
Rede neural na prática: Esboçando um neurônio

Introdução
Olá pessoal, e sejam bem-vindos a mais um artigo sobre Rede Neural.
No artigo anterior Rede neural na prática: Pseudo Inversa (II), mostrei a importância e o motivo pelo qual, sistemas de cálculo dedicados são desenvolvidos. Neste artigo daqui iremos começar uma nova fase no assunto sobre redes neurais. Desenvolver um material para ser utilizado nesta fase não é algo simples. Apesar de parecer simples, é difícil explicar de forma simples algo do qual muita gente faz uma grande confusão.
E o que vamos ver nesta fase? Bem, aqui quero mostrar a você, meu caro leitor como uma rede neural aprende. Até o momento, o que vimos foi como uma rede neural, consegue estabelecer uma correlação entre diferentes dados. Mas aquilo que foi visto até o momento, é de utilidade quando você já tem um banco de dados, com informações e registros previamente filtrados e selecionados. Permitindo assim que a rede neural encontre a melhor solução para representar aquelas informações contidas no banco de dados. Pois bem, mas como em um caso de dados não filtrados, uma rede neural consegue estabelecer uma correlação entre eles? Esta é a parte na qual muitos com toda a certeza, ficam pensando que uma rede neural é uma entidade inteligente. Já que eles imaginam que a rede neural esteja aprendendo como classificar as coisas.
E é justamente por conta disto, desta má interpretação que as pessoas fazem sobre o tema, que torna tão difícil explicar sobre o mesmo. Já que muitas das vezes, a pessoa que está procurando tal entendimento, não tem conhecimentos mínimos sobre como classificar informações diferentes. Porém tais informações, tem algum tipo de correlação entre elas. Esta é a parte confusa. Não para quem mexe com tais coisas. Mas sim para quem não mexe. Pois ao explicarmos algo, o ouvinte, acaba pensando uma outra coisa completamente desconexa com a explicação inicial. E por conta disto acaba por não entender de fato como uma rede neural consegue classificar as coisas.
Perceba o seguinte: não estou dizendo em momento algum que uma rede neural aprende. Que existe uma forma de inteligência oculta nela. Qualquer pessoa que pensar assim, estará completamente equivocada. Uma rede neural, nada mais é do que uma grande equação matemática. E esta equação consegue de alguma forma, que veremos nesta fase dos artigos. Entender os dados e os classificar de alguma maneira. E uma fez que eles estejam classificados. Qualquer dado semelhante, ou próximo de algo já classificado, será tido como uma informação com algum nível de possibilidade sobre algo já conhecido.
Sobre esta questão, já falei antes nos artigos anteriores. Mas aqui, vamos ver algo um pouco diferente. Não muito, só um pouco. Mas igualmente interessante. Então vamos começar pelo básico do básico, e vamos evoluir até chegar em uma forma de construir uma rede neural com base em neurônios que criamos neste começo.
O básico do básico
Para entender de fato como uma rede neural aprende, conforme vamos mostrando as coisas a ela. Quero pedir a você, meu caro leitor, que esqueça tudo que você pensa saber sobre Inteligência artificial e redes neurais. Grande parte do que você julga saber, muito provavelmente é pura bobagem ou informação equivocada. Ainda mais se você viu, leu ou procurou se informar com base em algum site de noticia ou coisa do gênero. O assunto rede neurais, basicamente veio a publico, por conta que alguns empresários, começaram a querer ganhar dinheiro em cima da coisa. Mas redes neurais, vem sendo desenvolvidas a anos. Na verdade, décadas. Não é algo recente, e tão pouco funciona como muito dizem. Elas são sim algo útil, porém voltadas a pessoas que realmente se interessam por programação.
Basicamente, toda e qualquer rede neural, e você pode subentender isto como sendo uma inteligência artificial. Se baseia em um conceito muito simples, no qual falei nos artigos anteriores. Porém aqui vamos nos aprofundar neste conceito. O tal conceito é a RETA SECANTE. Não interessa o que digam, falem, ou queiram mostrar. Tudo, absolutamente tudo em redes neurais se resume a este simples conceito. Encontrar uma RETA SECANTE que se aproxime da RETA TANGENTE. Simples assim.
Nos artigos anteriores, pulamos esta parte, e partimos direto para encontrar a reta tangente. Por isto da fórmulas vistas nos artigos anteriores. Elas tem como objetivo, justamente criar um atalho até a reta tangente. Então todo aquele material, se refere e trata, de um fato, muito específico. Que é quando temos em nosso banco de dados, informações devidamente selecionadas e filtradas. Quando isto acontece, não precisamos usar a reta secante, vamos direto para a reta tangente. Criando assim a fórmula que melhor represente o conteúdo de um banco de dados. Ou se preferir, um banco de conhecimento. Assim quando um programa de pesquisa for procurar algo neste banco de conhecimento, conseguirá nos dar um resultado, muitas das vezes quase perfeito, sobre uma dada informação. E este tipo de programa, é que muitos chamam de inteligência artificial. Porém existem casos em que não temos todas as informações para criar o banco de dados, ou banco de conhecimento. E mesmo assim, precisamos de alguma forma, que a rede neural consiga construir uma correlação entre as informações que estão entrando no banco de dados. Tal mecanismo é chamado de treinamento. Ou seja, você tem um monte de dados aparentemente sem nenhuma correlação entre eles. Mas que você consegue classificá-los de alguma forma simples. Então você envia estes dados de forma aleatória para a rede neural e ensinando como encontrar a tal reta tangente. Que no final irá gerar uma equação matemática. Esta equação é que servirá para que a inteligência artificial, consiga gerar resultados a nos ser apresentados. Isto conforme os dados desconhecidos pela rede neural, porém classificados por um humano, são usados para testar a tal equação gerada.
Não sei se você meu caro leitor, conseguiu compreender como a coisa funciona. Mas vou tentar deixar isto claro, para quem não é programador. Porém já sabe como fazer as coisas no mercado financeiro. Quando você vai começar no mercado, a primeira coisa que você deve fazer é o chamado BackTest. Então você escolhe um modelo que será operado. Vai no gráfico e procura todos os sinais onde aquele modelo apareceu. Isto é o equivalente a fase de treinamento da rede neural. Quando o modelo estiver sido completamente testado dentro de um período de tempo. Você começa a fase de testagem. Ou seja, você escolhe dias aleatórios e verifica se o modelo aconteceu ou não. Se você conseguir reconhecer o modelo, mesmo quando ele parece não estar presente, significa que você entendeu o modelo. E consegue expressar ele com uma fórmula matemática. Ok, agora vem a fase três, que é o teste as cegas. Onde você entra no mercado, e usando a conta demo, verifica se aquela fórmula matemática funciona ou não para identificar o seu modelo de operação. Se você já fez isto, sabe que nunca é 100% certo. Sempre existe uma margem de erro no sistema. Mas se esta margem de erro for pequena, tudo bem, sua fórmula funciona.
E é isto que uma rede neural tenta fazer. Procurar a tal fórmula, seja para reconhecimento de escrita, rosto, moléculas, plantas, bichos, sons, imagens, enfim qualquer coisa que você queira que ela reconheça.
Então vamos a um novo tópico, para começar a ver como podemos fazer isto.
Um neurônio
Tendo entendido o tópico anterior, vamos começar pelo mais simples que se possa criar. Ou seja, um único neurônio. Mas não fique desmotivado, imaginando que faremos apenas um único neurônio, e que ele não tem utilidade alguma. Você verá que a coisa irá crescer de forma muito rápida. Então não tente acelerar a coisa. Vá com calma, meu caro leitor. Comece devagar, entendendo o que cada coisa estará fazendo. Para realmente entender as coisas quando estivermos montando arquiteturas de neurônios.
Muito bem, vamos começar pelo código mostrado abaixo.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ void OnStart() { Print("The first neuron..."); } //+------------------------------------------------------------------+
Este código aparentemente sem graça, apenas imprime uma mensagem no terminal. Somente isto. Mas note que se trata de um script, mas também pode ser transformado em um serviço. Mas por enquanto, vamos deixar ele como sendo um simples script. Muito bem, o que um neurônio precisa fazer? Você pode pensar em mil coisas diferentes. Mas tente resumir elas a uma única coisa, na qual todas as demais, tem em comum. Esta é a primeira parte, resumir tudo a uma única coisa a ser feita.
Bem, um neurônio, precisa saber como fazer um cálculo. Isto para que possa nos retornar uma informação. Porém, não sabemos que cálculo é este, apenas temos a informação para treinar o neurônio. Estão o código acima, é modificado para o código abaixo.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; Print("The first neuron..."); } //+------------------------------------------------------------------+
Obviamente, olhando os dados de treinamento, você logo nota que existe um padrão ali. Ou seja, estamos multiplicando o primeiro número por dois. Porém o nosso neurônio, não sabe disto. Mas queremos que ele aprenda, a desenvolver uma equação, a fim de conseguir saber nos responder quando o informamos sobre um dado número. Então o nosso neurônio irá usar a equação que ele criou, e nos retornar uma informação, em cima do conhecimento que ele criou.
Legal, mas como vamos fazer o neurônio encontrar a tal fórmula? Detalhe: Não vale usar o conhecimento mostrado nos artigos anteriores. E então meu caro leitor, como podemos fazer com que o neurônio encontre a tal equação que melhor represente os dados de treinamento?
E mais uma vez, você poderá cair frente a algo que muitos fazem muita confusão. O que faremos é simplesmente dizer ao neurônio, para usar um valor aleatório qualquer, e com base neste valor tentar encontrar a equação matemática. Esta parte é onde muitos geram muita confusão. Não estamos dizendo para o neurônio procurar o valor que deve ser usado na multiplicação. Mesmo por que poderíamos estar usando uma soma, ou divisão, ou qualquer outra coisa. Até mesmo dados aleatórios. O que queremos é que o neurônio procure e encontre uma equação matemática e não um valor. O valor em si, que permitimos que ele comece usando, é simplesmente um ponto de partida. Apenas isto. Então melhoramos o código mais um pouco, como você pode ver abaixo.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; double weight; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; } //+------------------------------------------------------------------+
Bem, estamos progredindo. Só que antes, vamos entender uma coisa. Normalmente, na função MathSrand, usamos um valor vindo do relógio do sistema. Isto para que cada vez que estivermos iniciando o gerador de números aleatórios, ele comece em um valor diferente. Um lembrete: Os números gerados não são de fato aleatórios, eles são pseudoaleatórios. Ou seja, apesar de não serem aleatórios, é difícil encontrar um padrão, a fim de saber o próximo número na lista. Mas como queremos que sempre seja iniciado em algum valor, indicamos o valor a MathSrand. Assim poderemos testar a coisa com mais calma. Mas o que nos interessa é o valor que está na variável weight. Este é o valor para dizer ao nosso neurônio que ele está no caminho certo, ou no caminho errado. Como é um valor aleatório, ele não tem uma direção a seguir ainda.
Agora preste atenção a um outro fato. O valor de weight, está entre 0 e 1, isto por que, na macro o valor da função rand está sendo dividido pelo valor máximo que pode ser retornado por rand. Veja a documentação para mais detalhes a este respeito. Mas estou limitando weight entre 0 e 1 para facilitar o que será visto depois. Mas nada impede de você usar o valor de rand diretamente, apenas será necessário fazer alguns ajustes no futuro. Isto quando formos ver outras questões de cálculo.
Muito bem, agora vamos começar a fazer as coisas acontecerem. Nosso neurônio está começando a tomar forma. Mas para que sigamos em frente, primeiro precisamos dizer ao neurônio para usar uma fórmula matemática inicial. Veja, que a coisa não nasce do nada. Precisamos dizer a rede neural como ela deverá funcionar. Ela não é capaz de se criar por si só. Ok, se você tem um mínimo de conhecimento sobre cálculos matemáticos, sabe que tudo e absolutamente tudo, da mais simples a mais complexa dos polinômios, pode ser resumido em uma única coisa. Tal coisa são as derivadas. Mas não qualquer derivada. Estamos querendo uma bem específica, que seja tão simples quanto for possível. Nos artigos anteriores, mostrei que a equação da reta é a equação mais simples possível. E qualquer polinômio, ou equação pode ser resumida a esta equação da reta, se você for derivando a equação ao seu limite máximo. Em último caso, podemos chegar em uma constante. Mas o que precisamos é uma derivada que podemos usar como cálculo mínimo. Então voltamos a cair na equação mostrada abaixo.
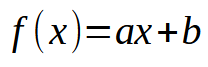
Aqui não importa a ordem desta derivada. O que nos importa é que se a simplificamos mais, chegaremos a uma constante. E não é isto que queremos, pois uma constante não nos serve para nada. Porém, o valor de constante < b >, que é o ponto de intersecção deverá neste primeiro momento ser pensado como sendo igual a zero. Já o valor da constante < a > que é o coeficiente angular, iremos usar o valor que estiver na variável weight. Com isto temos um novo código como é visto abaixo.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; double weight, fx, x; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; for (uint c = 0; c < Train.Size() / 2; c++) { x = Train[c][0]; fx = x * weight; Print("Actual: ", fx , " expected: ", x); } } //+------------------------------------------------------------------+
Ok, ao rodar este código você verá no terminal do MetaTrader uma imagem parecida com a vista logo abaixo.
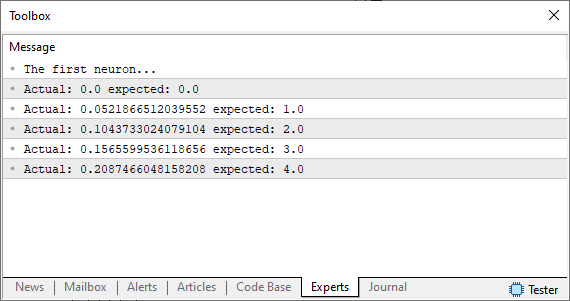
Note que o fato de estamos usando um chute, que é o tal número aleatório não está nem perto do que queremos ou esperávamos obter. Mas então como podemos melhorar isto? Bem, nosso neurônio básico está bem encaminhado. O que precisamos fazer agora, é basicamente usar o mesmo princípio que vimos nos artigos anteriores. Ou seja, vamos definir um sistema de erro para o neurônio saber para onde caminhar a fim de buscar a equação mais adequada. Fazer isto é algo bastante simples como você pode notar no código abaixo.
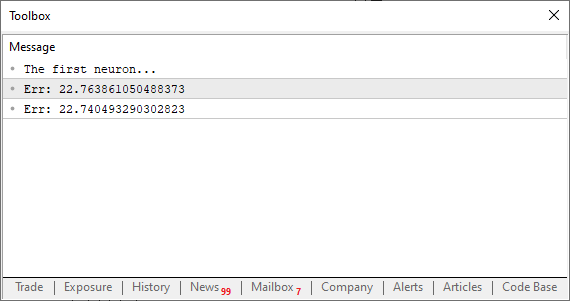
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; double weight, fx, dx, x, err; const uint nTrain = Train.Size() / 2; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; err = 0; for (uint c = 0; c < nTrain; c++) { x = Train[c][0]; fx = x * weight; Print("Actual: ", fx , " expected: ", x); dx = fx - Train[c][1]; err += MathPow(dx, 2); } Print("Err: ", err / nTrain); } //+------------------------------------------------------------------+
Ok, ao rodar este código você irá ver algo parecido com a imagem abaixo.
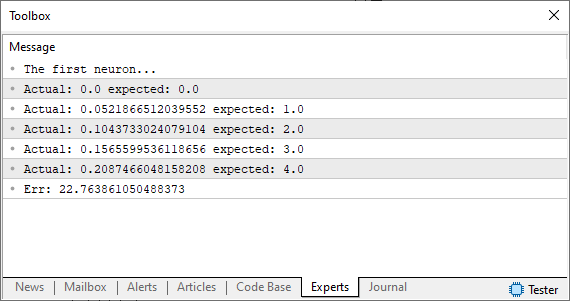
Muito bem, neste ponto, estamos em uma encruzilhada. Isto por que estamos exatamente naquele ponto, onde fazíamos ajustes manuais, a fim de procurar o menor erro. Se você não sabe do que estou falando, veja os artigos anteriores para entender. Mas diferente do que fazíamos, que era um ajuste manual. Aqui iremos forçar o computador a procurar o melhor ajuste para nos. Não iremos atrás da reta tangente, da forma como era feito antes. Iremos atrás da reta tangente usando a reta secante. E é a partir deste momento em que a máquina começará a enlouquecer. Podendo em alguns momentos convergir e em outros divergir da solução correta.
Lembre-se do seguinte fato: Queremos fazer com que o valor da variável err, diminua. E é este fato que permitirá que a máquina enlouqueça. Mas para entender melhor isto, vamos a um novo tópico.
Usando a reta secante
No artigo Rede neural na prática: Reta Secante, mencionei brevemente o fato da reta secante ser a principal reta na rede neural. Lá mostrei uma figura que você pode rever logo abaixo.
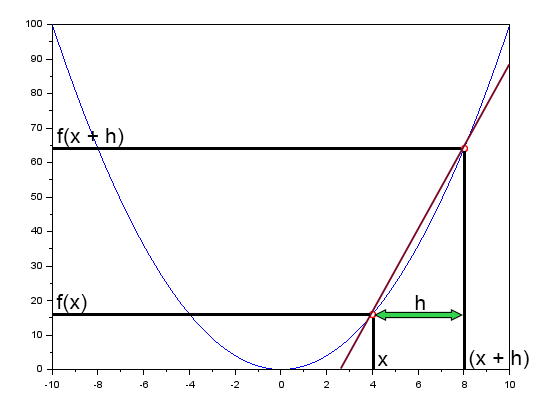
Esta figura, mostra a curva de erro. Assim como também uma reta. Esta é a reta secante. Ao limpar a figura acima, deixando em destaque apenas a reta secante. Podemos ver a imagem abaixo.
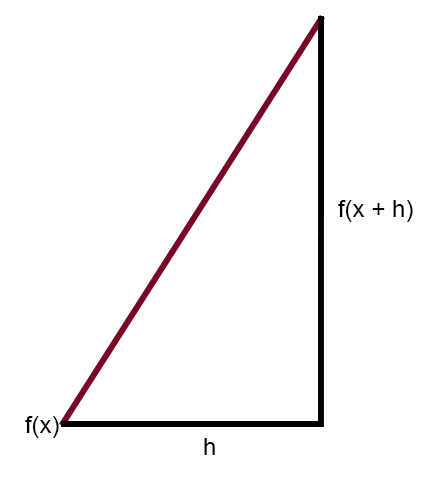
Se você formular esta mesma imagem, de modo a tornar o valor da constante < h > em um número igual a zero, você chegará se seguinte expressão mostrada abaixo.
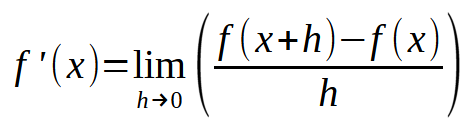
Agora vem a parte divertida. Esta fórmula mostrada acima, é justamente a fórmula mágica, de rede neural que aprende com seus erros. Ou seja, se você usar esta equação mostrada acima. Você conseguirá forçar o computador, a encontrar uma equação de reta, que melhor represente os dados que estão entrando na rede neural. E com isto forçar a máquina a aprender a resolver um dado problema. Seja ele qual for. Não importa o que se esteja jogando dentro da rede neural. O cálculo será sempre e sempre o mesmo. Agora preste atenção. O segredo está em usar um valor adequado para < h >. Se o valor for maior que um dado limite, a máquina irá endoidar, tentando encontrar a melhor equação de reta. Se o valor for muito pequeno, a máquina irá demorar várias e várias horas para encontrar a equação mais adequada. Então um pouco de bom senso, irá lhe ajudar bastante neste momento. Não seja muito exigente, mas também não seja muito desleixado. Seja prudente.
Assim como faremos para adicionar isto no neurônio? Bem, antes de fazermos isto, vamos fazer um pequeno teste. Veja como o código deverá ficar.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 2; const double eps = 1e-3; //+------------------------------------------------------------------+ double Cost(const double w) { double err; err = 0; for (uint c = 0; c < nTrain; c++) err += MathPow((Train[c][0] * w) - Train[c][1], 2); return err / nTrain; } //+------------------------------------------------------------------+ void OnStart() { double weight; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; Print("Err: ", Cost(weight)); Print("Err: ", Cost(weight + eps)); } //+------------------------------------------------------------------+
Ui. Este agora sim, passou a ser um programa realmente interessante. Ao executar ele você verá algo parecido com a imagem abaixo.
O que nos importa aqui é justamente se o valor do erro está crescendo ou diminuindo. O valor em sim não nos interessa. Agora preste atenção: O valor de eps é o nosso < h > na fórmula vista logo acima. Quanto mais este valor aproximar de zero, mais perto da reta tangente ficaremos a cada iteração executada. Isto por que a reta secante começará a convergir para um ponto limite. Então o que precisamos fazer agora é algo muito simples. Apenas precisamos criar um laço, de forma que este valor de erro, ou custo, seja cada vez menor. Chegará um ponto em que ele irá parar de diminuir e começará a crescer. Neste exato momento o programa, deverá notar isto e sair do laço. Caso contrário ele irá entrar em um loop infinito. Mas também podemos criar outro tipo de limitação, a fim de evitar o laço infinito. Normalmente pedimos para que o laço efetue um dado numero de interações antes de encerrar. Isto para o caso do programa não conseguir convergir ou se ele ficar doidão. Pois pode acontecer de ele ficar doido devido ao valor usado para executar os passos. Veremos isto em um momento oportuno. Por enquanto, não se preocupe com este fato. Mas independente disto, nada lhe impede de forçar o programa a procurar o menor valor de custo. Fica ao seu critério, o momento de terminar o laço. De qualquer forma, para evitar a fadiga. Vamos ver como seria isto na prática. Veja o código abaixo para entender.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. //+------------------------------------------------------------------+ 06. double Train[][2] { 07. {0, 0}, 08. {1, 2}, 09. {2, 4}, 10. {3, 6}, 11. {4, 8}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 2; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w) 18. { 19. double err; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. err += MathPow((Train[c][0] * w) - Train[c][1], 2); 24. 25. return err / nTrain; 26. } 27. //+------------------------------------------------------------------+ 28. void OnStart() 29. { 30. double weight, err; 31. 32. Print("The first neuron..."); 33. MathSrand(512); 34. weight = (double)macroRandom; 35. 36. for(ulong c = 0; c < 10; c++) 37. { 38. err = ((Cost(weight + eps) - Cost(weight)) / eps); 39. weight -= (err * eps); 40. Print(c, " --> ", weight, " :: ", err); 41. } 42. Print("Weight: ", weight); 43. } 44. //+------------------------------------------------------------------+
Ao executar este código, você poderá ver no terminal algo parecido com a imagem abaixo.
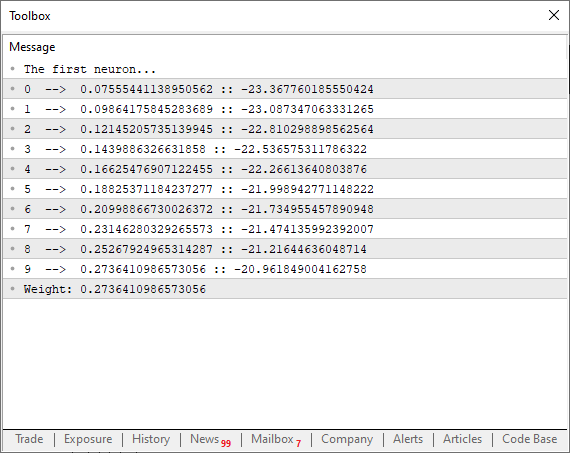
Note uma coisa interessante sendo feita aqui. Na linha 38 estamos executando justamente o cálculo mostrado acima. Onde estamos forçando a reta secante a procurar um ponto limite mínimo para que a função venha a convergir. Porém note que na linha 39, não estou simplesmente modificando, o ponto na curva da função, usando puramente o valor de erro, ou custo total. Por que? O motivo é que se você fizer isto, o programa irá ficar pulando de um lado para outro na curva da função parabólica. E não queremos isto. Queremos que o valor venha a ser modificado com calma, sem sobressaltos. Mas por que não usamos o valor de eps para ajustar o próximo ponto na curva da parábola? O motivo é que se formos fazer assim, precisaríamos saber se o erro estaria aumentando ou diminuindo. Algo que se torna completamente desnecessário, se fizermos a fatoração vista na linha 39. Além do mais, isto força o neurônio a tentar convergir mais rapidamente no começo do processo. E conforme ele vai se aproximando do valor ideal, a curva de decaimento, começará a ficar cada vez mais suave. Tendendo assim a construirmos uma função de decaimento log invertido. O que é muito bom, diga-se de passagem. Pois acabaremos chegando em um valor de erro adequado muito mais rápido.
Ok, mas este mesmo código visto acima, pode melhorar ainda mais. Podemos adicionar algumas outras coisas para podemos analisar melhor o que está acontecendo. Ao mesmo tempo, podemos adicionar um teste extra, que terá como objetivo, fazer com que o laço finalize, assim que o ponto mínimo de convergência for alcançado. Isto mesmo antes do contador não ter alcançado o máximo de interações. Desta maneira o novo código pode ser visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. //+------------------------------------------------------------------+ 06. double Train[][2] { 07. {0, 0}, 08. {1, 2}, 09. {2, 4}, 10. {3, 6}, 11. {4, 8}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 2; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w) 18. { 19. double err; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. err += MathPow((Train[c][0] * w) - Train[c][1], 2); 24. 25. return err / nTrain; 26. } 27. //+------------------------------------------------------------------+ 28. void OnStart() 29. { 30. double weight, err, e1; 31. int f = FileOpen("Cost.csv", FILE_COMMON | FILE_WRITE | FILE_CSV); 32. 33. Print("The first neuron..."); 34. MathSrand(512); 35. weight = (double)macroRandom; 36. 37. for(ulong c = 0; (c < ULONG_MAX) && ((e1 = Cost(weight)) > eps); c++) 38. { 39. err = (Cost(weight + eps) - e1) / eps; 40. weight -= (err * eps); 41. if (f != INVALID_HANDLE) 42. FileWriteString(f, StringFormat("%I64u;%f;%f\n", c, err, e1)); 43. } 44. if (f != INVALID_HANDLE) 45. FileClose(f); 46. Print("Weight: ", weight); 47. } 48. //+------------------------------------------------------------------+
A graça deste código é que ele é extremamente divertido. Isto para que você possa estudar e brincar com ele. Tomei a liberdade de lançar os valores não para dentro do terminal do MetaTrader 5, mas para dentro de um arquivo. Ao fazer isto, podemos gerar um gráfico para estudar com calma o que está acontecendo. No caso como o código se encontra configurado. O gráfico resultante pode ser visto abaixo:
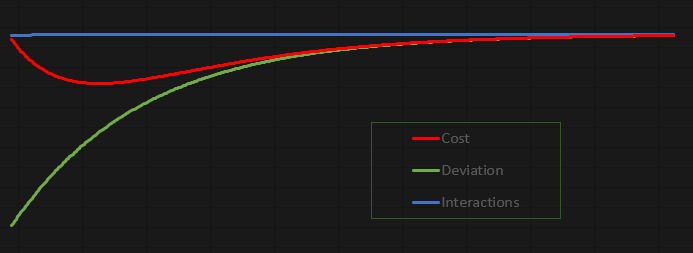
Este gráfico foi feito no Excel, com base nos valores que estarão no arquivo criado pelo neurônio. É bem verdade que a forma como o arquivo está sendo criado, é um tanto quanto desajeitada. Porém como se trata de uma aplicação voltada para ser o mais didática e divertida. Não vejo problema na maneira como estamos fazendo a transferência dos dados para dentro do arquivo.
Considerações finais
Neste artigo, fizemos a confecção de um neurônio básico. Apesar de ele ser algo muito simples, e muitos acharem que o código é totalmente bobo e sem nenhum propósito. Quero que você, meu caro leitor, e entusiasta pelo tema de redes neurais. Brinque e se divirta estudando este simples neurônio. Não precisa ficar com receio de mexer no código a fim de entender o mesmo. Ele está no anexo, justamente para isto. Para que você consiga entender como um simples neurônio funciona. Quero que você leia este artigo com bastante calma. Procure digitar o código desde o seu primeiro momento, e vá testando o mesmo até chegar no código presente no final do artigo. Faça isto, não procurando copiar o código, mas sim criando ele da forma que você o faça funcionar como mostro no artigo. Crie o mesmo, da forma como você o entenda. Não procure me imitar, mas sim conseguir o mesmo resultado que eu estou obtendo. Ou seja, o valor que criar a correlação entre os dados presentes no array de treinamento. Simples assim.
Como o código estará no anexo. Quero dar algumas dicas de pontos que você pode mexer, que vão ser bem interessantes neste primeiro contato. Lembre-se de estudar cada mudança com calma. O primeiro ponto é no array de treinamento que se encontra presente na linha seis no código do anexo. Você pode colocar valores diferentes ali. Isto para que o neurônio tente achar alguma correlação entre eles.
Um outro ponto bastante interessante, é mudar o valor da constante da linha 15. Mude ele para valores maiores e menores e veja o resultado que o neurônio irá reportar no final de seu trabalho. Você notará que valores menores, tomam mais tempo de processamento. Porém como compensação o resultado é bem mais próximo do valor ideal.
Outro ponto, igualmente interessante de ser modificado é na linha 35. Ali estamos colocando um peso que irá variar entre zero e um. Mas você pode modificar isto, multiplicando o valor retornado da macro. Por exemplo, experimente colocar na linha 35 algo como mostrado logo abaixo.
weight = (double)macroRandom * 50;
Você notará que as coisas serão bem diferentes, pelo simples fato de ter mudado o peso inicial que o neurônio irá começar usando. E quando se sentir totalmente seguro do que está acontecendo, mude o código da linha 34 para o que é visto logo abaixo.
MathSrand(GetTickCount());
Ao fazer isto você notará que as coisas realmente são bem mais interessantes do que muitos costumam falar. Mas principalmente você começará a entender como um simples neurônio, de uma rede neural, consegue aprender algo. No próximo artigo, vamos tornar este simples neurônio algo ainda mais interessante. Então, antes de ver o próximo artigo, estude e brinque bastante com este código daqui. Pois a coisa está apenas começando.
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso