
MQL5中的范畴论(第19部分):自然性四边形归纳法
概述:
我们已经通过这些系列文章介绍了范畴论在分类离散数据中的应用,并通过相当多的例子展示了交易算法是如何实现的,主要是管理跟踪止损,也包括处理进场信号和头寸大小的算法;可以无缝地结合到 EA 交易中,以实现其一些概念。IDE中的MQL5向导在这方面发挥了重要作用,因为所有共享源代码都需要与向导一起组装,才能产生可测试的系统。
在这篇文章中,我们将重点讨论如何利用自然性四边形,这是我们在上一篇文章中引入的一个概念,并进行归纳。这一做法的潜在适用好处将通过3个可以通过套利联系起来的外汇货币对来证明。我们希望对其中一对的价格变化数据进行分类,目的是评估我们是否可以为该对开发进场信号算法。
自然性四边形是自然变换到可交换图的扩展。因此,如果我们有两个独立的范畴,它们之间有一个以上的函子,我们可以评估同域范畴中两个或多个对象之间的关系,并使用这种分析不仅与其他类似的范畴相关,如果对象处于时间序列中,还可以在所观察的范畴内进行预测。
了解设置:
我们在这篇文章中的两个范畴将与我们在上一篇文章中探讨的结构相似,因为它们之间有两个函子。但这将是主要的相似性,因为在这种情况下,我们在两个范畴中都有多个对象,而在上一篇文章中,我们在域范畴中有两个对象,在共域中只有四个对象。
因此,在以单个时间序列为特征的域范畴中,我们基本上将该序列中的每个价格点表示为一个对象。这些“对象”将按时间顺序通过态射进行链接,态射只需将它们增加到脚本所附的图表时间框架。此外,由于我们处理的是时间序列,这意味着我们的范畴是未绑定的,因此没有基数。再一次,正如我们文章中关注的那样,范畴/对象的总体大小和内容本身并不是我们感兴趣的,而是态射,更具体地说是这些对象的函子。
在共域范畴中,我们有另外两个外汇货币对的两个价格时间序列。回想一下套利至少需要三个外汇货币对,它们可能更多,但在我们的情况下,我们使用最低限度来保持我们的实现相对简单。因此,域范畴将有其第一对的价格序列,即 USDJPY。另外两个包含在共域范畴中作为价格序列的货币对将是 EURJPY 和 EURUSD。
链接第二个范畴中的价格点“对象”的态射将仅在特定系列中,因为我们在开始时没有任何链接每个系列中的对象的态射。
自然性四边形和归纳:
因此,范畴论中的自然性四边形的概念强调转通(commutation),在我们的上一篇文章中,它被用作验证分类的一种手段。概括一下,如果我们考虑下图,它表示共域类别中的四个对象:
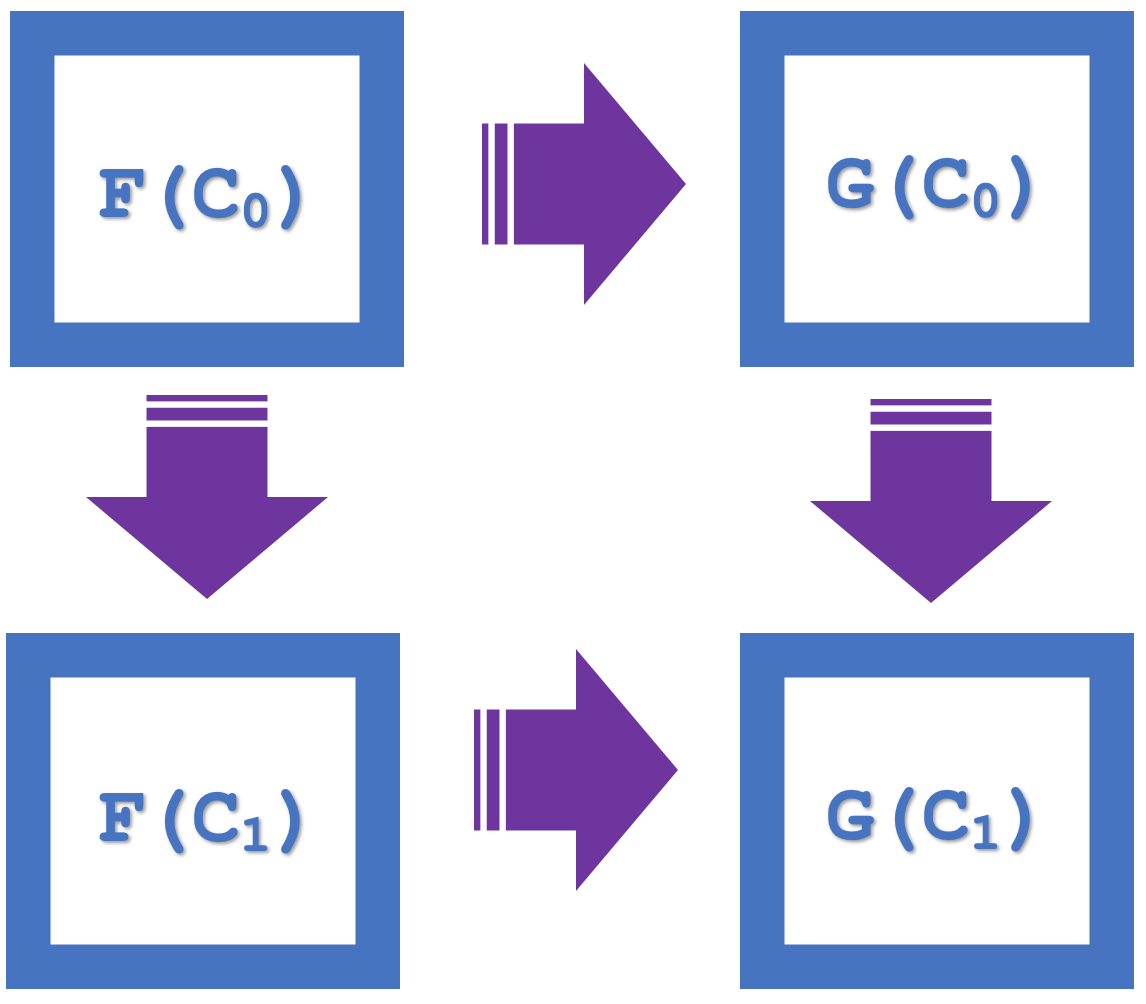
我们可以看到,有一个转通,即F(C0)到G(C 0),然后G(C 1),等价于F(C 0,到F(C 1,再到G(C1)。
本文引入的归纳概念强调了在一系列多个四边形上进行转通的能力,这简化了设计并节省了计算资源。如果我们探讨下面列出n个四边形的图表:
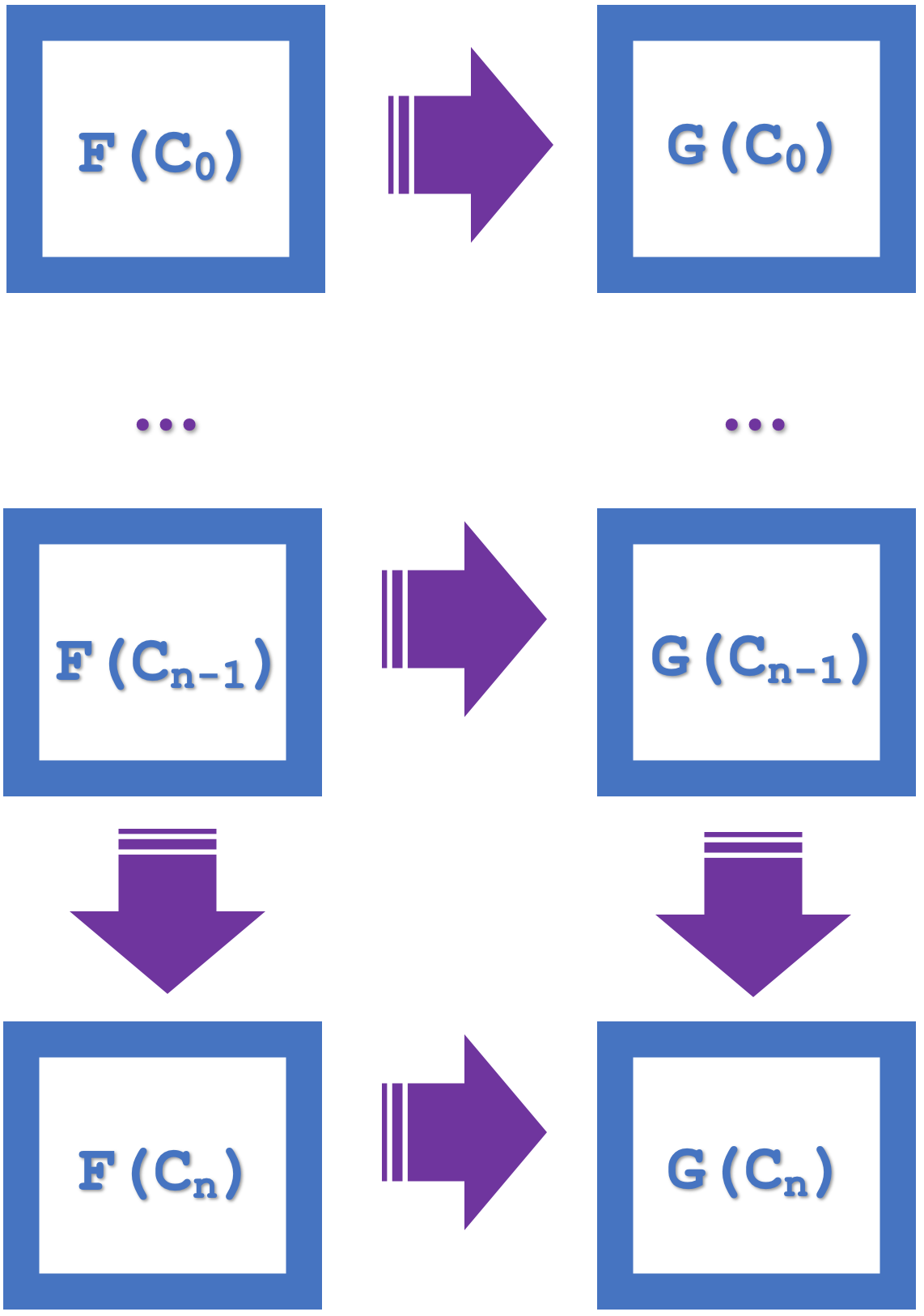
如果小的自然性四边形转通,那么大的四边形也转通。这个更大的转通意味着在'n'间距上的态射和函子。因此,我们的两个函数都来自 USDJPY 系列,但连接到不同的 EURJPY 和 EURUSD 系列。因此,自然变换将从 EURJPY 转换为 EURUSD。由于我们在上一篇文章中使用自然性四边形进行分类,我们的预测将是自然变换的共域,即 EURUSD。归纳法允许我们在多个柱中查看这些预测,而不是像上一篇文章中那样只查看一个柱。在上一篇文章中,考虑到必须使用的许多随机决策林,尝试多柱预测是计算密集型的。有了归纳法,我们现在可以开始在n个柱滞后时进行分类。
这些自然性四边形作为一个集成的单个矩形的可视化表示如下所示:
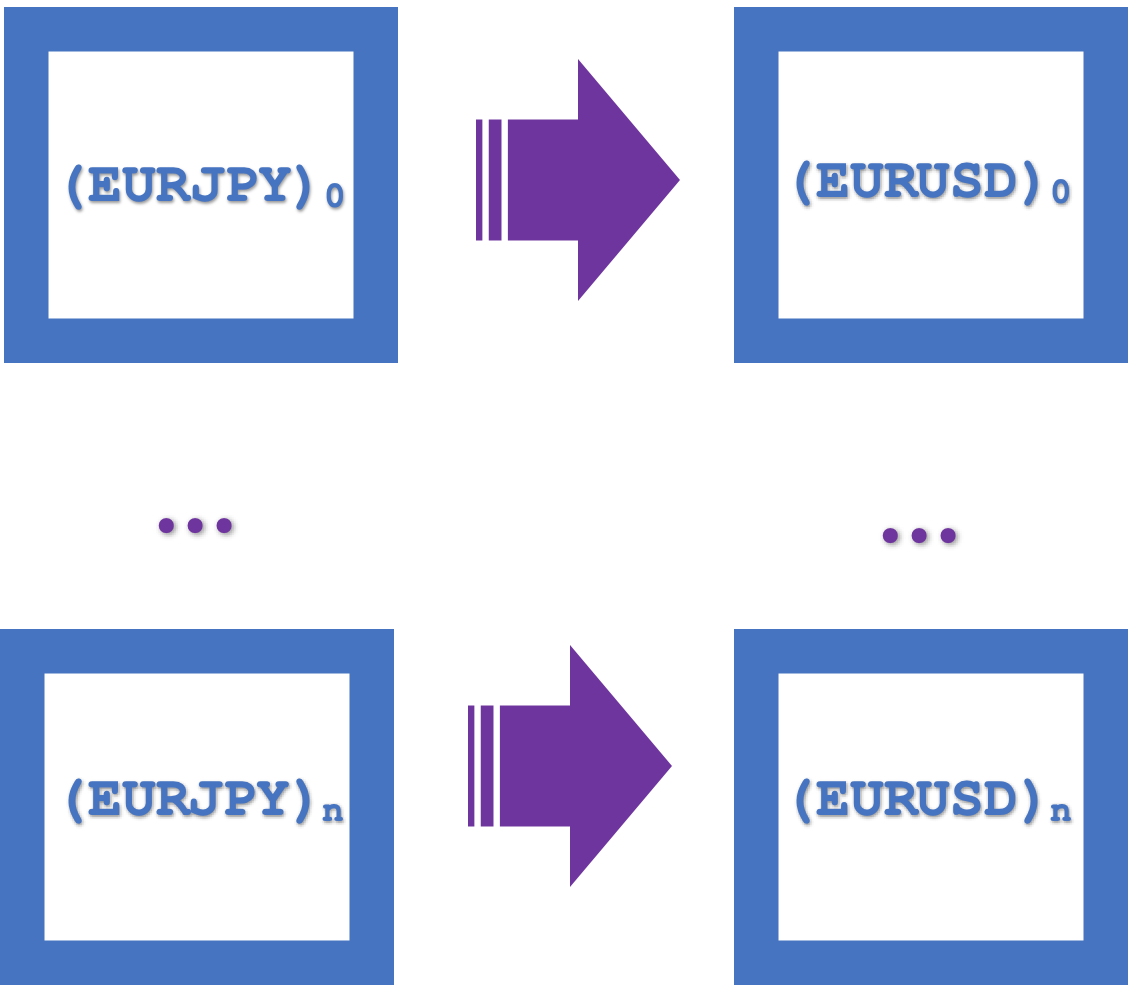
其中的函子角色:
已经介绍过函子,因此本段旨在强调我们如何将它们应用于这些自然性四边形。在上一篇文章中,我们使用多层感知器来定义函子的映射,但在本文中,我们将研究随机决策林,以达到相同的目的。
随机决策森林是一种使用多种学习方法(森林)来改进预测的分类器。与多层感知器(MLP)一样,它相对复杂,通常被称为集成学习方法。出于我们的目的,从第一原理实现这一点太乏味了,这就是为什么这是一件好事,Alglib已经在MQL5的库中的'Include\Math'文件夹下有可用的实现类。
因此,随机决策森林(Random Decision Forests, RDF)的映射是通过设置森林大小并将权重归因于森林的各种树木和相应分支来定义的。不过,为了简单地描述它们,你可以将RDF视为一个小型决策者团队,每个决策者都是一棵树,知道如何查看数据集并做出选择。他们都得到了相同的问题(数据),每个人都给出了答案(决定)。一旦所有团队都做出了自己的选择,他们就会投票选出最受欢迎的决定。这个过程最酷的地方是,尽管所有团队(树)都得到了相同的数据,但由于他们是随机采样的,所以每个团队都从不同的部分学习。由此做出的决定往往是明智和准确的!
我从一开始就尝试过自己的实现,这个算法虽然可以简单地描述,但相当复杂。不过,使用Alglib可以采用多种格式。其中最简单的主要只需要两个输入参数,即森林数量,以及一个称为R的 double 类型输入参数,该参数设置用于建造树的训练集的百分比。为了我们的目的,这就是我们将要使用的。还有其他要求,如自变量的数量和因变量的数量(也称为分类器),但这些是大多数机器学习模型的典型要求。
MQL5脚本实现:
到目前为止,我们已经严格使用MQL5的IDE对这些系列中提供的所有内容进行了编码。强调除了自定义指标、EA交易和MQL5脚本之外,您还可以在此IDE中编码/开发服务、库、数据库甚至python脚本,这可能很有用。
在本文中,我们只是使用一个脚本来演示通过自然性四边形归纳法来分类。EA交易的信号类实例是理想的,而不仅仅是一个脚本。然而,实现多货币信号类虽然可能,但并不像本文所允许的那样可行。因此,我们将在非优化的环境中打印 EURUSD 收盘价的预测和实际变化,并使用这些结果来支持或反驳我们的论点,即自然性四边形归纳法在进行预测时是有用的。
因此,我们的脚本首先创建一个域范畴的实例来保存我们的一系列 USDJPY 收盘价格变化。该范畴可用于训练和标记。尽管使用它进行训练会为从它到共域范畴的函子(我们的两个函子)设置权重,但这些权重对我们的预测并不重要(如上一篇文章中所述),只是在这里简单提一下。
//create domain series (USDJPY-rates) in first category for training CCategory _c_a_train;_c_a_train.Let(); int _a_size=GetObject(_c_a_train,__currency_a,__training_start,__training_stop);
然后,我们创建一个共域范畴的实例,该实例将以前面提到的两个时间序列为特征,即 EURJPY 和 EURUSD。由于每个价位代表一个对象,我们需要注意通过顺序添加每个系列的对象来“保留”范畴中的两个系列。我们将它们称为b和c。
//create 2 series (EURJPY and EURUSD rates) in second category for training CCategory _c_bc_train;_c_bc_train.Let(); int _b_trains=GetObject(_c_bc_train,__currency_b,__training_start,__training_stop); int _c_trains=GetObject(_c_bc_train,__currency_c,__training_start,__training_stop);
因此,我们像上一篇文章中那样的预测将集中在形成自然性四边形的共域中的对象上。将每个系列连接在一起的态射,以及跨系列连接对象的自然变换,就是我们将映射为RDF的内容。
我们的脚本有一个归纳次数的输入参数,这就是我们如何放大四边形并在下一个柱之外进行投影。因此,我们在n个归纳上的自然性四边形将形成一个四边形,我们认为它有角A、B、C和D,这样AB和CD将是我们的变换,而AC和BD将是态射。
在实现这种映射时,可以选择同时使用MLP和RDF,比如分别用于变换和态射。我将让读者来探讨一下,因为我们已经看到了如何合并MLP。不过,接下来我们需要用数据填充RDF的训练模型,这是通过矩阵完成的。从AB到CD的每个映射的四个RDF将有自己的矩阵,它们由以下列表填充:
//create natural transformation, by induction across, n squares..., cpi to pmi //mapping by random forests int _training_size=fmin(_c_trains,_b_trains); int _info_ab=0,_info_bd=0,_info_ac=0,_info_cd=0; CDFReport _report_ab,_report_bd,_report_ac,_report_cd; CMatrixDouble _xy_ab;_xy_ab.Resize(_training_size,1+1); CMatrixDouble _xy_bd;_xy_bd.Resize(_training_size,1+1); CMatrixDouble _xy_ac;_xy_ac.Resize(_training_size,1+1); CMatrixDouble _xy_cd;_xy_cd.Resize(_training_size,1+1); double _a=0.0,_b=0.0,_c=0.0,_d=0.0; CElement<string> _e_a,_e_b,_e_c,_e_d; string _s_a="",_s_b="",_s_c="",_s_d=""; for(int i=0;i<_training_size-__n_inductions;i++) { _s_a="";_e_a.Let();_c_bc_train.domain[i].Get(0,_e_a);_e_a.Get(1,_s_a);_a=StringToDouble(_s_a); _s_b="";_e_b.Let();_c_bc_train.domain[i+_b_trains].Get(0,_e_b);_e_b.Get(1,_s_b);_b=StringToDouble(_s_b); _s_c="";_e_c.Let();_c_bc_train.domain[i+__n_inductions].Get(0,_e_c);_e_c.Get(1,_s_c);_c=StringToDouble(_s_c); _s_d="";_e_d.Let();_c_bc_train.domain[i+_b_trains+__n_inductions].Get(0,_e_d);_e_d.Get(1,_s_d);_d=StringToDouble(_s_d); if(i<_training_size-__n_inductions) { _xy_ab[i].Set(0,_a); _xy_ab[i].Set(1,_b); _xy_bd[i].Set(0,_b); _xy_bd[i].Set(1,_d); _xy_ac[i].Set(0,_a); _xy_ac[i].Set(1,_c); _xy_cd[i].Set(0,_c); _xy_cd[i].Set(1,_d); } }
一旦我们的数据集准备好了,我们就可以继续为每个RDF声明模型实例,并继续对每个RDF进行单独的训练。如下所示:
CDForest _forest; CDecisionForest _rdf_ab,_rdf_cd; CDecisionForest _rdf_ac,_rdf_bd; _forest.DFBuildRandomDecisionForest(_xy_ab,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_ab,_rdf_ab,_report_ab); _forest.DFBuildRandomDecisionForest(_xy_bd,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_bd,_rdf_bd,_report_bd); _forest.DFBuildRandomDecisionForest(_xy_ac,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_ac,_rdf_ac,_report_ac); _forest.DFBuildRandomDecisionForest(_xy_cd,_training_size-__n_inductions,1,1,__training_trees,__training_r,_info_cd,_rdf_cd,_report_cd);
我们需要在“info”参数的整数值中评估的每个训练的输出。与MLP的情况一样,这个值应该是正的。如果我们所有的“info”参数都是正的,那么我们可以继续进行前瞻测试。
请注意,我们的脚本输入参数包括3个日期,即训练开始日期、训练停止日期和测试停止日期。这些值最好在使用前进行验证,以确保它们按照我所说的顺序递增。此外,缺少的是测试开始日期,因为训练停止日期也充当了测试开始日期。因此,我们使用以下代码实现了一个前瞻测试:
// if(_info_ab>0 && _info_bd>0 && _info_ac>0 && _info_cd>0) { //create 2 objects (cpi and pmi) in second category for testing CCategory _c_cp_test;_c_cp_test.Let(); int _b_test=GetObject(_c_cp_test,__currency_b,__training_stop,__testing_stop); ... ... MqlRates _rates[]; ArraySetAsSeries(_rates,true); if(CopyRates(__currency_c,Period(), 0, _testing_size+__n_inductions+1, _rates)>=_testing_size+__n_inductions+1) { ArraySetAsSeries(_rates,true); for(int i=__n_inductions+_testing_size;i>__n_inductions;i--) { _s_a="";_e_a.Let();_c_cp_test.domain[i].Get(0,_e_a);_e_a.Get(1,_s_a);_a=StringToDouble(_s_a); double _x_ab[],_y_ab[]; ArrayResize(_x_ab,1); ArrayResize(_y_ab,1); ArrayInitialize(_x_ab,0.0); ArrayInitialize(_y_ab,0.0); // _x_ab[0]=_a; _forest.DFProcess(_rdf_ab,_x_ab,_y_ab); ... double _x_cd[],_y_cd[]; ArrayResize(_x_cd,1); ArrayResize(_y_cd,1); ArrayInitialize(_x_cd,0.0); ArrayInitialize(_y_cd,0.0); // _x_cd[0]=_y_ac[0]; _forest.DFProcess(_rdf_cd,_x_cd,_y_cd); double _c_forecast=0.0; if((_y_bd[0]>0.0 && _y_cd[0]>0.0)||(_y_bd[0]<0.0 && _y_cd[0]<0.0))//abd agrees with acd on currency c change { _c_forecast=0.5*(_y_bd[0]+_y_cd[0]); } double _c_actual=_rates[i-__n_inductions].close-_rates[i].close; if((_c_forecast>0.0 && _c_actual>0.0)||(_c_forecast<0.0 && _c_actual<0.0)){ _strict_match++; } else if((_c_forecast>=0.0 && _c_actual>=0.0)||(_c_forecast<=0.0 && _c_actual<=0.0)){ _generic_match++; } else { _miss++; } } // ... } }
请记住,我们有兴趣预测 EURUSD 的变化,在我们的正方形中用D表示。 在检查我们对前瞻测试的预测时,我们记录在方向上严格匹配的值,以及在涉及零的情况下可能在方向上匹配的值。最后,我们还记录未命中的值。这一切都在上面显示的代码中得到了体现。
因此,为了总结我们的脚本,我们首先声明训练范畴,我们迫切需要这些范畴来进行数据预处理和训练。我们使用的套利外汇货币对是 USDJPY、EURJPY 和 EURUSD。我们使用在序列中充当态射的RDF和在序列中的自然变换来映射我们的共域范畴中的对象,以对由训练停止日期和测试停止日期定义的测试数据进行预测。
结果和分析:
如果我们运行本文末尾所附的脚本,该脚本实现了上面的共享源代码,我们将获得以下日志,其中 USDJPY 日线图上的归纳数为1:
2023.09.01 13:39:14.500 ct_19_r1 (USDJPY.ln,D1) void OnStart() misses: 45, strict matches: 61, & generic matches: 166, for strict pct (excl. generic): 0.58, & generic pct: 0.83, with inductions at: 1
然而,如果我们将归纳数增加到2,这就是我们得到的:
2023.09.01 13:39:55.073 ct_19_r1 (USDJPY.ln,D1) void OnStart() misses: 56, strict matches: 63, & generic matches: 153, for strict pct (excl. generic): 0.53, & generic pct: 0.79, with inductions at: 2
有一个轻微的下降,尽管这是一个显著的,仍然是一个积极的下降,因为严格的匹配比未命中更多。我们可以创建一个针对匹配和失误的归纳次数日志。如下图所示:
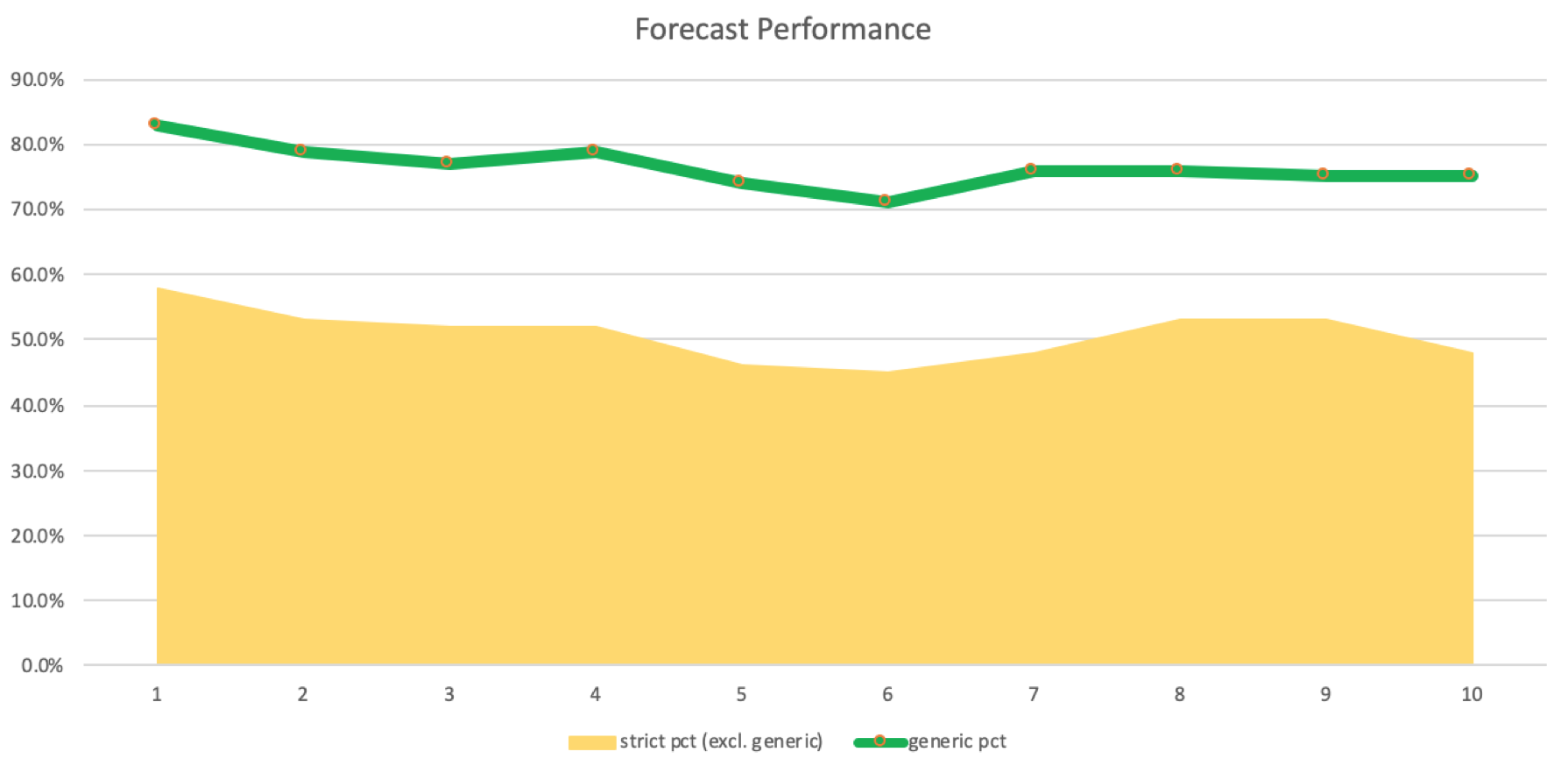
这些预测和记录的匹配的准确性需要在实际的交易系统中得到确认,该系统在各种归纳滞后的情况下运行,以证明或反驳其性能。通常情况下,系统可以以较小的获胜百分比盈利,这意味着我们不能最终说使用5到8的归纳滞后对我们的系统来说是理想的。使用一个可以轻松适应多种货币的EA交易设置进行测试可以验证这一点。
此实现中面临的主要挑战是无法作为MQL5向导 EA 交易的专家信号类进行测试。默认情况下,向导程序集仅为一个交易品种(图表交易品种)启动指标和价格缓冲区。解决这个问题以容纳多个交易品种是可能的,但需要创建一个从CExpert类继承的自定义类并进行一些更改。我觉得这篇文章太长了,所以读者可以独立探究。
与传统方法的比较:
与使用移动平均线等简单指标的“传统”方法相比,我们的自然性四边形归纳法似乎很复杂,如果你只是阅读它的描述,可能会令人费解。不过,我确实希望,考虑到在线和MQL5库中有过多的代码库(如Alglib),读者可以了解到一些看似复杂的方法或想法是如何在200行以下轻松编码的。允许一个人以无缝的方式探索、采纳或反驳新思想。MQL5的IDE是数学爱好者的天堂。
该系统值得强调的主要优势是其适应性和潜在的准确性。
真实世界应用程序:
如果我们要探索我们的套利对预测系统的实际应用,那将是在试图利用三对套利机会的背景下进行的。现在我们都知道,每个经纪商都有自己的外汇货币对价差政策,如果要存在套利机会,那是因为三对中的一对定价错误,导致价差超过了这对的价差。这些机会在过去的几年里一直存在,但随着这些年来大多数经纪商的延迟减少,它们已经落后了。事实上,一些经纪商甚至判定这种方法违规。
因此,如果我们要进行套利,它将是一种伪形式,我们会“忽略”价差,转而关注原始价格加上自然性四边形的预测。因此,例如,一个简单的做多系统会观察第三对的套利价格,在我们的情况下,EURUSD 高于当前报价,预测也会涨价。为了概括 EURUSD 的套利价格,在我们的案例中,可以通过以下公式得出:
EURJPY / USDJPY
将这样一个系统与我们从上面的脚本中获得的内容相结合,不可避免地会导致自确认以来的交易减少。对于每个信号,分别是多头和空头的较高或较低套利价格所要求的。使用 EA 信号类生成代码类的实例是一种首选方法,由于MQL5向导类中的多货币支持还不那么强大,我们只能在这里提到它,并让读者如上所述修改专家类,或者尝试另一种方法,允许使用向导组装的 EA 交易测试这种多货币方法。
用MQL5向导制作的 EA 交易验证测试想法,不仅可以用更少的代码将一些东西组合在一起,还可以将其他现有信号与我们正在处理的信号相结合,并查看信号之间是否存在相对权重,以满足我们的结果目标。因此,例如,如果我们不提供最后附带的脚本,而是能够实现多货币并提供一个可行的信号文件,则该文件可以与其他库信号文件(如Awesome Oscillator、RSI等)甚至读者的另一个自定义信号文件相结合,以开发一个新的交易系统,其结果比单个信号文件更有意义或更平衡。
如果我们不编写信号文件,而是编写专家货币类的自定义实例,则引入自然性四边形的方法除了可能提供信号文件外,还可以用于增强风险管理和投资组合优化。有了这种方法,尽管是初步的,但我们可以根据预测价格波动的大小来确定和限制头寸的大小。
结论:
为了总结本文的主要收获,我们研究了自然性四边形在通过归纳法扩展时如何简化设计,并在对数据进行分类时节省计算资源,从而预测未来。
精确的序列预测永远不应该是交易系统的终极目标。许多交易方法都是通过很小的胜率而持续盈利的,这就是为什么我们无法将这些想法作为专家信号类进行测试,这令人沮丧,而且显然会使这里的结果对归纳的作用和潜力没有定论。
因此,鼓励读者在允许为 EA 交易提供多种货币支持的环境中进一步测试所附代码,以便对哪些归纳会有滞后,而哪些没有问题得出更好的结论。
参考:
在文章中分享的 Wikipedia 链接。
附录:MQL5代码段
附加的是一个脚本(ct_19_r1.mq5),需要在IDE中编译该脚本,然后将其*.ex5文件附加到MetaTrader 5终端中的图表中。它可以在多个设置和提供的默认套利对之外的不同套利对的情况下运行。所附的第二个文件包含了系列文章中综合的范畴论相关类。它始终需要位于include文件夹中。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/13273