
Нейросети в трейдинге: Кусочно-линейное представление временных рядов

Введение
Чаще всего, говоря о представлении временного ряда, перед нами предстают данные, являющиеся последовательностью точек, записанных в хронологическом порядке. Однако, с ростом объема исходной информации, растет и сложность её анализа, что снижает эффективность использования имеющейся информации. Это особенно важно при работе на финансовых рынках, когда потеря времени при анализе информации и принятии решения ведут к повышению рисков недополучения прибыли, а порой и к убыткам. И в этой связи особая роль отводится преимуществам снижения размерности данных, для повышения эффективности и результативности их интеллектуального анализа. Одним из подходов к снижению размерности данных является кусочно-линейное представление временных рядов.
Кусочно-линейное представление временных рядов — это метод аппроксимации временного ряда с помощью линейных функций на небольших интервалах. И в данной статье я хочу вас познакомить с алгоритмом двунаправленного кусочно-линейного представления временных рядов (Bidirectional Piecewise Linear Representation — BPLR), который был представлен в работе "Bidirectional piecewise linear representation of time series with application to collective anomaly detection". Данный метод был предложен для решения задач поиска аномалий во временных рядах.
Обнаружение аномалий временных рядов является важнейшей подобластью интеллектуального анализа данных временных рядов. Его целью является выявление неожиданного поведения во всем наборе данных. Поскольку аномалии часто вызваны различными механизмами, у них отсутствуют конкретные критерии для определения. На практике данные, демонстрирующие ожидаемое поведение, как правило привлекают больше внимания, в то время как аномальные данные часто воспринимаются, как шум и впоследствии игнорируются или устраняются. Тем не менее, аномалии могут содержать полезную информацию, что делает их обнаружение очень важным. Точное обнаружение аномалий может помочь смягчить ненужные неблагоприятные последствия в различных областях, таких как окружающая среда, промышленность, финансы и другие.
Аномалии во временных рядах можно разделить на следующие три категории:
- Точечные аномалии: точка данных считается аномальной по отношению к остальным точкам данных. Эти аномалии часто вызваны ошибками измерений, неисправностями датчиков, ошибками ввода данных или другими исключительными событиями;
- Контекстуальные аномалии: в определенном контексте точка данных считается аномальной, но в остальном нет;
- Коллективные аномалии: подпоследовательность временных рядов, демонстрирующая аномальное поведение. Это довольно сложная задача, потому что такие аномалии не могут считаться аномальными при индивидуальном анализе. Напротив, аномальным является коллективное поведение группы.
Коллективные аномалии могут дать ценную информацию об анализируемой системе или процессе, поскольку они могут указывать на проблему группового уровня, которую необходимо решить. Таким образом, обнаружение коллективных аномалий может быть важной задачей во многих областях, таких как кибербезопасность, финансы и здравоохранение. Авторы метода BPLR в своей работе сосредоточились на выявлении именно коллективных аномалий.
Высокая размерность данных временных рядов требует значительных вычислительных ресурсов при использовании исходных данных для выявления аномалий. Тем не менее, для повышения эффективности обнаружения аномалий, типичный подход включает в себя сначала уменьшение размерности, а затем использование меры расстояния для выполнения задачи в преобразованном подпространстве представления. Поэтому авторы метода предлагают новый алгоритм двунаправленной сегментации для кусочно-линейного представления BPLR. С помощью этого метода можно преобразовать исходный временной ряд в форму выражения низкой размерности, которая подходит для эффективного анализа.
В работе также предлагается новый алгоритм измерения подобия, основанный на идее кусочно-интегрированного (PI). Он выполняет эффективное вычисление меры подобия с относительно низкими вычислительными затратами.
1. Алгоритм
Обнаружение аномалий на основе предложенного метода BPLR состоит из двух этапов:
- Представление временных рядов;
- Измерение подобия.
Прежде чем перейти к описанию алгоритма представления временных рядов в методе BPLR, следует акцентировать внимание на том, что метод разработан для решения задач обнаружения аномалий. Предполагается, что анализируемый временной ряд имеет некую цикличность, размер которой может быть получен экспериментально или из априорных знаний. Поэтому весь исходный временной ряд разбивается на непересекающиеся подпоследовательности, размер которых равен предполагаемому циклу исходных данных. В сравнении полученных подпоследовательностей авторы метода и пытаются найти аномальные участки. Далее мы опишем алгоритм представления одной подпоследовательности, который повторяется для всех элементов анализируемого временного ряда.
Для выполнения задачи представления временного ряда нам необходимо найти несколько наборов точек сегментации в каждой подпоследовательности. А затем преобразовать исходную подпоследовательность в набор линейных сегментов.
Вначале, с целью поиска наиболее вероятных точек разделения подпоследовательности на отдельные сегменты, мы выделяем все возможные точки разворота тренда (Trend Turning Points — TTP). Авторы метода выделяют 6 вариантов точек разворота тренда.
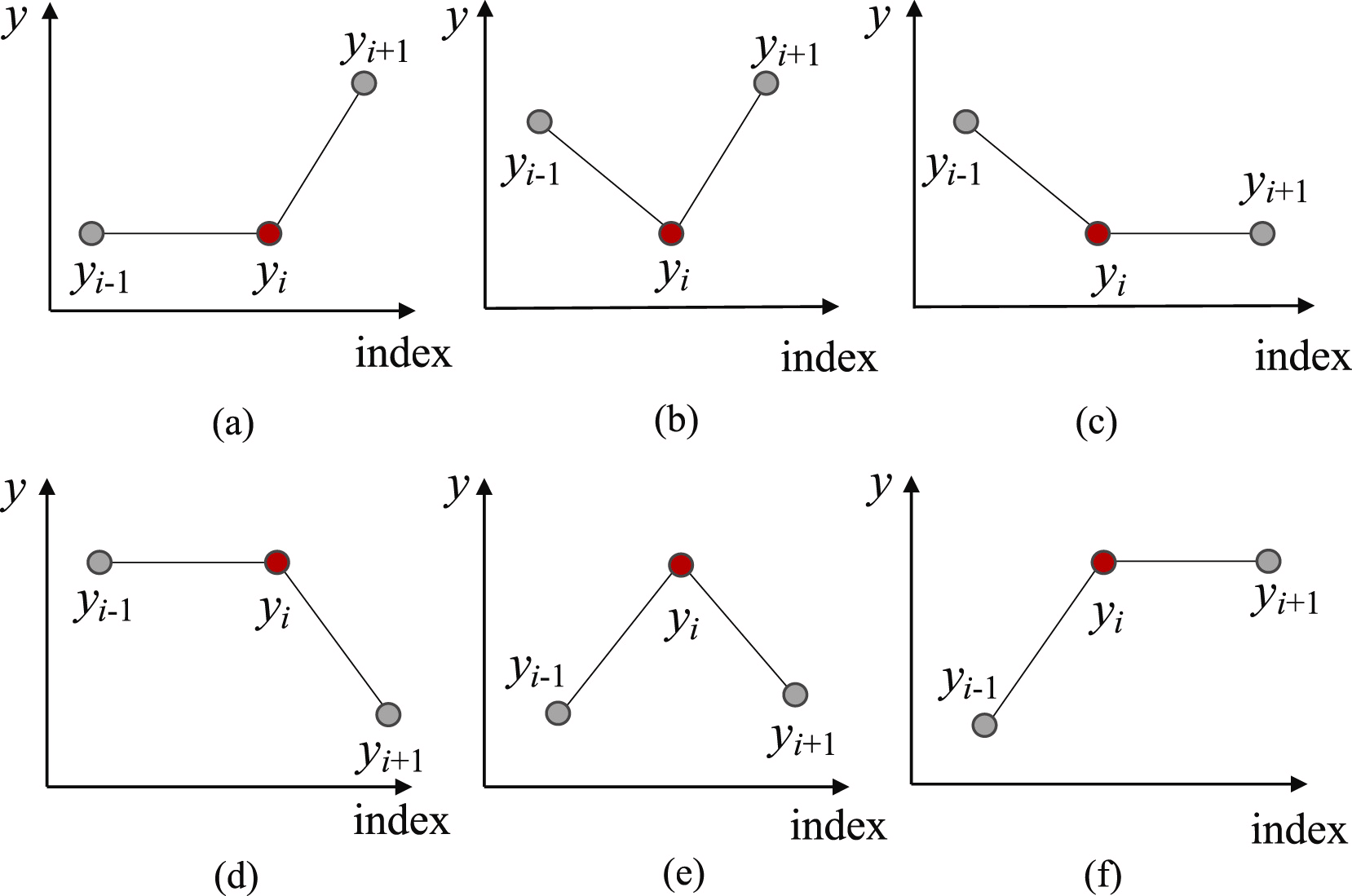
И тут следует отметить, что первый и последний элементы подпоследовательности автоматически считаются точками разворота тренда.
Следующим этапом определяется важность каждой найденной точки разворота тренда. В качестве меры важности TTP авторы метода предлагают использовать отклонение от среднего значения подпоследовательности.
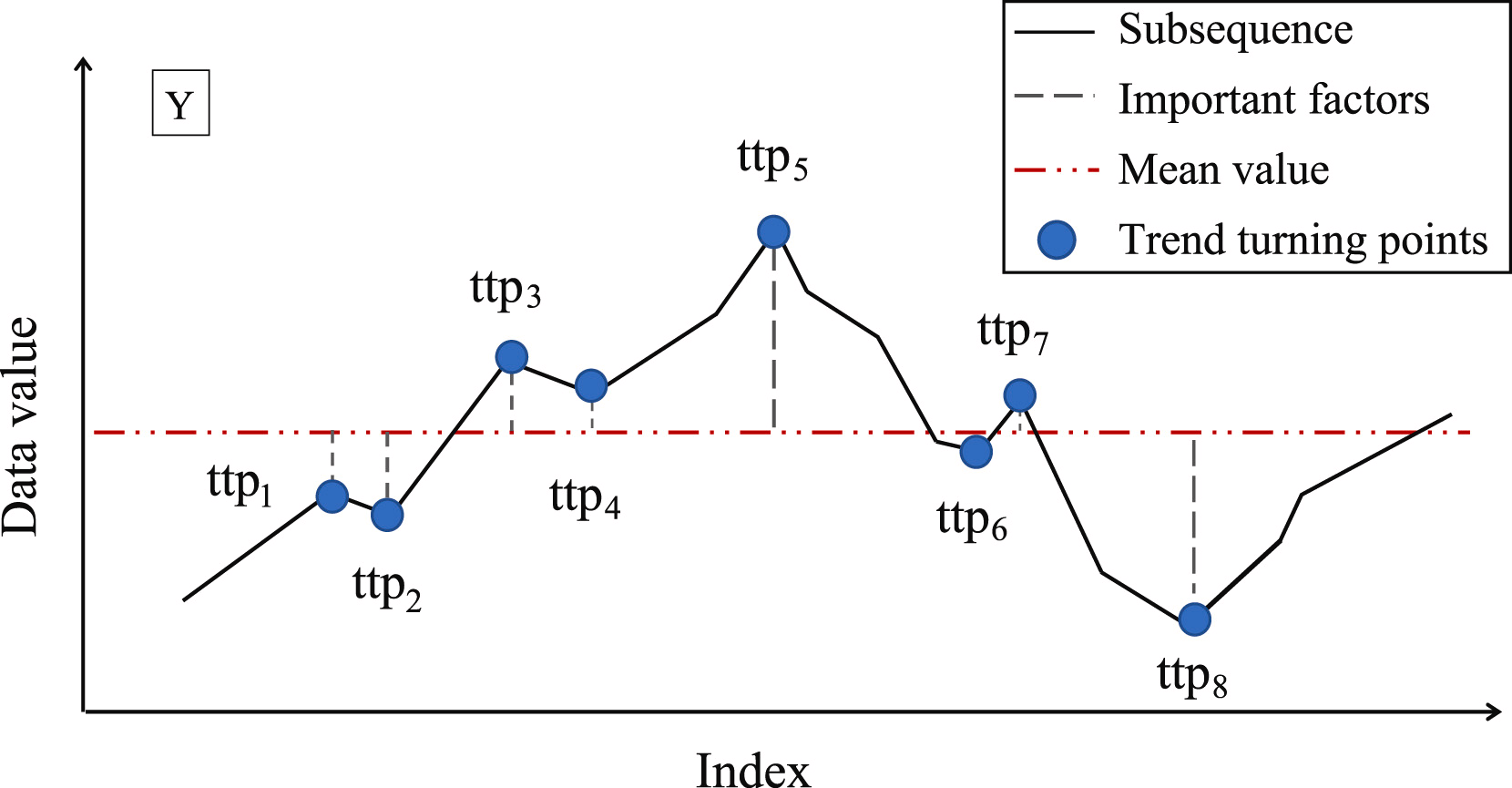
Затем точки разворота тренда сортируются в соответствии с их важностью. Определение сегментов осуществляется итерационно, начиная от TTP1 с максимальной важностью в двух направлениях: до и после TTP1. При этом, для определения качества сегмента вводится дополнительный гиперпараметр δß, который определяет максимально допустимое отклонение точек последовательности от линии сегмента.
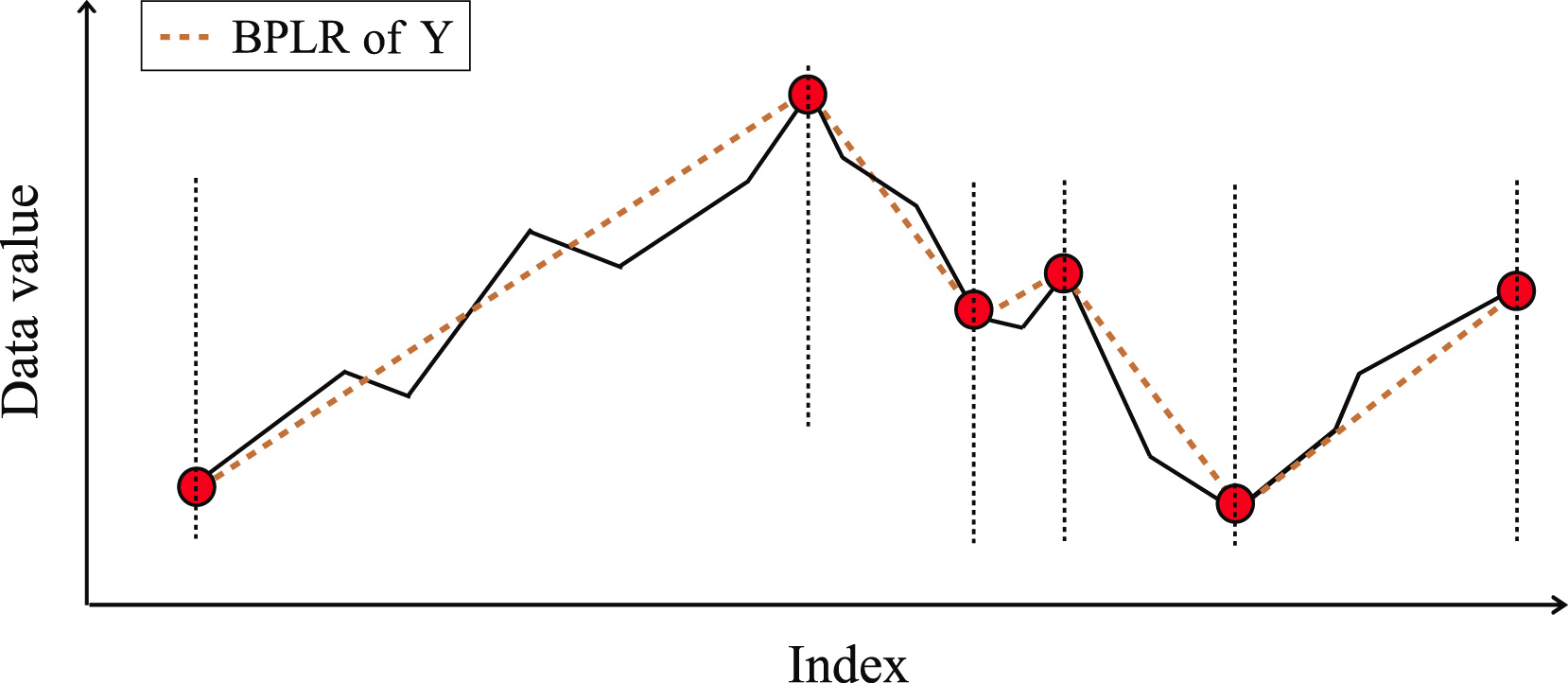
Для определения точки начала предшествующего сегмента, мы осуществляем перебор элементов исходной последовательности в обратном порядке от анализируемой TTP1, пока все элементы между TTP1 и кандидатом в начало сегмента находятся не далее δß. При нахождении точки с выходом за указанные границы, перебор останавливается, а сегмент сохраняется. Если в зону действия сегмента попадают ранее найденные точки разворота тренда, то они удаляются.
Аналогичным образом осуществляется поиск окончания сегмента в сторону после TTP1. Именно благодаря поиску сегментов в направлениях до и после экстремума, метод получил название двунаправленного.
После определения конечных точек обоих сегментов, операции повторяются с экстремумом, следующим по важности. Итерации завершаются, когда в массиве не остается необработанных точек разворота тренда.
Для определения сходства двух подпоследовательностей определяется площадь фигуры, которую образуют сегменты анализируемых последовательностей.
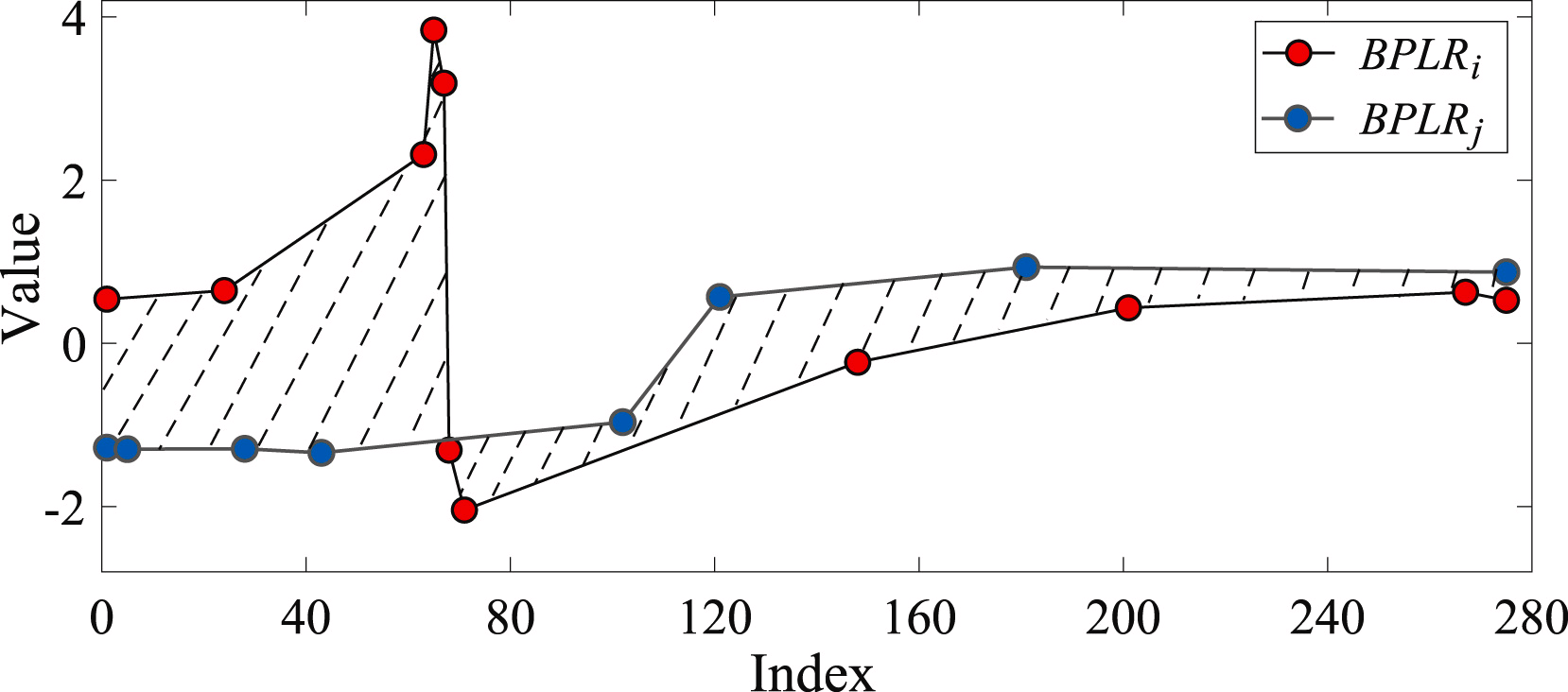
Для решения задачи поиска аномалий авторы метода составляют матрицу отклонений Mdist. Затем для каждой отдельной подпоследовательности вычисляется суммарное отклонение от других подпоследовательностей анализируемого временного ряда Di. На практике Di представляет собой суммы элементов матрицы Mdist в i строке. Аномальной считается подпоследовательность, суммарное отклонение которой отличается более заданного порога погрешности от среднего значения аналогичного показателя остальных подпоследовательностей.
В своей работе авторы метода BPLR приводят результаты экспериментов на синтетических и реальных данных, которые свидетельствуют об эффективности предложенного решения.
2. Реализация средствами MQL5
Выше мы познакомились с теоретическим представлением метода BPLR для поиска аномальных подпоследовательностей временных рядов. А в практической части данной статьи реализуем свое видение предложенных подходов средствами MQL5. И надо сказать, что мы лишь частично воспользуемся предложенными решениями.
Сразу скажу, что в рамках данной работы мы не будем искать аномалии временных рядов. Финансовые рынки настолько динамичны и многогранны — вполне ожидаемо, что между любыми двумя непересекающимися подпоследовательностями мы получим значительные отклонения.
С другой стороны, альтернативное представление временного ряда в виде кусочно-линейной последовательности может быть весьма полезным. В рамках своих предыдущих работ мы уже говорили о пользе сегментирования данных. И вопрос определения размера сегмента остается весьма актуальным. При этом мы использовали всегда равные размеры сегментов. А метод кусочно-линейного представления позволяет использовать динамические размеры сегментов, в зависимости от анализируемого временного ряда исходных данных, что в какой-то мере позволяет решить вопрос извлечения признаков временного ряда различного масштаба. В это же время, кусочно-линейное представление имеет фиксированный размер вне зависимости от размера сегмента, что делает его удобным для последующего анализа.
Здесь так же надо сказать и о представлении сегментов. Само название "кусочно-линейное представление" указывает на представление сегмента в виде линейной функции:
![]()
Как следствие, мы явным образом указываем направление главной тенденции на временном участке сегмента. А возможность сжатия данных является дополнительным бонусом, который позволяет снизить сложность модели.
И конечно, мы не будем делить анализируемый временной ряд на подпоследовательности. Мы представим в виде кусочно-линейной последовательности весь набор исходных данных. А наша модель, на основе анализа представленных данных, должна сделать выводы и предложить "единственно верное" решение.
Ну а начнем мы работу с построения программы на стороне OpenCL.
2.1 Реализация на стороне OpenCL
Как вы знаете, с целью оптимизации затрат на обучение и эксплуатацию своих моделей, основную часть вычислений мы вынесли в контекст OpenCL устройств, что позволило нам организовать вычисления в многомерном пространстве параллельных потоков. И данная реализация в этом плане не является исключением.
Для целей сегментации анализируемого временного ряда мы создадим кернел PLR.
__kernel void PLR(__global const float *inputs, __global float *outputs, __global int *isttp, const int transpose, const float min_step ) { const size_t i = get_global_id(0); const size_t lenth = get_global_size(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1);
В параметрах кернелу мы планируем передавать указатели на 3 буфера данных:
- inputs — исходные результаты
- outputs — результаты
- isttp — служебный буфер для фиксирования точек разворота тренда
Кроме того, мы добавим 2 константы:
- transpose — флаг необходимости транспонирования исходных данных и результатов
- min_step — минимальное отклонение элементов последовательности для фиксирования TTP
Вызывать кернел мы планируем в 2 мерном пространстве задач по числу элементов в анализируемой последовательности и количеству унитарных последовательностей в многомерном временном ряде. Соответственно, в теле кернела мы сразу идентифицируем текущий поток в пространстве задач, а затем определим константы смещение в буфере исходных данных.
//--- constants const int shift_in = ((bool)transpose ? (i * variables + v) : (v * lenth + i)); const int step_in = ((bool)transpose ? variables : 1);
После небольшой подготовительной работы, мы определим наличие точки разворота тренда в позиции анализируемого элемента. Крайние точки анализируемого временного ряда автоматически получают статус точки разворота тренда, так как они априори являются крайними точками сегмента.
float value = inputs[shift_in]; bool bttp = false; if(i == 0 || i == lenth - 1) bttp = true;
В отдельных случаях мы сначала ищем ближайшее отклонение значений анализируемого ряда на минимально-необходимое значение до текущего элемента последовательности. При этом сохраняем минимальное и максимальное значения в интервале из пройденных.
else { float prev = value; int prev_pos = i; float max_v = value; float max_pos = i; float min_v = value; float min_pos = i; while(fmax(fabs(prev - max_v), fabs(prev - min_v)) < min_step && prev_pos > 0) { prev_pos--; prev = inputs[shift_in - (i - prev_pos) * step_in]; if(prev >= max_v && (prev - min_v) < min_step) { max_v = prev; max_pos = prev_pos; } if(prev <= min_v && (max_v - prev) < min_step) { min_v = prev; min_pos = prev_pos; } }
Затем аналогичным образом ищем последующий элемент с минимально-необходимым отклонением.
//--- float next = value; int next_pos = i; while(fmax(fabs(next - max_v), fabs(next - min_v)) < min_step && next_pos < (lenth - 1)) { next_pos++; next = inputs[shift_in + (next_pos - i) * step_in]; if(next > max_v && (next - min_v) < min_step) { max_v = next; max_pos = next_pos; } if(next < min_v && (max_v - next) < min_step) { min_v = next; min_pos = next_pos; } }
И проверяем, является ли текущее значение экстремумом.
if( (value >= prev && value > next) || (value > prev && value == next) || (value <= prev && value < next) || (value < prev && value == next) ) if(max_pos == i || min_pos == i) bttp = true; }
Но тут следует помнить, что при поиске элементов с минимально-необходимым отклонением мы могли собрать некий коридор значений из нескольких элементов последовательности, которые формируют некоторое плато экстремума. Поэтому флаг точки разворота тренда элемент получает только в том случае, если является экстремумом в таком коридоре.
Сохраним полученный флаг и очистим буфер результатов. При этом синхронизируем потоки локальной группы.
//--- isttp[shift_in] = (int)bttp; outputs[shift_in] = 0; barrier(CLK_LOCAL_MEM_FENCE);
Синхронизация потоков нам необходима для получения уверенности, что перед последующими операциями все потоки текущего унитарного временного ряда записали свои флаги наличия точки разворота тренда.
Следующие операции выполняются только потоками, в которых определена точка разворота тренда. Остальные потоки просто не удовлетворяют поставленным условиям и практически завершают выполнение операций.
Здесь мы сначала посчитаем позицию текущего экстремума. Для этого мы посчитаем количество положительных флагов по текущей позиции элемента, и предусмотрительно сохраним в локальной переменной позицию предшествующей точки разворота тренда в буфере исходных данных.
//--- calc position int pos = -1; int prev_in = 0; int prev_ttp = 0; if(bttp) { pos = 0; for(int p = 0; p < i; p++) { int current_in = ((bool)transpose ? (p * variables + v) : (v * lenth + p)); if((bool)isttp[current_in]) { pos++; prev_ttp = p; prev_in = current_in; } } }
После чего определим параметры линейного приближения тенденции текущего сегмента.
//--- cacl tendency if(pos > 0 && pos < (lenth / 3)) { float sum_x = 0; float sum_y = 0; float sum_xy = 0; float sum_xx = 0; int dist = i - prev_ttp; for(int p = 0; p < dist; p++) { float x = (float)(p); float y = inputs[prev_in + p * step_in]; sum_x += x; sum_y += y; sum_xy += x * y; sum_xx += x * x; } float slope = (dist * sum_xy - sum_x * sum_y) / (dist > 1 ? (dist * sum_xx - sum_x * sum_x) : 1); float intercept = (sum_y - slope * sum_x) / dist;
И сохраним полученные результаты в буфер результатов.
int shift_out = ((bool)transpose ? ((pos - 1) * 3 * variables + v) : (v * lenth + (pos - 1) * 3)); outputs[shift_out] = slope; outputs[shift_out + 1 * step_in] = intercept; outputs[shift_out + 2 * step_in] = ((float)dist) / lenth; }
Здесь стоит обратить внимание, что каждый полученный сегмент мы характеризуем 3 параметрами:
- slope — угол наклона линии тенденции;
- intercept — смещение линии тенденции в подпространстве исходных данных;
- dist — длина сегмента.
Наверное, надо пару слов сказать о представлении длительности сегмента. Думаю, вы догадались, что указание длины последовательности целочисленным значением, в данном случае, не лучший результат. Ведь для эффективной работы модели желателен нормализованный формат представления данных. Поэтому было принято решение представлять длительность сегмента в долях общего размера анализируемой унитарной временной последовательности. Поэтому мы разделим количество элементов в сегменте на количество элементов во всей последовательности унитарного временного ряда. И чтобы не попасть в "ловушку" целочисленных операций, мы предварительно переведем количество элементов в сегменте из типа int в тип float.
Кроме того, мы создадим отдельную ветку операций для последнего сегмента. Дело в том, что мы не знаем количество сегментов, которые будут сформированы в тот или иной момент времени. Чисто гипотетически, при значительных колебаниях элементов временного ряда и наличии точек разворота тренда в каждом элементе временного ряда, мы можем получить вместо сжатия в 3 раза больше значений. Конечно, такой поворот событий маловероятен, тем не менее, мы бы не хотели увеличения объема данных. Вместе с тем мы не желаем и потери данных.
Поэтому мы исходим из априорных знаний представления тайм-серий в MQL5 и понимания структуры анализируемых данных, — последние по времени данные находятся в начале нашего временного ряда. И им мы уделяем больше внимания. Данные, находящиеся в конце анализируемого окна, имеют большую глубину истории и, ожидаемо, оказывают меньшее влияние на последующие события. Хотя мы и не исключаем такое влияние.
Как следствие, для записи результатов мы используем размер буфера данных, аналогичный размеру тензора исходных значений временного ряда. Это позволяет нам записать сегментов в 3 раза меньше длины последовательности (3 элемента для записи 1 сегмента). Мы ожидаем, что такого объема более чем достаточно. Тем не менее, мы страхуемся, и при наличии большего количества сегментов, во избежание потери данных, мы объединяем данные последних сегментов в 1.
else { if(pos == (lenth / 3)) { float sum_x = 0; float sum_y = 0; float sum_xy = 0; float sum_xx = 0; int dist = lenth - prev_ttp; for(int p = 0; p < dist; p++) { float x = (float)(p); float y = inputs[prev_in + p * step_in]; sum_x += x; sum_y += y; sum_xy += x * y; sum_xx += x * x; } float slope = (dist * sum_xy - sum_x * sum_y) / (dist > 1 ? (dist * sum_xx - sum_x * sum_x) : 1); float intercept = (sum_y - slope * sum_x) / dist; int shift_out = ((bool)transpose ? ((pos - 1) * 3 * variables + v) : (v * lenth + (pos - 1) * 3)); outputs[shift_out] = slope; outputs[shift_out + 1 * step_in] = intercept; outputs[shift_out + 2 * step_in] = ((float)dist) / lenth; } } }
В большинстве же случаев мы ожидаем наличия меньшего количества сегментов, и тогда последние элементы нашего буфера результатов будут заполнены нулевыми значениями.
Здесь следует обратить внимание, что представленный выше алгоритм не содержит обучаемых параметров и может быть использован на стадии предварительной подготовки исходных данных. Это не подразумевает наличия процесса обратного прохода и распределения градиента ошибки. Тем не менее, в своей работе мы предполагаем внедрение данного алгоритма в свои модели. И как следствие, нам потребуется реализация алгоритма обратного прохода, для распределения градиента ошибки от последующих нейронных слоев до предыдущих. Вместе с тем отсутствие обучаемых параметров исключает наличие алгоритмов их оптимизации.
Таким образом, в рамках реализации алгоритмов обратного прохода мы создадим кернел распределения градиента ошибки PLRGradient.
__kernel void PLRGradient(__global float *inputs_gr, __global const float *outputs, __global const float *outputs_gr, const int transpose ) { const size_t i = get_global_id(0); const size_t lenth = get_global_size(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1);
В параметрах кернела мы так же передаем указатели на 3 буфера данных. Только на этот раз это 2 буфера градиентов ошибки (на уровне исходных данных и результатов) и буфер результатов прямого прохода текущего слоя. Кроме того, в параметры кернела мы добавим уже знакомый нам флаг транспонирования данных, который используется при определении смещений в буферах данных.
Вызывать кернел мы планируем во все том же 2 мерном пространстве задач. Первое измерение ограничивается размером последовательности временного ряда, а второе — количеством унитарных временных рядов в мультимодальных исходных данных. В теле кернела мы сразу идентифицируем текущий поток в пространстве задач по всем измерениям.
Следующим шагом мы определим константы смещений в буферах данных.
//--- constants const int shift_in = ((bool)transpose ? (i * variables + v) : (v * lenth + i)); const int step_in = ((bool)transpose ? variables : 1); const int shift_out = ((bool)transpose ? v : (v * lenth)); const int step_out = 3 * step_in;
Но на этом подготовительная работа не завершена. Далее нам предстоит найти сегмент, в который попадает анализируемый элемент исходных данных. Для этого мы организуем цикл, в теле которого будем суммировать размеры сегментов, начиная от самого первого. Итерации цикла будем повторять до тех пор, пока не найдем сегмент, который бы содержал искомый элемент исходных данных.
//--- calc position int pos = -1; int prev_in = 0; int dist = 0; do { pos++; prev_in += dist; dist = (int)fmax(outputs[shift_out + pos * step_out + 2 * step_in] * lenth, 1); } while(!(prev_in <= i && (prev_in + dist) > i));
После завершения итераций цикла мы получим:
- pos — индекс сегмента, содержащего искомый элемент исходных данных
- prev_in — смещение в буфере исходных данных до первого элемента сегмента
- dist — количество элементов в сегменте
Для вычисления производных первого порядка операций прямого прохода, нам так же понадобится сумма позиций элементов сегмента и сумма их квадратных значений.
//--- calc constants float sum_x = 0; float sum_xx = 0; for(int p = 0; p < dist; p++) { float x = (float)(p); sum_x += x; sum_xx += x * x; }
На этом этапе подготовительная работа завершена, и мы можем переходить к вычислению градиента ошибки. Для начала мы извлечем градиент ошибки для угла наклона и смещения.
//--- get output gradient float grad_slope = outputs_gr[shift_out + pos * step_out]; float grad_intercept = outputs_gr[shift_out + pos * step_out + step_in];
Теперь давайте вспомним формулу, которую мы использовали при прямом проходе для вычисления вертикального смещения линии тенденции.
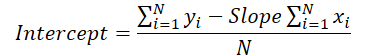
Можно заметить, что значение угла наклона линии используется для вычисления смещения. Поэтому необходимо откорректировать градиент ошибки угла наклона, учитывая его влияние на коррекцию смещения. Для этого найдем производную функции смещения по углу наклона.
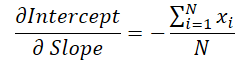
Умножим поученное значение на градиент ошибки смещения и результат прибавим к градиенту ошибки угла наклона.
//--- calc gradient
grad_slope -= sum_x / dist * grad_intercept;
Теперь давайте обратимся к формуле определения угла наклона.
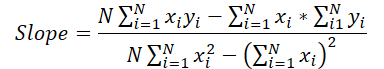
Легко заметить, что знаменатель в данном случае является константой, и мы можем скорректировать на него градиент ошибки угла наклона.
grad_slope /= fmax(dist * sum_xx - sum_x * sum_x, 1);
И в завершении посмотрим на влияние исходных данных в обоих формулах.
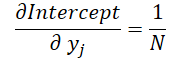
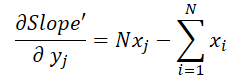
где 1 ≤ j ≤ N и
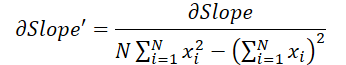
Вооружившись данными формулами, определим градиент ошибки на уровне исходных данных.
float grad = grad_intercept / dist; grad += (dist * (i - prev_in) - sum_x) * grad_slope; if(isnan(grad) || isinf(grad)) grad = 0;
Результат сохраним в соответствующий элемент буфера градиентов исходных данных.
//--- save result
inputs_gr[shift_in] = grad;
}
На этом мы завершаем работу на стороне контекста OpenCL, а полный код OpenCL программы вы можете найти во вложении.
2.2 Реализация нового класса
После завершения работы на стороне OpenCL контекста, мы переходим к работе с кодом основной программы. Здесь мы создадим новый класс CNeuronPLROCL, который позволит нам внедрить вышеописанный алгоритм в наши модели в виде обычного нейронного слоя.
Как и в большинстве аналогичных случаев, основной функционал новый объект унаследует от нашего базового класса нейронных слоев CNeuronBaseOCL. Ниже представлена структура нового класса.
class CNeuronPLROCL : public CNeuronBaseOCL { protected: bool bTranspose; int icIsTTP; int iVariables; int iCount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronPLROCL(void) : bTranspose(false) {}; ~CNeuronPLROCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint units_count, bool transpose, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronPLROCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); };
В представленной структуре можно заметить переопределение стандартного набора методов и добавления нескольких переменных, по названию которых легко догадаться о возложенном на них функционале.
- bTranspose — флаг необходимости транспонирования исходных данных и результатов
- iCount — размер анализируемой последовательности (глубина истории)
- iVariables — количество анализируемых параметров мультимодального временного ряда (унитарных последовательностей)
И обратите внимание, что несмотря на наличие вспомогательного буфера данных в параметрах кернела прямого прохода, на стороне основной программы мы не создаем дополнительный буфер. Здесь мы сохраним лишь указатель на него в локальную переменную icIsTTP.
Отсутствие внутренних объектов позволяет нам оставить пустыми конструктор и деструктор класса. А инициализация объекта осуществляется в методе Init.
bool CNeuronPLROCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint units_count, bool transpose, ENUM_OPTIMIZATION optimization_type, uint batch ) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_in * units_count, optimization_type, batch)) return false;
В параметрах метод получает основные константы определения архитектуры создаваемого объекта. И в теле класса мы сразу вызываем одноименный метод родительского класса, в котором уже реализованы необходимые контроли и инициализация унаследованных объектов и переменных.
Затем мы сохраним параметры конфигурации создаваемого объекта.
iVariables = (int)window_in; iCount = (int)units_count; bTranspose = transpose;
И в завершение метода создадим вспомогательный буфер данных на стороне OpenCL контекста.
icIsTTP = OpenCL.AddBuffer(sizeof(int) * Neurons(), CL_MEM_READ_WRITE); if(icIsTTP < 0) return false; //--- return true; }
После инициализации объекта, мы переходим к построению алгоритма прямого прохода, который реализован в методе feedForward. Здесь нам достаточно вызвать вышесозданный кернел прямого прохода PLR. Но есть нюанс — необходимо создать локальные группы для синхронизации потоков в рамках отдельно взятых унитарных временных рядов.
bool CNeuronPLROCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL || !NeuronOCL.getOutput()) return false; //--- uint global_work_offset[2] = {0}; uint global_work_size[2] = {iCount, iVariables}; uint local_work_size[2] = {iCount, 1};
Для этого мы задаем 2 мерное глобальное пространство задач. По первому измерению указываем размер анализируемой последовательности, а по второму измерению — количество унитарных временных рядов. Размер локальной группы мы так же задаем в 2 мерном пространстве задач. При этом размер первого измерения соответствует глобальному значению, а по второму измерению указываем 1. Таким образом, каждая локальная группа получает свою унитарную последовательность.
Далее нам остается предать необходимые параметры кернелу.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_PLR, def_k_plr_inputs, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PLR, def_k_plr_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_PLR, def_k_plt_isttp, icIsTTP)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PLR, def_k_plr_transpose, (int)bTranspose)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_PLR, def_k_plr_step, (float)0.3)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И поставить кернел в очередь выполнения.
//--- if(!OpenCL.Execute(def_k_PLR, 2, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
При этом не забываем на каждом этапе контролировать процесс выполнения операций. А в завершение метода вернем логическое значение результатов работы метода вызывающей программе.
Аналогичным образом построен алгоритм метода распределения градиента ошибки calcInputGradients. Но в отличие от метода прямого прохода, здесь мы не создаем локальных групп, и каждый поток выполняет свои операции вне зависимости от остальных. С полным кодом указанного метода вы можете самостоятельно ознакомиться во вложении.
Как уже было сказано выше, создаваемый нами объект не содержит обучаемых параметров. Поэтому метод их оптимизации updateInputWeights был переопределен лишь с целью сохранения общей структуры объектов и их совместимости в процессе реализации. Данный метод всегда возвращает значение true.
На этом мы завершаем рассмотрение алгоритмов реализации методов нового класса. А с полным кодом всех его методов, включая не рассмотренные в рамках данной статьи, вы можете самостоятельно ознакомиться во вложении.
2.3 Архитектура модели
В рамках данной статьи мы реализовали один из алгоритмов кусочно-линейного представления временных рядов и теперь можем добавить его в архитектуру своих моделей.
Для целей тестирования эффективности предложенной реализации, мы внедрили новый класс в структуру модели Энкодера состояния окружающей среды. И должен сказать, что мы максимально упростили архитектуру модели, с целью оценки влияния именного разложения временного ряда на отдельные линейные тенденции.
Как и ранее, архитектуру модели мы описываем в методе CreateEncoderDescriptions.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В параметрах метод получает указатель — объект динамического массива для записи архитектуры создаваемой модели. И в теле метода мы сразу проверяем актуальность полученного указателя. После чего, при необходимости, создаем новый экземпляр динамического массива.
На вход модели мы, как обычно, подаем информацию о состоянии окружающей среды на заданную глубину истории без какой-либо первичной обработки данных.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И здесь надо сказать, что алгоритм кусочно-линейного представления одинаково хорошо работает как с нормализованными, так и с "сырыми" данными. Но есть несколько нюансов.
Во-первых, в своей реализации мы использовали параметр минимально-необходимого отклонения значений временного ряда для фиксирования точки разворота тренда. Думаю, излишне говорить, что необходим тщательный подбор данного гиперпараметра для анализа каждого отдельного временного ряда. Использование алгоритма для анализа мультимодальных временных рядов, значения унитарных последовательностей которого находятся в различных распределениях, значительно усложняет данную задачу, а в большинстве случаев, делает невозможным использование одного гиперпараметра для всех анализируемых унитарных последовательностей.
Во-вторых, результаты PLR мы планируем использовать в моделях, эффективность которых значительно выше при использовании нормализованных исходных данных.
Конечно, мы можем использовать нормализацию результатов PLR перед передачей их модели, но и тут динамическое изменение количества сегментов усложняет задачу.
В то же время использование нормализации исходных данных перед подачей в слой кусочно-линейного представления значительно упрощает все указанные моменты. Приведение данных всех унитарных последовательностей к единому распределению позволяет использовать один гиперпараметр для анализа мультимодальных временных рядов. Более того, нормализация распределения исходных данных позволяет использовать усредненные гиперпараметры для совершенно различных исходных последовательностей.
Получив нормализованные данные на вход слоя, мы имеем нормализованные последовательности на выходе. Поэтому, следующим слоем нашей модели является слой пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Затем для работы в рамках унитарных последовательностей мы транспонируем исходные данные.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
Конечно, если говорить о нашей реализации алгоритма PLR, то вместо использования слоя транспонирования данных, более эффективным выглядит использование параметра транспонирования. Однако в данном случае, применение слоя транспонирования обусловлено дальнейшим построением архитектуры модели.
Далее подготовленные данные мы разделим на линейные сегменты.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPLROCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = int(false); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И воспользуемся 3 слойным MLP для прогнозирования отдельных унитарных последовательностей на заданный горизонт планирования.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = LatentCount; descr.step = LatentCount; descr.window_out = LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = LatentCount; descr.step = LatentCount; descr.window_out = NForecast; descr.optimization = ADAM; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Обратите внимание, что мы используем сверточные слои с неперекрывающимися окнами для организации условно-независимого прогнозирования значений отдельных унитарных последовательностей. Я использую определение "условно-независимого прогнозирования", так как при построении прогнозных траекторий всех унитарных последовательностей используются одни и те же матрицы весовых коэффициентов.
Прогнозные значения мы транспонируем в представление исходных данных.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
И добавляем к ним статистические параметры распределения, изъятые при нормализации исходных данных.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr*NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers=1; if(!encoder.Add(descr)) { delete descr; return false; }
На выходе модели мы воспользуемся наработками метода FreDF для согласования отдельных шагов построенных нами прогнозных унитарных последовательностей анализируемого временного ряда.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Таким образом, мы построили модель Энкодера окружающей среды, которая, по существу, объединяет PLR и MLP для прогнозирования временных рядов.
3. Тестирование
В практической части данной статьи мы реализовали алгоритм кусочно-линейного представления временных рядов (PLR). Предложенный алгоритм не содержит обучаемых параметров и подразумевает лишь преобразование анализируемого временного ряда в альтернативное представление. Мы так же представили довольно упрощенную модель прогнозирования временных рядов с использованием созданного слоя CNeuronPLROCL. И теперь пришло время оценить эффективность описанных подходов.
Для обучения модели Энкодера состояния окружающей среды прогнозированию последующих показателей анализируемого временного ряда, мы использовали обучающую выборку, собранную в рамках работы над предыдущей статьей.
Напомню, что для обучения моделей мы используем реальные исторические данные инcтрумента EURUSD тайм-фрейм H1, собранные за весь 2023 год. При обучении модели Энкодера состояния окружающей среды она работает только с историческими данными ценового движения и анализируемых индикаторов. Поэтому мы осуществляем обучение модели до получения желаемого результата, без необходимости обновления обучающей выборки.
Говоря об обучении модели, хочется отметить стабильность процесса. Модель обучается довольно быстро, без резких скачков ошибки прогнозирования.
В итоге, несмотря на относительную простоту модели, мы получили довольно неплохой результат. К примеру, ниже представлен сравнительный график целевого и прогнозного движения цены.
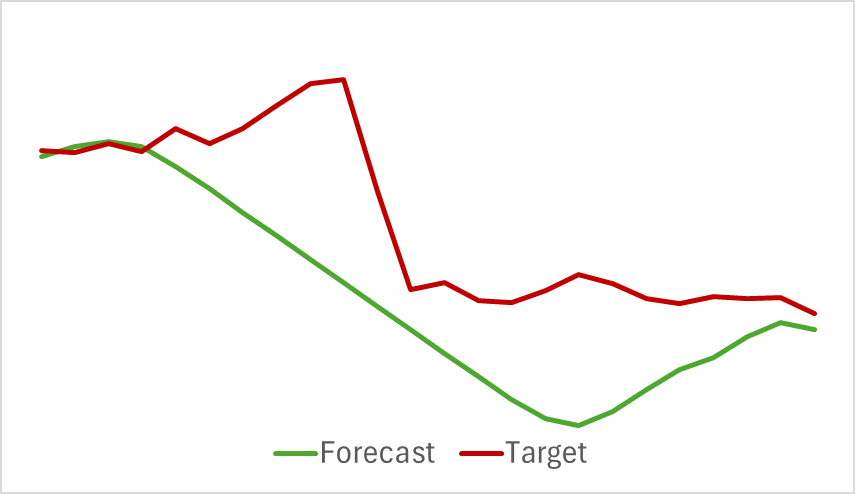
На графике видно, что модель смогла уловить основные тенденции предстоящего ценового движения. Довольно примечателен тот факт, что при горизонте прогнозирования 24 часа мы имеем довольно близкие значения в начале и конце прогнозной траектории. И только лишь импульс ценового движения прогнозной траектории более растянут по времени.
К этому можно добавить, что прогнозные траектории анализируемых индикаторов так же демонстрируют не плохие результаты. Ниже представлен график прогнозирования показателей индикатора RSI.
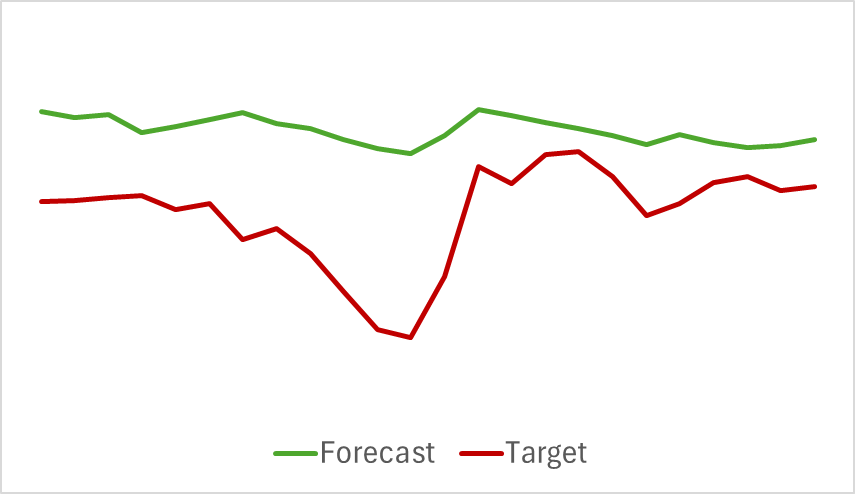
Прогнозные значения индикатора лежат несколько выше реальных значений и имеют меньшую амплитуду, но при этом можно заметить согласованность по времени и направлению основных импульсов.
Я бы хотел обратить внимание на тот факт, что представленные прогнозы ценового движения и показателей индикатора относятся к одному временному отрезку. И если сопоставить два представленных графика, то можно заметить, что основной импульс прогнозных и фактических значений индикаторов совпадает по времени с основным импульсом фактического ценового движения.
Заключение
В данной статье мы познакомились с методами альтернативного представления временных рядов в виде кусочно-линейного сегментирования. В практической части статьи был реализован один из вариантов предложенных подходов. А результаты проведенных экспериментов свидетельствуют об имеющемся потенциале рассмотренных подходов.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования