Gibt es ein Muster in diesem Chaos? Lassen Sie uns versuchen, es zu finden! Maschinelles Lernen am Beispiel einer bestimmten Stichprobe. - Seite 11
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Das ist der Punkt, es ist um den Faktor 2 besser als bei 5000+ Features.
Es stellt sich heraus, dass alle anderen 5000+ Chips das Ergebnis nur verschlechtern. Obwohl, wenn Sie sie auswählen, finden Sie sicherlich einige verbessernde.
Es ist interessant zu vergleichen, was Ihr Modell auf diese 2 zeigen wird.
Ich habe mat. Erwartung ein wenig mehr als eine, Gewinn innerhalb von 5 Tausend, die Genauigkeit schreibt 51% - dh die Ergebnisse sind deutlich schlechter.
Ja, und auf dem Testmuster habe ich einen Verlust in allen 100 Modellen.Ich habe mat. Erwartung ein wenig mehr als ein, Gewinn innerhalb von 5 Tausend, sagt die Genauigkeit 51% - das heißt, die Ergebnisse sind deutlich schlechter.
Ja, und bei der Teststichprobe gab es bei allen 100 Modellen einen Verlust.Aber bei der ersten Stichprobe gibt es auch Verluste.
Bei der zweiten H1-Probe? Ich verbessere mich bei dieser Probe.
Und bei der ersten Probe verliere ich auch.
Ja, ich spreche von der H1-Stichprobe. Ich trainiere zunächst auf train.csv, stoppe auf test.csv und prüfe unabhängig auf exam.csv, so dass die Variante mit zwei Spalten auf test.csv durchfällt. Die gestrigen Varianten fielen auch durch, aber es gab auch welche, die ein bisschen Geld verdient haben.
Was für Wundertabellen haben Sie also?Und dies ist, wie Valving vorwärts mit Ausbildung auf 20000 Zeilen in 10000 Zeilen. Das heißt, das Diagramm zeigt nicht 2 Jahre, sondern 5. 2 Jahre davon müssen im Drawdown sitzen, dann ein weiteres Jahr ohne Gewinn, wodurch der durchschnittliche Gewinn wieder auf 0,00002 pro Trade fällt. Auch nicht gut für den Handel.
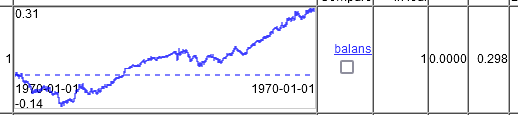
Nur auf 2 Zeitspalten.
Die gleichen Einstellungen auf allen 5000+ Spalten. Geringfügig besser. 0,00003 pro Handel.
Gewinn 0,20600, im Durchschnitt 0,00004 pro Handel. Angemessen mit dem Spread
Ja, die Zahl ist schon beeindruckend. Allerdings ist das Ziel markiert zu verkaufen, und da der gesamte Zeitraum auf einem großen TF ist der Verkauf, ich denke, es auch künstlich verbessert das Ergebnis.
Es ist mehr als 0,00002 auf allen Spalten, aber wie ich schon sagte "Spread, Slippages, etc. fressen den ganzen Gewinn auf". Teriminal zeigt den minimalen Spread pro Balken an (d.h. während der gesamten Stunde), aber im Moment eines Handels kann er 5 - 10 Punkte betragen, und bei Nachrichten kann er 20 und mehr betragen.
Der Aufschlag, den ich habe, wird also auf Minuten-Balken genommen, die Spreads weiten sich in der Regel im Laufe der Zeit aus, d.h. innerhalb einer Minute wird es wahrscheinlich immer einen großen Spread geben, oder ist das jetzt nicht so? Ich habe noch nicht einmal herausgefunden, wie der Spread in 5 funktioniert - ich finde es für Tests in 4 bequemer.
Du solltest nach Modellen mit einem durchschnittlichen Gewinn von mindestens 0,00020 pro Handel suchen. Im realen Handel können Sie dann 0,00010 erreichen. Dies gilt für EURUSD, bei anderen Paaren wie AUD NZD reichen selbst 50 Pkte. nicht aus, dort liegen die Spreads bei 20-30 Pkte.
Ich stimme zu. Das erste Beispiel in diesem Thread gibt eine Erwartung von 30 Pips an. Deshalb bleibe ich bei der Meinung, dass der Aufschlag smart sein sollte.
Nun, das ist wieder der beste Chart auf der Prüfung Probe. Wie von trayne zu wählen Einstellungen, die dann die beste Bilanz auf die Prüfung ein ist eine Frage ohne eine Lösung. Man wählt nach Test. Ich habe auf Ausbildung+Test trainiert. Im Grunde, was Sie haben eine Prüfung, ich habe einen Test.
Ich denke, Sie sollten damit beginnen, dass die Mehrheit der Stichprobe die Auswahlschwelle erreicht. Außerdem könnte es sinnvoll sein, das am wenigsten trainierte Modell von allen zu wählen - es hat weniger Anpassungen.
Und so geht es weiter mit dem Training auf 20000 Zeilen in 10000 Zeilen. D.h. auf dem Graphen nicht 2 Jahre, sondern 5. 2 Jahre davon müssen im Drawdown sitzen, dann ein weiteres Jahr ohne Gewinn, dadurch ist der durchschnittliche Gewinn wieder auf 0,00002 pro Trade gesunken. Auch nicht gut für den Handel.
Nur auf 2 Zeitspalten.
Die gleichen Einstellungen auf allen 5000+ Spalten. Geringfügig besser. 0,00003 pro Handel.
Es zeigt sich jedoch, dass auch die anderen Prädiktoren nützlich sein können. Man kann versuchen, sie in Gruppen zusammenzufassen, man kann sie zunächst auf Korrelation untersuchen und sie dann leicht reduzieren.
Was die Erwartungsmatrix betrifft, so ist es bei dieser Strategie vielleicht profitabler, nicht bei der Kerzeneröffnung einzusteigen, sondern 30 Pips vom Eröffnungskurs entfernt - Kerzen ohne Schwanz sind selten.
Der Aufschlag, den ich habe, wird also auf Minuten-Balken genommen, die Spreads weiten sich normalerweise über einen bestimmten Zeitraum aus, d.h. innerhalb einer Minute wird es wahrscheinlich immer einen großen Spread geben, oder ist das jetzt nicht so? Ich habe noch nicht einmal herausgefunden, wie der Spread in 5 funktioniert - für mich ist es bequemer für Tests in 4.
Und auch bei M1 wird der Mindestspread für die Barzeit eingehalten. Auf ECH-Konten haben fast alle M1-Bars 0,00001...0,00002 selten mehr. Alle Senior-Balken sind aus M1 aufgebaut, d.h. der gleiche Mindestspread wird eingehalten. Sie müssen 4 pts. Kommission pro Runde hinzufügen (andere Maklerzentren können andere Kommissionen haben).
Es stellt sich jedoch heraus, dass auch die anderen Prädiktoren nützlich sein können. Man kann versuchen, sie in Gruppen zusammenzufassen, man kann sie zunächst auf Korrelation prüfen und sie dann leicht reduzieren.
Vielleicht sollten wir sie auswählen. Aber wenn das Hinzufügen von 5000+ zu 2 eine kleine Verbesserung bringt, könnte es schneller sein, 10 Stück mit voller roher Gewalt mit Modelltraining auszuwählen. Ich denke, das wäre schneller, als 24 Stunden lang auf die Korrelation zu warten. Es ist nur notwendig, das erneute Training in einer Schleife direkt vom Terminal aus zu automatisieren.
Hat katbusta nicht eine DLL-Version? Die DLL kann direkt vom Terminal aus aufgerufen werden. Es gab einen Artikel mit Beispielen hier. https://www.mql5.com/ru/articles/18 und https://www.mql5.com/ru/articles/5798.
Vielleicht sollten wir auswählen. Aber wenn die Hinzufügung von 5000+ zu den 2ern eine kleine Verbesserung bringt, könnte es schneller sein, 10 Stücke mit voller roher Gewalt und Modelltraining auszuwählen. Ich denke, das wäre schneller, als 24 Stunden lang auf die Korrelation zu warten.
Ja, es ist besser, am Anfang in Gruppen zu arbeiten - man kann z. B. 10 Gruppen bilden und mit deren Kombinationen trainieren, die Modelle auswerten, die erfolglosesten Gruppen eliminieren und die verbleibenden neu gruppieren, d. h. die Anzahl der Prädiktoren in der Gruppe reduzieren und erneut trainieren. Ich habe diese Methode schon einmal angewandt - der Effekt ist da, aber wieder nicht schnell.
Sie müssen nur das erneute Training in einer Schleife direkt vom Terminal aus automatisieren.
Hat catbust nicht eine DLL-Version? Die DLL kann direkt vom Terminal aus aufgerufen werden. Es gab einen Artikel mit Beispielen hier. https://www.mql5.com/ru/articles/18 und https://www.mql5.com/ru/articles/5798.
Heh, es wäre schön, die volle Lernkontrolle über das Terminal zu bekommen, aber soweit ich weiß, gibt es keine fertige Lösung. Es gibt eine Bibliothek catboostmodel.dll, die nur das Modell anwendet, aber ich weiß nicht, wie man sie in MQL5 implementiert. Theoretisch ist es natürlich möglich, eine Schnittstelle in Form einer Bibliothek für das Training zu machen - der Code ist offen, aber ich kann es mir nicht leisten.
Ja, es ist besser, mit Gruppen zu beginnen - man kann z. B. 10 Gruppen bilden und sie in Kombinationen trainieren, die Modelle auswerten, die erfolglosesten Gruppen eliminieren und die verbleibenden neu gruppieren, d. h. die Anzahl der Prädiktoren in der Gruppe reduzieren und sie erneut trainieren. Ich habe diese Methode schon einmal angewandt - der Effekt ist da, aber wiederum nicht schnell.
Ich schlage etwas anderes vor. Wir fügen dem Modell eine Funktion nach der anderen hinzu. Und wählen die besten aus.
1) Trainiere 5000+ Modelle auf ein Merkmal: jedes von 5000+ Merkmalen. Nehmen Sie das beste aus dem Test.
2) Trainieren Sie (5000+ -1) Modelle auf 2 Merkmale: das erste beste Merkmal und( 5000+ -1) die übrigen. Finde das zweitbeste Merkmal.
3) Trainiere (5000+ -2) Modelle auf 3 Merkmale: auf das 1., 2. beste Merkmal und( 5000+ -2) die übrigen. Finde das drittbeste.
Wiederholen Sie den Vorgang, bis sich das Modell verbessert.
Ich habe normalerweise nach 6-10 hinzugefügten Merkmalen aufgehört, das Modell zu verbessern. Sie können auch einfach 10-20 oder so viele Merkmale hinzufügen, wie Sie möchten.
Aber ich denke, dass die Auswahl von Merkmalen nach Test das Modell an den Testabschnitt der Daten anpasst. Es gibt eine Variante der Auswahl nach Trayne mit Gewicht 0,3 und Test mit Gewicht 0,7. Aber ich denke, das ist auch eine Anpassung.
Ich wollte die Rolle vorwärts machen, dann wird die Anpassung für viele Testabschnitte sein, es wird länger dauern zu zählen, aber es scheint mir, dass dies die beste Option ist.
Auch wenn man keine Automatisierung für den Betrieb von catbusters.... hat. 50+ tausend Mal wird es schwierig sein, Modelle manuell neu zu trainieren, um 10 Merkmale zu erhalten.Das ist in etwa der Grund, warum ich mein Handwerk dem Catbust vorziehe. Auch wenn es 5-10 mal langsamer arbeitet als Cutbust. Du hattest ein Modell für 3 Minuten, ich hatte 22.
Das ist nicht das, was ich vorschlage. Wir fügen dem Modell ein Merkmal nach dem anderen hinzu. Und wählen die besten aus.
1) Trainieren Sie 5000+ Modelle auf ein Merkmal: jedes der 5000+ Merkmale. Nehmen Sie das beste aus dem Test.
2) Trainieren Sie (5000+ -1) Modelle auf 2 Merkmale: das erste beste Merkmal und( 5000+ -1) die übrigen. Finde das zweitbeste Merkmal.
3) Trainiere (5000+ -2) Modelle auf 3 Merkmale: auf das 1., 2. beste Merkmal und( 5000+ -2) die übrigen. Finde das drittbeste.
Wiederholen Sie den Vorgang, bis sich das Modell verbessert.
Ich habe normalerweise nach 6-10 hinzugefügten Merkmalen aufgehört, das Modell zu verbessern. Sie können auch einfach 10-20 oder so viele Merkmale hinzufügen, wie Sie möchten.
Die Ansätze können unterschiedlich sein - ihr Kern ist im Allgemeinen derselbe, aber der Nachteil ist natürlich der gleiche - zu hohe Rechenkosten.
Aber ich denke, dass die Merkmalsauswahl durch Test eine Anpassung des Modells an den Testabschnitt der Daten ist. Es gibt eine Variante der Auswahl durch trayne mit Gewicht 0,3 und test mit Gewicht 0,7. Aber ich denke, es ist auch eine Anpassung.
Ich würde gerne das Valving vorwärts machen, dann wird die Anpassung für viele Testabschnitte sein, es wird länger dauern zu berechnen, aber es scheint mir, dass dies die beste Option ist.
Deshalb bin ich auf der Suche nach einigen rationalen Korn innerhalb der Funktion, um seine Auswahl zu rechtfertigen. Bisher habe ich mich auf die Häufigkeit des Wiederauftretens von Ereignissen und die Verschiebung der Klassenwahrscheinlichkeit festgelegt. Im Durchschnitt ist der Effekt positiv, aber diese Methode bewertet eigentlich nur den ersten Split, ohne die korrelierenden Prädiktoren zu berücksichtigen. Ich denke aber, dass Sie die gleiche Methode auch für den zweiten Split ausprobieren sollten, indem Sie die Zeilen mit Prädiktorenwerten mit starker negativer Prädisposition aus der Stichprobe entfernen.
Auch wenn Sie keine Automatisierung haben, um catbusters.... 50+ tausend Mal laufen zu lassen, wäre es schwierig, Modelle manuell neu zu trainieren, um 10 Merkmale zu erhalten.
Das ist ungefähr der Grund, warum ich mein Handwerk Catbust vorziehe. Auch wenn es 5-10 mal langsamer arbeitet als Cutbust. Du hattest ein Modell, das 3 Minuten zum Zählen brauchte, ich hatte 22.
Trotzdem, lies meinen Artikel.... Jetzt funktioniert alles halbautomatisch - die Aufgaben werden erstellt und der Bootnik wird gestartet (einschließlich der Aufgaben für die Anzahl der im Training zu verwendenden Merkmale, d.h. man kann alle Varianten auf einmal erstellen und starten). Im Wesentlichen muss man dem Terminal beibringen, die Bat-Datei auszuführen, was meiner Meinung nach möglich ist, und das Ende des Trainings zu kontrollieren, dann das Ergebnis zu analysieren und eine weitere Aufgabe auf der Grundlage der Ergebnisse auszuführen.
Nur durch eine Änderung der Lernrate konnten zwei von 100 Modellen gefunden werden, die das vorgegebene Kriterium erfüllten.
Das erste.
Das zweite.
Es stellt sich heraus, dass CatBoost zwar eine Menge kann, aber es scheint notwendig zu sein, die Einstellungen aggressiver zu gestalten.
Wählen Sie diese Modelle durch die besten auf dem Test?
Oder unter einer Reihe von den besten im Test - die besten in der Prüfung?