Que mettre à l'entrée du réseau neuronal ? Vos idées... - page 30
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Un réseau normal triera de lui-même les données nécessaires et inutiles.
L'essentiel est de savoir ce qu'il faut enseigner !
L'apprentissage avec un professeur ne convient pas ici. Les réseaux à propagation d'erreurs vers l'arrière sont tout simplement inutiles.
Comprend-on comment le mécanisme doit être entraîné ? En gros, nous examinons les poids, nous les adaptons à un graphique, mais en même temps, il existe un autre ensemble de poids, un ensemble qui n'est pas seulement adapté à ce graphique, mais qui est "adapté" au suivant, et au suivant, et au suivant, et ainsi de suite, et il finit par "se casser" quelque part, loin devant.
Ici, l'apprentissage est présenté comme la recherche de la différence entre un ensemble d'ensembles qui ne fonctionnent pas et ceux qui fonctionnent.
De plus, le réseau formé n'a pas besoin d'un "réglage fin" supplémentaire, il modifie déjà lui-même le nombre de poids. Quelles sont les autres idées sur ce à quoi ressemble l'apprentissage automatique, sur la manière dont il est présenté ?
Un réseau normal triera de lui-même les données nécessaires et inutiles.
L'essentiel est de savoir ce qu'il faut enseigner !
L'apprentissage avec un professeur ne convient pas ici. Les réseaux à propagation d'erreur à rebours sont tout simplement inutiles.
Le réseau ne triera rien - il sélectionnera les variables qui correspondent le mieux à l'échantillon d'apprentissage.
Un grand nombre de variables est un problème majeur
Le réseau ne triera rien - il sélectionnera les variables qui correspondent le mieux à l'échantillon d'apprentissage.
Ungrand nombre de variables est le principal problème
Pour la mémorisation du chemin - le meilleur Pour l'apprentissage (dans la compréhension actuelle) - le plus grand mal.
former deux grilles - l'une en achat seulement, l'autre en vente.
allumez les deux :-)
ajoutez ensuite un réseau de résolution des collisions (ou simplement un alg.) afin qu'elles ne négocient pas dans des directions différentes en même temps.
J'ai réfléchi à la possibilité de créer un script pour le marquage. Notez toutes les dates d'entrée et de clôture. Si l'optimiseur définit des pondérations qui donnent un signal en dehors de ces dates, nous ouvrons avec le lot maximum à perdre. Ou nous n'ouvrons pas du tout.
Il s'avère que ce sera une méthode avec un professeur, mais par MT5 oblige
Le réseau neuronal peut fonctionner même sur une valeur d'un trait, si vous sélectionnez les paramètres.
mais nous avons besoin de conditions de graal (dts) avec presque aucune propagation. Je pense que n'importe quel TS fonctionnera dans de telles conditions :)
Existe-t-il un moyen de décrire le fait de demander à la machine d'ouvrir une position lorsqu'elle le juge nécessaire ? Comment l'expliquerions-nous : nous faisons en sorte que le réseau neuronal ouvre lui-même des positions... "si, alors". Nous spécifions quand ouvrir "si la sortie du réseau neuronal est supérieure à 0,6", "si des deux neurones de sortie, celui du haut a la valeur la plus élevée".
"Si - alors, si - alors." Et ainsi de suite. Et ici, pour qu'il n'y ait pas de limites d'ouverture, de conditions. Il y a des entrées, il y a des poids. À l'intérieur du réseau neuronal, il y a une sorte de bouillie qui se prépare.
Est-il possible de décrire à la machine, sur la base de son travail avec les entrées et les poids (à rechercher dans l'optimiseur), d'ouvrir des positions lorsqu'elle décide de le faire ? Comment cette condition peut-elle être prescrite ? De manière à ce qu'elle choisisse quand ouvrir des positions.
UPD Ajouter un deuxième réseau neuronal.
Ou plusieurs réseaux neuronaux, avec un moyen de les relier.
Ou existe-t-il une autre façon de décrire une telle tâche ?
UPD Ajouter un bloc d'expérience.
Il s'agit alors d'une sorte de table Q. Et nous avons besoin que tout soit à l'intérieur du réseau neuronal.
... Comment définir cette condition ? Pour qu'il choisisse quand s'ouvrir....
Je peux vous aider : donnez des signaux d'achat et de vente en même temps, et le neurone décidera où aller. Ne me remerciez pas...
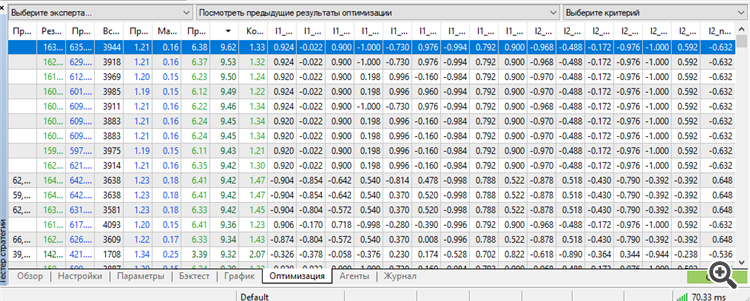
Pour la première fois, j'ai réussi à obtenir un set dans le top par un ouvrier. De plus, un ouvrier pour pas moins de 3 ans à l'avance.
Formation de 9 ans de 2012 à 2021
En avant 2021
A terme 2022
En avant 2023
Les 3 années de la période 2021-2023.12.13.
Il est vrai que nous avons dû utiliser tout le potentiel de MT5 : le nombre maximum de paramètres-poids optimisables.
Plus - MT5 jure. Eh, s'il était possible d'optimiser plus de paramètres, il serait plus intéressant de connaître les résultats. Je reste perplexe face à cette inscription "64 bits to long" ou quelque chose du genre. Si l'algorithme génétique permet d'optimiser encore plus, il serait intéressant de savoir comment contourner cette limitation.
si davantage de paramètres pouvaient être optimisés
Je suis passé de la Toyota à une vieille voiture de sport Comme MT5 est limité dans le nombre de paramètres optimisables, je suis passé à NeuroPro 1999, à partir de l'article ici -Neural Networks for Free and Easy - Connecting NeuroPro and MetaTrader 5 (Réseaux neuronaux gratuits et faciles - Connexion entre NeuroPro et MetaTrader 5).
J'ai augmenté la quantité de l'architecture : dans MT5 c'était 5-5-5-5, et ici c'est 10-10-10, et l'entraînement est déjà réel (pour être plus précis - standard, par la méthode de rétropropagation de l'erreur et d'autres caractéristiques internes du programme.


L'auteur du programme a craché dessus et ne va même pas mettre à jour la rareté - d'après ses réponses à mes questions, il n'a aucun intérêt à développer NeoroPro, à introduire le multithreading, les méthodes modernes, etc.) Étonnamment, le programme peut produire des résultats similaires à ceux de MT5. Mais il est facile de briser l'avance - ajouter un autre neurone / ajouter une autre couche / réduire la taille des données d'un mois et tout deviendra aléatoire.
En d'autres termes, nous devons trouver un juste milieu entre le surentraînement et le sous-entraînement. De plus, après l'entraînement, le modèle ne fonctionne toujours pas. Nous avons besoin d'une post-optimisation des paramètres MT5 - seuils d'ouverture pour l'achat et la vente. Quelque chose de similaire a été fait par NeuroMachine des créateurs de MeGatrader en son temps.
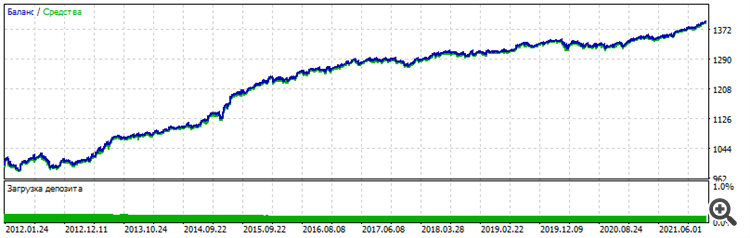
Sans cela, le graphique d'équilibre se déplace à peine vers le haut sur la période enseignée et s'épuise sur le forward. Les conditions ont changé : 6 entrées déjà, EURUSD H1, aux prix d'ouverture, 10 ans d'enseignement de 2012 à 2022.
Forward - deux dernières années 2022-2023-12-16
Graphique global - vous pouvez voir que la stabilité est similaire, le caractère est identique, cela ne ressemble pas à de la chance.
Je vais essayer d'autres paires et augmenter l'architecture pour exclure complètement le facteur chance et confirmer la performance de la méthode. Bien et le plus important - postoptimisation - l'ensemble de travail était dans le top dans le tri par le paramètre "Facteur de récupération". Si ce n'est pas le cas à une date ultérieure, il n'y aura pas de confirmation. Une fois de plus, je serai coincé dans le hasard, la chance, la chance.
La méthode de la piqûre créative m'a conduit à une idée : une couche de neurones au sens classique du terme est un amas de malaises.
Surtout la première couche, qui reçoit les données d'entrée.
La couche la plus importante. L'entrée est constituée de données hétérogènes. Ou homogènes - peu importe. Chaque chiffre, chaque nombre est une représentation de la forme, du contenu, de la dépendance - dans l'original.
C'est comme une source, comme un film, comme une photographie. Et imaginez qu'un réseau neuronal ordinaire prenne chaque chiffre, chaque attribut - et les additionne stupidement, multipliés par le poids, en un tas d'ordures, appelé additionneur. C'est comme brouiller une photo et essayer de restaurer l'image - rien ne marchera. Rien n'y fait. La source est perdue, effacée. Elle n'existe plus. Toute restauration se réduit à une seule chose : un dessin supplémentaire. C'est ainsi que les réseaux neuronaux modernes fonctionnent pour restaurer de vieilles photos, ou pour les améliorer, les mettre à l'échelle - ils les dessinent simplement. C'est le travail créatif du réseau neuronal, il n'a pas de source, il dessine ce qu'il a déjà eu dans sa base de données d'images, quelque chose de similaire, même si c'est à 99%, mais pas la source.
Ainsi, nous lui donnons des prix, des augmentations de prix, des prix transformés, des données d'indicateurs, des nombres dans lesquels un certain chiffre, un certain état du graphique est encodé - et il prend et efface stupidement le caractère unique de chaque nombre, jetant tous les nombres dans une fosse et tirant une conclusion (sortie) sur la base de cet énorme déchet, dans lequel il est impossible de distinguer ce qui est quoi. Un tel nombre d'additionneur sera désormais identique à différents chiffres, avec différents nombres. En d'autres termes, nous avons deux chiffres - ils sont affichés dans une séquence de chiffres différente. Le contenu de ces chiffres est différent, mais le volume peut être le même. Le volume est numérique. Dans l'additionneur, ce heap-mala peut signifier à la fois un chiffre et un autre. Nous ne saurons jamais lequel exactement - à ce stade, nous avons effacé l'information unique.
Nous l'avons étalée, jetée dans un pot, et maintenant c'est de la soupe. Et si l'entrée est nulle ? Avec une probabilité de 1000 %, le premier additionneur transformera ces déchets en déchets au carré. Et avec une probabilité de 1000 %, un tel réseau neuronal n'isolera jamais rien de ces déchets, ne les trouvera jamais, ne les extraira jamais. Car dans ce cas, il ne se contente pas de creuser dans les déchets, il les passe également au hachoir à viande appelé "couches suivantes".
Mon approche de profane me dit que nous devons changer la façon dont nous abordons les architectures et la façon dont nous traitons les entrées. J'en veux pour preuve mes graphiques ci-dessus. Une entrée, deux entrées, trois entrées - un neurone, deux neurones, trois neurones.
C'est tout, l'étape suivante est le recyclage - mémoriser le chemin plutôt que de travailler sur de nouvelles données. La deuxième confirmation est le recyclage lui-même. Plus il y a de neurones, plus il y a de couches - moins bien c'est pour les nouvelles données. C'est-à-dire qu'à chaque nouvelle couche, à chaque nouveau neurone, nous transformons les données d'origine en déchets au carré, et il ne reste plus au réseau neuronal qu'à mémoriser le chemin.
Ce dont il s'acquitte parfaitement au cours du réentraînement. C'est une petite fantaisie.