
Применение теории игр в алгоритмах трейдинга

В условиях, где скорость принятия решений критична, а рынок характеризуется высокой степенью неопределённости, требуется иной подход к созданию торговых систем.
AdaptiveQ Enhanced — торговый советник, разработанный на основе методов глубокого обучения с подкреплением (DQN), теории игр и причинно-следственного анализа. Советник анализирует рынок, моделируя 531 441 уникальное состояние, учитывая взаимосвязи между семью основными валютными парами. Ключевым элементом алгоритма является равновесие Нэша, применяемое для выбора оптимальной стратегии в условиях взаимного влияния инструментов.
В новой версии системы реализован расширенный набор действий: помимо стандартных операций покупки и продажи, добавлены функции наращивания позиции и выборочного закрытия прибыльных сделок. Это обеспечивает адаптивность и гибкость в различных рыночных сценариях. В статье рассматривается практическая реализация этих подходов на языке MQL5 и демонстрируется, как сочетание адаптивного обучения, теории игр и ИИ позволяет строить более точные и устойчивые торговые стратегии.
Теоретические основы: от обучения с подкреплением к равновесию Нэша
Глубокое обучение с подкреплением (DQN)
Прежде чем погружаться в технические аспекты кода, давайте заложим теоретический фундамент. В основе нашей системы лежит глубокое Q-обучение (Deep Q-Network, DQN) — современная версия алгоритма обучения с подкреплением, который доказал свою эффективность не только в играх, но и в решении сложных финансовых задач.
В классическом обучении с подкреплением агент (в нашем случае — торговая система) взаимодействует с окружающей средой (рынком), выполняя определенные действия (открытие/закрытие позиций). За каждое действие агент получает вознаграждение и переходит в новое состояние. Цель агента — максимизировать совокупное вознаграждение с течением времени.
Математически это выражается через Q-функцию, которая оценивает ожидаемую полезность действия a в состоянии s:
Q(s, a) = r + γ max Q(s', a')
где r — немедленное вознаграждение, γ — фактор дисконтирования (насколько мы ценим будущие вознаграждения), s' — новое состояние, а a' — возможные действия в новом состоянии.
Теория игр и равновесие Нэша
Традиционные торговые системы рассматривают каждый инструмент изолированно. Наш подход принципиально иной: мы применяем теорию игр, чтобы учитывать взаимосвязи между валютными парами.
Равновесие Нэша — это состояние, в котором ни один игрок не может улучшить свой результат, односторонне изменив свою стратегию. В контексте нашей системы это означает, что мы находим оптимальную стратегию для каждой валютной пары с учетом стратегий всех остальных пар.
В коде это реализовано через функцию DetermineActionNash(), которая теперь работает с расширенным пространством из шести возможных действий. Каждое действие оценивается не только на основе данных конкретной валютной пары, но и с учетом корреляций с другими инструментами:
void DetermineActionNash(int symbolIdx) { double actionScores[TOTAL_ACTIONS]; // Получаем базовые оценки действий из Q-матрицы for(int action = 0; action < TOTAL_ACTIONS; action++) { actionScores[action] = qMatrix[tradeStates[symbolIdx].currentStateIdx][action][symbolIdx]; } // Корректировка на основе корреляции с другими символами (Нэш) for(int otherIdx = 0; otherIdx < TOTAL_SYMBOLS; otherIdx++) { if(otherIdx != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherIdx]; for(int action = 0; action < TOTAL_ACTIONS; action++) { double otherScore = qMatrix[tradeStates[otherIdx].currentStateIdx][action][otherIdx]; // Учитываем корреляцию только если есть значимая связь if(MathAbs(corr) > 0.3) { actionScores[action] += corr * otherScore * 0.05; } } } }
Обратите внимание на тонкую настройку — корреляция учитывается, только если её абсолютное значение превышает 0.3. Это позволяет отфильтровать "шум" и сосредоточиться на действительно значимых взаимосвязях между валютными парами.
Причинно-следственный вывод в многомерном пространстве действий
В обновленной версии AdaptiveQ Enhanced наша система получила расширенный арсенал возможных действий:
- Открытие позиции Buy
- Открытие позиции Sell
- Добавление объёма к существующим позициям Buy
- Добавление объёма к существующим позициям Sell
- Закрытие только прибыльных позиций Buy
- Закрытие только прибыльных позиций Sell
Это существенно обогащает стратегический потенциал системы. Теперь она может не только открывать и закрывать позиции, но и наращивать объемы при развитии тренда в нужном направлении, а также избирательно фиксировать прибыль, оставляя убыточные позиции открытыми в ожидании разворота рынка.
Особенно интересно реализовано закрытие только прибыльных позиций — этот механизм позволяет системе фиксировать прибыль, не реализуя убытки, что существенно улучшает общую доходность:
void ClosePositionsByTypeIfProfitable(string symbol, ENUM_POSITION_TYPE posType) { CTrade trade; CPositionInfo pos; for(int i = PositionsTotal() - 1; i >= 0; i--) { if(pos.SelectByIndex(i)) { if(pos.Symbol() == symbol && pos.PositionType() == posType) { double profit = pos.Profit(); // Закрываем только если позиция в прибыли if(profit > 0) { trade.PositionClose(pos.Ticket()); } } } } }
Техническая реализация: анатомия AdaptiveQ Enhanced
Огромное пространство состояний и многоуровневый анализ
Одна из ключевых особенностей нашей системы — огромное пространство состояний (531,441 уникальных состояний). Это обеспечивает детальный анализ рыночных условий и позволяет системе адаптироваться к широкому спектру сценариев.
В обновленной версии каждое состояние стало еще более информативным. Теперь система анализирует рынок не только на текущем таймфрейме, но одновременно на трех различных временных интервалах: M15, H1 и H4. Этот мультитаймфреймовый подход позволяет AdaptiveQ Enhanced получить полную картину рыночной динамики — от краткосрочных колебаний до среднесрочных трендов.
Для каждого таймфрейма система отслеживает целый комплекс параметров:
- Разницу между ценой и 20 скользящими средними (от MA10 до MA200)
- Бинарные флаги положения цены относительно ключевых уровней MA
- Значения технических индикаторов RSI и Stochastic
- Моментум движения цены
Все эти данные преобразуются в уникальный индекс состояния, который затем используется для обращения к Q-матрице:
int ConvertToStateIndex(MarketState &state) { double range = state.price_high - state.price_low; if(range == 0) range = 0.0001; // Базовые компоненты из цен int o_idx = (int)((state.price_open - state.price_low) / range * 9); int c_idx = (int)((state.price_close - state.price_low) / range * 9); int m_idx = (int)((state.momentum + 0.001) / 0.002 * 9); // Базовый индекс из основных компонентов int stateIdx = o_idx * 81 + c_idx * 9 + m_idx; // Добавляем компоненты из разницы с MA для текущего таймфрейма int ma_idx = 0; for(int i = 0; i < 10; i++) { int diff_idx = (int)((state.ma_diff[i] + 0.01) / 0.02 * 9); diff_idx = MathMin(MathMax(diff_idx, 0), 8); ma_idx += diff_idx * (int)MathPow(9, i % 3); } // Добавляем компоненты из индикаторов для каждого таймфрейма ulong tf_state = 0; for(int tfIdx = 0; tfIdx < TOTAL_TIMEFRAMES; tfIdx++) { // RSI: 0-100 -> 0-9 int rsi_idx = (int)(state.tf_rsi[tfIdx] / 10); rsi_idx = MathMin(MathMax(rsi_idx, 0), 9); tf_state = tf_state * 10 + rsi_idx; // Stochastic %K: 0-100 -> 0-9 int stoch_k_idx = (int)(state.tf_stoch_k[tfIdx] / 10); stoch_k_idx = MathMin(MathMax(stoch_k_idx, 0), 9); tf_state = tf_state * 10 + stoch_k_idx; // Бинарные флаги для MA: выбираем ключевые МА (10, 50, 100, 200) int ma_flags = 0; ma_flags |= state.tf_ma_above[tfIdx][0] << 0; // MA10 ma_flags |= state.tf_ma_above[tfIdx][4] << 1; // MA50 ma_flags |= state.tf_ma_above[tfIdx][9] << 2; // MA100 ma_flags |= state.tf_ma_above[tfIdx][19] << 3; // MA200 tf_state = tf_state * 16 + ma_flags; } // Хэшируем вместе базовый индекс и индикаторы ulong hash = stateIdx + ma_idx + (ulong)tf_state; // Приводим к диапазону TOTAL_STATES через хэш return (int)(hash % TOTAL_STATES); }
Всмотритесь в эту функцию внимательнее. Здесь происходит удивительная трансформация: многомерное пространство рыночных параметров преобразуется в уникальный идентификатор состояния. Это как если бы мы создали многомерную карту рынка, где каждая точка соответствует определенной комбинации цен и индикаторов, а затем, свернули ее в одномерный индекс с помощью хеш-функции.
Кэширование и оптимизация быстродействия
Учитывая вычислительную сложность системы, мы уделили особое внимание оптимизации. В новой версии добавлено кэширование не только цен и корреляций, но и значений всех используемых индикаторов:
// Кэш для цен и корреляций (оптимизация быстродействия) double bidCache[TOTAL_SYMBOLS], askCache[TOTAL_SYMBOLS]; double correlationMatrix[TOTAL_SYMBOLS][TOTAL_SYMBOLS]; double pointCache[TOTAL_SYMBOLS]; // Кэш для Point // Кэш для индикаторов double maCache[TOTAL_SYMBOLS][10]; double maTFCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; int maAboveCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; double rsiCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochKCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochDCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];Более того, система теперь сохраняет хендлы индикаторов между вызовами, что позволяет избежать их многократного создания:
// Хендлы для индикаторов, чтобы избежать многократного создания int rsiHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; int stochHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];А для экономии вычислительных ресурсов добавлен механизм периодического обновления индикаторов:
// Время последнего обновления индикаторов datetime lastMAUpdate = 0; datetime lastIndicatorsUpdate = 0; int indicatorUpdateInterval = 60; // Обновлять индикаторы каждую минуту void UpdateIndicatorsCache() { datetime currentTime = TimeCurrent(); if(currentTime - lastIndicatorsUpdate < indicatorUpdateInterval) return; // ... код обновления индикаторов ... lastIndicatorsUpdate = currentTime; }
Этот прием может показаться тривиальным, но на практике он дает значительный прирост производительности, что критически важно для системы, работающей одновременно с семью валютными парами на трех таймфреймах.
Адаптивное обучение с механизмом упущенной выгоды
Сердце нашей системы — механизм адаптивного обучения, который теперь стал еще более продвинутым. В отличие от классического Q-learning, AdaptiveQ Enhanced использует концепцию "упущенной выгоды" (opportunity cost), которая позволяет системе учиться быстрее на своих ошибках.
Когда система принимает решение, она не только оценивает фактическое вознаграждение от выбранного действия, но и симулирует потенциальный результат альтернативных действий. Если оказывается, что другое действие могло бы принести большую прибыль, система корректирует свою стратегию более агрессивно:// Проверяем, привело ли действие к убытку и можно ли было получить прибыль с альтернативным действием bool wasLoss = reward < 0; bool couldProfit = tradeStates[symbolIdx].alternativeReward > 0 && tradeStates[symbolIdx].opportunityCost < 0; // Применяем адаптивную скорость обучения для случаев упущенной выгоды if(wasLoss && couldProfit) { // Увеличиваем скорость обучения для быстрой адаптации к неправильным решениям double adaptiveLearningRate = MathMin(learningRate * adaptiveMultiplier, 0.9); // Дополнительно уменьшаем Q-значение пропорционально упущенной выгоде newQ -= adaptiveLearningRate * MathAbs(tradeStates[symbolIdx].opportunityCost) * opportunityCostWeight; }
Это похоже на то, как опытный трейдер не только учится на своих ошибках, но и анализирует упущенные возможности, корректируя свою стратегию более агрессивно, когда видит, что альтернативное решение было бы значительно лучше. Благодаря параметру adaptiveMultiplier, пользователь может настроить, насколько интенсивно система будет учиться на упущенных возможностях.
Другим инновационным аспектом обучения является каузальное влияние между валютными парами:
// Обновляем Q-значения для других символов на основе корреляции (каузальное обучение) for(int otherSymbol = 0; otherSymbol < TOTAL_SYMBOLS; otherSymbol++) { if(otherSymbol != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherSymbol]; // Применяем обновление только если корреляция значима if(MathAbs(corr) > 0.2) { qMatrix[tradeStates[symbolIdx].previousStateIdx][tradeStates[symbolIdx].previousAction][otherSymbol] += learningRate * reward * corr * 0.1; } } }
Когда система получает опыт по одной валютной паре, она может переносить его на другие связанные инструменты, учитывая степень их корреляции. Это создает эффект "перекрестного обучения", что существенно ускоряет процесс адаптации системы к рыночным условиям.
Практические аспекты использования AdaptiveQ Enhanced
Расширенные возможности настройки и управления рисками
AdaptiveQ Enhanced предлагает впечатляющий набор параметров для тонкой настройки системы под индивидуальные предпочтения трейдера:
input OPERATION_MODE OperationMode = MODE_LEARN_AND_TRADE; // Режим работы системы input CLOSE_STRATEGY CloseStrategy = STRATEGY_CLOSE_ALL; // Стратегия закрытия input POSITION_MODE PositionMode = MODE_MULTI; // Режим позиций input double TradeVolume = 0.01; // Базовый объем сделки input double AddVolumePercent = 50.0; // Процент от базового объема для добавления к позиции input int TakeProfit = 2500; // Take Profit (пункты) input int StopLoss = 1500; // Stop Loss (пункты) input double LearningRate = 0.1; // Скорость обучения input double DiscountFactor = 0.9; // Фактор дисконтирования input double AdaptiveMultiplier = 1.5; // Множитель адаптивной скорости обучения input double OpportunityCostWeight = 0.2; // Вес упущенной выгоды input int MaxPositionsPerSymbol = 5; // Максимальное количество позиций на один символ
Система может работать в трех режимах позиций: MODE_SINGLE позволяет иметь только одну позицию по каждому символу, MODE_MULTI разрешает открывать до MaxPositionsPerSymbol однонаправленных позиций, а MODE_OPPOSITE позволяет одновременно иметь позиции в противоположных направлениях.
Особого внимания заслуживает параметр AddVolumePercent, который определяет, какой объем будет добавлен к существующей позиции при действиях ACTION_ADD_BUY и ACTION_ADD_SELL . Это дает возможность реализовать стратегию наращивания позиций, когда система добавляет объем в направлении успешной тенденции.
Интеллектуальное управление позициями
Возможность избирательного закрытия только прибыльных позиций — одно из самых интересных нововведений в AdaptiveQ Enhanced. Это позволяет системе фиксировать прибыль, одновременно давая убыточным позициям шанс восстановиться:
case ACTION_CLOSE_PROFITABLE_BUYS: if(tradeStates[symbolIdx].buyPositions > 0) { // Закрываем только прибыльные позиции BUY ClosePositionsByTypeIfProfitable(symbol, POSITION_TYPE_BUY); tradeStates[symbolIdx].actionSuccessful = true; } break;
В сочетании с возможностью открывать множественные позиции, это создает интересную динамику: система может постепенно наращивать позиции при развитии тренда, затем частично фиксировать прибыль при первых признаках разворота, сохраняя часть позиций для потенциального продолжения движения.
Периодическое сохранение и загрузка обученной модели
Изюминкой нашей системы по-прежнему остается возможность сохранять и загружать обученную Q-матрицу. В новой версии этот механизм стал еще более надежным, благодаря периодическому автоматическому сохранению:
void CheckAndSaveQMatrix() { if(IsNewBar() && OperationMode == MODE_LEARN_AND_TRADE) { Print("Периодическое сохранение Q-матрицы..."); SaveQMatrix(); } }
Система проверяет появление нового бара и периодически сохраняет накопленные знания, что защищает от потери данных обучения при непредвиденном завершении работы.
Вот так работает вся система:
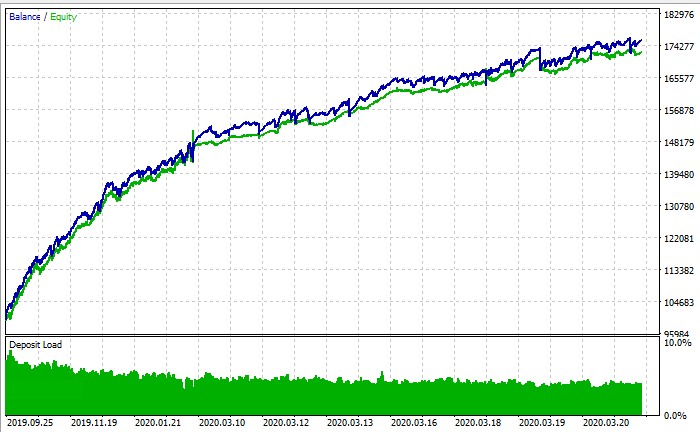
Заключение: новые горизонты алгоритмической торговли
Торговый советник AdaptiveQ Enhanced представляет собой не просто еще один инструмент для алгоритмической торговли, а принципиально новый подход к анализу и прогнозированию финансовых рынков. Объединяя глубокое обучение с подкреплением, теорию игр и причинно-следственный вывод с расширенным арсеналом торговых действий и мультитаймфреймовым анализом, мы создали систему, способную улавливать сложные взаимосвязи между различными валютными парами и принимать оптимальные торговые решения.
Особенно эффективным оказался механизм адаптивной скорости обучения с учетом упущенной выгоды. Когда система принимает неверное решение, а альтернативное действие могло бы принести прибыль, она увеличивает скорость обучения в соответствии с AdaptiveMultiplier (по умолчанию в 1.5 раза). Это своего рода "урок с повышенной интенсивностью" — система учится быстрее на своих ошибках, чем на успехах, что соответствует и человеческой психологии.
Будущее алгоритмической торговли лежит именно в сфере адаптивных систем, способных учиться и эволюционировать вместе с рынком. И AdaptiveQ Enhanced — это не просто эксперимент, а рабочий инструмент, открывающий новые горизонты для исследований и разработок. Код, представленный в этой статье, доступен для экспериментов и дальнейшего улучшения. Я приглашаю сообщество MQL5 принять участие в развитии этой концепции и создании еще более совершенных торговых систем на основе искусственного интеллекта и теории игр.
Мир финансов становится все более сложным и взаимосвязанным. И только системы, способные воспринимать эту сложность и адаптироваться к ней, смогут успешно конкурировать на рынках будущего. AdaptiveQ Enhanced — это шаг в этом направлении, шаг к более умной, более адаптивной и, в конечном счете, более прибыльной алгоритмической торговле.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Оригинальная штука, переполняюсь восторгом как от предмета искусства, спасибо :) Правда тестировать желательно на реальных тиках, потому что мельчит со сделками.
Приветствую! Очень интересен ваш проект, но я новичок в этой сфере. Я не могу разобраться с запуском советника в тестере стратегий. Как я понял полноценно настроить и обучить его через тестер невозможно? Или я что-то делаю не так? Буду признателен за ОС
Приветствую! Очень интересен ваш проект, но я новичок в этой сфере. Я не могу разобраться с запуском советника в тестере стратегий. Как я понял полноценно настроить и обучить его через тестер невозможно? Или я что-то делаю не так? Буду признателен за ОС
Откуда у меня родственники в Нидерландах?👀
Откуда у меня родственники в Нидерландах?👀
Ахахах, не в Нидерландах)) ВПН вещь такая)))
ПС: По итогу в тестере стратегий можно запустить обучение или нет? По скрину графика баланса это тестер стратегий, но что бы я не делал у меня даже близко в + не торгует