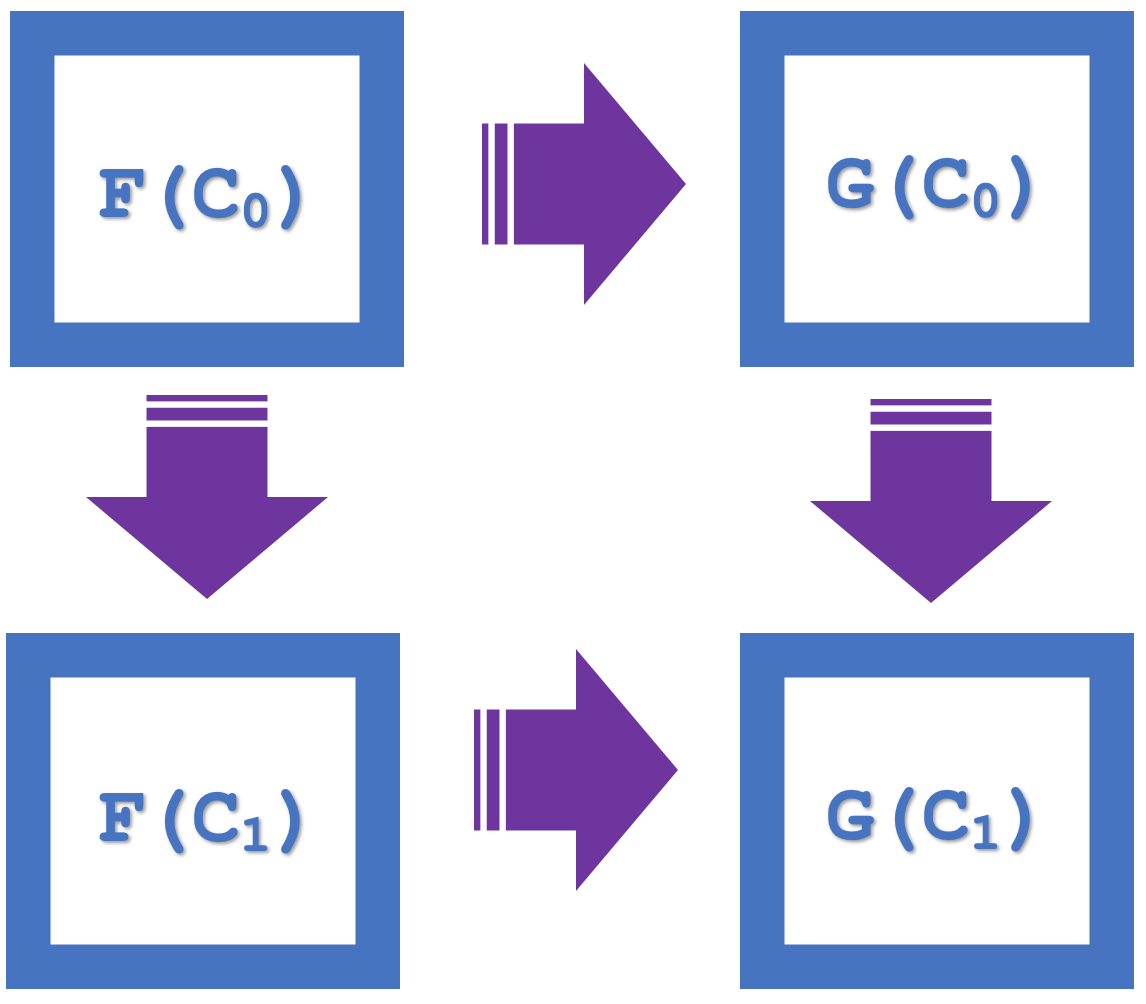
Wir können sehen, dass es eine Kommutation gibt, da F(C 0 ) zu G(C 0 ) und dann G(C 1 ) äquivalent zu F(C 0 ) zu F(C 1 ) und dann G(C 1 ) ist.
Das Konzept der Induktion, das in diesem Artikel vorgestellt wird, hebt die Fähigkeit hervor, über Serien von mehreren Quadraten zu wechseln, was das Design vereinfacht und Rechenressourcen spart. Betrachten wir das folgende Diagramm, in dem n Quadrate aufgelistet sind:
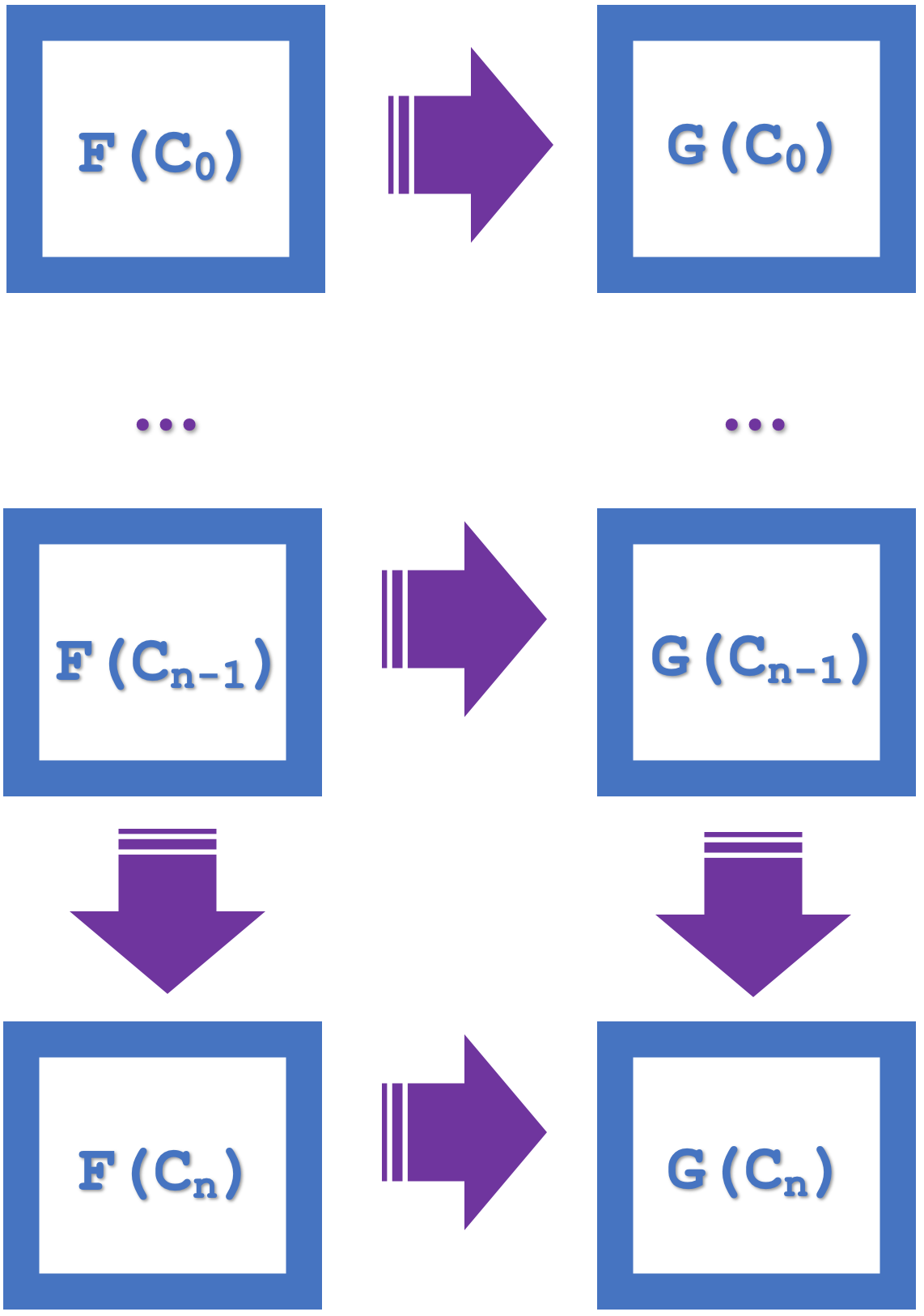
Wenn die kleinen natürlichen Quadrate kommutativ sind, folgt daraus, dass auch das größere Rechteck kommutativ ist. Diese größere Kommutation impliziert Morphismen und Funktoren in einem Abstand von ‚n‘. Unsere beiden Funktoren werden also beide aus der USDJPY-Serie stammen, aber mit verschiedenen Serien von EURJPY und EURUSD verbunden sein. Die natürlichen Transformationen werden daher von EURJPY zu EURUSD sein. Da wir wie in unserem letzten Artikel das/die natürliche(n) Quadrat(e) für die Klassifizierung verwenden, beziehen sich unsere Prognosen auf die Codomäne der natürlichen Transformationen, und das ist EURUSD. Die Induktion ermöglicht es uns, diese Prognosen über mehrere Balken hinweg zu betrachten, im Gegensatz zu nur einem wie im letzten Artikel. Im letzten Artikel war der Versuch einer Mehrbalkenprognose angesichts der vielen zufälligen Entscheidungswälder, die verwendet werden mussten, sehr rechenintensiv. Durch Induktion können wir nun mit der Klassifizierung bei „n bars lag“ (vor n Balken) beginnen.
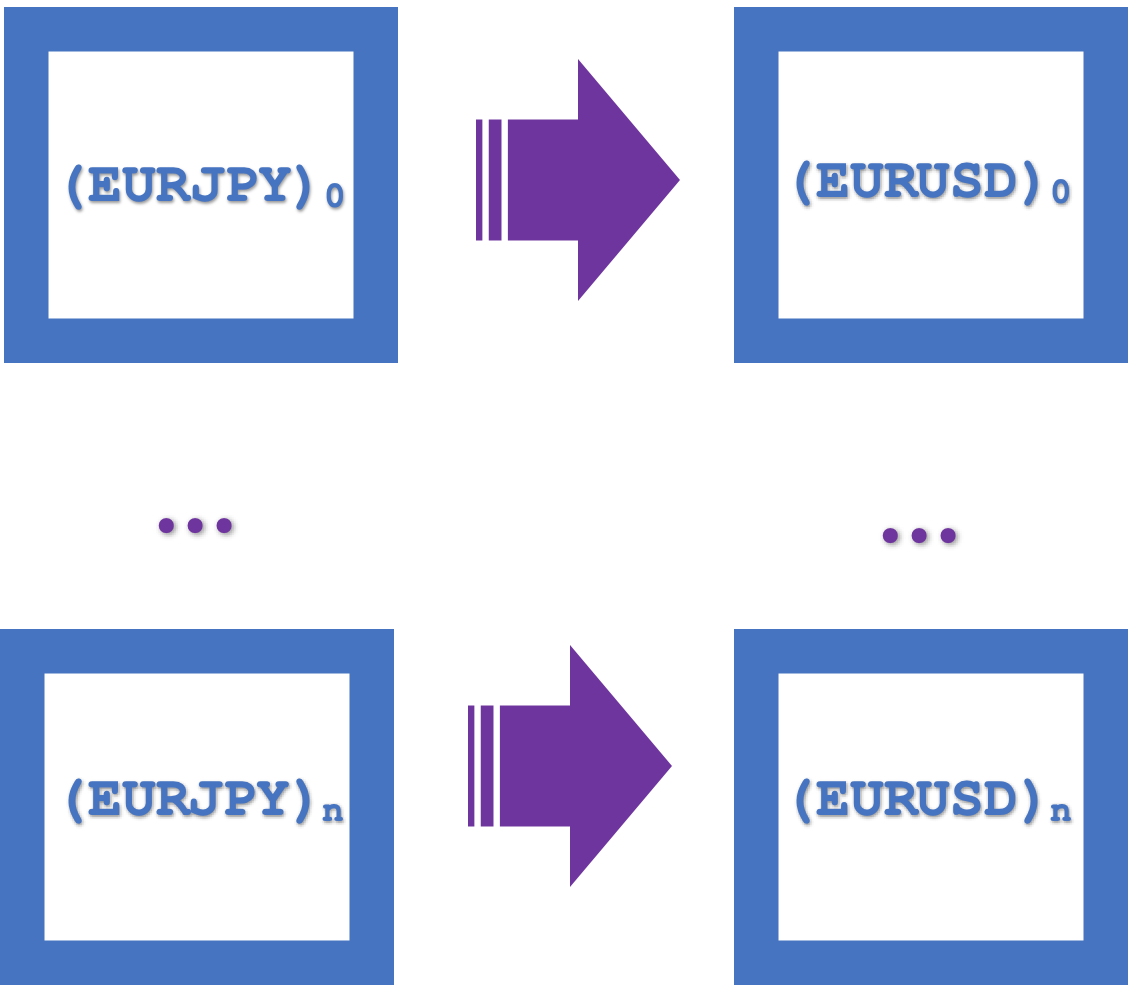
Eine visuelle Darstellung dieser natürlichen Quadrate als integriertes einzelnes Rechteck wird unten gezeigt:
Funktoren spielen dabei eine Rolle:
Das Thema Funktor (Mathematik) wurde bereits eingeführt, sodass dieser Absatz dazu dient, zu verdeutlichen, wie wir sie mit diesen natürlichen Quadrate verwenden können. Im letzten Artikel haben wir mehrschichtige Perceptrons verwendet, um die Zuordnung unserer Funktoren zu definieren, aber in diesem Artikel werden wir uns mit zufälligen Entscheidungswäldern beschäftigen, die denselben Zweck erfüllen.
Der Random Forest ist ein Klassifikator, der mehrere Lernmethoden (Wälder) verwendet, um die Vorhersage zu verbessern. Wie das mehrschichtige Perzeptron (MLP) ist es relativ komplex und wird oft als Ensemble-Lernmethode bezeichnet. Dies von Grund auf zu implementieren wäre für unsere Zwecke zu mühsam, weshalb es gut ist, dass die Alglib bereits Implementierungsklassen hat, die in der Bibliothek von MQL5 unter dem Ordner ‚Include\Math‘ verfügbar sind.
Die Zuordnung durch Random Decision Forests (RDF, Zufallsentscheidungswälder) wird also durch die Festlegung einer Waldgröße und die Zuweisung von Gewichten an die verschiedenen Bäume und die jeweiligen Zweige des Waldes definiert. Um sie einfach zu beschreiben, könnte man RDFs als ein Team von kleinen Entscheidungsträgern betrachten, wobei jeder Entscheidungsträger ein Baum ist, der weiß, wie man einen Datensatz betrachtet und eine Entscheidung trifft. Sie erhalten alle dieselbe Frage (Daten), und jeder gibt eine Antwort (Entscheidung). Sobald alle Teams ihre Wahl getroffen haben, stimmen sie über die beliebteste Entscheidung ab. Das Tolle an diesem Prozess ist, dass alle Teams (Bäume) zwar dieselben Daten erhielten, aber jedes von ihnen aus unterschiedlichen Teilen lernte, da sie nach dem Zufallsprinzip Stichproben zogen. Die daraus resultierenden Entscheidungen sind oft klug und richtig!
Ich habe versucht, meine eigene Implementierung von Grund auf zu machen, und dieser Algorithmus ist, obwohl er einfach beschrieben werden kann, ziemlich komplex. Mit Alglib kann dies jedoch in verschiedenen Formaten geschehen. Die einfachste davon erfordert im Prinzip nur zwei Eingaben, nämlich die Anzahl der Wälder und einen Eingabeparameter vom Typ double mi9t dem Namen R, der den Prozentsatz eines Trainingssatzes festlegt, der zur Erstellung der Bäume verwendet wird. Für unsere Zwecke werden wir das verwenden. Es gibt noch weitere Anforderungen wie die Anzahl der unabhängigen Variablen und der abhängigen Variablen (auch Klassifikatoren genannt), aber diese sind typisch für die meisten maschinellen Lernmodelle.
MQL5-Skript-Implementierung:
Wir haben ausschließlich die IDE von MQL5 verwendet, um alles zu programmieren, was in dieser Serie bisher vorgestellt wurde. Es mag nützlich sein, hervorzuheben, dass Sie neben nutzerdefinierten Indikatoren, Expertenberatern und MQL5-Skripten auch Dienste, Bibliotheken, Datenbanken und sogar Python-Skripte in dieser IDE programmieren/entwickeln können.
In diesem Artikel verwenden wir lediglich ein Skript, um die Klassifizierung nach natürlichen Quadrate in der Induktion zu demonstrieren. Eine Instanz der Signalklasse eines Expert Advisors wäre ideal gewesen und nicht nur ein Skript, aber die Implementierung einer Signalklasse für mehrere Währungen ist zwar möglich, aber nicht so machbar, wie es dieser Artikel erlauben würde. Daher werden wir in einer nicht optimierten Einstellung die prognostizierten und tatsächlichen Änderungen des Schlusskurses von EURUSD ausdrucken und diese Ergebnisse verwenden, um unsere These zu unterstützen oder zu widerlegen, dass natürliche Quadrate mit Induktion bei der Erstellung von Prognosen helfen können.
Unser Skript beginnt also mit der Erstellung einer Instanz der Domänenkategorie, die unsere Serie von USDJPY-Schlusskursänderungen enthält. Diese Kategorie könnte für das Training verwendet werden und ist als solche gekennzeichnet. Obwohl das Training mit ihr die Gewichte für die Funktoren aus ihr in die Codomain-Kategorie (unsere beiden Funktoren) setzen würde, sind diese Gewichtungen für unsere Prognosen nicht entscheidend (wie im letzten Artikel erwähnt), werden aber hier aus der Perspektive erwähnt.
//create domain series (USDJPY-rates) in first category for training CCategory _c_a_train;_c_a_train.Let(); int _a_size=GetObject(_c_a_train,__currency_a,__training_start,__training_stop);
Anschließend erstellen wir eine Instanz der Kategorie Codomain, die, wie bereits erwähnt, zwei Zeitreihen enthält: EURJPY und EURUSD. Da jeder Preispunkt ein Objekt darstellt, müssen wir darauf achten, dass die beiden Serien innerhalb der Kategorie „erhalten“ bleiben, indem wir die Objekte für jede Serie nacheinander hinzufügen. Wir bezeichnen sie als b und c.
//create 2 series (EURJPY and EURUSD rates) in second category for training CCategory _c_bc_train;_c_bc_train.Let(); int _b_trains=GetObject(_c_bc_train,__currency_b,__training_start,__training_stop); int _c_trains=GetObject(_c_bc_train,__currency_c,__training_start,__training_stop);
Unsere Prognosen werden sich also wie im letzten Artikel auf die Objekte im Codomain konzentrieren, die das Natürlichkeitsquadrat bilden. Die Morphismen, die die einzelnen Serien miteinander verbinden, und die natürlichen Transformationen, die Objekte über Serien hinweg verbinden, werden wir als RDFs abbilden.
Unser Skript hat einen Eingabeparameter für die Anzahl der Induktionen, mit dem wir das Quadrat hochskalieren und Projektionen über den nächsten 1-Balken hinaus vornehmen. Unsere natürlichen Quadrate über n Induktionen bilden also ein einziges Quadrat mit den Ecken A, B, C und D, sodass AB und CD unsere Transformationen sind, während AC und BD Morphismen darstellen.
Bei der Implementierung dieser Abbildung kann man sowohl MLPs als auch RDFs verwenden, beispielsweise für Transformationen und Morphismen. Ich überlasse es dem Leser, dies zu erforschen, da wir bereits gesehen haben, wie MLPs einbezogen werden können. Nun müssen wir aber unsere Trainingsmodelle für die RDF mit Daten füllen, und das geschieht über eine Matrix. Die vier RDFs für jedes Mapping von AB nach CD haben ihre eigene Matrix und werden durch die untenstehende Auflistung gefüllt:
//create natural transformation, by induction across, n squares..., cpi to pmi //mapping by random forests int _training_size=fmin(_c_trains,_b_trains); int _info_ab=0,_info_bd=0,_info_ac=0,_info_cd=0; CDFReport _report_ab,_report_bd,_report_ac,_report_cd; CMatrixDouble _xy_ab;_xy_ab.Resize(_training_size,1+1); CMatrixDouble _xy_bd;_xy_bd.Resize(_training_size,1+1); CMatrixDouble _xy_ac;_xy_ac.Resize(_training_size,1+1); CMatrixDouble _xy_cd;_xy_cd.Resize(_training_size,1+1); double _a=0.0,_b=0.0,_c=0.0,_d=0.0; CElement<string> _e_a,_e_b,_e_c,_e_d; string _s_a="",_s_b="",_s_c="",_s_d=""; for(int i=0;i<_training_size-__n_inductions;i++) { _s_a="";_e_a.Let();_c_bc_train.domain[i].Get(0,_e_a);_e_a.Get(1,_s_a);_a=StringToDouble(_s_a); _s_b="";_e_b.Let();_c_bc_train.domain[i+_b_trains].Get(0,_e_b);_e_b.Get(1,_s_b);_b=StringToDouble(_s_b); _s_c="";_e_c.Let();_c_bc_train.domain[i+__n_inductions].Get(0,_e_c);_e_c.Get(1,_s_c);_c=StringToDouble(_s_c); _s_d="";_e_d.Let();_c_bc_train.domain[i+_b_trains+__n_inductions].Get(0,_e_d);_e_d.Get(1,_s_d);_d=StringToDouble(_s_d); if(i<_training_size-__n_inductions) { _xy_ab[i].Set(0,_a); _xy_ab[i].Set(1,_b); _xy_bd[i].Set(0,_b); _xy_bd[i].Set(1,_d); _xy_ac[i].Set(0,_a); _xy_ac[i].Set(1,_c); _xy_cd[i].Set(0,_c); _xy_cd[i].Set(1,_d); } }
Sobald unsere Datensätze fertig sind, können wir Modellinstanzen für jede RDF deklarieren und mit dem individuellen Training der einzelnen RDFs fortfahren. Dies geschieht wie unten dargestellt:
CDForest _forest; CDecisionForest _rdf_ab,_rdf_cd; CDecisionForest _rdf_ac,_rdf_bd; _forest.DFBuildRandomDecisionForest(_xy_ab,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_ab,_rdf_ab,_report_ab); _forest.DFBuildRandomDecisionForest(_xy_bd,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_bd,_rdf_bd,_report_bd); _forest.DFBuildRandomDecisionForest(_xy_ac,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_ac,_rdf_ac,_report_ac); _forest.DFBuildRandomDecisionForest(_xy_cd,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_cd,_rdf_cd,_report_cd);
Das Ergebnis jedes Trainings, das wir im ganzzahligen Wert des Parameters „info“ auswerten müssen. Wie bei den MLP sollte dieser Wert positiv sein. Wenn alle Parameter von „info“ positiv sind, können wir mit einem Walk-Forward-Test fortfahren.
Beachten Sie, dass unsere Skript-Eingabeparameter 3 Daten enthalten, nämlich ein Startdatum für das Training, ein Enddatum für das Training und ein Enddatum für die Tests. Diese Werte sollten idealerweise vor der Verwendung validiert werden, um sicherzustellen, dass sie in der angegebenen Reihenfolge aufsteigend sind. Außerdem fehlt ein Startdatum für die Prüfung, da das Datum, an dem die Ausbildung endet, auch als Startdatum für die Prüfung gilt. Wir implementieren also einen Vorwärtstest mit dem unten stehenden Listing:
// if(_info_ab>0 && _info_bd>0 && _info_ac>0 && _info_cd>0) { //create 2 objects (cpi and pmi) in second category for testing CCategory _c_cp_test;_c_cp_test.Let(); int _b_test=GetObject(_c_cp_test,__currency_b,__training_stop,__testing_stop); ... ... MqlRates _rates[]; ArraySetAsSeries(_rates,true); if(CopyRates(__currency_c,Period(), 0, _testing_size+__n_inductions+1, _rates)>=_testing_size+__n_inductions+1) { ArraySetAsSeries(_rates,true); for(int i=__n_inductions+_testing_size;i>__n_inductions;i--) { _s_a="";_e_a.Let();_c_cp_test.domain[i].Get(0,_e_a);_e_a.Get(1,_s_a);_a=StringToDouble(_s_a); double _x_ab[],_y_ab[]; ArrayResize(_x_ab,1); ArrayResize(_y_ab,1); ArrayInitialize(_x_ab,0.0); ArrayInitialize(_y_ab,0.0); // _x_ab[0]=_a; _forest.DFProcess(_rdf_ab,_x_ab,_y_ab); ... double _x_cd[],_y_cd[]; ArrayResize(_x_cd,1); ArrayResize(_y_cd,1); ArrayInitialize(_x_cd,0.0); ArrayInitialize(_y_cd,0.0); // _x_cd[0]=_y_ac[0]; _forest.DFProcess(_rdf_cd,_x_cd,_y_cd); double _c_forecast=0.0; if((_y_bd[0]>0.0 && _y_cd[0]>0.0)||(_y_bd[0]<0.0 && _y_cd[0]<0.0))//abd agrees with acd on currency c change { _c_forecast=0.5*(_y_bd[0]+_y_cd[0]); } double _c_actual=_rates[i-__n_inductions].close-_rates[i].close; if((_c_forecast>0.0 && _c_actual>0.0)||(_c_forecast<0.0 && _c_actual<0.0)){ _strict_match++; } else if((_c_forecast>=0.0 && _c_actual>=0.0)||(_c_forecast<=0.0 && _c_actual<=0.0)){ _generic_match++; } else { _miss++; } } // ... } }
Denken Sie daran, dass wir uns für die Projektion von Veränderungen im EURUSD interessieren, der in unserem Quadrat als D dargestellt ist. Bei der Überprüfung unserer Projektionen im Vorwärtstest protokollieren wir die Werte, die streng in der Richtung übereinstimmen, die Werte, die in der Richtung übereinstimmen könnten, da wir Nullen beteiligt haben, und schließlich protokollieren wir auch die Fehltreffer. Dies alles ist in der oben gezeigten Auflistung enthalten.
Um unser Skript zusammenzufassen, beginnen wir also mit der Festlegung von Trainingskategorien, von denen wir eine für die Datenvorverarbeitung und das Training benötigen. Die von uns verwendeten Arbitrage-Devisenpaare sind USDJPY, EURJPY und EURUSD. Wir bilden Objekte in unserer Codomain-Kategorie ab, indem wir RDFs verwenden, die als Morphismen in der Serie dienen, und natürliche Transformationen über die Serie hinweg, um Vorhersagen über Testdaten zu treffen, die durch das Trainingsstoppdatum und das Teststoppdatum definiert sind.
Ergebnisse und Analyse:
Wenn wir das am Ende dieses Artikels angehängte Skript ausführen, das die oben genannte gemeinsame Quelle implementiert, erhalten wir die folgenden Protokolle mit Einleitungen bei 1 auf dem Tages-Chart von USDJPY:
2023.09.01 13:39:14.500 ct_19_r1 (USDJPY.ln,D1) void OnStart() misses: 45, strict matches: 61, & generic matches: 166, for strict pct (excl. generic): 0.58, & generic pct: 0.83, with inductions at: 1
Wenn wir jedoch unsere Induktionen auf 2 erhöhen, erhalten wir folgendes Ergebnis:
2023.09.01 13:39:55.073 ct_19_r1 (USDJPY.ln,D1) void OnStart() misses: 56, strict matches: 63, & generic matches: 153, for strict pct (excl. generic): 0.53, & generic pct: 0.79, with inductions at: 2
Es ist ein leichter Rückgang zu verzeichnen, wenn auch ein signifikanter, aber immer noch positiver, da strenge Treffer mehr sind als Fehlschüsse. Wir können ein Protokoll erstellen, in dem die Anzahl der Induktionen mit den Übereinstimmungen und Fehlversuchen verglichen wird. Dies wird in der folgenden Grafik dargestellt:
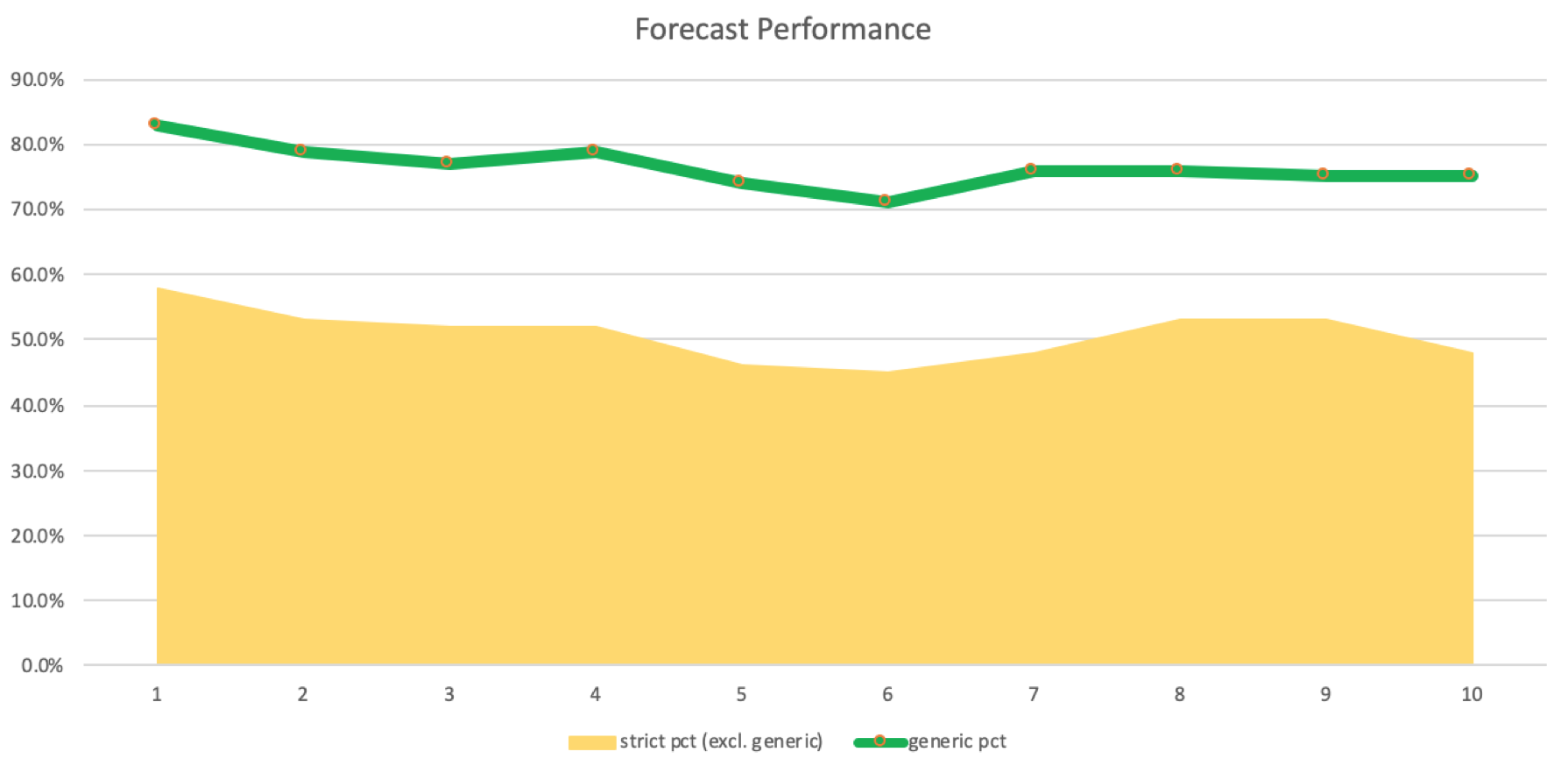
Die Genauigkeit dieser Prognosen und der protokollierten Übereinstimmungen müsste in einem tatsächlichen Handelssystem bestätigt werden, das mit den verschiedenen Induktionsverzögerungen läuft, um ihre Leistung zu beweisen oder zu widerlegen. Oftmals können Systeme auch mit einem geringeren Gewinnprozentsatz rentabel sein, sodass wir nicht abschließend sagen können, dass die Verwendung von Induktionsverzögerungen von 5 bis 8 für unser System ideal ist. Ein Test mit einem Expert Advisor, der problemlos mehrere Währungen verarbeiten kann, würde dies bestätigen.
Die größte Herausforderung bei dieser Implementierung ist die Unfähigkeit, als Experten-Signalklasse eines MQL5-Assistenten-Expertenberaters zu testen. Die Assistenten-Baugruppe initiiert standardmäßig Indikatoren und Preispuffer für nur ein Symbol, das Chart-Symbol. Die Umgehung dieses Problems, um mehrere Symbole unterzubringen, ist möglich, erfordert aber die Erstellung einer nutzerdefinierten Klasse, die von der Klasse CExpert erbt, und einige Änderungen. Ich hielt dies für zu langatmig für diesen Artikel, sodass der Leser dies selbst erforschen kann.
Vergleich mit traditionellen Methoden:
Im Vergleich zu „traditionellen“ Methoden, die einfache Indikatoren wie den gleitenden Durchschnitt verwenden, erscheint unser Ansatz der natürlichen Quadratinduktion komplex und vielleicht verworren, wenn Sie nur seine Beschreibung lesen. Ich hoffe jedoch, dass angesichts der Fülle von Code-Bibliotheken (wie Alglib), die online und in der MQL5-Bibliothek verfügbar sind, der Leser ein Gefühl dafür bekommt, wie ein scheinbar komplexer Ansatz oder eine Idee leicht in weniger als 200 Zeilen kodiert werden kann. Sie ermöglichen es, neue Ideen zu erforschen, anzunehmen oder zu verwerfen, und zwar auf nahtlose Weise. Die IDE von MQL5 ist ein Paradies für Philomaten.
Die wichtigsten Stärken dieses Systems sind seine Anpassungsfähigkeit und seine potenzielle Genauigkeit.
Praktische Anwendungen:
Wenn wir praktische Anwendungen unseres Prognosesystems mit Arbitrage-Paaren erforschen wollen, dann im Rahmen des Versuchs, Arbitrage-Möglichkeiten innerhalb der drei Paare zu nutzen. Wie wir alle wissen, hat jeder Broker seine eigene Spread-Politik für Devisenpaare, und wenn es Arbitragemöglichkeiten gibt, dann nur, weil eines der drei Paare so stark fehlbewertet ist, dass der Abstand größer ist als der Spread des Paares. Diese Möglichkeiten gab es in früheren Jahren, aber da die Latenzzeiten bei den meisten Brokern im Laufe der Jahre reduziert wurden, sind sie ziemlich rückläufig. Einige Makler haben diese Praxis sogar verboten.
Wenn wir also Arbitrage betreiben, dann in einer Pseudoform, bei der wir den Spread „übersehen“ und stattdessen die Rohpreise plus die Prognose unserer natürlichen Quadrate betrachten. Ein einfaches System für eine Kaufposition würde zum Beispiel darauf achten, dass der Arbitragekurs des dritten Paares, in unserem Fall EURUSD, über dem aktuellen Kurs liegt und die Prognose ebenfalls auf einen Kursanstieg hindeutet. Um den Arbitragepreis für EURUSD zu rekapitulieren, würde er in unserem Fall durch:
EURJPY / USDJPY.
Die Einbeziehung eines solchen Systems in das obige Skript führt zwangsläufig zu weniger Abschlüssen, da für jedes Signal entweder ein höherer oder ein niedrigerer Arbitragepreis für Kauf- bzw. Verkaufspositionen erforderlich ist. Die Arbeit mit der Signalklasse des Experten, um eine Instanz einer Klasse zu erzeugen, die dies kodiert, ist ein bevorzugter Ansatz, und da die Mehrwährungsunterstützung innerhalb der MQL5-Assistenten-Klassen noch nicht so robust ist, können wir sie hier nur erwähnen und den Leser auffordern, die Expertenklasse wie oben erwähnt zu modifizieren oder einen anderen Ansatz zu versuchen, der es ermöglicht, diesen Mehrwährungsansatz mit den vom Assistenten zusammengestellten Expertenberatern zu testen.
Um es noch einmal zu wiederholen: Das Testen von Ideen mit MQL5-Assistenten ermöglicht es nicht nur, etwas mit weniger Code zusammenzustellen, sondern auch, andere spannende Signale mit dem zu kombinieren, woran wir gerade arbeiten, und zu sehen, ob es eine relative Gewichtung unter den Signalen gibt, die unserem Ergebnisziel entspricht. Wenn wir also zum Beispiel, anstatt das am Ende angehängte Skript zur Verfügung zu stellen, in der Lage wären, mehrere Währungen zu implementieren und eine funktionsfähige Signaldatei bereitzustellen, könnte diese Datei mit anderen Signaldateien aus der Bibliothek (wie dem Awesome Oscillator, RSI usw.) oder sogar mit einer anderen nutzerdefinierten Signaldatei vom Leser kombiniert werden, um ein neues Handelssystem mit aussagekräftigeren oder ausgewogeneren Ergebnissen als nur der einzelnen Signaldatei zu entwickeln.
Der Ansatz der Induktion von natürlichen Quadraten kann neben der Bereitstellung einer Signaldatei auch zur Verbesserung des Risikomanagements und der Portfolio-Optimierung verwendet werden, wenn wir anstelle einer Signaldatei eine nutzerdefinierte Instanz der Expert Money-Klasse programmieren. Mit diesem - wenn auch rudimentären - Ansatz könnten wir unsere Positionen im Verhältnis zur Größe der prognostizierten Kursbewegung mit Einschränkungen vergrößern.
Schlussfolgerung:
Um die wichtigsten Erkenntnisse aus diesem Artikel zusammenzufassen, haben wir uns angesehen, wie natürliche Quadrate, wenn sie durch Induktion erweitert werden, das Design vereinfachen und Rechenressourcen bei der Klassifizierung von Daten und somit bei Prognosen für die Zukunft einsparen.
Präzise Prognosereihen sollten niemals das einzige und endgültige Ziel eines Handelssystems sein. Viele Handelsmethoden sind mit einem geringen Gewinnanteil nachhaltig profitabel, weshalb unsere Unfähigkeit, diese Ideen als Expertensignalklasse zu testen, entmutigend ist und die Ergebnisse hier eindeutig nicht aussagekräftig in Bezug auf die Rolle und das Potenzial der Induktion macht.
Daher werden die Leser ermutigt, den beigefügten Code in Einstellungen zu testen, die die Unterstützung mehrerer Währungen für Expertenberater ermöglichen, um zu besseren Schlussfolgerungen darüber zu gelangen, welche Induktionsverzögerungen funktionieren und welche nicht.
Referenzen:
Wikipedia, wie in den Links im Artikel angegeben.
Anhang: MQL5 Code-Schnipsel
Im Anhang finden Sie ein Skript (ct_19_r1.mq5), das in der IDE kompiliert werden muss, um ausgeführt zu werden, und dessen *.ex5-Datei dann auf einem Chart im MetaTrader 5 Terminal gestartet wird. Es kann mit mehreren Einstellungen und verschiedenen Arbitragepaaren neben den Standardeinstellungen ausgeführt werden. Die zweite angehängte Datei bezieht sich auf die Klassen der Kategorientheorie, die in dieser Reihe zusammengestellt wurden. Sie muss sich wie immer im Include-Ordner befinden.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/13273
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.