
您应当知道的 MQL5 向导技术(第 10 部分):非常规 RBM
概述

限制性玻尔兹曼机(RBM)是一种神经网络形式,其结构非常简单,在特定圈子中,它们颇受推崇,在于它们能揭示数据集中隐藏的属性和特征。它们从较大维度的输入数据中通过学习,完成较小维度的权重,这些权重通常作为参考概率分布。如常,可从此处阅读更多内容,但通常它们的结构可以用下图来描绘:
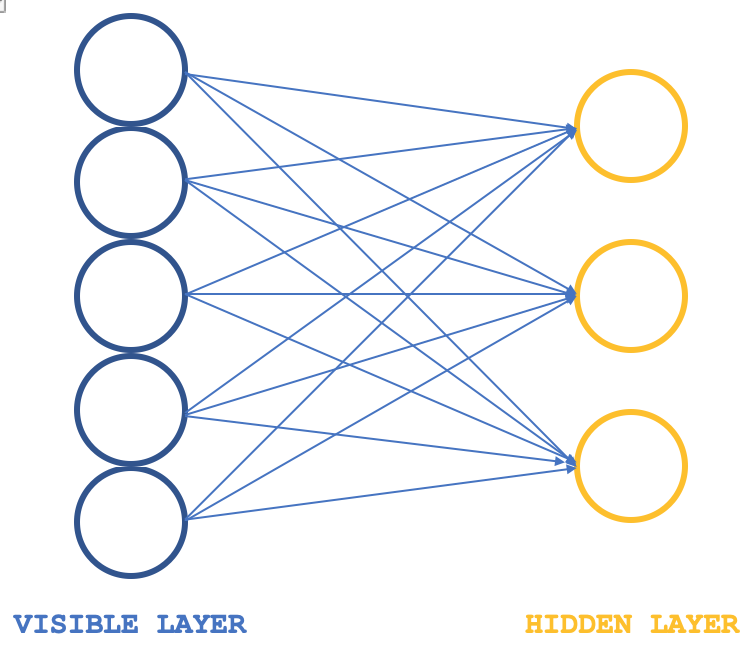
典型情况,RBM 由 2 层组成,(我说典型是因为有一些网络将它们堆叠成变换器),一个可见层和一个隐藏层,可见层比隐藏层更大(含有更多的神经元)。在所谓的正相阶段,可见层中的每个神经元都与隐藏层中的每个神经元相连接,如此,在这个阶段(大多数神经网络都很常见),可见层的输入值乘以连接神经元的权重值,且这些乘积的总和会被添加到偏差中,以便判定相应隐藏神经元的数值。随后是与之相逆的负相阶段,且经由不同的神经元连接,它旨在从隐藏层中的计算值开始将输入数据恢复到其原始状态。
故此,正如人们所期望的那样,在早前的一环中,重建的输入数据必然与初始输入数据不匹配,因为 RBM 通常使用随机权重进行初始化。这意味着需要调整权重,以便重建的输出更接近初始输入数据,这是每个环节之后的附加阶段。这个环节的正相阶段、后随的负相阶段、以及权重调整,其最终结果和意图,是达到连接神经元权重,即将其应用于输入数据时,可为我们提供“直观”的隐藏层中的神经元数值。隐藏层中的这些神经元数值就是所谓的输入数据遍布于隐藏神经元的概率分布。
RBM 环节的正相和负相通常统称为吉布斯(Gibbs)抽样。为了得到准确映射到数据概率分布的连接权重,连接权重可经由所谓的对比散度调整。故此,如果我们有一个简单的类,能在 MQL5 中描绘这一点,那么我们的接口可能如下所示:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Crbm { protected: ... public: bool init; matrix weights_v_to_h; matrix weights_h_to_v; vector bias_v_to_h; vector bias_h_to_v; matrix old_visible; matrix old_hidden; matrix new_hidden; matrix new_visible; matrix output; void GibbsSample(matrix &Input); void ContrastiveDivergence(); Crbm(int Visible, int Hidden, int Sample, double LearningRate, ENUM_LOSS_FUNCTION Loss); ~Crbm(); };
此处值得留意的变量是从可见层传播到隐藏层时记录权重的矩阵,以及逆向传播时记录权重的矩阵,它们分别被相应命名为 'weights_v_to_h' 和 'weights_h_to_v'。还有,应包括记录偏差的向量,最重要的是吉布斯抽样中存储每次所采样神经元数值的 4 组神经元;可见层 2 个,隐藏层 2 个。正相和负相的吉布斯抽样可如下定义其函数:
//+------------------------------------------------------------------+ //| Feed through network using Gibbs Sampling | //+------------------------------------------------------------------+ void Crbm::GibbsSample(matrix &Input) { old_visible.Fill(0.0); old_visible.Copy(Input); //old_hidden = old_visible * weights_v_to_h; //new_hidden = Sigmoid(old_hidden) + bias_v_to_h; for (int GibbsStep = 0; GibbsStep < sample; GibbsStep++) { // Positive phase... Upward pass with biases for (int j = 0; j < hidden; j++) { old_hidden[GibbsStep][j] = 0.0; for (int i = 0; i < visible; i++) { old_hidden[GibbsStep][j] += (old_visible[GibbsStep][i] * weights_v_to_h[i][j]); } new_hidden[GibbsStep][j] = 1.0 / (1.0 + exp(-(old_hidden[GibbsStep][j] + bias_v_to_h[j]))); } } //new_visible = new_hidden * weights_h_to_v; //output = Sigmoid(new_visible) + bias_v_to_h; for (int GibbsStep = 0; GibbsStep < sample; GibbsStep++) { // Negative phase... Downward pass with biases for (int i = 0; i < visible; i++) { new_visible[GibbsStep][i] = 0.0; for (int j = 0; j < hidden; j++) { new_visible[GibbsStep][i] += (new_hidden[GibbsStep][j] * weights_h_to_v[j][i]); } output[GibbsStep][i] = 1.0 / (1.0 + exp(-(new_visible[GibbsStep][i] + bias_h_to_v[i]))); } } }
与之类似,神经元权重和偏差的更新可以通过以下函数实现:
//+------------------------------------------------------------------+ //| Update weights using Contrastive Divergence | //+------------------------------------------------------------------+ void Crbm::ContrastiveDivergence() { // Update weights based on the difference between positive and negative phase matrix _weights_v_to_h_update; _weights_v_to_h_update.Init(visible, hidden); _weights_v_to_h_update.Fill(0.0); matrix _weights_h_to_v_update; _weights_h_to_v_update.Init(hidden, visible); _weights_h_to_v_update.Fill(0.0); for (int i = 0; i < visible; i++) { for (int j = 0; j < hidden; j++) { _weights_v_to_h_update[i][j] = learning_rate * ( (old_visible[0][i] * weights_v_to_h[i][j]) - old_hidden[0][j] ); _weights_h_to_v_update[j][i] = learning_rate * ( (new_hidden[0][j] * weights_h_to_v[j][i]) - new_visible[0][i] ); } } // Apply weight updates for (int i = 0; i < visible; i++) { for (int j = 0; j < hidden; j++) { weights_v_to_h[i][j] += _weights_v_to_h_update[i][j]; weights_h_to_v[j][i] += _weights_h_to_v_update[j][i]; } } // Bias updates vector _bias_v_to_h_update; _bias_v_to_h_update.Init(hidden); vector _bias_h_to_v_update; _bias_h_to_v_update.Init(visible); // Compute bias updates for (int j = 0; j < hidden; j++) { _bias_v_to_h_update[j] = learning_rate * ((old_hidden[0][j] + bias_v_to_h[j]) - new_hidden[0][j]); } for (int i = 0; i < visible; i++) { _bias_h_to_v_update[i] = learning_rate * ((new_visible[0][i] + bias_h_to_v[i]) - output[0][i]); } // Apply bias updates for (int i = 0; i < visible; ++i) { bias_h_to_v[i] += _bias_h_to_v_update[i]; } for (int j = 0; j < hidden; ++j) { bias_v_to_h[j] += _bias_v_to_h_update[j]; } }
使用旧的 RBM 结构,即使在示意图中仅展示了 2 层制程,代码也有 5 层的神经元值,因为负相和正相神经元数值在每次乘积、以及每次激活后都会被记录下来。故此,旧的可见层记录原始输入数据值,旧的隐藏层记录输入和权重的第一个乘积,而随后新的隐藏层记录该乘积的希格玛激活值。新的可见层记录新的隐藏层和负相权重之间的第二次乘积,最后,输出层记录该乘积的激活值。
RBM 的这种正统方式在此仅用于探索目的,因为它随经过编译,但未经测试,由于本文专注介绍设计和训练 RBM 的备选方式。不过,出于分析目的,吉布斯抽样函数的关键输出将是第一和第二隐藏层中的神经元数值。在网络经过充分训练后,可从这两组神经元的双精度值中捕获输入数据属性。
如此,我们可以看看哪些非常规的 RBM 能保持基本原则,但结构不同呢?一个 3-层感知器,其输入层和输出层具有匹配的大小,而其单个隐藏层的大小则小于这两个外层。既然感知器典型情况已具备监督学习,那么如何确保训练仍然是无监督的呢?将每行输入数据也用作目标输出,这本质上是吉布斯抽样在每次循环中执行的操作,如此我们就可像您往常一般通过反向传播达成获取隐藏层所有连接权重的目标。因此,我们的 RBM 结构将类似于下图:
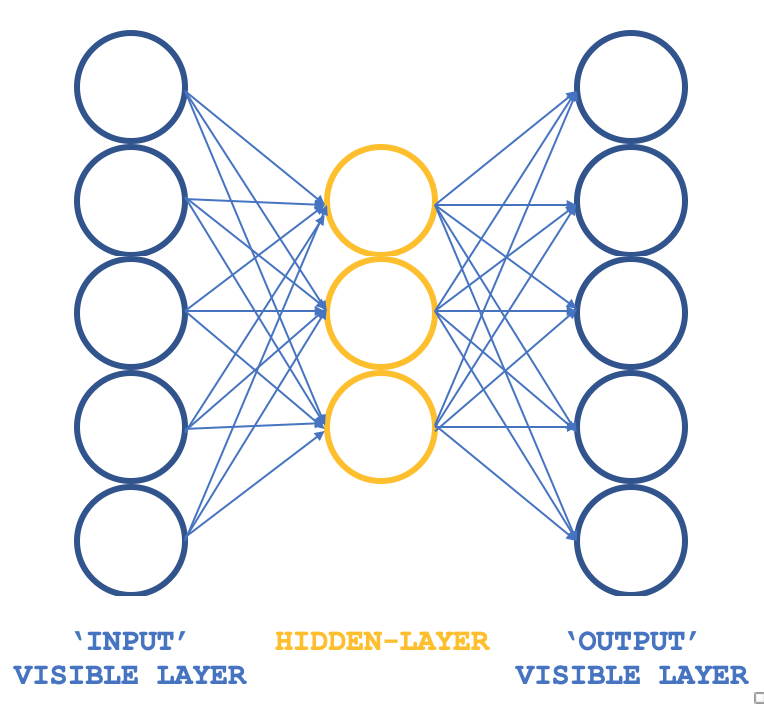
当与 ALGLIB 类一起使用时,这样就提供了一种紧凑、高效的方式来测试 RBM,而非从头开始编写所有代码,这就是我们在这些系列中探索的主题。一旦一个人有了可行的思路,那么就可以考虑定制,也许还可以考虑从头开始编码。
回顾一下,训练目标是获得网络权重,这些权重可以准确地映射隐藏层中输入数据的特征。这些将被提取,并在模型的下一阶段使用,出于我们的目的,它们可以被视为输入数据的规范化格式。
RBM 的起源
参考 deeplearning.net 上的一篇文章,遗憾的是不再有上传,RBM 通常被定义为基于能量的模型,因为它们有能力将标量能量与感兴趣数据集的每个配置相关联。学习是通过修改该能量函数,令其造型具有理想的属性来完成的。“能量函数”是一句口语化,即函数将输入数据集转换为不同的(传输)格式,最后返回至输入数据,如此“能量”是输入数据集和输出数据之间的差值。因此,训练 RBM 的全部意义在于具有理想的“低能量”配置,其中初始输入和最终输出之间的差异最小。基于能量的概率模型将定义通过该能量函数获得的概率分布,即隐藏神经元向量作为所有采样输入数据的隐藏神经元数值之和的分数。
一般来说,训练基于能量的模型,是在训练数据的经验性负对数似然上执行(随机)梯度下降。而一般的玻尔兹曼机没有任何隐藏层,且所有的神经元都相互连接。
因此,令这种计算易于进行的第一步是采用固定数量的模型样本来估算期望值。用于估算正相梯度的样本称为权重,这些矩阵权重和输入数据集向量的乘积应提供神经元值的向量。(即,进行蒙特-卡罗时)。有了这个,我们几乎就有了一个实用的随机算法来学习 EBM。唯一欠缺的因素是如何提取这些权重。虽然统计文献中有很多抽样方法,但马尔可夫链蒙特卡罗方法特别适用于某些模型,诸如玻尔兹曼机(BM),一种特定类型的 EBM。
玻尔兹曼机(BM)是对数线性马尔可夫随机场(MRF)的一种特殊形式,即,能量函数的自由参数是线性的。为了令它们足够强大,来表示复杂的分布(即,从有限参数设置变为非参数设置),我们考虑到一些变量从未被观察到(如上所注,它们被称为隐藏)。通过拥有更多的隐藏变量(也称为隐藏单位),我们可以提高玻尔兹曼机制(BM)的建模能力。受限型玻尔兹曼机是其衍生品,进一步约束 BM,致其成为没有可见-可见、和隐藏-隐藏连接的 BM,如上面介绍图所绘。
因此,在实践中,并非数据集的所有层面都能轻易“可见”,或者我们往往需要引入一些未观察到的变量来提高模型的表达能力。这可被认定为一种假设,即输入数据集的某些层面是未知的,因此需要进行调查。因此,这个假设意味着这些未知数的梯度,其中梯度是已知数据和未知(又名“隐藏”数据)之间的变化或差值。
梯度将包含两个相位,称为正相位和负相位。正相和负相这两项反映的是它们对模型定义的概率密度或映射未知数的影响。正相(即第一阶段)增加了训练数据的概率(通过减少相应的自由能量),而第二相降低了模型生成的样本恢复到采样数据集的可能性。
如此,总而言之,当已知的大小和隐藏数据集是未定义之时,就像在不受约束的玻尔兹曼机中一样,通常很难通过解析来判定这个梯度,因为它涉及大量的计算。这就是为什么 RBM 通过预定义已知和未知的数量,就能切实可行地检测概率分布。
网络架构和训练
我们上面所示的 3-层结构将使用大小为 5 的输入和输出层,以及大小为 3 的隐藏层来实现。基于 5 个神经元值的输入将会当作当前指标值。鉴于所有来源都已附上,因此读者可以替换这些内容,但在本文中,我们将用移动平均线、MACD、随机震荡指标、威廉姆斯百分比范围、和相对活力指数的指标值读数。如上所述,常规化输出捕获来自第一和第二隐藏层值中的神经元值,这意味着该输出向量的大小是隐藏层大小的两倍。
所有权重乘积和激活都由 ALGLIB 类处理,这些可在一个神经元上逐个自定义,且共享以前文章中所示的代码。在本文中,我们采用的是默认值,一旦更加深入,肯定需要调整,但现在它可以用于说明数据概率分布的提取。
故而,该网络上穿插的连接汇集成一只蝴蝶,而非上图所示的箭头
传统神经网络中的反向传播通过多元链式规则的梯度下降来调整连接权重。这与对比离散度不同,不仅它必然会计算更加密集,而且可能会产生与常规 RBM 中得到的截然不同的权重(概率分布)。在本文中,我们把它用于测试运行,并且由于完整的源代码是共享的,因此可以针对该阶段定制修改。
如上所述,反向传播通常是有监督的,因为您需要目标值来获得梯度,在我们的例子中,由于输入作为目标,我们修改后的 RBM 仍然符合无监督的资质。
在训练时,我们的网络将调整其权重,以便输出尽可能接近输入。在此过程中,馈送到网络的任何新数据集都将为隐藏层的神经元提供关键信息。这些信息来自神经元,正如人们所期望的那样,采用数组格式。不过,这个数组的大小是隐藏层中神经元数量的两倍。在我们为测试适配的格式中,隐藏层中的神经元是 3,如此意味着我们从寻找的 5 个指标中捕获属性,输出数组的大小为 6。
这些隐藏神经元值可看作是 5 个指标值的常规化格式。在这种情况下,我们没有降维,因为属性向量的大小为 6,但我们用到了 5 个指标的输入值,但如果我们要使用更多的指标,比如 8 个,并将隐藏层上的神经元数量保持在 3,我们就要降维。
那么我们如何使用这些数值呢?如果我们坚持视它们为指标值的常规化,它们就可作为一个分类向量,如果我们当下在不同的模型中使用它们,即在每组指标值之后,我们以价格最终变化的形式添加监督,那么它们可能会很有用。故此,所有我们要做的只是比较当前值的向量,其最终价格变化对于其它已知变化的向量、以及加权平均值来说是未知的,其中这些向量之间的余弦相似性可当作权重,为下一次变化提供平均预测。
利用 MQL5 编码网络
我们奇怪的 RBM 的接口实现如下所示:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Crbm { protected: int visible; int hidden; int sample; double loss; string file; public: bool init; ... CArrayDouble losses; void Train(matrix &W); void Process(matrix &W, matrix &XY, bool Compare = false); bool ReadWeights(); bool WriteWeights(); bool Writer(); Crbm(int Visible, int Hidden, int Sample, double Loss, string File); ~Crbm(); };
在接口中,我们声明、并运行感知器所需的基本最小类,就像我们在之前的文章中所做的那样。唯一值得注意的新增项是 'losses' 双精度数组,它帮助我们跟踪输入层和输出层之间的差异,并指导流程中哪些网络可将其参数导出写入文件,因为正如过去所强调的那样,感知器应经过测试,且具有导出可调参数的能力,以便在部署或将 EA 移动到生产环境时,可以很容易地采用学习到的权重,而不必每次都按初始随机权重再次训练。
故此,losses 数组只记录每根价格柱线上每个数据行的输入数据集和输出数据集之间的余弦相似性。测试运行结束时,如果低于输入阈值(默认值为 0.9,但它可以调整)的余弦相似度小于上次在文件记录时写入的数值,则把网络权重或可导出参数写入文件。该阈值参数标记为 'loss'。
权重和输入值相乘所用的语法应当比所研究的更复杂,因为'矩阵'和'向量'目前已是 MQL5 中的嵌入式数据类型。在监控关联以及相应的行和列大小时,简单地将它们相乘可以获得相同的结果,但所需内存较少,因此计算资源更少。
网络函数使用 ALGLIB 类来启动、训练和处理数据集。除此之外的自定义,使用自己的硬编码感知器,可以在测试和部署时提高效率,因为 ALGLIB 的代码相当复杂。且“晦涩难懂”,因为它是一个函数库,倾向于满足更广泛的多种场景。然而,即使采用开箱即用的实现方式,也可以进行一些基本的定制,例如激活和乖离,它们对网络性能的影响可能非常显著。这对于初始测试阶段来说可能是资源多样化,这就是我们在这里探索的内容。
因此,通过这种测试设置,我们在每根新柱线上训练我们的非常规 RBM,或者每当我们获得新的价格点时,这意味着我们在每个输入数据点进行分类的权重都会随着每次验算而得到细化和调整。也可以探索权重调整的替代方法,例如每季度调整一次、或每年两次,前提是在使用网络之前已经进行了相当于几年时间的训练。这些在文章中未曾考虑,但提到它可令读者去寻求可能的途径。训练和处理函数的定义如下所示:
//+------------------------------------------------------------------+ //| Train Data Matrix | //+------------------------------------------------------------------+ void Crbm::Train(matrix &W) { for(int s = 0; s < sample; s++) { for(int i = 0; i < visible; i++) { xy.Set(s, i, W[s][i]); xy.Set(s, i + visible, W[s][i]); } } train.MLPTrainLM(model, xy, sample, 0.001, 2, info, report); }
这是十分基本的,因为 ALGLIB 类处理编码。process 函数的编码如下:
//+------------------------------------------------------------------+ //| Process New Vector | //+------------------------------------------------------------------+ void Crbm::Process(matrix &W, matrix &XY, bool Compare = false) { for(int w = 0; w < int(W.Rows()); w++) { CRowDouble _x = CRowDouble(W.Row(w)), _y; base.MLPProcess(model, _x, _y); for(int i = 6; i < visible + 7; i++) { XY[w][i - 6] = model.m_neurons[i]; } //Comparison vector _input = _x.ToVector(); vector _output = _y.ToVector(); if(Compare) { for(int i = 0; i < int(_input.Size()); i++) { printf(__FUNCSIG__ + " at: " + IntegerToString(i) + " we've input: " + DoubleToString(_input[i]) + " & y: " + DoubleToString(_y[i]) ); } //Loss printf(__FUNCSIG__ + " loss is: " + DoubleToString(_output.Loss(_input, LOSS_COSINE)) ); } losses.Add(_output.Loss(_input, LOSS_COSINE)); } }
从某种意义上说,这个函数代表了算法的“秘制酱汁”,因为它显示了我们如何从感知器中检索每个输入数据值的隐藏神经元值。在每根柱线上,我们提取这些权重作为一种采样形式。因此,我们以矩阵格式输出它们,其中输入数据行为我们提供了一个权重向量。
为每个输入数据点提取的权重作为 5 个指标值的常规化形式,上述权重向量比较可以实现如下:
//+------------------------------------------------------------------+ //| RBM Output. | //+------------------------------------------------------------------+ double CSignalRBM::GetOutput(void) { m_close.Refresh(-1); MA.Refresh(-1); MACD.Refresh(-1); STOCH.Refresh(-1); WPR.Refresh(-1); RVI.Refresh(-1); double _output = 0.0; int _i=StartIndex(); matrix _w; _w.Init(m_sample,__VISIBLE); matrix _xy; _xy.Init(m_sample,7); if(RBM.init) { for(int s=0;s<m_sample;s++) { for(int i=0;i<5;i++) { if(i==0){ _w[s][i] = MA.GetData(0,_i+s); } else if(i==1){ _w[s][i] = MACD.GetData(0,_i+s); } else if(i==2){ _w[s][i] = WPR.GetData(0,_i+s); } else if(i==3){ _w[s][i] = STOCH.GetData(0,_i+s); } else if(i==4){ _w[s][i] = RVI.GetData(0,_i+s); } } if(s>0){ _xy[s][2*__HIDDEN] = m_close.GetData(_i+s)-m_close.GetData(_i+s+1); } } RBM.Train(_w); RBM.Process(_w,_xy); double _w=0.0,_w_sum=0.0; vector _x0=_xy.Row(0); _x0.Resize(6); for(int s=1;s<m_sample;s++) { vector _x=_xy.Row(s); _x.Resize(6); double _weight=fabs(1.0+_x.Loss(_x0,LOSS_COSINE)); _w+=(_weight*_xy[s][6]); _w_sum+=_weight; } if(_w_sum>0.0){ _w/=_w_sum; } _output=_w; } return(_output); }
在最后一个 for 循环中,我们根据余弦相似度权重与具有已知 Y(最终价格变化)的其它数据点获得平均可能的预测
我们依据交易品种 GBPUSD ,2023.07.01 到 2023.10.01 的 H4 时间帧数据,优化了智能交易信号类的自定义实例,并从 2023.10.01 到 2023.12.25 进行了前向演练测试,并获得了以下报告。


从中窥视,它可能有前途。如常,理想测试情况是使用交易经纪商的真实跳价数据。不仅是针对输入数据源,也要对感知器的设计和效率进行相应的修改和定制,才能达到理想情况。最后一点很重要,因为可靠的测试结果应该依据较长的历史数据,故此使用开箱即用的 ALGLIB 源,这可能是一个挑战。
结束语
总而言之,我们已经研究了 RBM 网络的传统定义,以及如何在 MQL5 中编写脚本。更重要的是,我们已经探索了如何利用这个网络的一个不寻常的变体,它的结构和训练很像一个简单的多层感知器,并检查了“概率分布”,我们称之为输出权重,是否可用来构建智能交易信号类的另一个自定义实例。来自后向和前向测试的结果表明,使用该系统时可能要进行更广泛的测试,并且可能要对数据输入的选择进行微调。
提示
随附的代码一旦与 MQL5 向导组装在一起即可使用。我已经在这些系列的前面文章中演示了如何做到这一点,不过这篇文章也可作为指导新手的向导。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/13988
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。