
独自のLLMをEAに総合する(第5部): LLMを使った取引戦略の開発とテスト(I) - 微調整

目次
はじめに
前回の記事では、GPUアクセラレーションを活用して大規模言語モデルを学習する方法を紹介しましたが、取引戦略の策定やバックテストの実行には触れませんでした。しかし、最終的な目標は、学習させたモデルを効果的に活用し、実際の取引に役立てることです。そこで今回の記事からは、訓練済みの言語モデルを活用し、取引戦略を立て、外国為替の通貨ペアでその戦略をテストするプロセスに入ります。もちろん、これは単純な作業ではなく、適切な技術的手段を導入する必要があります。では、順を追って実行していきましょう。
この全プロセスが完了するまでに、いくつかの記事を要するかもしれません。
- 最初のステップは、取引戦略を立てることです。
- 次に、第2のステップとして、戦略に基づいたデータセットを作成し、そのデータが大規模言語モデルの入力および出力として適合するよう、モデルを微調整(または再訓練)します。これを実現するためには、さまざまなアプローチが存在しますので、可能な限り多くの例を紹介します。
- 第3のステップは、モデルによる推論と、その結果を取引戦略に統合することです。そして、この戦略に基づいてEA(エキスパートアドバイザー)を作成します。もちろん、この推論段階では、適切な推論フレームワークの選定や最適化手法(フラッシュアテンション、モデルの量子化、速度向上など)など、解決すべき技術的課題も残っています。
- 第4のステップは、ヒストリカルバックテストを用いて、クライアント側でEAをテストすることです。
ここで、すでに自身のデータでモデルを訓練している場合、なぜさらに微調整が必要なのか疑問に思う方もいるかもしれません。その理由についてはこの記事で詳しく説明します。
もちろん、利用可能な手法は、大規模言語モデルの微調整に限りません。他にも、RAG技術(検索情報を活用して大規模言語モデルのコンテンツ生成を補助する技術)や、エージェント技術(大規模言語モデルによる推論で生成される知的体)なども活用できます。ただし、これらすべてを1つの記事で解説すると長くなりすぎ、内容が混乱してしまう可能性があります。そのため、数回に分けて詳しく説明することにします。今回は、主に最初のステップと第2のステップに焦点を当て、取引戦略の策定と大規模言語モデル(GPT2)の微調整の具体例を取り上げます。
大規模言語モデルの微調整
まず、この「微調整」について理解することが重要です。すでにモデルを訓練したのに、なぜさらに微調整が必要なのか、疑問に思う方もいるでしょう。なぜ訓練済みモデルをそのまま使わないのでしょうか。この疑問を解くためには、大規模言語モデルと従来のニューラルネットワークモデルの違いを理解する必要があります。現在の大規模言語モデルは、主に複雑な注意メカニズムを持つTransformerアーキテクチャに基づいています。これらのモデルは非常に複雑で、多数のパラメータを持つため、学習には大量のデータと高性能なコンピュータハードウェアが必要です。学習時間も、数時間から数日、場合によっては数十日に及ぶことがあります。そのため、個人開発者がゼロからこれらのモデルを訓練するのは困難です(もちろん、自宅に大規模な計算リソースがあれば別ですが)。
現時点では、すでに訓練済みの大規模言語モデルを微調整することで、独自のデータセットに基づいたモデルを作成する選択肢が広がります。さらに、大規模なクラウドコンピューティング環境で大量のデータを使って訓練されたモデルは、一般的に優れた互換性と汎化能力を持っています。これは、特定のデータセットで直接訓練したモデルが劣るというわけではありません。もしデータの質と量が十分で、さらに十分な計算リソースがあれば、ゼロからモデルを訓練することも可能で、むしろ高い効果が得られることもあります。
つまり、微調整はより多くの選択肢を提供する手法です。そのため、大規模言語モデルの主流のパラダイムでは、まず大量の一般データを使って事前学習をおこない、その後、特定のタスクに適応させるために微調整をおこなう流れが一般的です。この微調整は、基本的には従来のニューラルネットワークの転移学習や微調整に似ていますが、大規模言語モデル特有の違いも存在します。以下では、大規模言語モデルでよく使われる具体的な微調整方法を紹介します。
大規模モデルの微調整は、教師あり学習、教師なし学習、強化学習の3つの方法に分けられます。
- 教師あり学習による微調整法:これは最も一般的な方法で、ラベル付きデータを使用してモデルを訓練します。例えば、対話の質問と回答のペアデータセットを収集し、入力と目標出力を対応させてモデルを最適化します。
- 教師なし学習による微調整法:ラベル付きデータが不足している場合に有効です。大規模言語モデルは、ラベルなしの大量のテキストを使って事前学習を続けることができ、これによりモデルが言語構造をより深く理解できるようになります。
- 強化学習による微調整法:従来の強化学習と同様に、まず報酬モデルとしてテキスト品質を比較するモデル(Criticに相当)を構築し、同じプロンプトに対して事前学習モデルが生成した複数の異なる出力の品質をランク付けします。また、この報酬モデルは、2つの出力結果の長所と短所を判断するために、2値分類モデルを使用することも可能です。次に、この報酬モデルを用いて、与えられたプロンプトに対する事前学習モデルの出力結果を評価し、より良い品質を持つ出力を得ることを目指します。強化学習による微調整は、事前学習モデルの出力を改善し、最適化されたテキスト生成結果を得るための手法です。よく使われる強化学習法には、DPO、ORPO、PPOなどがあります。
大規模モデルの微調整は、具体的にはModel-TuningとPrompt-Tuningの2つのカテゴリに分類されます。
1. フルパラメータ微調整
最も直接的な方法は、大規模言語モデル全体のすべてのパラメータを微調整することです。つまり、モデルの全パラメータを新しいデータセットに合わせて更新します。この方法は「非効率的な微調整」とも呼ばれ、モデルのパラメータ数が増えるにつれ、必要なハードウェアリソースも指数関数的に増加します。例を挙げます。例えば、8B規模のパラメータを持つ大規模モデルを微調整するには、80Gのビデオメモリを持つGPUが2つ、または合計160GのマルチGPUが必要です。このようなハードウェア投資は、一般の開発者にとってハードルが高いものです。
2. アダプタチューニング
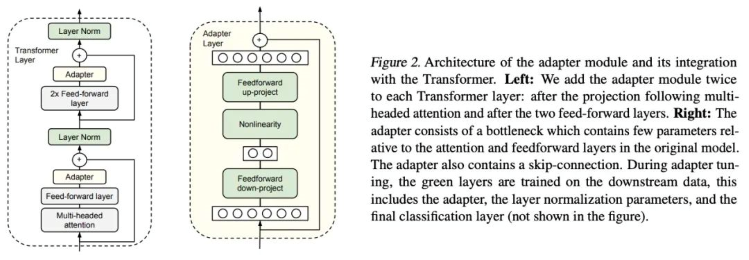
アダプタチューニングは、Googleの研究者がBERTに対して提案したPEFT (Parameter-Efficient Fine-Tuning)の手法であり、PEFT研究の先駆けとなりました。具体的な下流タスクにおいて、すべてのパラメータを微調整する「フル微調整」は効率が悪く、一方で事前学習モデルを固定して一部の層だけを微調整する方法では、十分な効果を得にくいです。そこで、彼らは「アダプタ構造」を提案し、これをTransformerアーキテクチャに組み込むことで、事前学習モデルのパラメータを固定し、新たに追加したアダプタだけを微調整することが可能となりました。このアダプタは、効率を高めるために次のように設計されています。まず、高次元の特徴量を低次元にマッピングする「ダウンプロジェクト層」を通過させ、その後、非線形層を経由します。続いて「アッププロジェクト層」で低次元の特徴量を元の高次元に戻します。さらに、スキップコネクションを導入し、最悪の場合でも元のアイデンティティまで劣化できるように設計されています。
論文:「Parameter-Efficient Transfer Learning for NLP」(https://arxiv.org/pdf/1902.00751)
コード:https://github.com/google-research/adapter-bert
3. Parameter-Efficient Prompt-Tuning

Parameter-Efficient Prompt-Tuningは、モデルの微調整方法として非常に効率的かつ実用的です。入力データの前にタスク関連の連続的な埋め込みベクトルを追加することで、計算量とパラメータを削減し、訓練プロセスを高速化できます。さらに、必要なデータ量が少なく、大量のラベル付きデータへの依存を減らすことができます。また、プロンプトはタスクに応じてカスタマイズ可能で、強力なタスク適応能力を持っています。実際の応用では、Parameter-Efficient Prompt-Tuningにより、様々なタスクのニーズに迅速に対応し、モデルのパフォーマンスを向上させることができます。この手法を実装する一般的な手順は以下の通りです。
- タスク関連の埋め込みベクトルを定義:タスクに合わせた連続的な埋め込みベクトルを設計します。これらは手動で設計するか、他の方法で自動的に学習させることができます。
- 入力接頭辞を修正:定義された埋め込みベクトルを入力データの前に接頭辞として追加し、元の入力とともにモデルに渡します。
- モデルの微調整:接頭辞付きの入力データを使ってモデルを微調整します。この際、更新されるのは接頭辞部分のパラメータのみで、元の事前学習モデルのパラメータは変更されません。
- 評価と最適化:検証セットを用いてモデルの性能を評価し、必要に応じて最適化します。このプロセスを繰り返すことで、特定のタスクに最適な微調整されたモデルを得ることができます。
論文:「The Power of Scale for Parameter-Efficient Prompt Tuning Official」 (https://arxiv.org/pdf/2104.08691.pdf)
4. Prefix-Tuning

Prefix-Tuning法では、各入力に対して連続的なタスク関連埋め込みベクトル(連続タスク固有ベクトル)を追加することが提案されています。Prefix-Tuningは、固定的な事前学習パラメータを使用しつつ、タスクごとに1つ以上の埋め込みを追加するだけでなく、多層パーセプトロンを用いて接頭辞をエンコードします(ここで、多層パーセプトロンが接頭辞エンコーダとして機能する点に注意してください)。このため、もはやPrompt-TuningのようにLLMに入力し続けることはありません。
ここで「連続」(continuous)という用語は、手動で定義されたテキストプロンプトトークンの「離散」(discrete)と相対的な意味を持ちます。例えば、手動で定義されたプロンプトトークンの配列が ['The', 'movie', 'is', '[MASK]'] である場合、これらのトークンを入力として埋め込みベクトルに置き換えることで、埋め込みは連続的になります。下流タスクを再学習する際には、元の大きなモデルのすべてのパラメータを固定し、下流タスクに関連する接頭辞ベクトル(接頭辞埋め込み)だけを再学習します。自己回帰型LMモデル(今回の例ではGPT-2など)の場合、元のプロンプトの前に接頭辞が追加されます(z = [PREFIX; x; y])。一方、エンコーダ+デコーダ型LMモデル(BARTなど)の場合、エンコーダとデコーダの入力それぞれに接頭辞が追加されます (z = [PREFIX; x; PREFIX’; y],)。
論文:「Prefix-Tuning:Optimizing Continuous Prompts for Generation, P-Tuning v2:Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks」(https://aclanthology.org/2021.acl-long.353)
コード:https://github.com/XiangLi1999/PrefixTuning
5. P-TuningとP-Tuning V2

P-Tuningは、マルチタスクや低リソース環境における言語モデルの性能を大幅に向上させることができます。小規模で計算が容易なフロントエンドサブネットワークを導入することで、入力機能を強化し、ベースモデルの性能を向上させています。P-Tuningでは、LLMのパラメータを固定し、多層パーセプトロンとLSTMを用いてプロンプトをエンコードします。その後、エンコードされたベクトルは他のベクトルと連結してLLMに入力されます。訓練後、プロンプトエンコーディング後のベクトルだけが保持され、エンコーダー自体は保持されない点に注意が必要です。この方法は、さまざまなタスクにおけるモデルの精度とロバスト性を向上させるだけでなく、微調整に必要なデータ量と計算コストを大幅に削減します。ただし、P-Tuningの問題点として、パラメータが少ないモデルでは性能が低下することが挙げられます。このため、LoRAと同様に、各層に新しいパラメータを埋め込んだV2バージョン(Deep FTと呼ばれる)があります。
具体的には、P-Tuning v2はP-Tuningを基にしたアップグレード版です。主な改良点は、より効率的な刈り込み法の採用により、モデルの微調整に必要なパラメータ量をさらに減少させることです。厳密に言えば、P-Tuning v2は全く新しい手法ではなく、Deep Prompt Tuning(Li and Liang, 2021; Qin and Eisner, 2021)を最適化したものです。
P-Tuning v2は生成と知識探索のために設計されていますが、最も重要な改良点の1つは、入力層だけでなく、事前学習モデルの各層に継続的なプロンプトを適用できることです。この方法では、パラメータの0.1%~3%を微調整するだけで、モデル微調整に匹敵する性能を発揮します。
P-Tuningの論文:「GPT Understands, Too」 (https://arxiv.org/pdf/2103.10385)
6. LORA

LoRA法は、まず事前学習モデルのパラメータを凍結し、デコーダーの各層にdropout、Linear、およびConv1dのパラメータを追加します。根本的には、LoRAは完全なパラメータ微調整のパフォーマンスを達成することができません。実験によれば、フルパラメータ微調整はLoRA法よりもはるかに優れていますが、リソースが限られた状況ではLoRAの方が良い選択肢となります。LoRAは、学習前の重みを凍結したまま、適応中の密な層の変化を階数分解行列として最適化することで、ニューラルネットワークのいくつかの密な層を間接的に訓練することを可能にします。
LoRAの特徴
- よく訓練されたモデルは共有可能であり、異なるタスクのために多くの小さなLoRAモジュールを構築するのに使用できます。共有モデルをフリーズさせ、図1の行列AとBを置き換えることで、効率的にタスクを切り替えられ、ストレージ要件とタスク切り替えのオーバーヘッドを大幅に削減します。
- LoRAは訓練をより効率的におこないます。適応型オプティマイザを使用する場合、ほとんどのパラメータについて勾配を計算したり、オプティマイザの状態を維持したりする必要がないため、ハードウェアの閾値は3分の1に減少します。逆に、注入されたはるかに小さい低階数行列だけを最適化します。
- ここでの単純な線形設計は、展開中に訓練可能な行列と凍結された重みをマージすることを可能にし、完全に微調整されたモデルと比較して、構造上の推論遅延を生じさせません。
- LoRAはこれまでの多くの方法とは無関係であり、多様な手法と組み合わせることができます。
論文:「LORA:LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS」(https://arxiv.org/pdf/2106.09685.pdf)
コード:https://github.com/microsoft/LoRA
7.AdaLoRA

どのLoRAパラメータが他より重要かを決定する方法は多数ありますが、その1つがAdaLoRAです。AdaLoRAの作者は、LoRA行列の特異値を重要性の指標として考慮することを推奨しています。
上記のLoRA-dropとの重要な違いは、LoRA-dropの中間層のアダプタが完全に訓練されているか、全く訓練されていないかのどちらかであるのに対し、AdaLoRAは異なるアダプタが異なる階数を持つことを決定できる点です(オリジナルのLoRAメソッドでは、すべてのアダプタが同じ階数を持ちます)。
AdaLoRAは、同じ階数の標準的なLoRAと比較して合計で同じ数のパラメータを持っていますが、これらのパラメータの分布は異なります。LoRAではすべての行列の階数が同じですが、AdaLoRAでは、ある行列は高い階数を持ち、別の行列は低い階数を持つため、最終的なパラメータの総数は同じになります。実験によると、AdaLoRAは標準的なLoRA手法よりも優れた結果を示しています。これは、与えられたタスクにとって特に重要なモデルの部分に学習可能なパラメータがより効果的に分布していることを示しており、モデルの末端に近い層ほど高い階数を提供し、これらに適応することがより重要であることを示しています。
AdaLoRAは、特異値分解によって重み行列を増分行列に分解し、各増分行列の特異値のサイズを動的に調整します。これにより、微調整プロセス中にモデルのパフォーマンスに大きく貢献するパラメータや、モデルのパフォーマンスに必要なパラメータのみが更新され、結果としてモデルのパフォーマンスとパラメータの効率が向上します。
論文:「ADALORA:ADAPTIVE BUDGET ALLOCATION FOR PARAMETER-EFFICIENT FINE-TUNING」(https://arxiv.org/pdf/2303.10512)
コード:https://github.com/QingruZhang/AdaLoRA
8.QLoRA

QLoRAは、凍結された4ビットの量子化された事前学習済み言語モデルを介して、低ランクアダプタ(LoRA: Low-Rank Adapter)に勾配をバックプロパゲートします。この手法により、完全な16ビット微調整タスクの性能を維持しつつ、メモリ使用量を大幅に削減し、計算リソースを節約することができます。
QLoRAの技術的特徴:
- 凍結された4ビット量子化された事前学習済み言語モデルを通じて、低ランクアダプタ(LoRA)に勾配をバックプロパゲートします。
- 正規分布データの情報を量子化するための理論的に最適なデータ型として、4ビット整数や4ビット浮動小数点よりも優れた実証結果を得られる4-bit NormalFloat (NF4)を採用しています。
- 定量化定数を定量化する方法である二重量子化を適用することにより、平均して1パラメータあたり約0.37ビットを節約できます。
- NVIDIAユニファイドメモリでページングオプティマイザを使用し、長いシーケンス長を持つ小さなバッチを処理する際に、勾配チェックポイント中のメモリスパイクを回避します。これにより、メモリ要件が大幅に削減され、16ビットで完全に微調整されたベンチマークと比較しても、実行時間や予測性能が低下することなく、48GBのGPU1台で65Bパラメータモデルの微調整が可能になりました。
論文:「QLORA:Efficient Finetuning of Quantized LLMs」 (https://arxiv.org/pdf/2305.14314.pdf)
コード:https://github.com/artidoro/qlora
この記事では、一般的に使用されている代表的な方法と、LoRA技術に基づくいくつかのバリエーションを紹介します。具体的には、LoRA+、VeRA、LoRA-fa、LoRA-drop、DoRA、Delta-LoRAなどがあります。各手法について詳しくは紹介しませんので、興味のある方は関連文献をご参照ください。
もちろん、私たちの技術的ニーズを満たすための他の迅速なエンジニアリング手法(RAGテクノロジーなど)もいくつか存在しますので、今後の記事でそれらについても紹介していく予定です。
次に、フルパラメータでGPT-2を微調整する例を示します。
取引戦略の策定
取引戦略に関しては、大規模言語モデルの微調整を導くために簡単な例を使用し、一時的にEAの実装には関与しません(具体的な実装は、EAを合理的に作成する前に、我々の完全な大規模言語モデルの推論戦略が完成するまで待つ必要がある)。まず、ある通貨ペアのある期間の直近20相場の終値をクライアントから取得し、その平均値をAと定義します。次に、大規模言語モデルを使って、同じ期間の次の40相場の終値を予測し、その平均値をBと定義します。そして、予測値に従って、次に買うか売るかを判断します。
- 40の予測値の平均値Bが、現在の直近20終値の平均値Aより大きければ買い。
- 40の予測値の平均値Bが、現在の直近20終値の平均値Aより小さければ売り。
- AとBが等しいか非常に近い場合は、操作しない。
これで取引戦略の策定は完了しました。これはデモ用のかなり単純な取引戦略であり、理想化されたものかもしれません。入力をダイナミックに変更し、予測結果の長さの合計を60から入力の長さを引くなど、必要に応じてこの戦略を置き換えることもできます。あるいは、波動戦略、ワニ戦略、タートル戦略に基づいてルールを策定するなど、他の取引ロジックを直接利用することもできます。次に、戦略に従ってデータセットを作成し、大規模言語モデルの微調整を開始します。
データセットの作成
大規模言語モデルの学習について説明したときに、すでにデータセットを作っています。それは「llm_data.csv」ファイルに含まれる内容です。このデータセットには5M周期の通貨ペアの気配値のみが含まれており、それに応じて64列の合計2442行のデータが処理されています。具体的な処理方法については、本連載のCPUやGPUを使った大規模言語モデルの学習編(具体的なリンクは「独自のLLMをEAに統合する(第3部):CPUを使った独自のLLMの訓練 - MQL5 Articles」です。もちろん、記事で提供されているスクリプトを使ってデータセットを再カスタマイズしたり、自分の優れたアイデアをデータセットにすることもできます(政府財政データと為替レートの相関関係をデータセットにするなど)。要するに、このデータセットは数値だけでなく、どのような形式でも構いません。
1. 前処理まず、必要なライブラリをインポートします。
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from transformers import TextDataset, DataCollatorForLanguageModeling from transformers import Trainer, TrainingArguments import torch
データファイルを読みます。
df = pd.read_csv('llm_data.csv') このデータセットを更新しました。このデータセットには、元の64の代わりに、各行に5M周期の通貨ペアの終値が60含まれるようになり、データはテキスト形式に処理されています。
sentences = [' '.join(map(str, prices)) for prices in df.iloc[:-10,1:].values]
このコード行は、主にDataframeファイル全体を読み込み、その要素を走査し、各行を文字列に変換し、それらを1つの文として扱い、各文には60の終値が含まれます。つまり、“0.6119 0.61197 0.61201…0.61196”のように変換し、“0.6119” “0.61197”…“0.61196”ではありません。これは、設定した配列の長さを言語モデルに記憶させるためで、たとえば20個のデータを入力すると、私たちがコントロールできない内容を出力する代わりに、モデルが残りの40個のデータを完成させてくれます。
また、このコード行には説明が必要な特別な場所があります。df.iloc[:-10,1:].valuesです。「:-10」はcsvファイルの先頭から最後の10行を取得し、残りの10行をテスト用に残すことを意味します。「1:」は、各行の最初の列を削除します。この列はcsvファイル内のインデックス値であり、必要ありません。
そうすれば、次回からはcsvファイルを何度も処理する必要がなく、処理したファイルを直接読み込むだけで済みます。
with open('train.txt', 'w') as f: for sentence in sentences: f.write(sentence + '\n')
2. データをDatasetクラスとしてロードする
データの前処理が終わった後、さらにトークナイザーを使ってデータを処理し、pytorchのDatasetデータフォーマットにロードする必要があります。現在、よく使われるいくつかのクラスがTransformersライブラリに統合され、この作業を直接おこなえるようになっています。この記事の例では、TextDatasetを直接使ってこの機能を実現することができ、とても簡単ですが、まずGPT2を使ってトークナイザをインスタンス化する必要があります。GPT2をロードしたことがない場合、初めて使用するとき、TransformersライブラリはHuggingfaceから事前学習ファイルをダウンロードするので、ネットワークがブロックされていないことを確認してください。特にdockerやwslを使っている方は、ネットワーク設定が正しいかどうか確認してください。
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
train_dataset = TextDataset(tokenizer=tokenizer,
file_path="train.txt",
block_size=60) 3. 言語モデルのデータをロードする
ここでは、データをインスタンス化するために、TransformerライブラリのDataCollatorForLanguageModelingクラスを直接使用しています。
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
次に、事前に訓練されたモデルをロードし、微調整してみましょう。
モデルの微調整
微調整のためのデータセットを準備したら、大規模言語モデルの微調整を開始することができます。
1. 事前学習済みモデルのロード
モデルを微調整する最初のステップは、事前に訓練されたモデルをロードすることです。すでにトークナイザーをロードしたので、ここではモデルをロードするだけですみます。
model = GPT2LMHeadModel.from_pretrained('gpt2') 次に、訓練パラメータを設定する必要があります。また、Transformersライブラリーは、追加の設定ファイルを必要とせず、この機能を実装するための非常に便利なクラスを提供してくれます。
training_args = TrainingArguments(output_dir="./gpt2_stock", overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=32, save_steps=10_000, save_total_limit=2, load_best_model_at_end=True, )
2. 微調整パラメータの初期化
TrainingArgumentsをインスタンス化する際、以下のパラメータを使用しました。
- output_dir:予測結果とチェックポイントを保存する場所(カレントディレクトリのgpt2_stockフォルダを出力パスとして定義)
- overwrite_output_dir:出力ファイルを上書きするかどうか(上書きを選択)
- num_train_epochs:訓練エポック数(3を選択)
- per_device_train_batch_size:訓練のバッチサイズ(先ほど紹介した2のべき乗である32を選択)
- save_steps=10_000:save_strategy=steps場合、2回のチェックポイント保存がおこなわれるまでの更新ステップ数。[0,1)の範囲の整数または浮動小数点数。1より小さい場合は、総訓練ステップの比率として解釈されます。
- save_total_limit:値が渡された場合、チェックポイントの総量を制限します。output_dir内の古いチェックポイントを削除します。
- load_best_model_at_end:訓練の最後の段階でモデルの重みを使用するのではなく、訓練の過程で最適なモデルをロードするかどうか。
あくまで例なので、例えばこのクラスを詳細に定義していないため、設定せずデフォルト値を使用したパラメータがたくさんあります。
- deepspeed:ディープスピードを使って訓練を加速させるかどうか
- eval_steps:2つの評価間の更新ステップ数
- dataloader_pin_memory:データローダーにメモリーを固定するかどうか
このTrainingArgumentsクラスは非常に強力で、訓練パラメータのほとんどを含み、使い勝手が非常に良いことがお分かりいただけると思います。
3. 微調整
さて、微調整プロセスに戻りましょう。微調整プロセスを定義することができますが、言語モデルの学習プロセスについては前回の記事で詳述しました。そのため、微調整のプロセスは訓練のプロセスと大差ありません。読者の皆さんはすでによくご存知だと思いますので、この記事では言語モデルの微調整プロセスを詳細に説明するのではなく、Transformerライブラリで提供されているTrainerクラスを直接使用して実装します。ここで、パラメータとして定義したモデル、training_args、data_collator、train_datasetをTrainerクラスに渡して、Trainerをインスタンス化します。
trainer = Trainer(model=model, args=training_args, data_collator=data_collator, train_dataset=train_dataset,)
Trainerクラスには、重要なコールバックなど、設定しなかったパラメータも存在します。コールバックを使用することで、訓練ループの動作をカスタマイズできます。これらのコールバックは、訓練ループの状態をチェックしたり(進捗報告、TensorBoardや他のMLプラットフォームへのロギングなど)、早期停止などの決定を下すことができます。この記事で設定しなかったのは一例に過ぎず、微調整の過程におけるモデルのパラメータ設定は比較的保守的です。もしモデルの性能を向上させたいのであれば、このオプションを無視してはいけないことを覚えておいてください。インスタンス化されたTrainerクラスのtran()メソッドを呼び出せば、微調整プロセスを直接実行できます。
trainer.train()
学習が終わったらモデルを保存し、推論するときにfrom_pretrained()メソッドを直接使って微調整されたモデルをロードできるようにします。
trainer.save_model("./gpt2_stock") 次に、微調整が効果的かどうかをチェックするために推論をしてみましょう。
prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1]))
generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt').to("cuda"),
do_sample=True,
max_length=200)[0],
skip_special_tokens=True)
print(f"test the model:{generated}") この部分では、「prompt = '.join(map(str, df.iloc[:,1:20].values[-1])」がデータセットの最後の行を文字列形式に変換しています。「tokenizer.encode(prompt, return_tensors='pt')」は、入力テキスト(プロンプト)をモデルが理解できる形式に変換します。つまり、テキストを一連のトークンに変換します。「return_tensors='pt'」は、返されるデータ型がPyTorchのテンソルであることを示します。「do_sample=True」は生成処理でランダムサンプリングが使用されることを示し、「max_length=200」は生成されるテキストの最大長を制限します。では、コード全体を実行した結果を見てみましょう。

微調整された事前学習モデルは、私たちが望んでいた結果をうまく出力していることがわかります。
添付ファイルのスクリプト名はFin-tuning.pyです。
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from transformers import TextDataset, DataCollatorForLanguageModeling from transformers import Trainer, TrainingArguments import torch dvc='cuda' if torch.cuda.is_available() else 'cpu' print(dvc) df = pd.read_csv('llm_data.csv') sentences = [' '.join(map(str, prices)) for prices in df.iloc[:-10,1:].values] with open('train.txt', 'w') as f: for sentence in sentences: f.write(sentence + '\n') tokenizer = GPT2Tokenizer.from_pretrained('gpt2') train_dataset = TextDataset(tokenizer=tokenizer, file_path="train.txt", block_size=60) data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False) model = GPT2LMHeadModel.from_pretrained('gpt2') training_args = TrainingArguments(output_dir="./gpt2_stock", overwrite_output_dir=True, num_train_epochs=3, per_device_train_batch_size=32, save_steps=10_000, save_total_limit=2, load_best_model_at_end=True, ) trainer = Trainer(model=model, args=training_args, data_collator=data_collator, train_dataset=train_dataset,) trainer.train() trainer.save_model("./gpt2_stock") prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt').to(dvc), do_sample=True, max_length=200)[0], skip_special_tokens=True) print(f"test the model:{generated}")
テスト
微調整が完了した後も、モデルをテストし、モデルの出力と元の真の値とのギャップをチェックする必要があります。最も簡単な方法は、真の値と予測値との平均二乗誤差(MSE)を計算することです。
まず必要なライブラリをインポートし、微調整したGPT2モデルとデータをロードします。
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from sklearn.metrics import mean_squared_error import torch import numpy as np df = pd.read_csv('llm_data.csv') dvc='cuda' if torch.cuda.is_available() else 'cpu' model = GPT2LMHeadModel.from_pretrained('./gpt2_stock') tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
このプロセスは、モデルのパスが微調整の際にモデルの重みを保存したパスに変更されることを除けば、微調整のプロセスと大差はありません。モデルとトークナイザをロードした後、推論後の真の値と予測値を処理する必要があります。この部分も、微調整スクリプトのステップと同じです。
prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt'), do_sample=True, max_length=200)[0], skip_special_tokens=True)
ここで、データセットの最後の行の終値40件を真の値とし、真の値と予測値をリスト形式に変換すると、長さが一致します。
true_prices= df.iloc[-1:,21:].values.tolist()[0] generated_prices=generated.split('\n')[0] generated_prices=list(map(float,generated_prices.split())) generated_prices=generated_prices[0:len(true_prices)] def trim_lists(a, b): min_len = min(len(a), len(b)) return a[:min_len], b[:min_len] true_prices,generated_prices=trim_lists(true_prices,generated_prices)
真の値と予測値を同じ長さに保つためには、最小のリストの長さに従って別のリストをカットする必要があるので、このタスクを完了するために trim_lists(a, b) を定義します。そして、真の値と予測値を表示し、それらが期待値を満たしているかどうかを確認します。
print(f"true_prices:{true_prices}") print(f"generated_prices:{generated_prices}")
結果は以下の通りです。
true_prices: [0.6119, 0.61197, 0.61201, 0.61242, 0.61237, 0.6123, 0.61229, 0.61242, 0.61212, 0.61197, 0.61201, 0.61213, 0.61212,
0.61206, 0.61203, 0.61206, 0.6119, 0.61193, 0.61191, 0.61202, 0.61197, 0.6121, 0.61211, 0.61214, 0.61203, 0.61203, 0.61213, 0.61218,
0.61227, 0.61226, 0.61227, 0.61231, 0.61228, 0.61227, 0.61233, 0.61211, 0.6121, 0.6121, 0.61195, 0.61196]
generated_prices:[0.61163, 0.61162, 0.61191, 0.61195, 0.61209, 0.61231, 0.61224, 0.61207, 0.61187, 0.61184, 0.6119, 0.61169, 0.61168、
0.61162, 0.61181, 0.61184, 0.61184, 0.6118, 0.61176, 0.61169, 0.61191, 0.61195, 0.61204, 0.61188, 0.61205, 0.61188, 0.612, 0.61208,
0.612, 0.61192, 0.61168, 0.61165, 0.61164, 0.61179, 0.61183, 0.61192, 0.61168, 0.61175, 0.61169, 0.61162]
次に、平均二乗誤差(MSE)を計算し、結果を出力して確認することができます。
mse = mean_squared_error(true_prices, generated_prices)
print('MSE:', mse) 結果はMSE:2.1906250000000092e-07です。
ご覧の通り、MSEは非常に小さいですが、これは本当にモデルが非常に正確であることを意味するのでしょうか。元データは非常に小さな値であることを忘れないでください。このため、MSEは非常に小さいですが、元の値も比較的小さいため、現時点ではMSEはモデルの精度を正確に反映することはできません。さらに、予測値と元の値の間の二乗平均平方根誤差(RMSE)と正規化二乗平均平方根誤差(NRMSE)を計算し、観測値の範囲に対する予測誤差の大きさを決定し、モデルの精度を決定する必要があります。
rmse=np.sqrt(mse) nrmse=rmse/(np.max(true_prices)-np.min(generated_prices)) print(f"RMSE:{rmse},NRMSE:{nrmse}")
結果は
- RMSE:0.00046804113067122735
- NRMSE:0.5850514133390986

MSEとRMSEの値は非常に小さいですが、NRMSEの値は0.5850514133390986であり、これは予測誤差が観測値の範囲の約58.5%を占めていることを意味します。これは、RMSEの絶対値は非常に小さいものの、観測値の範囲と比較すると、予測誤差は依然として比較的大きいことを示しています。
では、どうすればモデルの精度を上げることができるのでしょうか。選択肢はいくつかあります。
- 微調整中のエポック数を増やす
- データ量を増やす
- 微調整パラメータを適切に最適化する
- より大きなスケールのモデルに交換する
これらの方法は実装が難しくありません。この記事では、それぞれの方法を1つずつ検証することはしませんが、自分のアイデアに応じて1つまたは複数の方法を選択して実装してください。結果は、間違いなくこの記事の例よりもはるかに良いものになるでしょう。
添付ファイルのスクリプト名はtest.pyです。
import pandas as pd from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config from sklearn.metrics import mean_squared_error import torch import numpy as np df = pd.read_csv('llm_data.csv') dvc='cuda' if torch.cuda.is_available() else 'cpu' model = GPT2LMHeadModel.from_pretrained('./gpt2_stock') tokenizer = GPT2Tokenizer.from_pretrained('gpt2') prompt = ' '.join(map(str, df.iloc[:,1:20].values[-1])) generated = tokenizer.decode(model.generate(tokenizer.encode(prompt, return_tensors='pt'), do_sample=True, max_length=200)[0], skip_special_tokens=True) true_prices= df.iloc[-1:,21:].values.tolist()[0] generated_prices=generated.split('\n')[0] generated_prices=list(map(float,generated_prices.split())) generated_prices=generated_prices[0:len(true_prices)] def trim_lists(a, b): min_len = min(len(a), len(b)) return a[:min_len], b[:min_len] true_prices,generated_prices=trim_lists(true_prices,generated_prices) print(f"true_prices:{true_prices}") print(f"generated_prices:{generated_prices}") mse = mean_squared_error(true_prices, generated_prices) print('MSE:', mse) rmse=np.sqrt(mse) nrmse=rmse/(np.max(true_prices)-np.min(generated_prices)) print(f"RMSE:{rmse},NRMSE:{nrmse}")
結論
本稿では主に、大規模言語モデルを取引戦略に活用するための前提条件について説明しました。具体的には、大規模言語モデルの出力が取引戦略の要件を満たしている必要があることを強調しました。また、このタスクを達成するためにいくつかの技術的手法についても議論しました。紙面の都合上、すべての手法に関連するコード例を示すことはできませんでしたが、フルパラメータでGPT-2を微調整した例を紹介しました。もちろん、このデータセットは本文で言及したすべての微調整手法に適用できるわけではなく、後述の詳細な例で手法に適したデータセット作成方法を示す予定です。しかしご心配なく。次の記事では代表的な手法をいくつか選び、関連するコード例とそれにマッチしたEAの例を提供します。また、RAGテクノロジーとエージェントテクノロジーについても簡単に触れていますが、詳細な議論と関連コードの実装を提供する特別記事も用意しています。
準備はいいですか。では、次の記事でお会いしましょう。
参照文献
https://alexqdh.github.io/posts/2183061656/
http://note.iawen.com/note/llm/finetune
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/13497
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索