
Нейросети в трейдинге: "Легкие" модели прогнозирования временных рядов

Введение
Прогнозирование предстоящего ценового движения имеет решающее значение в построении торговой стратегии. Достижение точных прогнозов, как правило, требует применение мощных и сложных моделей глубокого обучения.
Основа для точного долгосрочного прогнозирования временных рядов заключается в присущей данным периодичности и тенденции. Кроме того, уже давно замечено, что ценовое движение валютных пар тесно связано с отдельными торговыми сессиями. Например, если мы дискретизируем временной ряд ежедневных последовательностей в определенное время суток, то каждая подпоследовательность демонстрирует аналогичные или последовательные тенденции. В этом случае периодичность и тренд исходной последовательности декомпозируется и трансформируется. То есть периодические паттерны трансформируются в динамику межподпоследовательности, в то время как трендовые паттерны переинтерпретируются как внутри подпоследовательные характеристики. Эта декомпозиция открывает новые перспективы для разработки облегченных моделей долгосрочного прогнозирования временных рядов. На которые обратили свое внимание авторы статьи "SparseTSF: Modeling Long-term Time Series Forecasting with 1k Parameters".
В своей работе они, наверное, впервые исследуют, как использовать эту периодичность и декомпозицию в данных для построения специализированных облегченных моделей прогнозирования временных рядов. Что позволяет им предложить алгоритм SparseTSF — чрезвычайно легкую модель долгосрочного прогнозирования временных рядов.
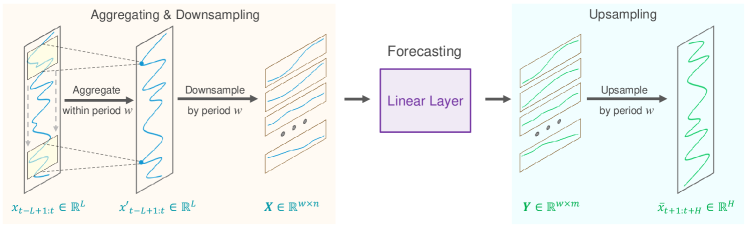
Технически была предложена методика межпериодного разреженного прогнозирования. Сначала исходные данные делятся на последовательности с постоянной периодичностью. А затем выполняется прогнозирование для каждой подпоследовательности с пониженной дискретизацией. Тем самым исходная задача прогнозирования временных рядов упрощается до задачи прогнозирования межпериодного тренда.
Такой подход дает два преимущества:
- Эффективное разделение периодичности данных и тренда, позволяющее модели стабильно идентифицировать и извлекать периодические признаки, фокусируясь на прогнозировании изменений тренда;
- Экстремальное сжатие размера параметров модели, значительно снижающее потребность в вычислительных ресурсах.
1. Алгоритм SparseSTF
Задача долгосрочного прогнозирования временных рядов (Long-term Time Series Forecasting — LTSF) заключается в прогнозировании будущих значений на расширенном горизонте с использованием ранее наблюдаемых данных многомерных временных рядов. Основная цель LTSF — продление горизонта планирования H, так как он предоставляет более богатые и продвинутые рекомендации к практическому применению. Однако расширение горизонта планирования часто ведет к увеличению сложности обучаемой модели. Для решения этой проблемы авторы метода SparseTSF сосредоточились на разработке моделей, которые были бы не только чрезвычайно легкими, но так же надежными и эффективными.
Последние достижения в области LTSF привели к сдвигу в сторону подходов прогнозирования независимых канала при работе с данными многомерных временных рядов. Эта стратегия упрощает процесс прогнозирования, сосредоточившись на отдельных одномерных временных рядах в наборе данных, снижая сложность учета межканальных отношений. В результате основная цель основных современных моделей в последние годы сместилась в сторону эффективного прогнозирования путем моделирования долгосрочных зависимостей, включая периодичность и тренды, в одномерных последовательностях.
Учитывая, что прогнозируемые данные часто демонстрируют постоянную, априорную периодичность, авторы метода SparseTSF предлагают использовать межпериодное разреженное прогнозирование для улучшения извлечения долгосрочных последовательных зависимостей при одновременном уменьшении масштаба параметров модели. В предложенном решении используется один линейный слой для моделирования задачи LTSF.
Предполагается, что временной ряд Xt длиной L имеет известную периодичность w. Первым шагом предложенного алгоритма является понижение дискретизации исходной последовательности в w подпоследовательностей длиной n (n=L/w). После чего к этим подпоследовательностям применяется модель прогнозирования с общими параметрами. В результате данной операции мы получаем w прогнозируемых подпоследовательностей, каждая из которых имеет длину m (m=H/w), которые составляют полную прогнозируемую последовательность длиной H.
Интуитивно этот процесс прогнозирования выглядит как скользящий прогноз с разреженным интервалом w, выполненный полносвязным слоем с совместным использованием параметров в течение постоянного периода времени w. Это можно рассматривать как модель, выполняющую разреженное скользящее прогнозирование по периодам.
Технически процесс понижения частоты дискретизации эквивалентен изменению формы тензора исходных данных Xt до матрицы n*w с последующим транспонированием до w*n. Прогнозирование последующей траектории с разреженным скольжением эквивалентно применению линейного слоя размера n*m к последней размерности матрицы. В результате данной операции получается w*m матрица.
В ходе повышающей дискретизации мы выполняем обратные операции: транспонирование матрицы w*m с последующим переформатированием в полную прогнозируемую последовательность длины H.
Однако предложенный подход сталкивается с двумя проблемами:
- Потеря информации, поскольку для прогнозирования используется только одна точка данных за период, а остальные игнорируются;
- Усиление влияния выбросов, поскольку присутствие экстремальных значений в подпоследовательностях с пониженной дискретизацией может непосредственно влиять на прогноз.
Для решения этих проблем авторы метода SparseTSF вводят скользящее агрегирование исходной последовательности перед выполнением разреженного прогнозирования. Каждая агрегированная точка данных включает информацию из других точек в течение окружающего периода, решая первую проблему. Более того, поскольку агрегированное значение по существу является средневзвешенным значением окружающих точек, оно смягчает влияние выбросов, тем самым решается вторая проблема.
Технически это скользящее агрегирование данных может быть реализована с помощью сверточного слоя с нулевым заполнением.
Данные временных рядов часто демонстрируют сдвиги в распределении между обучающими и тестовыми наборами данных. Использование простых стратегий нормализации выборки между исходными данными и прогнозной последовательностью может помочь смягчить эту проблему. В алгоритме SparseTSF используется прямолинейная стратегия нормализации. В частности, из исходных данных вычитается среднее значение последовательности до того, как она попадет в модель. И прибавляется обратно к полученным результатам.
Авторская визуализация метода SparseTSF представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода SparseTSF мы переходим к реализации предложенных подходов средствами MQL5. Для этого в рамках нашей библиотеки мы создадим новый класс CNeuronSparseTSF.
2.1 Создание класса SparseTSF
Наш новый класс унаследует основной функционал от базового класса полносвязного слоя CNeuronBaseOCL. Структура класса CNeuronSparseTSF представлена ниже.
class CNeuronSparseTSF : public CNeuronBaseOCL { protected: CNeuronConvOCL cConvolution; CNeuronTransposeOCL acTranspose[4]; CNeuronConvOCL cForecast; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSparseTSF(void) {}; ~CNeuronSparseTSF(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint sequence, uint variables, uint period, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronSparseTSF; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
В структуре нового класса мы добавим 2 сверточных слоя. Один из них выполняет роль агрегирования данных, а второй — прогнозирования последующих последовательностей. Кроме того, для переформатирования данных мы будем использовать целый массив транспонирований. Все добавленные внутренние объекты объявлены статично, что позволяет оставить "пустыми" конструктор и деструктор класса. А непосредственная инициализация объекта класса осуществляется в методе Init.
В параметрах метода инициализации мы передаем основные параметры создаваемого объекта:
- sequence — длина последовательности исходных данных;
- variables — количество анализируемых параметров (унитарных последовательностей в мультимодальных исходных данных);
- period — периодичность исходных данных;
- forecast — глубина прогноза.
bool CNeuronSparseTSF::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint sequence, uint variables, uint period, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch ) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, forecast * variables, optimization_type, batch)) return false;
В теле метода мы, как обычно, вызываем одноименный метод родительского класса, в котором уже построен процесс инициализации унаследованных объектов и переменных.
Обратите внимание, что при вызове метода инициализации родительского класса мы указываем размер слоя равный произведению глубины прогноза на количество унитарных последовательностей в мультимодальных данных.
После успешной инициализации унаследованных объектов и переменных мы переходим к этапу инициализации добавленных внутренних объектов. Их инициализацию мы будем осуществлять в последовательности проведения прямого прохода. И тут, как говорится, "следите за руками". А в нашем случае — за размерностью тензора обрабатываемых данных.
На вход слоя мы ожидаем получить тензор исходных данных размерностью L*v, где L — длина последовательности исходных данных, а v — количество унитарных рядов в мультимодальных исходных данных. Как было сказано в первой части данной статьи, метод SparseTSF работает в парадигме прогнозирования независимых унитарных последовательностей. И для организации подобного процесса мы транспонируем матрицу исходных данных до v*L.
if(!acTranspose[0].Init(0, 0, OpenCL, sequence, variables, optimization, iBatch)) return false;
Далее мы планируем осуществить агрегирование исходных данных при помощи сверточного слоя. В данной операции мы проведем свертку в рамках 2 периодов исходных данных с шагом в 1 период. Для сохранения размерности — количество фильтров свертки равно размеру периода.
if(!cConvolution.Init(0, 1, OpenCL, 2 * period, period, period, sequence / period, variables, optimization, iBatch)) return false; cConvolution.SetActivationFunction(None);
Обратите внимание, что агрегирование данных мы осуществляем в рамках независимых унитарных последовательностей.
Следующим шагом алгоритма SparseTSF является дискредитация исходных данных. На этом этапе авторы метода предлагают изменить размерность и транспонировать тензор исходных данных. В нашем случае мы работаем с одномерными буферами данных. И изменение размерность исходных данных носит декларативный характер — оно не ведет к перестановке данных в памяти. Чего не скажешь о транспонировании. Поэтому далее мы инициализируем следующий слой транспонирования данных.
if(!acTranspose[1].Init(0, 2, OpenCL, variables * sequence / period, period, optimization, iBatch)) return false;
Может показаться немного странным использование второго слоя транспонирования данных. Ведь, на первый взгляд, он выполняет операцию обратную предыдущему транспонированию исходных данных. Но это совсем не так. Я не зря акцентировал внимание на размерностях данных выше. Общий размер буфера данных у нас остается неизменным — L*v. Только после декларативного изменения размерности матрицы данных мы говорим, что её размер равен (v * L/w) * w, где w — периодичность исходных данных. И транспонируем её до w * (L/w * v). После выполнения такой операции в нашем буфере данных будет наблюдаться последовательность отдельных этапов периодичности исходных данных с учетом независимости унитарных рядов исходных данных.
Графически результат 2 этапов транспонирования данных можно представить следующим образом:
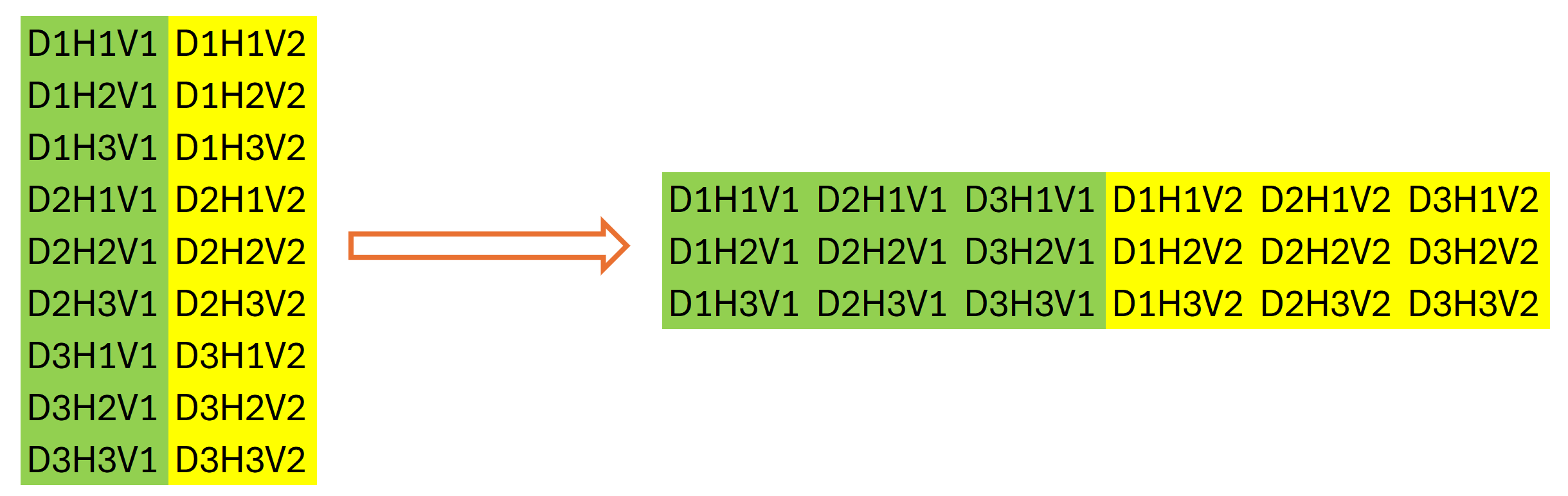
Затем мы используем сверточный слой для независимого прогнозирования отдельных шагов в рамках периодичности исходных данных для унитарных последовательностей на заданный горизонт планирования.
if(!cForecast.Init(0, 3, OpenCL, sequence / period, sequence / period, forecast / period, variables, period, optimization, iBatch)) return false; cForecast.SetActivationFunction(TANH);
Обратите внимание, что размер анализируемого окна исходных данных и его шага равно "sequence / period", а количество фильтров свертки — "forecast / period". Это позволяет нам получить прогнозные значения на весь горизонт планирования за один проход. При этом мы используем отдельные фильтры для каждого шага периода анализируемых данных.
Так как мы предполагаем работать с нормализованными данными, то используем гиперболический тангенс в качестве функции активации для прогнозных значений. Это позволяет ограничить результаты прогнозов в диапазоне [-1, 1].
Далее нам предстоит привести прогнозируемые значения к требуемой последовательности. Эту операцию мы выполняем с помощью 2 последовательных слоев транспонирования данных, которые выполняют операции обратной перестановки значений.
if(!acTranspose[2].Init(0, 4, OpenCL, period, variables * forecast / period, optimization, iBatch)) return false; if(!acTranspose[3].Init(0, 5, OpenCL, variables, forecast, optimization, iBatch)) return false;
А с целью исключения излишнего копирования данных мы организуем подмену буферов результатов и градиентов ошибки текущего слоя.
if(!SetOutput(acTranspose[3].getOutput()) || !SetGradient(acTranspose[3].getGradient()) ) return false; //--- return true; }
На каждой итерации мы проверяем результаты выполнения операций. А итоговый логический результат работы метода мы вернем вызывающей программе.
Обратите внимание, что в процессе инициализации объекта мы не сохранили параметры архитектуры создаваемого слоя. В данном случае нам достаточно передать соответствующие параметры вложенным объектам. Их архитектура однозначно определяет работу класса, что делает излишни дополнительное хранение полученных параметров.
После инициализации объекта класса мы переходим к созданию метода прямого прохода CNeuronSparseTSF::feedForward, в котором выстраиваем алгоритм метода SparseTSF с передачей данных между внутренними объектами.
В параметрах метода прямого прохода мы получаем указатель на объект предшествующего слоя, который содержит исходные данные.
bool CNeuronSparseTSF::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!acTranspose[0].FeedForward(NeuronOCL)) return false;
И так как алгоритм мы будем воссоздавать с использованием ранее созданных методов вложенных объектов, то не будем организовывать проверку актуальности полученного указателя. А просто передадим его в метод прямого прохода первого слоя транспонирования данных, в котором уже организована подобная проверка наряду с операциями основного функционала перестановки данных в буфере данных. Мы лишь проверяем логический результат выполнения операций вызываемого метода.
Далее осуществляется агрегирование данных, которое выполняется вызовом метода прямого прохода сверточного слоя.
if(!cConvolution.FeedForward(acTranspose[0].AsObject())) return false;
В соответствии с алгоритмом метода SparseTSF, агрегированные данные суммируются с исходными данными. Однако, чтобы не нарушать последовательность данных, мы будем суммировать транспонированную версию исходных данных с результатами агрегации.
if(!SumAndNormilize(cConvolution.getOutput(), acTranspose[0].getOutput(), cConvolution.getOutput(), 1, false)) return false;
Следующим шагом мы вызываем метод прямого прохода следующего слоя транспонирования данных, который завершает процесс дискретизации исходной последовательности.
if(!acTranspose[1].FeedForward(cConvolution.AsObject())) return false;
После чего осуществляем прогнозирование наиболее вероятного продолжения анализируемого временного ряда с помощью второго вложенного сверточного слоя.
if(!cForecast.FeedForward(acTranspose[1].AsObject())) return false;
Напомню, что прогнозирование подпоследовательностей осуществляется на основе анализа отдельных шагов в рамках заданной периодичности исходных данных. При этом мы делаем независимые прогнозы по каждой унитарной последовательности мультимодального временного ряда исходных данных. И для каждого шага замкнутого цикла периодичности исходных данных используются свои обучаемые параметры.
Перестановка прогнозных значений в требуемый порядок ожидаемой на выходе последовательности осуществляется с помощью 2 последующих слоев транспонирования данных.
if(!acTranspose[2].FeedForward(cForecast.AsObject())) return false; if(!acTranspose[3].FeedForward(acTranspose[2].AsObject())) return false; //--- return true; }
Конечно, для шага изменения порядка прогнозных значений в буфере данных мы могли бы создать новый кернел и заменить одним его вызовом 2 слоя транспонирования данных. Это дало бы нам некий прирост производительности ввиду исключения излишней операции переноса данных. Но с учетом размера модели прирост производительности ожидается незначительный, и в рамках данного эксперимента мы решили сократить код программы и работу программиста.
Обратите внимание, что операции метода прямого прохода завершаются на выполнении методов прямого прохода вложенных объектов. При этом мы не осуществляем перенос значений в буфер результатов текущего слоя, унаследованный от родительского класса. Однако последующие слои нашей модели не имеют доступа к вложенным объектам и работают с данными буфера результатов нашего слоя. Видимый разрыв потока данных мы компенсировали подменой буферов результатов и градиентов ошибки на стадии инициализации нашего класса. Таким образом, буфер результатов нашего слоя получил указатель на буфер результатов последнего слоя транспонирования данных. И, выполняя последнюю операцию транспонирования, мы фактически записываем данные в буфер результатов нашего слоя. Тем самым исключаются излишние операции переноса данных между объектами.
Как всегда, на каждом этапе мы проверяем результат выполнения операций и возвращаем итоговое логическое значение вызывающей программе.
На этом мы завершаем реализацию прямого прохода метода SparseTSF и переходим к построению алгоритмов обратного прохода. Здесь нам предстоит распределить градиент ошибки между всеми участниками процесса в соответствии с их влиянием на результат и скорректировать параметры модели в сторону минимизации ошибки прогнозирования продолжения анализируемого мультимодального временного ряда.
Первым мы построим метод распределения градиента ошибки CNeuronSparseTSF::calcInputGradients. Как и в случае прямого прохода, в параметрах метода мы получаем указатель на объект предшествующего слоя, в который на данном этапе нам предстоит записать градиент ошибки в соответствии с влиянием исходных данных на результат работы модели.
bool CNeuronSparseTSF::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!acTranspose[2].calcHiddenGradients(acTranspose[3].AsObject())) return false;
Распределять градиент ошибки мы будем в соответствии с операциями прямого прохода, но в обратном порядке. Как Вы знаете, благодаря подмене указателей на буфера данных, градиент ошибки, полученный от последующего слоя модели, попадает в буфер последнего внутреннего слоя транспонирования данных. И мы без выполнения дополнительных операций переноса данных сразу переходим к работе с внутренними объектами.
Сначала мы проводим градиент ошибки через 2 слоя транспонирования данных, чтобы добиться требуемой дискретизации градиентов.
if(!cForecast.calcHiddenGradients(acTranspose[2].AsObject())) return false;
При необходимости мы скорректируем полученный градиент на производную функции активации слоя прогнозирования данных.
if(cForecast.Activation() != None && !DeActivation(cForecast.getOutput(), cForecast.getGradient(), cForecast.getGradient(), cForecast.Activation())) return false;
После чего опустим градиент ошибки до уровня агрегированных данных.
if(!acTranspose[1].calcHiddenGradients(cForecast.AsObject())) return false; if(!cConvolution.calcHiddenGradients(acTranspose[1].AsObject())) return false;
И проведем градиент ошибки через слой агрегации.
if(!acTranspose[0].calcHiddenGradients(cConvolution.AsObject())) return false;
Напомню, что при агрегировании данных мы использовали остаточные связи путем суммирования агрегированных данных и исходной последовательности. Следовательно, градиент ошибки так же проходит по 2 потокам данных, и мы суммируем значения 2 буферов градиентов ошибки.
if(!SumAndNormilize(cConvolution.getGradient(), acTranspose[0].getGradient(), acTranspose[0].getGradient(), 1, false)) return false;
После чего передаем полученный градиент ошибки до уровня предшествующего слоя и, при необходимости, корректируем их на производную функции активации.
if(!NeuronOCL || !NeuronOCL.calcHiddenGradients(acTranspose[0].AsObject())) return false; if(NeuronOCL.Activation() != None && !DeActivation(NeuronOCL.getOutput(), NeuronOCL.getGradient(), NeuronOCL.getGradient(), NeuronOCL.Activation())) //--- return true; }
В завершении метода мы возвращаем логический результат выполнения операций вызывающей программе.
После распределения градиента ошибки до всех объектов нашей модели в соответствии с их влиянием на итоговый результат нам предстоит скорректировать параметры модели в сторону минимизации ошибки прогнозирования данных. Данный функционал выполняется в методе CNeuronSparseTSF::updateInputWeights. И здесь все довольно прозаично и просто. Наш новый класс содержит лишь 2 внутренних сверточных слоя, которые содержат обучаемые параметры. Как вы знаете, при транспонировании данных не используются обучаемые параметры. Поэтому в рамках процесса корректировки параметров модели нам достаточно лишь вызвать одноименные методы вложенных сверточных слоев и проверить логическое значение выполнения операций вызываемых методов. Весь процесс корректировки параметров уже построен во внутренних объектах.
bool CNeuronSparseTSF::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cConvolution.UpdateInputWeights(acTranspose[0].AsObject())) return false; if(!cForecast.UpdateInputWeights(acTranspose[1].AsObject())) return false; //--- return true; }
На этом мы завершаем рассмотрение алгоритмом построения методов основного функционала нашего нового класса CNeuronSparseTSF. Все вспомогательные методы данного класса построены по уже знакомым Вам из предыдущих статей данной серии схемам. Поэтому мы не будем на них останавливаться в рамках данной статьи и оставим для самостоятельного изучения. А полный код всех методов нового класса Вы можете найти во вложении.
2.2 Архитектура обучаемых моделей
Выше мы реализовали основные подходы метода SparseTSF средствами MQL5 в рамках нового класса CNeuronSparseTSF. И теперь нам предстоит внедрить объект нового класса в нашу модель. Думаю очевидно, что алгоритм прогнозирования временного ряда мы, как и ранее, будем использовать в модели Энкодера состояния окружающей среды. Архитектура данной модели у нас представлена в методе CreateEncoderDescriptions, в параметрах которого мы передаем указатель на объект динамического массива для записи архитектуры создаваемой модели.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы проверяем актуальность полученного указателя и, при необходимости, создаем новый объект динамического массива.
Далее, как обычно, мы используем базовый полносвязный слой для записи исходных данных.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM_MINI; if(!encoder.Add(descr)) { delete descr; return false; }
В модель мы передаем "сырые" не обработанные исходные данные, что позволяет нам минимизировать работу по подготовке исходных данных на стороне основной программы. А предварительную обработку получаемые данные проходят в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
За которым мы устанавливаем наш новый слой метода SparseTSF.
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSparseTSF; descr.count = HistoryBars; descr.window = BarDescr;
Напомню, что для обучения и тестирования моделей в рамках данной серии статей мы используем исторические данные таймфрейма H1. И в данных условиях мы установим размер периода исходных данных равный 24, что соответствует 1 календарному дню.
descr.step = 24; descr.window_out = NForecast; descr.activation = None; descr.optimization = ADAM_MINI; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь стоит отметить, что использование рассматриваемых моделей не ограничивается таймфреймом H1. Однако тестирование и обучение различных моделей в одинаковых условиях позволяет нам оценить производительность моделей, минимизируя влияние внешних факторов на их эффективность.
Метод SparseTSF несмотря на кажущуюся простоту является довольно комплексным и самодостаточным. И для получения желаемого прогноза предстоящего ценового движения нам остается лишь добавить показатели распределения исходных данных, изъятые в слое пакетной нормализации.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
И для согласования частотных характеристик прогнозных значений воспользуемся подходами метода FreDF.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Как можно заметить, архитектура модели Энкодера состояния окружающей среды получилась довольно краткой. Что вполне соответствует заявленной авторами метода SparseTSF легковесности.
Модели Актера и Критика мы перенесли без изменения из предыдущей статьи. То же касается и программ обучения моделей и взаимодействия с окружающей средой. Поэтому в рамках данной статьи мы не будем останавливаться на их рассмотрении. А полный код всех программ и классов, используемых при подготовке данной статьи, Вы можете найти во вложении.
3. Тестирование
В предыдущих разделах данной статьи мы познакомились с теоретическими аспектами метода SparseTSF и реализовали подходы, предложенные авторами метода, средствами MQL5. И теперь пришло время оценить эффективность предложенных подходов в сфере прогнозирования предстоящего ценового движения на реальных исторических данных. А так же проверить возможность использования полученных прогнозов для построения эффективной политики действий нашего Актера.
В процессе построения новой модели мы не вносили изменений в структуру исходных данных и ожидаемых прогнозируемых результатов. Это позволило нам использовать программы взаимодействия с окружающей средой и обучения моделей из предыдущих работ без каких-либо изменений. Это же позволяет нам использовать для первичного обучения моделей ранее собранные обучающие выборки. Таким образом, мы осуществляем обучение Энкодера состояния окружающей среды с использованием буфера воспроизведения опыта ранее обучаемых моделей.
Как Вы помните, Энкодер состояния окружающей среды работает только с ценовым движением и значениями анализируемых индикаторов, которые не зависят от действий Актера. Соответственно, в понимании Энкодера все проходы в обучающей выборки на одном историческом интервале идентичны. Это позволяет нам обучать модель Энкодера без необходимости обновления обучающей выборки. А легковесность предложенной модели дает возможность значительно снизить затраты ресурсов и времени на обучение Энкодера.
Нельзя сказать, что в процессе обучения модели были получены прогнозы последующих состояний высокой точности. Но, в целом, качество прогнозов сопоставимо с более сложными моделями, обучение которых требует больше ресурсов и времени. И в этом плане, можно сказать, что мы отчасти получили желаемый результат.
Второй этап — обучение политики Актера на основе полученных прогнозных значений. На этом этапе мы осуществляем итерационное обучение моделей с периодическим обновлением обучающей выборки, что позволяет нам иметь актуальную обучающую выборку с реальным вознаграждением за распределение действий, близкое к текущей политике Актера. И должен признаться, что на данном этапе я был приятно удивлен — на первый взгляд не выразительные прогнозы предстоящего ценового движения оказались достаточно информативными для построения политик Актера, способной генерировать прибыль как на обучающей, так и на тестовой выборке.
Напомню, что для обучения моделей мы использовали исторические данные инструмента EURUSD таймфрейм H1 за весь 2023 год. Параметры всех анализируемых индикаторов используются по умолчанию. Тестирование обученных моделей осуществляется на исторических данных Января 2024 года с сохранением всех прочих параметров. Таким образом, мы максимально приближаем тестирование модели к реальным условиям её эксплуатации.
Результаты тестирования обученной модели представлены ниже.
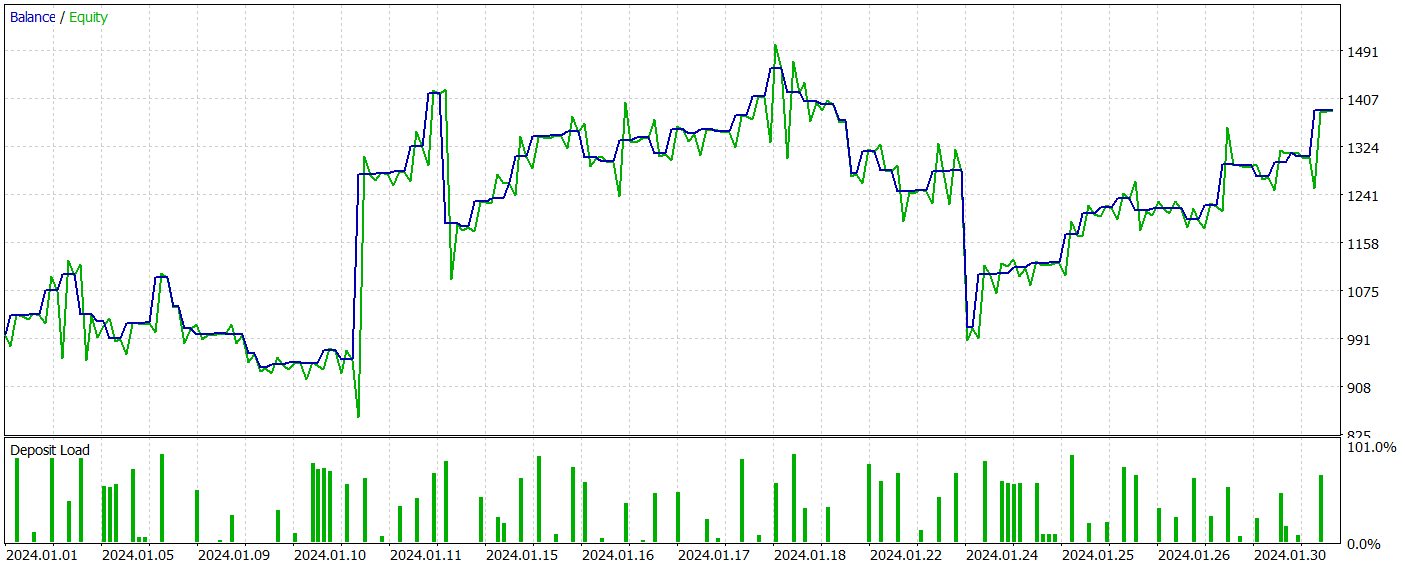
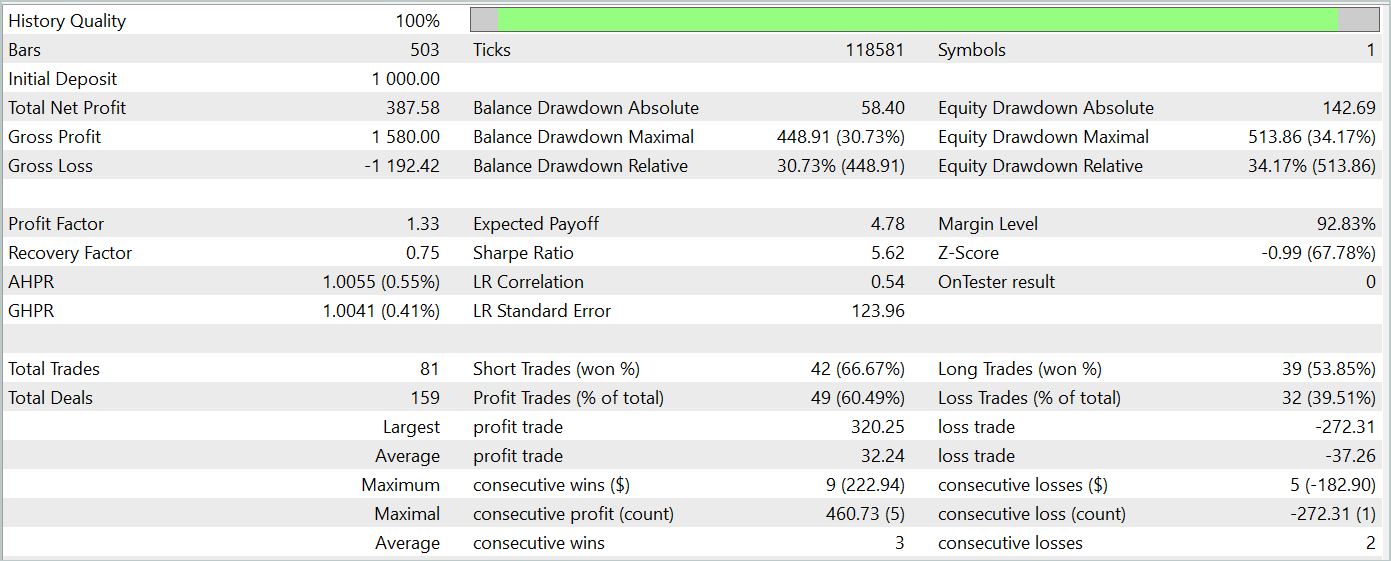
За период тестирования модель совершила 81 сделку. При этом мы имеем почти равное распределение между короткими и длинными позициями — 42 против 39, соответственно. Более 60% сделок было закрыто с прибылью, что позволило получить профит-фактор на уровне 1.33.
Одной из особенностей метода SparseTSF является прогнозирование данных в разрезе отдельных шагов периода цикличности исходных данных. Напомню, что в обученной модели Энкодера состояния окружающей среды мы анализировали часовые данные с периодом цикличности 24 часа. И в этом аспекте особый интерес вызывает доходность модели в почасовом разрезе.
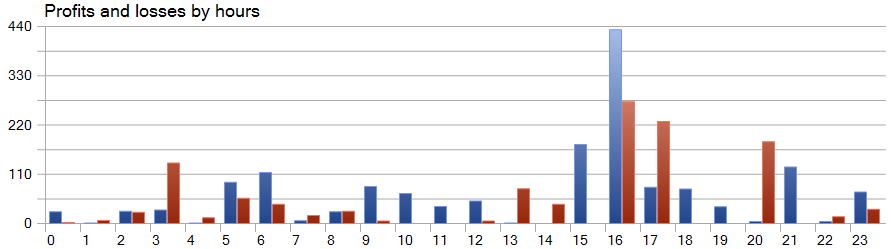
На представленном графике мы видим практическое отсутствие убытков в первой половине европейской сессии с 9 до 12 часов. Средняя длительность удержания сделки в размере 1 час 6 минут позволяет говорить о минимальном смещении между открытием сделки и фиксации прибыли/убытков. Максимальная же доходность наблюдается вначале американской сессии (15-16 часов).
Заключение
В данной статье мы познакомились с метод SparseTSF, который демонстрирует преимущества в области прогнозирования временных рядов благодаря своей легковесной архитектуре и эффективному использованию ресурсов. Использование минимального количество параметров делает предложенную модель особенно полезной для приложений с ограниченными вычислительными ресурсами и коротким временем принятия решений.
SparseTSF позволяет анализировать отдельные шаги временных рядов с заданной периодичностью и выполнять независимые прогнозы для каждой унитарной последовательности, что обеспечивает высокую гибкость и адаптивность модели.
В практической части статьи мы реализовали предложенные подходы средствами MQL5, обучили и провели тестирование обученной модели на реальных исторических данных. Как результат, мы получили модель, способную генерировать прибыль обучающей и тестовой выборках. Что свидетельствует об эффективности предложенных подходов.
Тем не менее хочу ещё раз напомнить, что в данной статье представлены программы, предназначенные только для демонстрации одного из вариантов реализации предложенных подходов и их использования. Однако, представленные программы не готовы к использованию на реальных финансовых рынках.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования