Gibt es ein Muster in diesem Chaos? Lassen Sie uns versuchen, es zu finden! Maschinelles Lernen am Beispiel einer bestimmten Stichprobe.
Ich schlage vor, die Datei über den Link herunterzuladen. Es gibt 3 csv-Dateien im Archiv:
- train.csv - die Probe, auf der Sie trainieren müssen.
- test.csv - eine Hilfsstichprobe, die während des Trainings verwendet werden kann, einschließlich der Zusammenführung mit train.
- exam.csv - eine Probe, die in keiner Weise am Training teilnimmt.
Die Probe selbst enthält 5581 Spalten mit Prädiktoren, das Ziel in 5583 Spalte "Target_100", Spalten 5581, 5582, 5584, 5585 sind Hilfsspalten und enthalten:
- 5581 Spalte "Zeit" - Datum des Signals
- 5582 Spalte "Ziel_P" - Richtung des Handels "+1" - Kauf / "-1" - Verkauf
- 5584 Spalte "Target_100_Buy" - finanzielles Ergebnis des Kaufs
- 5585 Spalte "Target_100_Sell" - finanzielles Ergebnis des Verkaufs.
Das Ziel ist es, ein Modell zu erstellen, das mehr als 3000 Punkte in der exam.csv Probe "verdient".
Die Lösung sollte ohne Einblick in die Prüfung sein, d.h. ohne Verwendung von Daten aus dieser Probe.
Um das Interesse aufrechtzuerhalten, ist es wünschenswert, über die Methode zu berichten, die es ermöglicht hat, ein solches Ergebnis zu erzielen.
Stichproben können auf jede beliebige Weise transformiert werden, einschließlich der Änderung des Ziels, aber Sie sollten das Wesen der Transformation erklären, so dass es sich nicht um eine reine Anpassung an die Prüfungsstichprobe handelt.
Das Training von CatBoost mit den untenstehenden Einstellungen - mit Seed brute force - ergibt diese Wahrscheinlichkeitsverteilung.
FOR %%a IN (*.) DO ( catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_8\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 8 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 16 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_24\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 24 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 32 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_40\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 40 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 48 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_56\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 56 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 64 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_72\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 72 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 80 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
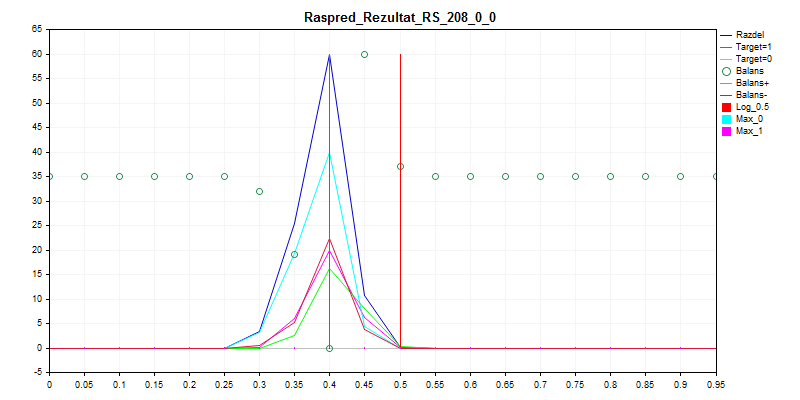
1. Sampling Zug

2. Stichprobe Test
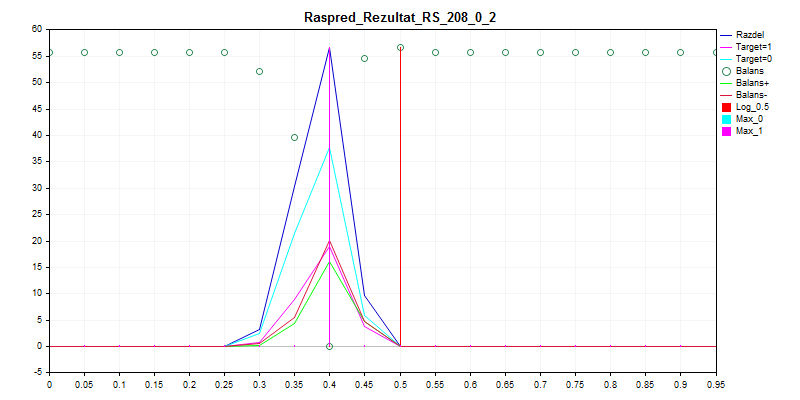
3. Probe Prüfung
Wie Sie sehen können, zieht es das Modell vor, fast alles mit Null zu klassifizieren - so ist die Wahrscheinlichkeit eines Fehlers geringer.
Die letzten 4 Spalten
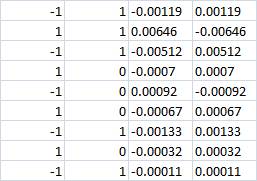
Bei 0 Klasse sollte der Verlust in beiden Fällen offensichtlich sein? D.h. -0,0007 in beiden Fällen. Oder wenn die Kauf-/Verkaufswette trotzdem gemacht wird, machen wir dann einen Gewinn in der richtigen Richtung?
Letzte 4 Spalten
Bei 0 Klasse sollte der Verlust offenbar in beiden Fällen sein? D.h. -0,0007 in beiden Fällen. Oder wenn die Kauf/Verkaufs-Wette trotzdem gemacht wird, machen wir dann einen Gewinn in der richtigen Richtung?
Bei Null Grad - den Handel nicht eingehen.
Früher habe ich 3 Ziele verwendet - deshalb die letzten beiden Spalten mit Fin-Ergebnissen statt einem, aber mit CatBoost musste ich auf zwei Ziele umsteigen.
Die 1/-1 Richtung wird durch eine andere Logik ausgewählt, d.h. der MO ist nicht an der Richtungsauswahl beteiligt? Sie müssen nur lernen, 0/1 zu handeln bzw. nicht zu handeln (wenn die Richtung starr gewählt wird)?
Ja, das Modell entscheidet nur, ob man einsteigt oder nicht. Im Rahmen dieses Experiments ist es jedoch nicht verboten, ein Modell mit drei Zielen zu erlernen; zu diesem Zweck genügt es, das Ziel unter Berücksichtigung der Einstiegsrichtung zu transformieren.
Wenn die Klasse Null ist, geben Sie die Transaktion nicht ein.
Früher habe ich 3 Ziele verwendet - deshalb die letzten beiden Spalten mit dem finanziellen Ergebnis anstelle von einem, aber mit CatBoost musste ich zu zwei Zielen wechseln.
Ja, das Modell entscheidet nur, ob es eintritt oder nicht. Im Rahmen dieses Experiments ist es jedoch nicht verboten, dem Modell drei Ziele beizubringen, dazu genügt es, das Ziel unter Berücksichtigung der Einstiegsrichtung zu transformieren.
Wenn die Klasse Null ist, geben Sie die Transaktion nicht ein.
Früher habe ich 3 Ziele verwendet - deshalb die letzten beiden Spalten mit dem finanziellen Ergebnis anstelle von einem, aber mit CatBoost musste ich zu zwei Zielen wechseln.
Ja, das Modell entscheidet nur, ob es eintritt oder nicht. Im Rahmen dieses Experiments ist es jedoch nicht verboten, dem Modell drei Ziele beizubringen; zu diesem Zweck genügt es, das Ziel unter Berücksichtigung der Einstiegsrichtung zu transformieren.
Catbusta hat eine Multiklasse, es ist seltsam, 3 Klassen aufzugeben
D.h. wenn bei der Klasse 0 (nicht eingeben) die richtige Richtung der Transaktion gewählt wird, gibt es dann einen Gewinn oder nicht?
Es wird keinen Gewinn geben (wenn Sie eine Neubewertung vornehmen, wird es einen kleinen Prozentsatz an Gewinn bei Null geben).
Es ist nur möglich, das Ziel korrekt umzuwandeln, indem man "1" in "-1" und "1" zerlegt, ansonsten ist es eine andere Strategie.
Es gibt sie, aber es gibt keine Integration in MQL5.
Es gibt kein Entladen von Modellen in irgendeine Sprache.
Wahrscheinlich ist es möglich, eine dll-Bibliothek hinzuzufügen, aber ich kann es nicht herausfinden, auf meine eigene.
Es wird keinen Gewinn geben (wenn Sie eine Neubewertung vornehmen, wird ein kleiner Prozentsatz des Gewinns bei Null liegen).
Dann haben die Spalten mit den Finanzergebnissen wenig Sinn. Es werden auch Fehler der Klasse 0 prognostiziert (statt 0 werden wir 1 prognostizieren). Und der Preis des Fehlers ist unbekannt. Das heißt, die Bilanzlinie wird nicht erstellt werden. Zumal Sie 70% der Klasse 0 haben. D.h. 70% der Fehler mit unbekanntem finanziellen Ergebnis.
Sie können 3000 Punkte vergessen. Wenn das der Fall ist, wird es unzuverlässig sein.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich schlage vor, die Datei über den Link herunterzuladen. Das Archiv enthält 3 csv-Dateien:
Die Probe selbst enthält 5581 Spalten mit Prädiktoren, das Ziel in 5583 Spalte "Target_100", Spalten 5581, 5582, 5584, 5585 sind Hilfsspalten und enthalten:
Das Ziel ist es, ein Modell zu erstellen, das mehr als 3000 Punkte in der exam.csv Probe "verdient".
Die Lösung sollte ohne Einblick in die Prüfung sein, d.h. ohne Verwendung von Daten aus dieser Probe.
Um das Interesse aufrechtzuerhalten, ist es wünschenswert, über die Methode zu berichten, die es ermöglicht hat, ein solches Ergebnis zu erzielen.
Die Stichproben können auf jede beliebige Weise transformiert werden, einschließlich der Änderung der Zielstichprobe, aber Sie sollten die Art der Transformation erklären, so dass es sich nicht um eine reine Anpassung an die Prüfungsstichprobe handelt.