
Ihrer eigenes LLM in einen EA integrieren (Teil 5): Handelsstrategie mit LLMs(I) entwickeln und testen – Feinabstimmung

Inhaltsverzeichnis
- Inhaltsverzeichnis
- Einführung
- Feinabstimmung von großen Sprachmodellen
- Formulierung der Handelsstrategie
- Erstellung eines Datensatzes
- Feinabstimmung des Modells
- Tests
- Schlussfolgerung
- Referenzen
Einführung
In unserem letzten Artikel haben wir die GPU-Beschleunigung zum Trainieren großer Sprachmodelle vorgestellt, aber wir haben sie nicht zur Formulierung von Handelsstrategien oder zum Backtesting verwendet. Das eigentliche Ziel der Ausbildung unseres Modells besteht jedoch darin, es zu nutzen, damit es uns dient. Ab diesem Artikel werden wir also Schritt für Schritt das trainierte Sprachmodell verwenden, um Handelsstrategien zu formulieren und unsere Strategien an Devisenpaaren zu testen. Natürlich ist dies kein einfacher Prozess. Es erfordert, dass wir entsprechende technische Mittel einsetzen, um diesen Prozess zu erreichen. Lassen Sie uns also Schritt für Schritt vorgehen.
Der gesamte Prozess kann mehrere Artikel in Anspruch nehmen.
- Der erste Schritt besteht darin, eine Handelsstrategie zu formulieren;
- Der zweite Schritt ist die Erstellung eines Datensatzes entsprechend der Strategie und die Feinabstimmung des Modells (oder das Training des Modells), sodass die Eingabe und die Ausgabe des großen Sprachmodells mit unserer formulierten Handelsstrategie übereinstimmen. Es gibt viele verschiedene Methoden, diesen Prozess zu erreichen, und ich werde so viele Beispiele wie möglich anführen;
- Der dritte Schritt ist die Inferenz des Modells und die Verschmelzung des Outputs mit der Handelsstrategie und die Erstellung von EA entsprechend unserer Handelsstrategie. Natürlich bleibt in der Inferenzphase des Modells noch einiges zu tun (Auswahl des geeigneten Inferenzrahmens und der Optimierungsmethoden: z. B. Flash-Attention, Modellquantisierung, Speedup usw.);
- Der vierte Schritt ist das historische Backtesting, mit dem wir unseren EA auf der Client-Seite testen.
Einige Freunde werden sich fragen: Ich habe bereits ein Modell mit meinen eigenen Daten trainiert, warum muss ich es noch feinabstimmen? Die Antwort auf diese Frage soll in diesem Artikel gegeben werden.
Natürlich sind die verfügbaren Methoden nicht auf die Feinabstimmung (fine-tuning) des großen Prophezeiungsmodells beschränkt. Es können auch andere Techniken verwendet werden, wie z. B. die RAG-Technologie (eine Technik, die das große Sprachmodell bei der Generierung von Inhalten mit Hilfe von Retrieval-Informationen unterstützt) und die Agententechnologie (ein intelligenter Körper, der durch die Inferenz des großen Sprachmodells entsteht). Würden all diese Inhalte in einem einzigen Artikel behandelt, wäre dieser zu lang und würde nicht ausreichen, um die Regeln zu lesen, und er würde chaotisch wirken, weshalb wir sie in mehreren Teilen behandeln. In diesem Artikel besprechen wir hauptsächlich unsere ersten und zweiten Schritte, formulieren Handelsstrategien und geben ein Beispiel für die Feinabstimmung eines großen Sprachmodells (GPT2).
Feinabstimmung von großen Sprachmodellen
Bevor wir beginnen, müssen wir diese Feinabstimmung erst einmal verstehen. Einige Freunde mögen Zweifel haben: Wir haben in den vorangegangenen Artikeln bereits ein Modell trainiert, warum müssen wir es noch feiner abstimmen? Warum nicht direkt das trainierte Modell verwenden? Um diese Frage zu verstehen, müssen wir zunächst den Unterschied zwischen großen Sprachmodellen und herkömmlichen neuronalen Netzmodellen beachten: In diesem Stadium basieren große Sprachmodelle im Wesentlichen auf der Transformer-Architektur, die komplexe Aufmerksamkeitsmechanismen beinhaltet. Da es sich um ein komplexes Modell mit einer großen Anzahl von Parametern handelt, ist für das Training großer Sprachmodelle in der Regel eine große Datenmenge sowie eine leistungsstarke Computerhardware erforderlich, und die Trainingszeit beträgt in der Regel mehrere Stunden bis zu mehreren Tagen. Für einen einzelnen Entwickler ist es also relativ schwierig, ein Sprachmodell von Grund auf zu trainieren (wenn man natürlich eine Goldmine zu Hause hat, ist das eine andere Geschichte).
Zum jetzigen Zeitpunkt bietet uns die Verwendung unseres eigenen Datensatzes zur Feinabstimmung des bereits trainierten großen Sprachmodells mehr Auswahlmöglichkeiten. Und das große Sprachmodell, das mit einer großen Menge an Daten auf einem groß angelegten Cluster-Computing trainiert wurde, hat eine bessere Kompatibilität und Generalisierungsfähigkeit. Das bedeutet nicht, dass das direkt mit spezifischen Daten trainierte Modell nicht gut genug ist. Solange die Datenmenge und -qualität gut und groß genug sind und die Hardware-Ausstattung stark genug ist, können Sie Ihren eigenen Datensatz vollständig verwenden, um ein Modell von Grund auf zu trainieren, und der Effekt kann besser sein.
Das bedeutet nur, dass wir durch die Feinabstimmung mehr Wahlmöglichkeiten haben. Das gängige Paradigma für große Sprachmodelle besteht also darin, das Sprachmodell zunächst auf einer großen Menge allgemeiner Daten zu trainieren und dann eine Feinabstimmung für spezifische nachgelagerte Aufgaben vorzunehmen, um den Zweck der Domänenanpassung zu erreichen. Die hier erwähnte Feinabstimmung entspricht im Wesentlichen dem Transfer-Lernen oder der Feinabstimmung herkömmlicher neuronaler Netze, aber es gibt auch ganz erhebliche Unterschiede. Im Folgenden werden insbesondere die in großen Sprachmodellen häufig verwendeten Feinabstimmungsmethoden vorgestellt.
Die Feinabstimmung großer Modelle lässt sich in Methoden des überwachten Lernens, Methoden des unüberwachten Lernens und Methoden des verstärkenden Lernens unterteilen:
- Methode der Feinabstimmung durch überwachtes Lernen: Dies ist die gängigste Methode, d. h., das Modell wird mit gekennzeichnete Daten trainiert. Sie können zum Beispiel einige Datensätze mit Dialogfragen und Antworten sammeln. Legen Sie dabei die Zielausgabe und -eingabe als ein Paar von gepaarten Beispielen fest, um das Modell zu optimieren.
- Unüberwachtes Lernen - Methode zur Feinabstimmung: Wenn nicht genügend gekennzeichneter Text vorhanden ist, kann das große Sprachmodell weiterhin mit einer großen Menge nicht-gekennzeichneten Textes trainieren, was dem Modell hilft, die Sprachstruktur besser zu verstehen.
- Methode des Verstärkungslernens zur Feinabstimmung: Wie beim traditionellen Reinforcement Learning wird zunächst ein Textqualitäts-Vergleichsmodell (äquivalent zu einem Kritiker) als Belohnungsmodell erstellt und die Qualität mehrerer verschiedener Outputs, die das Pre-Training-Modell für dasselbe Prompt-Wort liefert, bewertet. Gleichzeitig kann dieses Belohnungsmodell ein binäres Klassifizierungsmodell verwenden, um die Vor- und Nachteile der beiden Eingabeergebnisse zu beurteilen. Verwenden Sie dann das Belohnungsmodell auf der Grundlage der angegebenen Beispieldaten für Eingabeaufforderungswörter, um die Qualität des Ergebnisses der benutzerdefinierten Wortvervollständigung des vorab trainierten Modells zu bewerten und mit dem Sprachmodellziel bessere Ergebnisse zu erzielen. Die Feinabstimmung des Verstärkungslernens führt dazu, dass der vom LLM auf der Grundlage des Vortrainingsmodells generierte Ergebnistext bessere Ergebnisse erzielt. Zu den häufig verwendeten Methoden des Verstärkungslernens gehören DPO, ORPO, PPO usw.
Für die Feinabstimmung großer Modelle werden hauptsächlich zwei Methoden verwendet: Model-Tuning und Prompt-Tuning:
1. Vollständige Parameter-Feinabstimmung
Der direkteste Weg ist die Feinabstimmung des gesamten großen Sprachmodells, was bedeutet, dass alle Parameter zur Anpassung an den neuen Datensatz aktualisiert werden. Diese Methode wird auch als ineffiziente Feinabstimmung bezeichnet, da das Parametervolumen des aktuellen großen Sprachmodells immer größer wird und die erforderlichen Hardware-Ressourcen exponentiell ansteigen. Um ein Beispiel zu nennen: Für die Feinabstimmung eines großen Sprachmodells mit einer Parameterskala von 8 B sind beispielsweise 2 Videospeicher von 80 GB oder insgesamt etwa 160 GB für das Beschleunigungstraining auf mehreren Karten erforderlich. Diese Hardware-Investition dürfte die meisten normalen Entwickler abschrecken.
2. Adapter-Tuning
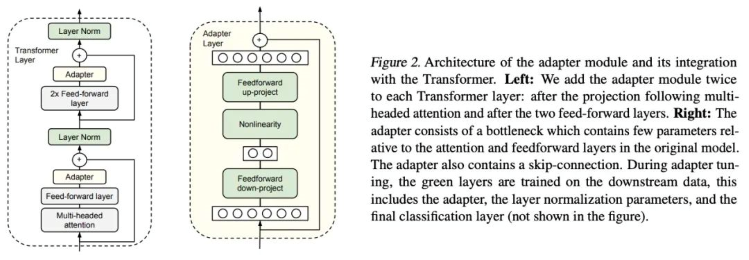
Adapter-Tuning ist eine PEFT-Feinabstimmungsmethode für BERT, die von Google-Forschern zum ersten Mal vorgeschlagen wurde und auch den Auftakt zur PEFT-Forschung bildete. Bei einer spezifischen nachgelagerten Aufgabe ist ein „Full-Finetuning“ (d.h. alle Parameter des Pre-Training-Modells werden fein abgestimmt) zu ineffizient, und wenn das feste Pre-Training-Modell verwendet wird, werden nur einige wenige Parameterschichten, die der nachgelagerten Aufgabe nahe kommen, fein abgestimmt, und es ist schwierig, eine bessere Wirkung zu erzielen. Also entwarfen sie die Adapter-Struktur, betteten sie in die Transformator-Struktur ein und legten während des Trainings die Parameter des ursprünglichen Vor-Trainingsmodells fest und nahmen lediglich eine Feinabstimmung der neu hinzugefügten Adapter-Struktur vor. Um die Effizienz des Trainings zu gewährleisten (d.h. so wenige Parameter wie möglich einzuführen), wurde der Adapter so aufgebaut: Zunächst bildet eine Abwärtsschicht hochdimensionale Merkmale auf niedrigdimensionale Merkmale ab und durchläuft dann eine nichtlineare Schicht. Danach verwenden wir eine Up-Project-Struktur, um niedrigdimensionale Merkmale auf die ursprünglichen hochdimensionalen Merkmale zurückzubilden. Gleichzeitig ist eine Skip-Connection-Struktur auch so konzipiert, dass sie im schlimmsten Fall zur Identität degradiert werden kann.
Artikel: „Parameter-Efficient Transfer Learning for NLP“ (https://arxiv.org/pdf/1902.00751)
Code: https://github.com/google-research/adapter-bert
3. Parametereffizientes Prompt-Tuning

Parametereffizientes Prompt-Tuning ist eine effiziente und praktische Methode zur Feinabstimmung von Modellen. Durch das Hinzufügen kontinuierlicher aufgabenbezogener Einbettungsvektoren vor der Eingabe für das Training kann der Umfang der Berechnungen und Parameter reduziert und der Trainingsprozess beschleunigt werden. Gleichzeitig wird für eine effektive Feinabstimmung nur eine kleine Datenmenge benötigt, was die Abhängigkeit von einer großen Menge an markierten Daten verringert. Darüber hinaus können verschiedene Prompts für verschiedene Aufgaben angepasst werden, was zu einer hohen Anpassungsfähigkeit führt. In praktischen Anwendungen kann die parametereffiziente Eingabeaufforderung (Prompt Tuning) dazu beitragen, dass wir uns schnell an verschiedene Aufgabenstellungen anpassen und die Leistung des Modells verbessern können. Um ein parameter-effizientes Prompt-Tuning zu implementieren, sind im Allgemeinen die folgenden Schritte erforderlich:
- Definieren der aufgabenbezogene Einbettungsvektoren - die kontinuierlichen, aufgabenbezogene Einbettungsvektoren werden entsprechend den Anforderungen der Aufgabe definiert. Diese Vektoren können manuell entworfen oder durch andere Methoden automatisch gelernt werden.
- Ändern der Eingabepräfix: Einfügen des definierten Einbettungsvektors als Präfix vor den Eingabedaten. Diese Präfixe werden dem Modell zusammen mit der ursprünglichen Eingabe zum Training übergeben.
- Feinabstimmung des Modells: Die Eingabedaten werden mit dem Präfix für die Feinabstimmung verwendet. Bei diesem Verfahren werden nur die Parameter des Präfix-Teils aktualisiert, die Parameter des ursprünglichen Pre-Training-Modells bleiben unverändert.
- Bewertung und Optimierung: Die Leistung des Modells wird anhand des Validierungssatzes ausgewertet und es werden Optimierungsanpassungen vorgenommen. Durch kontinuierliche Iteration und Optimierung können wir ein fein abgestimmtes Modell für bestimmte Aufgaben erhalten.
Artikel: „The Power of Scale for Parameter-Efficient Prompt Tuning Official” (https://arxiv.org/pdf/2104.08691.pdf)
Code: https://github.com/google-research/prompt-tuning
4. Prefix-Tuning

Die Prefix-Tuning-Methode schlägt vor, zu jeder Eingabe für das Training einen kontinuierlichen aufgabenbezogenen Einbettungsvektor (kontinuierliche aufgabenspezifische Vektoren) hinzuzufügen. Prefix-Tuning ist immer noch ein fester Pre-Trainings-Parameter, aber zusätzlich zum Hinzufügen einer oder mehrerer Einbettungen für jede Aufgabe wird ein mehrschichtiges Perzeptron verwendet, um das Präfix zu kodieren (beachten Sie, dass das mehrschichtige Perzeptron der Präfix-Kodierer ist), und es wird nicht mehr wie beim Prompt-Tuning weiterhin LLM eingegeben.
Kontinuierlich (kontinuierlich) bezieht sich hier auf die diskreten (diskreten) manuell definierten Textprompt-Token. Ein manuell definiertes Prompt-Token-Array ist z. B. ['The', 'movie', 'is', '[MASK]']; wenn das Token dort durch einen Einbettungsvektor als Eingabe ersetzt wird, ist die Einbettung ein kontinuierlicher (stetiger) Ausdruck. Wenn Sie die nachgelagerte Aufgabe neu trainieren, fixieren Sie alle Parameter des ursprünglichen großen Modells und trainieren nur den Präfix-Vektor (Präfix-Einbettung), der sich auf die nachgelagerte Aufgabe bezieht. Bei selbstregressiven LM-Modellen (wie dem in unserem Beispiel verwendeten GPT-2) wird ein Präfix vor der ursprünglichen Eingabeaufforderung hinzugefügt (z = [PREFIX; x; y]); bei LM-Modellen mit Encoder und Decoder (wie BART) wird ein Präfix an die Eingabe des Encoders bzw. Decoders angehängt (z = [PREFIX; x; PREFIX'; y],).
Artikel: „Präfix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks” (https://aclanthology.org/2021.acl-long.353)
Code: https://github.com/XiangLi1999/PrefixTuning
5. P-Tuning und P-Tuning V2

P-Tuning kann die Leistung von Sprachmodellen in Multitasking- und Low-Resource-Umgebungen erheblich verbessern. Es verbessert die Eingabemerkmale durch die Einführung eines kleinen, leicht zu berechnenden Front-End-Teilnetzes, wodurch die Leistung des Basismodells verbessert wird. Die P-Abstimmung legt weiterhin LLM-Parameter fest, verwendet ein mehrschichtiges Perzeptron und ein LSTM, um den Prompt zu kodieren, und nach der Kodierung wird er normalerweise in den LLM eingegeben, nachdem er mit anderen Vektoren verkettet wurde. Beachten Sie, dass nach dem Training nur der Vektor nach der Prompt-Codierung erhalten bleibt und der Encoder nicht mehr erhalten ist. Diese Methode kann nicht nur die Genauigkeit und Robustheit des Modells bei verschiedenen Aufgaben verbessern, sondern auch die für die Feinabstimmung erforderliche Datenmenge und die Rechenkosten erheblich reduzieren. Das Problem mit p-tuning ist, dass es bei Modellen mit kleinen Parametern schlecht funktioniert. Deshalb gibt es eine V2-Version, ähnlich wie bei LoRA, bei der neue Parameter in jede Schicht eingebettet werden (Deep FT genannt).
Bei P-Tuning v2 handelt es sich um eine auf P-Tuning basierende verbesserte Version. Die wichtigste Verbesserung ist die Einführung einer effizienteren Beschneidungsmethode, mit der das Parametervolumen der Modellfeinabstimmung weiter reduziert werden kann. Genau genommen ist das P-Tuning V2 keine brandneue Methode, sondern eine optimierte Version des Deep Prompt Tuning (Li und Liang, 2021; Qin und Eisner, 2021).
P-tuning v2 ist für die Generierung und Erforschung von Wissen konzipiert, aber eine der wichtigsten Verbesserungen ist die Anwendung von kontinuierlichen Aufforderungen auf jede Schicht des Pre-Training-Modells, nicht nur auf die Eingabeschicht. Diese Methode benötigt nur eine Feinabstimmung von 0,1%-3% der Parameter und kann mit der Modell-Feinabstimmung mithalten, was ihre Stärke zeigt!
P-Tuning Artikel: „GPT Understands, Too“ (https://arxiv.org/pdf/2103.10385).
6. LoRA

Die LoRA-Methode friert zunächst die Parameter des Pre-Training-Modells ein und fügt in jeder Schicht des Decoders zusätzliche Parameter für Dropout+Linear+Conv1d hinzu. In der Tat kann LoRA grundsätzlich nicht die Leistung einer vollständigen Feinabstimmung der Parameter erreichen. Den Experimenten zufolge ist die Feinabstimmung der Parameter wesentlich besser als die LoRA-Methode, aber in Situationen mit geringen Ressourcen ist LoRA die bessere Wahl. Mit LoRA können wir einige dichte Schichten im neuronalen Netz indirekt trainieren, indem wir die Rangzerlegungsmatrix der Änderungen in der dichten Schicht während der Anpassung optimieren, während die Gewichte vor dem Training eingefroren bleiben.
Merkmale von LoRA:
- Ein gut trainiertes Modell kann gemeinsam genutzt werden, um viele kleine LoRA-Module für verschiedene Aufgaben zu erstellen. Wir können das gemeinsame Modell einfrieren und die Aufgaben effektiv wechseln, indem wir die Matrizen A und B in Abbildung 1 ersetzen, wodurch der Speicherbedarf und der Aufwand für den Aufgabenwechsel erheblich reduziert werden.
- LoRA macht die Ausbildung effizienter. Bei der Verwendung von adaptiven Optimierern wird der Hardware-Schwellenwert um das Dreifache reduziert, da wir keine Gradienten berechnen oder den Optimierungsstatus der meisten Parameter aufrechterhalten müssen. Im Gegenteil, wir optimieren nur die eingespeiste, viel kleinere Matrix mit niedrigem Rang.
- Unser einfaches lineares Design ermöglicht es uns, die trainierbare Matrix mit den eingefrorenen Gewichten während des Einsatzes zu verschmelzen und führt im Vergleich zum vollständig fein abgestimmten Modell zu keiner Verzögerung der Inferenz in der Struktur.
- LoRA ist für viele bisherige Methoden irrelevant und kann mit vielen Methoden kombiniert werden.
Artikel: „LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS” (https://arxiv.org/pdf/2106.09685.pdf).
Code: https://github.com/microsoft/LoRA.
7. AdaLoRA

Es gibt viele Möglichkeiten zu entscheiden, welche LoRA-Parameter wichtiger sind als andere, und AdaLoRA ist eine davon. Die Autoren von AdaLoRA empfehlen, den Singulärwert der LoRA-Matrix als Indikator für die Wichtigkeit zu betrachten.
Ein wichtiger Unterschied zum obigen LoRA-drop ist, dass die Adapter in der mittleren Schicht von LoRA-drop entweder vollständig oder gar nicht trainiert sind. AdaLoRA kann entscheiden, dass verschiedene Adapter unterschiedliche Ränge haben (bei der ursprünglichen LoRA-Methode haben alle Adapter den gleichen Rang).
AdaLoRA hat insgesamt die gleiche Anzahl von Parametern wie Standard-LoRA desselben Ranges, aber die Verteilung dieser Parameter ist anders. In LoRA ist der Rang aller Matrizen gleich, während in AdaLoRA einige Matrizen einen höheren und einige Matrizen einen niedrigeren Rang haben, sodass die Gesamtzahl der Parameter gleich ist. Experimente haben gezeigt, dass AdaLoRA bessere Ergebnisse liefert als Standard-LoRA-Methoden, was darauf hindeutet, dass es eine bessere Verteilung der trainierbaren Parameter auf die Teile des Modells gibt, die für eine bestimmte Aufgabe besonders wichtig sind, und dass die Schichten, die näher am Ende des Modells liegen, einen höheren Rang haben, was darauf hindeutet, dass die Anpassung an diese Schichten wichtiger ist.
AdaLoRA zerlegt die Gewichtsmatrix durch Singulärwertzerlegung in eine inkrementelle Matrix und passt die Größe der Singulärwerte in jeder inkrementellen Matrix dynamisch an, sodass während des Feinabstimmungsprozesses nur die Parameter aktualisiert werden, die mehr zur Modellleistung beitragen oder notwendig sind, um die Modellleistung und Parametereffizienz zu verbessern.
Artikel: „ADALORA: ADAPTIVE BUDGET ALLOCATION FOR PARAMETER-EFFICIENT FINE-TUNING” (https://arxiv.org/pdf/2303.10512).
Code: https://github.com/QingruZhang/AdaLoRA.
8. QLoRA

QLoRA überträgt den Gradienten auf den Low-Rank-Adapter (LoRA) durch ein eingefrorenes, quantisiertes 4-Bit-Sprachmodell, das den Speicherverbrauch erheblich reduziert und Rechenressourcen spart, während die Leistung der kompletten 16-Bit-Feinabstimmung erhalten bleibt.
Technische Merkmale von QLoRA:
- Backpropagation von Gradienten in Low-Order-Adaptern (LoRAs) über ein eingefrorenes, 4-Bit-quantisiertes, vortrainiertes Sprachmodell.
- Einführung von 4-Bit-NormalFloat (NF4), einem theoretisch optimalen Datentyp für die Quantisierung von Informationen für normal verteilte Daten, der bessere empirische Ergebnisse als 4-Bit-Ganzzahlen und 4-Bit-Gleitkommazahlen liefern kann.
- Wir wenden die Doppelquantisierung an, eine Methode zur Quantifizierung von Quantifizierungskonstanten, die im Durchschnitt etwa 0,37 Bits pro Parameter einspart.
- Verwenden Sie einen Paging-Optimierer mit NVIDIA Unified Memory, um Speicherspitzen beim Gradienten-Checkpointing zu vermeiden, wenn Sie kleine Batches mit langen Sequenzlängen verarbeiten. Erheblich reduzierte Speicheranforderungen, die eine Feinabstimmung eines 65B-Parameter-Modells auf einem einzigen 48GB-Grafikprozessor ohne Beeinträchtigung der Laufzeit oder der Vorhersageleistung im Vergleich zu einem vollständig feinabgestimmten 16-Bit-Benchmark ermöglichen.
Artikel: „QLORA: Efficient Finetuning of Quantized LLMs” (https://arxiv.org/pdf/2305.14314.pdf).
Code: https://github.com/artidoro/qlora.
In diesem Artikel werden nur einige häufig verwendete repräsentative Methoden sowie einige auf der LoRA-Technologie basierende Varianten aufgeführt: LoRA+, VeRA, LoRA-fa, LoRA-drop, DoRA and Delta-LoRA, etc. In diesem Artikel werden sie nicht einzeln vorgestellt, interessierte Leser können die einschlägige Literatur zu Rate ziehen.
Natürlich gibt es noch einige andere Souffleurtechniken, die ebenfalls unseren technischen Bedürfnissen entsprechen (z.B. die RAG-Technik), die ich Ihnen in den folgenden Artikeln vorstellen werde.
Als Nächstes zeigen wir Ihnen ein Beispiel für die Feinabstimmung von GPT2 mit allen Parametern.
Formulierung der Handelsstrategie
Was die Handelsstrategie betrifft, so verwenden wir ein einfaches Beispiel, um die Feinabstimmung des großen Sprachmodells anzuleiten, wobei die EA-Implementierung vorübergehend nicht einbezogen wird (die spezifische Implementierung muss warten, bis unsere vollständige Inferenzstrategie für das große Sprachmodell fertiggestellt ist, bevor wir vernünftigerweise EA erstellen können). Wir holen uns zunächst die letzten 20 Schlusskurse eines bestimmten Zeitraums für ein bestimmtes Währungspaar vom Client und definieren deren Durchschnitt als A. Dann verwenden wir das umfangreiche Sprachmodell, um die Schlusskurse der nächsten 40 Kurse desselben Zeitraums vorherzusagen, und definieren deren Durchschnitt als B. Dann entscheiden wir anhand des vorhergesagten Werts, ob wir als Nächstes kaufen oder verkaufen:
- Wenn der Durchschnittswert B von 40 vorhergesagten Werten größer ist als der Durchschnittswert A der letzten 20 Schlusskurse, dann wird gekauft.
- Wenn der Durchschnittswert B von 40 vorhergesagten Werten kleiner ist als der Durchschnittswert A der letzten 20 Schlusskurse, dann wird verkauft.
- Wenn A und B gleich oder sehr nahe beieinander liegen, sollten wir nichts tun.
Damit haben wir die Formulierung der Handelsstrategie abgeschlossen. Dies ist eine recht einfache Handelsstrategie zur Demonstration, die idealisiert werden kann. Wir können diese Strategie auch nach Bedarf ersetzen, z. B. indem wir die Eingabe in dynamisch ändern, die Gesamtlänge der Vorhersageergebnisse 60 minus die Länge der Eingabe. Oder wir nutzen direkt andere Handelslogiken, wie z.B. die Formulierung von Regeln, die auf der Wellenstrategie, der Krokodilstrategie oder der Schildkrötenstrategie basieren. Als Nächstes beginnen wir mit der Erstellung eines Datensatzes entsprechend der Strategie und der Feinabstimmung des großen Sprachmodells.
Erstellung eines Datensatzes
Beim Training großer Sprachmodelle haben wir bereits einen Datensatz erstellt, der in der Datei „llm_data.csv“ enthalten ist. Dieser Datensatz enthält nur die Notierungen eines Währungspaares in einem 5M-Zyklus und wurde entsprechend verarbeitet, mit insgesamt 2442 Datenzeilen mit jeweils 64 Spalten. Für den spezifischen Verarbeitungsprozess lesen Sie bitte den Teil über das Training großer Sprachmodelle mit CPU oder GPU in dieser Artikelserie (der spezifische Link ist „Integrieren Sie Ihr eigenes LLM in Ihren EA (Teil 3): Training Ihres eigenen LLM mit CPU - ein MQL5 Artikel“). Natürlich können Sie das Skript aus dem Artikel auch verwenden, um den Datensatz anzupassen oder Ihre eigene hervorragende Idee in einen Datensatz zu verwandeln (z. B. die Korrelation zwischen staatlichen Finanzdaten und Wechselkursen in einen Datensatz zu verwandeln usw.). Kurz gesagt, dieser Datensatz kann in jeder beliebigen Form vorliegen, nicht nur in Form von Zahlenangaben.
1. VorverarbeitungZunächst importieren wir die benötigten Bibliotheken:
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from transformers import TextDataset, DataCollatorForLanguageModeling from transformers import Trainer, TrainingArguments import torch
Lesen Sie die Datendatei:
df = pd.read_csv('llm_data.csv') Ich habe diesen Datensatz aktualisiert, dieser Datensatz enthält nun 60 Schlusskurse eines Währungspaares in einem 5M-Zyklus in jeder Zeile, anstatt der ursprünglichen 64, und die Daten sind im Textformat verarbeitet:
sentences = [' '.join(map(str, prices)) for prices in df.iloc[:-10,1:].values]
Diese Codezeile liest hauptsächlich die gesamte Dataframe-Datei, durchläuft ihre Elemente und wandelt jede Zeile in eine Zeichenkette um, wobei sie wie ein Satz behandelt wird. Jeder Satz enthält 60 Schlusskurse. Das heißt, wir wandeln es um in: „0.6119 0.61197 0.61201...0.61196“, nicht: „0.6119“ „0.61197“... „0.61196“. So kann sich das Sprachmodell die von uns festgelegte Sequenzlänge merken. Wenn wir z. B. 20 Daten eingeben, vervollständigt das Modell die restlichen 40 Daten für uns, anstatt Inhalte auszugeben, die wir nicht kontrollieren können.
Es gibt auch eine besondere Stelle in dieser Codezeile, die erklärt werden muss, nämlich „df.iloc[:-10,1:].values“. Das „:-10“ bedeutet, dass wir den Anfang der CSV-Datei bis zu den letzten 10 Zeilen nehmen und die restlichen 10 Zeilen zum Testen belassen; „1:“ bedeutet, dass wir die erste Spalte jeder Zeile entfernen, diese Spalte ist der Indexwert in der CSV-Datei, wir brauchen sie nicht.
Als Nächstes fügen wir alle Sequenzen zu einem Datensatz zusammen und speichern ihn als „train.txt“, sodass wir die CSV-Datei beim nächsten Mal nicht mehrfach verarbeiten müssen, sondern die verarbeitete Datei direkt lesen können.
with open('train.txt', 'w') as f: for sentence in sentences: f.write(sentence + '\n')
2. Laden wir die Daten als Klasse Dataset
Nachdem die Vorverarbeitung der Daten abgeschlossen ist, müssen wir noch den Tokenizer verwenden, um die Daten weiter zu verarbeiten und in das Datenformat „Dataset“ in pytorch zu laden. Jetzt sind einige häufig verwendete Klassen in die Transformers-Bibliothek integriert, um diese Arbeit direkt zu erledigen. In dem Beispiel in diesem Artikel können Sie direkt TextDataset verwenden, um diese Funktion zu erreichen, was sehr einfach ist, aber wir müssen zuerst GPT2 verwenden, um den Tokenizer zu instanziieren. Wenn Sie GPT2 noch nicht geladen haben, lädt die Transformers-Bibliothek bei der ersten Verwendung die Pre-Training-Datei von Huggingface herunter. Stellen Sie sicher, dass das Netzwerk nicht blockiert ist. Speziell für Freunde, die Docker oder wsl verwenden, stellen Sie bitte sicher, dass Ihre Netzwerkkonfiguration korrekt ist, sonst wird das Laden fehlschlagen.
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
train_dataset = TextDataset(tokenizer=tokenizer,
file_path="train.txt",
block_size=60) 3. Laden der Daten für das Sprachmodell
Hier verwenden wir direkt die DataCollatorForLanguageModeling-Klasse in der Transformer-Bibliothek, um die Daten zu instanziieren, und müssen keine zusätzliche Arbeit mehr leisten.
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
Als Nächstes laden wir das vorab trainierte Modell und nehmen eine Feinabstimmung vor.
Feinabstimmung des Modells
Sobald wir unseren Datensatz für die Feinabstimmung vorbereitet haben, können wir mit dem Prozess der Feinabstimmung unseres großen Sprachmodells beginnen.
1. Laden des vortrainierten Modells
Der erste Schritt bei der Feinabstimmung eines Modells ist das Laden des vortrainierten Modells. Wir haben bereits den Tokenizer geladen, also müssen wir hier nur noch das Modell laden:
model = GPT2LMHeadModel.from_pretrained('gpt2') Als Nächstes müssen wir die Trainingsparameter festlegen. Die Transformers-Bibliothek bietet uns auch eine sehr bequeme Klasse zur Implementierung dieser Funktion, ohne dass zusätzliche Konfigurationsdateien erforderlich sind:
training_args = TrainingArguments(output_dir="./gpt2_stock", overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=32, save_steps=10_000, save_total_limit=2, load_best_model_at_end=True, )
2. Initialisierung der Feinabstimmungsparameter
Bei der Instanziierung von TrainingArguments haben wir die folgenden Parameter verwendet:
- output_dir: Der Ort, an dem Vorhersageergebnisse und Kontrollpunkte gespeichert werden. Wir haben den Ordner „gpt2_stock“ im aktuellen Verzeichnis als Ausgabepfad definiert.
- overwrite_output_dir: Ob die Ausgabedatei überschrieben werden soll. Wir haben uns für das Überschreiben entschieden.
- num_train_epochs: Die Anzahl der Trainingsepochen. Wir haben 3 Epochen gewählt.
- per_device_train_batch_size: Die Größe des Trainings-Batch. Wir haben uns für die Zahl 32 entschieden, die, wie bereits erwähnt, am besten eine Potenz von 2 ist.
- save_steps=10_000: Die Anzahl der Aktualisierungsschritte vor zwei Checkpoint-Sicherungen, wenn save_strategy="steps". Sollte eine ganze Zahl oder ein Float im Bereich [0,1] sein. Ist sie kleiner als 1, wird sie als Verhältnis der gesamten Trainingsschritte interpretiert.
- save_total_limit: Wenn ein Wert übergeben wird, wird die Gesamtzahl der Kontrollpunkte begrenzt. Löscht die älteren Checkpoints in output_dir.
- load_best_model_at_end: Ob das beste Modell während des Trainingsprozesses geladen werden soll, anstatt die Modellgewichte im letzten Schritt des Trainings zu verwenden.
Es gibt viele Parameter, die wir nicht festgelegt und die Standardwerte verwendet haben, weil wir nur ein Beispiel sind, also haben wir diese Klasse nicht im Detail definiert, zum Beispiel:
- deepspeed: Ob Deepspeed zur Beschleunigung der Ausbildung eingesetzt werden soll.
- eval_steps: Anzahl der Aktualisierungsschritte zwischen zwei Bewertungen.
- dataloader_pin_memory: Ob wir den Speicher im Datenlader anheften (pin) wollen oder nicht.
Wie man sieht, ist die Klasse TrainingArguments sehr leistungsfähig, sie enthält fast alle Trainingsparameter, ist sehr bequem zu nutzen und es wird dem Leser dringend empfohlen, einen Blick in die offizielle Dokumentation zu werfen.
3. Feinabstimmung
Kehren wir nun zu unserem Feinabstimmungsprozess (fine-tuning) zurück, und jetzt können wir unseren Feinabstimmungsprozess definieren. Wir haben den Trainingsprozess des Sprachmodells in einem früheren Artikel ausführlich beschrieben. Der Prozess der Feinabstimmung unterscheidet sich nicht wesentlich vom Trainingsprozess. Ich denke, dass die Leser damit bereits sehr vertraut sind, weshalb das Beispiel in diesem Artikel den Feinabstimmungsprozess des Sprachmodells nicht mehr im Detail definiert, sondern direkt die in der Transformer-Bibliothek enthaltene Klasse Trainer verwendet, um ihn zu implementieren. Nun übergeben wir das Modell, training_args, data_collator und train_dataset, die wir als Parameter definiert haben, an die Klasse Trainer, um den Trainer zu instanziieren:
trainer = Trainer(model=model, args=training_args, data_collator=data_collator, train_dataset=train_dataset,)
Die Klasse Trainer hat auch andere Parameter, die wir nicht gesetzt haben, wie die wichtigen Callbacks: Sie können Callbacks verwenden, um das Verhalten der Trainingsschleife anzupassen, diese Callbacks können den Status der Trainingsschleife überprüfen (für Fortschrittsberichte, Logging auf TensorBoard oder anderen ML-Plattformen, usw.) und Entscheidungen treffen (wie z.B. frühzeitiges Beenden, usw.). Der Grund, warum wir sie in diesem Artikel nicht festgelegt haben, liegt darin, dass es nur ein Beispiel ist, und die Parametereinstellungen des Modells im Feinabstimmungsprozess relativ konservativ sind. Wenn Sie möchten, dass Ihr Modell besser funktioniert, denken Sie bitte daran, dass diese Option nicht ignoriert werden sollte. Rufen Sie die Methode tran() der instanziierten Trainerklasse auf, und Sie können den Feinabstimmungsprozess direkt durchführen:
trainer.train()
Nachdem das Training beendet ist, speichern wir das Modell, sodass wir direkt die Methode from_pretrained() verwenden können, um das feinabgestimmte Modell zu laden, wenn wir inferieren:
trainer.save_model("./gpt2_stock") Als Nächstes führen wir eine Inferenz durch, um zu prüfen, ob die Feinabstimmung wirksam ist:
prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1]))
generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt').to("cuda"),
do_sample=True,
max_length=200)[0],
skip_special_tokens=True)
print(f"test the model:{generated}") In diesem Teil des Codes wandelt „prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1]))“ die letzte Zeile unseres Datensatzes in ein String-Format um. „tokenizer.encode(prompt, return_tensors='pt')“ dieser Teil des Codes wandelt den Eingabetext (Prompt) in eine Form um, die das Modell verstehen kann, d. h. er wandelt den Text in eine Reihe von Token um. „return_tensors='pt'“ gibt an, dass der zurückgegebene Datentyp ein PyTorch-Tensor ist. „do_sample=True“ gibt an, dass bei der Generierung eine Zufallsstichprobe verwendet wird, und „max_length=200“ begrenzt die maximale Länge des generierten Textes. Werfen wir nun einen Blick auf die Ergebnisse der Ausführung des gesamten Codes:

Es ist zu erkennen, dass das fein abgestimmte, vortrainierte Modell erfolgreich die gewünschten Ergebnisse liefert.
Der vollständige Code lautet wie folgt, der Name des Skripts im Anhang lautet „Fin-tuning.py“:
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from transformers import TextDataset, DataCollatorForLanguageModeling from transformers import Trainer, TrainingArguments import torch dvc='cuda' if torch.cuda.is_available() else 'cpu' print(dvc) df = pd.read_csv('llm_data.csv') sentences = [' '.join(map(str, prices)) for prices in df.iloc[:-10,1:].values] with open('train.txt', 'w') as f: for sentence in sentences: f.write(sentence + '\n') tokenizer = GPT2Tokenizer.from_pretrained('gpt2') train_dataset = TextDataset(tokenizer=tokenizer, file_path="train.txt", block_size=60) data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False) model = GPT2LMHeadModel.from_pretrained('gpt2') training_args = TrainingArguments(output_dir="./gpt2_stock", overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=32, save_steps=10_000, save_total_limit=2, load_best_model_at_end=True, ) trainer = Trainer(model=model, args=training_args, data_collator=data_collator, train_dataset=train_dataset,) trainer.train() trainer.save_model("./gpt2_stock") prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt').to(dvc), do_sample=True, max_length=200)[0], skip_special_tokens=True) print(f"test the model:{generated}")
Tests
Nachdem die Feinabstimmung abgeschlossen ist, müssen wir das Modell noch testen und den Abstand zwischen der Ausgabe des Modells und dem ursprünglichen wirklichen Wert überprüfen. Die einfachste Methode ist die Berechnung des mittleren, quadratischen Fehlers (MSE) zwischen dem wirklichen Wert und dem vorhergesagten Wert.
Nun erstellen wir ein Skript, um den Testprozess zu implementieren, importieren zunächst die erforderlichen Bibliotheken, laden das von uns feinabgestimmte GPT2-Modell und die Daten:
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from sklearn.metrics import mean_squared_error import torch import numpy as np df = pd.read_csv('llm_data.csv') dvc='cuda' if torch.cuda.is_available() else 'cpu' model = GPT2LMHeadModel.from_pretrained('./gpt2_stock') tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
Dieser Prozess unterscheidet sich nicht wesentlich von unserem Feinabstimmungsprozess, außer dass der Modellpfad auf den Pfad geändert wird, auf dem wir das Modellgewicht während der Feinabstimmung gespeichert haben. Nach dem Laden des Modells und des Tokenizers müssen wir den wirklichen Wert und den vorhergesagten Wert nach der Inferenz verarbeiten. Dieser Teil entspricht auch den Schritten in unserem Skript zur Feinabstimmung:
prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt'), do_sample=True, max_length=200)[0], skip_special_tokens=True)
Jetzt nehmen wir die letzten 40 Schlusskurse der letzten Zeile des Datensatzes als wirklichen Wert und wandeln den wirklichen Wert und den vorhergesagten Wert in eine Listenform um, und die Länge ist konsistent:
true_prices= df.iloc[-1:,21:].values.tolist()[0] generated_prices=generated.split('\n')[0] generated_prices=list(map(float,generated_prices.split())) generated_prices=generated_prices[0:len(true_prices)] def trim_lists(a, b): min_len = min(len(a), len(b)) return a[:min_len], b[:min_len] true_prices,generated_prices=trim_lists(true_prices,generated_prices)
Damit der wirkliche Wert und der vorhergesagte Wert die gleiche Länge haben, müssen wir eine weitere Liste entsprechend der Länge der kleinsten Liste abschneiden, also definieren wir „trim_lists(a, b)“, um diese Aufgabe zu erledigen. Dann drucken wir den wirklichen Wert und den vorhergesagten Wert aus, um zu sehen, ob sie den Erwartungen entsprechen:
print(f"true_prices:{true_prices}") print(f"generated_prices:{generated_prices}")
Wir können die folgenden Ergebnisse sehen:
true_prices: [0.6119, 0.61197, 0.61201, 0.61242, 0.61237, 0.6123, 0.61229, 0.61242, 0.61212, 0.61197, 0.61201, 0.61213, 0.61212,
0.61206, 0.61203, 0.61206, 0.6119, 0.61193, 0.61191, 0.61202, 0.61197, 0.6121, 0.61211, 0.61214, 0.61203, 0.61203, 0.61213, 0.61218,
0.61227, 0.61226, 0.61227, 0.61231, 0.61228, 0.61227, 0.61233, 0.61211, 0.6121, 0.6121, 0.61195, 0.61196]
generated_prices:[0.61163, 0.61162, 0.61191, 0.61195, 0.61209, 0.61231, 0.61224, 0.61207, 0.61187, 0.61184, 0.6119, 0.61169, 0.61168,
0.61162, 0.61181, 0.61184, 0.61184, 0.6118, 0.61176, 0.61169, 0.61191, 0.61195, 0.61204, 0.61188, 0.61205, 0.61188, 0.612, 0.61208,
0.612, 0.61192, 0.61168, 0.61165, 0.61164, 0.61179, 0.61183, 0.61192, 0.61168, 0.61175, 0.61169, 0.61162]
Anschließend können wir den mittleren, quadratischen Fehler (MSE) berechnen und die Ergebnisse zur Überprüfung ausdrucken:
mse = mean_squared_error(true_prices, generated_prices)
print('MSE:', mse) Das Ergebnis ist: MSE: 2.1906250000000092e-07.
Wie Sie sehen können, ist der MSE sehr klein, aber bedeutet das wirklich, dass unser Modell sehr genau ist? Bitte vergessen Sie nicht, dass unsere ursprünglichen Daten nur einen sehr geringen Wert hatten! Obwohl der MSE sehr klein ist, kann er die Genauigkeit des Modells derzeit nicht genau widerspiegeln, da unsere ursprünglichen Werte ebenfalls relativ klein sind. Wir müssen außerdem den mittleren, quadratischen Fehler (RMSE) und den normalisierten mittleren, quadratischen Fehler (NRMSE) zwischen dem vorhergesagten Wert und dem Originalwert berechnen, um die Größe des Vorhersagefehlers im Verhältnis zum Bereich der beobachteten Werte zu bestimmen und die Genauigkeit des Modells zu ermitteln:
rmse=np.sqrt(mse) nrmse=rmse/(np.max(true_prices)-np.min(generated_prices)) print(f"RMSE:{rmse},NRMSE:{nrmse}")
Das Ergebnis ist:
- RMSE:0.00046804113067122735
- NRMSE:0.5850514133390986

Wir können feststellen, dass die MSE- und RMSE-Werte zwar sehr gering sind, der NRMSE-Wert jedoch 0,5850514133390986 beträgt, was bedeutet, dass der Vorhersagefehler etwa 58,5 % des Bereichs der beobachteten Werte ausmacht. Dies zeigt, dass der absolute Wert des RMSE im Verhältnis zum Bereich der beobachteten Werte zwar sehr klein ist, der Vorhersagefehler aber immer noch relativ groß ist.
Wie können wir also unser Modell genauer machen? Hier sind ein paar Möglichkeiten:
- Erhöhen der Epochen während der Feinabstimmung
- Erhöhen der Datenmenge
- Optimieren der Feinabstimmungsparameter ordnungsgemäß
- Ersetzen durch ein größeres Modell
Diese Methoden sind nicht schwer zu implementieren, wird dieser Artikel nicht überprüfen sie eine nach der anderen, können Sie wählen, eine oder mehrere von ihnen nach Ihren eigenen Ideen zu üben, ich glaube, die Ergebnisse werden definitiv viel besser als das Beispiel in diesem Artikel!
Der vollständige Code, der Name des Skripts im Anhang ist test.py:
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from sklearn.metrics import mean_squared_error import torch import numpy as np df = pd.read_csv('llm_data.csv') dvc='cuda' if torch.cuda.is_available() else 'cpu' model = GPT2LMHeadModel.from_pretrained('./gpt2_stock') tokenizer = GPT2Tokenizer.from_pretrained('gpt2') prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt'), do_sample=True, max_length=200)[0], skip_special_tokens=True) true_prices= df.iloc[-1:,21:].values.tolist()[0] generated_prices=generated.split('\n')[0] generated_prices=list(map(float,generated_prices.split())) generated_prices=generated_prices[0:len(true_prices)] def trim_lists(a, b): min_len = min(len(a), len(b)) return a[:min_len], b[:min_len] true_prices,generated_prices=trim_lists(true_prices,generated_prices) print(f"true_prices:{true_prices}") print(f"generated_prices:{generated_prices}") mse = mean_squared_error(true_prices, generated_prices) print('MSE:', mse) rmse=np.sqrt(mse) nrmse=rmse/(np.max(true_prices)-np.min(generated_prices)) print(f"RMSE:{rmse},NRMSE:{nrmse}")
Schlussfolgerung
In diesem Artikel werden hauptsächlich die Voraussetzungen für die Verwendung großer Sprachmodelle für Handelsstrategien vorgestellt, d. h. die Ausgabe des großen Sprachmodells muss den Anforderungen unserer Handelsstrategie entsprechen. Wir haben einige technische Methoden erörtert, mit denen diese Aufgabe erfüllt werden kann. Obwohl wir aus Platzgründen nicht für alle Methoden relevante Code-Beispiele zur Verfügung gestellt haben, wird nur ein Beispiel für die Feinabstimmung von GPT2 mit allen Parametern gegeben (natürlich ist dieser Datensatz nicht auf alle im Text erwähnten Feinabstimmungsmethoden anwendbar, aber die detaillierten Beispiele in den späteren Artikeln werden die Methode zur Erstellung des Datensatzes angeben, die der Methode entspricht). Aber keine Sorge, ich werde in den folgenden Artikeln einige repräsentative Methoden auswählen, um relevante Code-Beispiele und EA-Beispiele, die zu den Beispielen passen, bereitzustellen. Für die RAG-Technologie und die Agententechnologie, die im Text nur erwähnt werden, wird es auch spezielle Artikel geben, die Sie mit detaillierten Diskussionen und entsprechenden Code-Implementierungen versorgen.
Sind Sie bereit? Wir sehen uns im nächsten Artikel!
Referenzen
https://alexqdh.github.io/posts/2183061656/
http://note.iawen.com/note/llm/finetune
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/13497
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.