¿Qué alimentar a la entrada de la red neuronal? Tus ideas... - página 31
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Como confirmación, mis gráficos de arriba. Una entrada, dos entradas, tres entradas: una neurona, dos neuronas, tres neuronas. Eso es todo, lo siguiente es el reentrenamiento - memorizar el camino, no trabajar con nuevos datos.
Lo mismo ocurre con los modelos de madera. Con 3-5 (tal vez hasta 10, pero más probablemente hasta 5) entradas/características, el modelo todavía puede mostrar beneficio en el avance, si más, ya es aleatorio o ciruela.
Es decir, reentrenamiento. Estos 3-5 mejores fichas se obtuvieron mediante una búsqueda completa de pares, treses, etc y la formación de modelos en ellos y seleccionar los mejores en el valving forward.
I van Butko #:
E imagina, una red neuronal ordinaria toma cada número, cada característica - y estúpidamente lo suma, adicionalmente multiplicado por el peso, en un montón de basura, llamado sumador.
Los árboles también usan la media de las hojas.Si es un bosque - promedia con otros árboles, si es un arbusto - resume con árboles refinadores. Es decir, la situación es la misma con las redes neuronales que con los modelos arbóreos. Todo se promedia. Cuando hay mucho ruido, se puede entrenar normalmente sólo con 3-5 fichas.
Promediar con ruido es reentrenar para ruido. P.D. En vez de NeuroPro de más de 20 años puedes usar algo más nuevo. R, Python, o si es difícil tratar con ellos, usar el EXE de Catbusta, como aquíhttps://www.mql5.com/ru/articles/8657. Puedes ejecutar automáticamente el EXE directamente desde el EA, es decir, automatizar completamente el proceso.
Ejemplo https://www.mql5.com/ru/forum/86386/page3282#comment_49771059 P.P.D. Es mejor dormir por la noche. No puedes comprar tu salud, aunque ganes millones en estas redes.
Lo mismo ocurre con los modelos de madera. Con 3-5 (tal vez hasta 10, pero más probablemente hasta 5) fichas/entradas el modelo puede seguir mostrando beneficios en el forward, si son más, entonces ya es aleatorio o plomizo.
Es decir, reentrenamiento. Estas 3-5 mejores fichas se obtuvieron mediante una búsqueda completa de pares, triples, etc. y entrenando modelos sobre ellas y seleccionando las mejores en el jacking forward.
Los árboles también utilizan el valor medio de las hojas.Si bosque - promedia con otros árboles, si arbusto - suma con árboles de refinado. Es decir, la situación es la misma con las redes neuronales que con los modelos arbóreos. Todos promedian. Cuando hay mucho ruido, es posible entrenar normalmente sólo en 3-5 fichas.
Promediar con ruido es volver a entrenar con ruido. P.D. En lugar de NeuroPro, que tiene más de 20 años, puedes usar algo más nuevo. R, Python, o si es difícil tratar con ellos, usar el EXE de Catbusta, como aquíhttps://www.mql5.com/ru/articles/8657. Puedes ejecutar automáticamente el EXE directamente desde el EA, es decir, automatizar completamente el proceso.
Ejemplo https://www.mql5.com/ru/forum/86386/page3282#comment_49771059 P.P.D. Es mejor dormir por la noche. No puedes comprar tu salud, aunque ganes millones en estas redes.
Gracias por el post
No veo el grial en la suma, sino en dividir el número
UPD
Y la tarea de las neuronas no es obtener un conjunto de números, sino obtener un número como entrada. Multiplicarlo por un peso y alimentarlo a través de una función no lineal.
Es decir, hay un número (valor de entrada, o salida de la neurona), y este número es dividido por dos o más neuronas de la capa siguiente.
Deben ser independientes de las demás neuronas. Es un departamento que hace sus propias cosas. Luego, todos estos departamentos deben informar a un jefe: la neurona de salida. Elabora una inferencia basada en las salidas de todas las neuronas finales. Con sus propios pesos.
Así reducimos la distorsión de la información y aumentamos su lectura.
El grial que veo no es la suma, sino la división de números
Bueno las hojas se obtienen dividiendo los datos, incluso en 1000000 partes/hojas diferentes.
Pero el resultado/respuesta de una hoja es la media de los ejemplos/filas incluidos en ella. Así que la división está ahí, pero también la suma. Usted puede dividir a 1 ejemplo en una hoja, pero eso es 100% sobreentrenamiento en el ruido. Árboles también bajo el ruido, no debe dividir profundamente, para un buen delantero (es cómo usted tiene el número de neuronas mejor - pequeño).
Tropezó con una cosa tal como la propagación y la comisión.
Rompen la red neuronal rápidamente. Gracias MT5, sabes como ponerte sobrio. Yo debería haber cambiado a usted de MT4 hace mucho tiempo
@ Andrey Dik tenía razón hace muchos años - el grial todavía se encuentra alrededor de la propagación y la comisión. Tan pronto como se eliminan - los griales de la red neuronal en adelante.
Bueno, las hojas se obtienen dividiendo los datos en 1000000 partes/hojas diferentes.
Pero el resultado/respuesta de una hoja es la media de los ejemplos/filas incluidos en ella. Así que hay división, pero también resumen. Usted puede dividir a 1 ejemplo en una hoja, pero eso es 100% sobreentrenamiento en el ruido. Los árboles también bajo ruido, no deben dividirse profundamente, para un buen avance (es como se tiene el número de neuronas mejor - pequeño).
Hombre, que tema más extenso. Ahora a googlear hojas. En unos 5 años voy a llegar a la rama MO, pero no voy a releerlo
Pasé de Toyota a un viejo coche deportivo Como MT5 está limitado en el número de parámetros optimizables, pasé a NeuroPro 1999, del artículo aquí -Redes neuronales gratis y fácil - conectar NeuroPro y MetaTrader 5.
Aumenté la arquitectura en cantidad: en MT5 era 5-5-5-5, y aquí es 10-10-10, y el entrenamiento ya es real (para ser más precisos - estándar, por el método de retropropagación de errores y otras características internas dentro del programa. Su autor no se preocupa por ello y ni siquiera va a actualizar la rareza - basado en sus respuestas a mis preguntas, no tiene ningún interés en desarrollar NeoroPro, introducir multithreading, métodos modernos, etc.
Tropezó con una cosa tal como la propagación y la comisión.
Rompen la red neuronal rápidamente. Gracias MT5, sabes como ponerte sobrio. Debería haber cambiado a usted de MT4 hace mucho tiempo
@ Andrey Dik tenía razón hace muchos años - el grial todavía se encuentra alrededor de la propagación con la comisión. Tan pronto como se eliminan - los griales de la red neuronal en adelante.
Curioso fenómeno. El entrenamiento sobre la arquitectura "extensión", cuando la primera capa consta de 1 neurona, luego la 2ª capa de 2, la 3ª capa de 3, etc. dio un conjunto tan divertido como curioso: Los resultados del conjunto sobre el periodo de optimización EURUSD son exactamente los mismos sobre otros pares de dólares: Optimización para 2021 sobre EURUSD
Prueba en GBPUSD para 2021
Prueba en AUDUSD para 2021
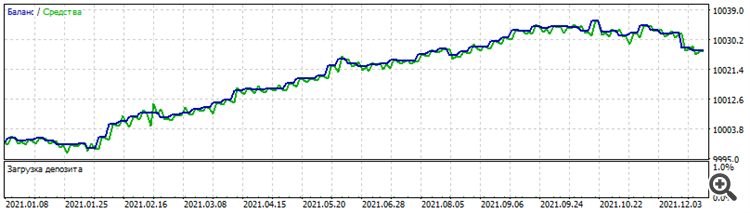

Prueba en NZDUSD para 2021
¿Por qué sólo los curiosos? Porque es un set muerto, no funciona ni antes ni después. Pero, el hecho mismo de que funciona en varios pares de dólares en el mismo período, dado que aunque hay cierta correlación entre ellos, la fijación de precios de cada par sigue siendodiferente.
Curioso fenómeno. El entrenamiento en la arquitectura "extensión", cuando la primera capa consta de 1 neurona, luego la 2ª capa de 2, la 3ª capa de 3, etc. dio un conjunto tan divertido como curioso: Los resultados del conjunto en el periodo de optimización EURUSD son exactamente los mismos en otros pares de dólares: Optimización para 2021 en EURUSD
Prueba en GBPUSD para 2021
Prueba en AUDUSD para 2021 Prueba en NZDUSD para 2021 ¿Por qué sólo lo curioso? Sí porque es un set muerto, no funciona ni antes ni después. Pero, el hecho mismo de que funcione en varios pares de dólares en el mismo periodo, dado que aunque hay cierta correlación entre ellos, el precio de cada par sigue siendodiferente.
No, es diferente
En todos ellos, excepto en el euro, un tercio del saldo al final está en el mismo sitio.