
Developing an MQL5 RL agent with RestAPI integration (Part 4): Organizing functions in classes in MQL5

Introduction
Welcome to the fourth part of our series in which we explore creating a reinforcement learning agent in MQL5 with RestAPI integration. Before today's article, we looked at such important aspects as using RestAPI in MQL5, creating MQL5 functions for interacting with the REST API in tic-tac-toe, as well as executing automatic moves and test scripts. This gave us a solid foundation and helped us understand how MQL5 interacts with external elements.
In this article, we will take an important step and organize our functions into classes in MQL5. To do this, we will use object-oriented programming (OOP). OOP is a way of writing code that helps keep it organized and easy to understand. This is important because it makes it easier for us to maintain and improve the code. Its code is well organized and is modular, we can use it in different parts of the project or even in future projects.
Also, in this article, we will see how to restructure existing MQL5 functions into classes. We will see how this can make code more readable and efficient. Also, the article contains practical examples of how to do this, showing how the application of the presented ideas can make code easier to maintain and improve.
Object-oriented programming (OOP) is a powerful way of developing software. In MQL5, the use of classes is a great advantage over the procedural code writing method. In this part, we will look at how to improve the quality of our project using this characteristic. Let's look at four important aspects:
-
Encapsulation and modularity: Classes help organize related functions and variables in one place, making them easier to maintain and reducing errors.
-
Code reuse: Once you write a class, you can use it in different places, saving time and maintaining code consistency.
-
Ease of maintenance and improvement: When functions are separated into classes, it is easier to find and fix bugs or make improvements because the clear structure makes the code more accessible.
-
Abstraction and flexibility: Classes promote abstraction by hiding complexity and revealing only what we need. This makes the code more intuitive and flexible.
We will see that rearranging functions into classes in MQL5 is not just for the sake of beauty, it is a significant change that makes the code more efficient, easier to understand and maintain. The article will show how to transform isolated functions into well-defined class methods, which will provide both immediate and long-term benefits. This will not only improve our current project but will also help us create a solid foundation for future MQL5 projects.
Current code state
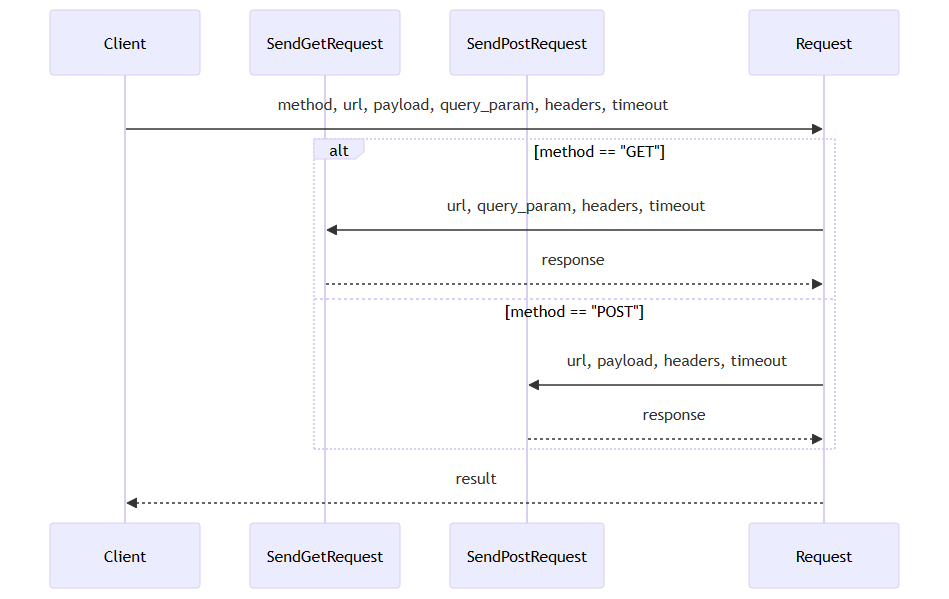
In its current state, our code consists of a number of functions to handle HTTP requests, such as SendGetRequest, SendPostRequest and Request. These functions are responsible for sending GET and POST requests to the API, processing responses and eliminating possible errors.
//+------------------------------------------------------------------+ //| Request.mqh | //| Copyright 2023, Lejjo Digital | //| https://www.mql5.com/en/users/14134597 | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Lejjo Digital" #property link "https://www.mql5.com/en/users/14134597" #property version "1.00" #define ERR_HTTP_ERROR_FIRST ERR_USER_ERROR_FIRST+1000 //+511 //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int SendGetRequest(const string url, const string query_param, string &out, string headers = "", const int timeout = 5000, bool debug=false) { char data[]; uchar result[]; string result_headers; int res = -1; int data_size = StringLen(query_param); if(data_size > 0) { StringToCharArray(query_param, data, 0, data_size); res = WebRequest("GET", url + "?" + query_param, NULL, NULL, timeout, data, data_size, result, result_headers); } else { res = WebRequest("GET", url, headers, timeout, data, result, result_headers); } if(res >= 200 && res <= 204) // OK { //--- delete BOM int start_index = 0; int size = ArraySize(result); for(int i = 0; i < fmin(size, 8); i++) { if(result[i] == 0xef || result[i] == 0xbb || result[i] == 0xbf) start_index = i + 1; else break; } out = CharArrayToString(result, start_index, WHOLE_ARRAY, CP_UTF8); if(debug) Print(out); return res; } else { if(res == -1) { return (_LastError); } else { //--- HTTP errors if(res >= 100 && res <= 511) { out = CharArrayToString(result, 0, WHOLE_ARRAY, CP_UTF8); if(debug) Print(out); return res; } return (res); } } return (0); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int SendPostRequest(const string url, const string payload, string &out, string headers = "", const int timeout = 5000, bool debug=false) { char data[]; uchar result[]; string result_headers; int res = -1; ArrayResize(data, StringToCharArray(payload, data, 0, WHOLE_ARRAY) - 1); if(headers == "") { headers = "Content-Type: application/json\r\n"; } res = WebRequest("POST", url, headers, timeout, data, result, result_headers); if(res >= 200 && res <= 204) // OK { //--- delete BOM int start_index = 0; int size = ArraySize(result); for(int i = 0; i < fmin(size, 8); i++) { if(result[i] == 0xef || result[i] == 0xbb || result[i] == 0xbf) start_index = i + 1; else break; } out = CharArrayToString(result, start_index, WHOLE_ARRAY, CP_UTF8); if(debug) Print(out); return res; } else { if(res == -1) { return (_LastError); } else { //--- HTTP errors if(res >= 100 && res <= 511) { out = CharArrayToString(result, 0, WHOLE_ARRAY, CP_UTF8); if(debug) Print(out); return res; } return (res); } } return res; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int Request(string method, string &out, const string url, const string payload = "", const string query_param = "", string headers = "", const int timeout = 5000) { ResetLastError(); if(method == "GET") { return SendGetRequest(url, query_param, out, headers, timeout); } else if(method == "POST") { return SendPostRequest(url, payload, out, headers, timeout); } return -1; } //+------------------------------------------------------------------+
Challenges and problems of this approach:
-
Lack of encapsulation and modularity: Currently, functions are isolated, and there is no clear mechanism for grouping them by functionality or purpose. This makes the logic flow difficult to maintain and understand.
-
Limited code reuse: Because features are specific and not organized in a modular structure, code reuse across different contexts or projects will be limited, which can lead to code duplication. This, in turn, increases the risk of inconsistencies and errors.
-
Complex maintenance and extensibility: Without a clear separation of responsibilities, identifying and fixing errors, as well as adding new functionality becomes a complex task. This becomes especially problematic for projects that are expanding or require constant updating.
Examples of current function organization:
In their current state, functions are performed according to a procedural scheme. For example, the SendGetRequest function takes URL parameters, request parameters and others, and returns the result using the WebRequest response as a basis. Similarly, SendPostRequest handles POST requests. The Request functions serve to facilitate GET and POST function calls, depending on the HTTP method we specify.
The SendGetRequest function:
int SendGetRequest(const string url, const string query_param, string &out, string headers = "", const int timeout = 5000, bool debug=false) { char data[]; uchar result[]; string result_headers; int res = -1; int data_size = StringLen(query_param); if(data_size > 0) { StringToCharArray(query_param, data, 0, data_size); res = WebRequest("GET", url + "?" + query_param, NULL, NULL, timeout, data, data_size, result, result_headers); } else { res = WebRequest("GET", url, headers, timeout, data, result, result_headers); } if(res >= 200 && res <= 204) // OK { //--- delete BOM int start_index = 0; int size = ArraySize(result); for(int i = 0; i < fmin(size, 8); i++) { if(result[i] == 0xef || result[i] == 0xbb || result[i] == 0xbf) start_index = i + 1; else break; } out = CharArrayToString(result, start_index, WHOLE_ARRAY, CP_UTF8); if(debug) Print(out); return res; } else { if(res == -1) { return (_LastError); } else { //--- HTTP errors if(res >= 100 && res <= 511) { out = CharArrayToString(result, 0, WHOLE_ARRAY, CP_UTF8); if(debug) Print(out); return res; } return (res); } } return (0); }
The SendPostRequest function:
int SendPostRequest(const string url, const string payload, string &out, string headers = "", const int timeout = 5000, bool debug=false) { char data[]; uchar result[]; string result_headers; int res = -1; ArrayResize(data, StringToCharArray(payload, data, 0, WHOLE_ARRAY) - 1); if(headers == "") { headers = "Content-Type: application/json\r\n"; } res = WebRequest("POST", url, headers, timeout, data, result, result_headers); if(res >= 200 && res <= 204) // OK { //--- delete BOM int start_index = 0; int size = ArraySize(result); for(int i = 0; i < fmin(size, 8); i++) { if(result[i] == 0xef || result[i] == 0xbb || result[i] == 0xbf) start_index = i + 1; else break; } out = CharArrayToString(result, start_index, WHOLE_ARRAY, CP_UTF8); if(debug) Print(out); return res; } else { if(res == -1) { return (_LastError); } else { //--- HTTP errors if(res >= 100 && res <= 511) { out = CharArrayToString(result, 0, WHOLE_ARRAY, CP_UTF8); if(debug) Print(out); return res; } return (res); } } return res; }
Note that the functions contain several repeating elements, which makes it difficult, for example, to handle responses to different errors, since they can be applied in one part and ignored in another, or similar situations.
This approach, although functional, does not take advantage of the benefits of object orientation, such as encapsulation and modularity. Each function operates relatively independently, without a single structure that links them or controls their behavior in a consistent manner.
Importance of OOP
OOP is a programming paradigm that uses "objects" as fundamental building blocks. These objects are data structures consisting of data fields and procedures called methods that represent real-world entities or concepts. In OOP, each object has the ability to receive and send messages and process data, while acting as an autonomous unit with specific functions or responsibilities within the software system.
Advantages of OOP in maintaining and scaling projects:
-
Easier Maintenance: OOP makes software easier to maintain due to its modular design. Each object is an independent unit with its own logic and data, which means that changes to a particular object generally do not affect other objects. This feature makes the process of updating, fixing bugs and improving the system much more manageable.
-
Improved scalability: OOP allows developers to create systems that can easily scale in size and complexity. Adding new functionality becomes more efficient because new objects can be created with specific functionality without the need for extensive modification of existing code.
-
Code reuse: Inheritance, one of the core principles of OOP, allows developers to create new classes based on existing ones. This promotes code reuse, reduces redundancy, and makes maintenance easier.
How does modularity help improve our code?
Modularity is one of the main advantages of OOP. It provides developers with the following features:
-
Breaking down complex systems: Using OOP, a complex system can be broken down into smaller, manageable components (objects), each with clearly defined responsibilities. This makes the system easier to understand, develop, and maintain.
-
Focus on abstraction: Modularity allows developers to focus on abstraction, working on high-level concepts rather than low-level details, making complex problems easier to solve and code cleaner.
-
Encouraging flexibility and extensibility: Objects and classes can be designed to be flexible and extensible to allow the system to evolve and adapt over time without the need for a complete rewrite.
-
Encouraging collaboration: In a collaborative development environment, different teams or developers can work on different modules or objects at the same time, increasing efficiency and reducing development time.
The use of OOP in our project with RestAPI integration provides a robust approach to managing software complexity, which greatly improves maintainability, scalability, and overall code quality.
Refactoring functions in classes
Now that we understand the importance of OOP and how it can improve the maintainability and scalability of our projects, I propose to refactor existing functions into classes. To better illustrate this process, we'll provide a diagram that shows how the new object-oriented code will be more organized and understandable. We will follow a step-by-step process to transform our procedural code into more organized and understandable object-oriented code.
Implementation
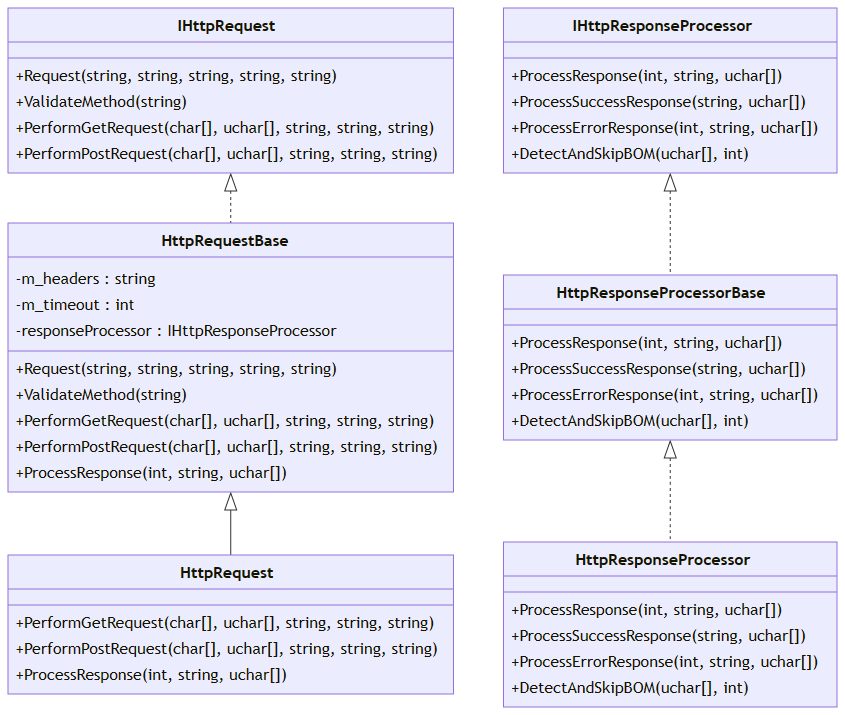
Step 1. Defining interfaces. Let's start by defining interfaces for our objects, which will describe the methods and functionality they should have. We have two: IHttpRequest and IHttpResponseProcessor. These interfaces define the contracts that our concrete classes must follow.
//+------------------------------------------------------------------+ //| Interface for HttpRequest | //+------------------------------------------------------------------+ interface IHttpRequest { public: virtual int Request(string method, string &out, const string url, const string payload = "", const string query_param = "") = 0; virtual int ValidateMethod(string method) = 0; virtual int PerformGetRequest(char &data[], uchar &result[], string &result_headers, const string url, const string query_param) = 0; virtual int PerformPostRequest(char &data[], uchar &result[], string &result_headers, const string url, const string payload) = 0; }; //+------------------------------------------------------------------+ //| Interface for HttpResponseProcessor | //+------------------------------------------------------------------+ interface IHttpResponseProcessor { public: virtual int ProcessResponse(int res, string &out, uchar &result[]) = 0; virtual int ProcessSuccessResponse(string &out, uchar &result[]) = 0; virtual int ProcessErrorResponse(int res, string &out, uchar &result[]) = 0; virtual int DetectAndSkipBOM(uchar &result[], int size) = 0; };
Step 2. Create abstract classes. We create abstract classes that implement these interfaces. These classes do not have actual implementation of methods but define the relevant structures. The abstract classes are HttpResponseProcessorBase and HttpRequestBase.
//+------------------------------------------------------------------+ //| Abstract base class for HttpResponseProcessor | //+------------------------------------------------------------------+ class HttpResponseProcessorBase : public IHttpResponseProcessor { public: HttpResponseProcessorBase() {} virtual int ProcessResponse(int res, string &out, uchar &result[]) override = 0; virtual int ProcessSuccessResponse(string &out, uchar &result[]) override = 0; virtual int ProcessErrorResponse(int res, string &out, uchar &result[]) override = 0; virtual int DetectAndSkipBOM(uchar &result[], int size) override = 0; }; //+------------------------------------------------------------------+ //| Abstract base class for HttpRequest | //+------------------------------------------------------------------+ class HttpRequestBase : public IHttpRequest { protected: string m_headers; int m_timeout; IHttpResponseProcessor *responseProcessor; public: HttpRequestBase(string headers = "", int timeout = 5000) : m_headers(headers), m_timeout(timeout) { if (responseProcessor == NULL) { responseProcessor = new HttpResponseProcessor(); } } virtual int Request(string method, string &out, const string url, const string payload = "", const string query_param = "") override; virtual int ValidateMethod(string method) override; virtual int PerformGetRequest(char &data[], uchar &result[], string &result_headers, const string url, const string query_param) override = 0; virtual int PerformPostRequest(char &data[], uchar &result[], string &result_headers, const string url, const string payload) override = 0; virtual int ProcessResponse(int res, string &out, uchar &result[]) = 0; };
The HttpRequestBase class:
-
HttpRequestBase(string headers = "", int timeout = 5000): This is the constructor for the HttpRequestBase class. It takes two optional parameters, headers and timeout, which specify the HTTP headers to send in requests and the timeout for the response, respectively. The constructor initializes the given values and creates an instance of the HttpResponseProcessor class (the class that handles HTTP responses).
-
virtual int Request(string method, string &out, const string url, const string payload = "", const string query_param = ""): This virtual method allows you to make an HTTP request. Takes the HTTP method (GET or POST), destination URL, possible request body (payload) and request parameters (query_param). Coordinates PerformGetRequest or PerformPostRequest function calls based on the specified method and then processes the response by using the ProcessResponse method.
-
virtual int ValidateMethod(string method): This method checks the validity of the specified HTTP method (GET or POST). Returns true if it is valid and false otherwise.
-
virtual int PerformGetRequest(char &data[], uchar &result[], string &result_headers, const string url, const string query_param): This abstract virtual method must be implemented by derived classes. Performs an HTTP GET request to the specified URL and returns the response data in the data parameter, result in the result parameter and response headers in result_headers.
-
virtual int PerformPostRequest(char &data[], uchar &result[], string &result_headers, const string url, const string payload): This abstract virtual method must be implemented by derived classes. Performs an HTTP POST request to the specified URL with a request body (payload) and returns the response data in the data parameter, result in the result parameter and response headers in result_headers.
-
virtual int ProcessResponse(int res, string &out, uchar &result[]): This abstract virtual method must be implemented by derived classes. It processes the HTTP response based on the 'res' response code. If the response is successful (response code is in the range from 200 to 299), ProcessSuccessResponse is called. Otherwise ProcessErrorResponse is called. The result is stored in out, and the raw response data is in result.
Step 3. Creating concrete classes. Let's create concrete classes that implement interface methods. HttpRequest and HttpResponseProcessor are concrete classes.
//+------------------------------------------------------------------+ //| Concrete class for HttpRequest | //+------------------------------------------------------------------+ class HttpRequest : public HttpRequestBase { public: HttpRequest(string headers = "", int timeout = 5000) : HttpRequestBase(headers, timeout) {} virtual int PerformGetRequest(char &data[], uchar &result[], string &result_headers, const string url, const string query_param) override; virtual int PerformPostRequest(char &data[], uchar &result[], string &result_headers, const string url, const string payload) override; virtual int ProcessResponse(int res, string &out, uchar &result[]) override; }; //+------------------------------------------------------------------+ //| Concrete class for HttpResponseProcessor | //+------------------------------------------------------------------+ class HttpResponseProcessor : public HttpResponseProcessorBase { public: virtual int ProcessResponse(int res, string &out, uchar &result[]) override; virtual int ProcessSuccessResponse(string &out, uchar &result[]) override; virtual int ProcessErrorResponse(int res, string &out, uchar &result[]) override; virtual int DetectAndSkipBOM(uchar &result[], int size) override; };
Step 4. Implementing methods of concrete classes. Let's implement concrete class methods with real functionality. Here we have methods PerformGetRequest, PerformPostRequest, ProcessResponse, ProcessSuccessResponse, ProcessErrorResponse and DetectAndSkipBOM.
int HttpRequest::PerformGetRequest(char &data[], uchar &result[], string &result_headers, const string url, const string query_param) { if (StringLen(query_param) > 0) return WebRequest("GET", url + "?" + query_param, NULL, NULL, m_timeout, data, StringLen(query_param), result, result_headers); return WebRequest("GET", url, m_headers, m_timeout, data, result, result_headers); } int HttpRequest::PerformPostRequest(char &data[], uchar &result[], string &result_headers, const string url, const string payload) { if (m_headers == "") m_headers = "Content-Type: application/json\r\n"; ArrayResize(data, StringToCharArray(payload, data, 0, WHOLE_ARRAY) - 1); return WebRequest("POST", url, m_headers, m_timeout, data, result, result_headers); } int HttpRequest::ProcessResponse(int res, string &out, uchar &result[]) { if (res >= 200 && res <= 299) return responseProcessor.ProcessSuccessResponse(out, result); return responseProcessor.ProcessErrorResponse(res, out, result); } int HttpResponseProcessor::ProcessResponse(int res, string &out, uchar &result[]) { if (res >= 200 && res <= 299) return ProcessSuccessResponse(out, result); return ProcessErrorResponse(res, out, result); } int HttpResponseProcessor::ProcessSuccessResponse(string &out, uchar &result[]) { int size = ArraySize(result); int start_index = DetectAndSkipBOM(result, size); out = CharArrayToString(result, start_index, WHOLE_ARRAY, CP_UTF8); return 0; } int HttpResponseProcessor::ProcessErrorResponse(int res, string &out, uchar &result[]) { ResetLastError(); if (res == -1) return GetLastError(); else if (res >= 100 && res <= 511) // Errors HTTP { out = CharArrayToString(result); Print(out); return res; } return res; } int HttpResponseProcessor::DetectAndSkipBOM(uchar &result[], int size) { int start_index = 0; for (int i = 0; i < MathMin(size, 3); i++) { if (result[i] == 0xef || result[i] == 0xbb || result[i] == 0xbf) start_index = i + 1; else break; } return start_index; }
HttpRequest class:
-
HttpRequest(string headers = "", int timeout = 5000): This is a constructor of the HttpRequest class. It calls the constructor of the base class HttpRequestBase in order to trigger header and timeout parameters.
-
virtual int PerformGetRequest(char &data[], uchar &result[], string &result_headers, const string url, const string query_param): This is an implementation of the PerformGetRequest method in the HttpRequest class. Performs an HTTP GET request to the specified URL, including request parameters, if any. Raw response data will be saved in data, results in result, and response headers in result_headers.
-
virtual int PerformPostRequest(char &data[], uchar &result[], string &result_headers, const string url, const string payload): This is an implementation of the PerformPostRequest method in the HttpRequest class. Performs an HTTP POST request to the specified URL, including the request body (payload). We save raw response data in data, results in result, and response headers in result_headers.
-
virtual int ProcessResponse(int res, string &out, uchar &result[]): An implementation of the ProcessResponse method in the HttpRequest class. Calls ProcessSuccessResponse in case of successful response (the response code is in the range between 200 and 299), otherwise ProcessErrorResponse. We will store the result in 'out', and the raw response data in 'result'.
Benefits of refactoring:
Refactoring our project's code, moving from a procedural to an object-oriented approach, shows several significant benefits. We'll discuss them by comparing the old code with the new code that uses classes, and focus on how this improves the readability, maintainability, and adaptability of the code.
Comparison of old and new code with classes:
Previous code (procedural):
- Structure: The code consisted of separate functions (SendGetRequest, SendPostRequest, Request) that handled various aspects of HTTP requests.
- Maintenance: Any changes to one function might require similar changes to others, since the code was repetitive and did not effectively share common logic.
- Readability: Although each function was relatively simple, the code as a whole was more difficult to understand, especially for new developers.
New (object oriented) code:
- Structure: Introduction of interfaces (IHttpRequest, IHttpResponseProcessor) and abstract classes (HttpRequestBase, HttpResponseProcessorBase), followed by concrete implementations (HttpRequest, HttpResponseProcessor).
- Maintenance: The code is now more modular, with clearly defined tasks for each class. This makes it easier to update and fix your code, since changes to one class usually don't affect other classes.
- Readability: Organizing into classes and methods makes the code more intuitive. All classes and methods have a clear purpose, making it easier to understand what the code does and how it works.
Improved readability and maintenance:
Readability
- Logical organization: The code is now divided into classes with specific functions, making it easier to understand the relationships between different parts of the code.
- Descriptive names: When using classes and methods, names can be more descriptive to clearly convey the functionality of each piece of code.
Maintenance
- Easy to update: Changes to one piece of code (such as HTTP response processing logic) can be made in one place, without having to change multiple functions scattered throughout the code.
- Extensibility: Adding new functionality or adapting code to new requirements is easy because the object-oriented structure is designed to be extensible and flexible.
- Scalability: As the project grows, it becomes easier to add new functionality or integrate with other APIs and systems. Classes can be extended or new classes can be created based on existing ones.
- Code reuse: Components can be reused in different parts of the project or even in other projects, saving time and effort.
- Ease of testing: Code testing becomes easier as you can focus on specific units (classes or methods) individually.
Refactoring our code to an object-oriented approach was a strategic change that not only improves the current quality of our project, but also lays a strong foundation for its future development. This transformation gives us cleaner code that is easier to understand, maintain, and extend.
By encapsulating logic into well-defined classes, we reduce redundancy, improve clarity, and increase the efficiency of our code. This is especially important in a constantly changing environment where flexibility and the ability to quickly respond to new requirements are important.
In addition, the modularity achieved with OOP facilitates team collaboration, where different parts of the project can be worked on simultaneously with less risk of code conflicts. This also opens the door to more advanced development techniques, such as unit testing, which are easier to implement in an object-oriented framework.
//+------------------------------------------------------------------+ //| Requests.mqh | //| Copyright 2023, Lejjo Digital | //| https://www.mql5.com/en/users/14134597 | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Lejjo Digital" #property link "https://www.mql5.com/ru/users/14134597" #property version "1.05" //+------------------------------------------------------------------+ //| Interface for HttpRequest | //+------------------------------------------------------------------+ interface IHttpRequest { public: virtual int Request(string method, string &out, const string url, const string payload = "", const string query_param = "") = 0; virtual int ValidateMethod(string method) = 0; virtual int PerformGetRequest(char &data[], uchar &result[], string &result_headers, const string url, const string query_param) = 0; virtual int PerformPostRequest(char &data[], uchar &result[], string &result_headers, const string url, const string payload) = 0; }; //+------------------------------------------------------------------+ //| Interface for HttpResponseProcessor | //+------------------------------------------------------------------+ interface IHttpResponseProcessor { public: virtual int ProcessResponse(int res, string &out, uchar &result[]) = 0; virtual int ProcessSuccessResponse(string &out, uchar &result[]) = 0; virtual int ProcessErrorResponse(int res, string &out, uchar &result[]) = 0; virtual int DetectAndSkipBOM(uchar &result[], int size) = 0; }; //+------------------------------------------------------------------+ //| Abstract base class for HttpResponseProcessor | //+------------------------------------------------------------------+ class HttpResponseProcessorBase : public IHttpResponseProcessor { public: HttpResponseProcessorBase() {}; virtual int ProcessResponse(int res, string &out, uchar &result[]) override = 0; virtual int ProcessSuccessResponse(string &out, uchar &result[]) override = 0; virtual int ProcessErrorResponse(int res, string &out, uchar &result[]) override = 0; virtual int DetectAndSkipBOM(uchar &result[], int size) override = 0; }; //+------------------------------------------------------------------+ //| Abstract base class for HttpRequest | //+------------------------------------------------------------------+ class HttpRequestBase : public IHttpRequest { protected: string m_headers; int m_timeout; IHttpResponseProcessor *responseProcessor; public: HttpRequestBase(string headers = "", int timeout = 5000) : m_headers(headers), m_timeout(timeout) { if(responseProcessor == NULL) { responseProcessor = new HttpResponseProcessor(); } } virtual int Request(string method, string &out, const string url, const string payload = "", const string query_param = "") override; virtual int ValidateMethod(string method) override; virtual int PerformGetRequest(char &data[], uchar &result[], string &result_headers, const string url, const string query_param) override = 0; virtual int PerformPostRequest(char &data[], uchar &result[], string &result_headers, const string url, const string payload) override = 0; virtual int ProcessResponse(int res, string &out, uchar &result[]) = 0; }; //+------------------------------------------------------------------+ //| Implement the Request function in HttpRequestBase class | //+------------------------------------------------------------------+ int HttpRequestBase::Request(string method, string &out, const string url, const string payload, const string query_param) override { if(!ValidateMethod(method)) { out = "Método HTTP inválido."; return -1; } char data[]; uchar result[]; string result_headers; int res = -1; if(method == "GET") res = PerformGetRequest(data, result, result_headers, url, query_param); else if(method == "POST") res = PerformPostRequest(data, result, result_headers, url, payload); if(res >= 0) return ProcessResponse(res, out, result); else { out = "Error when making HTTP request."; return res; } } //+------------------------------------------------------------------+ //| Implement the ValidateMethod function in HttpRequestBase class | //+------------------------------------------------------------------+ int HttpRequestBase::ValidateMethod(string method) { return (method == "GET" || method == "POST"); } //+------------------------------------------------------------------+ //| Concrete class for HttpRequest | //+------------------------------------------------------------------+ class HttpRequest : public HttpRequestBase { public: HttpRequest(string headers = "", int timeout = 5000) : HttpRequestBase(headers, timeout) {} virtual int PerformGetRequest(char &data[], uchar &result[], string &result_headers, const string url, const string query_param) override; virtual int PerformPostRequest(char &data[], uchar &result[], string &result_headers, const string url, const string payload) override; virtual int ProcessResponse(int res, string &out, uchar &result[]) override; }; //+------------------------------------------------------------------+ //| Implementation of functions for HttpRequest class | //+------------------------------------------------------------------+ int HttpRequest::PerformGetRequest(char &data[], uchar &result[], string &result_headers, const string url, const string query_param) { if(StringLen(query_param) > 0) return WebRequest("GET", url + "?" + query_param, NULL, NULL, m_timeout, data, StringLen(query_param), result, result_headers); return WebRequest("GET", url, m_headers, m_timeout, data, result, result_headers); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int HttpRequest::PerformPostRequest(char &data[], uchar &result[], string &result_headers, const string url, const string payload) { if(m_headers == "") m_headers = "Content-Type: application/json\r\n"; ArrayResize(data, StringToCharArray(payload, data, 0, WHOLE_ARRAY) - 1); return WebRequest("POST", url, m_headers, m_timeout, data, result, result_headers); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int HttpRequest::ProcessResponse(int res, string &out, uchar &result[]) { if(res >= 200 && res <= 299) return responseProcessor.ProcessSuccessResponse(out, result); return responseProcessor.ProcessErrorResponse(res, out, result); } //+------------------------------------------------------------------+ //| Concrete class for HttpResponseProcessor | //+------------------------------------------------------------------+ class HttpResponseProcessor : public HttpResponseProcessorBase { public: virtual int ProcessResponse(int res, string &out, uchar &result[]) override; virtual int ProcessSuccessResponse(string &out, uchar &result[]) override; virtual int ProcessErrorResponse(int res, string &out, uchar &result[]) override; virtual int DetectAndSkipBOM(uchar &result[], int size) override; }; //+------------------------------------------------------------------+ //| Implementation of functions for HttpResponseProcessor class | //+------------------------------------------------------------------+ int HttpResponseProcessor::ProcessResponse(int res, string &out, uchar &result[]) { if(res >= 200 && res <= 299) return ProcessSuccessResponse(out, result); return ProcessErrorResponse(res, out, result); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int HttpResponseProcessor::ProcessSuccessResponse(string &out, uchar &result[]) override { int size = ArraySize(result); int start_index = DetectAndSkipBOM(result, size); out = CharArrayToString(result, start_index, WHOLE_ARRAY, CP_UTF8); return 0; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int HttpResponseProcessor::ProcessErrorResponse(int res, string &out, uchar &result[]) override { ResetLastError(); if(res == -1) return GetLastError(); else if(res >= 100 && res <= 511) // Errors HTTP { out = CharArrayToString(result); Print(out); return res; } return res; }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int HttpResponseProcessor::DetectAndSkipBOM(uchar &result[], int size) override { int start_index = 0; for(int i = 0; i < MathMin(size, 3); i++) { if(result[i] == 0xef || result[i] == 0xbb || result[i] == 0xbf) start_index = i + 1; else break; } return start_index; }; //+------------------------------------------------------------------+
Examples of using classes
This section will provide practical examples of using classes created to perform HTTP requests in MQL5. These examples illustrate code reuse and the efficiency of creating new functionality.
Checking the success of the response:
void TestProcessSuccessResponse() { HttpResponseProcessor processor; string output; uchar result[]; // Simulate a successful response in JSON format string mockResponse = "{\"status\": \"success\", \"data\": \"Sample data\"}"; StringToCharArray(mockResponse, result); // Process the simulated response processor.ProcessSuccessResponse(output, result); // Check the output Print("Success Test: ", output); }
Explanation:
- HttpResponseProcessor processor: Creating an HttpResponseProcessor class processor object.
- StringToCharArray: Converts a simulated response string to a character array.
- processor.ProcessSuccessResponse(output, result): Calls a method to process the simulated response.
Error response test:
void TestProcessErrorResponse() { HttpResponseProcessor processor; string output; uchar result[]; // Simulate an error response (404 Not Found) string mockResponse = "404 Not Found"; StringToCharArray(mockResponse, result); // Process an error response processor.ProcessErrorResponse(404, output, result); // Check the output Print("Error Test: ", output); }
Explanation:
- This example is similar to the previous one, but it focuses on modeling and processing an HTTP error response.
BOM detection and skipping test:
void TestDetectAndSkipBOM() { HttpResponseProcessor processor; uchar result[6] = {0xEF, 0xBB, 0xBF, 'a', 'b', 'c'}; // 'abc' with BOM UTF-8 // Detect and skip the BOM (Byte Order Mark) int startIndex = processor.DetectAndSkipBOM(result, ArraySize(result)); // Check the initial index after BOM Print("Start index after BOM: ", startIndex); // Expected: 3 }
Explanation:
- uchar result[6] = {0xEF, 0xBB, 0xBF, 'a', 'b', 'c'};: Creates an array with a UTF-8 BOM followed by 'abc'.
- processor.DetectAndSkipBOM(result, ArraySize(result));: Detects and skips BOM, and then returns the start index of the corresponding content.
Running the test and HTTP GET request:
int OnInit() { RunTests(); // Run the tests HttpRequest httpRequest("", 5000); // Create an instance of the HttpRequest class string output; // Variable to store the output // Perform the GET request int responseCode = httpRequest.Request("GET", output, "https://jsonplaceholder.typicode.com/posts/1"); // Show the result Print("Response Code: ", responseCode); Print("Output: ", output); }
Explanation:
- HttpRequest httpRequest("", 5000): Creating an httpRequest object of the HttpRequest class with default settings.
- httpRequest.Request("GET", output, "https://..."): Performing a GET request to the specified URL and save the response to the output variable.
These examples show how the HttpResponseProcessor and HttpRequest classes can be used to handle various aspects of HTTP responses, such as success, error, and the presence of a BOM. They also demonstrate how easy it is to make GET requests using the HttpRequest class.
The modularization of code in classes is a fundamental approach in programming that enables the creation of an organized and understandable system. This practice involves dividing code into independent units called classes, each of which has its own responsibilities and functionality.
Using this technique, developers can structure their code more logically and clearly, making it more readable and easier to understand. This means that instead of monolithic code, we are dealing with disorganized code; the developer works with small parts of the system, each of which is represented by a class.
The advantage of this approach is that you can design classes holistically, with associated methods and attributes grouped together. This not only makes the code more understandable, but also makes it easier to maintain and further develop, since it is easier to find and fix problems in individual blocks.
In addition, class modularity promotes code reuse because classes can be used in different places in the program, saving time and effort in creating similar functionality.
Below is a complete example that includes test code to demonstrate the practical use of the HttpResponseProcessor and HttpRequest classes. This example will help illustrate how classes can be used effectively to make HTTP requests and handle responses, both on success and error, thereby providing a detailed and complete understanding of how the code works.
//+------------------------------------------------------------------+ //| test.mq5 | //| Copyright 2023, Lejjo Digital | //| https://www.mql5.com/en/users/14134597 | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Lejjo Digital" #property link "https://www.mql5.com/ru/users/14134597" #property version "1.00" #include "Requests.mqh" //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void TestProcessSuccessResponse() { HttpResponseProcessor processor; string output; uchar result[]; // Simulate a success report (example with JSON) string mockResponse = "{\"status\": \"success\", \"data\": \"Sample data\"}"; StringToCharArray(mockResponse, result); // Call ProcessSuccessResponse processor.ProcessSuccessResponse(output, result); // Check that the output is as expected Print("Success Test: ", output); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void TestProcessErrorResponse() { HttpResponseProcessor processor; string output; uchar result[]; // Simulate an error response (example with error 404) string mockResponse = "404 Not Found"; StringToCharArray(mockResponse, result); // Call ProcessErrorResponse with a simulated error code processor.ProcessErrorResponse(404, output, result); // Verify that the output is as expected Print("Error Test: ", output); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void TestDetectAndSkipBOM() { HttpResponseProcessor processor; uchar result[6] = {0xEF, 0xBB, 0xBF, 'a', 'b', 'c'}; // 'abc' with BOM UTF-8 // Call DetectAndSkipBOM int startIndex = processor.DetectAndSkipBOM(result, ArraySize(result)); // Check if the start index is correct Print("Índice de início após BOM: ", startIndex); // Expected: 3 } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void RunTests() { TestProcessSuccessResponse(); TestProcessErrorResponse(); TestDetectAndSkipBOM(); } //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- // Run HttpResponseProcessor tests RunTests(); // Create the HttpRequest class instance HttpRequest httpRequest("", 5000); // Variables to store the output string output; // Perform the GET request int responseCode = httpRequest.Request("GET", output, "https://jsonplaceholder.typicode.com/posts/1"); // Show the result Print("Response Code: ", responseCode); Print("Output: ", output); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- } //+------------------------------------------------------------------+
Conclusion
We have reached the end of this article, in which we have looked at the transformation of a "traditional" project into an object-oriented one. Moving from a procedural code structure to a class-based architecture not only provides cleaner organization, but also makes the code easier to maintain and extend.
Relevance of OOP in MQL5:
- The adoption of the OOP paradigm represents a significant quantum leap in software development. In our context, where MQL5 is mainly used for algorithmic trading and automation of financial market strategies, the importance of well-structured and modular code is even greater.
Benefits of modularity and encapsulation:
- Organizing code into classes allows us to encapsulate specific functionality to make the system more intuitive and easier to maintain. Each class becomes a module with specific responsibilities, making it easier to identify and resolve problems and to expand the system with new functionality.
Benefits of code reuse:
- OOP promotes code reuse. By creating well-defined classes, you can reuse these structures in different parts of the project or even in other projects. This not only saves time, but also improves code consistency and reliability.
Ease of maintenance and scalability:
- Maintaining and scaling a project becomes much more viable with OOP. As your project grows or adapts to new requirements, the ability to change a specific component without affecting the rest of the system is an invaluable advantage.
I encourage all readers, regardless of their level of programming experience, to apply OOP concepts in their MQL5 projects. Switching to OOP may seem challenging at first, but the long-term benefits in terms of code quality, development efficiency, and maintainability are undeniable.
Translated from Portuguese by MetaQuotes Ltd.
Original article: https://www.mql5.com/pt/articles/13863
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Check out the new article: Developing an MQL5 RL agent with RestAPI integration (Part 4): Organizing functions in classes in MQL5.
Author: Jonathan Pereira
Hi Jonathan,
Great article, just to make you aware. When you use the keyword "interface" you do not need to use "public:", "virtual" and " = 0;"
Shep
Hello, Jonathan,
Great article, but just to warn you. When you use the "interface" keyword, you don't need to use "public:", "virtual" and " = 0;"
Shep
Thank you for your comment! I'm glad you liked the article. I'd like to clarify why I chose to use public: , virtual and = 0; in the interfaces, even though some of these elements may seem redundant:
Code Clarity and Consistency:
Compatibility with C++:
Implicit documentation:
Extensibility and Maintainability:
Compliance with Coding Standards:
Although it's not strictly necessary to use public: , virtual and = 0; in MQL5 interfaces, choosing to include them brings benefits in terms of code clarity, consistency and maintainability. I hope this explanation helps clarify my design choice.
Thank you for your comment! I'm glad you liked the article. I'd like to clarify why I chose to use public: , virtual and = 0; in the interfaces, even though some of these elements may seem redundant:
Code Clarity and Consistency:
Compatibility with C++:
Implicit documentation:
Extensibility and Maintainability:
Compliance with Coding Standards:
Although it's not strictly necessary to use public: , virtual and = 0; in MQL5 interfaces, choosing to include them brings benefits in terms of code clarity, consistency and maintainability. I hope this explanation helps clarify my design choice.
I get you. I do a lot of work in C++, so I get you. Great work, great article and great response, thanks.