-Aleksey- : 당신은 틀렸습니다. 어떤 경우에도 특정 수의 단계에 대해 고유하게 간주됩니다. 고정되어 있더라도 그렇지는 않습니다. 아마도 당신은 이것을 하는 방법을 모를 것입니다. 그러나 이것은 중요한 것이 아니며 가장 중요한 것은 당신이 일하고 계속 파고 있다는 것입니다. 원하는 경우 - 내가 가르칠 것입니다, 개인에 작성합니다. HP를 사용하여 정상 잔차를 구한다는 것은 내가 이해하는 한 기존 계량 경제학을 통해 한 단계 이상 예측할 수 없는 비 결정적 추세가 식별되었음을 나타냅니다. 그리고 선택된 결정론적 경향을 예측하는 대신 정상 랜덤 잔차를 예측하는 것이 필요한 이유는 무엇입니까? 당신은 모든 것을 거꾸로 뒤집고 있습니다. 패키지를 계산의 수단으로 사용하기 전에 하고 싶은 것의 의미를 이해해야 합니다.
당신은 틀렸습니다. 어떤 경우에도 특정 수의 단계에 대해 모호하지 않은 것으로 간주됩니다.
기본적으로. 다음은 위의 모델에 대한 예측 오차의 그래프입니다.
그러한 오류로 예측을 신뢰할 수 있다고 생각하십니까? 예측 오류에 대한 기술 통계를 제공합니다.
바로 지금, 나는 사실과 예측 라인을 버릴 것입니다 ... 당신은 그것을 적절하게 운전할 것입니까?
저 할 수 있어요. 그러나 위의 모델을 보십시오. 성공. 지금까지는 이 모델 을 적용할 수 없다는 것이 분명해졌습니다. 그래서 모델로 시작하고 싶었다. 이것은 내가 아이디어를 전달하려고 하는 첫 번째 지점이 아닙니다. 예측은 할 수 있지만 신뢰할 수 있고 어느 정도입니까? 가장 중요한 것은 신뢰의 문제이며 나머지는 앞뒤로 숫자에 불과합니다.
faa1947 , 당신은 HP 필터가 무엇인지, 그리고 왜 이것이 결정적인 경향이 아닌지 이해하지 못합니다. 결정론은 매개변수 추세입니다. 반면 HP는 비모수적 추세이며 이러한 추세는 예측에 사용되지 않으므로 한 단계 예측에만 사용할 수 있습니다. 물론 죄송합니다. 하지만 각 편지를 설명할 수는 없습니다. 볼륨이 매우 클 것입니다.
faa1947 , 당신은 HP 필터가 무엇인지, 그리고 왜 이것이 결정적인 경향이 아닌지 이해하지 못합니다. 결정론은 매개변수 추세입니다. 반면 HP는 비모수적 추세이며 이러한 추세는 예측에 사용되지 않으므로 한 단계 예측에만 사용할 수 있습니다. 물론 죄송합니다. 하지만 각 편지를 설명할 수는 없습니다. 볼륨이 매우 클 것입니다.
나는 당신과 같은 초보자입니다. 나는 우리가 간단하게 시작해야 한다고 생각합니다. 확률 이론 및 매트 측면에서 추세, 존재 및 유형에 대한 논리적으로 일관된 수학적 정의를 제공합니다. 통계. 현재 추세, 예측 추세 및 그 관계. 그런 명확한 이해는 없지만 무언가를 세는 것은 그다지 의미가 없다고 생각합니다.
당신은 틀렸습니다. 어떤 경우에도 특정 수의 단계에 대해 고유하게 간주됩니다. 고정되어 있더라도 그렇지는 않습니다. 아마도 당신은 이것을 하는 방법을 모를 것입니다. 그러나 이것은 중요한 것이 아니며 가장 중요한 것은 당신이 일하고 계속 파고 있다는 것입니다. 원하는 경우 - 내가 가르칠 것입니다, 개인에 작성합니다. HP를 사용하여 정상 잔차를 구한다는 것은 내가 이해하는 한 기존 계량 경제학을 통해 한 단계 이상 예측할 수 없는 비 결정적 추세가 식별되었음을 나타냅니다. 그리고 선택된 결정론적 경향을 예측하는 대신 정상 랜덤 잔차를 예측하는 것이 필요한 이유는 무엇입니까? 당신은 모든 것을 거꾸로 뒤집고 있습니다. 패키지를 계산의 수단으로 사용하기 전에 하고 싶은 것의 의미를 이해해야 합니다.
당신은 틀렸습니다. 어떤 경우에도 특정 수의 단계에 대해 모호하지 않은 것으로 간주됩니다.
기본적으로. 다음은 위의 모델에 대한 예측 오차의 그래프입니다.
그러한 오류로 예측을 신뢰할 수 있다고 생각하십니까? 예측 오류에 대한 기술 통계를 제공합니다.
HP를 사용하여 정상 잔차를 얻는 것은 비 결정적 추세가 식별되었음을 나타냅니다.
HP를 사용하여 정지된 나머지를 얻는 것은 불가능합니다(위 참조).
HP는 분석 곡선입니다. 결정적이며 추세로 사용됩니다.
내가 이해하는 한 일반적인 계량 경제학 을 통해 한 단계 이상 예측되지 않습니다.
당신은 완전히 오해하고 있습니다.
그리고 왜 필요한가 - 정상 임의 나머지를 예측하기 위해
아무도 임의의 나머지를 예측하지 않습니다. 이것은 결정론적 추세에 대한 노이즈입니다.
...주어진 결정적 경향을 예측하려면?
TA가 일반적으로 수행하는 결정론적 추세를 예측하는 데 문제가 없습니다.
당신은 모든 것을 거꾸로 뒤집고 있습니다. 패키지를 계산의 수단으로 사용하기 전에 하고 싶은 것의 의미를 이해해야 합니다.
나는 패키지를 적용하고 당신은 그것을 보지 않고 논의합니다.
내 모든 게시물은 계산을 기반으로 하며 관련 튜토리얼에 대한 링크를 제공할 수 있습니다.
+1
바로 지금, 나는 사실과 예측 라인을 버릴 것입니다 ... 당신은 그것을 적절하게 운전할 것입니까?
그리고 나는 예측에 대한 신뢰에 대해 이야기하고 있습니다 - 관심을 확인합시다 .. 나는 2 줄을 버릴 것입니다 - 1 팩트 값과 두 번째 예측 .. 실행하고 당신의 의견을 말해 ... 그러면 우리는 예측이 실제로 어떻게 작동했는지 확인하십시오 ...
모든 것은 물론 약 .. 관심을 위해 ...
패키지로 전송:
인 것 같습니다. 회귀 방정식
FACT = C(1)*FACT(-1) + C(2)*HP(-1) + C(3)*HP(-2)
매끄럽게 하고 필터와 코티르 사이에 잔류물이 생겼습니다. 이것은 소음입니다.
나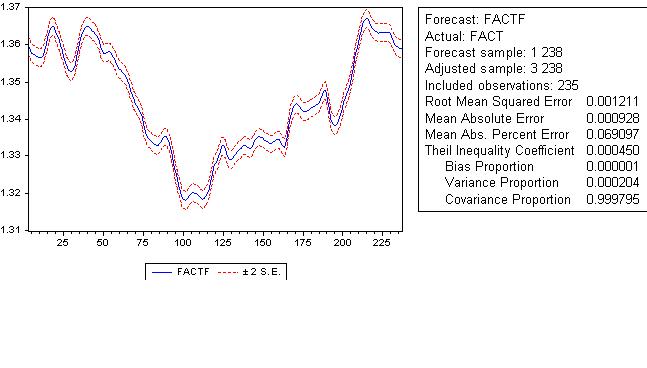
절대 예측 오차는 9핍입니다.
공동 일정:
빨간색은 내 예측입니다. 그는 당신보다 훨씬 낫습니다.
우리는 그가 성배를 받았다고 생각할 수 있습니다, 만세!!!
사용하지 마십시오. 잔류물의 이분산성에 대한 검정은 잔류물의 이분산성이 없을 확률이 0을 제공하므로 이분산성을 모델링할 필요가 있습니다. 한 발 앞선 예측은 신도 없이 거짓말을 할 것입니다. 그것이 전체 성배입니다.
예측 오차 그래프를 살펴보겠습니다.
오프셋이 있습니다. 우리는 추세를 완전히 제거하지 않았습니다. 기술 통계는 최종 평결을 제공합니다. 그런 멋진 예측은 사용할 수 없습니다.
faa1947 , 당신은 HP 필터가 무엇인지, 그리고 왜 이것이 결정적인 경향이 아닌지 이해하지 못합니다. 결정론은 매개변수 추세입니다. 반면 HP는 비모수적 추세이며 이러한 추세는 예측에 사용되지 않으므로 한 단계 예측에만 사용할 수 있습니다. 물론 죄송합니다. 하지만 각 편지를 설명할 수는 없습니다. 볼륨이 매우 클 것입니다.
어떤 것이 귀하의 의견에 가장 잘 사용되었는지 보여주십시오 ... 여러 가지를 가질 수 있습니다 ...
내 예측? 신뢰할 수 있습니까?
내 것이 더 좋고 신뢰할 수 없으며 그 이유를 보여 드렸습니다.
나는 당신의 예측의 신뢰성에 대해 아무 말도 할 수 없습니다. 왜냐하면 그것이 어떻게 얻어졌는지 모르기 때문입니다. 예를 들어 이 예측의 오류는 무엇인지, 이 오류의 통계는 무엇입니까? - 그리고 이것 외에 마차와 작은 수레.
시리즈를 계속할 수 있습니까? 바 20? 당신의 예측...
나는 방법을 모릅니다. 오류가 누적되고 요약되며 20개의 양초 후에는 20배 더 커질 것이라는 것을 압니다. 그래서 한 번도 해본 적이 없어요. 패키지에는 소위 "동적" 예측이 있지만 흥미로운 것은 없습니다.
4MB가 넘습니다. 구글의 ' 계량학 '은 책도 많고 대학에서도 그런 전문 분야가 있다. EViews를 넣는 것이 가장 좋습니다. 도구와 각 장에 대한 링크가 있습니다.
행운을 빕니다.
나는 단지 가르침을 따랐지만 장점에 대해 뭔가를 원합니다.