
ニューラルネットワークが簡単に(第11部): GPTについて

目次
はじめに
GPTニューラルネットワークモデルは、2018年6月にOpenAIによって発表されてすぐに多くの言語テストで最良の結果を示しました。GDP-2は2019年に登場し、GPT-3は2020年5月に発表されました。これらのモデルは、関連するテキストを生成するニューラルネットワークの能力を実証しました。追加的な実験は音楽と画像を生成する能力に関するものでした。このようなモデルの主な欠点は、それらが関与するコンピューティングリソースに関連しています。最初のGPTを訓練するのには8つのGPUを搭載したマシンで1か月かかりました。この欠点は、新しい問題を解決するために事前訓練されたモデルを使用する可能性によって部分的に補うことができますが、モデルのサイズを考慮すると、機能を維持するにはかなりのリソースが必要です。
1. GPTモデルについて
概念的には、GPTモデルは、以前に検討されたTransformerに基づいて構築されています。主なアイデアは、事前に大量のデータに対して教師なしで訓練したモデルを比較的少量のラベル付きデータに対して微調整することです。
2段階で訓練する理由はモデルのサイズです。GPTのような最新の深層機械学習モデルには、最大で数億もの多数のパラメータが含まれます。このようなニューラルネットワークの訓練には膨大な訓練用の標本が必要です。教師あり学習を使用する場合、ラベル付き訓練セットの作成には大きな労働力がかかります。同時に、Web上には多くの異なるデジタル化されたラベルなしテキストがあり、教師なしモデルの訓練には最適です。ただし、教師なし学習の結果が教師あり学習より劣っていることがは統計によって示されているため、教師なし訓練の後で、ラベル付けされたデータの比較的小さな標本でモデルが微調整されます。
GPTは教師なし学習によって言語モデルを学習し、ラベル付きデータでさらに訓練されて特定のタスクに合わせたモデルが調整されます。したがって、事前訓練された1つのモデルを複製して微調整すればさまざまな言語タスクを実行できます。制限は教師なし学習の元のセットの言語に基づいています。
実践により、このアプローチは広い範囲にわたる言語の問題で良い結果を生み出すことが示されています。たとえば、GPT-3モデルは、特定のトピックに関する一貫性のあるテキストを生成できます。ただし、指定されたモデルには1,750億のパラメータ、シーケンスが含まれており、570GBのデータセットで事前訓練されています。
GPTモデルは自然言語処理用に開発されたものですが、音楽や画像の生成タスクでもうまく機能しました。
理論的には、GPTモデルはデジタル化されたデータの任意のシーケンスで使用できます。唯一の前提条件は、教師なし事前学習のためのデータとリソースが十分であることです。
2. GPTと以前に検討されたTransformerの違い
以前に検討されたTransformerとGPTモデルの違いを考えてみましょう。まず、GPTモデルはデコーダのみを使用するため、エンコーダがありません。エンコーダがないので、モデルにはエンコーダ-デコーダのSelf-Attention内層がありません。次の図は、GPT Transformerブロックを示しています。
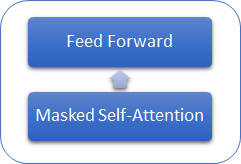
従来のTransformerと同様に、GPTモデルのブロックは重なって構築されています。また、各ブロックには、Attentionメカニズム用の独自の重み行列と、全結合フィードフォワード層があります。ブロックの数によってモデルのサイズが決まります。ブロックスタックは非常に大きくなる可能性があります。GPT-1と最小のGPT-2(GPT-2 Small)にはブロックが12個のありますが、GPT-2 Extra Largeには48個、GPT-3には96個があります。
従来の言語モデルと同様、GPTではシーケンスでの先行する要素との関係を見つけることができるのみで、将来を見据えることはできません。ただし、Transformerとは異なり、GPTでは要素のマスキングを使用しません。代わりに、計算プロセスに変更を加えます。GPTは、後続の要素のスコア行列のAttention率をリセットします。
同時に、GPTは自己回帰モデルとして分類できます。反復ごとに1つのシーケンストークンが生成されて、結果のトークンは入力シーケンスに追加され、次の反復のためにモデルに入力されます。
従来のTransformerと同様、self-attentionメカニズム内のトークンごとに、クエリ、キー、値の3つのベクトルが生成されます。新しい反復ごとに入力シーケンスが1トークンだけ変化する自己回帰モデルでは、トークンごとにベクトルを再計算する必要はありません。したがって、GPTの各層は、シーケンスの新しい要素に対してのみベクトルを計算し、シーケンスの各要素に対してそれらを計算します。各Transformerブロックは、後で使用するためにそのベクトルを保存します。
このアプローチにより、モデルは、最終的なトークンを受け取る前に、単語ごとにテキストを生成できます。
もちろん、GPTモデルではMulti-Head Attentionメカニズムを使用します。
3. 実装
始める前に、アルゴリズムを簡単に繰り返します。
- トークンの入力シーケンスがTransformerブロックに供給されます。
- トークンベクトルに、訓練中の重みWの対応する行列を乗算することにより、トークン(クエリ、キー、値)ごとに3つのベクトルが計算されます。
- クエリとキーを乗算することにより、シーケンス要素間の依存関係を決定します。この手順では、シーケンスの各要素の「クエリ」ベクトルに、シーケンスの現在の要素と以前のすべての要素のキーベクトルが乗算されます。
- 得られたAttentionスコアの行列は、各クエリのコンテキストでSoftMax関数を使用して正規化されます。シーケンスの後続の要素には、ゼロAttentionスコアが設定されます。
- 正規化されたAttentionスコアにシーケンスの対応する要素の「値」ベクトルを乗算し、結果のベクトルを加算することにより、シーケンスの各要素のAttention補正値(Z)を取得します。
- 次に、すべてのAttentionヘッドの結果に基づいて、重み付けされたZベクトルを決定します。このために、すべてのAttentionヘッドからの修正された「値」ベクトルが連結されて単一のベクトルになり、訓練済みのW0行列が乗算されます。
- 結果のテンソルは入力シーケンスに追加され、正規化されます。
- Multi-Heads Self-Attentionメカニズムの後には、フィードフォワードブロックの2つの全結合層が続きます。最初の(隠れ)層には、ReLU活性化関数を使用した入力シーケンスの4倍のニューロンが含まれています。2番目の層の次元は入力シーケンスの次元と等しく、ニューロンは活性化関数を使用しません。
- 全結合層の結果は、FeedForwardブロックにフィードされるテンソルと合計されます。結果のテンソルは正規化されます。
すべてのSelf-Attentionヘッドに対して1つのシーケンス。さらに、2〜5のアクションは、各Self-Attentionヘッドで同じです。
手順3と4の結果として、シーケンス内の要素の数に応じたサイズの正方行列スコアを取得します。各「クエリ」のコンテキスト内のすべての要素の合計は「1」です。
3.1. モデルの新しいクラスの作成
モデルを実装するために、CNeuronBaseOCL基本クラスに基づいて新しいクラスCNeuronMLMHAttentionOCLを作成しましょう。意図的に一歩後退し、以前に作成されたAttentionクラスは使用しませんでした。これは、新しいMulti-Head Self-Attention作成原則を扱っているためです。以前の第10部で、CNeuronMHAttentionOCLクラスを作成しました。これは、4つのAttentionスレッドの順次再計算を提供します。スレッドの数はメソッドにハードコーディングされているため、スレッドの数を変更するには、クラスコードとそのメソッドの変更に関連して、かなりの労力が必要になります。
警告: 上記のように、GPTモデルは、同じ(変更不可能な)ハイパーパラメータを持つ同一のTransformerブロックのスタックを使用しますが、唯一の違いは、訓練される行列にあります。そのため、クラスの作成時に渡すことができるハイパーパラメータを使用してモデルを作成できるようにする多層ブロックを作成することにしました。これには、スタック内のTransformerブロックの繰り返し回数が含まれます。
その結果、いくつかの指定されたパラメータに基づいてモデルのほぼ全体を作成できるクラスができました。したがって、新しいクラスのprotectedブロックで、ブロックパラメータを格納するための5つの変数を宣言します。
| iLayers | モデル内のTransformerブロックの数 |
| iHeads | Self-Attentionヘッドの数 |
| iWindow | 入力ウィンドウサイズ(1つの入力シーケンストークン) |
| iWindowKey | Query, Key, Value内部ベクトルの次元 |
| iUnits | 入力シーケンスの要素(トークン)の数 |
また、protectedブロックで、テンソルと訓練重み行列のバッファのコレクションを格納する6つの配列を宣言します。
| QKV_Tensors | Query, Key, Valueテンソルおよびそれらの勾配を格納するための配列 |
| QKV_Weights | Wq、Wk、Wvの重み行列とそれらのモーメント行列のコレクションを格納するための配列 |
| S_Tensors | スコア行列とその勾配のコレクションを格納するための配列 |
| AO_Tensors | Self-Attentionメカニズムの出力テンソルとその勾配を格納するための配列 |
| FF_Tensors | フィードフォワードブロックの入力テンソル、隠れテンソル、出力テンソル、およびそれらの勾配を格納するための配列 |
| FF_Weights | フィードフォワードブロックの重み行列とそのモーメントを格納するための配列 |
クラスメソッドは、後で実装するときに検討します。
class CNeuronMLMHAttentionOCL : public CNeuronBaseOCL { protected: uint iLayers; ///< Number of inner layers uint iHeads; ///< Number of heads uint iWindow; ///< Input window size uint iUnits; ///< Number of units uint iWindowKey; ///< Size of Key/Query window //--- CCollection *QKV_Tensors; ///< The collection of tensors of Queries, Keys and Values CCollection *QKV_Weights; ///< The collection of Matrix of weights to previous layer CCollection *S_Tensors; ///< The collection of Scores tensors CCollection *AO_Tensors; ///< The collection of Attention Out tensors CCollection *FF_Tensors; ///< The collection of tensors of Feed Forward output CCollection *FF_Weights; ///< The collection of Matrix of Feed Forward weights ///\ingroup neuron_base_ff virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///< \brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previos layer. virtual bool ConvolutionForward(CBufferDouble *weights, CBufferDouble *inputs,CBufferDouble *outputs, uint window, uint window_out, ENUM_ACTIVATION activ); ///< \brief Convolution Feed Forward method of calling kernel ::FeedForwardConv(). virtual bool AttentionScore(CBufferDouble *qkv, CBufferDouble *scores, bool mask=true); ///< \brief Multi-heads attention scores method of calling kernel ::MHAttentionScore(). virtual bool AttentionOut(CBufferDouble *qkv, CBufferDouble *scores, CBufferDouble *out); ///< \brief Multi-heads attention out method of calling kernel ::MHAttentionOut(). virtual bool SumAndNormilize(CBufferDouble *tensor1, CBufferDouble *tensor2, CBufferDouble *out); ///< \brief Method sum and normalize 2 tensors by calling 2 kernels ::SumMatrix() and ::Normalize(). ///\ingroup neuron_base_opt virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); ///< Method for updating weights.\details Calling one of kernels ::UpdateWeightsMomentum() or ::UpdateWeightsAdam() in depends on optimization type (#ENUM_OPTIMIZATION).@param NeuronOCL Pointer to previos layer. virtual bool ConvolutuionUpdateWeights(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *momentum1, CBufferDouble *momentum2, uint window, uint window_out); ///< Method for updating weights in convolution layer.\details Calling one of kernels ::UpdateWeightsConvMomentum() or ::UpdateWeightsConvAdam() in depends on optimization type (#ENUM_OPTIMIZATION). virtual bool ConvolutionInputGradients(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *inp_gradient, uint window, uint window_out, uint activ); ///< Method of passing gradients through a convolutional layer. virtual bool AttentionInsideGradients(CBufferDouble *qkv,CBufferDouble *qkv_g,CBufferDouble *scores,CBufferDouble *scores_g,CBufferDouble *gradient); ///< Method of passing gradients through attention layer. public: /** Constructor */CNeuronMLMHAttentionOCL(void); /** Destructor */~CNeuronMLMHAttentionOCL(void); virtual bool Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object.@param[in] window Size of in/out window and step.@param[in] units_countNumber of neurons.@param[in] optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); ///< Method to transfer gradients to previous layer @param[in] prevLayer Pointer to previous layer. //--- virtual int Type(void) const { return defNeuronMLMHAttentionOCL; }///< Identificator of class.@return Type of class //--- methods for working with files virtual bool Save(int const file_handle); ///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle); ///< Load method @param[in] file_handle handle of file @return logical result of operation };
クラスコンストラクタでは、クラスハイパーパラメータの初期値を設定し、コレクション配列を初期化します。
CNeuronMLMHAttentionOCL::CNeuronMLMHAttentionOCL(void) : iLayers(0), iHeads(0), iWindow(0), iWindowKey(0), iUnits(0) { QKV_Tensors=new CCollection(); QKV_Weights=new CCollection(); S_Tensors=new CCollection(); AO_Tensors=new CCollection(); FF_Tensors=new CCollection(); FF_Weights=new CCollection(); }
したがって、クラスデストラクタのコレクション配列を削除します。
CNeuronMLMHAttentionOCL::~CNeuronMLMHAttentionOCL(void) { if(CheckPointer(QKV_Tensors)!=POINTER_INVALID) delete QKV_Tensors; if(CheckPointer(QKV_Weights)!=POINTER_INVALID) delete QKV_Weights; if(CheckPointer(S_Tensors)!=POINTER_INVALID) delete S_Tensors; if(CheckPointer(AO_Tensors)!=POINTER_INVALID) delete AO_Tensors; if(CheckPointer(FF_Tensors)!=POINTER_INVALID) delete FF_Tensors; if(CheckPointer(FF_Weights)!=POINTER_INVALID) delete FF_Weights; }
モデルの構築に伴うクラスの初期化は、Initメソッドで実行されます。メソッドはパラメータを受け取ります。
| numOutputs | リンクを作成するための後続の層の要素の数 |
| myIndex | 層のニューロンインデックス |
| open_cl | OpenCLオブジェクトポインタ |
| window | 入力ウィンドウサイズ(入力シーケンストークン) |
| window_key | Query, Key, Value内部ベクトルの次元 |
| heads | Self-Attentionヘッド(スレッド)の数 |
| units_count | 入力シーケンスの要素の数 |
| layers | モデルスタック内のブロック(層)の数 |
| optimization_type | 訓練中のパラメータ最適化方法 |
bool CNeuronMLMHAttentionOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint window,uint window_key,uint heads,uint units_count,uint layers,ENUM_OPTIMIZATION optimization_type) { if(!CNeuronBaseOCL::Init(numOutputs,myIndex,open_cl,window*units_count,optimization_type)) return false; //--- iWindow=fmax(window,1); iWindowKey=fmax(window_key,1); iUnits=fmax(units_count,1); iHeads=fmax(heads,1); iLayers=fmax(layers,1);
メソッドの開始時に、適切なメソッドを呼び出して親クラスを初期化します。受信したOpenCLオブジェクトポインタと入力シーケンスサイズを検証するための基本的なチェックは実行しません。これらのチェックはすでに親クラスのメソッドに実装されているためです。
親クラスの初期化が成功したら、ハイパーパラメータを対応する変数に保存します。
次に、作成されるテンソルのサイズを計算します。Multi-Head Attentionを整理するために以前に変更されたアプローチに注意を払ってください。クエリ、キー、値の各ベクトルに対して個別の配列を作成することはありません。これらは、1つの配列に結合されます。さらに、Attentionヘッドごとに個別の配列を作成することはありません。代わりに、QKV(クエリ+キー+値)、スコア、およびself-attentionメカニズムの出力用の共通配列を作成します。要素は、テンソルのインデックスのレベルでシーケンスに分割されます。もちろん、このアプローチは理解するのがより困難です。また、テンソルで必要な要素を見つけるのがより難しい場合があります。ただし、Attentionヘッドの数に応じてモデルを柔軟にし、カーネルレベルでスレッドを並列化することにより、すべてのAttentionヘッドの同時再計算を整理できます。
QKV_Tensor(num)テンソルのサイズは、内部ベクトルの3つのサイズ(クエリ+キー+値)とヘッドの数の積として定義されます。重みの連結行列のサイズQKV_Weightは、入力シーケンストークンの3つのサイズの積として定義され、オフセット要素、内部ベクトルのサイズ、およびAttentionヘッドの数によって増加します。同様に、残りのテンソルのサイズを計算してみましょう。
uint num=3*iWindowKey*iHeads*iUnits; //Size of QKV tensor uint qkv_weights=3*(iWindow+1)*iWindowKey*iHeads; //Size of weights' matrix of QKV tensor uint scores=iUnits*iUnits*iHeads; //Size of Score tensor uint mh_out=iWindowKey*iHeads*iUnits; //Size of multi-heads self-attention uint out=iWindow*iUnits; //Size of our tensor uint w0=(iWindowKey+1)*iHeads*iWindow; //Size W0 tensor uint ff_1=4*(iWindow+1)*iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2=(4*iWindow+1)*iWindow; //Size of weights' matrix 2-nd feed forward layer
すべてのテンソルのサイズを決定したら、ブロック内のAttention層の数でサイクルを実行して、必要なテンソルを作成します。ループ本体内には2つのネストされたループが編成されています。最初のループは、値テンソルとその勾配の配列を作成します。2つ目は、重み行列とそのモーメントの配列を作成します。最終層では、フィードフォワードブロック出力テンソルとその勾配に対して新しい配列が作成されない代わりに、親クラスの出力と勾配配列へのポインタがコレクションに追加されます。このような単純な手順により、配列間で値を転送する不必要な反復が回避されるだけでなく、不必要なメモリ消費が排除されます。
for(uint i=0; i<iLayers; i++) { CBufferDouble *temp=NULL; for(int d=0; d<2; d++) { //--- Initialize QKV tensor temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(num,0)) return false; if(!QKV_Tensors.Add(temp)) return false; //--- Initialize scores temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(scores,0)) return false; if(!S_Tensors.Add(temp)) return false; //--- Initialize multi-heads attention out temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(mh_out,0)) return false; if(!AO_Tensors.Add(temp)) return false; //--- Initialize attention out temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(out,0)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 1 temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(4*out,0)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i==iLayers-1) { if(!FF_Tensors.Add(d==0 ? Output : Gradient)) return false; continue; } temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(out,0)) return false; if(!FF_Tensors.Add(temp)) return false; } //--- Initialize QKV weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; for(uint w=0; w<qkv_weights; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!QKV_Weights.Add(temp)) return false; //--- Initialize Weights0 temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w=0; w<w0; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- Initialize FF Weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w=0; w<ff_1; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; for(uint w=0; w<ff_1; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- for(int d=0; d<(optimization==SGD ? 1 : 2); d++) { temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights,0)) return false; if(!QKV_Weights.Add(temp)) return false; temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(w0,0)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initialize FF Weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(ff_1,0)) return false; if(!FF_Weights.Add(temp)) return false; temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(ff_2,0)) return false; if(!FF_Weights.Add(temp)) return false; } } //--- return true; }
その結果、各層について、次のテンソルの行列が得られます。
| QKV_Tensor |
|
| S_Tensors |
|
| AO_Tensors |
|
| FF_Tensors |
|
| QKV_Weights |
|
| FF_Weights |
|
配列コレクションを作成したら、「true」でメソッドを終了します。すべてのクラスとそのメソッドの完全なコードは、添付ファイルにあります。
3.2. フィードフォワード
フィードフォワードパスは、従来、feedForwardメソッドで構成されていました。このメソッドは、ニューラルネットワークの前の層へのポインタをパラメータとして受け取ります。メソッドの開始時に、受信したポインタの有効性を確認します。
bool CNeuronMLMHAttentionOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL)==POINTER_INVALID) return false;
次に、ループを編成して、ブロックのすべての層を再計算しましょう。前述の他のクラスの類似のメソッドとは異なり、このメソッドはトップレベルのメソッドです。編成された操作は、データの準備と補助メソッドの呼び出しに限定されます(これらのメソッドのロジックについては以下で説明します)。
ループの開始時に、コレクションから、現在の層に対応するQKVおよびQKV_Weightsテンソルの入力データバッファを受け取ります。次に、ConvolutionForwardを呼び出して、Query、Key、Value各ベクトルを計算します。
for(uint i=0; (i<iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferDouble *inputs=(i==0? NeuronOCL.getOutput() : FF_Tensors.At(6*i-4)); CBufferDouble *qkv=QKV_Tensors.At(i*2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i*(optimization==SGD ? 2 : 3)),inputs,qkv,iWindow,3*iWindowKey*iHeads,None)) return false;
Attention層を増やすときに問題が発生しました。ある時点で、エラー5113 ERR_OPENCL_TOO_MANY_OBJECTSが発生しました。そのため、すべてのテンソルをGPUメモリに永続的に保存することを検討する必要がありました。したがって、操作の完了後、この手順で使用されなくなったバッファを解放します。コードでは、GPUメモリから解放されたバッファの最新データを読み取ることを忘れないでください。本稿で紹介するクラスでは、バッファデータはカーネル初期化メソッドで読み取られます。これについては後で説明します。
CBufferDouble *temp=QKV_Weights.At(i*(optimization==SGD ? 2 : 3)); temp.BufferFree();
本稿で紹介するクラスでは、バッファデータはカーネル初期化メソッドで読み取られます。これについては後で説明します。
//--- Score calculation temp=S_Tensors.At(i*2); if(IsStopped() || !AttentionScore(qkv,temp,true)) return false; //--- Multi-heads attention calculation CBufferDouble *out=AO_Tensors.At(i*2); if(IsStopped() || !AttentionOut(qkv,temp,out)) return false; qkv.BufferFree(); temp.BufferFree();
Multi-Heads Self-Attentionを計算した後、連結されたAttention出力を入力シーケンスサイズに折りたたんで、2つのベクトルを追加し、結果を正規化します。
//--- Attention out calculation temp=FF_Tensors.At(i*6); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)),out,temp,iWindowKey*iHeads,iWindow,None)) return false; out.BufferFree(); //--- Sum and normalize attention if(IsStopped() || !SumAndNormilize(temp,inputs,temp)) return false; if(i>0) inputs.BufferFree();
Transformerのself-attentionメカニズムの後には、2つの全結合層で構成されるフィードフォワードブロックが続きます。次に、結果が入力シーケンスに追加されます。最終テンソルは正規化され、次の層に送られます。この場合、ループを終了します。
//--- Feed Forward inputs=temp; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=FF_Tensors.At(i*6+1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1),inputs,temp,iWindow,4*iWindow,LReLU)) return false; out=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1); out.BufferFree(); out=FF_Tensors.At(i*6+2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2),temp,out,4*iWindow,iWindow,activation)) return false; temp.BufferFree(); temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); //--- Sum and normalize out if(IsStopped() || !SumAndNormilize(out,inputs,out)) return false; inputs.BufferFree(); } //--- return true; }
完全なメソッドコードは、以下の添付ファイルに記載されています。ここで、FeedForwardメソッドから呼び出されるヘルパーメソッドについて考えてみましょう。最初に呼び出すメソッドは、ConvolutionForwardです。フィードフォワード方式の1サイクルあたり4回呼び出されます。メソッド本体では、畳み込み層のフォワードパスカーネルが呼び出されます。この場合、このメソッドは、入力シーケンスの個別のトークンごとに全結合層の役割を果たします。このソリューションについては、第8部で詳しく説明しています。前述のソリューションとは対照的に、新しいメソッドはパラメータ内のバッファへのポインタを受け取り、OpenCLカーネルにデータを転送します。したがって、メソッドの開始時に、受信したポインタの有効性を確認します。
bool CNeuronMLMHAttentionOCL::ConvolutionForward(CBufferDouble *weights, CBufferDouble *inputs,CBufferDouble *outputs, uint window, uint window_out, ENUM_ACTIVATION activ) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(weights)==POINTER_INVALID || CheckPointer(inputs)==POINTER_INVALID || CheckPointer(outputs)==POINTER_INVALID) return false;
次に、GPUメモリにバッファを作成し、必要な情報を渡します。
if(!weights.BufferCreate(OpenCL)) return false; if(!inputs.BufferCreate(OpenCL)) return false; if(!outputs.BufferCreate(OpenCL)) return false;
この後に、第8部で説明されているコードが変更なしで続きます。呼び出されたカーネルは、変更なしでそのまま使用されます。
uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=outputs.Total()/window_out; OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_w,weights.GetIndex()); OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_i,inputs.GetIndex()); OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_o,outputs.GetIndex()); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_inputs,inputs.Total()); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_step,window); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_window_in,window); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffс_window_out,window_out); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_activation,(int)activ); if(!OpenCL.Execute(def_k_FeedForwardConv,1,global_work_offset,global_work_size)) { printf("Error of execution kernel FeedForwardConv: %d",GetLastError()); return false; } //--- return outputs.BufferRead(); }
feedForwardメソッドコードでは後にAttentionScoreメソッドの呼び出しがあります。このメソッドは、カーネルを呼び出してAttentionスコアを計算および正規化します。これらの結果の値は、スコア行列に書き込まれます。このメソッド用に新しいカーネルが作成されました。 メソッド自体を検討した後、後で検討します。
前のメソッドと同様に、AttentionScoreは、パラメータとして、初期データバッファへのポインタと取得された値のレコードを受け取ります。そのため、メソッドの開始時に、受信したポインタの有効性を確認します。
bool CNeuronMLMHAttentionOCL::AttentionScore(CBufferDouble *qkv, CBufferDouble *scores, bool mask=true) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(qkv)==POINTER_INVALID || CheckPointer(scores)==POINTER_INVALID) return false;
上記のロジックに従って、GPUとのデータ交換用のバッファを作成しましょう。
if(!qkv.BufferCreate(OpenCL)) return false; if(!scores.BufferCreate(OpenCL)) return false;
準備作業が終わったら、カーネルパラメータの指定に移りましょう。このカーネルのスレッドは、入力シーケンス要素のコンテキストとAttentionヘッドのコンテキストの2つの次元で作成されます。これにより、シーケンスのすべての要素とすべてのAttentionヘッドの並列計算が提供されます。
uint global_work_offset[2]= {0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iHeads; OpenCL.SetArgumentBuffer(def_k_MHAttentionScore,def_k_mhas_qkv,qkv.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionScore,def_k_mhas_score,scores.GetIndex()); OpenCL.SetArgument(def_k_MHAttentionScore,def_k_mhas_dimension,iWindowKey); OpenCL.SetArgument(def_k_MHAttentionScore,def_k_mhas_mask,(int)mask);
次に、カーネル呼び出しに直接進みます。計算結果は「スコア」バッファに読み込まれます。
if(!OpenCL.Execute(def_k_MHAttentionScore,2,global_work_offset,global_work_size)) { printf("Error of execution kernel MHAttentionScore: %d",GetLastError()); return false; } //--- return scores.BufferRead(); }
呼び出されたMHAttentionScoreカーネルのロジックを見てみましょう。上に示したように、カーネルはパラメータとしてqkvソースデータ配列へのポインタと結果のスコアを記録するための配列を受け取ります。また、カーネルは、パラメータとして内部ベクトル(Query、Key)のサイズと、後続の要素のマスキングアルゴリズムを有効にするためのフラグを受け取ります。
まず、処理中のクエリqの序数とAttentionヘッドhを取得します。また、クエリとAttentionヘッドの数の次元を取得します。
__kernel void MHAttentionScore(__global double *qkv, ///<[in] Matrix of Querys, Keys, Values __global double *score, ///<[out] Matrix of Scores int dimension, ///< Dimension of Key int mask ///< 1 - calc only previous units, 0 - calc all ) { int q=get_global_id(0); int h=get_global_id(1); int units=get_global_size(0); int heads=get_global_size(1);
得られたデータに基づいて、query配列とscore配列のシフトを決定します。
int shift_q=dimension*(h+3*q*heads); int shift_s=units*(h+q*heads);
また、Scoreの補正係数を計算します。
double koef=sqrt((double)dimension); if(koef<1) koef=1;
Attentionスコアはループで計算され、対応するAttentionヘッドの要素のシーケンス全体のキーを繰り返し処理します。
ループの開始時に、Attentionメカニズムを使用するための条件を確認します。この機能が有効になっている場合は、キーのシリアル番号を確認してください。現在のキーがシーケンスの次の要素に対応している場合は、ゼロスコアをscore配列に書き込み、次の要素に移動します。
double sum=0; for(int k=0;k<units;k++) { if(mask>0 && k>q) { score[shift_s+k]=0; continue; }
分析されたキーのAttentionスコアが計算される場合、ネストされたループを編成して、2つのベクトルの積を計算します。ループ本体での計算にはブランチがあって、1つはベクトル計算を使用し、もう1つはそのような計算を使用しません。最初のブランチは、キーベクトルの現在の位置から最後の要素までに4つ以上の要素がある場合に使用され、2番目は、キーベクトルの最後の4要素未満に使用されます。
double result=0; int shift_k=dimension*(h+heads*(3*k+1)); for(int i=0;i<dimension;i++) { if((dimension-i)>4) { result+=dot((double4)(qkv[shift_q+i],qkv[shift_q+i+1],qkv[shift_q+i+2],qkv[shift_q+i+3]), (double4)(qkv[shift_k+i],qkv[shift_k+i+1],qkv[shift_k+i+2],qkv[shift_k+i+3])); i+=3; } else result+=(qkv[shift_q+i]*qkv[shift_k+i]); }
Transformerアルゴリズムに従って、AttentionスコアはSoftMax関数を使用して正規化されます。この機能を実装するために、ベクトルの積の結果を補正係数で除算し、結果の値の指数を決定します。計算結果は、scoreテンソルの対応する要素に書き込まれ、指数の合計に追加される必要があります。
result=exp(clamp(result/koef,-30.0,30.0)); if(isnan(result)) result=0; score[shift_s+k]=result; sum+=result; }
同様に、すべての要素の指数を計算します。AttentionスコアのSoftMax正規化を完了するために、scoreテンソルのすべての要素が以前に計算された指数の合計で除算される別のループを編成します。
for(int k=0;(k<units && sum>1);k++) score[shift_s+k]/=sum; }
ループが終了したらカーネルを終了します。
feedForwardメソッドに進み、AttentionOutヘルパーメソッドについて考えてみましょう。このメソッドは、QKV、Scores、Outの3つのテンソルへのポインタをパラメータとして受け取ります。メソッドの構造は、前に検討したものと同様です。シーケンス要素とAttentionヘッドの2つの次元でMHAttentionOutカーネルを起動します。
bool CNeuronMLMHAttentionOCL::AttentionOut(CBufferDouble *qkv, CBufferDouble *scores, CBufferDouble *out) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(qkv)==POINTER_INVALID || CheckPointer(scores)==POINTER_INVALID || CheckPointer(out)==POINTER_INVALID) return false; uint global_work_offset[2]= {0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iHeads; if(!qkv.BufferCreate(OpenCL)) return false; if(!scores.BufferCreate(OpenCL)) return false; if(!out.BufferCreate(OpenCL)) return false; //--- OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_qkv,qkv.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_score,scores.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_out,out.GetIndex()); OpenCL.SetArgument(def_k_MHAttentionOut,def_k_mhao_dimension,iWindowKey); if(!OpenCL.Execute(def_k_MHAttentionOut,2,global_work_offset,global_work_size)) { printf("Error of execution kernel MHAttentionOut: %d",GetLastError()); return false; } //--- return out.BufferRead(); }
以前のカーネルと同様に、MHAttentionOutは、Multi-Head Attentionを考慮して新しく作成されました。クエリ、キー、値のすべてのテンソルに単一のバッファを使用します。カーネルはパラメータとしてScores、QKV、Out各テンソルおよび値ベクトルのサイズへのポインタを受け取ります。1、2番目のバッファは元のデータを提供し、最後のバッファは結果の記録に使用されます。
また、カーネルの開始時に、処理されているクエリqの序数、Attentionヘッドh、およびクエリとAttentionヘッドの数の次元を決定します。
__kernel void MHAttentionOut(__global double *scores, ///<[in] Matrix of Scores __global double *qkv, ///<[in] Matrix of Values __global double *out, ///<[out] Output tensor int dimension ///< Dimension of Value ) { int u=get_global_id(0); int units=get_global_size(0); int h=get_global_id(1); int heads=get_global_size(1);
次に、必要なAttentionスコアと、分析される出力値ベクトルの最初の要素の位置を決定します。さらに、QKVテンソルの1つの要素のベクトルの長さを計算します。この値は、QKVテンソルのシフトを決定するために使用されます。
int shift_s=units*(h+heads*u); int shift_out=dimension*(h+heads*u); int layer=3*dimension*heads;
主な計算にネストされたループを実装します。外側のループは、値のベクトルのサイズで実行されます。内側のループは、元のシーケンスの要素の数によって実行されます。外側のループの開始時に、結果の値を計算するための変数を宣言し、それをゼロ値で初期化します。内側のループは、値ベクトルのシフトの定義を開始します。後でベクトル計算を使用するため、内部ループのステップは4に等しいことに注意してください。
for(int d=0;d<dimension;d++) { double result=0; for(int v=0;v<units;v+=4) { int shift_v=dimension*(h+heads*(3*v+2))+d;
MHAttentionScoreカーネルと同様に、計算を2つのスレッドに分割します。1つはベクトル計算を使用し、
後1つは使用しません。シーケンスの長さが4の倍数でない場合、2番目のスレッドは最後の要素にのみ使用されます。
if((units-v)>4) { result+=dot((double4)(scores[shift_s+v],scores[shift_s+v+1],scores[shift_s+v+1],scores[shift_s+v+3]), (double4)(qkv[shift_v],qkv[shift_v+layer],qkv[shift_v+2*layer],qkv[shift_v+3*layer])); } else for(int l=0;l<(int)fmin((double)(units-v),4.0);l++) result+=scores[shift_s+v+l]*qkv[shift_v+l*layer]; } out[shift_out+d]=result; } }
ネストされたループを終了した後、結果の値を出力テンソルの対応する要素に書き込みます。
さらに、feedForwardメソッドでは、上記のConvolutionForwardメソッドが使用されます。すべてのメソッドと関数の完全なコードは、添付ファイルにあります。
3.3. フィードバックワード
以前に検討されたすべてのクラスと同様に、フィードバックプロセスには、エラー勾配の伝播と重みの更新の2つのサブプロセスが含まれます。最初の部分は、calcInputGradientsメソッドに実装されています。2番目の部分はupdateInputWeightsに実装されています。
calcInputGradientsメソッドの構成はfeedForwardと似ています。このメソッドは、パラメータとしてエラー勾配を渡す必要があるニューラルネットワークの前の層へのポインタを受け取るため、メソッドの開始時に、受信したポインタの有効性を確認します。
bool CNeuronMLMHAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false;
次に、ニューロンの次の層から受け取った勾配のテンソルを修正し、すべての内側の層にループを編成して、エラー勾配を順次計算します。これはフィードバックプロセスであるため、ループは逆の順序で内層を反復処理します。
for(int i=(int)iLayers-1; (i>=0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2),out_grad,FF_Tensors.At(i*6+1),FF_Tensors.At(i*6+4),4*iWindow,iWindow,None)) return false; CBufferDouble *temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); temp=FF_Tensors.At(i*6+1); temp.BufferFree(); temp=FF_Tensors.At(i*6+3); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1),FF_Tensors.At(i*6+4),FF_Tensors.At(i*6),temp,iWindow,4*iWindow,LReLU)) return false;
ループの開始時に、Transformerのフィードフォワードブロックのニューロンの全結合層を介したエラー勾配の伝播を計算します。この反復は、ConvolutionInputGradientsメソッドによって実行されます。メソッドの完了後にバッファを解放します。
ここでのアルゴリズムはプロセス全体を通したデータフローを実装するため、エラー勾配に対しても同じプロセスを実装する必要があります。したがって、フィードフォワードブロックから取得されたエラー勾配は、ニューロンの前の層から受信されたエラー勾配と合計されます。勾配が急上昇するリスクを排除するために、2つのベクトルの合計を正規化します。これらの操作はすべて、SumAndNormilizeメソッドで実行されます。メソッドの完了後にバッファを解放します。
//--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad,temp,temp)) return false; if(i!=(int)iLayers-1) out_grad.BufferFree(); out_grad=temp; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1); temp.BufferFree(); temp=FF_Tensors.At(i*6+4); temp.BufferFree(); temp=FF_Tensors.At(i*6); temp.BufferFree();
さらにアルゴリズムに沿って、エラー勾配をAttentionヘッドで割ってみましょう。これは、W0行列のConvolutionInputGradientsメソッドを呼び出すことによって行われます。
//--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)),out_grad,AO_Tensors.At(i*2),AO_Tensors.At(i*2+1),iWindowKey*iHeads,iWindow,None)) return false; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=AO_Tensors.At(i*2); temp.BufferFree();
Attentionヘッドに沿ったさらなる勾配伝播はAttentionInsideGradientsメソッドで編成されます。
if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i*2),QKV_Tensors.At(i*2+1),S_Tensors.At(i*2),S_Tensors.At(i*2+1),AO_Tensors.At(i*2+1))) return false; temp=QKV_Tensors.At(i*2); temp.BufferFree(); temp=S_Tensors.At(i*2); temp.BufferFree(); temp=S_Tensors.At(i*2+1); temp.BufferFree(); temp=AO_Tensors.At(i*2+1); temp.BufferFree();
ループの最後に、前の層に渡されたエラー勾配を計算します。ここで、前の反復から受信したエラー勾配は、連結テンソルQKV_Weightsを通過し、受信したベクトルは、self-attentionメカニズムのフィードフォワードブロックからのエラー勾配と合計され、結果は、勾配の急上昇を回避するために正規化されます。
CBufferDouble *inp=NULL; if(i==0) { inp=prevLayer.getOutput(); temp=prevLayer.getGradient(); } else { temp=FF_Tensors.At(i*6-1); inp=FF_Tensors.At(i*6-4); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i*(optimization==SGD ? 2 : 3)),QKV_Tensors.At(i*2+1),inp,temp,iWindow,3*iWindowKey*iHeads,None)) return false; //--- Sum and normalize gradients if(IsStopped() || !SumAndNormilize(out_grad,temp,temp)) return false; out_grad.BufferFree(); if(i>0) out_grad=temp; temp=QKV_Weights.At(i*(optimization==SGD ? 2 : 3)); temp.BufferFree(); temp=QKV_Tensors.At(i*2+1); temp.BufferFree(); } //--- return true; }
使用済みのデータバッファを解放することを忘れないでください。前の層のデータバッファがGPUメモリに残っていることに注意してください。
呼び出されたメソッドを見てみましょう。ご覧のとおり、最も頻繁に呼び出されるメソッドはConvolutionInputGradientsです。これは、畳み込み層の同様のメソッドに基づいており、現在のタスク用に最適化されています。このメソッドは、パラメータに、重みのテンソル、次の層の勾配、前の層の出力データ、および反復結果を格納するテンソルへのポインタを受け取ります。また、このメソッドは、パラメータとして入力および出力データウィンドウのサイズと使用される活性化関数を受け取ります。
bool CNeuronMLMHAttentionOCL::ConvolutionInputGradients(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *inp_gradient, uint window, uint window_out, uint activ) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(weights)==POINTER_INVALID || CheckPointer(gradient)==POINTER_INVALID || CheckPointer(inputs)==POINTER_INVALID || CheckPointer(inp_gradient)==POINTER_INVALID) return false;
メソッドの開始時に、受信したポインタの有効性を確認し、GPUメモリにデータバッファを作成します。
if(!weights.BufferCreate(OpenCL)) return false; if(!gradient.BufferCreate(OpenCL)) return false; if(!inputs.BufferCreate(OpenCL)) return false; if(!inp_gradient.BufferCreate(OpenCL)) return false;
データバッファを作成した後で、適切なOpenCLプログラムカーネルの呼び出しを実装します。ここでは、変更なしで畳み込みネットワークカーネルを使用します。
//--- uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=inputs.Total(); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_w,weights.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_g,gradient.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_o,inputs.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_ig,inp_gradient.GetIndex()); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_outputs,gradient.Total()); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_step,window); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_window_in,window); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_window_out,window_out); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_activation,activ); //Comment(com+"\n "+(string)__LINE__+"-"__FUNCTION__); if(!OpenCL.Execute(def_k_CalcHiddenGradientConv,1,global_work_offset,global_work_size)) { printf("Error of execution kernel CalcHiddenGradientConv: %d",GetLastError()); return false; } //--- return inp_gradient.BufferRead(); }
ConvolutionInputGradientsメソッドからも呼び出されるAttentionInsideGradientsメソッドは、同様のアルゴリズムに従って構築されます。メソッドコードについては、添付ファイルを参照してください。ここで、すべての計算がカーネルで実行されるため、指定されたメソッドから呼び出されたOpenCLプログラムカーネルを見てみましょう。
MHAttentionInsideGradientsカーネルは、シーケンスの要素とAttentionヘッドの2次元のスレッドによって起動されます。カーネルは、連結されたQKVテンソルとその勾配のテンソル、スコア行列テンソルとその勾配、前の反復からのエラー勾配テンソル、およびキーベクトルのサイズへのポインタをパラメーターとして受け取ります。
__kernel void MHAttentionInsideGradients(__global double *qkv,__global double *qkv_g, __global double *scores,__global double *scores_g, __global double *gradient, int dimension) { int u=get_global_id(0); int h=get_global_id(1); int units=get_global_size(0); int heads=get_global_size(1); double koef=sqrt((double)dimension); if(koef<1) koef=1;
メソッドの開始時に、処理されたシーケンス要素とAttentionヘッドの序数、およびそれらのサイズを取得します。また、scores行列の更新係数を計算します。
次に、ループを編成して、scores行列のエラー勾配を計算します。ループの後にバリアを設定することで、すべてのスレッド間で計算プロセスを同期させることができます。アルゴリズムは、scores行列の勾配が完全に再計算された後でのみ、次の操作ブロックに切り替わります。
//--- Calculating score's gradients uint shift_s=units*(h+u*heads); for(int v=0;v<units;v++) { double s=scores[shift_s+v]; if(s>0) { double sg=0; int shift_v=dimension*(h+heads*(3*v+2)); int shift_g=dimension*(h+heads*v); for(int d=0;d<dimension;d++) sg+=qkv[shift_v+d]*gradient[shift_g+d]; scores_g[shift_s+v]=sg*(s<1 ? s*(1-s) : 1)/koef; } else scores_g[shift_s+v]=0; } barrier(CLK_GLOBAL_MEM_FENCE);
別のループを実装して、クエリ、キー、値のベクトルのエラー勾配を計算しましょう。
//--- Calculating gradients for Query, Key and Value uint shift_qg=dimension*(h+3*u*heads); uint shift_kg=dimension*(h+(3*u+1)*heads); uint shift_vg=dimension*(h+(3*u+2)*heads); for(int d=0;d<dimension;d++) { double vg=0; double qg=0; double kg=0; for(int l=0;l<units;l++) { uint shift_q=dimension*(h+3*l*heads)+d; uint shift_k=dimension*(h+(3*l+1)*heads)+d; uint shift_g=dimension*(h+heads*l)+d; double sg=scores_g[shift_s+l]; kg+=sg*qkv[shift_q]; qg+=sg*qkv[shift_k]; vg+=gradient[shift_g]*scores[shift_s+l]; } qkv_g[shift_qg+d]=qg; qkv_g[shift_kg+d]=kg; qkv_g[shift_vg+d]=vg; } }
すべてのメソッドと関数の完全なコードは、添付ファイルにあります。
重みは、以前に検討されたfeedForwardメソッドとcalcInputGradientsメソッドの原則によって構築されたupdateInputWeightsメソッドで更新されます。畳み込みネットワークの重みを更新する1つのConvolutuionUpdateWeightsヘルパーメソッドのみが、このメソッド内で順番に呼び出されます。
bool CNeuronMLMHAttentionOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL)==POINTER_INVALID) return false; CBufferDouble *inputs=NeuronOCL.getOutput(); for(uint l=0; l<iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l*(optimization==SGD ? 2 : 3)),QKV_Tensors.At(l*2+1),inputs,(optimization==SGD ? QKV_Weights.At(l*2+1) : QKV_Weights.At(l*3+1)),(optimization==SGD ? NULL : QKV_Weights.At(l*3+2)),iWindow,3*iWindowKey*iHeads)) return false; if(l>0) inputs.BufferFree(); CBufferDouble *temp=QKV_Weights.At(l*(optimization==SGD ? 2 : 3)); temp.BufferFree(); temp=QKV_Tensors.At(l*2+1); temp.BufferFree(); if(optimization==SGD) { temp=QKV_Weights.At(l*2+1); } else { temp=QKV_Weights.At(l*3+1); temp.BufferFree(); temp=QKV_Weights.At(l*3+2); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)),FF_Tensors.At(l*6+3),AO_Tensors.At(l*2),(optimization==SGD ? FF_Weights.At(l*6+3) : FF_Weights.At(l*9+3)),(optimization==SGD ? NULL : FF_Weights.At(l*9+6)),iWindowKey*iHeads,iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=FF_Tensors.At(l*6+3); temp.BufferFree(); temp=AO_Tensors.At(l*2); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+3); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+3); temp.BufferFree(); temp=FF_Weights.At(l*9+6); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)+1),FF_Tensors.At(l*6+4),FF_Tensors.At(l*6),(optimization==SGD ? FF_Weights.At(l*6+4) : FF_Weights.At(l*9+4)),(optimization==SGD ? NULL : FF_Weights.At(l*9+7)),iWindow,4*iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)+1); temp.BufferFree(); temp=FF_Tensors.At(l*6+4); temp.BufferFree(); temp=FF_Tensors.At(l*6); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+4); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+4); temp.BufferFree(); temp=FF_Weights.At(l*9+7); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)+2),FF_Tensors.At(l*6+5),FF_Tensors.At(l*6+1),(optimization==SGD ? FF_Weights.At(l*6+5) : FF_Weights.At(l*9+5)),(optimization==SGD ? NULL : FF_Weights.At(l*9+8)),4*iWindow,iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); temp=FF_Tensors.At(l*6+5); if(temp!=Gradient) temp.BufferFree(); temp=FF_Tensors.At(l*6+1); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+5); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+5); temp.BufferFree(); temp=FF_Weights.At(l*9+8); temp.BufferFree(); } inputs=FF_Tensors.At(l*6+2); } //--- return true; }
すべてのクラスとそのメソッドの完全なコードは、添付ファイルにあります。
3.4. ニューラルネットワーク基本クラスの変更
これまでのすべての記事と同様に、新しいクラスを作成した後、基本クラスに変更を加えて、ネットワークが適切に動作するようにします。
新しいクラス識別子を追加しましょう。
#define defNeuronMLMHAttentionOCL 0x7889 ///<Multilayer multi-headed attention neuron OpenCL \details Identified class #CNeuronMLMHAttentionOCL
また、defineブロックには、OpenCLプログラムの新しいカーネルを操作するための定数を追加します。
#define def_k_MHAttentionScore 20 ///< Index of the kernel of the multi-heads attention neuron to calculate score matrix (#MHAttentionScore) #define def_k_mhas_qkv 0 ///< Matrix of Queries, Keys, Values #define def_k_mhas_score 1 ///< Matrix of Scores #define def_k_mhas_dimension 2 ///< Dimension of Key #define def_k_mhas_mask 3 ///< 1 - calc only previous units, 0 - calc all //--- #define def_k_MHAttentionOut 21 ///< Index of the kernel of the multi-heads attention neuron to calculate multi-heads out matrix (#MHAttentionOut) #define def_k_mhao_score 0 ///< Matrix of Scores #define def_k_mhao_qkv 1 ///< Matrix of Queries, Keys, Values #define def_k_mhao_out 2 ///< Matrix of Outputs #define def_k_mhao_dimension 3 ///< Dimension of Key //--- #define def_k_MHAttentionGradients 22 ///< Index of the kernel for gradients calculation process (#AttentionInsideGradients) #define def_k_mhag_qkv 0 ///< Matrix of Queries, Keys, Values #define def_k_mhag_qkv_g 1 ///< Matrix of Gradients to Queries, Keys, Values #define def_k_mhag_score 2 ///< Matrix of Scores #define def_k_mhag_score_g 3 ///< Matrix of Scores Gradients #define def_k_mhag_gradient 4 ///< Matrix of Gradients from previous iteration #define def_k_mhag_dimension 5 ///< Dimension of Key
また、ニューラルネットワーククラスコンストラクタに新しいカーネルの宣言を追加しましょう。
//--- create kernels opencl.SetKernelsCount(23); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers"); opencl.KernelCreate(def_k_MHAttentionGradients,"MHAttentionInsideGradients"); opencl.KernelCreate(def_k_MHAttentionScore,"MHAttentionScore"); opencl.KernelCreate(def_k_MHAttentionOut,"MHAttentionOut");
И создание нового типа нейронов в конструкторе нейронной сети.
case defNeuronMLMHAttentionOCL: neuron_mlattention_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(neuron_mlattention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_mlattention_ocl.Init(outputs,0,opencl,desc.window,desc.window_out,desc.step,desc.count,desc.layers,desc.optimization)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_mlattention_ocl)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl=NULL; break;
また、新しいクラスのニューロンの処理をCNeuronBaseOCLニューロンの基本クラスのディスパッチメソッドに追加しましょう。
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; } bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronMLMHAttentionOCL *mlat=NULL; CNeuronConvOCL *conv=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; case defNeuronMLMHAttentionOCL: mlat=TargetObject; temp=GetPointer(this); return mlat.calcInputGradients(temp); break; } //--- return false; } bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
すべてのクラスとそのメソッドの完全なコードは、添付ファイルにあります。
4. テスト
新しいアーキテクチャをテストするために、Fractal_OCL_AttentionMLMHとFractal_OCL_AttentionMLMH_v2の2つのエキスパートアドバイザーが作成されました。これらのEAは、前の記事のEAに基づいて作成されており、Attentionブロックのみが置き換えられています。Fractal_OCL_AttentionMLMH EAには、8つのself-attentionヘッドを備えた5層ブロックがあります。2番目のEAでは、12個のself-attentionヘッドを備えた12層ブロックを使用します。
ニューラルネットワークの新しいクラスは、以前のテストで使用されたものと同じデータセットでテストされました(H1時間枠のEURUSD、最後の20個のローソク足の履歴データをニューラルネットワークに供給)。
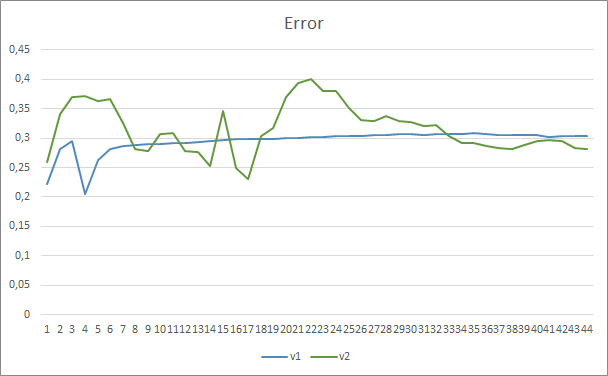
テスト結果で、より多くのパラメータがより長い訓練期間を必要とするという仮定が確認されました。最初の訓練エポックでは、パラメータが少ないエキスパートアドバイザーがより安定した結果を示していますが、訓練期間が延長されると、多数のパラメータを持つエキスパートアドバイザーがより良い値を示すようになります。一般に、33エポック後、Fractal_OCL_AttentionMLMH_v2のエラーはFractal_OCL_AttentionMLMH EAのエラーレベルを下回り、さらに低いままでした。
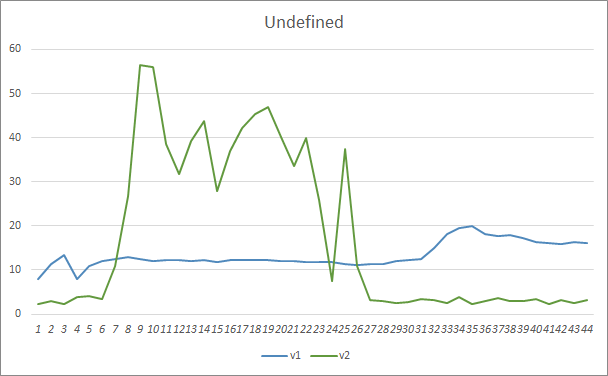
欠落したパターンパラメータは同様の結果を示しました。訓練の開始時には、Fractal_OCL_AttentionMLMH_v2 EAの不均衡なパラメータがパターンの50%以上を見逃していましたが、訓練をさらに進めると、この値は減少し、27エポック後に3〜5%で安定しました。パラメータのより少ないEAはよりスムーズな結果を示すと同時にパターンの10〜16%を見逃しました。
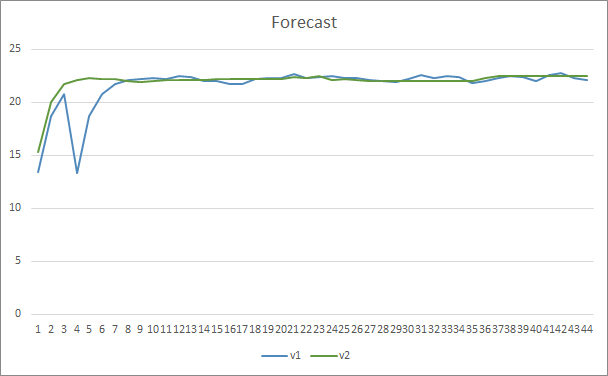
パターン予測の精度に関しては、両方のエキスパートアドバイザーが22〜23%のレベルで同等の結果を示しました。
終わりに
本稿では、OpenAIによって提示されたGPTアーキテクチャに類似した、新しいクラスのAttentionニューロンを作成しました。もちろん、これらのアーキテクチャの訓練と操作では時間とリソースを大量に消費するため、これらのアーキテクチャを完全な形で繰り返し訓練することは不可能です。ただし、ここで作成したオブジェクトは、自動売買ロボット作成の目的を持つニューラルネットワークでうまく使用できます。
参照文献
- ニューラルネットワークが簡単に
- ニューラルネットワークが簡単に(第2回): ネットワークの訓練とテスト
- ニューラルネットワークが簡単に(第3回): コンボリューションネットワーク
- ニューラルネットワークが簡単に(第4回): リカレントネットワーク
- ニューラルネットワークが簡単に(第5回): OPENCLでのマルチスレッド計算
- ニューラルネットワークが簡単に(第6回): ニューラルネットワークの学習率を実験する
- ニューラルネットワークが簡単に(第7回): 適応的最適化法
- ニューラルネットワークが簡単に(第8回): アテンションメカニズム
- ニューラルネットワークが簡単に(第9部): 作業の文書化
- ニューラルネットワークが簡単に(第10回): Multi-Head Attention
- 教師なし学習による言語理解の改善(英語)
- より良い言語モデルとその影響(英語)
- GPT3の仕組み - 視覚化とアニメーション
…
記事で使用されたプログラム
| # | 名称 | 種類 | 説明 |
|---|---|---|---|
| 1 | Fractal_OCL_AttentionMLMH.mq5 | エキスパートアドバイザー | GTPアーキテクチャを使用した分類ニューラルネットワーク(出力層に3つのニューロン)と5つのAttention層を備えたエキスパートアドバイザー |
| 2 | Fractal_OCL_AttentionMLMH_v2.mq5 | エキスパートアドバイザー | GTPアーキテクチャを使用した分類ニューラルネットワーク(出力層に3つのニューロン)と12のAttention層を備えたエキスパートアドバイザー |
| 3 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 4 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
| 5 | NN.chm | HTMLヘルプ | コンパイル済みのCHMファイル |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/9025
 パターン検索への総当たり攻撃アプローチ(第IV部): 最小限の機能
パターン検索への総当たり攻撃アプローチ(第IV部): 最小限の機能
 MVCデザインパターンとその可能なアプリケーション
MVCデザインパターンとその可能なアプリケーション
 グリッドおよびマーチンゲール取引システムでの機械学習 - あなたはそれに賭けますか
グリッドおよびマーチンゲール取引システムでの機械学習 - あなたはそれに賭けますか
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索