
知っておくべきMQL5ウィザードのテクニック(第10回):型破りなRBM
はじめに

制限ボルツマンマシン(RBM)はニューラルネットワークの一種であり、その構造は非常に単純ですが、データセットに隠された特性や特徴を明らかにすることができるため、特定の業界で尊敬を集めています。これは、より大きな次元の入力データからより小さな次元の重みを学習することによって達成されます。これらの重みはしばしば確率分布と呼ばれます。いつものように、こちら(英語)で詳細を読むことができますが、通常、その構造は以下の画像で説明することができます。
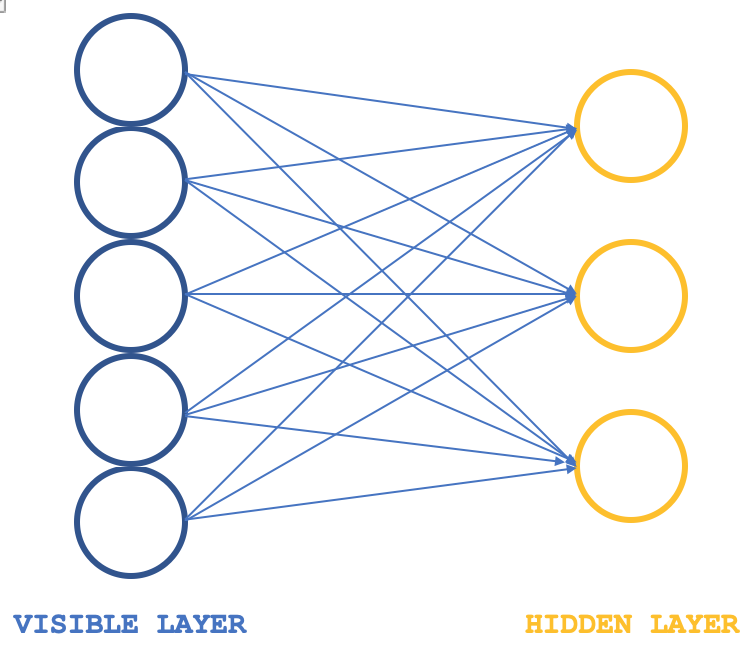
通常、RBMは可視層と隠れ層の2層で構成され、可視層は隠れ層よりも大きくなります(ニューロンが多くなる)(「通常」と言ったのは、transformerに積み重ねるネットワークもあるからです)。可視層のすべてのニューロンは、ポジティブフェーズと呼ばれる間に隠れ層の各ニューロンに接続します。このポジティブフェーズの間、ほとんどのニューラルネットワークで一般的なように、可視層の入力値に接続ニューロンの重み値が乗算され、これらの積の合計がバイアスに加算されて、それぞれの隠れニューロンの値が決定されます。そして、これの逆であるネガティブフェーズがそれに続き、異なるニューロン接続を通して、隠れ層で計算された値から始まる入力データを元の状態に戻すことを目指します。
つまり、RBMはランダムな重みで初期化されることが多いため、初期サイクルでは予想通り、再構成された入力データは初期入力と一致しなくなります。つまり、再構築された出力を入力データに近づけるために重みを調整する必要があるということです。これは各サイクルに続く追加のフェーズとなります。このポジティブフェーズ、ネガティブフェーズ、重み調整のサイクルの最終結果と目的は、入力データに適用したときに、隠れ層の「直感的な」ニューロン値を与えることができる接続ニューロンの重みに到達することです。隠れ層のこれらのニューロン値は、隠れニューロン全体の入力データの確率分布と呼ばれるものです。
RBMサイクルのポジティブフェーズとネガティブフェーズは、しばしばギブスサンプリングと総称されます。そして、データの確率分布に正確に対応する連結重みを得るために、CD (Contrastive Divergence)法と呼ばれる方法で連結重みを調整します。つまり、MQL5でこれを説明する簡単なクラスがあるとすれば、インターフェイスは次のようになります。
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Crbm { protected: ... public: bool init; matrix weights_v_to_h; matrix weights_h_to_v; vector bias_v_to_h; vector bias_h_to_v; matrix old_visible; matrix old_hidden; matrix new_hidden; matrix new_visible; matrix output; void GibbsSample(matrix &Input); void ContrastiveDivergence(); Crbm(int Visible, int Hidden, int Sample, double LearningRate, ENUM_LOSS_FUNCTION Loss); ~Crbm(); };
ここで注目すべき変数は、可視層から隠れ層に伝搬するときと、逆方向に伝搬するときの重みを記録する行列で、それぞれweights_v_to_hとweights_h_to_vと名付けられています。また、バイアスを記録するベクトルや、最も重要なこととして、ギブスサンプリングで使用され、各サンプリングでニューロン値を保存する4セットのニューロン(可視層用に2つ、隠れ層用に2つ)も含める必要があります。ポジティブフェーズとネガティブフェーズのギブスサンプリングは、その機能を以下のように定義することができます。
//+------------------------------------------------------------------+ //| Feed through network using Gibbs Sampling | //+------------------------------------------------------------------+ void Crbm::GibbsSample(matrix &Input) { old_visible.Fill(0.0); old_visible.Copy(Input); //old_hidden = old_visible * weights_v_to_h; //new_hidden = Sigmoid(old_hidden) + bias_v_to_h; for (int GibbsStep = 0; GibbsStep < sample; GibbsStep++) { // Positive phase... Upward pass with biases for (int j = 0; j < hidden; j++) { old_hidden[GibbsStep][j] = 0.0; for (int i = 0; i < visible; i++) { old_hidden[GibbsStep][j] += (old_visible[GibbsStep][i] * weights_v_to_h[i][j]); } new_hidden[GibbsStep][j] = 1.0 / (1.0 + exp(-(old_hidden[GibbsStep][j] + bias_v_to_h[j]))); } } //new_visible = new_hidden * weights_h_to_v; //output = Sigmoid(new_visible) + bias_v_to_h; for (int GibbsStep = 0; GibbsStep < sample; GibbsStep++) { // Negative phase... Downward pass with biases for (int i = 0; i < visible; i++) { new_visible[GibbsStep][i] = 0.0; for (int j = 0; j < hidden; j++) { new_visible[GibbsStep][i] += (new_hidden[GibbsStep][j] * weights_h_to_v[j][i]); } output[GibbsStep][i] = 1.0 / (1.0 + exp(-(new_visible[GibbsStep][i] + bias_h_to_v[i]))); } } }
同様に、ニューロンの重みとバイアスの更新は、以下の関数で実現できます。
//+------------------------------------------------------------------+ //| Update weights using Contrastive Divergence | //+------------------------------------------------------------------+ void Crbm::ContrastiveDivergence() { // Update weights based on the difference between positive and negative phase matrix _weights_v_to_h_update; _weights_v_to_h_update.Init(visible, hidden); _weights_v_to_h_update.Fill(0.0); matrix _weights_h_to_v_update; _weights_h_to_v_update.Init(hidden, visible); _weights_h_to_v_update.Fill(0.0); for (int i = 0; i < visible; i++) { for (int j = 0; j < hidden; j++) { _weights_v_to_h_update[i][j] = learning_rate * ( (old_visible[0][i] * weights_v_to_h[i][j]) - old_hidden[0][j] ); _weights_h_to_v_update[j][i] = learning_rate * ( (new_hidden[0][j] * weights_h_to_v[j][i]) - new_visible[0][i] ); } } // Apply weight updates for (int i = 0; i < visible; i++) { for (int j = 0; j < hidden; j++) { weights_v_to_h[i][j] += _weights_v_to_h_update[i][j]; weights_h_to_v[j][i] += _weights_h_to_v_update[j][i]; } } // Bias updates vector _bias_v_to_h_update; _bias_v_to_h_update.Init(hidden); vector _bias_h_to_v_update; _bias_h_to_v_update.Init(visible); // Compute bias updates for (int j = 0; j < hidden; j++) { _bias_v_to_h_update[j] = learning_rate * ((old_hidden[0][j] + bias_v_to_h[j]) - new_hidden[0][j]); } for (int i = 0; i < visible; i++) { _bias_h_to_v_update[i] = learning_rate * ((new_visible[0][i] + bias_h_to_v[i]) - output[0][i]); } // Apply bias updates for (int i = 0; i < visible; ++i) { bias_h_to_v[i] += _bias_h_to_v_update[i]; } for (int j = 0; j < hidden; ++j) { bias_v_to_h[j] += _bias_v_to_h_update[j]; } }
旧来のRBM構造では、模式的には2層しか図示されていないにもかかわらず、コードには5層分のニューロン値が記録されています。なぜなら、ネガティブフェーズとポジティブフェーズのニューロン値は、各積分の後、また各活性化の後にも記録されるからです。つまり、古い可視層は生の入力データ値を記録し、古い隠れ層は入力と重みの最初の積を記録し、新しい隠れ層はこの積のシグモイド活性化値を記録します。新しい可視層は、新しい隠れ層と負の位相重みの間の2番目の積を記録し、最後に「出力」層はこの積の活性化を記録します。
この記事では、RBMの設計と訓練における別のアプローチに焦点を当てているため、RBMにおけるこのオーソドックスなアプローチは、編集はされているが検証はされていないため、ここでは探索の目的のみで紹介されています。分析目的では、ギブスサンプリング関数の主要な出力は、第1と第2の「隠れ層」のニューロン値です。これら2組のニューロンの2倍の値は、ネットワークが十分に訓練された後の入力データの特性をとらえることになります。
では、基本的な考え方はそのままに、異なる構造を持つ「型破りのRBM」とはどのようなものしょうか。3層パーセプトロンは、入力層と出力層のサイズが一致し、1つの隠れ層のサイズがこれら2つの外側の層よりも小さいです。パーセプトロンは通常教師あり学習なので、教師なし学習であることをどのように保証するのでしょうか。各入力データ行を目標出力としても機能させることで、ギブスサンプリングが各ループで実行していることが本質的になり、隠れ層への全接続の重みを得るという目的は、通常の逆伝播と同じように達成できます。したがって、RBMの構造は以下の画像のようになります。
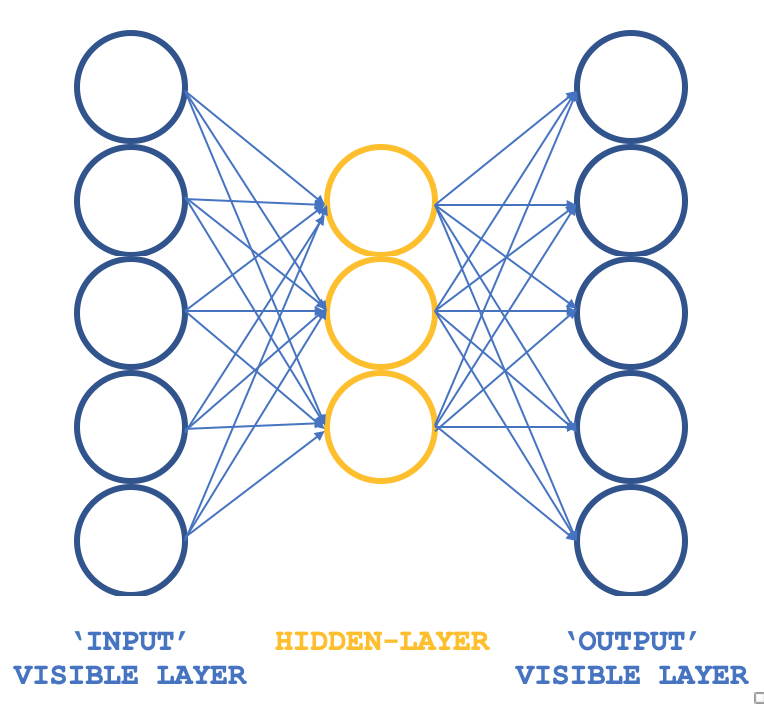
ALGLIBクラスと一緒に使用することで、すべてをゼロからコーディングするのではなく、本連載で探求しているテーマである、RBMをテストするためのコンパクトで効率的なアプローチが提供されます。実行可能なアイデアがあれば、カスタマイズやゼロからのコーディングも検討できるでしょう。
訓練の目的は、隠れ層で入力データの特徴を正確にマッピングできるネットワークの重みを得ることです。これらは抽出され、モデルの次の段階で使用されることになりますが、今回の目的では、入力データの正規化形式と考えることができます。
RBMの起源
deeplearning.netに掲載され、残念ながら現在はアップロードされていない記事を参照すると、RBMは、関心のあるデータセットの各構成にスカラーエネルギーを関連付ける能力により、しばしばエネルギーベースモデル(英語)として定義されています。学習は、そのエネルギー関数の形状が望ましい特性を持つように修正することによっておこなわれます。エネルギー関数とは、入力データセットを異なる(トランジット)形式に変換し、最終的に入力データに戻す関数の俗称で、「エネルギー」が入力データセットと出力データの差となります。したがって、RBMを訓練することの要点は、初期入力と最終出力の差が最小になるような「低エネルギー」の望ましい構成を持つことです。エネルギーベースの確率モデルは、このエネルギー関数を介して得られる確率分布を、サンプリングされたすべての入力データに対する隠れニューロン値の合計の分数として、隠れニューロンベクトルを定義します。
一般的に、エネルギーベースのモデルは、訓練データの経験的負の対数尤度(英語)に対して(確率的)勾配降下をおこなうことによって訓練されます。また、一般的なボルツマンマシンは隠れ層を持たず、すべてのニューロンが相互接続しています。
したがって、この計算を扱いやすくするための最初のステップは、一定数のモデルサンプルを使用して期待値を推定することです。ポジティブフェーズの勾配を推定するために使用されるサンプルは、重みと呼ばれます。これらの行列重みと入力データセットベクトルの積は、ニューロン値のベクトルを提供するはずです(モンテカルロをおこなう場合など)。これで、EBMを学習するための実用的な確率的アルゴリズムがほぼ完成したことになります。唯一欠けているのは、この重みをどうやって抽出するかということです。統計学の文献にはサンプリング法があふれていますが、マルコフ連鎖モンテカルロ法は、EBMの特定のタイプであるボルツマンマシン(BM)のようなモデルに特に適しています。
ボルツマンマシン(BM)は対数線形マルコフ確率場(MRF)の一種であり、エネルギー関数が自由パラメータに対して線形です。複雑な分布を表現するのに十分強力にする(つまり、限定的なパラメトリック設定からノンパラメトリック設定にする)ために、変数のいくつかは観測されないと考えます(前述のように、それらは隠れ変数と呼ばれる)。隠れ変数(隠れユニットとも呼ばれる)を増やすことで、ボルツマンマシン(BM)のモデル化能力を高めることができます。制限ボルツマンマシンは、この派生系で、上の紹介画像のように、BMを可視-可視接続と非可視-非可視接続のないものにさらに制限します。
したがって実際には、データセットのすべての側面が容易に「可視」であるわけではないことは当然であり、モデルの表現力を高めるためには、観測されない変数を導入する必要があります。これは、入力データセットには未知の側面があり、それゆえに調査する必要があるという推定と考えることができます。したがって、この推定は、これらの未知のデータに対する勾配を意味します。勾配とは、既知のデータと未知の、別名「隠れ」データとの間の変化または差のことです。
この勾配には2つのフェーズがあり、ポジティブフェーズ、ネガティブフェーズと呼ばれます。ポジティブとネガティブという用語は、確率密度やモデルによって定義されるマップされた未知数への影響を反映しています。ポジティブフェーズ(別名第1相)は、(対応する自由エネルギーを減少させることによって)訓練データの確率を増加させ、第2相は、モデルによって生成されたサンプルがサンプリングされたデータセットに戻る確率を減少させます。
つまり、制限なしボルツマンマシンのように、既知のデータセットと隠れデータセットのサイズが定義されていない場合、この勾配を解析的に決定することは、多くの計算を必要とするため、通常は困難です。そのため、RBMでは、既知と未知の数をあらかじめ定義しておくことで、確率分布を決定することが可能なのです。
ネットワークアーキテクチャと訓練
上記の3層構造体は、入力層と出力層のサイズを5、隠れ層のサイズを3として実装します。5つのニューロン値の入力は、現在の指標値となります。すべてのソースが添付されているので、読者はこれらを代用することができますが、この記事では、移動平均、MACD、ストキャスティックオシレーター、ウィリアムズパーセンテージレンジ、相対的な活力指数の指標値を使用しています。前述のように正規化出力は、第1および第2隠れ層の値からニューロンの値をキャプチャします。つまり、この出力ベクトルのサイズは隠れ層のサイズの2倍になります。
すべての重みの積と活性化はALGLIBのクラスによって処理され、これらはニューロンごとにカスタマイズ可能です。過去の記事でこれを示すコードを共有しました。この記事ではデフォルトの値を使用していますが、これがさらに一歩進めば調整が必要になることは間違いありません。しかし今のところ、これはデータの確率分布の取得を説明するのに役立ちます。
つまり、このネットワークの接続は、上の図のように、矢印ではなく蝶のような形をしています。
従来のニューラルネットワークにおける逆伝播は、多変量連鎖法則による勾配降下によって接続の重みを調整します。これは対比発散とは異なり、計算量が多くなるだけでなく、通常のRBMで得られるはずの重み(確率分布)と大きく異なる結果をもたらす可能性があります。この記事ではテスト用に使用していますが、完全なソースが共有されているため、このフェーズの修正はカスタマイズ可能です。
前述したように、逆伝播は、勾配を得るために目標値が必要なので、通常は教師ありです。私たちの場合、入力が目標として機能するため、修正されたRBMは依然として教師なしとして適格であると私は主張します。
訓練では、出力が入力にできるだけ近くなるように、ネットワークの重みを調整します。そうすることで、ネットワークに供給される新しいデータセットはすべて、隠れ層のニューロンに重要な情報を提供することになります。ニューロンからのこの情報は、予想通り配列形式になっています。この配列のサイズは、隠れ層のニューロン数の2倍です。テスト用に適応している形式では隠れ層のニューロンは3つなので、求めている5つの指標からの特性をキャプチャする出力配列のサイズは6になります。
これらの隠れニューロンの値は、5つの指標値の正規化形式とみなすことができます。この場合、特性ベクトルは6であり、5つの入力指標値を使用しているため、次元削減はおこなわれませんが、より多くの指標、例えば8つの指標を使用し、隠れ層のニューロン数を3に保てば、次元削減がおこなわれるでしょう。
では、これらの値をどのように使用するのでしょうか。単に指標値を正規化したものであるという見方にこだわれば、指標値の各セットに続く最終的な価格の変化という形で監視を加える別のモデルで使用する場合、分類ベクトルとして役立ち、比較に役立つ可能性があります。つまり、最終的な価格変動が未知である現在値のベクトルを、変動が既知である他のベクトルと比較し、これらのベクトル間のコサイン類似度が重みとして作用する加重平均によって、次の変動に対する平均的な予測を提供するだけです。
MQL5でネットワークをコーディングする
この奇妙なRBMを実装するインターフェイスは以下のようになります。
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class Crbm { protected: int visible; int hidden; int sample; double loss; string file; public: bool init; ... CArrayDouble losses; void Train(matrix &W); void Process(matrix &W, matrix &XY, bool Compare = false); bool ReadWeights(); bool WriteWeights(); bool Writer(); Crbm(int Visible, int Hidden, int Sample, double Loss, string File); ~Crbm(); };
インターフェイスでは、以前の記事で説明したように、パーセプトロンを実行するために必要な基本的な最小限のクラスを宣言し、使用します。というのも、これまで強調されてきたように、パーセプトロンは調整可能なパラメータを書き出す機能とともにテストされるべきであり、EAを本番環境に導入したり移動させたりする際には、毎回初期のランダムな重みから再訓練するのではなく、学習した重みをすぐに使用することができるからです。
従って、損失配列は、各価格バーの各データ行について、入力データセットと出力データセットの間のコサイン類似度を記録するだけです。テスト実行の最後に、入力閾値(デフォルト値は0.9だが調整可能)以下のコサイン類似度が、前回ログに書き込まれた値より小さければ、ネットワークの重みまたは書き出し可能なパラメータがファイルに書き込まれます。この閾値パラメータは「損失」とラベル付けされています。
重みと入力値の乗算に使用される構文は、MQL5でmatrixとvectorが埋め込みデータ型になったことを考えると、おそらく必要以上に複雑でしょう。モニタリングの関連付けと、それぞれの行と列のサイズを単純に掛け合わせるだけで、より少ないメモリ、したがってより少ない計算リソースで同じ結果を得ることができます。
ネットワーク機能はALGLIBクラスを使用してデータセットの開始、学習、処理をおこないます。ALGLIB のコードはライブラリであるため、より幅広いシナリオに対応する傾向があり、かなり複雑で「入り組んでいる」ため、独自にハードコードされたパーセプトロンを使用してこれ以外のカスタマイズをおこなうと、テスト時や展開時の効率が向上する可能性があります。しかし、アウトオブボックスの実装であっても、活性化やバイアスなど、いくつかの基本的なカスタマイズは可能であり、それらがネットワークのパフォーマンスに与える影響は非常に大きいです。これは最初のテスト段階では有益です。それが私たちがここで見ているものです。
つまり、このテストセットアップでは、新しいバーが出るたびに、あるいは新しい価格ポイントが出るたびに、型破りなRBMを訓練します。つまり、各入力データポイントの分類をおこなうために依存する重みが、パスごとに改良および調整されます。もちろん、ネットワークを使用する前にかなりの年数にわたる訓練がおこなわれていれば、四半期に1回、または1年に2回重みを調整するなど、重み調整の代替アプローチも検討できます。本稿ではこれらについては触れませんが、読者が追求しうる道として言及します。訓練関数とプロセス関数は以下のように定義されています。
//+------------------------------------------------------------------+ //| Train Data Matrix | //+------------------------------------------------------------------+ void Crbm::Train(matrix &W) { for(int s = 0; s < sample; s++) { for(int i = 0; i < visible; i++) { xy.Set(s, i, W[s][i]); xy.Set(s, i + visible, W[s][i]); } } train.MLPTrainLM(model, xy, sample, 0.001, 2, info, report); }
ALGLIBクラスがコーディングを処理するので、かなり初歩的です。プロセス関数は次のようにコーディングされます。
//+------------------------------------------------------------------+ //| Process New Vector | //+------------------------------------------------------------------+ void Crbm::Process(matrix &W, matrix &XY, bool Compare = false) { for(int w = 0; w < int(W.Rows()); w++) { CRowDouble _x = CRowDouble(W.Row(w)), _y; base.MLPProcess(model, _x, _y); for(int i = 6; i < visible + 7; i++) { XY[w][i - 6] = model.m_neurons[i]; } //Comparison vector _input = _x.ToVector(); vector _output = _y.ToVector(); if(Compare) { for(int i = 0; i < int(_input.Size()); i++) { printf(__FUNCSIG__ + " at: " + IntegerToString(i) + " we've input: " + DoubleToString(_input[i]) + " & y: " + DoubleToString(_y[i]) ); } //Loss printf(__FUNCSIG__ + " loss is: " + DoubleToString(_output.Loss(_input, LOSS_COSINE)) ); } losses.Add(_output.Loss(_input, LOSS_COSINE)); } }
この関数は、各入力データ値に対してパーセプトロンから隠れニューロンの値をどのように取り出すかを示しているので、ある意味でアルゴリズムの「秘密のソース」を示しています。それぞれのバーで、サンプリングの一形態としてこれらの重みを取り出します。したがって、入力データの行が重みのベクトルを与える行列形式で出力します。
各入力データポイントに対して抽出された重みは、5つの指標値を正規化した形となり、前述の重み付きベクトル比較は以下のように実現できます。
//+------------------------------------------------------------------+ //| RBM Output. | //+------------------------------------------------------------------+ double CSignalRBM::GetOutput(void) { m_close.Refresh(-1); MA.Refresh(-1); MACD.Refresh(-1); STOCH.Refresh(-1); WPR.Refresh(-1); RVI.Refresh(-1); double _output = 0.0; int _i=StartIndex(); matrix _w; _w.Init(m_sample,__VISIBLE); matrix _xy; _xy.Init(m_sample,7); if(RBM.init) { for(int s=0;s<m_sample;s++) { for(int i=0;i<5;i++) { if(i==0){ _w[s][i] = MA.GetData(0,_i+s); } else if(i==1){ _w[s][i] = MACD.GetData(0,_i+s); } else if(i==2){ _w[s][i] = WPR.GetData(0,_i+s); } else if(i==3){ _w[s][i] = STOCH.GetData(0,_i+s); } else if(i==4){ _w[s][i] = RVI.GetData(0,_i+s); } } if(s>0){ _xy[s][2*__HIDDEN] = m_close.GetData(_i+s)-m_close.GetData(_i+s+1); } } RBM.Train(_w); RBM.Process(_w,_xy); double _w=0.0,_w_sum=0.0; vector _x0=_xy.Row(0); _x0.Resize(6); for(int s=1;s<m_sample;s++) { vector _x=_xy.Row(s); _x.Resize(6); double _weight=fabs(1.0+_x.Loss(_x0,LOSS_COSINE)); _w+=(_weight*_xy[s][6]); _w_sum+=_weight; } if(_w_sum>0.0){ _w/=_w_sum; } _output=_w; } return(_output); }
最後のforループで、Y(最終的な価格変化)がわかっている他のデータポイントとのコサイン類似度重み付けに基づいて、平均的な可能性の高い予測を得ます。
2023.07.01から2023.10.01までの4時間足と、2023.10.01から2023.12.25までのウォークフォワードテストで、EAシグナルクラスのカスタマイズインスタンスを最適化し、以下のレポートを得ました。


これらを見る限り、期待できるかもしれません。いつものように、取引する証券会社の実際のティックを使用してテストするのが理想的です。そしてこれは、入力データソースだけでなく、おそらくパーセプトロンの設計や効率にも適切な変更やカスタマイズがなされた後が理想的でしょう。最後の部分は重要です。信頼できるテスト結果は長期間の履歴データに渡って得られる必要があるため、そのままのALGLIBソースではこれが困難になる可能性があります。
結論
従来のRBMネットワークの定義と、これをMQL5でどのように書けるかを見てきました。さらに重要なことは、単純な多層パーセプトロンのように構造化され、訓練されたこのネットワークの珍しい変形がどのように機能するかを探求し、出力重みと呼ばれる「確率分布」が、EAシグナルクラスの別のカスタムインスタンスの構築に利用できるかどうかを調べたことです。バックテストとフォワードテストの結果は、より広範なテストと、おそらくデータ入力の選択の微調整を条件として、システムを使用する可能性があることを示しています。
備考
添付のコードは、MQL5ウィザードで一度組み立てれば使用可能です。この連載の以前の記事でその方法を紹介しましたが、ウィザードを初めて使う方はこの記事をガイドにできます。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/13988
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索