Что подать на вход нейросети? Ваши идеи... - страница 30
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
На вход можно подавать всё что угодно:
время дня, день недели, можно и фазы луны и тд. и тп.
Нормальная сеть сама отсортирует нужные и ненужные данные.
Главное это чему учить!
Обучение с учителем здесь плохо подходит. Сети с обратным распространением ошибки просто бесполезны.
Есть ли понимание, как нужно обучать механизм?
То есть, по сути, мы перебираем веса, подгоняем их под график.
Но, при этом, существует другой набор весов, сет, который не просто подогнан под этот график, но и "подогнан" под следующий, и последующий и тд. И заканчивается "ломается" где-то там, далеко впереди.
Вот, обучение представляется, как нахождение разницы между набором сетов, которые не работают, и которые работают. И, далее, обученная сеть уже не нуждается в "доподгонке", она уже сама редактирует числа весов.
Какие ещё есть представления, как выглядит, как представляется обучение машины
На вход можно подавать всё что угодно:
время дня, день недели, можно и фазы луны и тд. и тп.
Нормальная сеть сама отсортирует нужные и ненужные данные.
Главное это чему учить!
Обучение с учителем здесь плохо подходит. Сети с обратным распространением ошибки просто бесполезны.
Сеть ничего не отсортирует - сеть отберет те переменные, которые лучше всего подходят для обучающей выборки.
Большое количество переменных - главное зло
Сеть ничего не отсортирует - сеть отберет те переменные, которые лучше всего подходят для обучающей выборки.
Большое количество переменных - главное зло
Для запоминания пути - самое то
Для обучения (в текущем понимании) - самое зло
обучи две сетки - одну только в buy вторую в sell
включи обе :-)
потом добавь сеть (или просто алг.) разрешения коллизий - чтобы одновременно в разные стороны не торговали
Я тут подумал, можно ведь сделать скриптом разметку. Записать все даты, где происходит вход и закрытие. Если оптимизатор выставляет веса, которые дают сигнал вне этих дат, то открываемся максимальным лотом, чтобы слиться. Либо не открываем вообще.
Получается, это будет метод с учителем, но силами МТ5
Нейросеть может работать даже на 1 значении одного признака, если подобрать параметры
но нужны граальные условия (дц) почти без спреда. Думаю, что на таких будут работать вообще любые ТС :)
Можно ли как-то описать требование машине открывать позицию, когда она посчитает нужным?
Как бы это объяснить: мы сами заставляем нейросеть открывать позиции... "если, то." Указываем, когда открывать "Если выход нейросети больше 0.6", "если из двух выходных нейронов у верхнего - больше значение". "Если - то, если - то".
И так далее.
А вот, чтобы не было границ открытий, условий. Вот есть входы, есть веса. Внутри нейросети варится какая-то каша. Можно ли описать как-то машине на основании её работы с входами и весами (перебираемыми в оптимизаторе) - открывать позиции когда она сама решит?
Как это условие прописать? Чтобы она выбирала, когда именно открывать.
UPD
Добавить какую-нибудь вторую нейросеть. Тогда как её подвязать...
Или несколько нейросетей. Как-то их связать.
Или есть какой-то иной способ описать такое задание
UPD
Блок опыта добавить. Тогда получается какая-то q-таблица.
А нужно, чтобы всё было внутри нейросети
... Как это условие прописать? Чтобы она выбирала, когда именно открывать...
Здесь могу помочь: подавайте сигналы одновременно и на покупку и на продажу, а нейронка сама решит куда пойти. Не благодарите...
Впервые удалось получить сет в топе рабочим. Причем, рабочим аж на 3 года форварда.
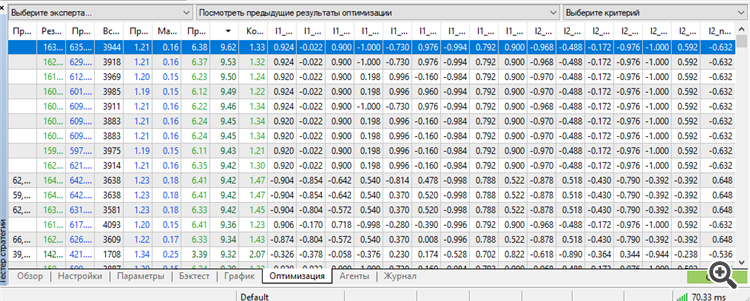
Обучение за 9 лет с 2012 по 2021
Форвард 2021 года
Форвард 2022 года
Форвард 2023 года
Все 3 года форварда 2021-2023.12.13
Правда, пришлось использовать весь потенциал МТ5: максимальное число оптимизируемых параметров-весов. Больше - МТ5 ругается.
Эх, если бы можно было оптимизировать больше параметров, было бы интересней узнать результаты. Упираюсь в эту надпись "64 bit to long" или как-то так. Если генетический алгоритм позволяет ещё больше оптимизировать, интересно узнать, как обойти это ограничение
если бы можно было оптимизировать больше параметров
Пересел с Тойоты на старый спортивный автомобиль
Поскольку МТ5 ограничен в количестве оптимизируемых параметров, пересел на программу NeuroPro 1999 года, из здешней статьи - Нейросети бесплатно и сердито - соединяем NeuroPro и MetaTrader 5
Увеличил архитектуру в количестве: в МТ5 было 5-5-5, а здесь уже 10-10-10 и обучение уже настоящее (точнее сказать - стандартное, методом обратного распространения ошибки и прочих там внутренних прибамбасов внутри программы. Автор которой наплевал на неё и не собирается даже обновлять раритет - исходя из его ответов на мои вопросы, у него нет интереса развивать NeoroPro, внедрять многопоточность, современные методы и тд.).
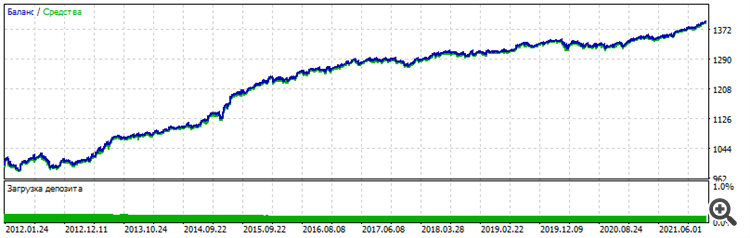


На удивление, программа может выдавать результат, схожий с МТ5. Но, поломать форвард легче лёгкого - добавь ещё один нейрон/ещё один слой/уменьши размер данных на месяц - и всё полетит в рандом. То есть, нужен поиск какой-то золотой середины между переобучением и недообучением.
Более того, после обучения модель всё равно не работает. Нужна постоптимизация в МТ5 параметров - порогов открытия на BUY и на SELL. Что-то подобное делала в своё время NeuroMachine от создателей МеГатрейдера. То есть, некая постобработка.
Без этого график баланса еле-еле двигается вверх на обучаемом периоде и сливает на форварде.
Условия изменились: уже 6 входов, EURUSD H1, по ценам открытия, 10 лет обучения с 2012 по 2022
Форвард - последние два года 2022-2023-12-16
Общий график - видно, что похожая стабильность, характер идентичный, на везение не похоже
Буду пробовать другие пары и увеличивать архитектуру, чтобы полностью исключить фактор удачи и подтвердить работоспособность метода.
Ну и самое главное - постоптимизация - рабочий сет был в топе в сортировке по параметру "Фактор восстановления". Если в последующем не будет - то никакого подтверждения не будет. Опять упрусь в рандом, везение, удачу.
Метод творческого тыка навёл на мысль:
Слой нейронов в классическом понимании - это куча-мала.
Особенно первый слой, который принимает входные данные. Важнейший слой.
На вход подаются разнородные данные. Или однородные - неважно. Каждая циферка, каждое число - это отображение формы, содержания, зависимости, - в оригинале. Это как исходник, плёнка, как фотография.
И вот представьте, обычная нейросеть берёт каждое число, каждый признак - и тупо суммирует, дополнительно помножив на вес, в одну кучу мусора, называемую сумматором.
Это как замылить фотографию и попытаться восстановить изображение - ничего не выйдет. Всё. Исходник утерян, стёрт. Его больше нет. Всё восстановление сводится к одному - дорисовывание. Так и работают современные нейросети по восстановлению старых фотографий, либо по улучшению их, апскейлу — она просто дорисовывает их, отсебятина. Просто творческая работа нейросети, у неё нет исходника, она рисует то, что у неё было в своей базе картинок когда-то, что-то похожее, пусть и на 99%, но не исходник.
И вот, подаём мы на вход нейросети цены, приращение цен, преобразованные цены, данные индикаторов, числа, в которых закодирована какая-то фигура, какое-то состояние на графике - а она берёт и тупо стирает уникальность каждого числа, бросая все числа в одну яму и делая вывод (выход) на основе этого огромного мусора, в котором уже не разобрать - что есть что.
Такое число сумматора отныне будет идентично разным фигурам, с разными числами. То есть у нас две фигуры - они отображены в разной последовательности чисел. Содержание этих фигур - разное, но объём может быть одинаковым. Объём числовой. И тогда в сумматоре эта куча-мала может означать как одну фигуру, так и другую. Какую конкретно - мы уже не узнаем никогда, на этом этапе мы стёрли уникальную информацию. Размазали её, кинули в один котёл, теперь это суп.
А если на входе мусор? Тогда с вероятностью в 1000% первый же сумматор превратит этот мусор в мусор в квадрате. И с вероятностью 1000% такая нейросеть никогда и ничего из этого мусора не выделит, не найдёт, не вычленит. Ведь в таком случае она не просто копается в мусоре, она его потом ещё и переламывает в мясорубке под названием "следующие слои".
Мой дилетанский подход говорит мне, что нужно менять подход к архитектурам и к отношению к входным данным.
В качестве подтверждения - мои графики выше. Один вход, два входа, три входа - один нейрон, два нейрона, три нейрона. Всё, дальше - переобучение - запоминание пути, а не работа на новых данных.
Второе подтверждение - собственно переобучение. Чем больше нейронов, чем больше слоёв - тем хуже на новых данных. То есть, мы исходные данные с каждым новым слоем, с каждым новым нейроном превращаем в мусор в квадрате, и всё, что остаётся нейросети - просто запоминать путь. С чем она прекрасно справляется при переобучении.
Такой, небольшой полёт мысли