
Desarrollo de un robot en Python y MQL5 (Parte 2): Selección, creación y entrenamiento de modelos, simulador personalizado en Python

Resumen del artículo anterior
En el artículo anterior hablamos un poco sobre el aprendizaje automático, realizamos un aumento de los datos, desarrollamos características para el futuro modelo y seleccionamos las mejores. Ahora es el momento de seguir adelante y crear un modelo de aprendizaje automático ya operativo, que aprenda de nuestras señales y comercie (esperemos que con éxito). Y para evaluar el modelo, escribiremos un simulador de Python personalizado que nos ayudará a evaluar el rendimiento del modelo y la belleza de los gráficos de prueba. Para que los gráficos de prueba resulten más bonitos y el modelo más robusto, también desarrollaremos una serie de trucos clásicos del aprendizaje automático.
Nuestro objetivo final será crear un modelo que funcione y sea lo más rentable posible para la previsión de precios y el trading. El código completo estará en Python, con la inclusión de la biblioteca MQL5.
Versión de Python y módulos necesarios
Para el trabajo se ha usado la versión 3.10.10 de Python. El código adjunto contiene varias funciones para el preprocesamiento de datos, la extracción de características y el entrenamiento de un modelo de aprendizaje automático. Concretamente, incluye:
- Una función de clusterización de características con la ayuda del Gaussian Mixture Model (GMM) de la biblioteca sklearn
- Una función para la extracción de características con la ayuda de la Recursive Feature Elimination with Cross-Validation (RFECV) de la biblioteca sklearn
- Una función para entrenar el clasificador XGBoost
Para ejecutar este código, deberán instalarse los siguientes módulos de Python:
- pandas
- numpy
- sklearn
- xgboost
- matplotlib
- seaborn
- MetaTrader5
- tqdm
Podremos instalarlos con pip, la utilidad de instalación de paquetes de Python. A continuación le mostramos un ejemplo de comando para instalar todos los módulos necesarios:
pip install pandas numpy sklearn xgboost matplotlib seaborn tqdm MetaTrader5
¡Vamos allá!
¿Clasificación o regresión?
Una de las eternas preguntas en la predicción de datos. La clasificación resulta más adecuada para problemas binarios en los que se necesita una respuesta clara de sí o no. Asimismo, existe la clasificación multiclase: también trataremos este tema en futuros artículos de la serie, es interesante y puede reforzar significativamente los modelos.
La regresión resulta adecuada para la predicción específica de un valor futuro concreto de una serie continua, incluida una serie de precios. Por un lado, puede ser mucho más cómodo, pero por otro, marcar los datos para la regresión, al igual que las etiquetas (labels), supone un reto mental, porque no se nos ocurre mucho más que tomar el precio futuro del activo.
Personalmente, me gusta más la clasificación porque facilita la partición de los datos. Podemos colocar muchas cosas dentro de las condiciones sí-no, y también poner complejos sistemas de trading manual al completo como SmartMoney en condiciones multiclase. Sin embargo, ya hemos visto el código de marcado de datos en el artículo anterior de esta serie, y es claramente adecuado para la clasificación binaria. Por lo tanto, este será el esquema modelo que tomaremos.
Queda por decidir el modelo en sí.
Seleccionamos de un modelo de clasificación
Tenemos que seleccionar un modelo de clasificación adecuado para nuestros datos con las características seleccionadas. La elección dependerá del número de características, los tipos de datos y el número de clases.
Modelos populares, por ejemplo: la regresión logística para la clasificación binaria, el bosque aleatorio para la alta dimensionalidad y las no linealidades, las redes neuronales para los problemas complejos. La oferta es enorme, y uno no sabe si quiera por dónde empezar. Después de probar muchas cosas, he llegado a la conclusión de que, en el entorno actual, el boosting y los modelos basados en este son los más eficaces.
Así que he decidido utilizar el modelo avanzado XGBoost, que se basa en árboles de decisión con regularización, concurrencia y mucha personalización. XGBoost suele ganar concursos de ciencia de datos gracias a su gran precisión. Este ha sido el principal criterio para elegir un modelo con el que trabajar.
Creación del código del modelo de clasificación
El código usa el modelo avanzado XGBoost, un boosting de gradiente sobre árboles de decisión. Una característica especial de XGBoost es el uso de segundas derivadas para la optimización, lo cual mejora la eficacia y la precisión en comparación con otros modelos.
La función train_xgboost_classifier recupera los datos y el número de rondas de boosting. Luego divide los datos en características X y etiquetas y, crea un modelo XGBClassifier con ajustes de hiperparámetros y lo entrena utilizando el método fit().
Los datos se dividen en entrenamiento/prueba, y el modelo se forma en el entrenamiento usando la función. Después se prueba con datos residuales y se calcula la precisión de las predicciones.
Las principales ventajas de XGBoost son: la combinación de varios modelos en uno de gran precisión, el uso del boosting de gradiente y la optimización de las segundas derivadas para una mayor eficacia.
Para utilizarlo, también deberemos instalar la biblioteca de ejecución OpenMP. Para instalar la biblioteca XGBoost, deberemos asimismo instalar el tiempo de ejecución OpenMP. Para Windows, necesitaremos descargar el Microsoft Visual C++ Redistributable que se corresponda con nuestra versión de Python.
Vamos a pasar al código propiamente dicho. Al principio del código, importamos la biblioteca xgboost así:
import xgboost as xgb Este es el resto del código:
import xgboost as xgb def train_xgboost_classifier(data, num_boost_rounds=500): # Check if data is not empty if data.empty: raise ValueError("Data should not be empty") # Check if all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check if all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create an XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Test the model on all data train_data = raw_data[raw_data.index <= FORWARD] # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate prediction accuracy accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Luego entrenamos el modelo y consideramos una precisión del 52%.
Así, nuestra precisión de clasificación se sitúa ahora en un 53% de etiquetas rentables. Tenga en cuenta que estamos hablando de la predicción de situaciones en las que el precio ha cambiado en una magnitud superior a la del Take Profit (200 pips) y no ha tocado el stop (100 pips). En la práctica, tendremos un factor de beneficio de aproximadamente tres, que será más que suficiente para una negociación rentable. El siguiente paso que veo es la escritura de un simulador customizado en Python para analizar el rendimiento del modelo, el rendimiento en dólares, no en pips. Debemos entender si el modelo está generando dinero dado el margen de beneficio, o si está drenando capital por el desagüe.
Escribimos una función de simulador customizado en Python
def test_model(model, X_test, y_test, markup, initial_balance=10000.0, point_cost=0.00001): balance = initial_balance trades = 0 profits = [] # Test the model on the test data predicted_labels = model.predict(X_test) for i in range(len(predicted_labels) - 48): if predicted_labels[i] == 1: # Open a long position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price > entry_price + markup: # Close the long position with profit profit = (exit_price - entry_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the long position with loss loss = (entry_price - exit_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) elif predicted_labels[i] == 0: # Open a short position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price < entry_price - markup: # Close the short position with profit profit = (entry_price - exit_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the short position with loss loss = (exit_price - entry_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) # Calculate the cumulative profit or loss total_profit = balance - initial_balance # Plot the balance change over the number of trades plt.plot(range(trades), [balance + sum(profits[:i]) for i in range(trades)]) plt.title('Balance Change') plt.xlabel('Trades') plt.ylabel('Balance ($)') plt.xticks(range(0, len(X_test), int(len(X_test)/10)), X_test.index[::int(len(X_test)/10)].strftime('%Y-%m-%d')) # Add dates to the x-axis plt.axvline(FORWARD, color='r', linestyle='--') # Add a vertical line for the FORWARD date plt.show() # Print the results print(f"Cumulative profit or loss: {total_profit:.2f} $") print(f"Number of trades: {trades}") # Get test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] # Test the model with markup and target labels initial_balance = 10000.0 markup = 0.00001 test_model(xgb_clf, X_test, y_test, markup, initial_balance)
El código crea una función para probar un modelo de aprendizaje automático con datos de prueba y analizar su rentabilidad considerando el margen de beneficio (deberá incluir las pérdidas por spread y las comisiones de varios tipos). Los swaps no se tendrán en cuenta, al fin y al cabo son dinámicos y dependen de los tipos clave. Pueden considerarse simplemente añadiendo un par de puntos al margen de beneficio.
La función obtiene el modelo, los datos de prueba, el markup y el balance inicial. Usando las predicciones del modelo, se simula el trading: long con 1, short con 0. Si el beneficio supera el margen, se cerrará la posición y el beneficio se añadirá al balance.
Asimismo, se llevan registros de las transacciones y de los beneficios/pérdidas de cada una. Además, se construye un gráfico de balance. Y se calcula el total acumulado de beneficios/pérdidas.
Finalmente, se obtienen los datos de la prueba y se eliminan las columnas innecesarias. El modelo xgb_clf entrenado se prueba con el markup y el balance inicial establecidos. ¡Vamos a probarlo!
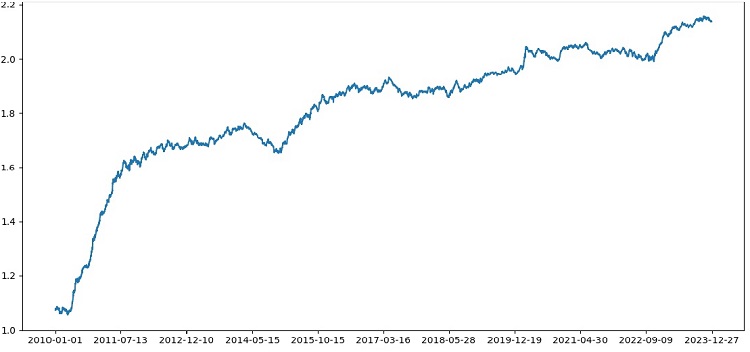
Como podemos ver, el simulador funciona en general con éxito, y vemos un hermoso gráfico de rentabilidad. Se trata de un simulador customizado para analizar el rendimiento de un modelo comercial de aprendizaje automático considerando el markup y las etiquetas.
Introducción de la validación cruzada en el modelo
La validación cruzada debe utilizarse para obtener una estimación más fiable de la calidad del modelo de aprendizaje automático. Esta herramienta permite estimar un modelo con múltiples subconjuntos de datos, lo cual ayuda a evitar el sobreajuste y obtener una estimación menos sesgada.
En nuestro caso, usaremos una validación cruzada quíntuple para estimar el modelo XGBoost. Para ello, vamos a utilizar la función cross_val_score de la biblioteca sklearn.
Luego modificaremos el código de la función train_xgboost_classifier como sigue:
def train_xgboost_classifier(data, num_boost_rounds=500): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data using cross-validation scores = cross_val_score(clf, X, y, cv=5) # Calculate the mean accuracy of the predictions accuracy = scores.mean() print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Train the model on the data without cross-validation clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Accuracy: {accuracy:.2f}")
Al entrenar el modelo, la función train_xgboost_classifier realizará una validación cruzada de 5 veces y mostrará la precisión media de la predicción. La formación seguirá incluyendo una muestra hasta la fecha FORWARD.
La validación cruzada solo se utiliza para estimar el modelo, no para entrenarlo. El entrenamiento se realizará con todos los datos hasta la fecha FORWARD sin validación cruzada.
La validación cruzada ofrece una evaluación más sólida e imparcial de la calidad del modelo, lo que en teoría aumentará su solidez ante nuevos datos de precios. ¿O no? Vamos a comprobar cómo funciona el simulador.
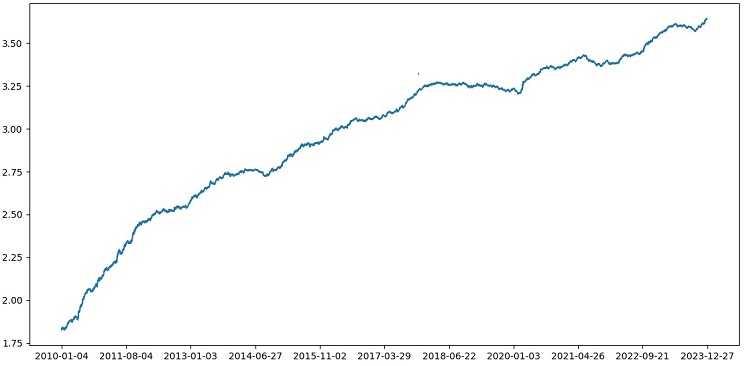
Tras probar XGBoost con validación cruzada en los datos de 1990-2024, hemos obtenido una precisión del 56% en la prueba posterior a 2010. El modelo ha mostrado una buena solidez con los nuevos datos en el primer intento. La precisión también ha aumentado bastante, lo cual es ciertamente positivo.
Optimización de los hiperparámetros del modelo de cuadrícula
La optimización de hiperparámetros supone un paso importante en la construcción de un modelo de aprendizaje automático para maximizar su precisión y rendimiento. Resulta similar a la optimización de los asesores expertos de MQL5, solo imagine que tiene un modelo MO en lugar de un asesor experto, y que utilizando una búsqueda de cuadrícula encuentra los parámetros que se muestran mejor.
Veamos cómo optimizar los hiperparámetros de XGBoost en una cuadrícula utilizando Scikit-learn.
Usaremos GridSearchCV de Scikit-learn para validar de forma cruzada el modelo sobre todos los conjuntos de hiperparámetros de la cuadrícula. Se seleccionará el conjunto con la máxima precisión media en la validación cruzada.
Código de optimización:
from sklearn.model_selection import GridSearchCV
# Define the grid of hyperparameters
param_grid = {
'max_depth': [3, 5, 7, 10],
'learning_rate': [0.1, 0.3, 0.5],
'n_estimators': [100, 500, 1000]
}
# Create XGBoost model
clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1)
# Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Print the best hyperparameters
print("Best hyperparameters:", grid_search.best_params_)
# Print the mean accuracy of the predictions on cross-validation for the best hyperparameters
print("Mean prediction accuracy on cross-validation:", grid_search.best_score_)
Aquí, definiremos una cuadrícula de hiperparámetros param_grid, crearemos un modelo XGBoost clf, y buscaremos los hiperparámetros óptimos sobre la cuadrícula usando el método GridSearchCV. A continuación, obtendremos los mejores hiperparámetros grid_search.best_params_ y la precisión media de la predicción en la validación cruzada grid_search.best_score_ .
Tenga en cuenta que en este código usaremos la validación cruzada para optimizar los hiperparámetros. Esto nos permite obtener una evaluación más fiable y objetiva de la calidad del modelo.
Tras ejecutar este código, obtendremos los mejores hiperparámetros para nuestro modelo XGBoost y la precisión de predicción media en la validación cruzada. A continuación, podremos entrenar el modelo con todos los datos utilizando los mejores hiperparámetros y probarlo con nuevos datos.
Por tanto, la optimización de hiperparámetros de un modelo sobre una cuadrícula supone una tarea importante en la construcción de modelos de aprendizaje automático. Utilizando el método GridSearchCV de la biblioteca Scikit-learn, podemos automatizar este proceso y encontrar los mejores hiperparámetros para un modelo y unos datos concretos.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 5, 7, 10], 'learning_rate': [0.05, 0.1, 0.2, 0.3, 0.5], 'n_estimators': [50, 100, 600, 1200, 2000] } # Train the model on the data using cross-validation and grid search grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Return the trained model with the best hyperparameters return grid_search.best_estimator_
Ensamblaje de modelos
Ha llegado el momento de hacer que nuestro modelo sea aún mejor. El ensamblaje de modelos supone un potente método de aprendizaje automático que combina varios modelos para mejorar la precisión de las predicciones. Los métodos más conocidos son el bagging (construcción de modelos a partir de distintas submuestras de datos) y el bootstrapping (entrenamiento secuencial de modelos para corregir los errores de modelos anteriores).
En nuestro problema, utilizaremos el conjunto XGBoost con bagging y boosting. Crearemos múltiples XGBoost entrenados con diferentes submuestras y fusionaremos sus predicciones. Optimizaremos los hiperparámetros de cada modelo con GridSearchCV.
Las ventajas del ensamblaje son: mayor precisión, menor varianza y mejor calidad general del modelo.
La función final de entrenamiento del modelo utilizará la validación cruzada, el ensamblaje y la selección de hiperparámetros erróneos sobre la cuadrícula.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Missing required columns in data: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 7, 12], 'learning_rate': [0.1, 0.3, 0.5], 'n_estimators': [100, 600, 1200] } # Train the model on the data using cross-validation and hyperparameter tuning grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean accuracy on cross-validation: {accuracy:.2f}") # Return the trained model return grid_search.best_estimator_ labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Test data test_data = raw_data[raw_data.index <= EXAMWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Implementaremos el ensamblaje de modelos usando el bagging; luego probaremos y obtendremos el siguiente resultado de nuestras pruebas:
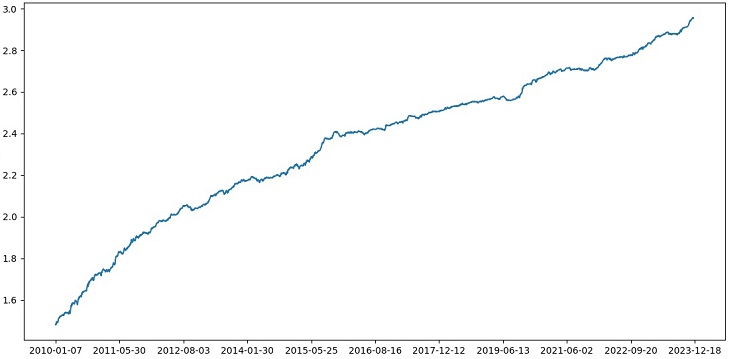
La precisión en la clasificación de las transacciones con una relación riesgo/beneficio de 1:8 ha aumentado hasta el 73%. Es decir, el ensamblaje y la búsqueda de cuadrículas han contribuido a la clasificación mucho más que en la versión anterior del código. Considero que se trata de un resultado más que notable, y en los gráficos anteriores del rendimiento del modelo en el segmento forward se puede ver claramente lo mucho que se ha fortalecido a lo largo de la evolución del código.
Aplicamos la muestra del examen y comprobamos la solidez del modelo
Ahora estamos utilizando para la prueba los datos posteriores a la fecha EXAMWARD. Esto nos permite probar el rendimiento del modelo con datos completamente nuevos que no se han utilizado en el entrenamiento ni en las pruebas del modelo. Así podemos evaluar objetivamente el rendimiento del modelo en condiciones reales.
La prueba con una muestra de examen supone un paso importante en la validación de un modelo de aprendizaje automático. Esto garantiza que el modelo funcione bien con datos nuevos y ofrece una indicación de su rendimiento real. Aquí resulta importante determinar correctamente el tamaño de la muestra y asegurarse de que sea representativa.
En nuestro caso, utilizamos los datos posteriores a EXAMWARD para probar el modelo con datos completamente desconocidos fuera del entrenamiento y la prueba. Así obtenemos una evaluación objetiva de la eficacia del modelo y su preparación para el uso en el mundo real.
Hemos realizado el entrenamiento con datos de 2000-2010, la prueba con datos de 2010-2019, y el examen a partir de 2019. El examen simula el trading con un futuro desconocido.
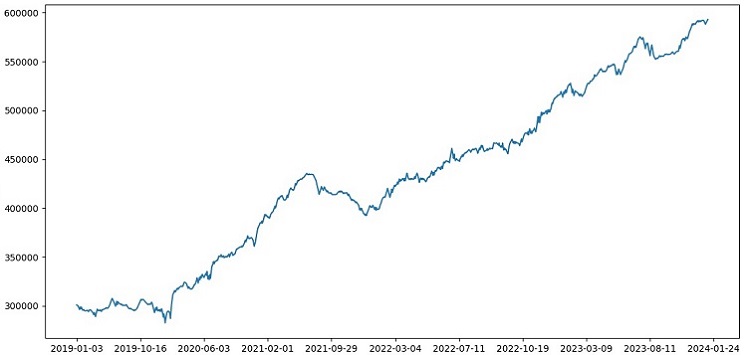
En general, las cosas pintan bastante bien. La precisión en el examen ha descendido al 60%, pero lo principal es que el modelo resulta rentable y bastante robusto, sin reducciones intensas. Es algo positivo ver que el modelo aprende el concepto de riesgo/beneficio, pues predice situaciones con bajo riesgo y alto beneficio potencial (utilizamos 1:8 de riesgo/beneficio).
Conclusión
Así, concluimos el segundo artículo de la serie sobre la creación de un robot comercial en Python. Hasta ahora hemos conseguido resolver las tareas relacionadas con el trabajo con los datos, el trabajo con las características, la tarea de selección de características e incluso la generación de características, la tarea de selección de modelos y el entrenamiento. También hemos escrito un simulador personalizado que prueba el modelo, y parece que funciona bastante bien. Por cierto, he probado otras características, incluso las más sencillas, intentando simplificar los datos, pero no he logrado resultados. Los modelos con estas características han agotado totalmente la cuenta en nuestro mismo simulador. Esto confirma una vez más que las características y los datos son tan importantes como la genialidad del modelo en sí. Podemos crear un buen modelo y aplicar todo tipo de mejoras y métodos, pero si las características son inútiles, también agotará sin piedad nuestro depósito con datos desconocidos. Y con buenas señales, incluso podemos obtener un resultado coherente en un modelo que no sea el mejor.
Planes de futuro
En el futuro, planeo crear una versión personalizada de trading en línea en el terminal MetaTrader 5 para negociar directamente a través de Python. Es cómodo. Permítame recordarle que la primera señal a mi cerebro sobre la necesidad de hacer una versión para Python han sido los problemas con el traslado de características a MQL5. Con las características, su selección, la partición de datos, el aumento de datos, me sigue pareciendo mucho más rápido y cómodo hacer mi trabajo en Python.
Creo que la biblioteca MQL5 para Python está inmerecidamente infravalorada, es obvio que poca gente la usa. Aunque es muy potente, podemos utilizarla para crear unos diseños realmente bonitos que gusten tanto a la vista como a la cartera.
También me gustaría implementar una versión que aprenda de los datos históricos de la profundidad de mercado en una bolsa de valores real, como Chicago o Moscú. Esta es también una perspectiva prometedora.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14910
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso