¿Qué alimentar a la entrada de la red neuronal? Tus ideas... - página 30
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Una red normal clasificará por sí misma los datos necesarios y los innecesarios.
Lo principal es qué enseñar.
El aprendizaje con un profesor no encaja aquí. Las redes con propagación de errores hacia atrás son simplemente inútiles.
¿Se entiende cómo debe entrenarse el mecanismo? Básicamente, repasamos los pesos, los ajustamos a un gráfico. Pero, al mismo tiempo, hay otro conjunto de pesos, un conjunto que no sólo se ajusta a este gráfico, sino que se "ajusta" al siguiente, y al siguiente, y al siguiente, y así sucesivamente.
Aquí, el aprendizaje se presenta como la búsqueda de la diferencia entre un conjunto de conjuntos que no funcionan y los que sí.
Y, además, la red entrenada no necesita más "ajuste fino", ya edita los números de pesos por sí misma. ¿Qué otras ideas hay sobre cómo es el aprendizaje automático, cómo se presenta?
Una red normal clasificará por sí misma los datos necesarios y los innecesarios.
Lo principal es qué enseñar.
El aprendizaje con un profesor no encaja aquí. Las redes con propagación de errores hacia atrás son simplemente inútiles.
La red no ordenará nada: la red seleccionará las variables que mejor se ajusten a la muestra de entrenamiento.
Un gran número de variables es un gran mal
La red no ordenará nada, sino que seleccionará las variables que mejor se ajusten a la muestra de entrenamiento.
Ungran número de variables es el principal mal
Para memorizar el camino - el mejor Para aprender (en el entendimiento actual) - el mayor mal.
formar dos parrillas - una en compra y otra en venta.
encienda ambas :-)
luego añade una red de resolución de colisiones (o simplemente alg.) para que no operen en direcciones diferentes al mismo tiempo.
He estado pensando, usted podría script de la marca. Anotar todas las fechas en las que se produce la entrada y el cierre. Si el optimizador pone pesos que dan señal fuera de esas fechas, abrimos con el lote máximo a perder. O no abrir en absoluto.
Resulta que va a ser un método con un maestro, pero por las fuerzas de MT5
La red neuronal puede trabajar incluso en 1 valor de un rasgo, si selecciona los parámetros
pero necesitamos condiciones de grial (dts) con casi ninguna propagación. Creo que cualquier TS trabajará en tales condiciones :)
¿Hay alguna forma de describir el hecho de exigir a la máquina que abra una posición cuando lo considere oportuno? ¿Cómo lo explicaríamos: hacemos que la propia red neuronal abra posiciones... "si, entonces". Especificamos cuándo abrir "Si la salida de la red neuronal es mayor que 0,6", "si de las dos neuronas de salida, la de arriba tiene el valor más alto".
"Si - entonces, si - entonces." Y así sucesivamente. Y aquí, para que no haya límites de apertura, condiciones. Hay entradas, hay pesos. Dentro de la red neuronal hay una especie de papilla gestándose.
¿Es posible describir de alguna manera a la máquina, basándose en su trabajo con las entradas y los pesos (que se buscarán en el optimizador), que abra posiciones cuando ella decida hacerlo? ¿Cómo se puede prescribir esta condición? Para que elija cuando abrir posiciones.
UPD Añadir una segunda red neuronal.
Luego como enlazarla... O varias redes neuronales.
Alguna forma de enlazarlas. O hay alguna otra forma de describir tal tarea
UPD Añadir un bloque de experiencia.
Entonces resulta que es una especie de tabla q. Y necesitamos que todo esté dentro de la red neuronal.
... ¿Cómo establezco esta condición? Para que elija cuándo abrir....
Aquí te puedo ayudar: da señales de compra y venta al mismo tiempo, y la neurona decidirá a dónde ir. No me des las gracias...
Por primera vez me las arreglé para conseguir un conjunto en la parte superior por un trabajador. Por otra parte, un trabajador de hasta 3 años hacia adelante.
Formación durante 9 años desde 2012 hasta 2021
Adelante 2021
Adelante 2022
Adelante 2023
Los 3 años de forward 2021-2023.12.13.
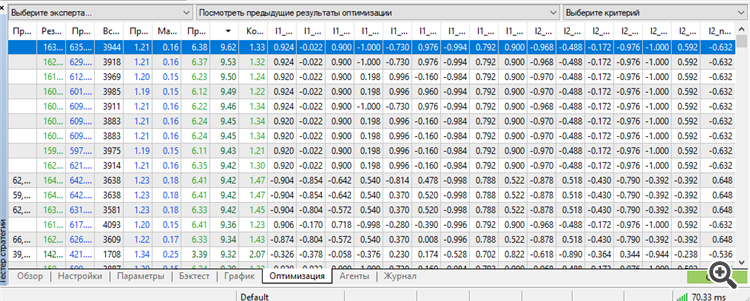
Es cierto, tuvimos que utilizar todo el potencial de MT5: el número máximo de parámetros-pesos optimizables.
Más - jura MT5. Eh, si fuera posible optimizar más parámetros, sería más interesante conocer los resultados. Estoy perplejo por esta inscripción "64 bits demasiado largos" o algo así. Si el algoritmo genético permite optimizar aún más, sería interesante saber cómo saltarse esta limitación
si se pudieran optimizar más parámetros
Como MT5 está limitado en el número de parámetros optimizables, cambié a NeuroPro 1999, del artículo aquí - Redes Neuronales gratis y fácil - Conectando NeuroPro y MetaTrader 5.
Aumenté la arquitectura en cantidad: en MT5 era 5-5-5-5, y aquí es 10-10-10, y el entrenamiento ya es real (para ser más precisos - estándar, por el método de retropropagación de errores y otras características internas dentro del programa.


El autor del programa escupir en él y ni siquiera va a actualizar la rareza - sobre la base de sus respuestas a mis preguntas, no tiene ningún interés en el desarrollo de NeoroPro, la introducción de multithreading, métodos modernos, etc.) Sorprendentemente, el programa puede producir resultados similares a MT5. Pero es fácil romper el avance - añadir otra neurona/añadir otra capa/reducir el tamaño de los datos un mes y todo irá al azar.
Es decir, necesitamos encontrar alguna media de oro entre el sobreentrenamiento y el infraentrenamiento. Además, después del entrenamiento el modelo sigue sin funcionar. Necesitamos post-optimización de los parámetros MT5 - umbrales de apertura para la compra y venta. Algo similar fue hecho por NeuroMachine de los creadores de MeGatrader en su tiempo.
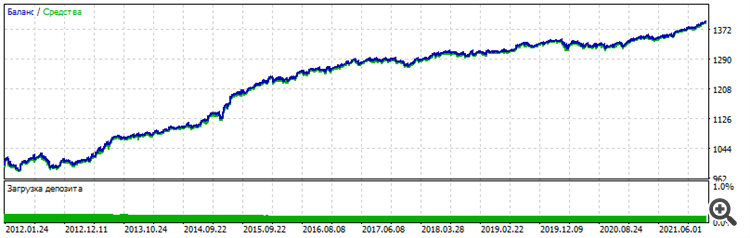
Es decir, algún tipo de post-procesamiento. Sin él, el gráfico de balance apenas se mueve hacia arriba en el periodo enseñado y se drena en el forward. Las condiciones han cambiado: 6 entradas ya, EURUSD H1, a precios de apertura, 10 años de enseñanza de 2012 a 2022.
Forward - últimos dos años 2022-2023-12-16
Gráfico general - se puede ver que la estabilidad similar, el carácter es idéntico, no parece suerte
Voy a probar otros pares y aumentar la arquitectura para excluir por completo el factor suerte y confirmar el rendimiento del método. Bueno y lo más importante - postoptimisation - el conjunto de trabajo estaba en la parte superior en la clasificación por el parámetro "Factor de recuperación". Si no lo hace en una fecha posterior - no habrá confirmación. Una vez más estaré atrapado en el azar, suerte, suerte.
El método del pinchazo creativo me llevó a una idea: una capa de neuronas en el sentido clásico es un montón de malestar.
Especialmente la primera capa, que recibe datos de entrada.
La capa más importante. La entrada son datos heterogéneos. U homogéneos - no importa. Cada dígito, cada número es una representación de forma, contenido, dependencia - en el original.
Es como una fuente, como una película, como una fotografía. E imagina, una red neuronal ordinaria toma cada número, cada atributo - y estúpidamente lo suma, adicionalmente multiplicado por peso, en un montón de basura, llamado sumador. Es como desenfocar una foto e intentar restaurar la imagen - nada funcionará. Ya está. La fuente se ha perdido, se ha borrado. Ha desaparecido. Toda restauración se reduce a una cosa - dibujo adicional. Así es como funcionan las redes neuronales modernas para restaurar fotos antiguas, o para mejorarlas, subirlas de escala - simplemente las dibuja. Sólo el trabajo creativo de la red neuronal, no tiene fuente, dibuja lo que tenía en su base de datos de imágenes una vez, algo similar, aunque sea en un 99%, pero no la fuente.
Y así, alimentamos precios, incrementos de precios, precios transformados, datos indicadores, números en los que alguna figura, algún estado en el gráfico está codificado - y toma y estúpidamente borra la unicidad de cada número, tirando todos los números en un pozo y haciendo una conclusión (salida) sobre la base de esta enorme basura, en la que es imposible distinguir qué es qué. Tal número de sumador de ahora en adelante será idéntico a diferentes figuras, con diferentes números. Es decir, tenemos dos cifras - que se muestran en una secuencia diferente de números. El contenido de estas cifras son diferentes, pero el volumen puede ser el mismo. El volumen es numérico. Y entonces en la sumadora este montón-mala puede significar tanto una figura como otra. Nunca sabremos cuál exactamente - en esta etapa hemos borrado la información única.
La untamos, la echamos en una olla, ahora es sopa. ¿Y si la entrada es basura? Entonces con 1000% de probabilidad el primer sumador convertirá esa basura en basura al cuadrado. Y con un 1000% de probabilidad, esa red neuronal nunca sacará nada de esa basura, nunca la encontrará, nunca la extraerá. Porque en este caso no sólo escarba en la basura, sino que también la rompe en una picadora de carne llamada "capas siguientes".
Mi enfoque de lego me dice que tenemos que cambiar la forma en que enfocamos las arquitecturas y la forma en que tratamos las entradas. Como prueba - mis gráficos de arriba. Una entrada, dos entradas, tres entradas - una neurona, dos neuronas, tres neuronas.
La segunda confirmación es el propio reentrenamiento. Cuantas más neuronas, más capas - peor sobre nuevos datos. Es decir, con cada nueva capa, con cada nueva neurona, convertimos los datos originales en basura al cuadrado, y lo único que le queda a la red neuronal es simplemente memorizar el camino.
Lo que hace perfectamente durante el reentrenamiento. Menuda fantasía.