
Aplicando o método de Monte Carlo no aprendizado por reforço

Resumo do material anterior e aprimoramento do algoritmo
No artigo anterior, vimos o algoritmo Random Decision Forest e escrevemos um EA simples de autoaprendizagem baseado no aprendizado por reforço (em inglês, 'reinforcement learning').
Vimos as principais vantagens desta abordagem:
- fácil escrita do algoritmo de negociação e alta velocidade de aprendizagem. O aprendizado por reforço (doravante simplesmente AR) é facilmente incorporado a qualquer EA e acelera sua otimização.
Essa abordagem também tem uma grande desvantagem:
- O algoritmo é propenso a reotimização (reaprendizagem), isto é, mostra inclinação para a fraca generalização na população geral cuja distribuição de resultados é desconhecida. Isso significa que ele, em vez de buscar padrões de mercado característicos e reais de todo o período histórico do instrumento financeiro, é retreinado para aprender a situação atual do mercado, enquanto os padrões globais permanecem em conformidade com o nível de “compreensão” do agente treinado. No entanto, a otimização genética tem a mesma desvantagem e funciona muito mais lentamente quando existe um grande número de variáveis.
Existem duas técnicas para evitar a reaprendizagem:
- A 'feature ingeneering' ou criação de características. O principal objetivo dessa abordagem é a seleção de características e variáveis-alvo que descrevam toda a população com um baixo erro. Em outras palavras, trata-se de buscar regularidades plausíveis usando métodos estatísticos e econométricos através da iteração de preditores. Em mercados não estacionários, essa tarefa é bastante complicada e, para certas estratégias, insolúvel. No entanto, deve-se procurar escolher a estratégia ideal.
- A 'regularization' ou regularização é usada para tornar o modelo mais geral, alterando o nível do algoritmo usado. Para isso, no RDF é usado o parâmetro r. A regularização permite obter um equilíbrio de erros entre as amostras de aprendizagem e as de teste, aumentando a estabilidade do modelo em novos dados (quando é possível em princípio).
Abordagem aprimorada do aprendizado por reforço
As técnicas acima estão incluídas no algoritmo de uma maneira autêntica. Por um lado, o design das características é realizado buscando incrementos de preço e selecionando os melhores, por outro lado, são escolhidos modelos com o menor erro de classificação de dados novos fora da amostra ('out-of-bag') aprimorando o parâmetro r.
Além disso, há um novo recurso para simultaneamente criar vários agentes de AR que podem ser usados para definir diferentes configurações, o que, em teoria, deve aumentar a estabilidade do modelo nos novos dados. Os modelos são iterados no otimizador usando o método de Monte Carlo (amostragem aleatória de rótulos), e o melhor é salvo num arquivo para uso posterior.
Criando classe base CRLAgent
Por conveniência, a biblioteca é feita em POO, facilitando a conexão ao EA e a declaração do número necessário de agentes de AR.
Aqui descrevo alguns campos de classe para uma melhor compreensão da estrutura de interação dentro do programa.
//+------------------------------------------------------------------+ //|RL agent base class | //+------------------------------------------------------------------+ class CRLAgent { public: CRLAgent(string,int,int,int,double, double); ~CRLAgent(void); static int agentIDs; void updatePolicy(double,double&[]); //Atualizamos a política do aprendiz após cada trade void updateReward(); //Atualizamos a recompensa após o fechamento do trade double getTradeSignal(double&[]); //Obtemos o sinal de negociação de um agente instruído ou aleatoriamente int trees; double r; int features; double rferrors[], lastrferrors[]; string Name;
Os primeiros três métodos são usados para formar a política (estratégia) do aprendiz (agente), para atualizar as recompensas e para receber o sinal de negociação do agente treinado. Eles são descritos detalhadamente no primeiro artigo.
Além disso, são declarados campos auxiliares que definem as configurações de uma floresta aleatória, o número de atributos (variáveis de entrada), arrays para armazenar erros de modelo e o nome do agente (ou do grupo de agentes).
private: CMatrixDouble RDFpolicyMatrix; CDecisionForest RDF; CDFReport RDF_report; double RFout[]; int RDFinfo; int agentID; int numberOfsamples; void getRDFstructure(); double getLastProfit(); int getLastOrderType(); void RecursiveElimination(); double bestFeatures[][2]; int bestfeatures_num; double prob_shift; bool random; };
Em seguida, são declarados um arrray para salvar a política parametrizada do aprendiz, um objeto de floresta aleatória e um objeto auxiliar para armazenar erros.
Uma variável estática está presente para armazenar o identificador exclusivo do agente:
static int CRLAgent::agentIDs=0;
O construtor inicializa todas as variáveis antes de começar a trabalhar:
CRLAgent::CRLAgent(string AgentName,int number_of_features, int bestFeatures_number, int number_of_trees,double regularization, double shift_probability) { random=false; MathSrand(GetTickCount()); ArrayResize(rferrors,2); ArrayResize(lastrferrors,2); Name = AgentName; ArrayResize(RFout,2); trees = number_of_trees; r = regularization; features = number_of_features; bestfeatures_num = bestFeatures_number; prob_shift = shift_probability; if(bestfeatures_num>features) bestfeatures_num = features; ArrayResize(bestFeatures,1); numberOfsamples = 0; agentIDs++; agentID = agentIDs; getRDFstructure(); }
No final, o controle é passado para o método getRDFstructure(), que executa as seguintes ações:
//+------------------------------------------------------------------+ //|Load learned agent | //+------------------------------------------------------------------+ CRLAgent::getRDFstructure(void) { string path=_Symbol+(string)_Period+Name+"\\"; if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(FileIsExist(path+"RFlasterrors"+(string)agentID+".rl",FILE_COMMON)) { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,lastrferrors,0); FileClose(getRDF); } while (getRDF<0); } else { int getRDF; do { getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } while (getRDF<0); } return; } if(FileIsExist(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON)) { int getRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_READ|FILE_TXT|FILE_COMMON); CSerializer serialize; string RDFmodel=""; while(FileIsEnding(getRDF)==false) RDFmodel+=" "+FileReadString(getRDF); FileClose(getRDF); serialize.UStart_Str(RDFmodel); CDForest::DFUnserialize(serialize,RDF); serialize.Stop(); getRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,bestFeatures,0); FileClose(getRDF); getRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_READ|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(getRDF,rferrors,0); FileClose(getRDF); getRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); double arr[2]; ArrayInitialize(arr,1); FileWriteArray(getRDF,arr,0); FileClose(getRDF); } else random = true; }
Se o processo de otimização do EA estiver em execução, é verificada a presença de arquivos de erros registrados em iterações anteriores do otimizador. Assim, a cada nova iteração, são comparados os erros do modelo - para a seleção subsequente do mínimo.
Caso o EA seja iniciado no modo de teste, o modelo treinado é carregado a partir de arquivos para uso posterior. Além disso, os últimos erros do modelo são apagados e são definidos valores padrão iguais a um, para que o novo processo de otimização seja iniciado a partir de zero.
Após a próxima execução no otimizador, o aprendiz é treinado da seguinte maneira:
//+------------------------------------------------------------------+ //|Learn an agent | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination();
O controle é transferido para o método especificado, que é destinado à seleção sequencial de características, nomeadamente de incrementos de preço. Vejamos como funciona isso:
//+------------------------------------------------------------------+ //|Recursive feature elimitation for matrix inputs | //+------------------------------------------------------------------+ CRLAgent::RecursiveElimination(void) { //feature transformation, making every 2 features as returns with different lag's ArrayResize(bestFeatures,0); ArrayInitialize(bestFeatures,0); CDecisionForest mRDF; CMatrixDouble m; CDFReport mRep; m.Resize(RDFpolicyMatrix.Size(),3); int modelCounterInitial = 0; for(int bf=1;bf<features;bf++) { for(int i=0;i<RDFpolicyMatrix.Size();i++) { m[i].Set(0,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][bf]); //Preenchemos o array com incrementos (dividimos o preço de índice zero do array pele preço com deslocamento bf) m[i].Set(1,RDFpolicyMatrix[i][features]); m[i].Set(2,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),1,2,trees,r,RDFinfo,mRDF,mRep); //Treinamos uma floresta aleatória, em que o preditor é apenas o incremento selecionado ArrayResize(bestFeatures,ArrayRange(bestFeatures,0)+1); bestFeatures[modelCounterInitial][0] = mRep.m_oobrelclserror; //Salvamos o erro na amostra OOB bestFeatures[modelCounterInitial][1] = bf; //Salvamos o atraso de incremento modelCounterInitial++; } ArraySort(bestFeatures); //Classificamos o array (por dimensão zero), isto é, por erro de OOB ArrayResize(bestFeatures,bestfeatures_num); //Deixamos apenas as melhores caraterísticas bestfeatures_num m.Resize(RDFpolicyMatrix.Size(),2+ArrayRange(bestFeatures,0)); for(int i=0;i<RDFpolicyMatrix.Size();i++) { //Novamente preenchemos o array, agora com todas as melhores caraterísticas for(int l=0;l<ArrayRange(bestFeatures,0);l++) { m[i].Set(l,RDFpolicyMatrix[i][0]/RDFpolicyMatrix[i][(int)bestFeatures[l][1]]); } m[i].Set(ArrayRange(bestFeatures,0),RDFpolicyMatrix[i][features]); m[i].Set(ArrayRange(bestFeatures,0)+1,RDFpolicyMatrix[i][features+1]); } CDForest::DFBuildRandomDecisionForest(m,RDFpolicyMatrix.Size(),ArrayRange(bestFeatures,0),2,trees,r,RDFinfo,RDF,RDF_report); //Ensinamos as melhores caraterísticas selecionadas a uma floresta aleatória }
Vemos o método de aprendizagem do agente inteiramente:
//+------------------------------------------------------------------+ //|Learn an agent | //+------------------------------------------------------------------+ double CRLAgent::learnAnAgent(void) { if(MQLInfoInteger(MQL_OPTIMIZATION)) { if(numberOfsamples>0) { RecursiveElimination(); if(RDF_report.m_oobrelclserror<lastrferrors[1]) { string path=_Symbol+(string)_Period+Name+"\\"; //FileDelete(path+"RFmodel"+(string)agentID+".rl",FILE_COMMON); CSerializer serialize; serialize.Alloc_Start(); CDForest::DFAlloc(serialize,RDF); serialize.SStart_Str(); CDForest::DFSerialize(serialize,RDF); serialize.Stop(); int setRDF; do { setRDF=FileOpen(path+"RFlasterrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); if(setRDF<0) continue; lastrferrors[0]=RDF_report.m_relclserror; lastrferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,lastrferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"RFmodel"+(string)agentID+".rl",FILE_WRITE|FILE_TXT|FILE_COMMON); FileWrite(setRDF,serialize.Get_String()); FileClose(setRDF); setRDF=FileOpen(path+"RFerrors"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); rferrors[0]=RDF_report.m_relclserror; rferrors[1]=RDF_report.m_oobrelclserror; FileWriteArray(setRDF,rferrors,0); FileClose(setRDF); setRDF=FileOpen(path+"Kernel"+(string)agentID+".rl",FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileWriteArray(setRDF,bestFeatures); FileClose(setRDF); } while(setRDF<0); } } } return 1-RDF_report.m_oobrelclserror; }
Após a seleção de características ser concluída e o agente ser treinado, na corrida da otimização atual o erro de classificação do agente é comparado com o erro mínimo armazenado durante a otimização geral. Caso o erro do agente atual seja menor, o modelo atual é mantido como o melhor e as futuras comparações ocorrerão com o erro deste modelo.
Separadamente, devemos considerar o método de Monte Carlo, ou amostragem aleatória de variáveis-alvo:
//+------------------------------------------------------------------+ //|Get trade signal | //+------------------------------------------------------------------+ double CRLAgent::getTradeSignal(double &featuresValues[]) { double res=0.5; if(!MQLInfoInteger(MQL_OPTIMIZATION) && !random) { double kerfeatures[]; ArrayResize(kerfeatures,ArrayRange(bestFeatures,0)); ArrayInitialize(kerfeatures,0); for(int i=0;i<ArraySize(kerfeatures);i++) { kerfeatures[i] = featuresValues[0]/featuresValues[(int)bestFeatures[i][1]]; } CDForest::DFProcess(RDF,kerfeatures,RFout); return RFout[1]; } else { if(countOrders()==0) if(rand()/32767.0<0.5) res = 0; else res = 1; else { if(countOrders(0)!=0) if(rand()/32767.0>prob_shift) res = 0; else res = 1; if(countOrders(1)!=0) if(rand()/32767.0<prob_shift) res = 0; else res = 1; } } return res; }
Se o EA não estiver no modo de otimização, para receber os sinais de negociação é usado o modelo já treinado carregado ao iniciar o EA. Caso contrário, se o processo de otimização estiver em progresso ou se não houver arquivos de modelo, os sinais ocorrem aleatoriamente caso não haja posições abertas (50/50) e com uma probabilidade de deslocamento dada pela variável prob_shift caso haja ordens abertas. Assim, por exemplo, caso já exista um trade aberto, você pode mudar a probabilidade de surgimento de sinal de venda para 0,1 (em vez de 0,5), assim, o número total de amostras no conjunto de aprendizagem diminui e as posições são mantidas por mais tempo. Além disso, ao definir prob_shift >= 0.5, o número de trades aumenta.
Criando a classe CRLAgents
Agora podemos ter muitos agentes (aprendizes) realizando várias tarefas no sistema de negociação. Esta classe é fornecida para gerenciar grupos de aprendizes homogêneos facilmente.
//+------------------------------------------------------------------+ //|Multiple RL agents class | //+------------------------------------------------------------------+ class CRLAgents { private: struct Agents { double inpVector[]; CRLAgent *ag; double rms; double oob; }; void getStatistics(); string groupName; public: CRLAgents(string,int,int,int,int,double,double); ~CRLAgents(void); Agents agent[]; void updatePolicies(double); void updateRewards(); double getTradeSignal(); double learnAllAgents(); void setAgentSettings(int,int,int,double); };
A estrutura Agents aceita os parâmetros de cada aprendiz, enquanto o array de estruturas contém seu número total. Caso haja apenas um agente, também faz sentido usar essa classe.
O construtor usa todos os parâmetros de aprendizagem necessários:
CRLAgents::CRLAgents(string AgentsName,int agentsQuantity,int features, int bestfeatures, int treesNumber,double regularization, double shift_probability) { groupName=AgentsName; ArrayResize(agent,agentsQuantity); for(int i=0;i<agentsQuantity;i++) { ArrayResize(agent[i].inpVector,features); ArrayInitialize(agent[i].inpVector,0); agent[i].ag = new CRLAgent(AgentsName, features, bestfeatures, treesNumber, regularization, shift_probability); agent[i].rms = agent[i].ag.rferrors[0]; agent[i].oob = agent[i].ag.rferrors[1]; } }
Entre eles, o nome do grupo de agentes, o número de trabalhadores, o número de características para cada trabalhador, o número de melhores sinais selecionados, o número de árvores na floresta, o parâmetro de regularização (separação em amostras de teste e de aprendizagem) e o desvio de probabilidade para controlar o número de trades.
Pode ser visto que os objetos dos aprendizes com as mesmas variáveis de entrada, assim como os erros de aprendizagem e do teste, são colocados no array de estruturas.
O método de treinamento de agentes chama o método de aprendizagem para cada classe base CRLAgent e retorna o erro médio na amostra de teste para todos os agentes:
//+------------------------------------------------------------------+ //|Learn all agents | //+------------------------------------------------------------------+ double CRLAgents::learnAllAgents(void){ double err=0; for(int i=0;i<ArraySize(agent);i++) err+=agent[i].ag.learnAnAgent(); return err/ArraySize(agent); }
Este erro é usado como um critério de otimização customizado para simplesmente visualizar o erro espalhado na iteração do modelo de Monte Carlo.
Como ao criar certo número de aprendizes num subgrupo suas configurações permanecem as mesmas, existe um método para ajustar os parâmetros de cada aprendiz:
//+------------------------------------------------------------------+ //|Change agents settings | //+------------------------------------------------------------------+ CRLAgents::setAgentSettings(int agentNumber,int features,int bestfeatures,int treesNumber,double regularization,double shift_probability) { agent[agentNumber].ag.features=features; agent[agentNumber].ag.bestfeatures_num=bestfeatures; agent[agentNumber].ag.trees=treesNumber; agent[agentNumber].ag.r=regularization; agent[agentNumber].ag.prob_shift=shift_probability; ArrayResize(agent[agentNumber].inpVector,features); ArrayInitialize(agent[agentNumber].inpVector,0); }
Ao contrário da classe base CRLAgent, na CRLAgents o sinal de negociação é exibido como a média dos sinais de todos os aprendizes pertencentes ao subgrupo:
//+------------------------------------------------------------------+ //|Get common trade signal | //+------------------------------------------------------------------+ double CRLAgents::getTradeSignal() { double signal[]; double sig=0; ArrayResize(signal,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) sig+=signal[i]=agent[i].ag.getTradeSignal(agent[i].inpVector); return sig/(double)ArraySize(agent); }
Finalmente, o método para obter estatísticas exibe informações sobre o erro de teste e aprendizagem de todos os agentes no final de uma única execução no testador:
//+------------------------------------------------------------------+ //|Get agents statistics | //+------------------------------------------------------------------+ void CRLAgents::getStatistics(void) { double arr[]; double arrrms[]; ArrayResize(arr,ArraySize(agent)); ArrayResize(arrrms,ArraySize(agent)); for(int i=0;i<ArraySize(agent);i++) { arrrms[i]=agent[i].rms; arr[i]=agent[i].oob; } Print(groupName+" TRAIN LOSS"); ArrayPrint(arrrms); Print(groupName+" OOB LOSS"); ArrayPrint(arr); }
Criando um robô de negociação baseado na biblioteca AR Monte Carlo
Resta escrever um EA simples para demonstrar as capacidades da biblioteca. Comecemos com o primeiro caso, quando é criado apenas um agente que estuda os preços de fechamento de um instrumento de negociação.
#include <RL Monte Carlo.mqh>
input int number_of_passes = 10; input double shift_probab = 0,5; input double regularize=0.6; sinput int number_of_best_features = 5; sinput double treshhold = 0.5; sinput double MaximumRisk=0.01; sinput double CustomLot=0; CRLAgents *ag1=new CRLAgents("RlMonteCarlo",1,500,number_of_best_features,50,regularize,shift_probab);
Conectamos a biblioteca e definimos inputs que podem ser otimizadas. number_of_passes se destina a determinar o número de passagens no otimizador do terminal e não é transmitido para nenhum lugar. Como as entradas e saídas são escolhidas aleatoriamente pelo trabalhador, é possível alcançar uma estratégia ótima usando múltiplas passagens e determinando o menor erro. Quanto mais passagens forem definidas, maior a probabilidade de obter uma estratégia ótima.
As configurações restantes já foram descritas acima e são transmitidas diretamente para o modelo que foi criado acima. Aqui criamos um agente pertencente ao grupo "RlMonteCarlo", 500 sinais são servidos como entrada, 5 deles são selecionados como os melhores sinais. O modelo tem 50 árvores de decisão, com uma separação de amostras de teste e de aprendizagem de 0,6 r), sem desvio de probabilidade.
Na função OnTester, retornamos o critério de otimização customizado (na forma do erro médio na amostra de teste para todos os aprendizes), tendo sido previamente treinados:
//+------------------------------------------------------------------+ //| Expert ontester function | //+------------------------------------------------------------------+ double OnTester() { if(MQLInfoInteger(MQL_OPTIMIZATION)) return ag1.learnAllAgents(); else return NULL; }
Quando um EA é desinicializado, são excluídos os usuários e é liberada memória:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { delete ag1; }
O vetor de preditores é preenchido da seguinte maneira:
//+------------------------------------------------------------------+ //| Calculate Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
Nesse caso, basta pegar os últimos 500 preços de fechamento. Lembremos que o preditor no modelo é a razão entre o elemento zero do array e outro (com certo atraso), por isso, vamos configurar um array aceitando preços de fechamento, as series. Depois disso, é chamado o método para receber o sinal de negociação.
A última função é de negociação:
//+------------------------------------------------------------------+ //| Place orders | //+------------------------------------------------------------------+ void placeOrders() { for(int b=OrdersTotal()-1; b>=0; b--) if(OrderSelect(b,SELECT_BY_POS)==true) { if(OrderType()==0 && Tsignal>0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} if(OrderType()==1 && Tsignal<0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) {ag1.updateRewards();} } if(countOrders(0)!=0 || countOrders(1)!=0) return; if(Tsignal<0.5-treshhold && (OrderSend(Symbol(),OP_BUY,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } if(Tsignal>0.5+treshhold && (OrderSend(Symbol(),OP_SELL,lotsOptimized(),SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,INT_MIN)>0)) { ag1.updatePolicies(Tsignal); } }
Além disso, é introduzido o parâmetro limiar (treshold), o que permite definir o limite para o acionamento do sinal. Por exemplo, se a probabilidade de um sinal de compra for menor do que 0,6, a ordem não será aberta.
Otimizando o EA RL Monte Carlo Trader
Vejamos as configurações que podem ser otimizadas:
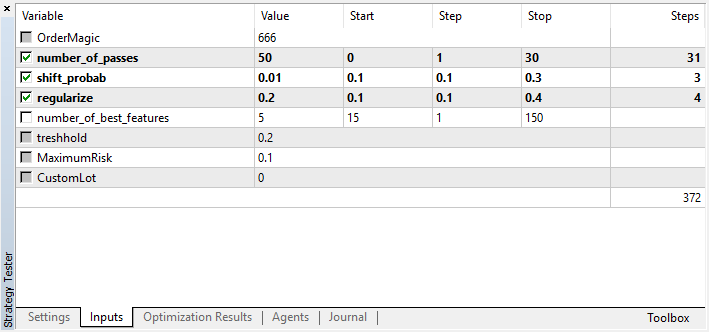
Lembremos que number_of_passes não transfere nenhum valor para o aprendiz, mas simplesmente define o número de passagens do otimizador. Suponhamos que tenhamos decidido sobre outras configurações e que agora queiramos usar exclusivamente a iteração pelo método de Monte Carlo, sendo assim, devemos otimizar apenas por este critério. As quatro configurações restantes podem ser otimizadas conforme desejado.
Outra característica da versão atual é que não há necessidade de desabilitar os agentes de teste, uma vez que as passagens no otimizador são independentes uns das outras e a sequência para salvar modelos não é importante.
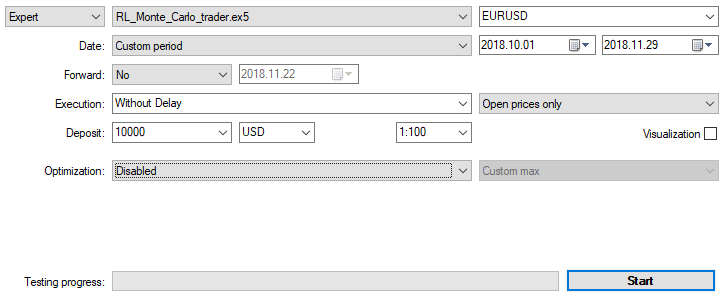
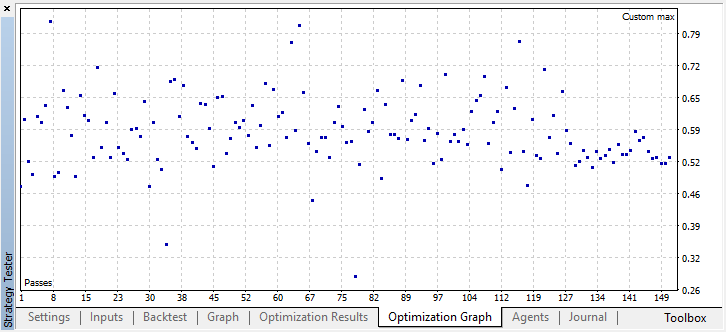
Otimizamos o EA com as configurações mencionadas acima num gráfico de 15 minutos por dois meses, com base nos preços de abertura. Como critério de otimização, deve ser selecionado o "Critério personalizado máximo". O processo de otimização pode ser interrompido a qualquer momento quando é atingido um valor aceitável para o critério de otimização:
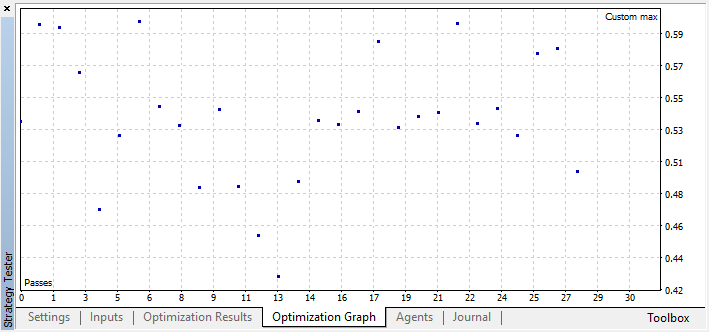
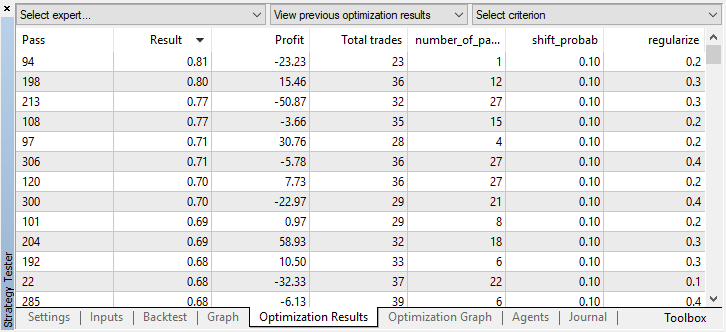
Por exemplo, parei o processo de otimização na etapa 44, porque um dos melhores modelos excedeu o limite de precisão de 0,6. Isto significa que o erro de classificação na amostra de teste caiu abaixo de 0,4. Vale a pena considerar que quanto melhor o modelo, menor o erro, mas para o funcionamento correto do algoritmo genético (se você quiser usá-lo), os valores de erro são invertidos.
Você pode verificar as configurações do melhor modelo na guia "otimização" classificando os valores pelo máximo do critério do usuário:
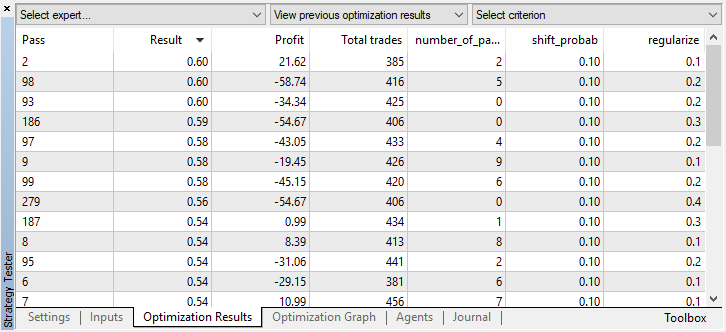
Neste caso, o melhor modelo é obtido com um desvio de probabilidade de 0.1 e com um parâmetro r de 0,2 (a amostra de aprendizagem é apenas 20% de todo o array de trades, enquanto 80% é uma subamostra de teste).
Após parar a otimização, basta ativar o modo de teste único (já que o melhor modelo é gravado no arquivo e somente ele será carregado):
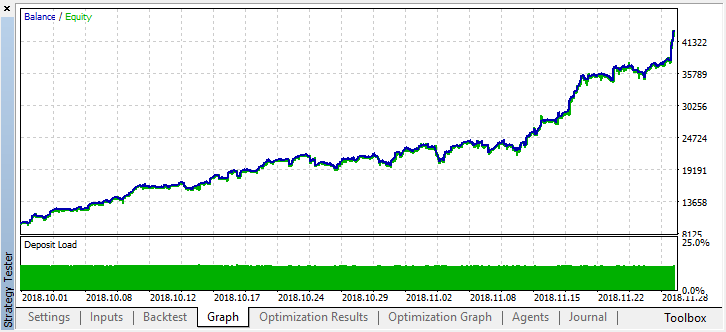
Voltemos atrás no histórico dois meses e vejamos como o modelo funciona durante quatro meses:
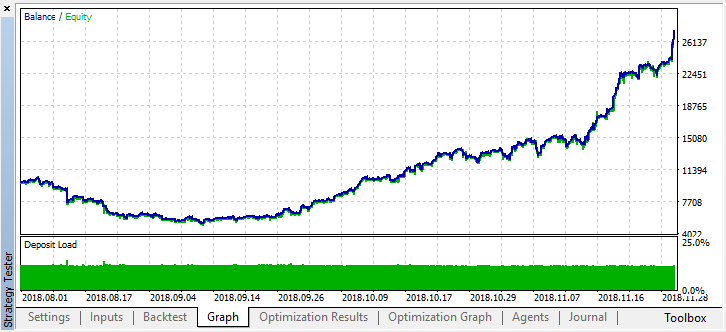
Pode ser visto que o modelo resultante dura mais um mês (quase todo o mês de setembro), mas em agosto ele quebra. Vamos tentar melhorar o modelo, definindo o limiar "treshhold" como 0,2:
Torna-se visivelmente melhor, com uma diminuição no número de trades, a precisão do modelo aumentou. Pode-se realizar um teste de maior profundidade, se levado em consideração que o período de aprendizagem tenha o comprimento apropriado.
Passamos à variante do EA em que são adicionados vários aprendizes, para comparar a eficácia da abordagem multi-agente com a de um único agente.
Para fazer isso, ao criar um grupo de agentes, adicionamos o final “Multi” para que os arquivos de sistemas diferentes não sejam misturados e especificamos o número de trabalhadores, por exemplo, cinco:
CRLAgents *ag1=new CRLAgents("RlMonteCarloMulti",5,500,number_of_best_features,50,regularize,shift_probab);
Mas todos os agentes acabam sendo os mesmos (eles têm configurações idênticas). Você pode configurar cada trabalhador separadamente na função de inicialização do EA:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ag1.setAgentSettings(0,500,20,50,regularize,shift_probab); ag1.setAgentSettings(1,200,15,50,regularize,shift_probab); ag1.setAgentSettings(2,100,10,50,regularize,shift_probab); ag1.setAgentSettings(3,50,5,50,regularize,shift_probab); ag1.setAgentSettings(4,25,2,50,regularize,shift_probab); return(INIT_SUCCEEDED); }
Aqui eu decidi não me perder em sutilezas para que eu não ficar completamente confuso, em vez disso, simplesmente organizei o número de caraterísticas para os agentes em ordem decrescente, de 500 para 25. Além disso, o número dos melhores caraterísticas selecionadas diminui de 20 para dois. As outras configurações não são alteradas, mas você pode alterá-las e adicionar novos parâmetros de otimização. Espero que os próprios leitores experimentem isso e compartilhem os resultados nos comentários deste artigo..
Lembremos que o preenchimento dos arrays com os valores do preditor é realizado na função:
//+------------------------------------------------------------------+ //| Calculate Tsignal | //+------------------------------------------------------------------+ void calcTsignal() { Tsignal=0; for(int i=0;i<ArraySize(ag1.agent);i++) { CopyClose(_Symbol,0,1,ArraySize(ag1.agent[i].inpVector),ag1.agent[i].inpVector); ArraySetAsSeries(ag1.agent[i].inpVector,true); } Tsignal=ag1.getTradeSignal(); }
Aqui nós simplesmente preenchemos o array inpVector com os preços de fechamento para cada aprendiz, dependendo do seu tamanho, portanto a função é universal para este caso e não precisa ser alterada.
Executamos a otimização exatamente com as mesmas configurações de um único agente:
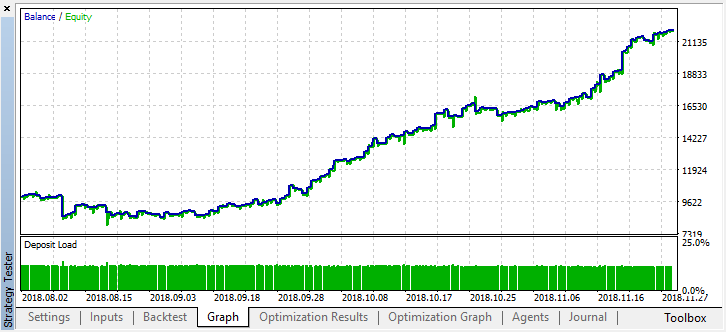
O melhor resultado ultrapassou 0,7, o que é muito melhor do que no primeiro caso. Executamos uma única execução no testador:
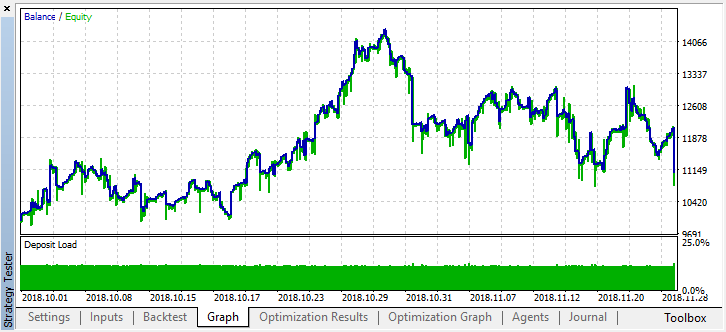
Ao mesmo tempo, no gráfico do saldo, o resultado real se tornou muito pior, por que isso aconteceu? Vejamos o número de trades aleatórios da melhor execução, existem apenas 21!
Aconteceu dessa maneira porque, com a amostragem aleatória, os sinais de vários agentes se sobrepõem e o número total de trades diminui. Para corrigir isso, é preciso definir o parâmetro shift_probab mais próximo de 0,5, neste caso o número de trades para cada agente individual é maior, enquanto o número total de trades também aumenta. Por outro lado, pode-se simplesmente aumentar o período de aprendizagem, mas primeiro veremos se é possível trabalhar ainda mais com tal modelo. Definimos "treshhold" como 0,2 e vejamos o que acontece:
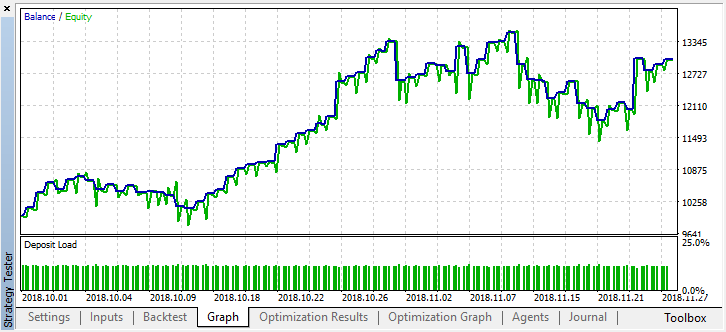
Pelo menos, o modelo não leva à perda de dinheiro, embora o número de trades diminua. Observe que, após uma única execução, os erros são enviados para o log do testador se você os esquecer de repente:
2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo TRAIN LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.02703 0.20000 0.09091 0.05714 0.14286 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 RlMonteCarlo OOB LOSS 2018.11.30 01:56:40.441 Core 2 2018.11.28 23:59:59 0.21622 0.23333 0.21212 0.17143 0.19048
Agora vamos testar esse modelo desde o começo do ano. Os resultados são razoavelmente estáveis:
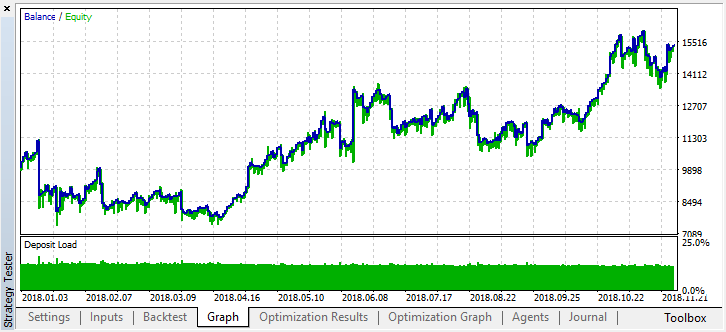
Bem, definimos shift_probab, digamos, como 0,3, e executamos o otimizador sem esse parâmetro, para os mesmos 2 meses em 15 minutos (simplesmente tentamos encontrar o equilíbrio no número de trades):
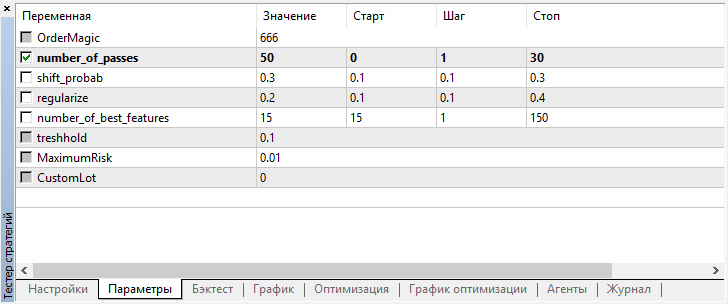
Não torturo meu laptop, pois a complexidade dos cálculos aumenta um pouco e, após várias iterações no otimizador, fico satisfeito com esse resultado:
2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti TRAIN LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.13229 0.16667 0.16262 0.14599 0.20937 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 RlMonteCarloMulti OOB LOSS 2018.11.30 02:53:17.236 Core 2 2018.11.28 23:59:59 0.45377 0.45758 0.44650 0.45693 0.46120
O erro no OOB (amostra de teste) permanece bastante alto, no entanto, com um limiar de 0,2, durante 4 meses, o modelo mostra um lucro, embora se comporte bastante instável nos dados do teste.
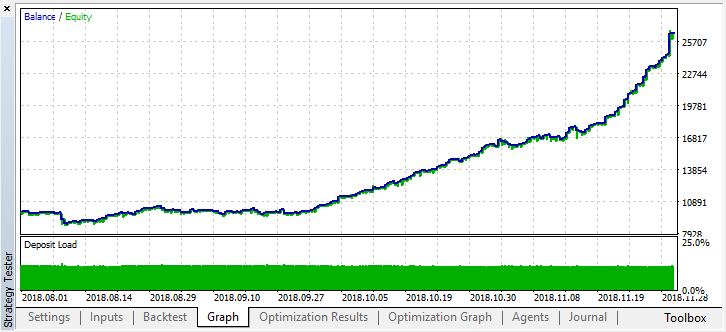
Deve ser entendido que todos os aprendizes são treinados nos mesmos dados, isto é, em preços de fechamento, portanto, não há muito sentido em adicionar novos. No entanto, este é um exemplo simples de como adicionar novos agentes.
Conclusões do trabalho realizado
O aprendizado por reforço é talvez um dos métodos mais interessantes de aprendizado de máquina. É sempre tentador pensar que a inteligência artificial é capaz de resolver os problemas da negociação nos mercados financeiros, ao mesmo tempo que aprende por si mesma, sem a ajuda de professor. Por outra parte, para usá-la, deve-se ter um amplo conhecimento de aprendizado de máquina, de estatística e de teoria da probabilidade. Note que o método de Monte Carlo e a seleção do modelo pelo menor erro com base nos dados do teste melhoraram significativamente o modelo proposto no primeiro artigo, pois o modelo começou a retreinar-se menos.
Lembre que é necessário escolher o melhor modelo - quanto ao número de trades e ao menor erro de classificação - na amostra 'out-of-bag'. Idealmente, os erros nas amostras de aprendizagem e nas de teste devem ser aproximadamente iguais e não atingir um valor de 0,5 (metade dos exemplos é incorretamente prevista).
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/4777
 Analisando resultados de negociação usando relatórios HTML
Analisando resultados de negociação usando relatórios HTML
 Uso Prático das Redes Neurais de Kohonen na Negociação Algorítmica. Parte II. Otimização e previsão
Uso Prático das Redes Neurais de Kohonen na Negociação Algorítmica. Parte II. Otimização e previsão
 Uso Prático das Redes Neurais de Kohonen na Negociação Algorítmica. Parte I. Ferramentas
Uso Prático das Redes Neurais de Kohonen na Negociação Algorítmica. Parte I. Ferramentas