Статьи по программированию на языке MQL5
Изучайте язык программирования торговых стратегий MQL5 по опубликованным здесь статьям, большая часть которых написана вами - членами сообщества. Все статьи разделены на категории для быстрого поиска ответа по тому или иному аспекту программирования: "Интеграция", "Тестер", "Торговые стратегии" и многое другое.
Следите за новыми публикациями и участвуйте в их обсуждении на форуме!
Новая статья

Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь

Шаблоны проектирования в MQL5 (Часть 2): Структурные шаблоны
В этой статье мы продолжим изучать шаблоны проектирования, которые позволяют разработчикам создавать расширяемые и надежные приложений не только на MQL5, но и на других языках программирования. В этот раз мы поговорим о другом типе — о структурных шаблонах. Будем учиться проектировать системы, используя имеющиеся классы для формирования более крупных структур.

Нейросети в трейдинге: Сегментация данных на основе уточняющих выражений
В процессе анализа рыночной ситуации мы делим её на отдельные сегменты, выявляя ключевые тенденции. Однако традиционные методы анализа часто фокусируются на одном аспекте, что ограничивает восприятие. В данной статье мы познакомимся с методом, позволяющем выделять несколько объектов, что даёт более полное и многослойное понимание ситуации.

Возможности Мастера MQL5, которые вам нужно знать (Часть 12): Полином Ньютона
Полином Ньютона, который создает квадратные уравнения из набора нескольких точек, представляет собой архаичный, но интересный подход к рассмотрению временных рядов. В этой статье мы попытаемся изучить, какие аспекты этого подхода могут быть полезны трейдерам, а также устранить его ограничения.

Мониторинг торговли с помощью Push-уведомлений — пример сервиса в MetaTrader 5
В статье рассмотрим создание программы сервиса для отправки уведомлений на смартфон о результатах торговли. В рамках статьи научимся работать со списками объектов Стандартной Библиотеки для организации выборки объектов по требуемым свойствам.

Разработка системы репликации - Моделирование рынка (Часть 14): Появление СИМУЛЯТОРА (IV)
В этой статье мы продолжим этап разработки симулятора. Однако сейчас мы увидим, как эффективно создать движение типа «СЛУЧАЙНОЕ БЛУЖДАНИЕ». Этот тип движения весьма интригующий, поскольку служит основой всего, что происходит на рынке капитала. Кроме того, мы начнем понимать некоторые концепции, основополагающие для тех, кто проводит анализ рынка.

Нестационарные процессы и ложная регрессия
Статья призвана продемонстрировать факт появления ложной регрессии при попытках применить регрессионный анализ к нестационарным процессам с помощью моделирования по методу Монте-Карло.

Нейросети — это просто (Часть 90): Частотная интерполяция временных рядов (FITS)
При изучении метода FEDformer мы приоткрыли дверь в частотную область представления временного ряда. В новой статье мы продолжим начатую тему. И рассмотрим метод, позволяющий не только проводить анализ, но и прогнозировать последующие состояния в частной области.

Теория хаоса в трейдинге (Часть 2): Продолжаем погружение
Продолжаем погружение в теорию хаоса на финансовых рынках, и рассмотрим ее применимость к анализу валют и иных активов.

Разработка системы репликации - Моделирование рынка (Часть 25): Подготовка к следующему этапу
В этой статье мы завершаем первый этап разработки системы репликации и моделирования. Дорогой читатель, этим достижением я подтверждаю, что система достигла продвинутого уровня, открывая путь для внедрения новой функциональности. Цель состоит в том, чтобы обогатить систему еще больше, превратив ее в мощный инструмент для исследований и развития анализа рынка.

Разметка данных в анализе временных рядов (Часть 5):Применение и тестирование советника с помощью Socket
В этой серии статей представлены несколько методов разметки временных рядов, которые могут создавать данные, соответствующие большинству моделей искусственного интеллекта (ИИ). Целевая разметка данных может сделать обученную модель ИИ более соответствующей пользовательским целям и задачам, повысить точность модели и даже помочь модели совершить качественный скачок!

Разработка системы репликации - Моделирование рынка (Часть 13): Появление СИМУЛЯТОРА (III)
Здесь мы немного упростим несколько элементов, связанных с работой в следующей статье. Я также объясню, как можно визуализировать то, что генерирует симулятор с точки зрения случайности.

Возможности Мастера MQL5, которые вам нужно знать (Часть 08): Перцептроны
Перцептроны, сети с одним скрытым слоем, могут стать хорошим подспорьем для тех, кто знаком с основами автоматической торговли и хочет окунуться в нейронные сети. Мы шаг за шагом рассмотрим, как их можно реализовать в сборке классов сигналов, которая является частью классов Мастера MQL5 для советников.
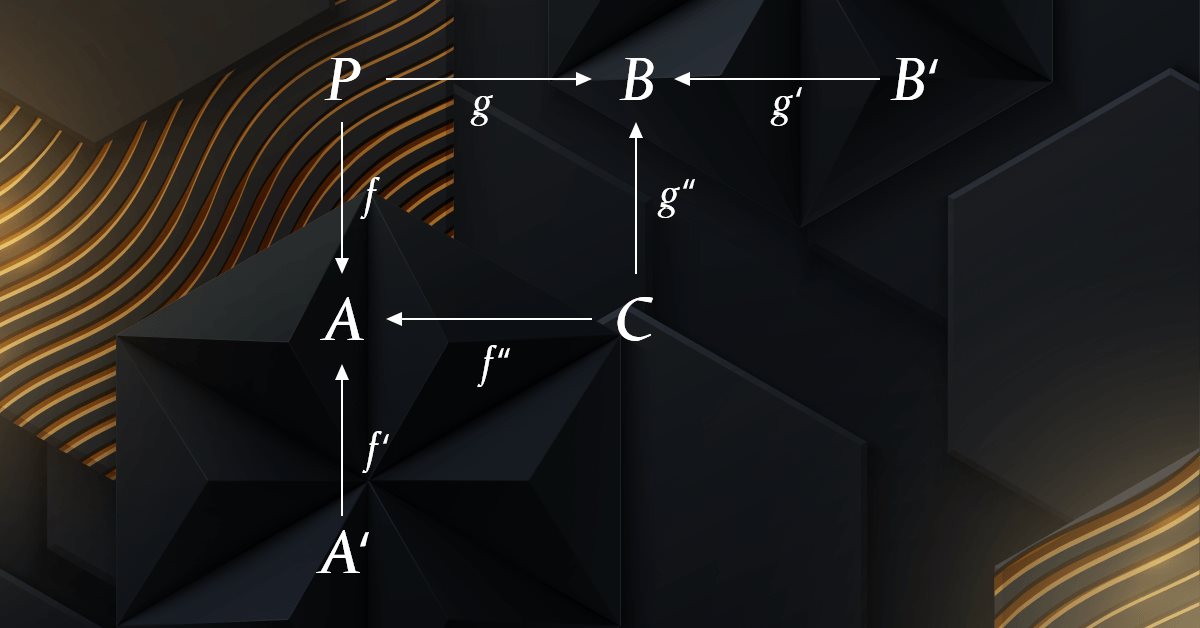
Теория категорий в MQL5 (Часть 4): Интервалы, эксперименты и композиции
Теория категорий представляет собой разнообразный и расширяющийся раздел математики, который пока относительно не освещен в MQL5-сообществе. Эта серия статей призвана описать некоторые из ее концепций для создания открытой библиотеки и дальнейшему использованию этого замечательного раздела в создании торговых стратегий.

Шаблоны проектирования в программировании на MQL5 (Часть 3): Поведенческие шаблоны 1
В новая статье серии, посвященной шаблонам проектирования, мы рассмотрим поведенческие шаблоны, чтобы понять, как эффективно создавать методы взаимодействия между созданными объектами. Спроектировав эти шаблоны поведения, мы сможем понять, как создавать многоразовое, расширяемое и тестируемое программное обеспечение.

Популяционные алгоритмы оптимизации: Гибридный алгоритм оптимизации бактериального поиска с генетическим алгоритмом (Bacterial Foraging Optimization - Genetic Algorithm, BFO-GA)
В статье представлен новый подход к решению оптимизационных задач, путём объединения идей алгоритмов оптимизации бактериального поиска пищи (BFO) и приёмов, используемых в генетическом алгоритме (GA), в гибридный алгоритм BFO-GA. Он использует роение бактерий для глобального поиска оптимального решения и генетические операторы для уточнения локальных оптимумов. В отличие от оригинального BFO бактерии теперь могут мутировать и наследовать гены.

Алгоритм поиска в окрестности — Across Neighbourhood Search (ANS)
Статья раскрывает потенциал алгоритма ANS, как важного шага в развитии гибких и интеллектуальных методов оптимизации, способных учитывать специфику задачи и динамику окружающей среды в пространстве поиска.

Возможности Мастера MQL5, которые вам нужно знать (Часть 11): Числовые стены
Числовые стены (Number Walls) — это вариант регистра сдвига с линейной обратной связью (Linear Shift Back Registers), который предварительно оценивает последовательности на предмет предсказуемости путем проверки на сходимость. Мы посмотрим, как эти идеи могут быть использованы в MQL5.

Машинное обучение и Data Science (Часть 19): Совершенствуем AI-модели с помощью AdaBoost
Алгоритм AdaBoost используется для повышения производительности моделей искусственного интеллекта. AdaBoost (Adaptive Boosting, адаптивный бустинг) представляет собой сложную методику ансамблевого обучения, которая легко объединяет слабых учащихся, повышая их коллективную способность прогнозирования.
Нейросети в трейдинге: Superpoint Transformer (SPFormer)
В данной статья предлагаем познакомиться с методом сегментации 3D-люъектов на основе Superpoint Transformer (SPFormer), который устраняет необходимость в промежуточной агрегации данных. Что ускоряет процесс сегментации и повышает производительность модели.

Перестановка ценовых баров в MQL5
В этой статье мы представляем алгоритм перестановки ценовых баров и подробно рассказываем, как тесты на перестановку (permutation tests) можно использовать для выявления случаев, когда эффективность стратегии была сфабрикована с целью обмануть потенциальных покупателей советников.

Введение в MQL5 (Часть 7): Руководство для начинающих по созданию советников и использованию кода от ИИ в MQL5
В этой статье мы представим полное руководство для начинающих по созданию советников (EA) на MQL5. Вы найдете пошаговые инструкции по созданию экспертов с использованием псевдокода и возможностей кода, сгенерированного ИИ. Эта статья предназначена для тех, кто только начинает свой пусть в алготрейдинге, а также для всех, кто хочет улучшить навыки разработки эффективных советников.

Гибридизация популяционных алгоритмов. Последовательная и параллельная схема
В статье мы погрузимся в мир гибридизации алгоритмов оптимизации, рассмотрев три ключевых типа: смешивание стратегий, последовательную и параллельную гибридизации. Мы проведем серию экспериментов, сочетая и тестируя соответствующие алгоритмы оптимизации.
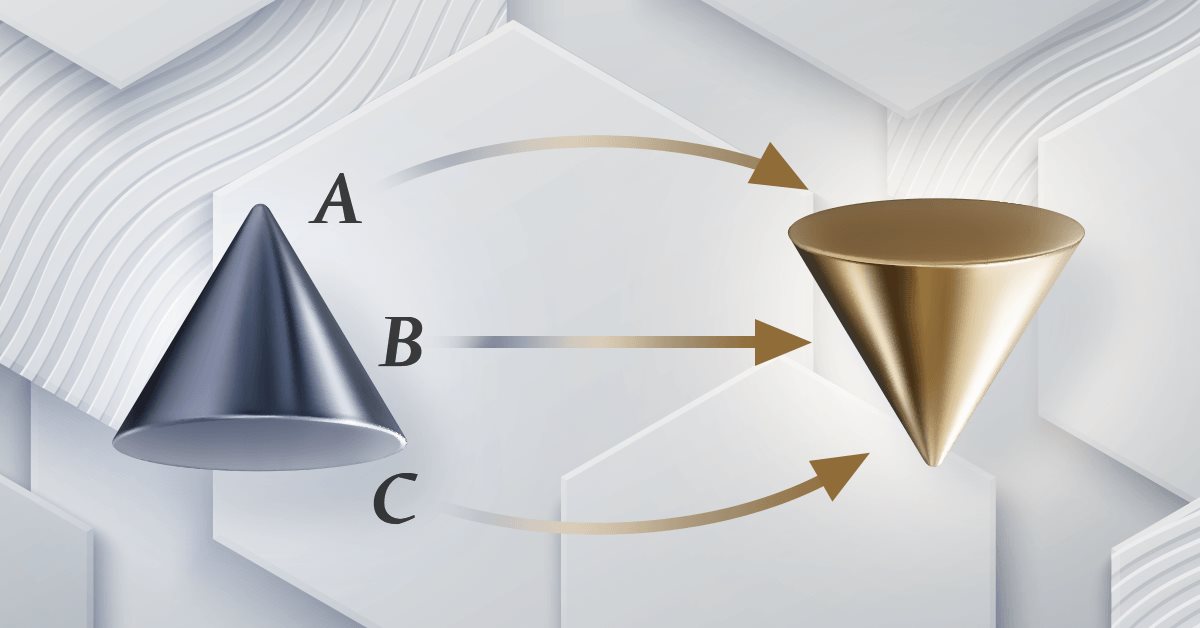
Теория категорий в MQL5 (Часть 22): Другой взгляд на скользящие средние
В этой статье мы попытаемся упростить описание концепций, рассматриваемых в этой серии, остановившись только на одном индикаторе - наиболее распространенном и, вероятно, самом легком для понимания. Речь идет о скользящей средней. Также мы рассмотрим значение и возможные применения вертикальных естественных преобразований.

DoEasy. Элементы управления (Часть 28): Стили полосы в элементе управления "ProgressBar"
В статье будут разработаны стили отображения и текст описания полосы прогресса элемента управления ProgressBar

Теория категорий в MQL5 (Часть 23): Другой взгляд на двойную экспоненциальную скользящую среднюю
В этой статье мы продолжаем рассматривать популярные торговые индикаторы под новым углом. Мы собираемся обрабатывать горизонтальную композицию естественных преобразований. Лучшим индикатором для этого является двойная экспоненциальная скользящая средняя (Double Exponential Moving Average, DEMA).

Нейросети — это просто (Часть 94): Оптимизация последовательности исходных данных
При работе с временными рядами мы всегда используем исходные данные в их исторической последовательности. Но является ли это оптимальным вариантом? Существует мнение, что изменение последовательности исходных данных позволит повысить эффективность обучаемых моделей. В данной статье я предлагаю вам познакомиться с одним из таких методов.

Добавляем пользовательскую LLM в торгового робота (Часть 2): Пример развертывания среды
Языковые модели (LLM) являются важной частью быстро развивающегося искусственного интеллекта, поэтому нам следует подумать о том, как интегрировать мощные LLM в нашу алгоритмическую торговлю. Большинству людей сложно настроить эти модели в соответствии со своими потребностями, развернуть их локально, а затем применить к алгоритмической торговле. В этой серии статей будет рассмотрен пошаговый подход к достижению этой цели.

Разработка системы репликации (Часть 37): Прокладываем путь (I)
В этой статье мы начнем делать то, что хотелось сделать гораздо раньше. Однако из-за отсутствия "твердой почвы" я не чувствовал себя уверенно, чтобы представить вопрос публично. Теперь у меня есть основа для того, чтобы делать то, что мы начнем сейчас. Неплохо бы максимально сосредоточиться на понимании содержания этой статьи, и я говорю это не для того, чтобы вы просто это прочитали. Я хочу подчеркнуть, что если вы не поймете данную статью, то можете полностью отказаться от надежды понять содержание следующих статей.

Графический интерфейс: советы и рекомендации по созданию графической библиотеки на MQL
Мы рассмотрим основы библиотек графического интерфейса, чтобы вы могли понять, как они работают, или даже начали создавать свои собственные.

Разработка системы репликации (Часть 32): Система ордеров (I)
Из всего, что было разработано до настоящего момента, данная система, как вы наверняка заметите и со временем согласитесь, - является самым сложным. Сейчас нам нужно сделать нечто очень простое: заставить нашу систему имитировать работу торгового сервера на практике. Эта необходимость точно реализовывать способ моделирования действий торгового сервера кажется простым делом. По крайней мере, на словах. Но нам нужно сделать это так, чтобы для пользователя системы репликации/моделирования всё происходило как можно более незаметно или прозрачно.

Разработка системы репликации (Часть 28): Проект советника — класс C_Mouse (II)
Когда начали создаваться первые системы, способные что-то считать, всё потребовало вмешательства инженеров, обладающих обширными знаниями о том, что проектируется. Мы говорим о рассвете компьютерной техники, о времени, когда не было даже терминалов, позволяющих что-либо программировать. По мере развития и роста интереса к тому, чтобы большее число людей могли создавать что-либо, появлялись новые идеи и методы программирования этих машин, которые раньше сводились к изменению положения соединителей. Именно тогда появились первые терминалы.

Популяционные алгоритмы оптимизации: Устойчивость к застреванию в локальных экстремумах (Часть II)
Продолжение эксперимента, цель которого - исследовать поведение популяционных алгоритмов оптимизации в контексте их способности эффективно покидать локальные минимумы при низком разнообразии в популяции и достигать глобальных максимумов. Результаты исследования.
Альтернативные показатели риска и доходности в MQL5
В этой статье мы представим реализацию нескольких показателей доходности и риска, рассматриваемых как альтернативы коэффициенту Шарпа, и исследуем гипотетические кривые капитала для анализа их характеристик.

Алгоритм кометного следа (Comet Tail Algorithm, CTA)
В данной статье мы рассмотрим новый авторский алгоритм оптимизации CTA (Comet Tail Algorithm), который черпает вдохновение из уникальных космических объектов - комет и их впечатляющих хвостов, формирующихся при приближении к Солнцу. Данный алгоритм основан на концепции движения комет и их хвостов, и предназначен для поиска оптимальных решений в задачах оптимизации.

Стратегия Билла Вильямса с индикаторами и прогнозами и без них
Мы рассмотрим одну из известных стратегий Билла Вильямса и попытаемся улучшить ее с помощью индикаторов и прогнозов.

Разработка системы репликации - Моделирование рынка (Часть 05): Предварительный просмотр
Нам удалось разработать способ осуществления репликации рынка достаточно реалистичным и доступным образом. Теперь давайте продолжим наш проект и добавим данные для улучшения поведения репликации.

Разметка данных в анализе временных рядов (Часть 6):Применение и тестирование советника с помощью ONNX
В этой серии статей представлены несколько методов разметки временных рядов, которые могут создавать данные, соответствующие большинству моделей искусственного интеллекта (ИИ). Целевая разметка данных может сделать обученную модель ИИ более соответствующей пользовательским целям и задачам, повысить точность модели и даже помочь модели совершить качественный скачок!

Машинное обучение и Data Science (Часть 18): Сравниваем эффективность TruncatedSVD и NMF в работе со сложными рыночными данными
Усеченное сингулярное разложение (TruncatedSVD) и неотрицательная матричная факторизация (NMF) представляют собой методы уменьшения размерности. Оба метода могут быть весьма полезными при работе с торговыми стратегиями, имеющими в своей основе анализ данных. В этой статье мы рассмотрим их применимость к обработке сложных рыночных данных — их возможности по уменьшению размерности для оптимизации количественного анализа на финансовых рынках.

Количественный подход в управлении рисками: Применение VaR модели для оптимизации мультивалютного портфеля с Python и MetaTrader 5
Эта статья раскрывает потенциал Value at Risk (VaR) модели для оптимизации мультивалютного портфеля. Используя мощь Python и функционал MetaTrader 5, мы демонстрируем, как реализовать VaR-анализ для эффективного распределения капитала и управления позициями. От теоретических основ до практической реализации, статья охватывает все аспекты применения одной из наиболее устойчивых систем расчета рисков — VaR — в алгоритмической торговле.

Понимание и эффективное использование OpenCL API путем воссоздания встроенной поддержки в виде DLL в Linux (Часть 2): Реализация OpenCL Simple DLL
В продолжение первой части создадим простую DLL и протестируем ее с помощью MetaTrader 5. Это хорошо подготовит нас к разработке полноценной поддержки OpenCL в виде DLL в следующей части.