
Нейросети в трейдинге: Пространственно-временная нейронная сеть (STNN)

Введение
Прогнозирование временных рядов играет важную роль в различных областях, в том числе финансах. И мы уже привыкли, что во многие реальные системы позволяют измерять многомерные данные, которые содержат богатую информацию о динамике целевой переменной. Однако эффективный анализ и прогнозирование многомерных временных рядов сталкивается с проблемой "проклятия размерности". И тогда очень важным становится вопрос выбора окна анализируемых исторических данных. Ведь, довольно часто при использовании недостаточного окна анализируемых данных модель прогнозирования демонстрирует неудовлетворительную производительность и терпит неудачу.
Для исследования многомерной информации было разработано уравнение преобразования пространственно-временной информации (STI) на основе теоремы вложения с задержкой. STI преобразует пространственную информацию многомерных переменных в будущую временную информацию целевой переменной, что эквивалентно увеличению размера выборки и решает проблему краткосрочных данных.
Уже знакомые нам модели на основе архитектуры Transformer обрабатывают последовательность данных и изучают информацию при помощи механизма Self-Attention, моделируя взаимосвязь переменных без учета расстояния между ними. Механизмы внимания могут улавливать глобальную информацию и фокусироваться на важном содержимом, что помогает смягчить проклятие размерности.
Для решения задач прогнозирования временных рядов в статье "Spatiotemporal Transformer Neural Network for Time-Series Forecasting" была предложена модель пространственно-временного Transformer (STNN) для эффективного многоступенчатого прогнозирования многомерных краткосрочных временных рядов, используя преимущества уравнения STI и структуры Transformer.
Авторы метода выделяют следующие преимущества, предложенных подходов:
- STNN использует уравнение STI для преобразования пространственной информации многомерных переменных в информацию о временной эволюции целевой переменной, что эквивалентно увеличению размера выборки.
- Предложен механизм непрерывного внимания для повышения точности численного прогнозирования.
- Пространственная структура Self-Attention в STNN собирает эффективную пространственную информацию многомерных переменных, временная структура Self-Attention используется для сбора информации о временной эволюции, а структура Transformer объединяет пространственную и временную информацию.
- Модель STNN может реконструировать фазовое пространство динамической системы для прогнозирования временных рядов.
1. Алгоритм STNN
Целью модели STNN является эффективное решение нелинейного уравнения преобразования STI, путем обучения Transformer.
![]()
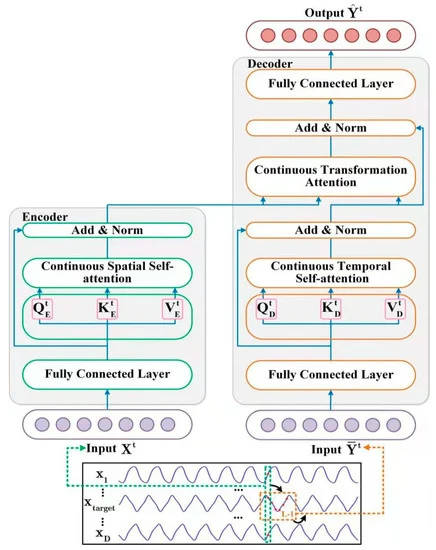
Модель STNN эксплуатирует уравнение преобразования STI и включает 2 специальных модуля внимания для выполнения прогнозирования на несколько шагов вперед. Как можно заметить в представленном выше уравнении, D-мерные исходные данные в момент времени t (Xt) подаются на вход Энкодера, который извлекает эффективную пространственную информацию из исходных переменных.
После этого эффективная пространственная информация передается в Декодер, который вводит временной ряд длиной L-1 из целевой переменной Y (𝐘t). Декодер извлекает информацию о временной эволюции целевой переменной. После чего прогнозирует будущие значения целевой переменной, путем объединения пространственной информации исходных переменных (𝐗t) и временной информации целевой переменной (𝐘t).
Обратите внимание, что целевая переменна является одной из переменных в многомерных исходных данных X.
Нелинейное преобразование STI решается парой Энкодер-Декодер. Энкодер состоит из 2 слоев. Первый является полносвязным слоем, а второй — непрерывным пространственным слоем Self-Attention. Авторы метода STNN используют непрерывный пространственный слой Self-Attention для извлечения эффективной пространственной информации из многомерных исходных данных 𝐗t.
Полносвязный слой используется для сглаживания исходных данных многомерного временного ряда 𝐗t и фильтрация шума. Нейроны данного слоя описываются следующим уравнением.
![]()
где WFFN — матрица коэффициентов,
bFFN — смещение,
ELU — функция активации.
Непрерывный пространственный слой Self-Attention принимает 𝐗t,FFN в качестве исходных данных. Так как слой Self-Attention принимает многомерный временной ряд, Энкодер может извлекать пространственную информацию из исходных данных. Для получения эффективной пространственной информации (SSAt), предлагается механизм непрерывного внимания пространственного слоя Self-Attention, работу которого можно описать следующим образом.
Вначале генерируются 3 матрицы обучаемых параметров (WQE, WKE и WVE), которые используются в слое непрерывного пространственного Self-Attention.
Затем, умножая исходные данные 𝐗t,FFN на выше указанные матрицы весов генерируются сущности Query, Key и Value непрерывного пространственного слоя Self-Attention.
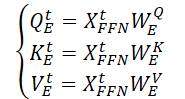
Выполняя матричное скалярное произведение, получаем выражение ключевой пространственной информации (SSAt) для исходных данных 𝐗t.
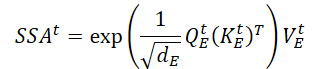
где dE — размерность матриц Query, Key и Value.
Авторы метода STNN акцентируют внимание, что в отличие от классического механизма дискретного вероятностного внимания, предложенный механизм непрерывного внимания может гарантировать бесперебойную передачу данных Энкодера.
На выходе Энкодера мы суммируем тензор ключевой пространственной информации со сглаженными исходных данными с последующей нормализацией данных, что позволяет предотвратить быстрое исчезновение градиента и ускорить скорость сходимости модели.
![]()
Декодер сочетает в себе эффективную пространственную информацию и временную эволюционную целевой переменной. В своей архитектуре он включает 2 полносвязных слоя, слой непрерывного временного Self-Attention и слоя внимания трансформации.
На вход Декодера подаются исходные данные исторической последовательности целевой переменной. Как и в случае Энкодера, эффективное представление исходных данных (𝐘t,FFN) получаем после фильтрации шума полносвязным слоем.
Далее полученные данные направляются в слой непрерывного временного Self-Attention, который фокусируется на исторической информации о временной эволюции между различными временными шагами целевой переменной. Поскольку влияние времени необратимо, мы определяем текущее состояние временного ряда, используя историческую информацию, но не будущую. Таким образом, слой непрерывного временного внимания использует механизм замаскированного внимания для отсеивания будущей информации. Рассмотрим подробнее данную операцию.
Сначала мы генерируем 3 матрицы обучаемых параметров (WQD, WKD и WVD), для временно-пространственного слоя Self-Attention. А затем посчитаем соответствующие матрицы сущностей Query, Key и Value.
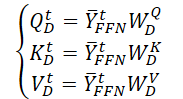
И выполняем матричное скалярное произведение для получения информации о временной эволюции целевой переменной на анализируемом отрезке истории.
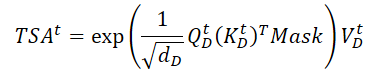
В отличии от Энкодера, здесь добавляется маска, которая обнуляет влияние последующих элементов анализируемых данных. Тем самым, мы не позволяем модели "заглядывать в будущее" при построении функции временной эволюции целевой переменной.
Далее мы используем остаточное соединение и нормализуем информацию о временной эволюции целевой переменной.
![]()
Слой внимания непрерывной трансформации для прогнозирования будущих значений целевой переменной объединяет информацию пространственных зависимостей (SSAt) с данными о временной эволюции целевой переменной (TSAt).
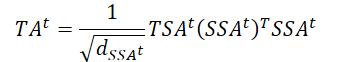
Здесь так же используются остаточные связи и нормализация данных.
![]()
На выходе Декодера авторы метода используют второй полносвязный слой для прогнозирования значений целевой переменной
![]()
При обучении модели STNN авторы метода использовали MSE в качестве функции потерь и L2 регуляризацию параметров.
Авторская визуализация метода представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода STNN мы переходим к практической части нашей статьи, в которой рассмотрим один из вариантов реализации предложенных подходов средствами MQL5.
Как обычно, в рамках данной статьи будет представлено собственное видение реализации, которое может отличаться от авторской реализации метода. Более того, в рамках данной реализации мы постарались максимально использовать имеющиеся у нас наработки, что несколько отдалило нас от авторского метода. Об этом мы поговорим в процессе реализации предложенных подходов.
Как Вы уже заметили из представленного выше теоретического описания алгоритма STNN, он включает 2 основных блока: Энкодер и Декодер. Свою работу мы так же разделим на реализацию 2 соответствующих классов. А начнем мы работу с реализации Энкодера.
2.1 Энкодер STNN
Алгоритмы работы Энкодера мы реализуем в рамках класса CNeuronSTNNEncoder. Авторы метода внесли некоторые корректировки в алгоритм Self-Attention. Тем не менее, он остается довольно узнаваем и включает базовые компоненты классического подхода. Поэтому, для реализации нового класса мы воспользуемся уже имеющимися наработками и унаследуем основной функционал базового алгоритма Self-Attention из класса CNeuronMLMHAttentionMLKV. Общая структура нового класса представлена ниже.
class CNeuronSTNNEncoder : public CNeuronMLMHAttentionMLKV { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSTNNEncoder(void) {}; ~CNeuronSTNNEncoder(void) {}; //--- virtual int Type(void) override const { return defNeuronSTNNEncoder; } };
Как можно заметить, в рамках нового класса отсутствует объявление новых переменных и объектов. Более того, в представленной структуре отсутствует даже переопределение методов инициализации объекта. И тому есть свои причины. Как уже было сказано выше, мы максимально эксплуатируем имеющиеся у нас наработки.
Для начала, давайте посмотрим на отличия предложенных подходов от реализованных нами ранее. Прежде всего, авторы метода STNN поместили полносвязный слой перед блоком Self-Attention. Технически, это не проблема объявления объектов, а только реализации алгоритмов прямого и обратного проходов. Значит реализация этого момента не отражается на алгоритме метода инициализации.
Второй момент заключается в том, что авторы метода STNN предусмотрели только один полносвязный слой. В классическом же подходе создается блок из 2 полносвязных слоев. Мое личное мнение, что использование блока из 2 полносвязных слоев, конечно, увеличивает затраты вычислительных ресурсов, но не снижает качества работы модели. И в качестве эксперимента для максимального сохранения имеющихся наработок мы можем использовать 2 слоя вместо 1.
Кроме того, авторы метода отказались от использования функции SoftMax для нормализации коэффициентов внимания. Вместо этого применяется простая экспонента произведения матриц Query и Key. На мой взгляд, отличие SoftMax лишь в нормализации данных и более сложном вычислении. И в своей реализации я рискну использовать уже реализованный подход с SoftMax.
Далее мы переходим к реализации алгоритмов прямого прохода. И здесь я обратил внимание на тот момент, что авторы метода внедрили маскирование последующих элементов только в Декодере. При этом мы помним, что целевая переменная может входить в набор исходных данных Энкодера. И здесь наблюдается некоторая алогичность. Но все "становится на свои места" после пристального изучения авторской визуализации метода.
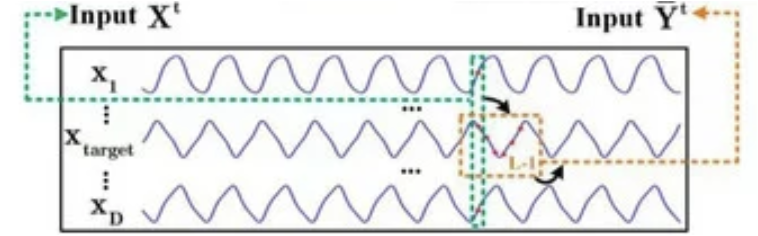
Исходные данные Энкодера находятся на некотором отдалении от анализируемого состояния. Не могу судить о причинах, по которым авторы метода выбрали такую реализацию. Но мое личное мнение, что использование полной информации, имеющейся на момент анализа данных, даст нам больше информации и потенциально повысит качество наших прогнозов. Поэтому в своей реализации я сдвигаю исходные данные Энкодера к текущему моменту и добавляю маску исходных данных, что позволит анализировать зависимости только с предшествующими данными.
Для реализации маскирования данных нам необходимо внести изменения в программу OpenCL. И здесь мы внесем лишь небольшие правки в кернел MH2AttentionOut. Мы не будем использовать дополнительный буфер маскирования. Мы поступим гораздо проще. Добавим лишь 1 константу, которая будет определять необходимость применения маски. А маскирование организуем непосредственно в алгоритме кернела.
__kernel void MH2AttentionOut(__global float *q, __global float *kv, __global float *score, __global float *out, int dimension, int heads_kv, int mask ///< 1 - calc only previous units, 0 - calc all ) { //--- init const int q_id = get_global_id(0); const int k = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_global_size(1); const int heads = get_global_size(2); const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_k = dimension * (2 * heads_kv * k + h_kv); const int shift_v = dimension * (2 * heads_kv * k + heads_kv + h_kv); const int shift_s = kunits * (q_id * heads + h) + k; const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); float koef = sqrt((float)dimension); if(koef < 1) koef = 1; __local float temp[LOCAL_ARRAY_SIZE];
В теле кернела мы внесем лишь точечные правки при вычислении суммы экспонент.
//--- sum of exp uint count = 0; if(k < ls) { temp[k] = 0; do { if(mask == 0 || q_id <= (count * ls + k)) if((count * ls) < (kunits - k)) { float sum = 0; int sh_k = 2 * dimension * heads_kv * count * ls; for(int d = 0; d < dimension; d++) sum = q[shift_q + d] * kv[shift_k + d + sh_k]; sum = exp(sum / koef); if(isnan(sum)) sum = 0; temp[k] = temp[k] + sum; } count++; } while((count * ls + k) < kunits); } barrier(CLK_LOCAL_MEM_FENCE); count = min(ls, (uint)kunits);
Здесь мы добавим условия и будем вычислять экспоненты только для предшествующих элементов. И здесь обратите внимание, что при создании исходных данных для модели мы формируем их из таймсерий исторических данных ценового движения и индикаторов. А в них текущий бар имеет индекс "0". Поэтому для маскирования элементов в исторической хронологии мы обнуляем коэффициенты зависимости всех элементов, индекс которых меньше анализируемого Query. Это мы видим при вычислении суммы экспонент и коэффициентов зависимости (в коде выделено подчеркиванием).
//--- do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- score float sum = temp[0]; float sc = 0; if(mask == 0 || q_id >= (count * ls + k)) if(sum != 0) { for(int d = 0; d < dimension; d++) sc = q[shift_q + d] * kv[shift_k + d]; sc = exp(sc / koef) / sum; if(isnan(sc)) sc = 0; } score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
В остальном код кернела остался неизменным.
//--- out for(int d = 0; d < dimension; d++) { uint count = 0; if(k < ls) do { if((count * ls) < (kunits - k)) { float sum = kv[shift_v + d] * (count == 0 ? sc : score[shift_s + count * ls]); if(isnan(sum)) sum = 0; temp[k] = (count > 0 ? temp[k] : 0) + sum; } count++; } while((count * ls + k) < kunits); barrier(CLK_LOCAL_MEM_FENCE); //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- out[shift_q + d] = temp[0]; } }
Обратите внимание, что при такой реализации мы просто обнулили коэффициенты зависимости последующих элементов. Это позволило нам организовать маскирование с минимальными правками кернела прямого прохода. И более того, такой подход не требует корректировки кернелов обратного прохода. Так как "0" в коэффициенте зависимости просто обнулит градиент ошибки на такие элементы последовательности.
Должен сказать, что на этом мы завершаем работу на стороне программы OpenCL в рамках данной реализации и переходим к работе над нашим классом в основной программе.
Здесь мы сначала организуем вызов выше скорректированного кернела в методе CNeuronSTNNEncoder::AttentionOut. Алгоритм метода постановки кернела в очередь выполнения остается прежним и, думаю, будет излишним его повторять в каждой статье. С его кодом Вы можете самостоятельно ознакомиться во вложении. Хочется лишь обратить внимание на указание "1" в параметр def_k_mh2ao_mask для выполнения маскирования данных.
Следующим этапом мы переходим к реализации метода прямого прохода нашего нового класса. И здесь мы вынуждены переопределить метод для перенесения блока FeedForward перед Self-Attention. Так же следует обратить внимание, что в отличии от классического Transformer, блок FeedForward лишен остаточных связей и нормализации данных.
Перед тем как приступить к реализации алгоритма, так же следует вспомнить, что для исключения излишнего копирования данных в методе инициализации родительского класса мы подменили указатели буферов результатов нашего слоя и градиентов ошибки аналогичными буферами последнего слоя FeedForward. И здесь мы воспользуемся тем свойством, что размеры буферов результатов блока внимания и FeedForward имеют аналогичные размеры. Поэтому мы просто изменим нумерацию при обращении к соответствующим буферам данных.
А теперь посмотрим на нашу реализацию. Как и ранее, в параметрах метода мы получаем указатель на объект предшествующего слоя, который нам передает исходные данные.
bool CNeuronSTNNEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
И сразу в теле метода мы проверяем актуальность полученного указателя. После чего переходим непосредственно к построению алгоритма прямого прохода. Здесь следует обратить внимание на ещё одно отличие нашей реализации. Авторы метода STNN в своей работе не указывают ни на количество слоев Энкодера, ни на количество голов внимания. Исходя из представленной выше визуализации и описания метода можно сделать предположение о наличие только 1 головы внимания в 1 слое Энкодера. В своей же реализации мы оставим классический подход с использованием многоголового внимания в многослойной архитектуре. И далее мы организуем цикл перебора вложенных слоев Энкодера.
В теле цикла, как уже было сказано ранее, исходные данные сначала проходят через блок FeedForward, где осуществляется сглаживание и фильтрация данных.
CBufferFloat *kv = NULL; for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Feed Forward CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(6 * i - 4)); CBufferFloat *temp = FF_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; inputs = FF_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), temp, inputs, 4 * iWindow, iWindow, None)) return false;
После чего мы определим матрицы сущностей Query, Key и Value.
//--- Calculate Queries, Keys, Values CBufferFloat *q = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, q, iWindow, iWindowKey * iHeads, None)) return false; if((i % iLayersToOneKV) == 0) { uint i_kv = i / iLayersToOneKV; kv = KV_Tensors.At(i_kv * 2); if(IsStopped() || !ConvolutionForward(KV_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, kv, iWindow, 2 * iWindowKey * iHeadsKV, None)) return false; }
Обратите внимание, что в данном случае мы используем подходы метода MLKV, унаследованные от родительского класса, что позволяет использовать один буфер Key-Value для нескольких голов внимания и слоев Self-Attention.
На основании полученных сущностей определим коэффициенты зависимости с учетом маскирования данных.
//--- Score calculation and Multi-heads attention calculation temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
И посчитаем результат слоя внимания с учетом остаточных связей и нормализации данных.
//--- Attention out calculation temp = FF_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9)), out, temp, iWindowKey * iHeads, iWindow, None)) return false; //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow, true)) return false; } //--- return true; }
После чего мы переходим к следующему вложенному слою. А при их исчерпании, завершаем работу метода.
Аналогичным образом, но в обратном порядке мы строим алгоритм метода распределения градиента ошибки CNeuronSTNNEncoder::calcInputGradients. В параметрах метод так же получает указатель на объект предшествующего слоя, только на этот раз нам предстоит передать в него градиент ошибки, соответствующий влиянию исходных данных на конечный результат работы модели.
bool CNeuronSTNNEncoder::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false; //--- CBufferFloat *out_grad = Gradient; CBufferFloat *kv_g = KV_Tensors.At(KV_Tensors.Total() - 1);
В теле метода мы, как и ранее, проверяем корректность полученного указателя. И объявляем локальные переменные для временного хранения указателей на объекты рабочих буферов данных.
Далее мы объявляем цикл обратного перебора вложенных слоев Энкодера.
for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) kv_g = KV_Tensors.At((i / iLayersToOneKV) * 2 + 1); //--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 6 : 9)), out_grad, AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iWindowKey * iHeads, iWindow, None)) return false;
В теле цикла мы сначала распределим градиент ошибки, полученный от последующего слоя, между головами внимания. После чего определим погрешность на уровне сущностей Query, Key и Value.
//--- Passing gradient to query, key and value if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), KV_Tensors.At((i / iLayersToOneKV) * 2), kv_g, S_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1))) return false; } else { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), KV_Tensors.At((i / iLayersToOneKV) * 2), GetPointer(Temp), S_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1))) return false; if(IsStopped() || !SumAndNormilize(kv_g, GetPointer(Temp), kv_g, iWindowKey, false, 0, 0, 0, 1)) return false; }
Обратите внимание на разветвление алгоритма, что связано с различными подходами распределения градиента ошибки до тензора Key-Value в зависимости от текущего слоя.
Далее мы передаем градиент ошибки от сущности Query на блок FeedForward с учетом остаточных связей.
CBufferFloat *inp = FF_Tensors.At(i * 6); CBufferFloat *temp = FF_Tensors.At(i * 6 + 3); if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, iWindowKey * iHeads, None)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
И при необходимости добавим погрешность влияние на сущности Key и Value.
if((i % iLayersToOneKV) == 0) { if(IsStopped() || !ConvolutionInputGradients(KV_Weights.At(i / iLayersToOneKV * (optimization == SGD ? 2 : 3)), kv_g, inp, GetPointer(Temp), iWindow, 2 * iWindowKey * iHeadsKV, None)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(Temp), temp, temp, iWindow, false, 0, 0, 0, 1)) return false; }
И опустим градиент ошибки через блок FeedForward.
//--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), out_grad, FF_Tensors.At(i * 6 + 1), FF_Tensors.At(i * 6 + 4), 4 * iWindow, iWindow, None)) return false; inp = (i > 0 ? FF_Tensors.At(i * 6 - 4) : prevLayer.getOutput()); temp = (i > 0 ? FF_Tensors.At(i * 6 - 1) : prevLayer.getGradient()); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), FF_Tensors.At(i * 6 + 4), inp, temp, iWindow, 4 * iWindow, LReLU)) return false; out_grad = temp; } //--- return true; }
Итерации цикла повторяются до полного перебора всех вложенных слоев и завершаются передачей градиента ошибки на уровень предшествующего слоя.
После распределения градиента ошибки нам остается оптимизировать параметры модели в сторону минимизации общей ошибки прогнозирования. Данные операции реализованы в методе CNeuronSTNNEncoder::updateInputWeights. Его алгоритм полностью повторяет аналогичный метод родительского класса. Различие лишь в указании буферов данных. Поэтому мы не будем сейчас детально останавливаться на его рассмотрении. И я предлагаю Вам самостоятельно ознакомиться с ним во вложении. Там же Вы найдете полный код класса Энкодера и всех его методов.
2.2 Декодер STNN
После реализации Энкодера мы переходим ко 2 части нашей работы, в которой реализуем алгоритм Декодера метода STNN. И здесь мы будем придерживаться тех же принципов, которыми пользовались при построении Энкодера. В частности, в рамках данной реализации мы будем максимально использовать ранее созданные наработки.
И приступая к реализации алгоритмов нашего Декодера следует обратить внимание, что в отличии от Энкодера, новый класс мы будем наследовать от объектов кросс-внимания. Ведь в данном слое нам предстоит сопоставить пространственную и временную информацию. Полная структура нового класса представлена ниже.
class CNeuronSTNNDecoder : public CNeuronMLCrossAttentionMLKV { protected: CNeuronSTNNEncoder cEncoder; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override; virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override; public: CNeuronSTNNDecoder(void) {}; ~CNeuronSTNNDecoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint window_kv, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronSTNNDecoder; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Обратите внимание, что в данном классе мы объявляем вложенный объект выше созданного Энкодера. Однако должен сразу сказать, что в данном случае он несет несколько иную смысловую нагрузку.
Если обратиться к представленному в 1 части данной статьи теоретическому описанию метода, то можно заметить сходство между блоками выявления пространственных и временных связей. Различия лишь в анализируемых исходных данных. В блоке пространственных связей анализируется большое количество параметров на малом временном отрезке. В блоке меж временных зависимостей анализируется целевая переменная на отдельном историческом отрезке. Алгоритмы же довольно схожи. Поэтому в данном случае мы используем вложенный Энкодер для выявления меж временных зависимостей целевой переменной.
Но вернемся к описанию алгоритмов наших методов. Объявление дополнительного вложенного объекта, даже статического, требует от нас переопределения метода инициализации класса Init. Тем не менее, наше стремлении максимально использовать созданные ранее наработки дает свои "плоды". Новый метод инициализации максимально простой.
bool CNeuronSTNNDecoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint window_kv, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!cEncoder.Init(0, 0, open_cl, window, window_key, heads, heads_kv, units_count, layers, layers_to_one_kv, optimization_type, batch)) return false; if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, window_kv, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false; //--- return true; }
Здесь мы лишь вызываем одноименные методы вложенного Энкодера и родительского класса с использованием одинаковых значений для одноименных параметров. Нам остается лишь проверить результат выполнения операций и вернуть полученное логическое значение вызывающей программе.
Аналогичный подход наблюдается и в методах прямого и обратного прохода. К примеру, в методе прямого прохода мы сначала вызываем одноименный метод Энкодера для выявления меж временных зависимостей между значениями целевой переменной. А затем сопоставим полученные меж временные зависимости с меж пространственными, которые получены от Энкодера модели STNN в параметрах контекста данного метода. Данная операция выполняется средствами прямого прохода, унаследованными от родительского класса.
bool CNeuronSTNNDecoder::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) { if(!cEncoder.FeedForward(NeuronOCL, Context)) return false; if(!CNeuronMLCrossAttentionMLKV::feedForward(cEncoder.AsObject(), Context)) return false; //--- return true; }
Здесь следует обратить на несколько моментов, где мы сделали отступление от алгоритма, предложенного авторами метода STNN. Мы сохранили в целом предложенную концепцию, но сделали довольно "большой шаг в сторону" в средствах реализации предложенных подходов.
И так мы сохранили:
- Выявление меж временных зависимостей;
- Сопоставление меж временных и меж пространственных зависимостей для целей прогнозирования значений целевой переменной.
Однако, как и в случае Энкодера, мы используем блок FeedForward из 2 полносвязных слоев вместо 1 слоя, предложенного авторами метода. Это касается как фильтрации данных перед выявлением меж временных зависимостей, так и прогнозирования значений целевой переменной на выходе Декодера.
Кроме того, для реализации кросс-внимания мы использовали прямой проход родительского класса, в котором реализован алгоритм классического многослойного кросс-внимания с остаточными связями блоков внимания и FeedForward. А это отличается от алгоритма кросс-внимания, предложенного авторами метода STNN.
Тем не менее, на мой взгляд, такая реализация имеет место быть, особенно с учетом эксперимента максимального использования созданных ранее наработок.
Так же хочется обратить внимание на тот момент, что, несмотря на использование многослойной структуры в блоках выявления меж временных зависимостей и кросс-внимания, общая архитектура Декодера приобретает однослойный характер. Иными словами, мы сначала выявляем меж временные зависимости в многослойном вложенном Энкодере. После чего многослойный блок кросс-внимания сопоставляет меж временные и меж пространственные зависимости перед прогнозированием значений целевой переменной.
Аналогичным образом построены и методы обратного прохода. Но мы не будем сейчас на них останавливаться. Я предлагаю Вам самостоятельно ознакомиться с ними во вложении.
На этом мы завершаем рассмотрение архитектуры и алгоритмов новых объектов. Их полный код ожидает Вас во вложении к данной статье.
2.3 Архитектура моделей
После рассмотрения алгоритмов реализации предложенных подходов метода STNN мы переходим к их практическому использованию в обучаемых моделях. И здесь следует обратить внимание, что Энкодер и Декодер в предложенном алгоритме оперируют с различными исходными данными. Это побудило нас выделить их в отдельные модели, архитектура которых представлена в методе CreateStateDescriptions.
В параметрах указанного метода мы будем передавать 2 указателя динамических массивов, для записи архитектуры соответствующих моделей.
bool CreateStateDescriptions(CArrayObj *&encoder, CArrayObj *&decoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } //--- if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; }
В теле метода мы проверяем полученные указатели и, при необходимости, создаем новые экземпляры массивов.
На вход Энкодера мы будем подавать уже привычный нам набор не обработанных данных.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Первичная обработка которых осуществляется в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
После чего мы добавляем слой Энкодера STNN.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSTNNEncoder; descr.count = HistoryBars; descr.window = BarDescr; descr.window_out = 32; descr.layers = 4; descr.step = 2; { int ar[] = {8, 4}; if(ArrayCopy(descr.heads, ar) < (int)ar.Size()) return false; } descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь мы используем 4 вложенных слоя Энкодера, каждый из которых использует 8 голов внимания сущностей Query и 4 для тензора Key-Value. Кроме того, один тензор Key-Value используется для 2 вложенных слоев Энкодера.
И на этом завершается архитектура модели Энкодера. Результаты её работы мы будем использовать в Декодере.
На вход Декодера мы подаем исторические значения целевой переменной, глубина анализируемой истории которых соответствует нашему горизонту планирования.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (NForecast * ForecastBarDescr); descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Здесь мы так же используем необработанные данные, которые подаются в слой пакетной нормализации данных.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
А далее следует слой Декодера STNN, архитектура которого так же насчитывает по 4 вложенных слоя меж временного и кросс-внимания.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSTNNDecoder; { int ar[] = {NForecast, HistoryBars}; if(ArrayCopy(descr.units, ar) < (int)ar.Size()) return false; } { int ar[] = {ForecastBarDescr, BarDescr}; if(ArrayCopy(descr.windows, ar) < (int)ar.Size()) return false; } { int ar[] = {8, 4}; if(ArrayCopy(descr.heads, ar) < (int)ar.Size()) return false; } descr.window_out = 32; descr.layers = 4; descr.step = 2; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
На выходе Декодера мы ожидаем получить прогнозные значения целевой переменной. Добавим к ним статистические показатели, изъятые в слое пакетной нормализации.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = ForecastBarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!decoder.Add(descr)) { delete descr; return false; }
И согласуем частотные характеристики прогнозного временного ряда.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = ForecastBarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
Архитектура моделей Актера и Критика перенесена без изменений из предыдущих статей и представлена методе CreateDescriptions, который Вы найдете во вложении к данной статье (файл "...\Experts\STNN\Trajectory.mqh").
2.4 Программы обучения моделей
Разделение Энкодера состояния окружающей среды на 2 модели потребовало внесение изменений и в программы обучения моделей. И надо сказать, что, помимо разделения алгоритма на 2 модели, здесь есть изменения в блоке подготовки исходных данных и целевых значений. Внесенные корректировки мы рассмотрим на примере советника обучения Энкодера состояния окружающей среды "...\Experts\STNN\StudyEncoder.mq5".
Напомню, что в рамках данного советника мы обучаем модель прогнозирования предстоящего ценового движения на некоторый горизонт планирования, достаточный для принятия торгового решения в отдельный момент времени.
В рамках данной статьи мы не будем подробно останавливаться на всех процедурах программы, рассмотрим лишь метод обучения моделей Train. Здесь мы сначала определяем вероятности выбора траекторий из буфера воспроизведения опыта в соответствии с их фактической результативностью на реальных исторических данных.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; matrix<float> mstate = matrix<float>::Zeros(1, NForecast * ForecastBarDescr); bool Stop = false;
И объявляем необходимый минимум локальных переменных. После чего организовываем цикл непосредственного обучения моделей. Количество итераций цикла определяется пользователем во внешних параметрах советника.
uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum() == 0) { iter--; continue; }
В теле цикла мы сэмплируем траекторию и состояние на ней для осуществления итераций оптимизации модели. Сначала мы осуществляем выявление меж пространственных зависимостей между анализируемыми переменными путем вызова метода прямого прохода нашего Энкодера.
bStateE.AssignArray(state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bStateE), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее мы подготовим исходные данные Декодеру. В общем случае мы исходим из того, что горизонт планирования меньше глубины анализируемой истории. Поэтому мы сначала перенесем исторические данные анализируемого состояния окружающей среды в матрицу. Изменим её размер таким образом, чтобы каждая строка матрицы представляла данные одного бара исторических данных. И обрежем матрицу. Количество строк полученной матрицы должно соответствовать горизонту планирования. А количество столбцов — целевым переменным.
mstate.Assign(state); mstate.Reshape(HistoryBars, BarDescr); mstate.Resize(NForecast, ForecastBarDescr); bStateD.AssignArray(mstate);
Здесь следует обратить внимание, что при подготовке обучающей выборки для каждого бара мы вначале записывали параметры ценового движения. Их мы и будем планировать. Поэтому берем первые столбцы матрицы.
Значения полученной матрицы мы переносим в буфер данных и осуществляем прямой проход Декодера.
if(!Decoder.feedForward((CBufferFloat*)GetPointer(bStateD), 1, false, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
После осуществления прямого прохода нам предстоит осуществить оптимизацию параметров модели. Для этого нам необходимо подготовить целевые значения, прогнозируемых переменных. Данную операцию мы осуществляем аналогично подготовке исходных данных Декодера, только операции осуществляем с последующими историческими значениями.
//--- Collect target data mstate.Assign(Buffer[tr].States[i + NForecast].state); mstate.Reshape(HistoryBars, BarDescr); mstate.Resize(NForecast, ForecastBarDescr); if(!Result.AssignArray(mstate)) continue;
И осуществляем обратный проход Декодера. Здесь мы оптимизируем параметры Декодера и передаем градиент ошибки Энкодеру.
if(!Decoder.backProp(Result, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
После чего оптимизируем параметры Энкодера.
if(!Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
И теперь нам остается проинформировать пользователя о ходе выполнения процесса обучения и перейти к следующей итерации цикла обучения.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После успешного завершения всех итераций обучения мы выводим в журнал результаты обучения моделей и инициализируем процесс завершения работы программы.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Decoder", Decoder.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем рассмотрение алгоритмов обучения моделей. А с полным кодом всех программ, используемых при подготовке данной статьи, Вы можете ознакомиться во вложении.
3. Тестирование
В данной статье мы познакомились с новым методом прогнозирования временных рядов на основе пространственно-временной информации STNN. Реализовали свое видение предложенных подходов средствами MQL5. И теперь пришло время оценить результаты наших трудов.
Как обычно, для обучения наших моделей мы будем использовать исторические данные инструмента EURUSD таймфрейм H1 за весь 2023 год. После чего проведем тестирование обученных моделей в тестере стратегий MetaTrader 5 на данных Января 2024 года. Не сложно заметить, что период тестирования следует непосредственно за периодом обучения. Такой подход максимально приближает нас к реальным условиям эксплуатации моделей.
Для обучения модели прогнозирования последующего ценового движения мы используем обучающую выборку, собранную при подготовке предыдущих статей данной серии. Как Вы знаете, обучение данной модели происходит только на анализе исторических данных ценового движения и показателей анализируемых индикаторов. Действия Агента не оказывают влияние на анализируемые данные, что позволяет обучать модель Энкодера состояния окружающей среды без периодического обновления обучающей выборки.
Мы продолжаем процесс обучения модели до стабилизации ошибки прогнозирования. К сожалению, на данном этапе нас ожидало разочарование. Наша модель не смогла дать желаемый прогноз предстоящего ценового движения, указав лишь общее направление тенденции.
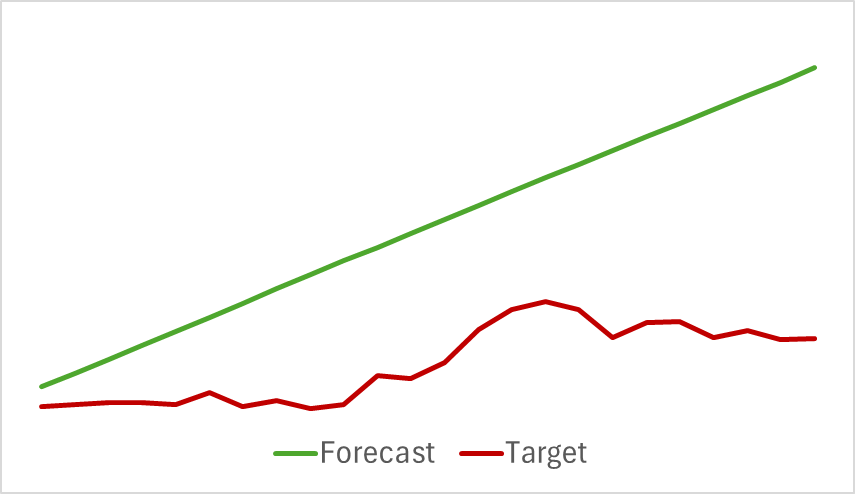
Конечно, несмотря на видимую прямолинейность прогнозного движения, в оцифрованных значениях есть колебания. Но они столь незначительны, что не визуализируются на графике. И здесь возникает вопрос: достаточно ли их для построения прибыльной стратегии нашим Актером?
Обучение моделей Актера и Критика мы осуществляем итерационно с периодическим обновлением обучающей выборки. Как Вы знаете, периодическое обновление обучающей выборки нам необходимо для более точной оценки действий Актера при смещении его политики в процессе обучения.
К сожалению, нам не удалось обучить политику Актера, способную генерировать устойчивую прибыль на тестовой выборке.
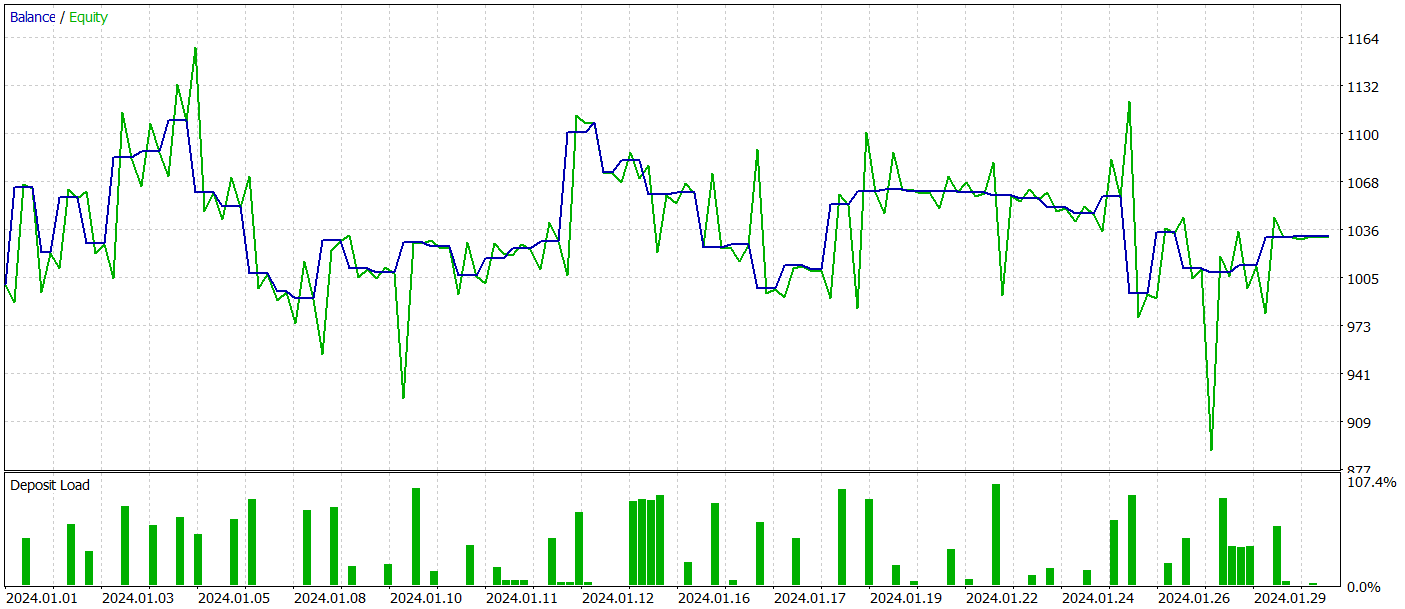
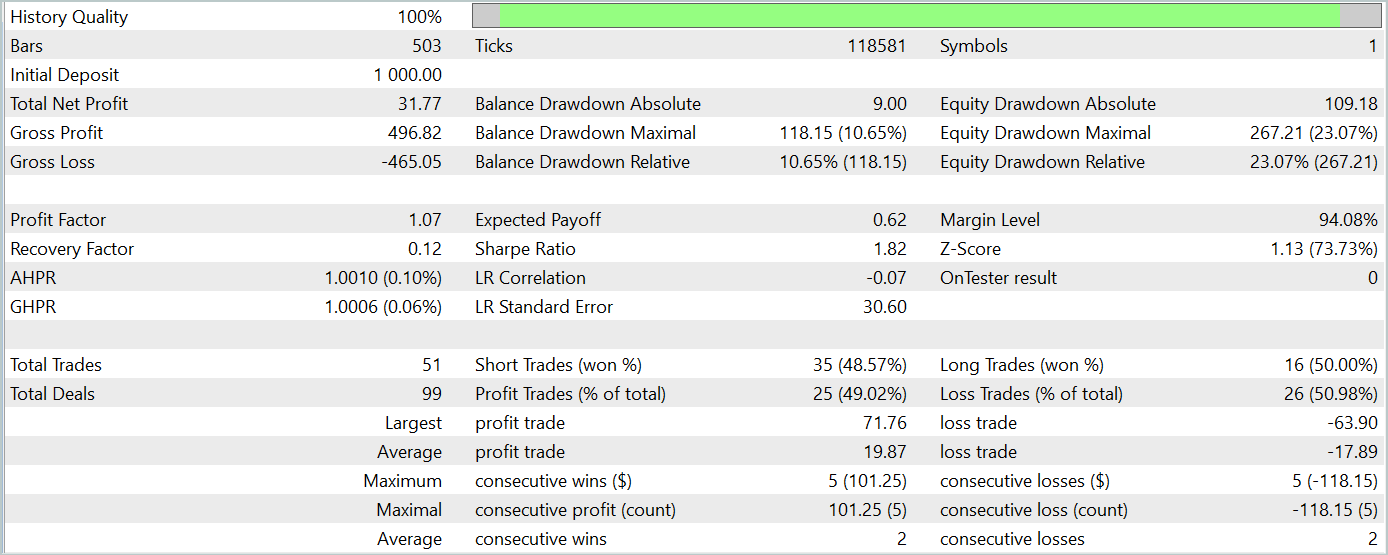
И, конечно, мы признаем, что в процессе реализации были допущены значительные отклонения от авторской реализации метода. И это могло сказаться на полученных результатах.
Заключение
В данной статье мы познакомились с ещё одним подходом к прогнозированию временных рядов, на основе нейронной сети пространственно-временного Transformer (STNN). Данная модель сочетает преимущества уравнения преобразования пространственно-временной информации (STI) и структуры Transformer для эффективного многоступенчатого прогнозирования краткосрочных временных рядов.
STNN использует уравнение STI, которое преобразует пространственную информацию многомерных переменных во временную информацию целевой переменной. Что эквивалентно увеличению размера выборки и помогает решить проблему недостаточности краткосрочных данных.
Для повышения точности численного прогнозирования в STNN был предложен механизм непрерывного внимания, который позволяет модели лучше учитывать важные аспекты данных.
В практической части статьи мы реализовали свое видение предложенных подходов средствами MQL5. Однако в своей реализации мы допустили значительные отклонения от авторского алгоритма, что могло сказаться на полученных результатах экспериментов.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Парадигмы программирования (Часть 2): Объектно-ориентированный подход к разработке советника на основе ценовой динамики
Парадигмы программирования (Часть 2): Объектно-ориентированный подход к разработке советника на основе ценовой динамики
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования