Técnicas do MQL5 Wizard que você deve conhecer (Parte 13): DBSCAN para a Classe de Sinais de Expert
Introdução
Esta série de artigos sobre o MQL5 Wizard é uma introdução sobre como ideias frequentemente abstratas em Matemática de outros campos da vida podem ser transformadas em sistemas de negociação e testadas ou validadas antes que qualquer compromisso sério seja feito com base nelas. Essa capacidade de pegar ideias simples e não totalmente implementadas ou previstas e explorar seu potencial como sistemas de negociação é uma das preciosidades apresentadas pela montagem do wizard do MQL5 para expert advisers. As classes de especialistas do wizard fornecem muitas das características mundanas exigidas por qualquer expert adviser, especialmente no que se refere à abertura e fechamento de negociações, mas também em aspectos negligenciados, como a execução de decisões apenas na formação de um novo candle.
Assim, mantendo essa biblioteca de processos como um aspecto separado de um expert adviser, com o MQL5 Wizard, qualquer ideia pode não apenas ser testada independentemente, mas também comparada em condições quase iguais com qualquer outra ideia (ou métodos) que possam estar sendo consideradas. Nesta série, examinamos métodos alternativos de clustering, como o clustering aglomerativo, bem como o clustering k-means.
Em cada uma dessas abordagens, antes de gerar os respectivos clusters, um dos parâmetros de entrada exigidos era o número de clusters a serem criados. Isso, essencialmente, assume que o usuário está bem familiarizado com o conjunto de dados e não está explorando ou observando um conjunto de dados desconhecido. Com o Clustering Espacial Baseado em Densidade para Aplicações com Ruído (DBSCAN), o número de clusters a ser formado é um ‘respeitado’ desconhecido. Isso oferece mais flexibilidade não apenas para explorar conjuntos de dados desconhecidos e descobrir suas principais características de classificação, mas também permite verificar 'viéses' existentes ou visões comumente aceitas sobre qualquer conjunto de dados, para ver se o número de clusters assumido pode ser verificado.
Ao considerar apenas dois parâmetros, a saber, epsilon, que é a distância espacial máxima entre pontos em um cluster; e o número mínimo de pontos necessários para constituir um cluster, o DBSCAN é capaz não apenas de gerar clusters a partir de dados amostrados, mas também de determinar o número apropriado desses clusters. Para apreciar seus feitos notáveis, pode ser útil observar alguns agrupamentos que ele pode realizar em oposição a abordagens alternativas.
De acordo com este artigo público no Medium, o DBSCAN e o clustering k-means, por sua definição, dariam esses resultados de clustering separados.
Para o clustering k-means teríamos:

enquanto o DBSCAN daria:

Além disso, este artigo também comparou o DBSCAN com outra abordagem de clustering chamada CLARANS, que produziu os seguintes resultados. Para o CLARANS, a reclassificação foi:

No entanto, o DBSCAN com as mesmas formas deu o seguinte agrupamento:
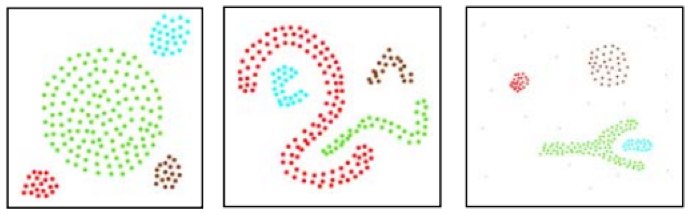
O primeiro exemplo pode ser uma apresentação conceitual, entretanto, o 2º exemplo é definitivo. Os argumentos por trás disso são que, sem um número pré-definido de clusters necessário para a classificação, o DBSCAN utiliza a densidade ou o espaçamento médio dos pontos para formar agrupamentos apropriados e, portanto, clusters.
Como pode ser observado nas imagens acima, o k-means está preocupado com a partição territorial que, neste caso, é governada pelas coordenadas dos eixos x e y. Então, o que o k-means faz é repartir os pontos dentro das limitações do eixo (neste caso x & y) como o melhor ajuste. O DBSCAN introduz uma ‘dimensão’ extra de densidade onde não é suficiente simplesmente se limitar às áreas de coordenadas dos eixos, mas também se considera a proximidade intra-regional de todos os pontos; o resultado disso é que os clusters podem se estender por regiões amplas além do que seria considerado sua média loci ou melhor ajuste.
Portanto, neste artigo, veremos como o DBSCAN pode ajudar a refinar as decisões de compra e venda da classe de sinais de expert usada no wizard do MQL5. Já vimos como o clustering pode ser informativo nesse tipo de decisão nos dois artigos anteriores sobre os assuntos vinculados acima, então vamos construir sobre isso ao criar classes de sinais para o DBSCAN.
Para esse fim, teremos 3 ilustrações de diferentes classes de sinais de especialistas que usam DBSCAN de diferentes maneiras, principalmente processando diferentes conjuntos de dados. Finalmente, como mencionado no início, essas ideias são apresentadas aqui para testes preliminares e triagem, e estão longe de ser algo que deve ser usado em contas reais A diligência independente por parte do leitor é sempre esperada.
Desmistificando o DBSCAN
Para 'desmistificar' o DBSCAN, pode ser uma boa ideia fornecer algumas ilustrações, fora do contexto de negociação, que podemos encontrar no dia a dia. Então, vamos analisar 3 exemplos.
Exemplo-1: Imagine uma situação em que você é dono de um supermercado e precisa analisar um conjunto de dados sobre alguns clientes e tentar ver se há algum padrão que possa ser identificado e usado no futuro para fins de planejamento. Essa análise pode, novamente, assumir várias formas, mas para nossos propósitos, estamos considerando principalmente o agrupamento. Com k-means, você teria que começar presumindo um número fixo de tipos de clientes, digamos que você assume que há consumidores discricionários, aqueles que compram apenas bens de alto valor, como eletrônicos, e apenas quando há promoções, e consumidores de produtos básicos, aqueles que você frequentemente vê em sua loja comprando mantimentos domésticos cerca de uma vez por semana. Com esse agrupamento definido, você então prosseguiria para detalhar o que eles compram e planejar adequadamente seus estoques para serem capazes de atender à demanda deles no futuro. Agora, porque você predefiniu seus clusters (tipos de clientes) para 2, você é obrigado a ter 2 grandes desembolsos de despesas (posicionados no tempo como centróides médios) para reabastecer seu estoque, e isso pode não ser tão amigável ao fluxo de caixa quanto você gostaria, já que mais despesas, porém de menor valor, poderiam ser mais gerenciáveis. Por outro lado, se você tivesse usado o DBSCAN para a segmentação de seus clientes, então o número de tipos de clientes que você obtém seria determinado pela densidade ou pela proximidade no tempo em que esses clientes tendem a fazer suas compras. Usamos a analogia dos eixos x e y para quantificar o epsilon (proximidade dos pontos de dados) acima, mas no caso dos clientes de supermercado, um calendário seria suficiente, onde o quão ‘próximos’ os clientes estão seria quantificado pela distância em tempo em relação a uma data no calendário em que fazem suas compras. Isso permite um agrupamento mais flexível dos clientes, o que, por sua vez, pode levar a desembolsos de despesas mais gerenciáveis ao reabastecer o estoque, entre outros benefícios.
Exemplo-2: Considere uma situação em que, como planejador urbano de uma cidade, você é encarregado de reavaliar o número máximo de residências que devem ser permitidas em cada bairro da cidade a partir do estudo dos padrões de tráfego urbano. Enquanto no exemplo-1 usamos o tempo como nosso domínio espacial para o agrupamento, para este exemplo estamos restritos às rotas físicas que atravessam a cidade e talvez conectem os bairros. O clustering k-means começaria usando o número existente de bairros como os clusters e, em seguida, determinaria a ponderação ou o limite populacional de cada bairro com base na quantidade média de tráfego matinal e vespertino em suas rotas de conexão. Com a nova proporção de ponderação, cada bairro teria então seu limite residencial reduzido ou aumentado proporcionalmente. No entanto, os próprios bairros podem não ser imutáveis. Alguns podem estar em declínio, outros prosperando e, mais importante, alguns podem estar surgindo; assim, usando o DBSCAN com apenas as rotas de tráfego e sem suposições sobre o número de bairros, podemos agrupar as rotas em diferentes formas de clusters, que então mapeariam nossos novos bairros. Nosso epsilon, neste caso, rastrearia quantos carros temos em cada rota (nas horas de pico da manhã e da noite), digamos, por quilômetro. Isso poderia implicar que rotas mais densas poderiam ser agrupadas do que rotas menos densas, o que cria problemas em casos em que as rotas levam a diferentes áreas geográficas. A maneira de contornar isso ou entender os dados seria que essas rotas, mesmo mapeando para diferentes áreas físicas, representam o mesmo ‘tipo de bairro’ (poderia ser devido ao nível de renda etc.) e, portanto, para fins de planejamento, podem ser provisionadas de maneira semelhante.
Exemplo-3: Finalmente, as redes sociais são uma mina de ouro de dados para muitas empresas, e entender melhor essas redes pode ser crucial na capacidade de classificar ou, no nosso caso, agrupar os usuários em diferentes grupos. Agora, porque os usuários de mídias sociais formam seus próprios grupos para lazer ou trabalho, podem ter interesses comuns ou não, e podem até interagir esporadicamente; é uma tarefa hercúlea para o k-means definir um número aceitável de clusters logo de início ao começar o processo de agrupamento. Por outro lado, o DBSCAN, ao focar na densidade, pode se concentrar no número de interações dos usuários, digamos, através da enumeração ao longo de um determinado período de tempo. Esse número de interações de um usuário para outro pode, assim, orientar o parâmetro epsilon na formação e definição dos diferentes clusters que poderiam ser possíveis em uma determinada plataforma de mídia social.
Além dos pontos levantados nesses exemplos, também vale destacar que o DBSCAN é mais adequado para lidar com ruídos e identificar outliers, especialmente em situações de aprendizado não supervisionado, como é o caso do DBSCAN. O parâmetro de entrada de número mínimo de pontos também é importante ao se chegar ao número ideal de clusters para um conjunto de dados amostrado, no entanto, não é tão sensível (ou importante) quanto o epsilon, porque seu papel essencial é definir o limite de 'ruído'. Com o DBSCAN, qualquer dado que não se enquadre nos clusters designados é considerado ruído.
Implementação no MQL5
Portanto, a estrutura básica dos expert advisers montados no MQL5 Wizard já foi coberta em artigos anteriores. O manual oficial sobre isso pode ser encontrado aqui. No entanto, para recapitular, os expert advisers montados no wizard dependem da Expert Class definida no arquivo ‘<include\Expert\Expert.mqh>’. Esta classe de especialista define principalmente como as funções típicas do expert adviser, relacionadas à abertura e fechamento de posições, são tratadas. Ela, por sua vez, depende da Classe Expert-Base que é definida no arquivo ‘<include\Expert\ExpertBase.mqh>’, e este último arquivo lida com a recuperação e o armazenamento em buffer das informações de preços atuais para o símbolo ao qual o expert adviser está anexado. A partir da Classe de Expert, que podemos considerar como a âncora, outras 3 classes são derivadas por herança: a Classe de Sinais de Expert, a Classe de Trailing de Expert e a Classe de Dinheiro de Expert. Implementações personalizadas de cada uma dessas classes já foram compartilhadas em artigos anteriores, no entanto, vale reiterar que a Classe de Sinais de Expert lida com decisões de compra e venda, enquanto a Classe de Trailing de Expert determina quando e quanto mover o trailing stop nas posições abertas, e, finalmente, a Classe de Dinheiro de Expert define que proporção da margem disponível pode ser usada no dimensionamento de posições.
Os passos para montar um expert advisor a partir das classes disponíveis na biblioteca são realmente diretos e existem artigos aqui, além do link compartilhado acima, sobre como proceder com isso. A preparação dos dados é tratada pela Expert Base Class, no entanto, para que isso seja viável, os testes devem ser feitos com dados de preços do seu corretor pretendido e os ticks reais devem ser baixados do servidor deles, tanto quanto disponível.
Ao codificar a função DBSCAN, este artigo público compartilha um código-fonte útil no qual nos baseamos para definir nossas funções. Se começarmos com a mais básica delas, há um total de 4 funções simples, estaríamos analisando a função de distância.
//+------------------------------------------------------------------+ //| Function for Euclidean Distance between points | //+------------------------------------------------------------------+ double CSignalDBSCAN::Distance(Spoint &A, Spoint &B) { double _d = 0.0; for(int i = 0; i < int(fmin(A.key.Size(), B.key.Size())); i++) { _d += pow(A.key[i] - B.key[i], 2.0); } _d = sqrt(_d); return(_d); }
O artigo citado e a maioria dos códigos-fonte públicos sobre DBSCAN utilizam a distância euclidiana como a métrica principal para quantificar a distância entre os pontos em qualquer conjunto de pontos. No entanto, considerando que nossos pontos estão em forma de vetor, o MQL5 apresenta várias outras alternativas para medir essa distância entre pontos, como a similaridade de cosseno, etc., e o leitor pode explorar essas, pois são sub-funções do tipo de dado vetor. Codificamos a função Euclidiana do zero, pois não consegui encontrá-la sob a função Loss ou as funções de Métrica de Regressão.
Em seguida, entre os blocos de construção, precisamos de uma função ‘RegionQuery’. Essa função retorna uma lista de pontos dentro do limite definido pelo parâmetro de entrada epsilon, que pode ser considerado dentro do mesmo cluster que o ponto em questão.
//+------------------------------------------------------------------+ //| Function that returns neighbouring points for an input point &P[]| //+------------------------------------------------------------------+ void CSignalDBSCAN::RegionQuery(Spoint &P[], int Index, CArrayInt &Neighbours) { Neighbours.Resize(0); int _size = ArraySize(P); for(int i = 0; i < _size; i++) { if(i == Index) { continue; } else if(Distance(P[i], P[Index]) <= m_epsilon) { Neighbours.Resize(Neighbours.Total() + 1); Neighbours.Add(i); } } P[Index].visited = true; }
Normalmente, para cada ponto dentro de um conjunto de dados em consideração, tentamos elaborar uma lista de pontos como essa, para que nada seja negligenciado, e essa lista é útil para a próxima função, que é a função ‘ExpandCluster’.
//+------------------------------------------------------------------+ //| Function that extends cluster for identified cluster IDs | //+------------------------------------------------------------------+ bool CSignalDBSCAN::ExpandCluster(Spoint &SetOfPoints[], int Index, int ClusterID) { CArrayInt _seeds; RegionQuery(SetOfPoints, Index, _seeds); if(_seeds.Total() < m_min_points) // no core point { SetOfPoints[Index].cluster_id = -1; return(false); } else { SetOfPoints[Index].cluster_id = ClusterID; for(int ii = 0; ii < _seeds.Total(); ii++) { int _current_p = _seeds[ii]; CArrayInt _result; RegionQuery(SetOfPoints, _current_p, _result); if(_result.Total() > m_min_points) { for(int i = 0; i < _result.Total(); i++) { int _result_p = _result[i]; if(SetOfPoints[_result_p].cluster_id == -1) { SetOfPoints[_result_p].cluster_id = ClusterID; } } } } } return(true); }
Essa função, que recebe um ID de cluster e um índice de ponto, determina se o ID do cluster precisa ser atribuído a novos pontos com base nos resultados da função de consulta de região mencionada acima. Se o resultado for verdadeiro, o cluster aumenta de tamanho, caso contrário, permanece inalterado. Dentro dessa função, verificamos se já há pontos identificados por clusters para evitar repetições e, como mencionado acima, quaisquer pontos não agrupados (que mantêm o ID do cluster: -1) são considerados ruído.
Juntar tudo isso é feito através da função principal DBSCAN, que itera por todos os pontos em um conjunto de dados estabelecendo se o ID do cluster atual precisa ser expandido. O ID do cluster atual é um número inteiro que é incrementado sempre que um novo cluster é estabelecido e, a cada incremento, a vizinhança de todos os pontos pertencentes a esse cluster é consultada através da função de consulta de região, como já mencionado, e isso é chamado através da função de expansão de cluster. A listagem para isso está abaixo:
//+------------------------------------------------------------------+ //| Main clustering function | //+------------------------------------------------------------------+ void CSignalDBSCAN::DBSCAN(Spoint &SetOfPoints[]) { int _cluster_id = -1; int _size = ArraySize(SetOfPoints); for(int i = 0; i < _size; i++) { if(SetOfPoints[i].cluster_id == -1) { if(ExpandCluster(SetOfPoints, i, _cluster_id)) { _cluster_id++; SetOfPoints[i].cluster_id = _cluster_id; } } } }
De forma semelhante, a estrutura que lida com o conjunto de dados referido como ‘conjunto de pontos’ na listagem acima é definida no cabeçalho da classe da seguinte forma:
struct Spoint { vector key; bool visited; int cluster_id; Spoint() { key.Resize(0); visited = false; cluster_id = -1; }; ~Spoint() {}; };
O DBSCAN, como um método de clustering, enfrenta desafios de memória dependendo do tamanho do conjunto de dados. Além disso, há uma linha de pensamento que acredita que o parâmetro de entrada principal, epsilon, que mede a densidade do cluster, não deve ser uniforme para todos os clusters. Na implementação que estamos usando para este artigo, este é o caso, no entanto, existem variantes do DBSCAN, como o HDBSCAN, que podemos cobrir em artigos futuros, que nem sequer requerem o epsilon como entrada, mas apenas dependem do número mínimo de pontos em um cluster, o que é um parâmetro menos crítico e sensível, tornando-o uma abordagem mais versátil para clustering.
Classes de Sinais
Se construirmos com base no que definimos acima na implementação, podemos apresentar várias abordagens diferentes para o clustering de dados de preços de segurança para gerar sinais de negociação. Portanto, as três abordagens exemplares prometidas no início do artigo serão:
- clustering dos dados brutos de preços OHLC,
- mudanças nos dados do indicador RSI,
- e, finalmente, mudanças no indicador de Média Móvel de Preços.
Em artigos anteriores sobre clustering, tínhamos um modelo bruto onde rotulávamos retrospectivamente valores agrupados com mudanças eventuais no preço e usávamos médias ponderadas atuais dessas mudanças para fazer nossa próxima previsão. Adotaremos uma abordagem semelhante, mas a principal diferença entre cada método será, principalmente, o conjunto de dados alimentado em nossa função DBSCAN. Como esses conjuntos de dados variam, os parâmetros de entrada para cada classe de sinais também podem ser diferentes.
Se começarmos com os dados brutos de OHLC, nosso conjunto de dados será constituído por 4 pontos-chave. Assim, o vetor que definimos como ‘key’ na estrutura ‘Spoint’ que contém nossos dados terá um tamanho de 4. Esses 4 pontos serão as respectivas mudanças nos preços de abertura, máxima, mínima e fechamento. Portanto, populamos uma estrutura ‘Spoint’ com as informações de preços atuais da seguinte forma:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CSignalDBSCAN::GetOutput() { double _output = 0.0; ... ... for(int i = 0; i < m_set_size; i++) { for(int ii = 0; ii < m_key_size; ii++) { if(ii == 0) { m_model.x[i].key[ii] = (m_open.GetData(StartIndex() + i) - m_open.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } else if(ii == 1) { m_model.x[i].key[ii] = (m_high.GetData(StartIndex() + i) - m_high.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } else if(ii == 2) { m_model.x[i].key[ii] = (m_low.GetData(StartIndex() + i) - m_low.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } else if(ii == 3) { m_model.x[i].key[ii] = (m_close.GetData(StartIndex() + i) - m_close.GetData(StartIndex() + ii + i + 1)) / m_symbol.Point(); } } if(i > 0) //assign classifier only for data points for which eventual bar range is known { m_model.y[i - 1] = (m_close.GetData(StartIndex() + i - 1) - m_close.GetData(StartIndex() + i)) / m_symbol.Point(); } } ... return(_output); }
Se montarmos este sinal através do wizard e executarmos testes no EURUSD para o ano de 2023 no timeframe diário, nossa melhor execução nos dá o seguinte relatório e curva de capital.


Pelos relatórios, você poderia dizer que há potencial, no entanto, neste caso, não fizemos um teste "walk forward" como tentamos em pequena escala em artigos anteriores, então o leitor é convidado a realizar isso antes de prosseguir.
Continuando com os valores absolutos do RSI como um conjunto de dados, implementaríamos isso de maneira semelhante, com a principal diferença sendo como estamos contabilizando os 3 diferentes períodos de atraso para os quais tomamos leituras do RSI. Assim, com este conjunto de dados, estamos obtendo 4 pontos de dados por vez, como com os preços brutos de OHLC, mas esses pontos de dados são valores do indicador RSI. Os atrasos nos quais são tomados são definidos por 3 parâmetros de entrada que rotulamos como A, B e C. O conjunto de dados é populado da seguinte forma:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CSignalDBSCAN::GetOutput() { double _output = 0.0; ... RSI.Refresh(-1); for(int i = 0; i < m_set_size; i++) { for(int ii = 0; ii < m_key_size; ii++) { if(ii == 0) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i); } else if(ii == 1) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i + m_lag_a); } else if(ii == 2) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i + m_lag_a + m_lag_b); } else if(ii == 3) { m_model.x[i].key[ii] = RSI.Main(StartIndex() + i + m_lag_a + m_lag_b + m_lag_c); } } if(i > 0) //assign classifier only for data points for which eventual bar range is known { m_model.y[i - 1] = (m_close.GetData(StartIndex() + i - 1) - m_close.GetData(StartIndex() + i)) / m_symbol.Point(); } } int _o[]; ... ... return(_output); }
Então, quando executamos testes para o mesmo símbolo durante o mesmo período de 2023 no timeframe diário, obtemos os seguintes resultados da nossa melhor execução:


Um relatório promissor, mas mais uma vez inconclusivo, pendente de sua própria diligência. Todos os experts montados para este artigo realizam negociações por ordem limitada e não usam preço de take profit ou stop loss para fechar posições. Isso implica que as posições são mantidas até que um sinal seja revertido e, em seguida, uma nova posição é aberta na direção oposta.
Finalmente, com mudanças na Média Móvel, preencheríamos um conjunto de dados quase da mesma forma que fizemos com o RSI, com a principal diferença sendo que aqui estamos procurando mudanças nas leituras do indicador MA, enquanto com o RSI estávamos interessados nos valores absolutos. Outra diferença importante seria os valores-chave: o tamanho do vetor ‘key’ dentro da estrutura ‘Spoint’ é de apenas 3 e não 4, já que estamos focando em mudanças de atraso e não em leituras absolutas.
Executar os testes gera o seguinte relatório para a melhor execução.


Conclusão
Para concluir, o DBSCAN é uma forma não supervisionada de classificar dados que requer poucos parâmetros de entrada, ao contrário de abordagens mais convencionais como o k-means. Ele requer apenas dois parâmetros, dos quais apenas um, o epsilon, é crítico, o que leva a uma dependência ou sensibilidade excessiva em relação a essa entrada.
Apesar dessa dependência excessiva do epsilon, o fato de que, para qualquer classificação, o número de clusters é determinado organicamente faz com que seja bastante versátil para vários conjuntos de dados e mais capaz de lidar com ruídos.
Quando usado dentro de uma instância personalizada da classe de sinais de expert, uma ampla variedade de conjuntos de dados de entrada, desde preços brutos até valores de indicadores, pode ser usada como base para classificar um ativo.
Além de criar uma instância personalizada da Classe de Sinais de Expert, o leitor pode criar implementações personalizadas semelhantes da classe de trailing de expert ou da classe de dinheiro de expert, que também utilizam o DBSCAN, como abordamos em artigos anteriores desta série.
Outro caminho que vale a pena explorar, que acredito ser o que o DBSCAN e o clustering em geral são preparados para, é a normalização de dados. Muitos modelos de previsão tendem a exigir uma forma de normalização de qualquer dado de entrada antes que possa ser usado na previsão. Por exemplo, um Algoritmo de Random Forest ou uma Rede Neural precisaria idealmente de dados normalizados, especialmente se esse feed de dados for de preços de ativos. Nos agora em voga Modelos de Linguagem de Grande Escala que usam a Arquitetura Transformer, o equivalente a essa etapa é a incorporação, onde essencialmente todo o texto, incluindo o numérico, é reassinado a um número para fins de processamento de feed forward através de uma rede neural. Sem essa normalização de texto e números, seria impossível para a rede processar de forma viável as grandes quantidades de dados que ela faz ao desenvolver algoritmos de IA. Mas também essa normalização lida com outliers, que podem ser um problema ao tentar treinar uma rede e obter pesos e vieses aceitáveis. Podem haver outros usos pertinentes para o clustering e o DBSCAN, mas esses são os meus dois centavos. Boa caçada.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/14489
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso