Gibt es ein Muster in diesem Chaos? Lassen Sie uns versuchen, es zu finden! Maschinelles Lernen am Beispiel einer bestimmten Stichprobe. - Seite 29
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Nun, das ist nur Ihr System, und es hat nichts mit den Daten zu tun, die ich angegeben habe, denn Sie haben keine anderen Daten zur Analyse verwendet, oder?
Ich hänge eine Datei an - bitte wenden Sie darauf das Modell an, das Sie zuvor trainiert haben - ich bin an dem Ergebnis interessiert.
PR=183856 +Geschäfte=693 -Geschäfte=18
Bei Spread=0 und Kommission=0.
Ihre Genetik ist also für die Daten verantwortlich, die in die Eingänge des Netzwerks eingespeist werden? Und die Daten selbst sind die Zeitreihenverzerrung?
Die Antwort auf die erste Frage habe ich bereits geschrieben ... :) Keine Verzerrung.
Mit freundlichen Grüßen, RomFil.
Auch für verschiedene Teile der Graphen benötigen wir unterschiedliche Tiefen von Stichproben, die in den Eingang der neuronalen Netze eingespeist werden. Das heißt, dass neuronale Netze mit unterschiedlichen Abtasttiefen in verschiedenen Teilen des Graphen eine unterschiedliche Genauigkeit aufweisen. Das "richtige" Komitee ermöglicht also eine korrekte Reaktion auf die gesamte Länge der Stichproben. Und vor allem, dass dieser Ausschuss selbst diese Korrektheit bestimmt. Vielleicht sind das schon die Grundlagen der KI ... :)
Interessant.
Ich selbst trainiere und vergleiche auf 5, 10, 20, 50 Tausend Zeilen und jeder handelt anders mit unterschiedlichen Ergebnissen. Sie miteinander zu kombinieren ist eine interessante Idee. Bilden Sie einen Durchschnitt?
Wenn man den Durchschnitt der verschiedenen Handelsmodelle ermittelt, widersprechen sie sich normalerweise und fangen an, seltener zu handeln, nur wenn die Mehrheit zustimmt.
Wie können 5-10 Modelle selbst die Korrektheit bestimmen? Meinen Sie den Durchschnitt?
PR=183856 +Gewerbe=693 -Gewerbe=18
Bei Spread=0 und Kommission=0.
Versuchen Sie, das Modell auf diese Daten anzuwenden und ich werde Sie nicht mehr damit quälen :)
Nun, das ist nur Ihr System, und es hat nichts mit den Daten zu tun, die ich angegeben habe, denn Sie haben keine anderen Daten zur Analyse verwendet, oder?
Ich hänge eine Datei an - bitte wenden Sie darauf das Modell an, das Sie zuvor trainiert haben - ich bin an dem Ergebnis interessiert.
Wie sich herausstellte, spielt es keine Rolle, welche Daten ...
Tatsächlich sieht der Graph, der von diesem Algorithmus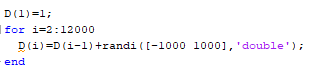 gebildet wird, wie folgt aus (und bei jedem Durchlauf erhält man aus bekannten Gründen einen anderen Graphen):
gebildet wird, wie folgt aus (und bei jedem Durchlauf erhält man aus bekannten Gründen einen anderen Graphen):
Trainee-Stichprobe erste 10000 Werte, die restlichen 2000 sind ein Test.
Das Ergebnis ist dieses:
PR=406206 +Handel=299 -Handel=34
Dies ist das Ende der Geschichte. Alles Gute und dass Träume wahr werden.
Mit freundlichen Grüßen, RomFil.
Versuchen Sie, das Modell erneut auf diese Daten anzuwenden, und ich werde Sie nicht mehr damit quälen :)
PR=116823 +Geschäfte=977 -Geschäfte=16
Die Antwort auf die erste Frage ist bereits geschrieben worden ... :) Kein Versatz.
Mit freundlichen Grüßen, RomFil.
Du schreibst selbst " Ja, fast reine Werte, verschiedene Tiefen, verschiedene Fenster, usw. ".
Das Ergebnis ist folgendes:
PR=406206 +Gewerbe=299 -Gewerbe=34
Es gibt 2000 Signale auf dem Chart, aber Sie haben 333 in der Beschreibung - oder ich verstehe wieder etwas nicht....
Okay, wenn dies der Chart des letzten Beispiels ist, stellt sich heraus, dass das auf EURUSD trainierte Modell perfekt auf 3 verschiedenen Währungsinstrumenten funktioniert, einschließlich Cross. Ich denke, es ist Zeit für einen Nobelpreis!
Dies ist das Ende der Geschichte. Alles Gute und dass Träume wahr werden.
Mit freundlichen Grüßen, RomFil.
Vielen Dank für den interessanten Abend und alles Gute für Sie!
PR=116823 +Gewerbe=977 -Gewerbe=16
Schock, Schock.
Der von diesem Algorithmus erzeugte Graph sieht wie folgt aus (und bei jedem Start wird aus bekannten Gründen ein anderer Graph erhalten):
Auf einem zufälligen Graphen und Training auf ihm?
Interessant.
Ich selbst unterrichte und vergleiche auf 5,10,20,50k Linien und jeder handelt anders mit unterschiedlichen Ergebnissen. Sie miteinander zu kombinieren ist eine interessante Idee. Machen Sie einen Durchschnitt?
In der Regel, wenn Sie Durchschnitt Handelsmodelle, widersprechen sie einander und beginnen zu handeln weniger oft, nur dann, wenn die meisten von ihnen zustimmen.
Wie können 5-10 Modelle die Korrektheit selbst bestimmen? Meinen Sie den Durchschnitt?
Sie stellen die richtigen Fragen!!! :)
Aber ich werde dieses Geheimnis nicht verraten. :) Aber ich werde eines sagen: Das Ergebnis des Ausschusses selbst bestimmt die "Korrektheit" dieses oder jenes Netzwerks. Keine Mittelwertbildung.