
Aprendizaje automático y Data Science (Parte 17): ¿Crece el dinero en los árboles? Bosques aleatorios en el mercado Fórex

Dos cabezas piensan mejor que una, no porque cualquiera de ellas sea infalible, sino porque es poco probable que se equivoquen en la misma dirección.
Algoritmo de bosque aleatorio
El bosque aleatorio es un método de aprendizaje conjunto que construye múltiples árboles de decisión durante el entrenamiento y da como resultado una clase en el modo de clasificación o una predicción media en el modo de regresión. Cada árbol del bosque aleatorio se entrena con un subconjunto diferente de datos, y la aleatoriedad añadida durante el entrenamiento ayudará a mejorar el rendimiento global del modelo y su generalizabilidad.
En primer lugar, debemos entender qué es el aprendizaje conjunto.
Formación de conjuntos
El aprendizaje conjunto es un enfoque en el que dos o más modelos de aprendizaje automático se ajustan a los mismos datos, combinándose además las predicciones de cada modelo. La idea que subyace en este aprendizaje es que los modelos conjuntos funcionan mejor que cualquier modelo individual.
El bosque aleatorio es un método de conjunto que combina las predicciones de varios árboles de decisión para mejorar la capacidad de predicción de un modelo individual.

Para demostrarlo, hemos construido un árbol de decisión y un bosque aleatorio de diez (10) árboles. En el mismo conjunto de datos, hemos logrado una mayor precisión en las fases de entrenamiento y prueba en la variante de bosque aleatorio.
Características principales del bosque aleatorio
01: Formación de conjuntos
El bosque aleatorio es un método de conjunto que combina las predicciones de varios modelos para producir un resultado mejorado.
for (uint i=0; i<m_ntrees; i++) //Build a given x number of trees { temp_data = data; matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets forest[i] = new CDecisionTreeClassifier(this.m_minsplit, this.m_maxdepth); //Add the tree to the forest forest[i].fit(x_subset, y_subset); //Add the trained tree to the forest preds = forest[i].predict(x_subset); }
02: Bootstrapping - agregación inicial (agrupación)
El bootstrapping en el aprendizaje automático es una técnica de remuestreo que consiste en obtener repetidamente muestras de los datos originales con reemplazo, con frecuencia para estimar un parámetro de población.
Cada árbol del bosque aleatorio se entrena con un subconjunto diferente de los datos creados usando bootstrapping (muestreo con reemplazo).
matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets
Código:
template<typename T> void CMatrixutils::Randomize(matrix<T> &matrix_,int random_state=-1, bool replace=false)
El parámetro replace = true permite seleccionar el mismo índice más de una vez, simulando el proceso de bootstrapping.
03: Aleatoriedad de las características
Al dividir los nodos en la construcción de cada árbol, se tienen en cuenta subconjuntos aleatorios de características.
Esto introduce una variedad adicional entre los árboles, haciendo que el conjunto resulte más robusto.
04: Mecanismo de votación (o promediación)
Para las tareas de clasificación, se usa el modo de predicción (la clase más frecuente).
En los problemas de regresión, se considera la media de las predicciones.
En la clasificación de los bosques aleatorios se usa un proceso de votación. Existen diferentes técnicas que pueden usarse como mecanismo de votación, como el voto suave o el umbral:
Votación suave
La predicción de cada árbol se vincula a una determinada puntuación de confianza (probabilidad) en la votación suave. La previsión final es una media ponderada de dichas probabilidades.
Como nuestra clase de árbol de decisión aún no puede predecir probabilidades, no podemos utilizar este mecanismo de votación. Utilizaremos la votación de usuario.
Umbral de votación
El mecanismo de votación es el siguiente: si un determinado porcentaje de árboles predice una determinada clase, esta se considerará la predicción final. Esto garantizará un nivel mínimo de confianza.
Usar un porcentaje de árboles para determinar qué clase predecir puede resultar difícil a la hora de pronosticar varias clases. Por lo tanto, configuraremos la función para que seleccione la clase que más árboles han predicho, independientemente de cuántas clases se hayan predicho.
double CRandomForestClassifier::predict(vector &x) { vector predictions(m_ntrees); //predictions from all the trees for (uint i=0; i<this.m_ntrees; i++) //all trees make the predictions predictions[i] = forest[i].predict(x); vector uniques = matrix_utils.Unique(predictions); return uniques[matrix_utils.Unique_count(predictions).ArgMax()]; //select the majority decision }
Ampliación de la clase de árbol de decisión
En el artículo anterior, hablamos de la clasificación mediante árboles de decisión, que resulta adecuada para clasificar variables objetivo binarias. En dicho artículo, tuvimos que ampliar las clases y el código de los árboles de decisión para los problemas de regresión.
class CDecisionTreeRegressor: public CDecisionTreeClassifier { private: double calculate_leaf_value(vector &Y); split_info get_best_split(matrix &data, uint num_features); double variance_reduction(vector &parent, vector &l_child, vector &r_child); Node *build_tree(matrix &data, uint curr_depth = 0); public: CDecisionTreeRegressor(uint min_samples_split = 2, uint max_depth = 2); ~CDecisionTreeRegressor(void); void fit(matrix &x, vector &y); };
En la mayoría de los casos, estas dos clases son similares, usan la misma clase de nodo y muchas funciones, salvo las funciones de cálculo del coste de la hoja, la ganancia de información, la construcción del árbol y el aprendizaje.
Valores de hoja en los árboles de decisión para problemas de regresión
En los problemas de regresión, el valor de la hoja de un nodo determinado será la media de todos sus valores.
double CDecisionTreeRegressor::calculate_leaf_value(vector &Y) { return Y.Mean();
Cálculo de la ganancia de la información
En el último artículo decíamos que el criterio de ganancia de información mide la reducción de la entropía o incertidumbre tras dividir un conjunto de datos.
En lugar de utilizar Gini y la entropía, que se basan en la probabilidad, utilizaremos una fórmula de reducción de la varianza para medir las impurezas en un nodo determinado.
double CDecisionTreeRegressor::variance_reduction(vector &parent, vector &l_child, vector &r_child) { double weight_l = l_child.Size() / (double)parent.Size(), weight_r = r_child.Size() / (double)parent.Size(); return parent.Var() - ((weight_l * l_child.Var()) + (weight_r * r_child.Var())); }
La función anterior calcula la reducción de la varianza conseguida al dividir el conjunto de datos en los nodos hijos izquierdo y derecho en un nodo concreto del árbol de decisión.
Construcción del árbol y función de entrenamiento
Construcción del árbol
Node *CDecisionTreeRegressor::build_tree(matrix &data, uint curr_depth=0) { matrix X; vector Y; if (!matrix_utils.XandYSplitMatrices(data,X,Y)) //Split the input matrix into feature matrix X and target vector Y. { #ifdef DEBUG_MODE printf("%s Line %d Failed to build a tree Data Empty",__FUNCTION__,__LINE__); #endif return NULL; //Return a NULL pointer } ulong samples = X.Rows(), features = X.Cols(); //Get the number of samples and features in the dataset. ArrayResize(nodes, nodes.Size()+1); //Append the nodes to memory Node *left_child, *right_child; if (samples >= m_min_samples_split && curr_depth<=m_max_depth) { split_info best_split = this.get_best_split(data, (uint)features); #ifdef DEBUG_MODE Print(__FUNCTION__," | ",__LINE__,"\nbest_split left: [",best_split.dataset_left.Rows(),"x",best_split.dataset_left.Cols(),"]\nbest_split right: [",best_split.dataset_right.Rows(),"x",best_split.dataset_right.Cols(),"]\nfeature_index: ",best_split.feature_index,"\nInfo gain: ",best_split.info_gain,"\nThreshold: ",best_split.threshold); #endif if (best_split.info_gain > 0) { left_child = this.build_tree(best_split.dataset_left, curr_depth+1); right_child = this.build_tree(best_split.dataset_right, curr_depth+1); nodes[nodes.Size()-1] = new Node(best_split.feature_index,best_split.threshold,left_child,right_child,best_split.info_gain); return nodes[nodes.Size()-1]; } } nodes[nodes.Size()-1] = new Node(); nodes[nodes.Size()-1].leaf_value = this.calculate_leaf_value(Y); return nodes[nodes.Size()-1]; }
Función Fit
void CDecisionTreeRegressor::fit(matrix &x, vector &y) { matrix data = matrix_utils.concatenate(x, y, 1); this.root = this.build_tree(data); is_fitted = true; }
La única diferencia entre la función build_tree de la clase Reressor y la clase Classifier es la función variance_reduction.
Para probar la regresión, hemos utilizado datos listos para usar del conjunto Airfoil noise data.
matrix data = matrix_utils.ReadCsv("airfoil_noise_data.csv"); matrix x; vector y; if (!matrix_utils.XandYSplitMatrices(data, x, y)) return INIT_FAILED; regressor_tree = new CDecisionTreeRegressor(3,3); regressor_tree.fit(x, y); regressor_tree.print_tree(regressor_tree.root); vector preds = regressor_tree.predict(x); Print("r-squared: ",metrics.r_squared(y, preds));
Resultados
KS 0 00:04:11.402 RandomForest Test (EURUSD,H1) : X_0<=3150.0?7.6482714516406745 FI 0 00:04:11.402 RandomForest Test (EURUSD,H1) ---> left: X_4<=0.0150478?4.070223732531591 ME 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> left: X_2<=0.1016?2.453283788183441 RR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=630.0?2.3366165961173238 JR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 126.94465000000002 MF 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 130.51523904382472 II 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_0<=1600.0?4.999630155449349 HF 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 127.90983653846149 JM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 122.97036507936505 JR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> right: X_4<=0.0483159?6.040280153408631 FI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=1250.0?5.315257051142112 IG 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 125.68045918367342 GM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 120.69493181818189 NQ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_0<=1250.0?13.291165881821172 GK 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 117.69977777777775 GH 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 109.80075000000001 EL 0 00:04:11.402 RandomForest Test (EURUSD,H1) ---> right: X_4<=0.00152689?28.997059993530435 OL 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> left: X_0<=6300.0?11.053304033466667 HK 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_4<=0.000930789?9.067095683299033 FG 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 134.9866388888889 NO 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 128.59900000000002 QS 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_4<=0.000930789?9.783359845444707 NI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 128.05125581395347 GJ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 120.90806666666667 RM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> right: X_4<=0.0341183?5.715854852017056 LN 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=5000.0?5.190320913085316 GN 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 120.08625170068028 NE 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 115.52968965517242 MI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_4<=0.0483159?4.450134400476193 IS 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 109.44371428571428 GQ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 104.84033333333332 PH 0 00:04:11.403 RandomForest Test (EURUSD,H1) r-squared: 0.5937442611327515
El árbol de regresión parece tener más ramas para los mismos parámetros.
La precisión de nuestro modelo de regresión durante el entrenamiento ha sido del 59%. Es una buena señal de que hayamos acertado. Aquí tenemos las proyecciones representadas en el gráfico:

La forma en que las predicciones coinciden con los valores reales parece casi un árbol.
Ventajas de los bosques aleatorios
Alta precisión: los bosques aleatorios suelen ofrecer una mayor precisión tanto en tareas de clasificación como de regresión.
Resistencia: la naturaleza de conjunto de Random Forest lo hace resistente al sobreentrenamiento y a los datos con ruido.
Importancia de las características: los bosques aleatorios pueden proporcionar información sobre la importancia de las características, lo cual ayuda a seleccionarlas.
Menor varianza: la diversidad de árboles minimiza la varianza del modelo, lo cual mejora la capacidad de generalización.
No es necesario escalar las características: al igual que los árboles de decisión, los bosques aleatorios son menos sensibles al escalado de características, lo que los hace adecuados para muestras con diferentes escalas de datos.
Versatilidad: resultan adecuados para diversos tipos de datos, incluidas características categóricas y numéricas.
Construcción de un clasificador de bosque aleatorio
Ya hemos investigado las ventajas del algoritmo de bosque aleatorio sobre el árbol de decisión. Veamos ahora cómo construir un modelo de bosque aleatorio, comenzando por un clasificador.
Habilitamos la clase CDecisionTreeClassifier.
class CRandomForestClassifier { CMetrics metrics; protected: uint m_ntrees; uint m_maxdepth; uint m_minsplit; int m_random_state; CMatrixutils matrix_utils; CDecisionTreeClassifier *forest[]; string ConvertTime(double seconds); public: CRandomForestClassifier(uint n_trees=100, uint minsplit=NULL, uint max_depth=NULL, int random_state=-1); ~CRandomForestClassifier(void); void fit(matrix &x, vector &y, bool replace=true); double predict(vector &x); vector predict(matrix &x); };
Como un clasificador de bosque aleatorio es simplemente x árboles clasificadores combinados en un único bosque, suministraremos a la clase un array forest[] de objetos CDecisionTreeClassifier
n_trees = 100 (por defecto), lo que significa que habrá 100 árboles en el bosque del clasificador de bosque aleatorio.
min_split y max_depth son los parámetros para cada árbol de los que hablamos en el último artículo. min_split es el número mínimo de ramas que deberá tener un árbol, y max_depth es lo largo que deberá ser el árbol en cuanto a esas ramas.
Incorporación de árboles en un bosque aleatorio
Esta es la función más importante de la clase CRandomForestClassifier, donde el bosque incluye n_trees árboles seleccionados en el constructor de la clase.
void CRandomForestClassifier::fit(matrix &x, vector &y, bool replace=true) { matrix x_subset; vector y_subset; matrix data = this.matrix_utils.concatenate(x, y, 1); matrix temp_data = data; vector preds; datetime time_start = GetTickCount(), current_time; Print("[ Classifier Random Forest Building ]"); for (uint i=0; i<m_ntrees; i++) //Build a given x number of trees { time_start = GetTickCount(); temp_data = data; matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets if (!this.matrix_utils.XandYSplitMatrices(temp_data, x_subset, y_subset)) //split the random subset into x and y subsets { ArrayRemove(forest,i,1); //Delete the invalid tree in a forest printf("%s %d Failed to split data for a tree ",__FUNCTION__,__LINE__); continue; } forest[i] = new CDecisionTreeClassifier(this.m_minsplit, this.m_maxdepth); //Add the tree to the forest forest[i].fit(x_subset, y_subset); //Add the trained tree to the forest preds = forest[i].predict(x_subset); current_time = GetTickCount(); printf(" ==> Tree <%d> Rand Seed <%s> Accuracy Score: %.3f Time taken: %s",i+1,m_random_state==-1?"None":string(m_random_state),metrics.accuracy_score(y_subset, preds), ConvertTime((current_time - time_start) / 1000.0)); } m_ntrees = ArraySize(forest); //The successfully build trees }
Comparación de los clasificadores Decision Tree y Random Forest
Para demostrar que los clasificadores aleatorios gestionan las tareas de clasificación mejor que los árboles de decisión, hemos realizado 5 pruebas.
Prueba 01:
| Entrenamiento | Simulación | |
|---|---|---|
| Árbol de decisión | 73.8% | 40% |
| Bosque aleatorio | 78% | 45% |
Prueba 02:
| Árbol de decisión | 73.8% | 40% |
| Bosque aleatorio | 83% | 45% |
Prueba 03:
| Árbol de decisión | 73.8% | 40% |
| Bosque aleatorio | 80% | 45% |
Prueba 04:
| Árbol de decisión | 73.8% | 40% |
| Bosque aleatorio | 78.8% | 45% |
Prueba 05:
| Árbol de decisión | 73.8% | 40% |
| Bosque aleatorio | 78.8% | 45% |
Según mi experiencia, el uso de un clasificador de bosque aleatorio para los datos comerciales puede resultar confuso, ya que uno puede encontrarse con situaciones en las que la precisión global del bosque aleatorio no supere la precisión de un único árbol de decisión. Esto se debe a uno o varios de los siguientes factores.
Por qué un bosque aleatorio no ofrece más precisión que un único árbol de decisión:
Falta de diversidad de árboles
Los bosques aleatorios aprovechan la diversidad de cada árbol. Si todos los árboles son iguales, el conjunto no supondrá una mejora significativa.
Asegúrese de introducir correctamente la aleatoriedad durante el entrenamiento de cada árbol. La aleatorización puede implicar la selección de subconjuntos aleatorios de características y/o el uso de diferentes subconjuntos de datos de entrenamiento.
Configuración de hiperparámetros
Experimente con diferentes hiperparámetros, como el número de características a considerar para cada división (m_max_features), el número mínimo de muestras para dividir un nodo interno (m_minsplit) y la profundidad máxima de los árboles (m_maxdepth).
Una búsqueda en cuadrícula o aleatoria sobre un rango de valores de hiperparámetros podría ayudarle a encontrar las mejores configuraciones.
Validación cruzada
Use la validación cruzada para evaluar el rendimiento del modelo. Esto le ayudará a evaluar de forma más fiable el grado de generalización del modelo a nuevos datos.
La validación cruzada también le servirá para detectar problemas de sobreentrenamiento o infraentrenamiento.
Entrenamiento en todo el conjunto de datos
Asegúrese de que los árboles no se ajustan a los datos de entrenamiento. Si cada árbol del bosque se entrena con el conjunto de datos completo, podrá captar ruido en lugar de señales.
Tal vez habría que entrenar cada árbol con datos empaquetados (bootstrapping).
Escalado de características
Si sus características tienen escalas diferentes, podría ser útil escalarlas. Los árboles de decisión no suelen ser sensibles a las escalas de características. Normalizar o estandarizar las características puede resultar útil, sobre todo si se estamos comparando el rendimiento de un solo árbol con el de un conjunto.
Métrica de evaluación
Asegúrese de usar la métrica de evaluación adecuada para el problema que intenta resolver con sus modelos. La medida común de la evaluación de la regresión es R-cuadrado, mientras que la medida común de la evaluación de la clasificación es la tasa de precisión.
El último argumento de fit() es error. Permite seleccionar la métrica adecuada para medir la precisión de cada árbol del bosque.
enum errors_classifier { ERR_ACCURACY }; enum errors_regressor { ERR_R2_SCORE, ERR_ADJUSTED_R };
Tamaño del conjunto
Experimente con el número de árboles del bosque. A veces, aumentar el número de árboles puede mejorar el rendimiento de un conjunto.
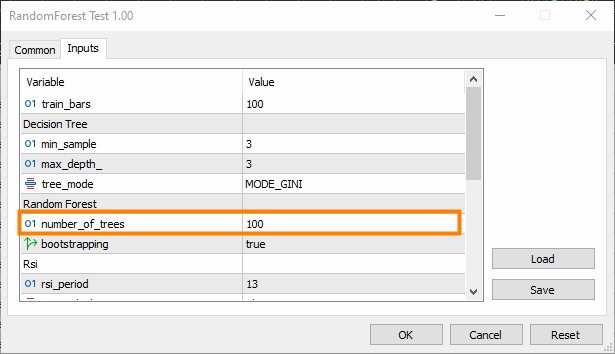
Sin embargo, al mismo tiempo añade complejidad: el tiempo de formación y pruebas puede aumentar drásticamente tras el cambio.
Calidad de los datos
Garantice la calidad de sus datos. Si existen valores atípicos o le faltan datos, esto puede afectar al rendimiento del bosque aleatorio.
Random Seed
Para garantizar la reproducibilidad, asegúrese de configurar correctamente el valor de Random Seed para cada ejecución.
Si se usa la misma semilla aleatoria, todos los árboles tendrán la misma precisión, lo cual no resultará mejor que un único árbol de decisión.
Prueba en el simulador de estrategias
El bosque aleatorio ha ganado en la fase de entrenamiento y prueba, pero ¿puede salir también vencedor en el comercio, donde se necesita algo más que capacidad de previsión para obtener beneficios?
Hemos realizado pruebas de ambos algoritmos con la configuración predeterminada desde el 2022.01.01 hasta el 2023.02.01.
Ajustes del simulador:
- Retrasos: Retraso arbitrario
- Modelado: Solo precios de apertura
- Depósito: 1000$
- Apalancamiento: 1/100
Gráfico de los resultados del bosque aleatorio:
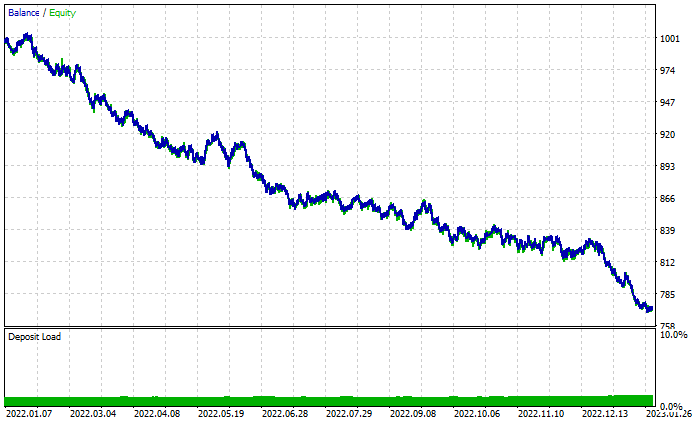
A pesar de tener un 46% de transacciones rentables, el gráfico tiene un aspecto terrible. Veamos qué hace el árbol de decisión:

Es mejor que un bosque aleatorio de 100 árboles a pesar del 44% de transacciones rentables.
Hemos hecho una optimización rápida para encontrar los mejores niveles de stop loss y take profit. El stop loss resultante es igual a 960, mientras que el take profit es igual a 1295 para ambos modelos, con el split mínimo fijado en 2. A continuación se resumen los resultados de ambos modelos.
Clasificador de árbol de decisión:
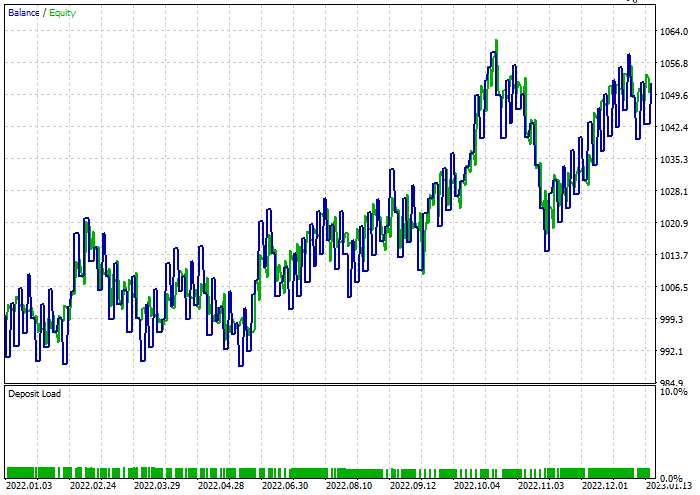
Durante las pruebas, el 47,68% de las transacciones han resultado rentables. Durante el periodo de prueba, el modelo ha obtenido 52 dólares de beneficio.
Clasificador de bosque aleatorio:

Reflexiones finales
Los bosques aleatorios se utilizan en diversos negocios e industrias, como las finanzas, el ocio y el sector médico. Sin embargo, como cualquier modelo, tienen algunos inconvenientes que debemos comprender antes de decidirnos a elegir este modelo para nuestro proyecto comercial.
Complejidad computacional:
Los modelos de bosque aleatorio, especialmente los que tienen un gran número de árboles, pueden resultar costosos desde el punto de vista informático y requerir recursos considerables.
Uso de memoria:
A medida que aumenta el número de árboles, también aumentará el volumen de memoria del modelo de bosque aleatorio, lo cual puede dar lugar a un mayor uso de memoria.
Interpretabilidad:
La naturaleza de conjunto de los bosques aleatorios los hace menos interpretables que los árboles de decisión individuales, sobre todo cuando el bosque está formado por varios árboles.
Sobreentrenamiento:
Aunque los bosques aleatorios son menos propensos al sobreentrenamiento que los árboles de decisión individuales, aún pueden sobreentrenarse con datos ruidosos o atípicos.
Tendencia a las clases dominantes:
En tareas de clasificación con distribuciones de clases desequilibradas, los bosques aleatorios pueden sesgarse hacia la clase dominante, lo cual afecta al rendimiento predictivo del modelo con respecto a las clases minoritarias.
Sensibilidad de los parámetros:
Aunque los bosques aleatorios son robustos ante la selección de hiperparámetros, el rendimiento del modelo puede seguir siendo sensible a valores específicos de los parámetros.
Caja negra:
La naturaleza de conjunto de los bosques aleatorios, que combinan múltiples árboles de decisión, puede dificultar la interpretación del proceso de toma de decisiones del modelo.
Tiempo de entrenamiento:
Entrenar un modelo de bosque aleatorio puede llevar más tiempo que entrenar un único árbol de decisión, especialmente si tenemos grandes conjuntos de datos.
La actividad comercial se retrasó 10 minutos porque tuvimos que esperar para formar 100 árboles.
Gracias por leernos.
Podrá seguir el desarrollo de este modelo de aprendizaje automático y mucho más en esta serie de artículos en mi repositorio en GitHub.
Contenidos del anexo:
| Archivo | Uso y descripción |
|---|---|
| Forest.mqh (ubicado en la carpeta include) | Contiene las clases de bosque aleatorio, CRandomForestClassifier y CRandomForestRegressor. |
| matrix_utils.mqh (Include) | Funciones adicionales para trabajar con matrices. |
| metrics.mqh (Include) | Funciones y código para medir el rendimiento de los modelos de aprendizaje automático. |
| preprocessing.mqh (Include) | Biblioteca para preprocesar datos de entrada brutos con el fin de adecuarlos para su uso en los modelos de aprendizaje automático. |
| tree.mqh (Include) | Contiene las clases del árbol de decisión. |
| RandomForest Test.mq5(Experts) | Asesor para ejecutar y probar modelos de bosque aleatorio. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13765
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso