Возможности Мастера MQL5, которые вам нужно знать (Часть 13): DBSCAN для класса сигналов советника
Введение
Эта серия статей о Мастере MQL5 демонстрирует, как часто абстрактные идеи в математике и других областях жизни могут быть воплощены в жизнь как торговые системы и протестированы перед применением. Способность брать простые и не полностью реализованные идеи и исследовать их потенциал в качестве торговых систем — одна из наиболее примечательных возможностей Мастера MQL5 для советников. Классы советников в Мастере предоставляют множество повседневных функций, необходимых любому советнику, особенно в том, что касается открытия и закрытия сделок, а также таких упускаемых из виду аспектов, как выполнение тех или иных действий только при формировании нового бара.
Таким образом, используя эту библиотеку процессов в качестве отдельного аспекта советника, с помощью Мастера MQL5 любую идею можно не только протестировать независимо, но и сравнить на равных с любыми другими идеями (или методами). В этой серии мы рассмотрели альтернативные методы кластеризации, такие как агломеративная кластеризация и кластеризация k-средних.
В каждом из этих подходов перед созданием соответствующих кластеров одним из необходимых входных параметров было количество создаваемых кластеров. Это требовало хорошего знания набора данных. В случае с основанной на плотности пространственной кластеризации для приложений с шумами (Density Based Spatial Clustering for Applications with Noise, DBSCAN) количество формируемых кластеров является "почетным" неизвестным. Это обеспечивает большую гибкость не только при исследовании неизвестных наборов данных и обнаружении их основных классификационных признаков, но также позволяет проверить существующие "предубеждения" или общепринятые взгляды на любой набор данных на предмет того, можно ли проверить количество предполагаемых кластеров.
Используя всего два параметра, а именно эпсилон (максимальное пространственное расстояние между точками в кластере) и количество минимальных точек, необходимых для формирования кластера, DBSCAN способен не только генерировать кластеры на основе выборочных данных, но и определять подходящее количество этих кластеров. Чтобы оценить его замечательные возможности, возможно, будет полезно взглянуть на некоторые кластеризации, которые он может выполнять в отличие от альтернативных подходов.
Согласно этой статье (на английском), DBSCAN и k-средние выдадут следующие результаты.
Кластеризация k-средних:

в то время как DBSCAN выдаст:

В статье (на английском) DBSCAN сравнивается с другим подходом кластеризации, названным CLARANS, со следующими результатами. При CLARANS повторная классификация дает следующее:

DBSCAN при тех же условиях демонстрирует следующую группировку:
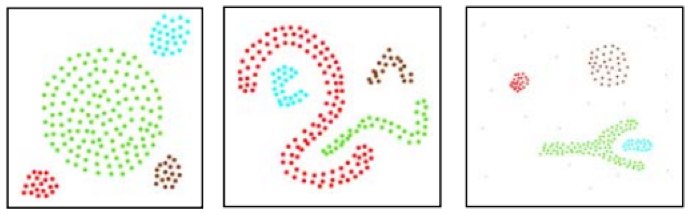
Первый пример может быть условным представлением, однако второй является окончательным. Аргументы в пользу этого утверждения заключаются в том, что без заранее установленного количества кластеров, необходимых для классификации, DBSCAN использует плотность или среднее расстояние между точками для создания соответствующих группировок и, следовательно, кластеров.
Как видно из изображений выше, k-средние занимаются территориальным разделением, которое в данном случае определяется координатами осей x и y. Итак, k-средние распределяют точки внутри ограничений по осям (в данном случае x и y) как наиболее подходящие. DBSCAN вводит дополнительное "измерение" плотности, где недостаточно просто располагаться в пределах областей координатных осей, но также принимается во внимание внутренняя близость всех точек. В результате кластеры могут простираться на обширные регионы, выходящие за пределы того, что можно было бы считать их средними локусами или наиболее подходящими точками.
Поэтому в этой статье мы рассмотрим, как DBSCAN может помочь в уточнении решений о покупке и продаже класса сигналов советника, используемых в Мастере MQL5. Мы уже видели, насколько кластеризация может быть информативной при принятии такого рода решений в двух предыдущих статьях, ссылки на которые приведены выше, поэтому мы будем опираться на эту информативность при построении классов сигналов для DBSCAN.
С этой целью у нас будут три иллюстрации различных классов сигналов советника, которые используют DBSCAN по-разному в первую очередь при обработке разных наборов данных. Как упоминалось в начале, эти идеи представлены здесь для предварительного тестирования. Их не следует использовать на реальных счетах. Читателям следует проявлять осмотрительность.
Снимаем завесу тайны с DBSCAN
Чтобы "демистифицировать" DBSCAN, возможно, было бы неплохо предоставить несколько каждодневных ситуаций, не связанных с трейдингом. Итак, давайте рассмотрим три примера.
Пример 1: Вы владелец супермаркета. Вам нужно проанализировать набор данных о покупателях и найти закономерности, которые можно использовать в будущем. Анализ также обычно может принимать различные формы, однако для наших целей мы в первую очередь рассматриваем кластеризацию. При использовании k-средних вам придется начать с предположения о фиксированном числе типов клиентов, скажем, тех, кто покупает только крупные потребительские товары или электронику и только во время распродаж, а основными потребителями являются те, кто покупает продукты для дома примерно раз в неделю. При таком пакетировании наборов вы затем сможете детализировать то, что они покупают, и соответствующим образом спланировать свои запасы, чтобы они могли удовлетворить спрос в будущем. Теперь, поскольку вы установили для своих кластеров (типов клиентов) значение два, вам обязательно придется работать с двумя основными типами затрат (позиционированных во времени как средние центроиды) для пополнения ваших запасов, что может негативно сказаться на вашем движении ликвидности. Расходы меньшего размера, возможно, были бы более управляемыми. С другой стороны, если бы вы использовали DBSCAN для сегментации своих клиентов, то количество типов клиентов, которые вы получите, будет определяться их плотностью или тем, насколько близко во времени клиенты склонны совершать покупки. Выше мы использовали аналогию осей X и Y для количественной оценки эпсилона (близости точек данных), но для случая с покупателями супермаркета будет достаточно календаря, где степень "близости" клиентов будет определяться количественно по тому, насколько далеко друг от друга они находятся по датам покупок. Это позволяет более гибко группировать клиентов, что, в свою очередь, может дать большую управляемость затрат при пополнении запасов, помимо других преимуществ.
Пример 2: Вы урбанист и вам поручено провести повторную оценку максимального количества жилых домов, которое должно быть разрешено к строительству в каждом районе города, на основе изучения особенностей городского движения. В то время как в примере 1 мы использовали время в качестве пространственной области для кластеризации, в этом примере мы ограничены физическими маршрутами, которые пересекают город и, возможно, соединяют районы. При использовании кластеризации K-средних мы используем существующее количество районов в качестве кластеров, а затем определим весовой коэффициент или порог численности населения каждого района на основе среднего количества утреннего и вечернего трафика на его соединительных маршрутах. Благодаря новой весовой пропорции для каждого района мы можем пропорционально уменьшить или увеличить лимит жилой площади. Разумеется, численность населения в районах непостоянна. Некоторые из них могут вымирать, другие процветать и, что более важно, могут появляться новые. Таким образом, используя DBSCAN только с маршрутами движения, а не с предположениями о количестве районов, мы можем группировать маршруты в различные формы кластеров, которые затем будут отображать наши новые районы. В этом случае наш эпсилон будет отслеживать, сколько машин у нас на каждом маршруте (в часы пик в утренние и вечерние часы), скажем, на километр. Это может означать, что более плотные маршруты могут быть сгруппированы вместе, чем менее плотные, что создает проблемы в тех случаях, когда маршруты ведут в разные географические районы. Чтобы обойти эту особенность или лучше понять данные, можно было бы предположить, что эти маршруты, даже если они находятся на разных территориях, представляют один и тот же "тип района" (это может быть связано с уровнем дохода населения и т. д.), и поэтому для целей планирования их можно обустроить аналогичным образом.
Пример 3: Социальные сети являются золотой жилой в плане данных для многих компаний, и ключ к их лучшему пониманию может заключаться в способности классифицировать или, в нашем случае, группировать пользователей по разным критериям. Учитывая, что пользователи социальных сетей формируют свои собственные группы для отдыха и работы, они могут иметь общие интересы и время от времени взаимодействовать. Перед k-средними стоит непростая задача — найти приемлемое количество кластеров с самого начала кластеризации. С другой стороны, DBSCAN, уделяя особое внимание плотности, может сосредоточиться на количестве взаимодействий с пользователем, скажем, посредством подсчета за установленный период времени. Таким образом, это количество взаимодействий одного пользователя с другим может определять параметр эпсилон при формировании и определении различных кластеров, которые могут быть возможны на данной платформе социальных сетей.
DBSCAN лучше справляется с обработкой шума и выявлением выбросов, особенно в ситуациях обучения без учителя. Входной параметр минимального количества точек также важен при достижении идеального количества кластеров для набора выборочных данных, однако он не так чувствителен (или важен), как эпсилон, поскольку его роль, по сути, заключается в установке порога "шума". При использовании DBSCAN любые данные, не попадающие в определенные кластеры, являются шумом.
Реализация средствами MQL5
Итак, базовая структура советников, собираемых Мастером MQL5, уже была рассмотрена в предыдущих статьях. Официальную статью на эту тему можно найти здесь. Советники, собранные Мастером, зависят от класса Expert, указанного в файле <include\Expert\Expert.mqh>. Этот класс в первую очередь определяет, как выполняются типичные функции советника, связанные с открытием и закрытием позиций. Это, в свою очередь, зависит от класса Expert-Base, определяемого в файле <include\Expert\ExpertBase.mqh>. Файл обрабатывает извлечение и буферизацию текущей информации о цене символа, к которому прикреплен советник. Из класса Expert, который мы можем рассматривать как якорь, путем наследования выводятся еще три класса, а именно: класс сигналов советника (Expert Signal), класс трейлинга советника (Expert Trailing) и класс средств советника (Expert Money). Пользовательские реализации каждого из этих классов уже были описаны в предыдущих статьях, однако стоит повторить, что класс сигналов Expert обрабатывает решения о покупке и продаже, в то время как класс Expert Trailing определяет, когда и насколько перемещать трейлинг-стоп на открытых позициях. Наконец, класс Expert Money определяет, какую долю доступной маржи использовать при определении размера позиции.
Шаги по сборке советника из доступных в библиотеке классов очень просты и описаны здесь. Подготовкой данных занимается базовый Expert Base. В идеале тестирование должно проводиться с ценовыми данными вашего предполагаемого брокера, а реальные тики должны быть загружены с его сервера в максимально доступном объеме.
Эта статья содержит исходный код, который мы используем для определения наших функций, при реализации функции DBSCAN. Имеются четыре несложные функции. Можно начать с самой простой - Distance.
//+------------------------------------------------------------------+ //| Function for Euclidean Distance between points | //+------------------------------------------------------------------+ double CSignalDBSCAN::Distance(Spoint &A, Spoint &B) { double _d = 0.0; for(int i = 0; i < int(fmin(A.key.Size(), B.key.Size())); i++) { _d += pow(A.key[i] - B.key[i], 2.0); } _d = sqrt(_d); return(_d); }
В цитируемой статье и в большинстве общедоступных исходных кодов DBSCAN евклидово расстояние используется в качестве основного показателя для количественной оценки того, насколько далеко точки находятся друг от друга в любом наборе точек. Однако, поскольку наши точки представлены в векторной форме, MQL5 предоставляет довольно много альтернатив измерению этого расстояния между точками, таких как косинусное сходство (cosine similarity) и т. д. Они являются подфункциями векторного типа данных. При необходимости читатель может их изучить. Мы реализуем евклидову функцию с нуля, так как мне не удалось найти ее в разделах Loss и RegressionMetric.
В качестве следующего строительного блока нам понадобится функция RegionQuery. Возвращает список точек в пределах порога, определенного входным параметром эпсилон, который можно считать находящимся в том же кластере, что и рассматриваемая точка.
//+------------------------------------------------------------------+ //| Function that returns neighbouring points for an input point &P[]| //+------------------------------------------------------------------+ void CSignalDBSCAN::RegionQuery(Spoint &P[], int Index, CArrayInt &Neighbours) { Neighbours.Resize(0); int _size = ArraySize(P); for(int i = 0; i < _size; i++) { if(i == Index) { continue; } else if(Distance(P[i], P[Index]) <= m_epsilon) { Neighbours.Resize(Neighbours.Total() + 1); Neighbours.Add(i); } } P[Index].visited = true; }
Обычно для каждой точки в рассматриваемом наборе данных мы пытаемся составить такой список точек, чтобы ничего не было упущено, и этот список полезен для следующей функции — ExpandCluster.
//+------------------------------------------------------------------+ //| Function that extends cluster for identified cluster IDs | //+------------------------------------------------------------------+ bool CSignalDBSCAN::ExpandCluster(Spoint &SetOfPoints[], int Index, int ClusterID) { CArrayInt _seeds; RegionQuery(SetOfPoints, Index, _seeds); if(_seeds.Total() < m_min_points) // no core point { SetOfPoints[Index].cluster_id = -1; return(false); } else { SetOfPoints[Index].cluster_id = ClusterID; for(int ii = 0; ii < _seeds.Total(); ii++) { int _current_p = _seeds[ii]; CArrayInt _result; RegionQuery(SetOfPoints, _current_p, _result); if(_result.Total() > m_min_points) { for(int i = 0; i < _result.Total(); i++) { int _result_p = _result[i]; if(SetOfPoints[_result_p].cluster_id == -1) { SetOfPoints[_result_p].cluster_id = ClusterID; } } } } } return(true); }
Эта функция принимает идентификатор кластера и индекс точки. Она определяет, нужно ли назначать идентификатор кластера каким-либо новым точкам на основе результатов функции RegionQuery, упомянутой выше. При true размер кластера увеличивается, в противном случае остается неизменным. В рамках этой функции мы проверяем наличие уже идентифицированных в кластере точек, чтобы избежать повторения. Как указано выше, любые некластеризованные точки (которые сохраняют идентификатор кластера: -1) считаются шумом.
Объединение всего этого осуществляется с помощью основной функции DBSCAN, которая перебирает все точки набора данных, определяя, нужно ли расширить текущий идентификатор кластера. Текущий идентификатор кластера представляет собой целое число, которое увеличивается при каждом создании нового кластера, и при каждом приращении окрестность всех точек, принадлежащих этому кластеру, запрашивается через упомянутую функцию RegionQuery. Она вызывается через функцию ExpandCluster. Соответствующий фрагмент кода приведен ниже:
//+------------------------------------------------------------------+ //| Main clustering function | //+------------------------------------------------------------------+ void CSignalDBSCAN::DBSCAN(Spoint &SetOfPoints[]) { int _cluster_id = -1; int _size = ArraySize(SetOfPoints); for(int i = 0; i < _size; i++) { if(SetOfPoints[i].cluster_id == -1) { if(ExpandCluster(SetOfPoints, i, _cluster_id)) { _cluster_id++; SetOfPoints[i].cluster_id = _cluster_id; } } } }
Аналогично, структура, которая обрабатывает набор данных, называемый в приведенном выше листинге "набором точек" (set of points), определяется в заголовке класса следующим образом:
struct Spoint { vector key; bool visited; int cluster_id; Spoint() { key.Resize(0); visited = false; cluster_id = -1; }; ~Spoint() {}; };
DBSCAN как метод кластеризации сталкивается с проблемами памяти в зависимости от размера набора данных. Кроме того, есть мнение, что эпсилон — ключевой входной параметр, измеряющий плотность кластеров, — не должен быть одинаковым для всех кластеров. Это действительно так в используемой нами реализации. Однако существуют варианты DBSCAN, такие как HDBSCAN, которые мы можем рассмотреть в будущих статьях. Они даже не требуют эпсилона в качестве входных данных, а полагаются только на минимальное количество точек в кластере. Это менее важный и чувствительный параметр, что делает его более универсальным при кластеризации.
Классы сигналов
Опираясь на наши наработки выше, мы можем представить ряд различных подходов к кластеризации данных о ценах на ценные бумаги для генерации торговых сигналов. Итак, три примерных подхода, обещанные в начале статьи, будут кластеризацией:
- необработанных данных ценового бара OHLC,
- изменений данных индикатора RSI,
- изменений цены скользящей средней.
В предыдущих статьях о кластеризации у нас была грубая модель, в которой мы ретроспективно помечали кластеризованные значения возможными изменениями цен и использовали текущие средневзвешенные значения этих изменений для составления нашего следующего прогноза. Мы будем использовать аналогичный подход, но основное различие между каждым методом будет в первую очередь заключаться в наборе данных, передаваемых в нашу функцию DBSCAN. Поскольку наборы данных различаются, входные параметры для каждого класса сигналов также могут быть разными.
Если мы начнем с необработанных данных OHLC, наш набор данных будет состоять из 4 ключевых точек. Вектор, который мы определили как key в структуре Spoint, содержащей наши данные, будет иметь размер 4. Эти 4 пункта будут изменениями цен открытия, максимума, минимума и закрытия. Итак, мы заполняем структуру Spoint текущей информацией о цене следующим образом:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CSignalDBSCAN::GetOutput() { double _output = 0.0; ... ... for(int i = 0; i < m_set_size; i++) { for(int ii = 0; ii < m_key_size; ii++) { if(ii == 0) { m_model.x[i].key[ii] = (m_open.GetData(StartIndex() + i) - m_open.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } else if(ii == 1) { m_model.x[i].key[ii] = (m_high.GetData(StartIndex() + i) - m_high.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } else if(ii == 2) { m_model.x[i].key[ii] = (m_low.GetData(StartIndex() + i) - m_low.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } else if(ii == 3) { m_model.x[i].key[ii] = (m_close.GetData(StartIndex() + i) - m_close.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } } if(i > 0) //assign classifier only for data points for which eventual bar range is known { m_model.y[i - 1] = (m_close.GetData(StartIndex() + i - 1) - m_close.GetData(StartIndex() + i)) / m_symbol.Point(); } } ... return(_output); }
Если мы соберем этот сигнал с помощью Мастера и проведем тесты по EURUSD за 2023 год на дневном таймфрейме, наш лучший результат даст нам следующий отчет и кривую эквити.


Судя по отчетам, можно сказать, что потенциал есть, однако в данном случае мы не проводили walk-forward тест, как мы пытались сделать в небольших масштабах в предыдущих статьях, поэтому читателю предлагается сделать это, прежде чем двигаться дальше.
Продолжая использовать абсолютные значения RSI как набора данных, мы проводим реализацию аналогичным образом, с основным отличием в том, как мы учитываем 3 различных периода задержки, для которых мы принимаем показания RSI. Итак, с этим набором данных мы получаем 4 точки данных за раз, как и в случае с необработанными ценами OHLC, но эти точки данных представляют собой значения индикатора RSI. Задержки, при которых они принимаются, задаются тремя входными параметрами, которые мы обозначили A, B и C. Набор данных заполняется следующим образом:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CSignalDBSCAN::GetOutput() { double _output = 0.0; ... RSI.Refresh(-1); for(int i = 0; i < m_set_size; i++) { for(int ii = 0; ii < m_key_size; ii++) { if(ii == 0) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i); } else if(ii == 1) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i + m_lag_a); } else if(ii == 2) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i + m_lag_a + m_lag_b); } else if(ii == 3) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i + m_lag_a + m_lag_b + m_lag_c); } } if(i > 0) //assign classifier only for data points for which eventual bar range is known { m_model.y[i - 1] = (m_close.GetData(StartIndex() + i - 1) - m_close.GetData(StartIndex() + i)) / m_symbol.Point(); } } int _o[]; ... ... return(_output); }
Итак, когда мы запускаем тесты для одного и того же символа за тот же период 2023 года на дневном интервале, мы получаем следующие результаты для нашего лучшего запуска:


Многообещающий отчет, но опять же требующий доработки. Все советники, собранные в этой статье, размещают сделки по лимитному ордеру и не используют тейк-профит или стоп-лосс для закрытия позиций. Это означает, что позиции удерживаются до тех пор, пока сигнал не развернется, а затем открывается новая позиция в обратном направлении.
Наконец, с помощью изменений скользящего среднего мы заполняли бы набор данных почти так же, как мы это делали с RSI. Основное отличие состоит в том, что здесь мы ищем изменения в показаниях индикатора скользящей средней, тогда как с RSI нас интересовали абсолютные значения. Еще одним важным отличием являются ключевые значения: размер вектора key в структуре Spoint составляет всего 3, а не 4, поскольку мы фокусируемся на изменениях задержки, а не на абсолютных показателях.
Выполнение тестовых запусков дает следующий отчет по наилучшему запуску.


Заключение
В заключение отметим, что DBSCAN — это неконтролируемый способ классификации данных, который принимает минимальные входные параметры, в отличие от более традиционных подходов, таких как k-средние. Методу необходимы лишь два параметра, из которых только один, эпсилон, является важным, что приводит к чрезмерной зависимости или чувствительности к этому входному параметру.
Несмотря на чрезмерную зависимость от эпсилона, тот факт, что для любой классификации количество кластеров определяется органически, делает метод достаточно универсальным для различных наборов данных и лучше справляется с шумом.
При применении в пользовательском экземпляре сигнального класса можно использовать самые разнообразные наборы входных данных, от необработанных цен до значений индикаторов, в качестве основы для классификации ценных бумаг.
Помимо создания собственного экземпляра класса Expert Signal, читатель может создавать аналогичные пользовательские реализации класса Expert Trailing или Expert Money, которые также используют DBSCAN, как мы рассматривали в предыдущих статьях этой серии.
Еще одно направление, на которое, по моему мнению, стоит обратить внимание (и то, для чего предназначены DBSCAN и кластеризация в целом) — это нормализация данных. Многие модели прогнозирования, как правило, требуют определенной формы нормализации любых входных данных, прежде чем их можно будет использовать в прогнозировании. Например, алгоритм случайного леса или нейронная сеть в идеале потребуют нормализованных данных, особенно если поток данных представляет собой цены на ценные бумаги. В модных сейчас больших языковых моделях, использующих архитектуру Трансформер (Transformer Architecture), эквивалентным шагом является эмбеддинг, где, по существу, всему тексту, включая числовые значения, повторно присваивается номер для целей прямой обработки через нейронную сеть. Без этой нормализации текста и чисел сеть не смогла бы эффективно обрабатывать огромные объемы данных при разработке алгоритмов ИИ. Также эта нормализация умеет работать с выбросами, которые могут усложнить дело при попытке обучить сеть и получить приемлемые веса и смещения. Думаю, при желании можно найти и другие подходящие варианты использования кластеризации и DBSCAN. Удачной охоты!
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/14489
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования