
Машинное обучение и Data Science (Часть 17): Растут ли деньги на деревьях? Случайные леса в форекс-трейдинге

Две головы лучше, чем одна не потому, что любая из них непогрешима, а потому, что они вряд ли ошибутся в одном и том же направлении.
Алгоритм случайного леса
Случайный лес — это метод ансамблевого обучения, который строит множество деревьев решений во время обучения и выводит класс в режиме классификации или среднее предсказание в режиме регрессий. Каждое дерево в случайном лесу обучается на различном подмножестве данных, а случайность, добавленная во время обучения, помогает улучшить общие показатели модели и ее обощающие способности.
Для начала давайте разберемся с тем, что такое ансамблевое обучение.
Ансамблевое обучение
Ансамблевое обучение — это подход, при котором две или более модели машинного обучения подбираются к одним и тем же данным, а прогнозы каждой модели объединяются. Идея такого обучения в том, что ансамблевые модели показывают себя лучше, чем любая отдельная модель.
Случайный лес — это ансамблевый метод, который объединяет прогнозы нескольких деревьев решений, чтобы улучшить прогностические способности отдельной/единственной модели.

Чтобы продемонстрировать это, я построил дерево решений и случайный лес из десяти (10) деревьев. На одном и том же наборе данных я добился большей точности на этапах обучения и тестирования в варианте с использованием случайного леса.
Ключевые особенности случайного леса
01: Ансамблевое обучение
Случайный лес — это ансамблевый метод, который объединяет прогнозы нескольких моделей для получения улучшенного результата.
for (uint i=0; i<m_ntrees; i++) //Build a given x number of trees { temp_data = data; matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets forest[i] = new CDecisionTreeClassifier(this.m_minsplit, this.m_maxdepth); //Add the tree to the forest forest[i].fit(x_subset, y_subset); //Add the trained tree to the forest preds = forest[i].predict(x_subset); }
02: Бутстрэппинг — начальная агрегация (пакетирование)
Бутстрэппинг в машинном обучении — это метод повторной выборки, который включает в себя многократное получение выборок из исходных данных с заменой, часто для оценки параметра совокупности.
Каждое дерево в случайном лесу обучается на различном подмножестве данных, созданном посредством бутстрэппинга (выборки с заменой).
matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets
Код:
template<typename T> void CMatrixutils::Randomize(matrix<T> &matrix_,int random_state=-1, bool replace=false)
Параметр replace = true позволяет выбирать один и тот же индекс более одного раза, имитирую процесс бутстрэппинга.
03: Случайность признаков
При разделении узлов при построении каждого дерева учитываются случайные подмножества признаков.
Это вносит дополнительное разнообразие среди деревьев, делая ансамбль более прочным.
04: Механизм голосования (или усреднения)
Для задач классификации используется режим прогнозов (наиболее частый класс).
В задачах регрессии рассматривается среднее значение прогнозов.
В классификации случайных лесов используется процесс голосования. Есть разные техники, которые можно использовать в качестве механизма голосования, например, мягкое голосование или порог:
Мягкое голосование
Прогноз каждого дерева связан с определенным показателем уверенности (вероятностью) при мягком голосовании. Окончательный прогноз представляет собой средневзвешенное значение этих вероятностей.
Поскольку наш класс дерева решений пока не может предсказывать вероятности, мы не можем использовать этот механизм голосования. Будем использовать пользовательское голосование.
Порог голосования
Механизм голосования выглядит следующим образом: если определенный процент деревьев предсказывает определенный класс, это считается окончательным прогнозом. Это обеспечит минимальный уровень доверия.
Использование процента деревьев для определения того, какой класс прогнозировать, может оказаться сложным для предсказания множества классов. Поэтому настроим функцию для выбора класса, который предсказало большинство деревьев, независимо от того, сколько классов было предсказано.
double CRandomForestClassifier::predict(vector &x) { vector predictions(m_ntrees); //predictions from all the trees for (uint i=0; i<this.m_ntrees; i++) //all trees make the predictions predictions[i] = forest[i].predict(x); vector uniques = matrix_utils.Unique(predictions); return uniques[matrix_utils.Unique_count(predictions).ArgMax()]; //select the majority decision }
Расширение класса дерева решений
В предыдущей статье мы обсуждали классификацию по деревьям решений, которая подходит для классификации двоичных целевых переменных. Пришлось расширить классы и код для деревьев решений для задач регрессии.
class CDecisionTreeRegressor: public CDecisionTreeClassifier { private: double calculate_leaf_value(vector &Y); split_info get_best_split(matrix &data, uint num_features); double variance_reduction(vector &parent, vector &l_child, vector &r_child); Node *build_tree(matrix &data, uint curr_depth = 0); public: CDecisionTreeRegressor(uint min_samples_split = 2, uint max_depth = 2); ~CDecisionTreeRegressor(void); void fit(matrix &x, vector &y); };
В большинстве случаев эти два класса похожи, они используют один и тот же класс узла и множество функций, за исключением функций расчета стоимости листа, прироста информации, построения дерева и обучения.
Значения листьев в деревьях решений для задач регрессии
В задачах регрессии значение листа данного узла является средним значением всех его значений.
double CDecisionTreeRegressor::calculate_leaf_value(vector &Y) { return Y.Mean();
Расчет прироста информации
В прошлой статье мы уже говорили, что критерий прироста информации измеряет снижение энтропии или неопределенности после разделения набора данных.
Вместо использования Джини и энтропии, которые основаны на вероятности, мы используем формулу уменьшения дисперсии для измерения примесей в данном узле.
double CDecisionTreeRegressor::variance_reduction(vector &parent, vector &l_child, vector &r_child) { double weight_l = l_child.Size() / (double)parent.Size(), weight_r = r_child.Size() / (double)parent.Size(); return parent.Var() - ((weight_l * l_child.Var()) + (weight_r * r_child.Var())); }
Функция выше вычисляет уменьшение дисперсии, достигаемое путем разделения набора данных на левый и правый дочерние узлы в определенном узле дерева решений.
Построение дерева и функция обучения
Построение дерева
Node *CDecisionTreeRegressor::build_tree(matrix &data, uint curr_depth=0) { matrix X; vector Y; if (!matrix_utils.XandYSplitMatrices(data,X,Y)) //Split the input matrix into feature matrix X and target vector Y. { #ifdef DEBUG_MODE printf("%s Line %d Failed to build a tree Data Empty",__FUNCTION__,__LINE__); #endif return NULL; //Return a NULL pointer } ulong samples = X.Rows(), features = X.Cols(); //Get the number of samples and features in the dataset. ArrayResize(nodes, nodes.Size()+1); //Append the nodes to memory Node *left_child, *right_child; if (samples >= m_min_samples_split && curr_depth<=m_max_depth) { split_info best_split = this.get_best_split(data, (uint)features); #ifdef DEBUG_MODE Print(__FUNCTION__," | ",__LINE__,"\nbest_split left: [",best_split.dataset_left.Rows(),"x",best_split.dataset_left.Cols(),"]\nbest_split right: [",best_split.dataset_right.Rows(),"x",best_split.dataset_right.Cols(),"]\nfeature_index: ",best_split.feature_index,"\nInfo gain: ",best_split.info_gain,"\nThreshold: ",best_split.threshold); #endif if (best_split.info_gain > 0) { left_child = this.build_tree(best_split.dataset_left, curr_depth+1); right_child = this.build_tree(best_split.dataset_right, curr_depth+1); nodes[nodes.Size()-1] = new Node(best_split.feature_index,best_split.threshold,left_child,right_child,best_split.info_gain); return nodes[nodes.Size()-1]; } } nodes[nodes.Size()-1] = new Node(); nodes[nodes.Size()-1].leaf_value = this.calculate_leaf_value(Y); return nodes[nodes.Size()-1]; }
Функция Fit
void CDecisionTreeRegressor::fit(matrix &x, vector &y) { matrix data = matrix_utils.concatenate(x, y, 1); this.root = this.build_tree(data); is_fitted = true; }
Единственное отличие между функцией build_tree класса Reressor и класса Classifier является функция variance_reduction.
Для тестирования регрессии я использовал готовые дынные из набора Airfoil noise data.
matrix data = matrix_utils.ReadCsv("airfoil_noise_data.csv"); matrix x; vector y; if (!matrix_utils.XandYSplitMatrices(data, x, y)) return INIT_FAILED; regressor_tree = new CDecisionTreeRegressor(3,3); regressor_tree.fit(x, y); regressor_tree.print_tree(regressor_tree.root); vector preds = regressor_tree.predict(x); Print("r-squared: ",metrics.r_squared(y, preds));
Результат
KS 0 00:04:11.402 RandomForest Test (EURUSD,H1) : X_0<=3150.0?7.6482714516406745 FI 0 00:04:11.402 RandomForest Test (EURUSD,H1) ---> left: X_4<=0.0150478?4.070223732531591 ME 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> left: X_2<=0.1016?2.453283788183441 RR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=630.0?2.3366165961173238 JR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 126.94465000000002 MF 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 130.51523904382472 II 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_0<=1600.0?4.999630155449349 HF 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 127.90983653846149 JM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 122.97036507936505 JR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> right: X_4<=0.0483159?6.040280153408631 FI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=1250.0?5.315257051142112 IG 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 125.68045918367342 GM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 120.69493181818189 NQ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_0<=1250.0?13.291165881821172 GK 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 117.69977777777775 GH 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 109.80075000000001 EL 0 00:04:11.402 RandomForest Test (EURUSD,H1) ---> right: X_4<=0.00152689?28.997059993530435 OL 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> left: X_0<=6300.0?11.053304033466667 HK 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_4<=0.000930789?9.067095683299033 FG 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 134.9866388888889 NO 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 128.59900000000002 QS 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_4<=0.000930789?9.783359845444707 NI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 128.05125581395347 GJ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 120.90806666666667 RM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> right: X_4<=0.0341183?5.715854852017056 LN 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=5000.0?5.190320913085316 GN 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 120.08625170068028 NE 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 115.52968965517242 MI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_4<=0.0483159?4.450134400476193 IS 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 109.44371428571428 GQ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 104.84033333333332 PH 0 00:04:11.403 RandomForest Test (EURUSD,H1) r-squared: 0.5937442611327515
Кажется, что дерево регрессии имеет больше ветвей при одних и тех же параметрах.
Точность нашей регрессионной модели во время обучения составила 59%. Это хороший признак того, что мы все поняли верно. Вот как выглядят прогнозы, нанесенные на график:

То, как прогнозы соответствуют фактическим значениям, выглядит почти как дерево.
Преимущества случайных лесов
Высокая точность — случайные леса часто дают повышенную точность как в задачах классификации, так и в задачах регрессии.
Устойчивость — ансамблевая природа Random Forest делает его устойчивым к переобучению и зашумленным данным.
Важность признаков — случайные леса могут давать информацию о важности признаков, помогая в выборе таких признаков.
Уменьшенная дисперсия — разнообразие деревьев сводит к минимуму дисперсию модели, что приводит к лучшей способности к обобщению.
Нет необходимости масштабировать функции — как и дерево решений, случайные леса менее чувствительны к масштабированию объектов, что делает их подходящими для выборок с разными масштабами данных.
Универсальность — подходят для различных типов данных, включая категориальные и числовые характеристики.
Построение классификатора случайного леса
Мы изучили преимущества алгоритма случайного леса по сравнению с деревом решений. Теперь давайте посмотрим, как построить модель случайного леса, начиная с классификатора.
Включаем класс CDecisionTreeClassifier.
class CRandomForestClassifier { CMetrics metrics; protected: uint m_ntrees; uint m_maxdepth; uint m_minsplit; int m_random_state; CMatrixutils matrix_utils; CDecisionTreeClassifier *forest[]; string ConvertTime(double seconds); public: CRandomForestClassifier(uint n_trees=100, uint minsplit=NULL, uint max_depth=NULL, int random_state=-1); ~CRandomForestClassifier(void); void fit(matrix &x, vector &y, bool replace=true); double predict(vector &x); vector predict(matrix &x); };
Поскольку классификатор случайного леса представляет собой просто x деревьев-классификаторов, объединенных в один лес, в класс подается массив forest[] из объектов CDecisionTreeClassifier.
n_trees = 100 (по умолчанию), что означает, что в лесу классификатора случайного леса будут 100 деревьев.
min_split и max_depth — это параметры для каждого дерева, о которых мы говорили в прошлой статье. min_split — минимальное количество ветвей, которое должно иметь дерево, а max_depth это то, какой длины должно быть дерево с точки зрения этих ветвей.
Встраивание деревьев в случайный лес
Это самая важная функция класса CRandomForestClassifier, где лес включает n_trees деревьев, выбранных в конструкторе класса.
void CRandomForestClassifier::fit(matrix &x, vector &y, bool replace=true) { matrix x_subset; vector y_subset; matrix data = this.matrix_utils.concatenate(x, y, 1); matrix temp_data = data; vector preds; datetime time_start = GetTickCount(), current_time; Print("[ Classifier Random Forest Building ]"); for (uint i=0; i<m_ntrees; i++) //Build a given x number of trees { time_start = GetTickCount(); temp_data = data; matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets if (!this.matrix_utils.XandYSplitMatrices(temp_data, x_subset, y_subset)) //split the random subset into x and y subsets { ArrayRemove(forest,i,1); //Delete the invalid tree in a forest printf("%s %d Failed to split data for a tree ",__FUNCTION__,__LINE__); continue; } forest[i] = new CDecisionTreeClassifier(this.m_minsplit, this.m_maxdepth); //Add the tree to the forest forest[i].fit(x_subset, y_subset); //Add the trained tree to the forest preds = forest[i].predict(x_subset); current_time = GetTickCount(); printf(" ==> Tree <%d> Rand Seed <%s> Accuracy Score: %.3f Time taken: %s",i+1,m_random_state==-1?"None":string(m_random_state),metrics.accuracy_score(y_subset, preds), ConvertTime((current_time - time_start) / 1000.0)); } m_ntrees = ArraySize(forest); //The successfully build trees }
Сравниваем Классификатор дерева решений и Классификатор случайного леса
Чтобы доказать, что случайные классификаторы справляются с задачами классификации лучше, чем деревья решений, я провел 5 тестов.
Тест 01:
| Обучение | Тестирование | |
|---|---|---|
| Древо решений | 73.8% | 40% |
| Случайный лес | 78% | 45% |
Тест 02:
| Древо решений | 73.8% | 40% |
| Случайный лес | 83% | 45% |
Тест 03:
| Древо решений | 73.8% | 40% |
| Случайный лес | 80% | 45% |
Тест 04:
| Древо решений | 73.8% | 40% |
| Случайный лес | 78.8% | 45% |
Тест 05:
| Древо решений | 73.8% | 40% |
| Случайный лес | 78.8% | 45% |
В моем опыте оказалось, что использование классификатора случайного леса для торговых данных может привести к путанице, поскольку можно столкнуться с ситуациями, когда общая точность случайного леса не превышает точность одного дерева решений. Это происходит из-за одного или нескольких из следующих факторов.
Почему случайный лес не дает большей точности, чем одно дерево решений:
Отсутствие разнообразия деревьев
Случайные леса извлекают выгоду из разнообразия отдельных деревьев. Если все деревья одинаковы, ансамбль не принесет значимого улучшения.
Убедитесь, что вы правильно вводите случайность во время обучения каждого дерева. Рандомизация может включать выбор случайных подмножеств признаков и/или использование разных подмножеств обучающих данных.
Настройка гиперпараметров
Поэкспериментируйте с различными гиперпараметрами, такими как количество объектов, которые следует учитывать для каждого разделения (m_max_features), минимальное количество выборок для разделения внутреннего узла (m_minsplit) и максимальная глубина деревьев (m_maxdepth).
Поиск по сетке или случайный поиск по диапазону значений гиперпараметров может помочь найти лучшие конфигурации.
Кросс-валидация
Используйте кросс-валидацию, чтобы оценить работу модели. Это помогает более надежно оценить то, насколько хорошо модель обобщается на новых данных.
Кросс-валидация также помогает обнаруживать проблемы переобучения или недообучения.
Обучение по всему набору данных
Убедитесь, что деревья не подгоняются под обучающие данные. Если каждое дерево в лесу обучено на всем наборе данных, оно может улавливать шум, а не сигнал.
Возможно, каждое дерево стоит обучить на пакетированных данных (бутсрэппинг).
Масштабирование признаков
Если ваши признаки имеют разные масштабы, возможно, будет полезно их масштабировать. Деревья решений, как правило, не чувствительны к масштабам признаков. Помочь может нормализация или стандартизация признаков, особенно если вы сравниваете производительность одного дерева с ансамблем.
Метрика оценки
Убедитесь, что используете соответствующую метрику оценки для проблемы, которую вы пытаетесь решить с помощью своих моделей. Общим показателем оценки регрессии является R-квадрат, а общим показателем оценки классификации является показатель точности.
Последний аргумент функции fit() — error. Позволяет выбрать подходящую метрику для измерения точности каждого дерева в лесу.
enum errors_classifier { ERR_ACCURACY }; enum errors_regressor { ERR_R2_SCORE, ERR_ADJUSTED_R };
Размер ансамбля
Поэкспериментируйте с количеством деревьев в лесу. Иногда увеличение количества деревьев может улучшить производительность ансамбля.
Но при вместе с тем это добавляет сложности — время обучения и тестирования может резко увеличиться после изменения.
Качество данных
Обеспечьте качество ваших данных. Если есть выбросы или пропущенные значения, это может повлиять на работу случайного леса.
Random Seed
Для обеспечения воспроизводимости убедитесь, что правильно устанавливаете значение Random Seed для каждого запуска.
Использование одного и того же случайного начального числа (Random seed) приведет к тому, что все деревья будут давать одинаковую точность, что будет не лучше, чем у одного дерева решений.
Проверка в тестере стратегий
Случайный лес победил на этапе обучения и тестирования, но сможет ли он также стать победителем в трейдинге, где для получения прибыли требуется нечто большее, чем умение прогнозировать?
Я провел тесты обоих алгоритмов с настройками по умолчанию с 2022.01.01 по 2023.02.01.
Настройки тестера:
- Задержки: Произвольная задержка
- Моделирование: Только цены открытия
- Депозит: 1000$
- Кредитное плечо: 1/100
График результатов случайного леса:
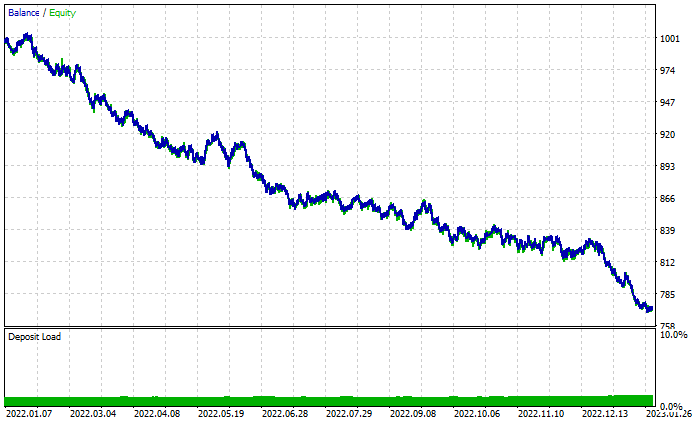
Несмотря на наличие 46% прибыльных сделок, график выглядит ужасно. Давайте посмотрим, что делает Древо решений:

Лучше, чем случайный лес из 100 деревьев, несмотря на 44% прибыльных сделок.
Я провел быструю оптимизацию для поиска лучших уровней стоп-лосса и тейк-профита. Получилось стоп-лосс = 960 и тейк-профита = 1295 для обеих моделей, при этом минимальный сплит был установлен равным 2. Ниже приведены результаты обеих моделей.
Классификатор дерева решений:
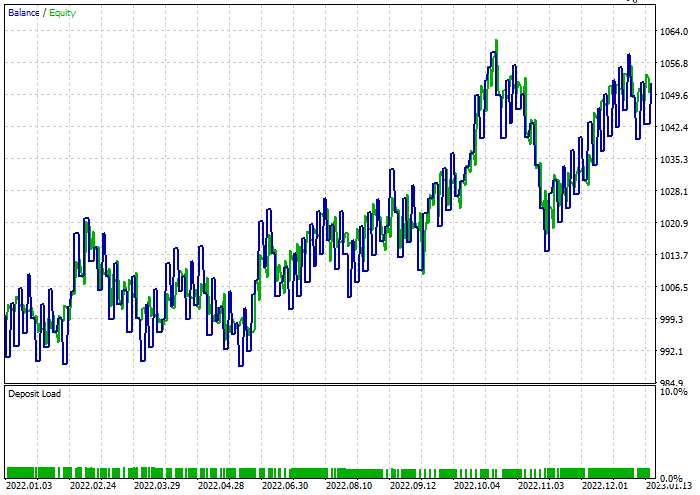
При тестировании 47,68% сделок оказались прибыльными. За время тестирования модель заработала 52 доллара прибыли.
Классификатор случайного леса:

Заключительные мысли
Случайные леса используются в различных сферах деятельности и отраслях, включая финансы, развлечения и медицинский сектор. Однако, как и у любой модели, у них есть некоторые недостатки, которые следует понимать, прежде чем принимать решение о выборе этой модели для своего торгового проекта.
Вычислительная сложность:
Модели случайного леса, особенно с большим количеством деревьев, могут быть дорогостоящими в вычислительном отношении и требовать значительных ресурсов.
Использование памяти:
По мере увеличения количества деревьев объем памяти модели случайного леса также увеличивается, что потенциально может привести к более высокому использованию памяти.
Интерпретируемость:
Ансамбльный характер случайных лесов делает их менее интерпретируемыми, чем отдельные деревья решений, особенно когда лес состоит из множества деревьев.
Переобучение:
Хотя случайные леса менее склонны к переобучению, чем отдельные деревья решений, они все равно могут переобучиться на зашумленных данных или данных с выбросами.
Склонность к доминирующим классам:
В задачах классификации с несбалансированным распределением классов случайные леса могут быть смещены в сторону доминирующего класса, что влияет на прогнозирующую эффективность модели в отношении классов меньшинства.
Чувствительность к параметрам:
Хотя случайные леса устойчивы к выбору гиперпараметров, работа модели по-прежнему может быть чувствительной к конкретным значениям параметров.
Черный ящик:
Ансамбльный характер случайных лесов, который объединяет несколько деревьев решений, может затруднить интерпретацию процесса принятия решений модели.
Время обучения:
Обучение модели случайного леса может занять больше времени, чем обучение одного дерева решений, особенно для больших наборов данных.
Торговая активность задержалась на 10 минут, так как пришлось ждать, чтобы обучить 100 деревьев.
Спасибо за прочтение.
За развитием этой модели машинного обучения и многого другого из этой серии статей можно следить в моем репозиторий на GitHub.
Содержимое вложения:
| Файл | Использование и описание |
|---|---|
| Forest.mqh (находится в папке include) | Содержит случайные классы леса, CRandomForestClassifier и CRandomForestRegressor. |
| matrix_utils.mqh (Include) | Дополнительные функции для работы с матрицами. |
| metrics.mqh (Include) | Функции и код для измерения производительности моделей машинного обучения. |
| preprocessing.mqh (Include) | Библиотека для предварительной обработки необработанных входных данных, чтобы сделать их пригодными для использования в моделях машинного обучения. |
| tree.mqh (Include) | Содержит классы дерева решений. |
| RandomForest Test.mq5(Experts) | Советник для запуска и тестирования моделей случайного леса. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/13765
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Очень познавательно и интересно