
Нейросети в трейдинге: Управляемая сегментация

Введение
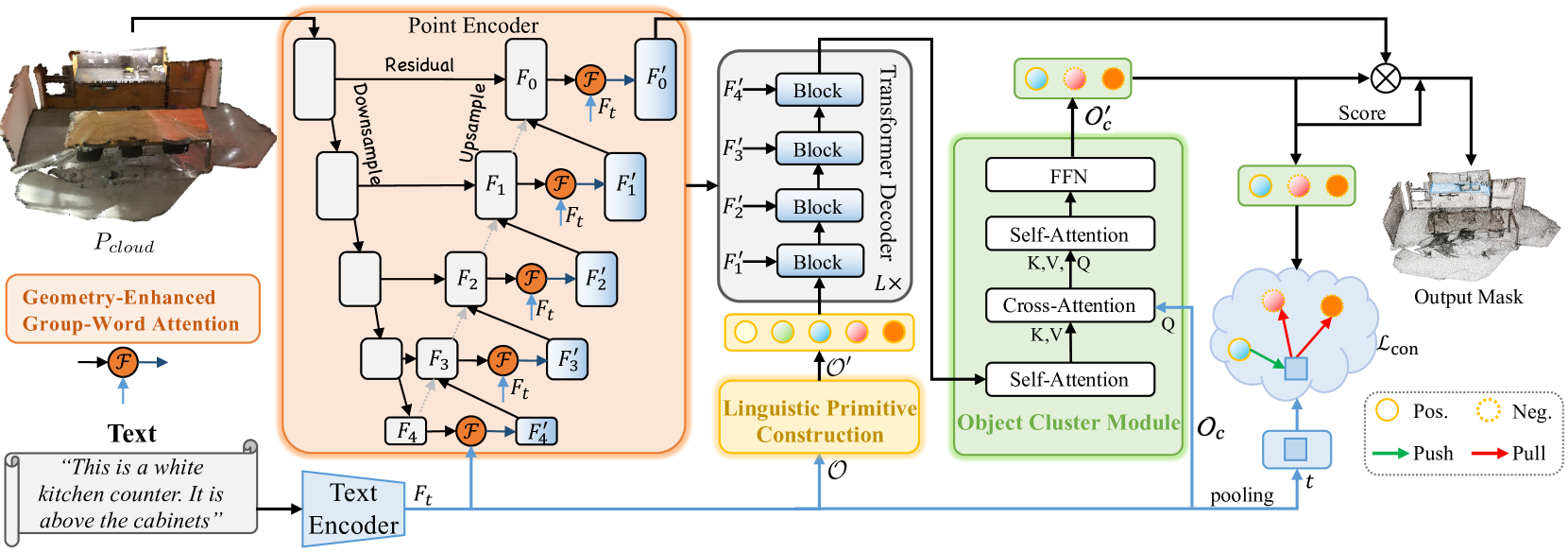
Задача управляемой сегментации предполагает выделение из облака точек области на основании представленного описания целевого объекта средствами естественного языка. В ходе её решения модель проводит детальный анализ сложных мелкозернистых семантических зависимостей и строит точечную маску целевого объекта. Для решения данной задачи в работе "RefMask3D: Language-Guided Transformer for 3D Referring Segmentation" был представлен эффективный комплексный фреймворк, который всесторонне использует языковую информацию. Предложенный метод RefMask3D улучшает алгоритмы мультимодального взаимодействия и понимания.
Авторы метода предлагают использовать ранние уровни кодирования функций для извлечения богатого мультимодального контекста. С этой целью они вводят модуль Geometry-Enhanced Group-Word Attention, в котором осуществляется кросс-модальное внимание между описанием объекта на естественном языке и локальными группами точек (субоблаками) на каждом этапе кодирования их признаков. Эта интеграция не только уменьшает шум, присущий прямой корреляции между точками и словами, который часто возникают из-за разреженной и нерегулярной природы облаков точек, но также использует внутренние геометрические отношения и тонкую структуру облака точек. Что значительно улучшает способность модели взаимодействовать с лингвистическими и геометрическими данными.
Кроме того, авторы метода добавляют обучаемый «фоновый» токен, который позволяет предотвратить переплетение нерелевантных языковых функций с признаками локальной группы. Такой подход гарантирует, что точечные объекты обогащаются семантической лингвистической информацией, поддерживая непрерывную и контекстно-зависимую осведомленность о соответствующем языковом контексте в каждой группе или объекте анализируемого облака точек.
Благодаря объединению функций машинного зрения и анализа естественного языка, авторы метода разработали стратегию эффективной идентификации целевого объекта в декодере, получившую название Linguistic Primitives Construction (LPC). Было предложено инициализировать набор разнообразных примитивов, каждый из которых предназначен для представления различных семантических атрибутов, таких как форма, цвет, размер, отношения, местоположение и т. д. Взаимодействуя с определенной лингвистической информацией, эти примитивы способны приобретать соответствующие атрибуты.
Использование семантически обогащенных примитивов в декодере усиливает фокус модели на разнообразной семантике облака точек, тем самым значительно улучшая способность точно локализовать и идентифицировать целевой объект.
Для сбора целостной информации и генерации эмбедингов объектов авторами фреймворка RefMask3D был предложен модуль кластера объектов (Object Cluster Module — OCM). Лингвистические примитивы предназначены для создания акцента на определенных частях облака точек, которые коррелируют с их семантическими атрибутами. Однако конечная цель состоит в идентификации целевого объекта на основе заданного описания. Это требует целостного понимания языка. Данная задача решается путем внедрения модуля кластера объектов. В этом модуле сначала анализируются отношения между лингвистическими примитивами, чтобы выявить общие признаки и различия в их основных областях. С использованием этой информации инициализируются запросы на основе естественного языка. Это позволяет зафиксировать выявленные общие признаки, которые формируют окончательный эмбединг, имеющий решающее значение для идентификации целевого объекта.
Предлагаемый модуль кластера объектов в значительной степени помогает модели углубить целостное понимание лингвистической и визуальной информации.
1. Алгоритм RefMask3D
Метод RefMask3D создает точечную маску целевого объекта по результатам анализа исходной сцены облака точек и текстового описания искомых признаков. Анализируемая сцена состоит в общей сложности из N точек, каждая из которых содержит информацию о 3D-координатах P и вспомогательную функцию F, описывающую цвет, форму и другие признаки.
Вначале используется текстовый Энкодер, который генерирует эмбединги текстового описания Ft. Затем извлекаются точечные характеристики посредством точечного кодировщика, который выстраивает глубокое взаимодействие между наблюдаемой формой и текстовым описанием с помощью модуля Geometry-Enhanced Group-Word Attention. Энкодер точек представляет собой магистраль, подобную 3D U-Net.
Конструктор лингвистических примитивов создает примитивы 𝒪′ для представления различных семантических атрибутов с помощью информативных языковых сигналов, повышая способность модели точно локализовать и идентифицировать цели за счет взаимодействия с конкретной лингвистической информацией.
Лингвистические примитивы 𝒪′, многомасштабные точечные объекты {𝑭1′,𝑭2′,𝑭3′,𝑭4′} и языковые функции 𝑭t составляют исходные данные для четырехслойного кросс-модального Декодера, созданного с использованием архитектуры Transformer.
Лингвистические примитивы, обогащенные с помощью Декодера, и объектные запросы 𝒪c подаются в модуль кластера объектов для анализа взаимосвязей между лингвистическими примитивами, с целью унификации их понимания и выявления общих характеристик.
Модуль слияния модальностей устанавливается поверх магистралей машинного зрения или языковой модели. Авторы метода интегрируют мультимодальное объединение в Энкодер точек. Слияние кросс-модальных функций на ранних стадиях повышает эффективность процесса слияния. Механизм Geometry-Enhanced Group-Word Attention инновационно обрабатывает локальные группы точек (субоблака) с геометрически соседними. Эта методология не только уменьшает шум, связанный с прямыми корреляциями между признаками точек и словами, но и извлекает выгоду из присущих им геометрических отношений в облаках точек, повышая способность модели точно интегрировать лингвистическую информацию и 3D-структуру.
В ванильном кросс-модальном внимании часто возникает проблема при работе с ситуациями, когда к точке нет связанных соответствующих слов. Для решения этой проблемы авторы метода предлагают внедрить изучаемые токены фоновой функции. Эта стратегия позволяет точкам без соответствующей текстовой информации сосредоточиться на общем эмбединге фонового токена, уменьшая потенциальное искажение, вызванное несвязанным текстом на точечном объекте.
Включение точечных объектов без соответствия языковых элементов для выделения фонового объекта уменьшает влияние нерелевантного объекта. Таким образом, мы получаем признаки точек, которые представляют собой уточненные лингвистические характеристики, связанные с локальными центроидами без влияния неуместных слов. Фоновый эмбединг — это обучаемый параметр, предназначенный для фиксации общего распределения набора данных и эффективного представления исходной информации. Этот эмбединг используется только в процессе вычисления внимания. Путем использования эмбединга фона, авторы метода способствуют более точным кросс-модальным взаимодействиям, на которые не оказывают негативного влияния нерелевантные слова.
Существующие подходы обычно используют запросы с координатами центроидов, взятые из исходного облака точек. Однако ключевым ограничением такого подхода является пренебрежение языковой информацией, которая жизненно необходима для точной сегментации. Использование выборки только из самых дальних точек часто приводит к тому, что прогнозы отклоняются от целевых объектов, особенно в разреженных сценах, тем самым препятствуя сходимости или приводя к потере объектов. Это становится особенно проблематичным, когда выбранные точки неточно отражают целевой объект или когда все они привязаны к одному слову. Для решения указанной проблемы авторы фреймворка предлагают конструкцию лингвистических примитивов для включения семантического контента, который обучает различные лингвистические примитивы для поиска объектов, связанных с соответствующими семантическими свойствами.
Обучаемые примитивы инициализируются путем их выборки из различных гауссовских распределений. Каждый из них определяет отдельное семантическое свойство. Предполагается, что эти примитивы содержат различную семантику, например, форму, цвет, размер, материал, отношения и местоположение. Каждый примитив агрегирует отдельные языковые признаки и извлекает соответствующую информацию. Лингвистические примитивы предназначены для демонстрации семантических паттернов. Подача таких примитивов в декодер Transformer позволяет ему выделять разнообразную языковую информацию, что способствует точной идентификации целевых объектов на более поздней стадии.
Каждый лингвистический примитив фокусируется на различных семантических паттернах в заданном облаке точек, которые коррелируют с их лингвистическими атрибутами. Однако конечная цель, основанная на заданном тексте, состоит в том, чтобы идентифицировать уникальный целевой объект. Это требует всестороннего анализа и понимания текстового описания целевого объекта. Для достижения данной цели авторы метода используют модуль кластера объектов, который позволяет анализировать зависимости между лингвистическими примитивами, выявлять общие характеристики и различия в их основных областях. Это способствует более глубокому пониманию представленных описаний объектов. Авторы метода используют механизм Self-Attention для извлечения общих характеристик из лингвистических примитивов. В процессе декодирования вводятся объектные запросы, рассматривая их в качестве Query, и общие признаки, обогащенные лингвистическими примитивами, в качестве Key-Value. Такая конфигурация позволяет декодеру объединять лингвистические выводы из лингвистических примитивов в запросы объектов, эффективно идентифицируя и группируя запросы указанного объекта в 𝒪c′, тем самым достигая точной идентификации объекта.
Несмотря на то, что предлагаемый модуль кластера объектов помогает в идентификации целевых объектов, он не устраняет неоднозначности, возникающие при других внедрениях. Эти неоднозначности могут привести к ложным срабатываниям на этапе вывода. Авторы RefMask3D используют контрастное обучение, чтобы отличить целевой токен от других. Это достигается за счет максимального сходства между целевым токеном и соответствующим выражением при минимизации сходства с нецелевыми (отрицательными) парами.
Авторская визуализация метода представлена RefMask3D ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода RefMask3D, мы переходим к практической части нашей статьи. В ней мы реализуем свое видение предложенных подходов средствами MQL5.
В представленном выше описании авторы метода RefMask3D разделили комплексный алгоритм на несколько функциональных блоков. И я думаю, будет вполне логично построить наши реализации в виде соответствующих модулей.
2.1 Geometry-Enhanced Group-Word Attention
А начнем мы работу с построения Энкодера точек, в который авторы метода встроили модуль Geometry-Enhanced Group-Word Attention. Алгоритм данного модуля мы реализуем в новом классе CNeuronGEGWA. Как было сказано в теоретическом описании метода RefMask3D, Энкодер точек построен в виде U-Net магистрали. Поэтому в качестве родительского класса был выбран CNeuronUShapeAttention, который предоставит нашему объекту базовый функционал. Структура нового класса представлена ниже.
class CNeuronGEGWA : public CNeuronUShapeAttention { protected: CNeuronBaseOCL cResidual; CNeuronMLCrossAttentionMLKV cCrossAttention; CBufferFloat cTemp; bool bAddNeckGradient; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronGEGWA(void) : bAddNeckGradient(false) {}; ~CNeuronGEGWA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronGEGWA; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); //--- virtual CNeuronBaseOCL* GetInsideLayer(const int layer) const; virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; } };
Здесь стоит отметить, что основной объем переменных и объектов, которые позволят нам организовать магистраль U-Net, унаследован от родительского класса. Однако мы добавляем объекты построения кросс-модального внимания.
Все объекты объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор класса. А инициализация всех унаследованных и добавленных объектов осуществляется в методе Init. Как вы знаете, в параметрах данного метода мы получаем константы, которые дают однозначное понимание требуемой архитектуры создаваемого объекта.
bool CNeuronGEGWA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В теле метода мы сразу вызываем одноименный метод базового полносвязного слоя CNeuronBaseOCL, который является начальным предком всех наших объектов нейронных слоев.
Обратите внимание, в данном случае мы вызываем метод базового класса, а не прямого родительского. Это связано с некоторыми особенностями архитектуры, которые мы используем для построения магистрали U-Net. В частности, при построении "шеи" мы используем рекурсивное создание объектов. И нам здесь необходимо использовать объекты другого класса.
Далее мы инициализируем объекты первичного внимания и масштабирования.
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2*window, window, (units_count + 1) / 2, optimization, iBatch)) return false;
За которыми следует алгоритм создания "шеи". Тип объекта "шеи" зависит от её размера. В общем случае мы создаем объект, аналогичный текущему. Только уменьшаем на "1" размер внутренней "шеи".
if(inside_bloks > 0) { CNeuronGEGWA *temp = new CNeuronGEGWA(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, (units_count + 1) / 2, window_kv, heads_kv, units_count_kv, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
А для последнего слоя мы используем блок кросс-внимания.
else { CNeuronMLCrossAttentionMLKV *temp = new CNeuronMLCrossAttentionMLKV(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, window_kv, heads_kv, (units_count + 1) / 2, units_count_kv, layers, 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
Затем мы инициализируем модуль повторного внимания и обратного масштабирования.
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, (units_count + 1) / 2, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, window, window, 2*window, (units_count + 1) / 2, optimization, iBatch)) return false;
После чего добавляем слой остаточной связи и модуль мультимодального кросс-внимания.
if(!cResidual.Init(0, 5, OpenCL, Neurons(), optimization, iBatch)) return false; if(!cCrossAttention.Init(0, 6, OpenCL, window, window_key, heads, window_kv, heads_kv, units_count, units_count_kv, layers, 1, optimization, iBatch)) return false;
Мы так же инициализируем вспомогательный буфер временного хранения данных.
if(!cTemp.BufferInit(MathMax(cCrossAttention.GetSecondBufferSize(), cAttention[0].Neurons()), 0) || !cTemp.BufferCreate(OpenCL)) return false;
А в завершении метода инициализации мы организуем подмену указателей на буфера данных для минимизации операций копирования информации.
if(Gradient != cCrossAttention.getGradient()) { if(!SetGradient(cCrossAttention.getGradient(), true)) return false; } if(cResidual.getGradient() != cMergeSplit[1].getGradient()) { if(!cResidual.SetGradient(cMergeSplit[1].getGradient(), true)) return false; } if(Output != cCrossAttention.getOutput()) { if(!SetOutput(cCrossAttention.getOutput(), true)) return false; } //--- return true; }
И вернем логический результат выполнения операций метода вызывающей программе.
После завершения работы по инициализации нового объекта, мы переходим к построению алгоритма прямого прохода, который реализован в методе feedForward. В отличие от родительского класса, наш новый объект требует двух источников данных. Поэтому унаследованный метод работы с одним источником данных мы переопределили с отрицательной "заглушкой". А новый метод написали, можно сказать, "с чистого листа".
В параметрах метода мы получаем указатели на 2 объекта исходных данных. Однако в данном случае мы не проверяем ни одного из них.
bool CNeuronGEGWA::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
Вначале мы передаем указатель на один источник данных в одноименный метод внутреннего слоя первичного внимания. Проверка указателя уже организована внутри данного метода. Нам лишь достаточно проверить логический результат выполнения операций вызванного метода. А затем масштабируем результаты работы блока внимания.
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
В "шею" мы передаем масштабированные данные и указатель на объект второго источника данных.
if(!cNeck.FeedForward(cMergeSplit[0].AsObject(), SecondInput)) return false;
Полученный результат мы проводим через второй блок внимания и осуществляем обратное масштабирование данных.
if(!cAttention[1].FeedForward(cNeck)) return false; if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
После чего добавляем остаточные связи и осуществляем анализ кросс-модальных зависимостей.
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), cResidual.getOutput(), 1, false)) return false; if(!cCrossAttention.FeedForward(cResidual.AsObject(), SecondInput)) return false; //--- return true; }
Перед началом работы над методами обратного прохода необходимо обсудить один момент. Посмотрите на представленную ниже вырезку из авторской визуализации метода RefMask3D.
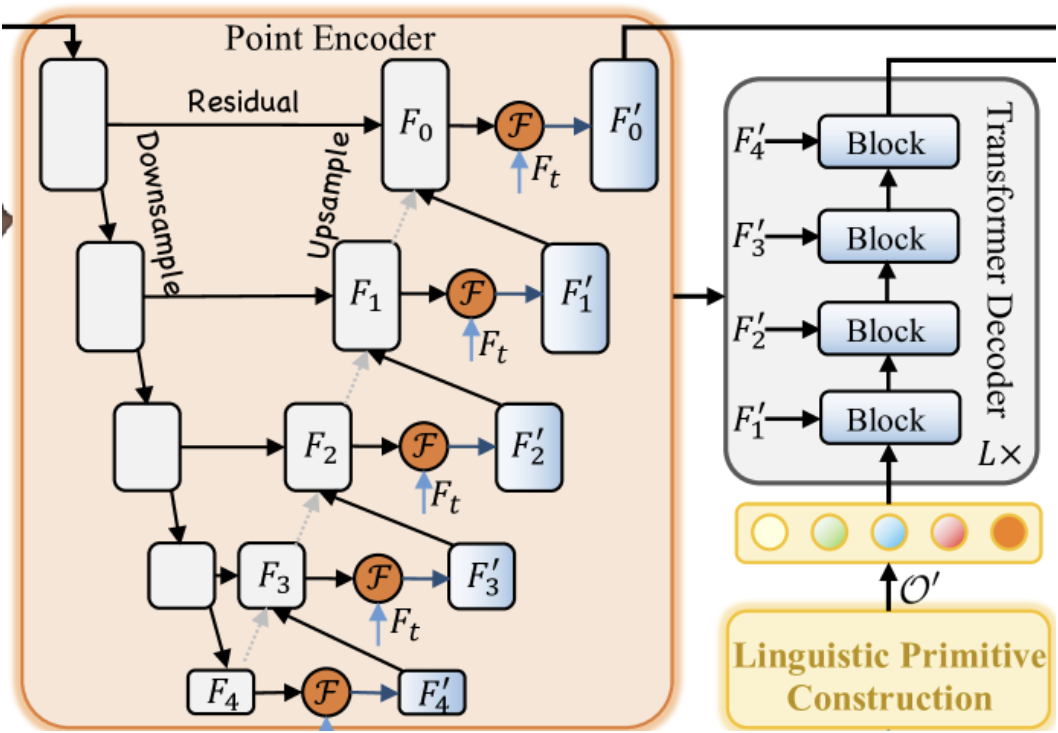
Дело в том, что в Декодере осуществляется кросс-модальное внимание обучаемых примитивов и промежуточных результатов нашего Энкодера точек. Эта, казалось бы, простая операция подразумевает соответствующий поток градиентов ошибки. Разумеется, нам нужно будет организовать соответствующие интерфейсы. Но несложно догадаться, что в ходе организации распределения градиента ошибки через наш общий блок RefMask3D, сначала мы вычислим градиенты Декодера, а затем — Энкодера точек. И при классической модели построения методов распределения градиентов ошибки, мы просто потеряем данные, полученные от Декодера. Однако мы понимаем, что такое использование блока является частным случаем. Поэтому в методе calcInputGradients мы предусмотрим 2 варианта работы: с удалением ранее сохраненных градиентов (классический алгоритм) и без (частный случай). Для этого мы добавили внутреннюю переменную-флаг bAddNeckGradient и метод для её изменения AddNeckGradient.
virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; }
Но вернемся к алгоритму обратного прохода. В параметрах метода calcInputGradients мы получаем указатели на 3 объекта и константу функции активации второго источника данных.
bool CNeuronGEGWA::calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!prevLayer) return false;
В теле метода мы проверяем актуальность указателя лишь на первый источник данных. Проверка остальных указателей осуществляется в теле методов распределения градиента ошибки внутренних слоев.
Благодаря организованной выше подмене указателей на буфера данных, алгоритм распределения градиентов ошибки начинается с внутреннего слоя кросс-модального внимания.
if(!cResidual.calcHiddenGradients(cCrossAttention.AsObject(), SecondInput, SecondGradient, SecondActivation)) return false;
После чего мы осуществляем масштабирование градиентов ошибки.
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
А вот далее мы организуем разветвление алгоритма в зависимости от необходимости сохранения ранее накопленного градиента ошибки. При необходимости сохранения, мы осуществим подмену буфера градиентов ошибки в "шее" на аналогичный буфер градиентов из первого слоя масштабирования данных. Здесь мы эксплуатируем то свойство, что размеры тензоров результатов указанного слоя масштабирования и "шеи" равны. А градиент ошибки на данный слой мы будем передавать позже. Поэтому в данном случае его эксплуатация безопасна.
if(bAddNeckGradient) { CBufferFloat *temp = cNeck.getGradient(); if(!cNeck.SetGradient(cMergeSplit[0].getGradient(), false)) return false;
Далее мы получаем градиент ошибки на уровне "шеи" классическим методом. Суммируем результаты из двух потоков информации и возвращаем указатели на объекты.
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false; if(!SumAndNormilize(cNeck.getGradient(), temp, temp, 1, false, 0, 0, 0, 1)) return false; if(!cNeck.SetGradient(temp, false)) return false; }
В случае, когда ранее накопленный градиент ошибки для нас не важен, мы просто получаем градиент ошибки стандартными методами.
else if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
Далее нам предстоит провести градиент ошибки через объект "шеи". Здесь мы используем классический метод. Только градиент ошибки второго источника данных мы получаем в буфер временного хранения данных. Ведь далее нам предстоит суммировать значения полученные от модуля кросс-модального внимания текущего объекта и шеи.
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject(), SecondInput, GetPointer(cTemp), SecondActivation)) return false; if(!SumAndNormilize(SecondGradient, GetPointer(cTemp), SecondGradient, 1, false, 0, 0, 0, 1)) return false;
Затем мы спускаем градиент ошибки до уровня первого источника исходных данных.
if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
Проводим через производную функции активации градиент ошибки остаточных связей и суммируем информацию из двух потоков.
if(!DeActivation(prevLayer.getOutput(), GetPointer(cTemp), cMergeSplit[1].getGradient(), prevLayer.Activation())) return false; if(!SumAndNormilize(prevLayer.getGradient(), GetPointer(cTemp), prevLayer.getGradient(), 1, false)) return false; //--- return true; }
Метод обновления параметров модели updateInputWeights довольно прост. Здесь мы лишь вызываем одноименные методы внутренних слоев, содержащих обучаемые параметры. Поэтому я предлагаю оставить его для самостоятельного изучения. Напомню, что полный код данного класса и всех его методов вы можете найти во вложении.
И несколько слов о создании интерфейса обращения к объектам "шеи". Для реализации данного функционала был создан метод GetInsideLayer, в параметрах которого мы будем передавать индекс необходимого слоя.
CNeuronBaseOCL* CNeuronGEGWA::GetInsideLayer(const int layer) const { if(layer < 0) return NULL;
Получение отрицательного индекса является признаком ошибки и метод возвращает указатель NULL. Нулевое значение говорит об обращении к текущему слою. Следовательно, метод вернет указатель на объект "шеи".
if(layer == 0) return cNeck;
В противном случае шея должна быть объектом соответствующего класса и мы рекурсивно вызываем данный метод с уменьшением индекса необходимого слоя на 1.
if(!cNeck || cNeck.Type() != Type()) return NULL; //--- CNeuronGEGWA* temp = cNeck; return temp.GetInsideLayer(layer - 1); }
2.2 Linguistic Primitives Construction
Следующим этапом мы создаем объект модуля генерации примитивов Linguistic Primitives Construction в классе CNeuronLPC. Авторская визуализация данного метода представлена ниже.
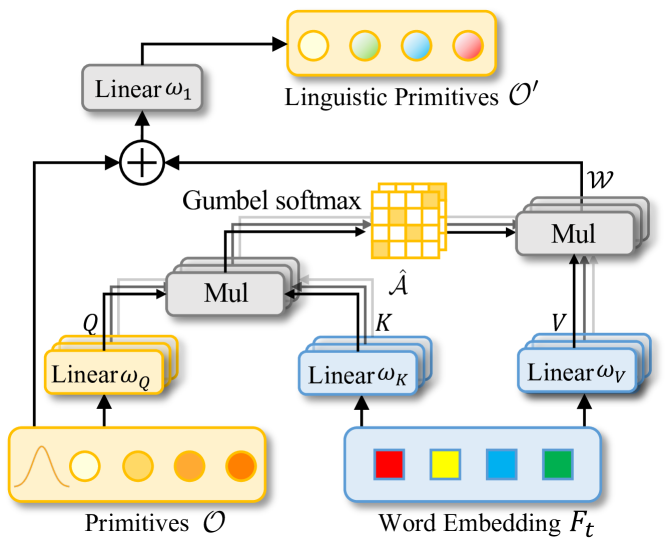
В ней несложно заметить сходство с классическим блоком кросс-внимания, что и послужило толчком для выбора родительского класса. В данном случаем мы используем объект кросс-внимания CNeuronMLCrossAttentionMLKV. Структура нового класса приведена ниже.
class CNeuronLPC : public CNeuronMLCrossAttentionMLKV { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cPrimitives; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return feedForward(NeuronOCL); } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return updateInputWeights(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronLPC(void) {}; ~CNeuronLPC(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronLPC; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Обратите внимание, если в предыдущем случае мы добавляли источники исходных данных для прямого и обратного проходов, то в данном случае наоборот. Несмотря на то, что модуль кросс-внимания требует два источника данных, в данной реализации мы будем использовать только один. Это связано с тем, что генерация второго источника данных (примитивов) осуществляется внутри данного объекта.
Для генерации обучаемых примитивов мы создаем 2 внутренних объекта полносвязных слоев. Оба объекта объявлены статично, что позволяет оставить "пустыми" конструктор и деструктор класса. Инициализация объявленных и унаследованных объектов осуществляется в методе Init.
bool CNeuronLPC::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, window, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false;
В параметрах данного метода, как всегда, мы получаем константы, позволяющие однозначно определить архитектуру создаваемого объекта. И в теле метода мы сразу вызываем одноименный метод родительского класса, в котором уже организованы контроль полученных параметров и инициализация унаследованных объектов.
Обратите внимание, что параметры генерируемых примитивов мы используем в качестве информации о первичном источнике данных.
Далее мы генерируем единичный полносвязный слой, состоящий из одного элемента.
if(!cOne.Init(window * units_count, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = cOne.getOutput(); if(!out.BufferInit(1, 1) || !out.BufferWrite()) return false;
А затем инициализируем слой генерации примитивом.
if(!cPrimitives.Init(0, 1, OpenCL, window * units_count, optimization, iBatch)) return false; //--- return true; }
Обратите внимание, что в данном случае мы не используем слой позиционного кодирования. Ведь по логике авторов метода одни примитивы отвечают за позицию объекта, а другие — аккумулируют его признаки.
Метод прямого прохода feedForward данного метода так же прост. В параметрах метода мы получаем указатель на объект исходных данных и сразу проверяем актуальность полученного указателя. Что, должен сказать, не часто встречается в последних методах прямого прохода.
bool CNeuronLPC::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Мы все больше привыкли, что подобная проверка осуществляется методами вложенных объектов. Однако в данном случае, полученные от внешней программы данные мы будем использовать в качестве контекста. А значит, при вызове методов внутренних объектов нам предстоит обращаться к вложенным объектам нашего источника данных. Поэтому мы вынуждены проверить полученный указатель.
Далее мы генерируем тензор признаков.
if(bTrain && !cPrimitives.FeedForward(cOne.AsObject())) return false;
И здесь надо сказать, что для сокращения времени принятия решения данная операция будет осуществляться только в процессе обучения модели. В режиме эксплуатации тензор примитивов остается статичным, и нам нет необходимости генерировать его на каждой итерации.
А завершает операции прямого прохода вызов одноименного метода родительского класса. В который мы передадим тензор примитивов в качестве первичного источника данных, а информацию, полученную от внешней программы, в качестве контекста.
if(!CNeuronMLCrossAttentionMLKV::feedForward(cPrimitives.AsObject(), NeuronOCL.getOutput())) return false; //--- return true; }
В методе распределения градиентов ошибки calcInputGradients мы выполняем операции в строгом соответствии с алгоритмом прямого прохода, только в обратном порядке.
bool CNeuronLPC::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Здесь мы также сначала проверяем полученный указатель на объект исходных данных. А затем вызываем одноименный метод родительского класса с распределением градиента ошибки между примитивами и исходным контекстом.
if(!CNeuronMLCrossAttentionMLKV::calcInputGradients(cPrimitives.AsObject(), NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) return false;
После чего добавим градиент ошибки диверсификации примитивов.
if(!DiversityLoss(cPrimitives.AsObject(), iUnits, iWindow, true)) return false; //--- return true; }
Распределение градиента ошибки до уровня единичного слоя не представляет ценности, поэтому мы опускаем данную операцию. А алгоритм метода обновления параметров мы оставим для самостоятельного изучения. Полный код данного класса и всех его методов вы можете найти во вложении.
Следующим блоком по ходу алгоритма RefMask3D идет блок ванильного декодера Transformer, в котором реализован алгоритм мультимодального кросс-внимания облака точек и обучаемых примитивов. Данный функционал мы можем покрыть уже имеющимися средствами. Поэтому не будем озадачиваться созданием нового блока.
И ещё один модуль, который нам предстоит реализовать, это модуль кластера объектов. Алгоритм данного модуля мы реализуем в классе CNeuronOCM. Это довольно комплексный модуль. Он сочетает в себе 2 блока Self-Attention примитивов и семантических функций, которые дополнены блоком кросс-внимания. Структура нового класса представлена ниже.
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); };
Думаю вы догадались, что методы данного класса имеют довольно сложные алгоритмы. Их описание требует пояснений. Однако формат статьи довольно ограничен. Поэтому с целью полноценного и качественного раскрытия реализованных алгоритмов, я предлагаю продолжить рассмотрение реализации в следующей статье. Там же будут представлены результаты тестирования моделей с использованием предложенных подходов на реальных данных.
Заключение
В данной статье мы познакомились с метод RefMask3D, который предназначен для анализа комплексного мультимодального взаимодействия и понимания признаков. Рассмотренный метод может стать важной инновацией в сфере трейдинга. Используя многомерные данные, он способен учитывать текущие и исторические паттерны рыночных данных. RefMask3D использует ряд механизмов, чтобы сосредоточиться на ключевых признаках, минимизируя влияние шума и нерелевантных данных.
В практической части статьи мы начали реализацию предложенных подходов средствами MQL5 и построили объекты двух предложенных модулей. Однако объем выполненной работы превышает размеры одной статьи. И начатая работа будет продолжена.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Введение в MQL5 (Часть 7): Руководство для начинающих по созданию советников и использованию кода от ИИ в MQL5
Введение в MQL5 (Часть 7): Руководство для начинающих по созданию советников и использованию кода от ИИ в MQL5
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования