取引における機械学習に関する記事
AIベースの取引ロボットの作成: ネイティブPythonとの統合、行列とベクトル、数学と統計のライブラリなど
取引に機械学習を使用する方法をご覧ください。ニューロン、パーセプトロン、畳み込みネットワークと再帰型ネットワーク、予測モデルなどの基本から始めて、独自のAIの開発に取り組みます。金融市場でのアルゴリズム取引のためにニューラル ネットワークを訓練して適用する方法を学びます。
新しい記事を追加

取引の機会を逃しています。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索

ニューラルネットワークの実験(第6回):価格予測のための自給自足ツールとしてのパーセプトロン
この記事では、パーセプトロンを自給自足の価格予測ツールとして使用する例として、一般的な概念と最もシンプルな既製のエキスパートアドバイザー(EA)を紹介し、その最適化の結果について説明します。

ニューラルネットワークの実験(第5回):ニューラルネットワークに渡すための入力の正規化
ニューラルネットワークはトレーダーのツールキットの究極のツールです。この仮定が正しいかどうかを確認してみましょう。MetaTrader 5は、取引でニューラルネットワークを使用するための自立した媒体としてアプローチされています。簡単な説明が記載されています。
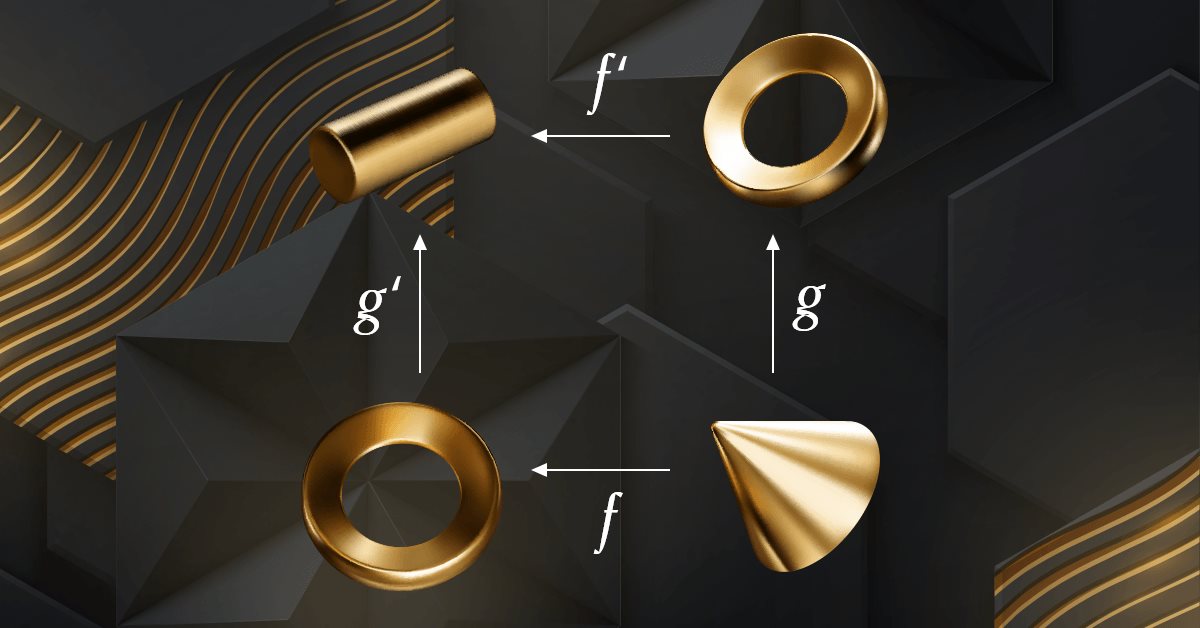
MQL5の圏論(第6回):単射的引き戻しと全射的押し出し
圏論は、数学の多様かつ拡大を続ける分野であり、最近になってMQL5コミュニティである程度取り上げられるようになりました。この連載では、その概念と原理のいくつかを探索して考察することで、トレーダーの戦略開発におけるこの注目すべき分野の利用を促進することを目的としたオープンなライブラリを確立することを目指しています。
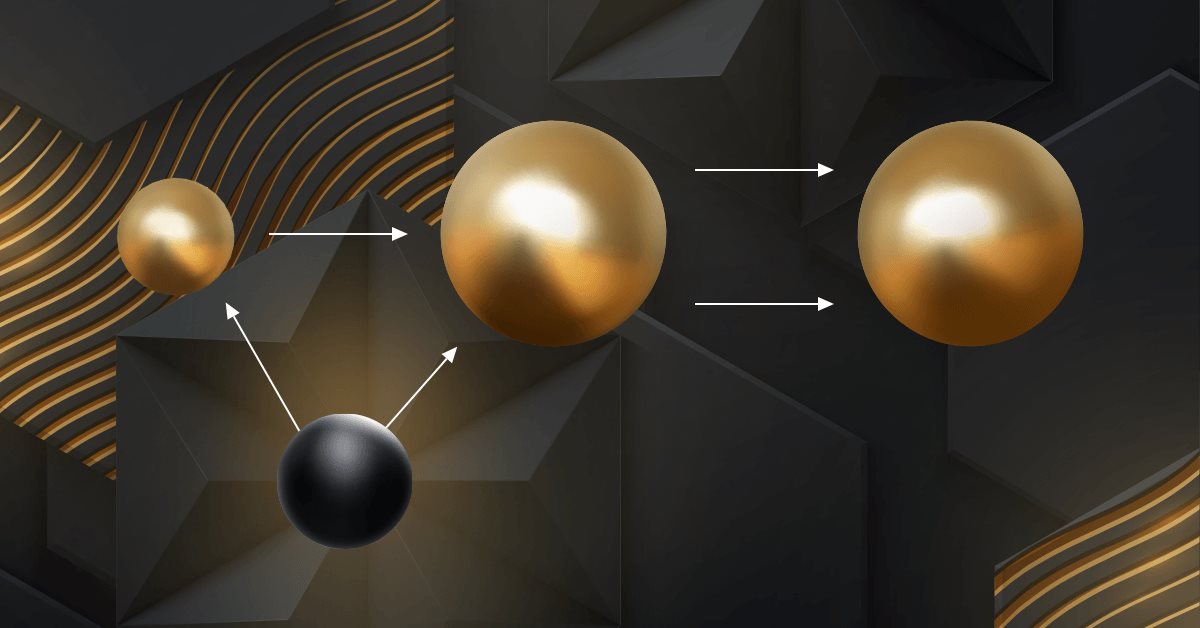
MQL5の圏論(第5回)等化子
圏論は、数学の多様かつ拡大を続ける分野であり、最近になってMQL5コミュニティである程度取り上げられるようになりました。この連載では、その概念と原理のいくつかを探索して考察することで、トレーダーの戦略開発におけるこの注目すべき分野の利用を促進することを目的としたオープンなライブラリを確立することを目指しています。

母集団最適化アルゴリズム:電磁気的アルゴリズム(ЕМ)
この記事では、様々な最適化問題において、電磁気的アルゴリズム(EM、electroMagnetism-like Algorithm)を使用する原理、方法、可能性について解説しています。EMアルゴリズムは、大量のデータや多次元関数を扱うことができる効率的な最適化ツールです。
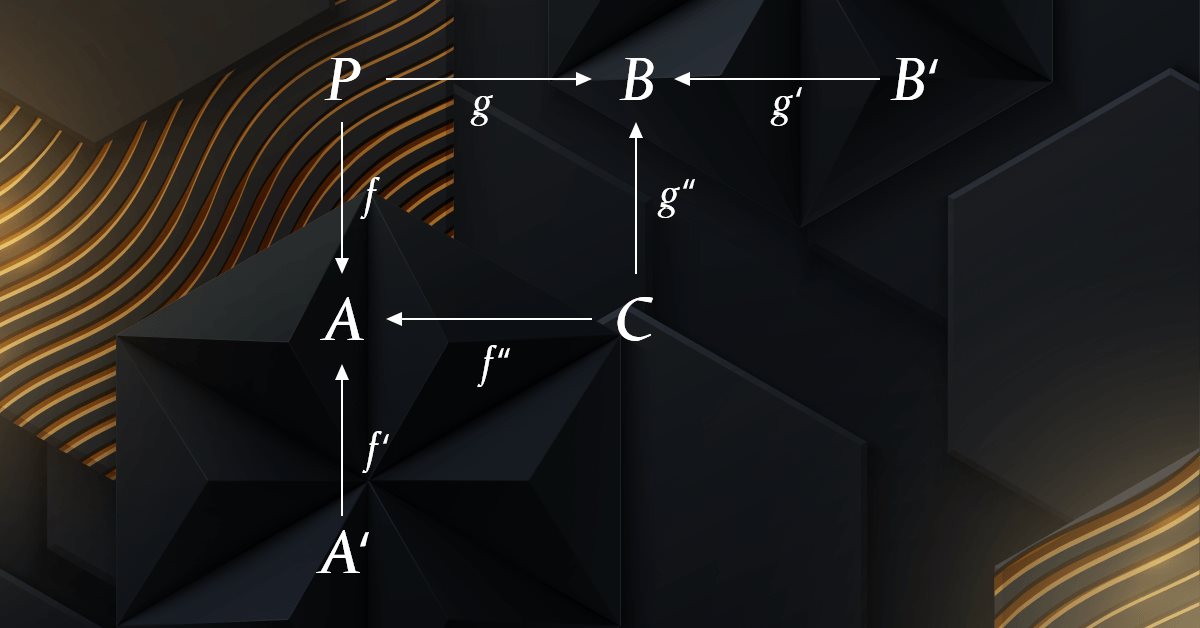
MQL5の圏論(第4回):スパン、実験、合成
圏論は数学の一分野であり、多様な広がりを見せていますが、MQL5コミュニティでは今のところ比較的知られていません。この連載では、その概念のいくつかを紹介して考察することで、トレーダーの戦略開発におけるこの注目すべき分野の利用を促進することを目的としたオープンなライブラリを確立することを目指しています。
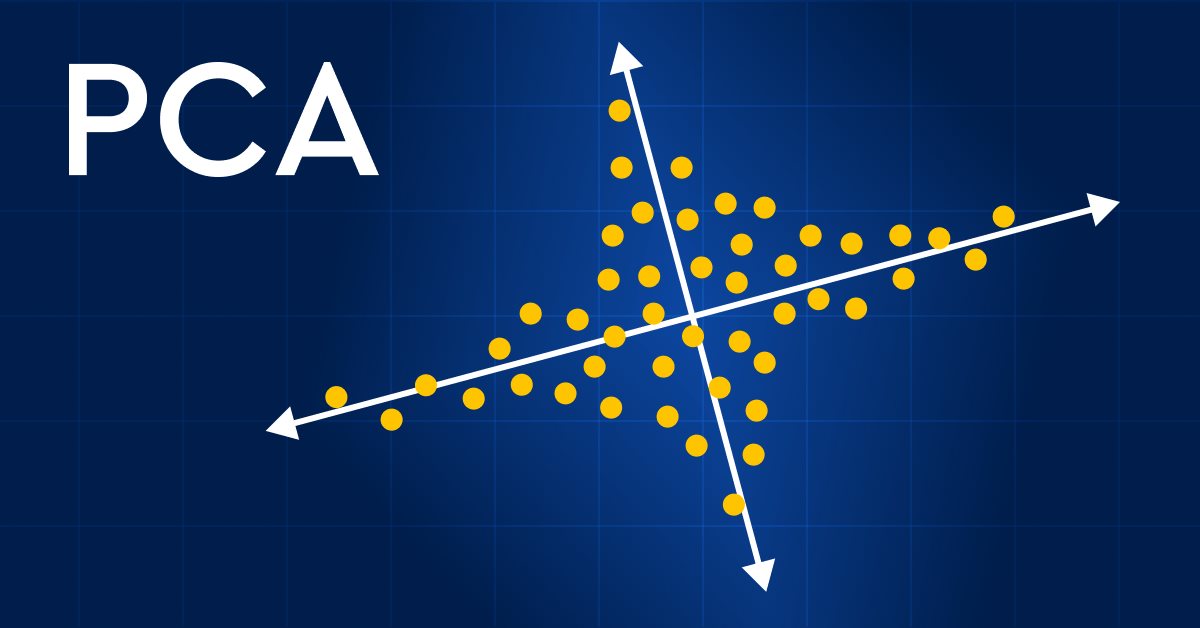
データサイエンスと機械学習(第13回):主成分分析(PCA)で金融市場分析を改善する
主成分分析(Principal component analysis、PCA)で金融市場分析に革命を起こしましょう。この強力な手法がどのようにデータの隠れたパターンを解き放ち、潜在的な市場動向を明らかにし、投資戦略を最適化するかをご覧ください。この記事では、PCAが複雑な金融データを分析するための新しいレンズをどのように提供できるかを探り、従来のアプローチでは見逃されていた洞察を明らかにします。金融市場データにPCAを適用することで競争力を高め、時代を先取りする方法をご覧ください。

データサイエンスと機械学習(第12回):自己学習型ニューラルネットワークは株式市場を凌駕することができるのか?
常に株式市場を予測しようとするのにお疲れでないでしょうか。より多くの情報に基づいた投資判断をするための水晶玉があったらとお思いでしょうか。自己学習型ニューラルネットワークは、あなたが探していたソリューションかもしれません。この記事では、これらの強力なアルゴリズムが、株式市場を凌駕する「波に乗る」のに役立つのかどうかを探ります。膨大な量のデータを分析し、パターンを特定することで、自己訓練されたニューラルネットワークは、しばしば人間のトレーダーよりも精度の高い予測をおこなうことができます。この最先端のテクノロジーを使って、利益を最大化し、よりスマートな投資判断をおこなう方法をご紹介します。

母集団最適化アルゴリズム:SSG(Saplings Sowing and Growing up、苗木の播種と育成)
SSG(Saplings Sowing and Growing up、苗木の播種と育成)アルゴリズムは、様々な条件下で優れた生存能力を発揮する、地球上で最も回復力のある生物の1つからインスピレーションを得ています。

MQL5の圏論(第3回)
圏論は数学の一分野であり、多様な広がりを見せていますが、MQL5コミュニティでは今のところ比較的知られていません。この連載では、その概念のいくつかを紹介して考察することで、トレーダーの戦略開発におけるこの注目すべき分野の利用を促進することを目的としたオープンなライブラリを確立することを目指しています。

MQL5行列を使用した誤差逆伝播法によるニューラルネットワーク
この記事では、行列を使用してMQL5で誤差逆伝播法(バックプロパゲーション)アルゴリズムを適用する理論と実践について説明します。スクリプト、インジケータ、エキスパートアドバイザー(EA)の例とともに、既製のクラスが提示されます。

母集団最適化アルゴリズム:ハーモニーサーチ(HS)
今回は、完璧な音のハーモニーを見つける過程に着想を得た、最も強力な最適化アルゴリズムであるハーモニーサーチ(HS)を研究し、検証してみます。私たちの評価でトップになるのはどのアルゴリズムでしょうか。

MQL5でONNXモデルをアンサンブルする方法の例
ONNX (Open Neural Network eXchange)は、ニューラルネットワークを表現するために構築されたオープンフォーマットです。この記事では、1つのエキスパートアドバイザー(EA)で2つのONNXモデルを同時に使用する方法を示します。

MQL5でONNXモデルを使用する方法
ONNX (Open Neural Network Exchange)は、機械学習モデルを表現するために構築されたオープンフォーマットです。この記事では、CNN-LSTMモデルを作成して金融時系列を予測する方法を検討します。MQL5エキスパートアドバイザー(EA)で作成されたONNXモデルを使用する方法も示します。

ニューラルネットワークが簡単に(第36回):関係強化学習
前回の記事で説明した強化学習モデルでは、元のデータ内のさまざまなオブジェクトを識別できる畳み込みネットワークのさまざまなバリアントを使用しました。畳み込みネットワークの主な利点は、場所に関係なくオブジェクトを識別できることです。同時に、畳み込みネットワークは、オブジェクトやノイズのさまざまな変形がある場合、常にうまく機能するとは限りません。これらは、関係モデルが解決できる問題です。

ニューラルネットワークの実験(第4回):テンプレート
この記事では、実験と非標準的な方法を使用して収益性の高い取引システムを開発し、ニューラルネットワークがトレーダーに役立つかどうかを確認します。ニューラルネットワークを取引に活用するための自給自足ツールとしてMetaTrader 5を使用します。簡単に説明します。

母集団最適化アルゴリズム:モンキーアルゴリズム(MA)
今回は、最適化アルゴリズムであるモンキーアルゴリズム(MA、Monkey Algorithm)について考えてみたいと思います。この動物が難関を乗り越え、最もアクセスしにくい木のてっぺんまで到達する能力が、MAアルゴリズムのアイデアの基礎となりました。

母集団最適化アルゴリズム:重力探索アルゴリズム(GSA)
GSAは、無生物から着想を得た母集団最適化アルゴリズムです。アルゴリズムに実装されたニュートンの重力の法則のおかげで、その物体の相互作用をモデル化する高い信頼性によって、惑星系や銀河団の魅惑的なダンスを観察することができます。今回は、最も興味深く、独創的な最適化アルゴリズムの1つを考えてみます。また、宇宙物体の移動シミュレータも提示されています。

ニューラルネットワークが簡単に(第35回):ICM(Intrinsic Curiosity Module、内発的好奇心モジュール)
強化学習アルゴリズムの研究を続けます。これまで検討してきたすべてのアルゴリズムでは、あるシステム状態から別の状態への遷移ごとに、エージェントがそれぞれの行動を評価できるようにするための報酬方策を作成する必要がありました。しかし、この方法はかなり人工的なものです。実際には、行動と報酬の間には、ある程度の時間差があります。今回は、行動から報酬までの様々な時間の遅れを扱うことができるモデル訓練アルゴリズムに触れてみましょう。
ニューラルネットワークが簡単に(第34部):FQF(Fully Parameterized Quantile Function、完全にパラメータ化された分位数関数)
分散型Q学習アルゴリズムの研究を続けます。以前の記事では、分散型の分位数Q学習アルゴリズムについて検討しました。最初のアルゴリズムでは、与えられた範囲の値の確率を訓練しました。2番目のアルゴリズムでは、特定の確率で範囲を訓練しました。それらの両方で、1つの分布のアプリオリな知識を使用し、別の分布を訓練しました。この記事では、モデルが両方の分布で訓練できるようにするアルゴリズムを検討します。

ニューラルネットワークが簡単に(第33部):分散型Q学習における分位点回帰
分散型Q学習の研究を続けます。今日は、この方法を反対側から見てみましょう。価格予測問題を解決するために、分位点回帰を利用する可能性を検討します。
データサイエンスと機械学習(第11回):単純ベイズ、取引における確率論
確率を利用した取引は綱渡りのようなもので、正確さとバランス、そしてリスクに対する鋭い理解が必要です。取引の世界では、確率がすべてです。確率は、成功と失敗、利益と損失の違いになります。確率の力を活用することで、トレーダーは十分な情報に基づいた意思決定をおこない、リスクを効果的に管理し、経済的目標を達成することができます。つまり、経験豊富な投資家であれ、初心者のトレーダーであれ、確率を理解することは、取引の可能性を引き出す鍵になるのです。この記事では、確率を利用したエキサイティングな取引の世界を探求し、取引ゲームを次のレベルに引き上げる方法を紹介します。

母集団最適化アルゴリズム:細菌採餌最適化(BFO)
大腸菌の採餌戦略は、科学者にBFO最適化アルゴリズムの作成を促しました。このアルゴリズムには、最適化に対する独自のアイデアと有望なアプローチが含まれており、さらに研究する価値があります。

ニューラルネットワークの実験(第3回):実用化
この連載では、実験と非標準的なアプローチを使用して、収益性の高い取引システムを開発し、ニューラルネットワークがトレーダーに役立つかどうかを確認します。ニューラルネットワークを取引に活用するための自給自足ツールとしてMetaTrader 5にアプローチします。

母集団最適化アルゴリズム:侵入雑草最適化(IWO)
雑草がさまざまな条件で生き残る驚くべき能力は、強力な最適化アルゴリズムのアイデアになっています。IWO(Invasive Weed Optimization)は、以前にレビューされたものの中で最高のアルゴリズムの1つです。


母集団最適化アルゴリズム:ホタルアルゴリズム(FA)
今回は、ホタルアルゴリズム(FA)という最適化手法について考えてみます。修正により、このアルゴリズムは部外者から真の評価表リーダーへと変貌を遂げました。

インディケーター情報の測定
機械学習は、ストラテジー開発の手法として注目されています。これまで、収益性と予測精度の最大化が重視される一方で、予測モデル構築のためのデータ処理の重要性はあまり注目されてきませんでした。この記事では、Timothy Masters著の書籍「Testing and Tuning Market Trading Systems」に記載されているように、予測モデル構築に使用するインディケーターの適切性を評価するために、エントロピーの概念を使用することについて考察しています。

行列ユーティリティ - 行列とベクトルの標準ライブラリの機能を拡張する
行列は大規模な数学的演算を効率的に処理できるため、機械学習アルゴリズムや一般的なコンピュータの基盤となっています。標準ライブラリは必要なものをすべて備えていますが、ユーティリティファイルでライブラリにはまだないいくつかの関数を導入して、拡張する方法を見てみましょう。

MQL5の圏論(第2回)
圏論は数学の一分野であり、多様な広がりを見せていますが、MQL5コミュニティではまだ比較的知られていません。この連載では、その概念のいくつかを紹介し、考察することで、コメントや議論を呼び起こし、トレーダーの戦略開発におけるこの注目すべき分野の利用を促進することを目的としたオープンなライブラリを確立することを目指しています。
MQL5の圏論(第1回)
圏論は数学の一分野であり、多様な広がりを見せていますが、MQLコミュニティではまだ比較的知られていない分野です。この連載では、その概念のいくつかを紹介して考察することで、コメントや議論を呼び起こし、トレーダーの戦略開発におけるこの注目すべき分野の利用を促進することを目的としたオープンなライブラリを確立することを目指しています。

母集団最適化アルゴリズム:魚群検索(FSS)
魚群検索(FSS)は、そのほとんど(最大80%)が親族の群落の組織的な群れで泳ぐという魚の群れの行動から着想を得た新しい最適化アルゴリズムです。魚の集合体は、採餌の効率や外敵からの保護に重要な役割を果たすことが証明されています。

母集団最適化アルゴリズム:カッコウ最適化アルゴリズム(COA)
次に考察するのは、レヴィフライトを使ったカッコウ検索最適化アルゴリズムです。これは最新の最適化アルゴリズムの1つで、リーダーボードの新しいリーダーです。

母集団最適化アルゴリズム:灰色オオカミオプティマイザー(GWO)
最新の最適化アルゴリズムの1つである灰色オオカミオプティマイザについて考えてみましょう。テスト関数の元々の動作により、このアルゴリズムは、以前に検討されたものの中で最も興味深いものの1つになります。これは、ニューラルネットワークの訓練に使用される最も優れたアルゴリズムの1つであり、多くの変数を持つ滑らかな関数です。


ニューラルネットワークが簡単に(第32部):分散型Q学習
この連載で前回Q学習法を紹介しました。この手法は、各行動の報酬を平均化するものです。2017年には、報酬分布関数を研究する際に、より大きな成果を示す2つの研究が発表されました。そのような技術を使って、私たちの問題を解決する可能性を考えてみましょう。

知っておくべきMQL5ウィザードのテクニック(第04回):線形判別分析
今日のトレーダーは哲学者であり、ほとんどの場合、新しいアイデアを探して試し、変更するか破棄するかを選択します。これは、かなりの労力を要する探索的プロセスです。この連載では、MQL5ウィザードがこの取り組みにおけるトレーダーの主力であるべきであることを示しています。
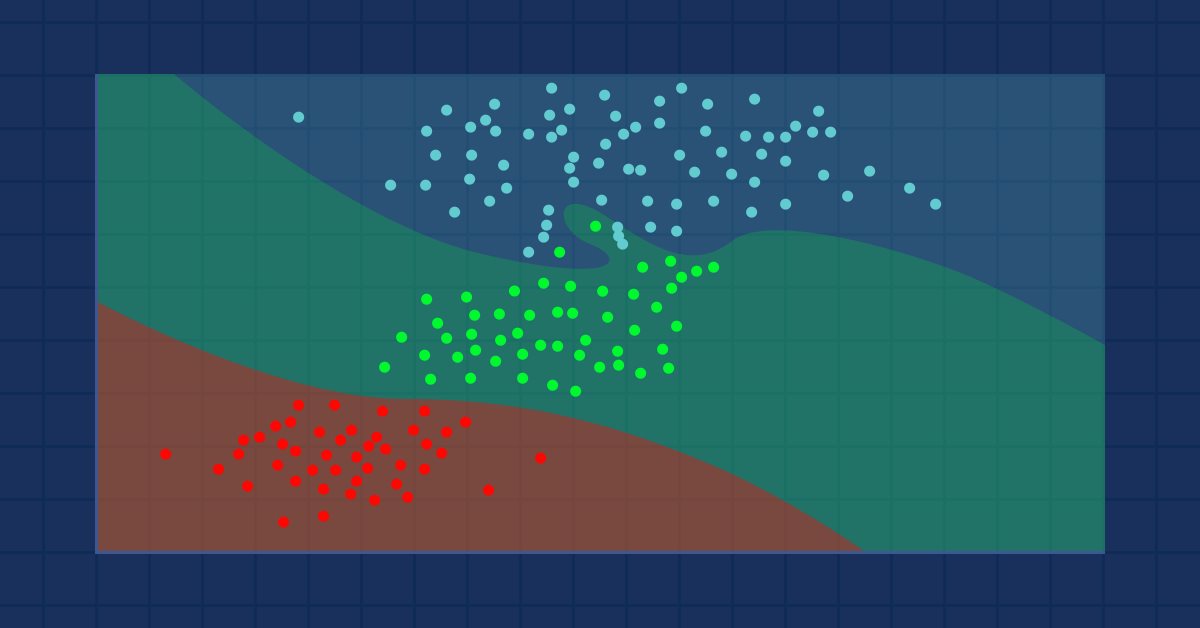
データサイエンスと機械学習(第09回):K近傍法(KNN)
これは、訓練データセットから学習しない遅延アルゴリズムです。代わりにデータセットを保存し、新しいサンプルが与えられるとすぐに動作します。シンプルでありながら、実世界でさまざまなケースに応用されています。

母集団最適化アルゴリズム:蟻コロニー最適化(ACO)
今回は、蟻コロニー最適化アルゴリズムについて解析します。このアルゴリズムは非常に興味深く、複雑です。この記事では、新しいタイプのACOの作成を試みます。