
Нейросети в трейдинге: Анализ облака точек (PointNet)

Введение
Облака точек — это простые и унифицированные структуры, которые избегают комбинаторных неоднородностей и сложностей сеток. Поскольку облака точек не имеют обычного формата, большинство исследователей обычно перед передачей подобных наборов данных в архитектуру глубокой сети преобразуют их в обычные 3D-воксельные сетки или наборы изображений. Однако такое преобразование делает результирующие данные излишне объемными, а также может привести к появлению артефактов квантования, которые часто скрывают естественные инвариантности данных.
По этой причине некоторые исследователи обратились к иному представлению данных для 3D-геометрии, используя просто облако точек. Модели, работающие с подобным представлением исходных данных, должны учитывать тот факт, что облако точек является просто набором точек и инвариантно к перестановкам его членов. Это требует определенной симметризации в вычислениях модели.
Одно из таких решений описано в статье "PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation". Представленная в ней модель под названием PointNet является унифицированным архитектурным решением, которое напрямую принимает облако точек в качестве исходных данных и возвращает либо метки классов для всего набора исходных данных, либо метки сегментов (частей) для каждой точки исходных данных.
Базовая архитектура модели удивительно проста. На начальных этапах каждая точка обрабатывается идентично и независимо. В базовой настройке каждая точка представлена всего тремя ее координатами (x, y, z). Дополнительные измерения могут быть добавлены путем вычисления нормалей и других локальных или глобальных объектов.
Ключом к подходу PointNet является использование одной симметричной функции — MaxPooling. По сути, сеть изучает набор оптимизационных функций, которые выбирают интересные или информативные объекты в облаке точек и кодируют причину их выбора. А полносвязные слои на выходе модели агрегируют эти изученные оптимальные значения в глобальный дескриптор для всей формы.
К указанному формату исходных данных легко применять жесткие или аффинные преобразования, так как каждая точка преобразуется независимо. Поэтому авторы метода добавляют зависимую от данных модель пространственного преобразования, которая пытается канонизировать данные перед их обработкой в PointNet, что еще больше повышает эффективность решения.
1. Алгоритм PointNet
Авторами метода PointNet был разработан фреймворк глубокого обучения, который в качестве исходных данных напрямую использует неупорядоченные наборы точек. Облако точек представляется в виде набора 3D-точек {Pi|i=1,…,n}, где каждая точка Pi является вектором его координат (x, y, z) плюс дополнительные каналы функций, такие как цвет и прочее.
Исходные данные модели представляют собой подмножество точек из евклидова пространства, которые обладают тремя основными свойствами:
- Неупорядоченные. В отличие от массивов пикселей на изображениях, облако точек представляет собой набор элементов без определенного порядка. Другими словами, модель, которая потребляет набор из N 3D-точек должна быть инвариантна к N! перестановок в порядке подачи исходного набора данных.
- Взаимодействие между точками. Точки взяты из пространства с метрикой расстояния. Это означает, что точки не изолированы, а соседние точки образуют осмысленное подмножество. Следовательно, модель должна быть способна захватывать локальные структуры из близлежащих точек, а также комбинаторные взаимодействия между локальными структурами.
- Инвариантность при преобразованиях. В качестве геометрического объекта выученное представление набора точек должно быть инвариантным к определенным преобразованиям. Например, одновременное вращение и перемещение точек не должно изменять ни глобальную категорию облака точек, ни их сегментацию.
Архитектура PointNet построена таким образом, что модели классификации и сегментации данных имеют большую часть общих структур. И содержит три ключевых модуля:
- слой максимального пула в качестве симметричной функции для агрегирования информации из всех точек,
- структура локальной и глобальной комбинации данных,
- две совместные сети выравнивания, которые выравнивают как исходные точки, так и точечные объекты.
Для того чтобы сделать модель инвариантной к перестановке исходных данных, существуют три стратегии:
- сортировка исходных данных в каноническом порядке;
- использование исходных данных в качестве последовательности для обучения RNN, но при обязательном дополнении обучающей выборки всеми возможными видами перестановок;
- использование простой симметричной функции для агрегирования информации из каждой точки. Когда симметричная функция принимает n векторов в качестве исходных данных и выводит новый вектор, который инвариантен к порядку ввода.
Сортировка исходных данных звучит как простое решение. Но на самом деле в многомерном пространстве не существует упорядочивания, которое было бы стабильным при точечных возмущениях в общем смысле. Следовательно, сортировка не решает проблему упорядочивания в полной мере. И модели трудно выучить согласованное сопоставление исходных и выходных данных. При проведении экспериментов авторы метода обнаружили, что применение MLP непосредственно к отсортированному набору точек работает плохо, хотя и немного лучше, чем прямая обработка неотсортированных исходных данных.
Несмотря на то, что RNN обладает относительно хорошей устойчивостью к порядку исходных данных для последовательностей небольшой длины (десятки), его трудно масштабировать до тысяч исходных элементов. В авторской статье также эмпирически показано, что модель, основанная на RNN, не работает хуже предложенного алгоритма PointNet.
Основная идея PointNet состоит в аппроксимации общей функции, определенной на множестве точек, путем применения симметричной функции к преобразованным элементам в множестве:
![]()
Эмпирически предложенный авторами метода базовый модуль очень прост: вначале приблизительно оцениваются h с помощью MLP и g композицией из функции с одной переменной и функции максимального пула. Эффективность такого подхода подтверждена в ходе экспериментов. Через коллекцию h, можно узнать ряд f для захвата различных свойств набора исходных данных.
Несмотря на простоту ключевого модуля, он обладает интересными свойствами и может достичь высокой производительности в нескольких различных приложениях.
На выходе предложенного ключевого модуля формируется вектор [f1,…,fK], который является глобальной сигнатурой исходного набора данных. Далее можно легко обучить SVM или MLP классификатор на форме глобальных признаков для классификации. Однако точечная сегментация требует сочетания локальных и глобальных знаний. Этого можно достичь простым, но очень эффективным способом.
После вычисления вектора признаков глобального облака точек, авторы PointNet предлагают возвращать его к каждому точечному объекту, конкатенируя глобальный объект с каждым из них. Затем извлекаются новые точечные признаки на основе объединенных точечных объектов — на этот раз поточечный признак учитывает как локальную, так и глобальную информацию.
С помощью этой модификации PointNet может прогнозировать количество балов на пункт, которое опирается как на локальную геометрию, так и на глобальную семантику. Например, можно точно предсказать нормали для каждой точки, подтвердив, что модель способна суммировать информацию из локальной окрестности точки. Представленные результаты экспериментов, проведенных авторами метода, демонстрируют, что предложенная модель может достичь самых современных результатов в сегментации фигурных частей и сегментации сцены.
Семантическая маркировка облака точек должна быть инвариантной, если облако точек претерпевает определенные геометрические преобразования, такие как жесткое преобразование. Поэтому авторы метода ожидают, что выученное представление по точечному множеству инвариантно к этим преобразованиям.
Естественным решением является выравнивание всего исходного набора по каноническому пространству перед извлечением признаков. Форма ввода облаков точек позволяет достичь этой цели простым способом. Достаточно спрогнозировать матрицу аффинного преобразования с помощью мини-сети (T-net) и непосредственно применить это преобразование к координатам исходных точек. Сама мини-сеть похожа на большую сеть и состоит из базовых модулей точечно-независимого извлечения признаков, максимального пулинга и полносвязных слоев.
Эту идею можно в дальнейшем распространить и на выравнивание пространства признаков. Можно вставить еще одну сеть выравнивания на точечные объекты и спрогнозировать матрицу преобразования признаков для выравнивания объектов из разных исходных данных облаков точек. Однако матрица преобразования в пространстве признаков имеет гораздо большую размерность, чем матрица пространственного преобразования, что значительно увеличивает сложность оптимизации. Поэтому авторы метода добавляют член регуляризации к ошибке в обучении SoftMax. Для этого ограничиваем матрицу преобразования признаков, чтобы она была близка к ортогональной матрице:
![]()
где A — матрица выравнивания признаков, предсказанная мини-сетью.
Ортогональное преобразование не приведет к потере информации на входе, поэтому является желательным. Авторы PointNet обнаружили, что при добавлении члена регуляризации, оптимизация становится более стабильной, и модель достигает лучшей производительности.
Авторская визуализация метода PointNet представлена ниже.
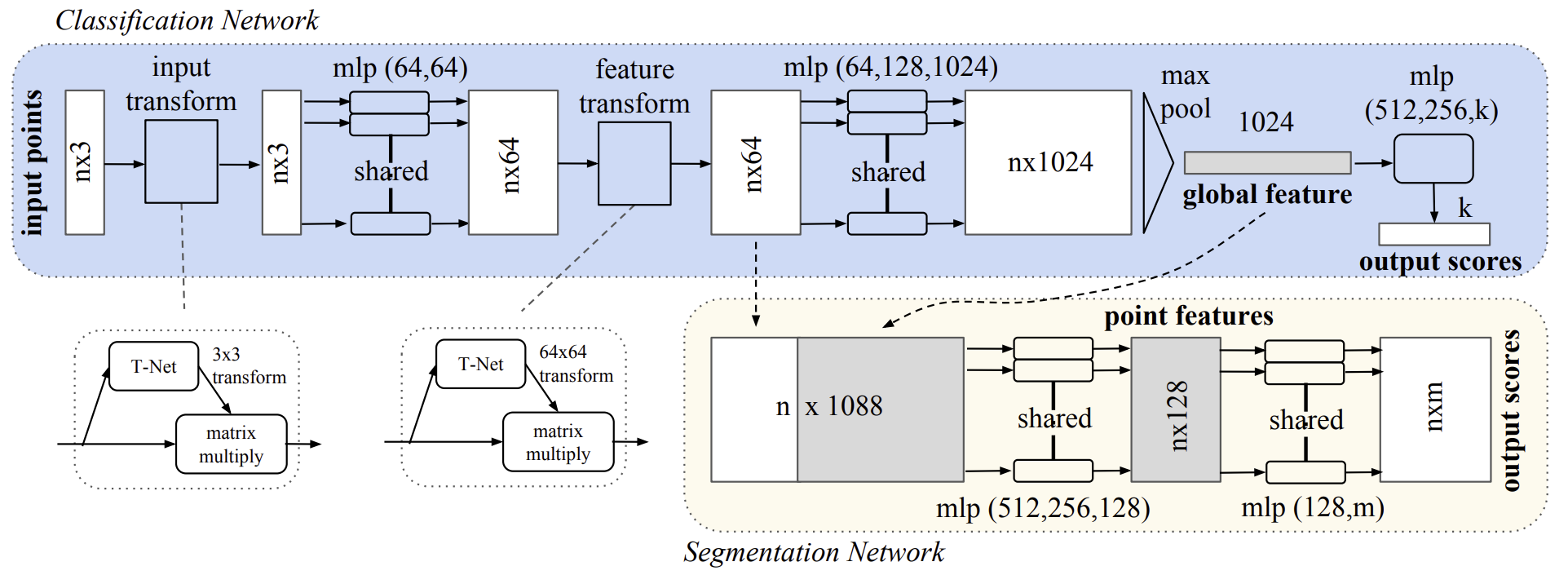
2. Реализация средствами MQL5
В предыдущем разделе мы познакомились с теоретическим описанием подходов, предложенных авторами метода PointNet. И теперь настало время перейти к практической части нашей статьи, в которой мы реализуем собственное видение предложенных подходов средствами MQL5.
2.1 Создание класса PointNet
Для имплементации алгоритмов PointNet в коде создадим новый класс CNeuronPointNetOCL с наследованием базового функционала от полносвязного слоя CNeuronBaseOCL. Структура нового класса представлена ниже.
class CNeuronPointNetOCL : public CNeuronBaseOCL { protected: CNeuronPointNetOCL *cTNet1; CNeuronBaseOCL *cTurned1; CNeuronConvOCL cPreNet[2]; CNeuronBatchNormOCL cPreNetNorm[2]; CNeuronPointNetOCL *cTNet2; CNeuronBaseOCL *cTurned2; CNeuronConvOCL cFeatureNet[3]; CNeuronBatchNormOCL cFeatureNetNorm[3]; CNeuronTransposeOCL cTranspose; CNeuronProofOCL cMaxPool; CNeuronBaseOCL cFinalMLP[2]; //--- virtual bool OrthoganalLoss(CNeuronBaseOCL *NeuronOCL, bool add = false); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPointNetOCL(void) {}; ~CNeuronPointNetOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronPointNetOCL; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Уже привычно наблюдать в структуре класса большое количество вложенных объектов. Но в данном случае есть свои нюансы. Во-первых, наряду со статическими объектами можно заметить несколько динамических. И в деструкторе класса мы должны будем удалить их из памяти устройства.
CNeuronPointNetOCL::~CNeuronPointNetOCL(void) { if(!!cTNet1) delete cTNet1; if(!!cTNet2) delete cTNet2; if(!!cTurned1) delete cTurned1; if(!!cTurned2) delete cTurned2; }
Тем не менее, мы не создаем указанные объекты в конструкторе класса, что позволяет нам оставить его пустым.
Второй нюанс, что 2 из вложенных динамических объектов являются экземплярами создаваемого нами класса CNeuronPointNetOCL. Такая себе "матрешка в матрешке".
И оба эти нюанса связаны с предложенным авторами метода подходом выравнивания исходных данных и признаков по некоторому каноническому пространству. Подробнее об этом мы поговорим в процессе реализации методов нашего класса.
Инициализация нового экземпляра объекта класса, как обычно, осуществляется в методе Init. В параметрах данного метода мы получаем основные константы, определяющие архитектуру создаваемого объекта.
Здесь стоит отметить, что в данном случае было принято решение о построении алгоритма классификации облака точек. Общая идея заключается в построении Энкодера состояния окружающей среды с использованием подходов PointNet, который возвращает некоторое вероятностное распределение отнесения текущего состояния окружающей среды к тому или иному типу. А политика Актера будет направлена на сопоставление отдельного типа состояния окружающей среды с некоторым набором параметров сделки, которая потенциально даст максимальную доходность в анализируемом состоянии окружающей среды. Отсюда и вытекают основные параметры создаваемой архитектуры класса:
- window — размер окна параметров одной точки в анализируемом облаке;
- units_count — количество точек в облаке;
- output — размер тензора результатов;
- use_tnets — необходимость создания моделей проекции исходных данных и признаков в каноническое пространство.
Здесь стоит обратить внимание, что параметром output указывается полный размер буфера результатов. И не стоит путать его с используемым нами ранее параметром окна результатов. Ведь в данном случае на выходе мы ожидаем получить дескриптор анализируемого состояния окружающей среды. И размер тензора результатов можно логически сопоставить с количеством возможных типов классификации состояний окружающей среды.
bool CNeuronPointNetOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, output, optimization_type, batch)) return false;
В теле метода мы, как обычно, сначала вызываем одноименный метод родительского класса, в котором уже реализованы минимально необходимый контроль полученных параметров и инициализация унаследованных объектов. При этом мы не забываем проверить результат выполнения операций вызываемого метода.
Затем мы переходим к инициализации вложенных объектов. И вначале мы проверим необходимость создания внутренних моделей проекции исходных данных и признаков в каноническое пространство.
//--- Init T-Nets if(use_tnets) { if(!cTNet1) { cTNet1 = new CNeuronPointNetOCL(); if(!cTNet1) return false; } if(!cTNet1.Init(0, 0, OpenCL, window, units_count, window * window, false, optimization, iBatch)) return false;
При необходимости создания моделей проекции, мы сначала проверяем актуальность указателя на объект модели и, при необходимости, создаем новый объект класса CNeuronPointNetOCL. После чего осуществляем его инициализацию.
Обратите внимание, размер исходных данных объекта генерации матрицы проекции соответствует размеру исходных данных, получаемых основным классом от внешней программы. А вот размер буфера результатов равен квадрату окна исходных данных. Ведь на выходе данной модели мы ожидаем получить квадратную матрицу для проекции исходных данных в каноническое пространство. Кроме того, мы указываем значение false в параметре необходимости создания матриц проекции исходных данных и признаков. Ведь мы не хотим неконтролируемого создания рекурсивных объектов. Да и создание вложенных моделей трансформации исходных данных внутри модели трансформации исходных данных звучит алогично.
Тут же мы проверяем указатель на объект записи скорректированных данных и, при необходимости, создаем новый экземпляр объекта.
if(!cTurned1) { cTurned1 = new CNeuronBaseOCL(); if(!cTurned1) return false; } if(!cTurned1.Init(0, 1, OpenCL, window * units_count, optimization, iBatch)) return false;
И инициализируем данный внутренний слой. Его размер соответствует тензору исходных данных.
Аналогичные операции мы осуществляем и для модели проекции признаков. Единственное отличие — в размерностях внутренних слоев.
if(!cTNet2) { cTNet2 = new CNeuronPointNetOCL(); if(!cTNet2) return false; } if(!cTNet2.Init(0, 2, OpenCL, 64, units_count, 64 * 64, false, optimization, iBatch)) return false; if(!cTurned2) { cTurned2 = new CNeuronBaseOCL(); if(!cTurned2) return false; } if(!cTurned2.Init(0, 3, OpenCL, 64 * units_count, optimization, iBatch)) return false; }
Далее мы формируем MLP первичного извлечения признаков точек. Так как на данном этапе авторы PointNet предлагают независимое извлечение признаков точек, то мы заменяем полносвязные слои на сверточные с размером шага равным размеру окна анализируемых данных. В нашем случае они равны размеру вектора описания одной точки.
//--- Init PreNet if(!cPreNet[0].Init(0, 0, OpenCL, window, window, 64, units_count, optimization, iBatch)) return false; cPreNet[0].SetActivationFunction(None); if(!cPreNetNorm[0].Init(0, 1, OpenCL, 64 * units_count, iBatch, optimization)) return false; cPreNetNorm[0].SetActivationFunction(LReLU); if(!cPreNet[1].Init(0, 2, OpenCL, 64, 64, 64, units_count, optimization, iBatch)) return false; cPreNet[1].SetActivationFunction(None); if(!cPreNetNorm[1].Init(0, 3, OpenCL, 64 * units_count, iBatch, optimization)) return false; cPreNetNorm[1].SetActivationFunction(None);
Между сверточными слоями мы вставляем слои пакетной нормализации и уже к ним применяем функцию активации. В данном случае мы используем по 2 слоя каждого типа с размерностью, предложенной авторами метода.
И аналогичным образом добавим трехслойный перцептрон извлечения признаков более высокого порядка.
//--- Init Feature Net if(!cFeatureNet[0].Init(0, 4, OpenCL, 64, 64, 64, units_count, optimization, iBatch)) return false; cFeatureNet[0].SetActivationFunction(None); if(!cFeatureNetNorm[0].Init(0, 5, OpenCL, 64 * units_count, iBatch, optimization)) return false; cFeatureNet[0].SetActivationFunction(LReLU); if(!cFeatureNet[1].Init(0, 6, OpenCL, 64, 64, 128, units_count, optimization, iBatch)) return false; cFeatureNet[1].SetActivationFunction(None); if(!cFeatureNetNorm[1].Init(0, 7, OpenCL, 128 * units_count, iBatch, optimization)) return false; cFeatureNetNorm[1].SetActivationFunction(LReLU); if(!cFeatureNet[2].Init(0, 8, OpenCL, 128, 128, 512, units_count, optimization, iBatch)) return false; cFeatureNet[2].SetActivationFunction(None); if(!cFeatureNetNorm[2].Init(0, 9, OpenCL, 512 * units_count, iBatch, optimization)) return false; cFeatureNetNorm[2].SetActivationFunction(None);
По существу, архитектура двух последних блоков идентична. Различие лишь в количестве слоев и их размеров. И логически их можно объединить в единый блок. В данном случае они разделены лишь для возможности вставки между ними блока трансформирования признаков в каноническое пространство.
Следующим этапом, после извлечения признаков точек, алгоритмом PointNet предусмотрено применение функции MaxPooling, которая должна выбрать максимальное значение по каждому элементу вектора признаков точек из всего анализируемого облака. Таким образом, предполагается, что облако точек характеризуется вектором признаков, который содержит максимальные значения соответствующих элементов из всех точек анализируемого облака.
В нашем арсенале уже есть класс CNeuronProofOCL, который выполняет аналогичный функционал, но в другом измерении. Поэтому мы сначала транспонируем полученную матрицу признаков точек.
if(!cTranspose.Init(0, 10, OpenCL, units_count, 512, optimization, iBatch)) return false;
А затем сформируем вектор максимальных значений.
if(!cMaxPool.Init(512, 11, OpenCL, units_count, units_count, 512, optimization, iBatch)) return false;
Полученный дескриптор анализируемого облака точек обрабатывается трехслойным MLP. Однако в данном случае было принято решение прибегнуть к небольшой хитрости — мы объявили только 2 внутренних полносвязных слоя. В качестве третьего мы решили использовать непосредственно сам создаваемый объект, ведь он унаследовал весь необходимый функционал от родительского класса.
//--- Init Final MLP if(!cFinalMLP[0].Init(256, 12, OpenCL, 512, optimization, iBatch)) return false; cFinalMLP[0].SetActivationFunction(LReLU); if(!cFinalMLP[1].Init(output, 13, OpenCL, 256, optimization, iBatch)) return false; cFinalMLP[1].SetActivationFunction(LReLU);
В завершении работы метода инициализации объекта класса мы явно укажем функцию активации и вернем логический результат выполнения операций вызывающей программе.
SetActivationFunction(None); //--- return true; }
После завершения реализации метода инициализации нашего нового класса, мы переходим к построению алгоритмов прямого прохода PointNet в методе feedForward. Как и ранее, в параметрах данного метода мы получаем указатель на объект исходных данных.
bool CNeuronPointNetOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- PreNet if(!cTNet1) { if(!cPreNet[0].FeedForward(NeuronOCL)) return false; }
И в теле метода нас сразу ждет разветвление алгоритма, в зависимости от необходимости проведения проекции исходных в данных в каноническое пространство. Здесь стоит обратить внимание, что при инициализации объекта мы сохраняли во внутренних переменных флаг необходимости проведения проекции данных. Однако, для проверки необходимости проведения проекции данных, мы можем использовать проверку актуальности указателей на соответствующие объекты. Ведь модели проекции создаются только при необходимости. По умолчанию они отсутствуют.
Следовательно, при отсутствии актуального указателя на объект модели для генерации матрицы проекции исходных данных, мы просто передаем полученный указатель на объект исходных данных в метод прямого прохода первого сверточного слоя блока предварительного извлечения признаков.
В случае же необходимости проекции данных в каноническое пространство, мы передаем полученные данные в метод прямого прохода модели для генерации матрицы трансформации данных.
else { if(!cTurned1) return false; if(!cTNet1.FeedForward(NeuronOCL)) return false;
На выходе модели проекции мы получаем квадратную матрицу трансформации данных. Соответственно, мы можем определить размерность окна данных по размеру тензора результатов.
int window = (int)MathSqrt(cTNet1.Neurons());
После чего мы используем операцию матричного умножения для получения проекции исходного облака точек в каноническом пространстве.
if(IsStopped() || !MatMul(NeuronOCL.getOutput(), cTNet1.getOutput(), cTurned1.getOutput(), NeuronOCL.Neurons() / window, window, window)) return false;
И уже проекцию исходных точек в каноническом пространстве мы передаем на вход первого слоя блока первичного извлечения признаков.
if(!cPreNet[0].FeedForward(cTurned1.AsObject())) return false; }
На данном этапе, вне зависимости от необходимости проекции исходных данных в каноническое пространство, мы уже осуществили прямой проход первого слоя блока первичного извлечения признаков. И далее мы осуществляем последовательный вызов методов прямого прохода всех слоев указанного блока.
if(!cPreNetNorm[0].FeedForward(cPreNet[0].AsObject())) return false; if(!cPreNet[1].FeedForward(cPreNetNorm[0].AsObject())) return false; if(!cPreNetNorm[1].FeedForward(cPreNet[1].AsObject())) return false;
Далее перед нами встает вопрос необходимости проекции признаков точек в каноническое пространство. Здесь алгоритм аналогичный проведению проекции исходных точек.
//--- Feature Net if(!cTNet2) { if(!cFeatureNet[0].FeedForward(cPreNetNorm[1].AsObject())) return false; } else { if(!cTurned2) return false; if(!cTNet2.FeedForward(cPreNetNorm[1].AsObject())) return false; int window = (int)MathSqrt(cTNet2.Neurons()); if(IsStopped() || !MatMul(cPreNetNorm[1].getOutput(), cTNet2.getOutput(), cTurned2.getOutput(), cPreNetNorm[1].Neurons() / window, window, window)) return false; if(!cFeatureNet[0].FeedForward(cTurned2.AsObject())) return false; }
После чего мы завершаем операции извлечения признаков точек анализируемого облака исходных данных.
if(!cFeatureNetNorm[0].FeedForward(cFeatureNet[0].AsObject())) return false; uint total = cFeatureNet.Size(); for(uint i = 1; i < total; i++) { if(!cFeatureNet[i].FeedForward(cFeatureNetNorm[i - 1].AsObject())) return false; if(!cFeatureNetNorm[i].FeedForward(cFeatureNet[i].AsObject())) return false; }
На следующем этапе мы транспонируем полученный тензор признаков. И формируем вектор дескриптора анализируемого облака.
if(!cTranspose.FeedForward(cFeatureNetNorm[total - 1].AsObject())) return false; if(!cMaxPool.FeedForward(cTranspose.AsObject())) return false;
И далее, согласно алгоритму классификации PointNet, осуществляется обработка полученного в MLP. Здесь мы осуществляем операции прямого прохода 2 внутренних полносвязных слоев.
if(!cFinalMLP[0].FeedForward(cMaxPool.AsObject())) return false; if(!cFinalMLP[1].FeedForward(cFinalMLP[0].AsObject())) return false;
А затем выполним вызов аналогичного метода родительского класса, передав в него указатель на внутренний слой.
if(!CNeuronBaseOCL::feedForward(cFinalMLP[1].AsObject())) return false; //--- return true; }
Напомню, что в данном случае родительским классом является полносвязный слой. Соответственно, вызывая метод прямого прохода родительского класса мы выполняем прямой проход полносвязного слоя. Только на этот раз для выполнения операций мы используем объекты не вложенного слоя, а унаследованные от родительского класса.
После успешного выполнения всех операций нашего метода прямого прохода мы возвращаем логическое значение осуществленных операций вызывающей программе.
На этом мы завершаем работу с методом прямого прохода и переходим к работе над методами обратного прохода, которые делятся на 2 блока: распределение градиента ошибки и корректировка обучаемых параметров модели.
Мы уже не раз говорили, что распределение градиента ошибки полностью повторяет алгоритм прямого прохода, поток информации осуществляется в обратном порядке. Однако в данном случае есть один нюанс. Для матриц проекции данных авторы метода PointNet ввели регуляризацию, которая максимально приближает матрицу проекции данных к ортогональной. Операции регуляризации не отражаются на алгоритме прямого прохода и участвуют только в процессе оптимизации параметров. Более того, для выполнения данных операций нам понадобится проведение дополнительной работы на стороне OpenCL-программы.
Для начала давайте посмотрим на предложенную формулу регуляризации.
![]()
Очевидно, в данном случае авторы метода эксплуатируют свойство, что при умножении ортогональной матрицы на транспонированную свою копию получается единичная матрица.
Если разобраться, то умножение матрицы на свою транспонированную копию в каждый элемент результирующей матрицы возвращает произведение двух соответствующих строк. Значит, для ортогональной матрицы векторное умножение строки на свою копию должно дать "1". Во всех других случаях векторное умножение двух строк матрицы дает "0".
Однако стоит отметить, что речь идет о регуляризации в рамках обратного прохода. А значит нам предстоит не только посчитать ошибку, но и вычислить градиент ошибки для каждого элемента.
Для реализации данного алгоритма на стороне OpenCL-программы мы создадим кернел OrthoganalLoss. В параметрах данного кернела мы получаем указатели на 2 буфера данных. Один из которых содержит исходную матрицу, а второй — для записи соответствующих градиентов ошибки. Тут же мы добавим флаг для указания перезаписи градиента ошибки или добавления к уже сохраненным значениям.
__kernel void OrthoganalLoss(__global const float *data, __global float *grad, const int add ) { const size_t r = get_global_id(0); const size_t c = get_local_id(1); const size_t cols = get_local_size(1);
При этом мы не указываем размерности матриц. Но здесь все довольно просто. Мы планируем запускать кернел в двухмерном пространстве задач по числу строк и столбцов в матрице.
В теле кернела мы сразу идентифицируем текущий поток в обоих измерениях пространства задач.
Стоит также напомнить, что мы имеем дело с квадратной матрицей. Поэтому для понимания полного размера матрицы нам достаточно определить количество потоков лишь в одном из измерений.
Для распределения операций векторного умножения по нескольким потокам, мы создадим локальные рабочие группы в рамках строк исходной матрицы. А для организации процесса обмена данными между потоками, воспользуемся массивом в локальной памяти OpenCL-контекста.
__local float Temp[LOCAL_ARRAY_SIZE]; uint ls = min((uint)cols, (uint)LOCAL_ARRAY_SIZE);
Далее мы определим константы смещения до необходимых объектов в буфере исходных данных.
const int shift1 = r * cols + c; const int shift2 = c * cols + r;
И загрузим из буфера данных значения соответствующих элементов.
float value1 = data[shift1]; float value2 = (shift1==shift2 ? value1 : data[shift2]);
Обратите внимание, что для минимизации операций обращения к глобальной памяти мы исключаем повторное чтение диагональных элементов.
Тут же мы сразу проверяем действительность полученных значений, заменяя недействительные числа нулевыми значениями.
if(isinf(value1) || isnan(value1)) value1 = 0; if(isinf(value2) || isnan(value2)) value2 = 0;
После чего вычислим их произведение с обязательной проверкой результата на действительность.
float v2 = value1 * value2; if(isinf(v2) || isnan(v2)) v2 = 0;
Следующим этапом мы организуем цикл параллельного суммирования полученных значений в отдельных элементах локального массива с обязательной синхронизацией потоков рабочей группы.
for(int i = 0; i < cols; i += ls) { //--- if(i <= c && (i + ls) > c) Temp[c - i] = (i == 0 ? 0 : Temp[c - i]) + v2; barrier(CLK_LOCAL_MEM_FENCE); }
А затем организуем цикл суммирования полученных значений элементов локального массива.
uint count = min(ls, (uint)cols); do { count = (count + 1) / 2; if(c < ls) Temp[c] += (c < count && (c + count) < cols ? Temp[c + count] : 0); if(c + count < ls) Temp[c + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
При этом мы так же уделяем особое внимание синхронизации потоков рабочей группы.
В результате выполненных операций в первом элементе локального массива мы получим значение произведения двух анализируемых строк матрицы. И теперь мы можем посчитать значение ошибки.
const float sum = Temp[0]; float loss = -pow((float)(r == c) - sum, 2.0f);
Однако это лишь часть работы. Далее нам предстоит определить градиент ошибки для каждого элемента исходной матрицы. Вначале мы считаем градиент ошибки на уровне произведения векторов.
float g = (2 * (sum - (float)(r == c))) * loss;
А затем спустим градиент ошибки до первого элемента в произведении значений текущего потока.
g = value2 * g;
В обязательном порядке проверим действительность значения полученного градиента ошибки.
if(isinf(g) || isnan(g)) g = 0;
После чего сохраним его в соответствующем элементе глобального буфера градиентов ошибки.
if(add == 1) grad[shift1] += g; else grad[shift1] = g; }
Здесь мы в обязательном порядке проверяем флаг добавления или перезаписи значения градиента ошибки и выполняем соответствующую операцию.
Обратите внимание, что в рамках кернела мы вычисляем градиент ошибки только для одного из элементов в произведении. Градиент ошибки для второго элемента произведения будет выполнен в потоке с зеркальным указанием строки и столбца матрицы.
Постановка данного кернела в очередь выполнения осуществляется в методе CNeuronPointNetOCL::OrthoganalLoss. Его алгоритм построен в полном соответствии базовых принципов постановки кернелов программы OpenCL в очередь выполнения, которые были уже много раз рассмотрены в предыдущих статьях. И я предлагаю вам самостоятельно изучить код указанного метода. Его полный код представлен во вложении.
А я предлагаю вам познакомиться с алгоритмом метода распределения градиента ошибки calcInputGradients. В параметрах данного метода мы, как и ранее, получаем указатель на объект предыдущего слоя, который в данном случае является получателем градиента ошибки на уровне исходных данных.
bool CNeuronPointNetOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В теле метода мы сразу проверяем актуальность полученного указателя. Ведь в противном случае теряется смысл дальнейшего выполнения операций.
Затем мы проведем градиент ошибки через перцептрон интерпретации дескриптора облака точек.
if(!CNeuronBaseOCL::calcInputGradients(cFinalMLP[1].AsObject())) return false; if(!cFinalMLP[0].calcHiddenGradients(cFinalMLP[1].AsObject())) return false;
Через слой MaxPooling с последующим транспонированием доведем градиент ошибки до признаков соответствующих точек.
if(!cMaxPool.calcHiddenGradients(cFinalMLP[0].AsObject())) return false; if(!cTranspose.calcHiddenGradients(cMaxPool.AsObject())) return false;
И опускаем градиент ошибки через слои извлечения признаков точек, разумеется в обратном порядке.
uint total = cFeatureNet.Size(); for(uint i = total - 1; i > 0; i--) { if(!cFeatureNet[i].calcHiddenGradients(cFeatureNetNorm[i].AsObject())) return false; if(!cFeatureNetNorm[i - 1].calcHiddenGradients(cFeatureNet[i].AsObject())) return false; } if(!cFeatureNet[0].calcHiddenGradients(cFeatureNetNorm[0].AsObject())) return false;
До этого момента все довольно обычно. Но мы подошли к уровню проекции признаков точек в каноническое пространство. Конечно, если это не требуется, то мы просто передаем градиент ошибки в блок первичного извлечения признаков.
if(!cTNet2) { if(!cPreNetNorm[1].calcHiddenGradients(cFeatureNet[0].AsObject())) return false; }
А вот во втором случае алгоритм более сложный. Сначала мы спускаем градиент ошибки до уровня проекции данных.
else { if(!cTurned2) return false; if(!cTurned2.calcHiddenGradients(cFeatureNet[0].AsObject())) return false;
После чего мы распределяем градиент ошибки между признаками точек и матрицей проекции. И тут, если заглянуть на пару шагов вперед, то можно заметить, что на уровень признаков точек мы будем спускать градиент ошибки и через модель генерации матрицы проекции. Поэтому, чтобы в последующем не перезаписать необходимые данные, на данном этапе мы передадим градиент ошибки не в последний слой блока предварительного извлечения признаков, а в предпоследний.
Напомню, что последним в блоке предварительного извлечения признаков является слой пакетной нормализации. А перед ним идет сверточный слой независимого извлечения признаков отдельных точек. Оба этих слоя имеют одинаковую размерность буферов градиентов ошибки, что позволяет нам осуществить подстановку буферов без страха выхода за границы буфера.
int window = (int)MathSqrt(cTNet2.Neurons()); if(IsStopped() || !MatMulGrad(cPreNetNorm[1].getOutput(), cPreNet[1].getGradient(), cTNet2.getOutput(), cTNet2.getGradient(), cTurned2.getGradient(), cPreNetNorm[1].Neurons() / window, window, window)) return false;
И после разделения градиента ошибки по двум потокам данных мы добавим градиент ошибки регуляризации на уровне матрицы проекции.
if(!OrthoganalLoss(cTNet2.AsObject(), true)) return false;
Далее спустим градиент ошибки через блок формирования матрицы проекции.
if(!cPreNetNorm[1].calcHiddenGradients((CObject*)cTNet2)) return false;
И суммируем градиент ошибки из двух потоков информации.
if(!SumAndNormilize(cPreNetNorm[1].getGradient(), cPreNet[1].getGradient(), cPreNetNorm[1].getGradient(), 1, false, 0, 0, 0, 1)) return false; }
А далее мы можем спокойно пропустить градиент ошибки через блок первичного извлечения признаков до уровня проекции исходных данных.
if(!cPreNet[1].calcHiddenGradients(cPreNetNorm[1].AsObject())) return false; if(!cPreNetNorm[0].calcHiddenGradients(cPreNet[1].AsObject())) return false; if(!cPreNet[0].calcHiddenGradients(cPreNetNorm[0].AsObject())) return false;
Здесь мы применяем алгоритм, аналогичный распределению градиента ошибки через проекцию признаков. Самый простой вариант алгоритма наблюдается при отсутствии матрицы проекции данных. Мы просто передаем градиент ошибки в буфер предыдущего слоя.
if(!cTNet1) { if(!NeuronOCL.calcHiddenGradients(cPreNet[0].AsObject())) return false; }
А вот в случае необходимости проекции данных, мы сначала спускаем градиент ошибки до уровня проекции.
if(!cTurned1) return false; if(!cTurned1.calcHiddenGradients(cPreNet[0].AsObject())) return false;
И распределяем градиент ошибки по двум потокам в зависимости от их влияния на результат.
int window = (int)MathSqrt(cTNet1.Neurons()); if(IsStopped() || !MatMulGrad(NeuronOCL.getOutput(), NeuronOCL.getGradient(), cTNet1.getOutput(), cTNet1.getGradient(), cTurned1.getGradient(), NeuronOCL.Neurons() / window, window, window)) return false;
И добавим к полученному градиенту ошибки значение регуляризации.
if(!OrthoganalLoss(cTNet1, true)) return false;
И тут мы сталкиваемся с проблемой перезаписи градиента ошибки. На данном этапе у нас отсутствуют свободные буферы для записи данных. И при распределении градиента ошибки по 2 направлениям мы сразу записали градиент ошибки в буфер предшествующего слоя. И теперь нам предстоит спустить градиент ошибки через блок генерации матрицы проекции исходных данных, операции которого перезапишут значения градиента ошибки с потерей ранее сохраненных данных. Для избежания потери данных нам необходимо их скопировать в подходящий буфер данных. Но где нам взять такой буфер? При инициализации класса мы не создавали буфера хранения промежуточных данных. И тут наш взгляд падает на слой записи проекции данных. Его размер аналогичен размеру тензора исходных данных. А градиент ошибки, сохраненный в нем, мы уже распределили на 2 потока и в последующих операциях не используется.
В то же время равенство размеров буферов наталкивает на мысль целесообразности прямого переноса данных. А что, если вместо прямого копирования данных мы осуществим подмену указателей на буфера данных. Ведь операция копирования указателя гораздо дешевле полного копирования данных буфера и не зависит от размера буфера.
CBufferFloat *temp = NeuronOCL.getGradient(); NeuronOCL.SetGradient(cTurned1.getGradient(), false); cTurned1.SetGradient(temp, false);
А после перестановки указателей на буфера данных мы можем смело передать градиент ошибки от матрицы проекции данных до уровня предыдущего слоя.
if(!NeuronOCL.calcHiddenGradients(cTNet1.AsObject())) return false; if(!SumAndNormilize(NeuronOCL.getGradient(), cTurned1.getGradient(), NeuronOCL.getGradient(), 1, false, 0, 0, 0, 1)) return false; } //--- return true; }
И в завершении операций метода мы суммируем градиент ошибки от двух потоков информации и возвращаем логический результат выполнения операций метода вызывающей программе.
Обновление обучаемых параметров модели осуществляется в методе updateInputWeights. Алгоритм данного метода по обыкновению прост — мы лишь поочередно вызываем одноименные методы внутренних объектов, содержащих обучаемые параметры. При этом не забываем вызвать аналогичный метод родительского класса, так как мы используем его функционал в качестве третьего слоя MLP оценки дескриптора облака точек. В рамках данной статьи мы не будем подробно останавливаться на рассмотрении кода данного метода. И я предлагаю вам самостоятельно ознакомиться с ним в приложенных к статье файлам.
А мы на этом завершаем рассмотрение алгоритмов построения методов класса CNeuronPointNetOCL. Во вложении к данной статье вы найдете полный код данного класса и всех его методов.
2.2 Архитектура моделей
Поле имплементации подходов, предложенных авторами метода PointNet, средствами MQL5 мы переходим к внедрению нового объекта в архитектуру наших моделей. Как уже было сказано выше, наш новый класс CNeuronPointNetOCL мы добавляем в архитектуру модели Энкодера состояния окружающей среды, которая представлена в методе CreateEncoderDescriptions.
Здесь стоит обратить внимание, что мы практически полностью реализовали весь алгоритм в рамках одного блока. Это позволяет нам создать модель с довольно краткой и лаконичной архитектурой верхнего уровня. Я специально акцентировал внимание, что в данном методе представлена "архитектура верхнего уровня". Ведь под кратким наименованием блока CNeuronPointNetOCL кроется довольно комплексная и многоуровневая архитектура нейронной сети.
На вход модели мы, как обычно, подаем "сырые" необработанные данные, которые приводятся к сопоставимому виду средствами слоя пакетной нормализации данных.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } //--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
После чего мы сразу передаем их в наш новый блок PointNet.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPointNetOCL; descr.window = BarDescr; // Variables descr.count = HistoryBars; // Units descr.window_out = LatentCount; // Output Dimension descr.step = int(true); // Use input and feature transformation descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь стоит обратить внимание, что на выходе нашего блока CNeuronPointNetOCL мы не указали функцию активации. Такой шаг сделан намеренно, чтобы предоставить пользователю возможность расширения архитектуры блока идентификации облака точек. Однако в рамках данного эксперимента мы лишь добавим слой SoftMax для перевода полученных результатов в область вероятностных значений.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
На этом завершается архитектура нашей новой модели Энкодера состояния окружающей среды.
Надо сказать, что мы также упростили архитектуру моделей Актера и Критика. В них мы заменили блок многоголового кросс-внимания простым слоем конкатенации данных. Но с этими точечными правками я предлагаю вам ознакомиться самостоятельно во вложении.
Несколько слов надо сказать и о программах обучения моделей. Изменение архитектуры моделей не отразилось на структуре исходных данных и результатов, что позволяет нам использовать ранее созданные программы взаимодействия с окружающей средой и собранные ими данные для офлайн-обучения. Однако в собранном нами ранее наборе данных отсутствуют метки классов отобранных состояний окружающей среды. А работа по их созданию потребует дополнительных затрат. Мы же решили пойти иным путем и обучить Энкодер состояния окружающей среды в процессе обучения политики Актера. Поэтому мы исключили советник отдельного обучения Энкодера состояния окружающей среды "StudyEncoder.mq5". А в программу обучения моделей Актера и Критика "Study.mq5" были внесены точечные правки для обучения Энкодера состояния окружающей среды, с которыми я предлагаю вам ознакомиться самостоятельно.
Напомню, что во вложении вы найдете полный код представленного в данной статье класса и всех его методов, а также алгоритмы всех программ, используемых при подготовке статьи. А мы переходим к завершающему этапу нашей работы — тестированию и оценке результатов проделанной работы.
3. Тестирование
В данной статье мы познакомились с новым методом обработки исходных данных в виде облака точек PointNet и реализовали свое видение предложенных авторами метода подходов средствами MQL5. И теперь пришло время проверить эффективность предложенных подходов для решения наших задач. Для этого мы обучим представленные в данной статье модели на реальных исторических данных инструмента EURUSD. В рамках нашего эксперимента для обучения моделей мы будем использовать исторические данные 2023 года в качестве обучающей выборки. А тестирование обученных моделей проведем на данных Января 2024 года. В обоих случаях мы используем таймфрейм H1 и параметры по умолчанию для всех анализируемых индикаторов.
В принципе, мы используем параметры обучения и тестирования моделей без изменения уже несколько статей. Поэтому первичное обучение осуществляется на данных ранее собранных выборок.
В то же время, обучение модели Энкодера состояния окружающей среды осуществляется одновременно с обучением политики Актера. А обучение последнего, как вы знаете, осуществляется итерационно — с периодическим обновлением данных обучающей выборки. Такой подход позволяет поддерживать актуальность обучающей выборки и её соответствие области действий текущей политики Актера. Что в свою очередь, позволяет осуществить более тонкую настройку обучаемой политики.
После нескольких итераций обучения моделей нам удалось получить политику Актера, способную генерировать прибыль на обучающей и тестовой выборках. Результаты тестирования представлены ниже.
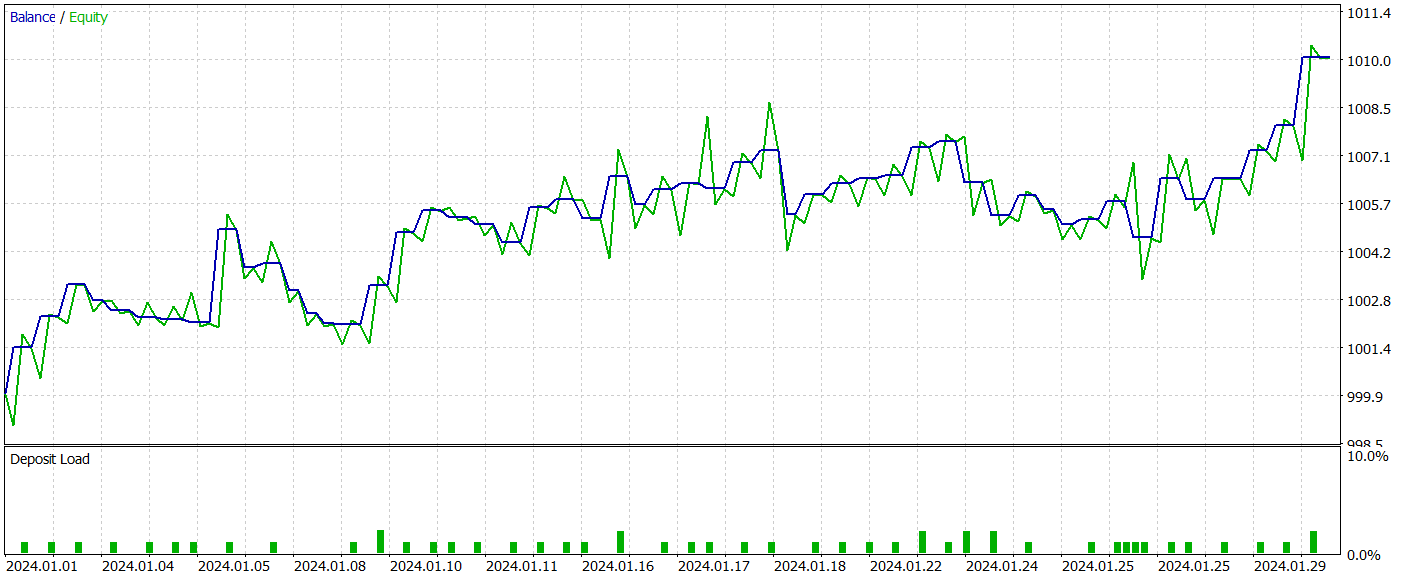
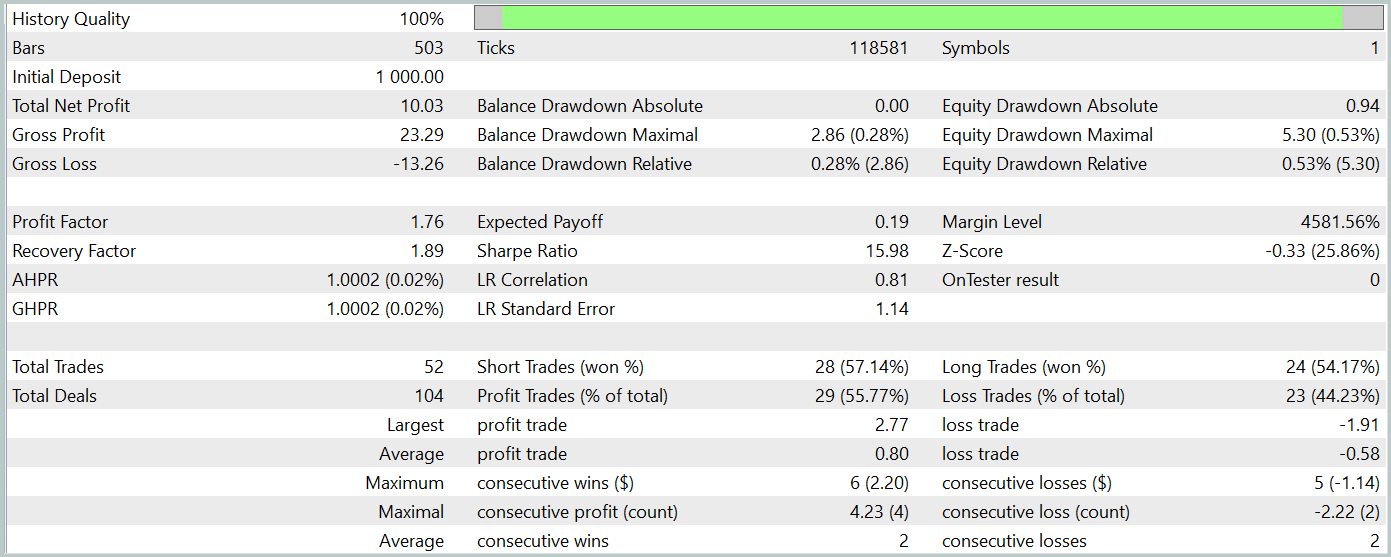
За период тестирования модель совершила 52 торговых операции, 55.77% из которых были закрыты с прибылью. Стоит отметить, что мы имеем практический паритет длинных и коротких позиций (24 против 28, соответственно). При этом как максимальная, так и средняя прибыльная сделка превышают аналогичный показатель убыточных позиций. Что позволило зафиксировать профит фактор на уровне 1.76. График баланса имеет явную тенденцию к росту. Однако, короткий период тестирования и малое количество совершенных операций не позволяют говорить о стабильности работы выученной политики на длительном временном промежутке.
В целом, реализованные подходы заслуживают внимания, но требуют дополнительного тестирования.
Заключение
В данной статье мы познакомились с новым методом PointNet, который является унифицированным архитектурным решением и напрямую принимает облако точек в качестве исходных данных. Применение PointNet в области трейдинга позволяет эффективно анализировать сложные многомерные данные, такие как ценовые паттерны, без необходимости их преобразования в другие форматы. Что открывает новые возможности для более точного прогнозирования рыночных трендов и улучшения алгоритмов принятия решений. И потенциально может повысить эффективность торговых стратегий на финансовых рынках.
В практической части статьи мы реализовали свое видение предложенных подходов средствами MQL5, обучили модели на реальных исторических данных и провели тестирование советника с использованием выученной политики в тестере стратегий MetaTrader 5. По результатам тестирования мы получили многообещающие результаты. Однако следует помнить, что все программы, представленные в рамках данной статьи, носят ознакомительный характер и созданы только для целей демонстрации возможностей предложенных подходов. Перед использованием программ на реальных финансовых рынках, требуется их дополнительная доработка, которая также включает дообучение и всестороннее тестирование представленных моделей.
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования