O Método de Agrupamento de Manipulação de Dados: Implementando o Algoritmo Combinatório em MQL5

Introdução
O algoritmo combinatório do GMDH, frequentemente chamado de COMBI, é a forma básica do GMDH e serve como base para algoritmos mais complexos dentro da família. Assim como o Algoritmo Iterativo em Camadas Múltiplas (MIA), ele opera em uma amostra de dados de entrada representada como uma matriz contendo observações sobre um conjunto de variáveis. A amostra de dados é dividida em duas partes: uma amostra de treinamento e uma amostra de teste. A subamostra de treinamento é usada para estimar os coeficientes do polinômio, enquanto a subamostra de teste é usada para selecionar a estrutura do modelo ideal com base no valor mínimo do critério selecionado. Neste artigo, descreveremos o cálculo do algoritmo COMBI. Além disso, apresentaremos sua implementação em MQL5, estendendo a classe "GmdhModel" descrita no artigo anterior. Mais adiante, também discutiremos o algoritmo Combinatório Seletivo, intimamente relacionado, e sua implementação em MQL5. E, finalmente, concluiremos fornecendo uma aplicação prática dos algoritmos GMDH, construindo modelos preditivos para o preço diário do Bitcoin.
O algoritmo COMBI
A diferença fundamental entre o MIA e o COMBI está em sua estrutura de rede. Ao contrário da natureza em camadas do MIA, o COMBI é caracterizado por uma única camada.

O número de nós nessa camada é determinado pelo número de entradas. Onde cada nó representa um modelo candidato definido por uma ou mais de todas as entradas. Para ilustrar, vamos considerar um exemplo de um sistema que queremos modelar, definido por 2 variáveis de entrada. Aplicando o algoritmo COMBI, todas as combinações possíveis dessas variáveis são usadas para construir um modelo candidato. O número de combinações possíveis é dado por:

onde:
- m representa o número de variáveis de entrada.
Para cada uma dessas combinações, um modelo candidato é gerado. Os modelos candidatos avaliados nos nós da primeira e única camada são dados por:

onde:
- 'a' são os coeficientes, 'a1' é o primeiro coeficiente e 'a2' é o segundo.
- 'x' são as variáveis de entrada, 'x1' representando a primeira variável de entrada ou preditor e 'x2' é a segunda.
O processo envolve a resolução de um sistema de equações lineares para derivar estimativas dos coeficientes de um modelo candidato. Critérios de desempenho de cada modelo são usados para selecionar o modelo final que melhor descreve os dados.
Implementação do COMBI em MQL5
O código que implementa o algoritmo COMBI depende da classe base GmdhModel descrita no artigo anterior. Ele também depende de uma classe intermediária chamada LinearModel, declarada em linearmodel.mqh. Que encapsula a característica mais fundamental que distingue o método COMBI. O fato de que os modelos COMBI são exclusivamente lineares.
//+------------------------------------------------------------------+ //| linearmodel.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "gmdh.mqh" //+------------------------------------------------------------------+ //| Class implementing the general logic of GMDH linear algorithms | //+------------------------------------------------------------------+ class LinearModel:public GmdhModel { protected: vector calculatePrediction(vector& x) { if(x.Size()<ulong(inputColsNumber)) return vector::Zeros(ulong(inputColsNumber)); matrix modifiedX(1,x.Size()+ 1); modifiedX.Row(x,0); modifiedX[0][x.Size()] = 1.0; vector comb = bestCombinations[0][0].combination(); matrix xx(1,comb.Size()); for(ulong i = 0; i<xx.Cols(); ++i) xx[0][i] = modifiedX[0][ulong(comb[i])]; vector c,b; c = bestCombinations[0][0].bestCoeffs(); b = xx.MatMul(c); return b; } virtual matrix xDataForCombination(matrix& x, vector& comb) override { matrix out(x.Rows(), comb.Size()); for(ulong i = 0; i<out.Cols(); i++) out.Col(x.Col(int(comb[i])),i); return out; } virtual string getPolynomialPrefix(int levelIndex, int combIndex) override { return "y="; } virtual string getPolynomialVariable(int levelIndex, int coeffIndex, int coeffsNumber, vector& bestColsIndexes) override { return ((coeffIndex != coeffsNumber - 1) ? "x" + string(int(bestColsIndexes[coeffIndex]) + 1) : ""); } public: LinearModel(void) { } vector predict(vector& x, int lags) override { if(lags <= 0) { Print(__FUNCTION__," lags value must be a positive integer"); return vector::Zeros(1); } if(!training_complete) { Print(__FUNCTION__," model was not successfully trained"); return vector::Zeros(1); } vector expandedX = vector::Zeros(x.Size() + ulong(lags)); for(ulong i = 0; i<x.Size(); i++) expandedX[i]=x[i]; for(int i = 0; i < lags; ++i) { vector vect(x.Size(),slice,expandedX,ulong(i),x.Size()+ulong(i)-1); vector res = calculatePrediction(vect); expandedX[x.Size() + i] = res[0]; } vector vect(ulong(lags),slice,expandedX,x.Size()); return vect; } }; //+------------------------------------------------------------------+
O arquivo combi.mqh contém a definição da classe COMBI. Ela herda de LinearModel e define os métodos "fit()" para ajustar um modelo.
//+------------------------------------------------------------------+ //| combi.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "linearmodel.mqh" //+------------------------------------------------------------------+ //| Class implementing combinatorial COMBI algorithm | //+------------------------------------------------------------------+ class COMBI:public LinearModel { private: Combination getBest(CVector &combinations) { double proxys[]; int best[]; ArrayResize(best,combinations.size()); ArrayResize(proxys,combinations.size()); for(int k = 0; k<combinations.size(); k++) { best[k]=k; proxys[k]=combinations[k].evaluation(); } MathQuickSortAscending(proxys,best,0,int(proxys.Size()-1)); return combinations[best[0]]; } protected: virtual void removeExtraCombinations(void) override { CVector2d realBestCombinations; CVector n; Combination top; for(int i = 0 ; i<bestCombinations.size(); i++) { top = getBest(bestCombinations[i]); n.push_back(top); } top = getBest(n); CVector sorted; sorted.push_back(top); realBestCombinations.push_back(sorted); bestCombinations = realBestCombinations; } virtual bool preparations(SplittedData &data, CVector &_bestCombinations) override { lastLevelEvaluation = DBL_MAX; return (bestCombinations.push_back(_bestCombinations) && ulong(level+1) < data.xTrain.Cols()); } void generateCombinations(int n_cols,vector &out[]) override { GmdhModel::nChooseK(n_cols,level,out); return; } public: COMBI(void):LinearModel() { modelName = "COMBI"; } bool fit(vector &time_series,int lags,double testsize=0.5,CriterionType criterion=stab) { if(lags < 1) { Print(__FUNCTION__," lags must be >= 1"); return false; } PairMVXd transformed = timeSeriesTransformation(time_series,lags); SplittedData splited = splitData(transformed.first,transformed.second,testsize); Criterion criter(criterion); int pAverage = 1; double limit = 0; int kBest = pAverage; if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } bool fit(matrix &vars,vector &targets,double testsize=0.5,CriterionType criterion=stab) { if(vars.Cols() < 1) { Print(__FUNCTION__," columns in vars must be >= 1"); return false; } if(vars.Rows() != targets.Size()) { Print(__FUNCTION__, " vars dimensions donot correspond with targets"); return false; } SplittedData splited = splitData(vars,targets,testsize); Criterion criter(criterion); int pAverage = 1; double limit = 0; int kBest = pAverage; if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } }; //+------------------------------------------------------------------+
Usando a classe COMBI
Ajustar um modelo a um conjunto de dados usando a classe COMBI é exatamente igual a aplicar a classe MIA. Criamos uma instância e chamamos um dos métodos "fit()". Isso é demonstrado nos scripts COMBI_test.mq5 e COMBI_Multivariable_test.mq5.
//+------------------------------------------------------------------+ //| COMBI_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\combi.mqh> input int NumLags = 2; input int NumPredictions = 6; input CriterionType critType = stab; input double DataSplitSize = 0.33; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector tms = {1,2,3,4,5,6,7,8,9,10,11,12}; if(NumPredictions<1) { Alert("Invalid setting for NumPredictions, has to be larger than 0"); return; } COMBI combi; if(!combi.fit(tms,NumLags,DataSplitSize,critType)) return; string modelname = combi.getModelName()+"_"+EnumToString(critType)+"_"+string(DataSplitSize); combi.save(modelname+".json"); vector in(ulong(NumLags),slice,tms,tms.Size()-ulong(NumLags)); vector out = combi.predict(in,NumPredictions); Print(modelname, " predictions ", out); Print(combi.getBestPolynomial()); } //+------------------------------------------------------------------+
Ambos aplicam o algoritmo COMBI aos mesmos conjuntos de dados usados nos scripts de exemplo que demonstram como aplicar o algoritmo MIA de um artigo anterior.
//+------------------------------------------------------------------+ //| COMBI_Multivariable_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\combi.mqh> input CriterionType critType = stab; input double DataSplitSize = 0.33; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- matrix independent = {{1,2,3},{3,2,1},{1,4,2},{1,1,3},{5,3,1},{3,1,9}}; vector dependent = {6,6,7,5,9,13}; COMBI combi; if(!combi.fit(independent,dependent,DataSplitSize,critType)) return; string modelname = combi.getModelName()+"_"+EnumToString(critType)+"_"+string(DataSplitSize)+"_multivars"; combi.save(modelname+".json"); matrix unseen = {{8,6,4},{1,5,3},{9,-5,3}}; for(ulong row = 0; row<unseen.Rows(); row++) { vector in = unseen.Row(row); Print("inputs ", in, " prediction ", combi.predict(in,1)); } Print(combi.getBestPolynomial()); } //+------------------------------------------------------------------+
Observando a saída do COMBI_test.mq5, podemos comparar a complexidade do polinômio ajustado com o produzido pelo algoritmo MIA. Abaixo estão os polinômios para a série temporal e o conjunto de dados multivariável, respectivamente.
LR 0 14:54:15.354 COMBI_test (BTCUSD,D1) COMBI_stab_0.33 predictions [13,14,15,16,17,18.00000000000001] PN 0 14:54:15.355 COMBI_test (BTCUSD,D1) y= 1.000000e+00*x1 + 2.000000e+00 CI 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [8,6,4] prediction [18.00000000000001] QD 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [9] QQ 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [9,-5,3] prediction [7.00000000000001] MM 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) y= 1.000000e+00*x1 + 1.000000e+00*x2 + 1.000000e+00*x3 - 7.330836e-15
A seguir estão os polinômios revelados pelo método MIA.
JQ 0 14:43:07.969 MIA_Test (Step Index 500,M1) MIA_stab_0.33_1_0.0 predictions [13.00000000000001,14.00000000000002,15.00000000000004,16.00000000000005,17.0000000000001,18.0000000000001] IP 0 14:43:07.969 MIA_Test (Step Index 500,M1) y = - 9.340179e-01*x1 + 1.934018e+00*x2 + 3.865363e-16*x1*x2 + 1.065982e+00 II 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [1,2,4] prediction [6.999999999999998] CF 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [8.999999999999998] JR 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [9,1,3] prediction [13.00000000000001] NP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_1 = 1.071429e-01*x1 + 6.428571e-01*x2 + 4.392857e+00 LR 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_2 = 6.086957e-01*x2 - 8.695652e-02*x3 + 4.826087e+00 ME 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_3 = - 1.250000e+00*x1 - 1.500000e+00*x3 + 1.125000e+01 DJ 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) IP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_1 = 1.555556e+00*f1_1 - 6.666667e-01*f1_3 + 6.666667e-01 ER 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_2 = 1.620805e+00*f1_2 - 7.382550e-01*f1_3 + 7.046980e-01 ES 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_3 = 3.019608e+00*f1_1 - 2.029412e+00*f1_2 + 5.882353e-02 NH 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) CN 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f3_1 = 1.000000e+00*f2_1 - 3.731079e-15*f2_3 + 1.155175e-14 GP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f3_2 = 8.342665e-01*f2_2 + 1.713326e-01*f2_3 - 3.359462e-02 DO 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) OG 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) y = 1.000000e+00*f3_1 + 3.122149e-16*f3_2 - 1.899249e-15
O modelo MIA é convoluto, enquanto o modelo COMBI é menos complicado, muito semelhante à própria série. Isso reflete a natureza linear do método. Isso também é confirmado pela saída do script COMBI_Multivariable_test.mq5, que representa uma tentativa de construir um modelo para somar 3 números juntos, fornecendo variáveis de entrada e exemplos de saídas correspondentes. Aqui, o algoritmo COMBI conseguiu deduzir com sucesso as características subjacentes do sistema.
A busca exaustiva do algoritmo COMBI é tanto uma vantagem quanto uma desvantagem. Por um lado positivo, avaliar todas as combinações das entradas garante que o polinômio ideal que descreve os dados seja encontrado. No entanto, se houver muitas variáveis de entrada, essa busca extensa pode se tornar computacionalmente cara. Possivelmente resultando em longos tempos de treinamento. Lembre-se de que o número de modelos candidatos é dado por 2 elevado à potência m, menos 1. Quanto maior for m, maior será o número de modelos candidatos que precisam ser avaliados. O algoritmo Combinatório Seletivo foi desenvolvido para resolver esse problema.
O Algoritmo Combinatório Seletivo
O Algoritmo Combinatório Seletivo, que chamaremos de MULTI, é apresentado como uma melhoria do método COMBI, em termos de eficiência. Uma busca exaustiva é evitada empregando procedimentos semelhantes aos usados em algoritmos em camadas múltiplas do GMDH. Portanto, pode ser visto como uma abordagem em camadas múltiplas da natureza de camada única do algoritmo COMBI.

Na primeira camada, todos os modelos contendo uma das variáveis de entrada são estimados, sendo o melhor selecionado de acordo com o critério externo e passado para a próxima camada. Nas camadas subsequentes, diferentes variáveis de entrada são selecionadas e adicionadas a esses modelos candidatos, com a esperança de melhorá-los. Novas camadas são adicionadas dessa maneira, dependendo de haver algum aumento na precisão na estimativa das saídas e/ou, na disponibilidade de variáveis de entrada que ainda não fazem parte de um modelo candidato. Isso significa que o número máximo de camadas possíveis coincide com o número total de variáveis de entrada.
Avaliar modelos candidatos dessa maneira frequentemente leva à evitação de uma busca exaustiva, mas também introduz um problema. Existe a possibilidade de que o algoritmo não encontre o polinômio ideal que melhor descreve o conjunto de dados. Uma indicação de que mais modelos candidatos deveriam ter sido considerados na fase de treinamento. Deduzir o polinômio ideal torna-se uma questão de ajuste cuidadoso de hiperparâmetros. Particularmente, o número de modelos candidatos que são avaliados em cada camada.
Implementando o Algoritmo Combinatório Seletivo
A implementação do algoritmo combinatório seletivo é fornecida em multi.mqh. Ele contém a definição da classe MULTI, que herda de LinearModel.
//+------------------------------------------------------------------+ //| multi.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "linearmodel.mqh" //+------------------------------------------------------------------+ //| Class implementing combinatorial selection MULTI algorithm | //+------------------------------------------------------------------+ class MULTI : public LinearModel { protected: virtual void removeExtraCombinations(void) override { CVector2d realBestCombinations; CVector n; n.push_back(bestCombinations[0][0]); realBestCombinations.push_back(n); bestCombinations = realBestCombinations; } virtual bool preparations(SplittedData &data, CVector &_bestCombinations) override { return (bestCombinations.setAt(0,_bestCombinations) && ulong(level+1) < data.xTrain.Cols()); } void generateCombinations(int n_cols,vector &out[]) override { if(level == 1) { nChooseK(n_cols,level,out); return; } for(int i = 0; i<bestCombinations[0].size(); i++) { for(int z = 0; z<n_cols; z++) { vector comb = bestCombinations[0][i].combination(); double array[]; vecToArray(comb,array); int found = ArrayBsearch(array,double(z)); if(int(array[found])!=z) { array.Push(double(z)); ArraySort(array); comb.Assign(array); ulong dif = 1; for(uint row = 0; row<out.Size(); row++) { dif = comb.Compare(out[row],1e0); if(!dif) break; } if(dif) { ArrayResize(out,out.Size()+1,100); out[out.Size()-1] = comb; } } } } } public: MULTI(void):LinearModel() { CVector members; bestCombinations.push_back(members); modelName = "MULTI"; } bool fit(vector &time_series,int lags,double testsize=0.5,CriterionType criterion=stab,int kBest = 3,int pAverage = 1,double limit = 0.0) { if(lags < 1) { Print(__FUNCTION__," lags must be >= 1"); return false; } PairMVXd transformed = timeSeriesTransformation(time_series,lags); SplittedData splited = splitData(transformed.first,transformed.second,testsize); Criterion criter(criterion); if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } bool fit(matrix &vars,vector &targets,double testsize=0.5,CriterionType criterion=stab,int kBest = 3,int pAverage = 1,double limit = 0.0) { if(vars.Cols() < 1) { Print(__FUNCTION__," columns in vars must be >= 1"); return false; } if(vars.Rows() != targets.Size()) { Print(__FUNCTION__, " vars dimensions donot correspond with targets"); return false; } SplittedData splited = splitData(vars,targets,testsize); Criterion criter(criterion); if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } }; //+------------------------------------------------------------------+
A classe MULTI funciona de maneira semelhante à classe COMBI, com os métodos "fit()" familiares. Em relação à classe COMBI, os leitores devem notar que há mais hiperparâmetros nos métodos "fit()". "kBest" e "pAverage" são dois parâmetros que podem precisar de ajustes cuidadosos ao aplicar a classe MULTI. Ajustar um modelo a um conjunto de dados é demonstrado nos scripts, MULTI_test.mq5 e MULTI_Multivariable_test.mq5. O código é apresentado abaixo.
//+----------------------------------------------------------------------+ //| MULTI_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+----------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\multi.mqh> input int NumLags = 2; input int NumPredictions = 6; input CriterionType critType = stab; input int Average = 1; input int NumBest = 3; input double DataSplitSize = 0.33; input double critLimit = 0; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector tms = {1,2,3,4,5,6,7,8,9,10,11,12}; if(NumPredictions<1) { Alert("Invalid setting for NumPredictions, has to be larger than 0"); return; } MULTI multi; if(!multi.fit(tms,NumLags,DataSplitSize,critType,NumBest,Average,critLimit)) return; vector in(ulong(NumLags),slice,tms,tms.Size()-ulong(NumLags)); vector out = multi.predict(in,NumPredictions); Print(" predictions ", out); Print(multi.getBestPolynomial()); } //+------------------------------------------------------------------+
//+------------------------------------------------------------------+ //| MULTI_Mulitivariable_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\multi.mqh> input CriterionType critType = stab; input double DataSplitSize = 0.33; input int Average = 1; input int NumBest = 3; input double critLimit = 0; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- matrix independent = {{1,2,3},{3,2,1},{1,4,2},{1,1,3},{5,3,1},{3,1,9}}; vector dependent = {6,6,7,5,9,13}; MULTI multi; if(!multi.fit(independent,dependent,DataSplitSize,critType,NumBest,Average,critLimit)) return; matrix unseen = {{1,2,4},{1,5,3},{9,1,3}}; for(ulong row = 0; row<unseen.Rows(); row++) { vector in = unseen.Row(row); Print("inputs ", in, " prediction ", multi.predict(in,1)); } Print(multi.getBestPolynomial()); } //+------------------------------------------------------------------+
Pode-se ver, ao executar os scripts, que os polinômios induzidos de nossos conjuntos de dados simples são exatamente os mesmos que os obtidos aplicando o algoritmo COMBI.
IG 0 18:24:28.811 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [1,2,4] prediction [7.000000000000002] HI 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [9] NO 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [9,1,3] prediction [13.00000000000001] PP 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) y= 1.000000e+00*x1 + 1.000000e+00*x2 + 1.000000e+00*x3 - 7.330836e-15 DP 0 18:25:04.454 MULTI_test (BTCUSD,D1) predictions [13,14,15,16,17,18.00000000000001] MH 0 18:25:04.454 MULTI_test (BTCUSD,D1) y= 1.000000e+00*x1 + 2.000000e+00
Um modelo GMDH para preços de Bitcoin
Nesta seção do texto, aplicaremos o método GMDH para construir um modelo preditivo de preços de fechamento diários do Bitcoin. Isso é realizado no script GMDH_Price_Model.mq5, anexado ao final do artigo. Embora nossa demonstração trate especificamente do símbolo Bitcoin, o script pode ser aplicado a qualquer símbolo e timeframe. O script possui vários parâmetros mutáveis pelo usuário que controlam vários aspectos do programa.
//--- input parameters input string SetSymbol=""; input ENUM_GMDH_MODEL modelType = Combi; input datetime TrainingSampleStartDate=D'2019.12.31'; input datetime TrainingSampleStopDate=D'2022.12.31'; input datetime TestSampleStartDate = D'2023.01.01'; input datetime TestSampleStopDate = D'2023.12.31'; input ENUM_TIMEFRAMES tf=PERIOD_D1; //time frame input int Numlags = 3; input CriterionType critType = stab; input PolynomialType polyType = linear_cov; input int Average = 10; input int NumBest = 10; input double DataSplitSize = 0.2; input double critLimit = 0; input ulong NumTestSamplesPlot = 20;
Eles estão listados e descritos na tabela a seguir.
| Nome do Parâmetro de Entrada | Descrição |
|---|---|
| SetSymbol | Define o nome do símbolo dos preços de fechamento que serão usados como dados de treinamento, se deixado em branco, assume-se o símbolo do gráfico ao qual o script é aplicado. |
| modeltype | Isso é uma enumeração que representa a escolha do algoritmo GMDH. |
| TrainingSampleStartDate | Data de início do período de preços de fechamento na amostra. |
| TrainingSampleStopDate | Data de término do período de preços de fechamento na amostra. |
| TestSampleStartDate | Data de início do período de preços fora da amostra. |
| TestSampleStopDate | Data de término do período de preços fora da amostra. |
| tf | O timeframe aplicado. |
| Numlags | Define o número de valores defasados que serão usados para prever o próximo preço de fechamento. |
| critType | Especifica o critério externo para o processo de construção do modelo. |
| polyType | Tipo de polinômio a ser usado para construir novas variáveis a partir das existentes durante o treinamento, aplicável apenas quando o algoritmo MIA é selecionado. |
| Average | O número dos melhores modelos parciais a serem considerados no cálculo dos critérios de parada |
| Numbest | Para os modelos MIA, define o número dos melhores modelos parciais com base nos quais as novas entradas da camada subsequente serão construídas. Para os modelos COMBI, é o número de modelos candidatos que serão selecionados em cada camada para consideração nas iterações subsequentes. |
| DataSplitSize | Fração dos dados de entrada que deve ser usada para avaliar os modelos |
| critLimit | O valor mínimo pelo qual o critério externo deve ser melhorado para continuar o treinamento |
| NumTestSamplePlot | O valor define o número de amostras do conjunto de dados fora da amostra que serão visualizadas junto com as previsões correspondentes. |
O script começa com a seleção de uma amostra adequada de observações a serem usadas como dados de treinamento.
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //get relative shift of IS and OOS sets int trainstart,trainstop, teststart, teststop; trainstart=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TrainingSampleStartDate); trainstop=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TrainingSampleStopDate); teststart=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TestSampleStartDate); teststop=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TestSampleStopDate); //check for errors from ibarshift calls if(trainstart<0 || trainstop<0 || teststart<0 || teststop<0) { Print(ErrorDescription(GetLastError())); return; } //---set the size of the sample sets size_observations=(trainstart - trainstop) + 1 ; size_outsample = (teststart - teststop) + 1; //---check for input errors if(size_observations <= 0 || size_outsample<=0) { Print("Invalid inputs "); return; } //---download insample prices for training int try = 10; while(!prices.CopyRates(SetSymbol,tf,COPY_RATES_CLOSE,TrainingSampleStartDate,TrainingSampleStopDate) && try) { try --; if(!try) { Print("error copying to prices ",GetLastError()); return; } Sleep(5000);
Outra amostra de preços de fechamento é baixada, que será usada para visualizar o desempenho do modelo com um gráfico dos preços de fechamento previstos e reais.
//---download out of sample prices testing try = 10; while(!testprices.CopyRates(SetSymbol,tf,COPY_RATES_CLOSE|COPY_RATES_TIME|COPY_RATES_VERTICAL,TestSampleStartDate,TestSampleStopDate) && try) { try --; if(!try) { Print("error copying to testprices ",GetLastError()); return; } Sleep(5000); }
Os parâmetros definidos pelo usuário do script permitem a aplicação de um dos três modelos GMDH que discutimos e implementamos.
//--- train and make predictions switch(modelType) { case Combi: { COMBI combi; if(!combi.fit(prices,Numlags,DataSplitSize,critType)) return; Print("Model ", combi.getBestPolynomial()); MakePredictions(combi,testprices.Col(0),predictions); } break; case Mia: { MIA mia; if(!mia.fit(prices,Numlags,DataSplitSize,polyType,critType,NumBest,Average,critLimit)) return; Print("Model ", mia.getBestPolynomial()); MakePredictions(mia,testprices.Col(0),predictions); } break; case Multi: { MULTI multi; if(!multi.fit(prices,Numlags,DataSplitSize,critType,NumBest,Average,critLimit)) return; Print("Model ", multi.getBestPolynomial()); MakePredictions(multi,testprices.Col(0),predictions); } break; default: Print("Invalid GMDH model type "); return; } //---
O programa termina exibindo um gráfico dos preços de fechamento previstos, juntamente com os valores reais do conjunto de dados fora da amostra.
//--- ulong TestSamplesPlot = (NumTestSamplesPlot>0)?NumTestSamplesPlot:20; //--- if(NumTestSamplesPlot>=testprices.Rows()) TestSamplesPlot = testprices.Rows()-Numlags; //--- vector testsample(100,slice,testprices.Col(0),Numlags,Numlags+TestSamplesPlot-1); vector testpredictions(100,slice,predictions,0,TestSamplesPlot-1); vector dates(100,slice,testprices.Col(1),Numlags,Numlags+TestSamplesPlot-1); //--- //Print(testpredictions.Size(), ":", testsample.Size()); //--- double y[], y_hat[]; //--- if(vecToArray(testpredictions,y_hat) && vecToArray(testsample,y) && vecToArray(dates,xaxis)) { PlotPrices(y_hat,y); } //--- ChartRedraw(); }
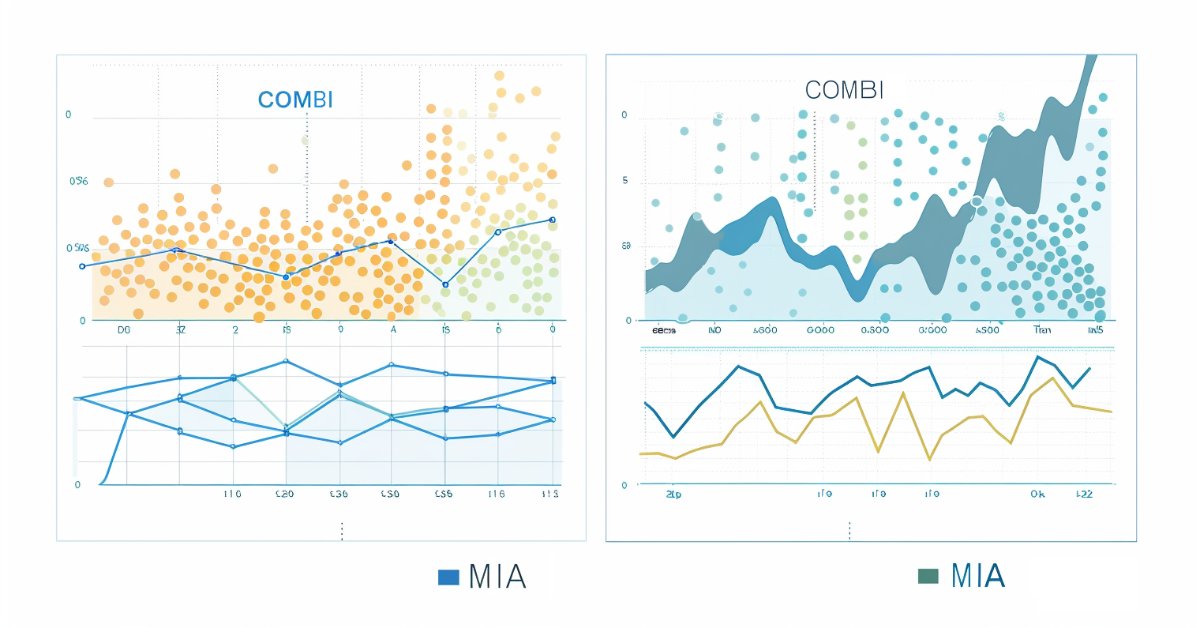
Abaixo estão os gráficos das previsões feitas usando os algoritmos combinatório e iterativo multicamadas, respectivamente.


Conclusão
Em conclusão, o algoritmo combinatório do GMDH oferece uma estrutura para modelar sistemas complexos, com pontos fortes particulares em áreas onde abordagens indutivas e baseadas em dados são vantajosas. Sua aplicação prática é limitada devido à ineficiência do algoritmo ao lidar com grandes conjuntos de dados. O algoritmo combinatório seletivo mitiga essa limitação apenas até certo ponto. Os ganhos em velocidade são contrabalançados pela introdução de mais hiperparâmetros que precisam ser ajustados para obter o máximo do algoritmo. A aplicação do método GMDH na análise de séries temporais financeiras demonstra seu potencial em fornecer insights valiosos.
| Arquivo | Descrição |
|---|---|
| Mql5\include\VectorMatrixTools.mqh | arquivo de cabeçalho com definições de funções usadas para manipular vetores e matrizes |
| Mql5\include\JAson.mqh | contém a definição dos tipos personalizados usados para analisar e gerar objetos JSON |
| Mql5\include\GMDH\gmdh_internal.mqh | arquivo de cabeçalho contendo definições de tipos personalizados usados na biblioteca GMDH |
| Mql5\include\GMDH\gmdh.mqh | arquivo include com definição da classe base GmdhModel |
| Mql5\include\GMDH\linearmodel.mqh | arquivo include com definição da classe intermediária LinearModel, que é a base para as classes COMBI e MULTI |
| Mql5\include\GMDH\combi.mqh | arquivo include com definição da classe COMBI |
| Mql5\include\GMDH\multi.mqh | arquivo include com definição da classe COMBI |
| Mql5\include\GMDH\mia.mqh | contém a classe MIA que implementa o algoritmo iterativo multicamadas |
| Mql5\script\COMBI_test.mq5 | um script que demonstra o uso da classe COMBI construindo um modelo de uma série temporal simples |
| Mql5\script\COMBI_Multivariable_test.mq5 | um script que mostra a aplicação da classe COMBI para construir um modelo de um conjunto de dados multivariável |
| Mql5\script\MULTI_test.mq5 | um script que demonstra o uso da classe MULTI construindo um modelo de uma série temporal simples |
| Mql5\script\MULTI_Multivariable_test.mq5 | um script que mostra a aplicação da classe MULTI para construir um modelo de um conjunto de dados multivariável |
| Mql5\script\GMDH_Price_Model.mqh | um script que demonstra um modelo GMDH de uma série de preços |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/14804
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso