Теория категорий в MQL5 (Часть 16): Функторы с многослойными перцептронами
Введение
В нашей серии статей показано, как некоторые фундаментальные концепции теории категорий могут быть представлены и использованы в коде MQL5, чтобы помочь трейдерам разрабатывать более надежные торговые системы. Существует множество аспектов теории категорий, но функторы и естественные преобразования, пожалуй, являются ключевыми. Снова останавливаясь на функторах (как и в двух предыдущих статьях), мы выделяем одну из краеугольных идей теории.
Однако в этой статье, несмотря на то, что мы всё еще говорим о функторах, мы будем исследовать его применение для генерации сигналов входа и выхода, в отличие от прошлой статьи, в которой мы фокусировались только на настройке трейлинг-стопа. Это опять же не означает, что в прилагаемом коде находится грааль. Скорее, это идея, которую читатель должен улучшать и модифицировать в зависимости от того, как он видит рынки.
Краткий обзор предыдущей статьи: Функторы и графы в MQL5
Функторы — это сопоставление (mapping) категорий, которое фиксирует отношения не только между объектами в двух категориях, но и между морфизмами этих категорий. Это означает, что мы реализуем в коде одно из двух сопоставлений при составлении прогнозов.
Графы, которые можно рассматривать как представление взаимосвязанных систем со стрелками и вершинами, были введены в серию в части 11. В предыдущей статье мы проиллюстрировали их данными экономического календаря, доступными в терминале MetaTrader 5, и использовали простую гипотезу, которая связывает 4 различные точки данных, которые составляют часть временного ряда. Этот граф, как было показано в статье, фактически является отдельной категорией.
Однако функторы, рассмотренные в нашей последней статье, отображают две категории с помощью простого линейного уравнения. В опубликованном коде были варианты масштабирования до квадратного уравнения, однако они не были реализованы в тестировании, проведенном для статьи. Таким образом, отображение функтора, по сути, брало значение объекта в категории домена, умножало его на коэффициент и добавляло константу, чтобы получить значение объекта в кодомене. Оно было линейным, поскольку коэффициент и константа фактически представляли собой наклон и точку пересечения оси y простого линейного уравнения.
Функторы теории категорий на основе данных экономического календаря
Переформатирование данных экономического календаря как категории, достигнутое с помощью графов, оказалось подходящим, учитывая сложную взаимосвязанность календарных данных. Как видно из вкладки календаря в терминале MetaTrader 5, существует множество различных типов экономических данных. Эта проблема была подчеркнута в предыдущей статье, где необходимость сопоставления этих данных при принятии торговых решений для валютной пары может быть затруднена из-за зависимости от валюты. Для обеспечения безопасности нет необходимости объединять данные. Тем не менее, тот факт, что некоторые из этих данных зависят от других экономических данных, следует принимать во внимание, особенно учитывая, что мы работаем с S&P 500. Чтобы решить эту проблему, в последней статье мы выдвинули простую гипотезу о том, что индекс потребительских цен (CPI) зависит от индекса PMI, а тот зависит от проведения казначейских аукционов (10-year yield auction), результаты которого, в свою очередь, зависят от розничных продаж. Таким образом, вместо временного ряда только одной из этих точек экономических данных, у нас есть ряд из нескольких точек, составляющих основу волатильности S&P 500.
Однако в этой статье нас интересует индекс S&P 500 не только из-за его волатильности, как это было в предыдущих статьях, но и из-за его трендов. Мы хотим делать прогнозы по его краткосрочным (месячным) трендам и использовать эти прогнозы для открытия позиций в нашем советнике. Это означает, что мы будем иметь дело с классом сигналов советника, а не с классом трейлинга, как это было до сих пор в этой серии. Таким образом, реализация преобразований на основе функторов на графах данных экономического календаря приведет к прогнозируемому изменению индекса S&P 500. Такая реализация будет достигнута с помощью многослойного перцептрона.
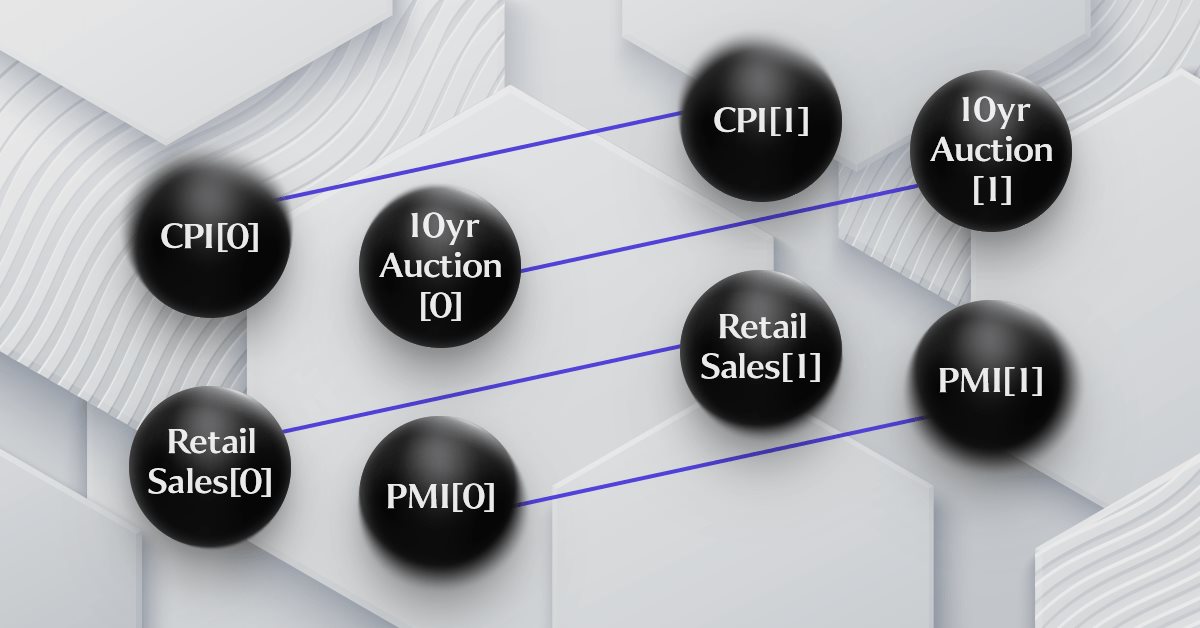
В последней статье я приводил схематическое представление нашей простой гипотезы, которая связывает четыре рассматриваемые точки экономических данных, однако она была чрезмерно упрощена и не отображалась в виде графа временного ряда. Попытаемся добиться этого на схеме ниже:

Как вы можете видеть на диаграмме, добавление объектов временных рядов добавляет некоторую сложность, что ясно подтверждает тот факт, что это граф. Гипотеза, на которой основана схема, является спорной. Кто-то, например, скажет, что индекс потребительских цен является результатом розничных продаж, на которые, в свою очередь, влияет PMI, зависящий от денежной массы, измеренной на основе результатов 10-летних аукционов. Существует даже ряд других вариантов с другими или более важными экономическими данными, которые, возможно, будут иметь более важное значение для влияния на дельту прогноза S&P 500. Хорошая новость заключается в том, что, несмотря на все эти возможные перестановки и гипотезы, тестер стратегий в терминале может опровергнуть все эти аргументы, поэтому полезно четко изложить свои идеи в формате, который можно эффективно протестировать.
Чтобы помочь в этом, мастер MQL5 позволяет легко собрать советник в несколько кликов, даже если всё, что вы написали, — это сигнальный файл.
Функторы теории категорий для значений индекса S&P 500
В файле сигналов представление значений индекса S&P 500 в виде графа представляет собой категорию, поскольку, как описано в последней статье, каждая вершина графа (точка данных) эквивалентна объекту, и, таким образом, стрелки между вершинами можно рассматривать как морфизмы. Объект может иметь один элемент, но в этом случае точка данных включает в себя больше, чем просто интересующее нас значение, поскольку дополнительные данные, не рассматриваемые для нашей категории, включают в себя: дату публикации экономических данных, консенсусные прогнозы для этих данных, ведущие к их выпуску, и другие данные. Все они перечислены на вкладке календаря в терминале MetaTrader. Эта ссылка ведет на страницу с типами событий календаря, и каждый перечисленный атрибут будет применим к нашему объекту. Все эти данные затем образуют объект или то, что мы называем множеством, в категории экономического календаря.
К сожалению, использование функторов для анализа и предварительной обработки исторических данных экономического календаря может быть выполнено только в тестере стратегий не напрямую с сервера(ов) MetaQuotes. Это, безусловно, узкое место, которое мы преодолели, экспортировав данные в CSV-файл с помощью скрипта, а затем прочитав этот CSV-файл в тестере стратегий, как в предыдущей статье. Разница здесь в том, что мы делаем это для экземпляра класса сигнала советника, а не для класса трейлинга. Поскольку мы имеем дело с двумя функторами, используемый скрипт создал два файла - с префиксом true, что означает, что функтор применяется к объектам, и с префиксом false, означающим, что он относится к морфизмам. Файлы приложены к статье.
Графическое представление преобразованных значений индекса S&P 500 представлено на диаграмме выше.
Архитектура нейронной сети на основе функторов
Функторы в качестве многослойных перцептронов (нейронных сетей) в этой статье — это шаг вперед по сравнению с предыдущими линейными или квадратичными отношениями, которые мы использовали при сопоставлении категорий и даже объектов внутри категории (поскольку отношения морфизма между двумя элементами могут быть определены таким же образом). Как подчеркивалось ранее, использование функторов подразумевает отображение не только объектов двух категорий, но и их соответствующих морфизмов. Таким образом, одно может проверить другое, то есть, если вы знаете объекты в категории кодомена, то подразумеваются морфизмы, и наоборот. Это означает, что мы будем иметь дело с двумя перцептронами между нашими категориями.
В этой статье не будут объясняться основы перцептронов, поскольку на эту тему есть множество статей не только на этом веб-сайте, но и в Интернете в целом, поэтому читателю предлагается провести собственное предварительное исследование, если это поможет прояснить то, что здесь изложено. Представленная здесь сетевая архитектура была реализована во многом благодаря Alglib, доступном в MetaTrader IDE в папке Include\Math. А вот так происходит инициализация персептрона с помощью библиотеки:
//+------------------------------------------------------------------+ //| Function to train Perceptron. | //+------------------------------------------------------------------+ bool CSignalCT::Train(CMultilayerPerceptron &MLP) { CMLPBase _base; CMLPTrain _train; if(!ReadPerceptron(m_training_profit)) { _base.MLPCreate1(__INPUTS,m_hidden,__OUTPUTS,MLP); m_training_profit=0.0; } else { printf(__FUNCSIG__+" read perceptron, with profit: "+DoubleToString(m_training_profit)); } ... return(false); }
Перцептроны, используемые из этой библиотеки, очень просты и состоят из трех слоев - входной слой, скрытый слой и выходной слой. Наша категория экономических данных содержит одновременно четыре точки данных (на основе нашей гипотезы), поэтому количество входных данных в скрытом слое будет равно четырем. Количество точек на скрытом слое будет одним из немногих оптимизируемых параметров, но наше значение по умолчанию — семь. Затем, наконец, в выходном слое появится один результат — прогнозируемое изменение индекса S&P 500. Знание весов, отклонений и функций активации является ключом к пониманию работы персептронов с прямой связью. Читателю предлагается провести исследование по этим вопросам по мере необходимости.
Обучение нейронной сети на основе функтора
Процесс обучения на данных исторического экономического календаря будет осуществляться с использованием алгоритма Левенберга-Марквардта. Как и в случае с прямым и обратным распространением ошибки, код обрабатывается функциями AlgLib. Мы бы реализовали обучение с использованием библиотеки следующим образом:
int _info=0; CMatrixDouble _xy; CMLPReport _report; TrainingLoad(m_training_stop,_xy,m_training_points,m_testing_points); // if(m_training_points>0) { _train.MLPTrainLM(MLP,_xy,m_training_points,m_decay,m_restarts,_info,_report); if(_info>0){ return(true); } }
Ключевой частью здесь является заполнение матрицы XY входными данными из файла csv в общем каталоге. Матрица извлекает четыре точки данных, определенные в каждой строке данных, как исторические данные, каждый раз, когда генерируется новый столбец (или по таймеру), и использует его для обучения сети, чтобы генерировать ее веса и смещения. Заполнение входной матрицы XY будет обрабатываться функцией TrainingLoad, как показано ниже:
//+------------------------------------------------------------------+ //| Function Get Training Points and Initialize Training Matrix. | //+------------------------------------------------------------------+ void CSignalCT::TrainingLoad(datetime Date,CMatrixDouble &XY,int &TrainingPoints,int &TestingPoints) { TrainingPoints=0; TestingPoints=0; ResetLastError(); string _file="_s_"+m_currency+"_"+m_symbol.Name()+"_"+EnumToString(m_period)+"_"+string(m_objects)+".csv"; int _handle=FileOpen(_file,FILE_SHARE_READ|FILE_ANSI|FILE_COMMON,"\n",CP_ACP); if(_handle!=INVALID_HANDLE) { string _line=""; int _line_length=0; while(!FileIsLineEnding(_handle)) { //--- find out how many characters are used for writing the line _line_length=FileReadInteger(_handle,INT_VALUE); //--- read the line _line=FileReadString(_handle,_line_length); string _values[]; ushort _separator=StringGetCharacter(",",0); if(StringSplit(_line,_separator,_values)==6) { datetime _date=StringToTime(_values[0]); _d_economic.Let(); _d_economic.Cardinality(4); //printf(__FUNCSIG__+" initializing for: "+TimeToString(Date)+" at: "+TimeToString(_date)); if(_date<Date) { TrainingPoints++; // XY.Resize(TrainingPoints,__INPUTS+__OUTPUTS); for(int i=0;i<__INPUTS;i++) { XY[TrainingPoints-1].Set(i,StringToDouble(_values[i+1])); } // XY[TrainingPoints-1].Set(__INPUTS,StringToDouble(_values[__INPUTS+1])); } else { TestingPoints++; } } } FileClose(_handle); } else { printf(__FUNCSIG__+" failed to load file. Err: "+IntegerToString(GetLastError())); } }
Стоит отметить, что после обучения причина, по которой нейронные сети работают и популярны, заключается в их способности разрабатывать и повторно использовать веса и смещения. В этой статье хранение этих весов и смещений осуществляется с помощью специальной функции, которой автор пока не готов делиться, поэтому ссылка на нее в виде библиотеки ex5 будет присутствовать в листинге, но ее код — нет.
Обычно при обучении сети используется предварительная обработка данных, которая направлена на нормализацию данных до сопоставимых значений и разделение их на наборы обучения и тестирования. Однако для наших целей мы обучаем загруженный набор исторических данных при инициализации эксперта, а затем тестируем его, используя отдельную часть данных CSV, разделение которых из обучающих данных определяется входной датой. Поскольку нашим единственным оптимизируемым параметром будет количество весов в скрытом слое (от 5 до 12), мы записываем обученные веса сети в файл в общем каталоге и в конце каждого прохода оптимизации, только если критерии оптимизации этого прохода превышают критерии оптимизации уже записанного файла на более раннем проходе. Если запись сделана, то при инициализации сети на следующем проходе начальные веса будут записаны из этого файла.
Обратное распространение ошибки и градиентный спуск обрабатываются функцией MLPTrainLM, которая находится в классе CMLPTrain библиотеки AlgLib.
Генерация торговых сигналов с использованием функторов и нейронных сетей
Категория S&P 500, представляющая собой линейный порядок изменений индекса образует кодомен для наших "двух" функторов из категории данных экономического календаря. Напомню, что их "два", потому что объекты и морфизмы связаны. Таким образом, наш сигнал на тестовом периоде, определяемом входной датой, считанной из файла CSV, будет генерироваться весами, полученными в конце каждого обучения. Обучение коду, приложенному к этой статье, происходит при каждой инициализации советника. К статье приложен файл сигналов, который, как и файлы, приложенные к предыдущим статьям, можно использовать после сборки в мастере MQL5 через MetaEditor IDE. Мы могли бы дополнительно потренироваться на таймере, поскольку каждый новый столбец предоставляет новую строку данных для нашего CSV-файла, однако этот подход не рассматривается в статье, и читателю предлагается самостоятельно изучить его, поскольку он может быстро обнаружить больше возникающих сигналов.
Наша функция GetOutput, как и в предыдущих статьях, будет отвечать за получение значения, на основе которого мы обрабатываем наше торговое решение. Как видно из листинга ниже, помимо обновления категорий текущими значениями, сетевые входы подготавливаются на основе текущих показаний календаря из файла csv в общем каталоге. Они заполняются в массиве "_x_inputs", из которого массив пересылается в сеть с помощью функции MLPProcess, которая является частью класса CMLPBase. Это показано ниже:
//+------------------------------------------------------------------+ //| Get Output value, forecast for next change in price bar range. | //+------------------------------------------------------------------+ double CSignalCT::GetOutput(datetime Date) { if(Date>=D'2023.07.01') { printf(__FUNCSIG__+" log profit: "+DoubleToString(m_training_profit)+", account profit: "+DoubleToString(m_account.Profit())+", equity: "+DoubleToString(m_account.Equity())+", deposit: "+DoubleToString(m_training_deposit)); if(m_training_profit<m_account.Equity()-m_training_deposit) { printf(__FUNCSIG__+" perceptron write... "); m_training_profit=m_account.Equity()-m_training_deposit; WritePerceptron(m_training_profit,_MLP); } } ... _value="";_e.Let();_e.Cardinality(1); _d_economic.Get(3,_e);_e.Get(0,_value); _x_inputs[3]=StringToDouble(_value);//printf(__FUNCSIG__+" val 4: "+_value); //forward feed?... CMLPBase _base; _base.MLPProcess(_MLP,_x_inputs,_y_inputs); _output=_y_inputs[0]; //printf(__FUNCSIG__+" output is: "+DoubleToString(_output)); return(_output); }
Существует также возможность включить управление рисками и определение размера позиций в торговую систему, использующую эти методы, которые могут включать определение размера в зависимости от величины сигнала. Это, безусловно, потребует нормализации значения сигнала, и, как всегда, при изменении размера позиции необходимо проявлять особую осторожность. Эти изменения, однако, могут быть достигнуты путем создания специального экземпляра класса ExpertMoney точно так же, как мы используем собственный экземпляр класса ExpertSignal при определении точек входа и выхода.
Обратное тестирование и оценка производительности
Наше тестирование на истории будет оптимизацией идеального количества весов в скрытом слое. Поскольку они варьируются от 5 до 12, существует только восемь вариантов, и все же мы хотим провести несколько прогонов для каждого числа весов, прежде чем выбрать идеальное число. Таким образом, чтобы иметь несколько прогонов, мы добавляем параметр, который не влияет на производительность советника, но должен быть оптимизирован, и, следовательно, добавляет дополнительные прогоны в процесс оптимизации, чтобы позволить каждому варианту количества весов выполнить несколько прогонов теста. Как упоминалось выше, если в конце каждого прогона результат теста лучше, чем у последнего файла, записанного в общую папку, то эти веса заменяют записанные ранее. Критерием оптимизации будет максимальная прибыль. Мы проводим прогоны на месячном временном интервале, потому что календарные экономические данные в среднем обновляются примерно так же часто. Тестовые прогоны индекса S&P 500 на месячном интервале проводились с 1 июля по 1 августа 2022 года, и наш лучший прогон для функтора объект-объект дал следующие результаты:

Точно так же наш функтор морфизм-морфизм дал следующие результаты:

Анализ ключевых показателей отчетов по просадке и коэффициенту прибыли показывает большую эффективность функтора морфизм-морфизм. Возможно, именно на него стоит обратить внимание при дальнейшей работе? Ответ на этот вопрос будет зависеть не только от тестирования на альтернативных ценных бумагах, но и на использовании различных подходов к обучению при проведении тестовых запусков, например, тех, которые рассматривают, следует ли проводить обучение на каждом новом баре или ежеквартально.
Заключение
Ключевые результаты тестирования с помощью перцептронов заключаются в том, что торговая система может быть разработана с использованием сигнала, подобного тому, который представлен в файле сигналов. На этапе разработки должна быть доступна подходящая категория предметной области с данными в формате, легко доступном для тестировщика стратегий, а поскольку надежное тестирование обычно занимает несколько лет, эти данные должны быть обширными.
Значение использования многослойных перцептронов в качестве функторов — это не просто шаг вперед. Такое применение имеет большой потенциал, учитывая множество типов и форматов, которые могут использовать нейронные сети. В статье приведены ссылки на дальнейшее изучение перцептронов. Тема хорошо известна и задокументирована. Многие уже рассмотренные понятия, включая пределы, копределы и универсальные свойства, могут быть сформулированы с помощью нейронных сетей.
Ссылки
Ссылки на статьи в Википедии приведены в статье.
Примечания к приложениям
Поместие файл SignalCT_16_.mqh в папку MQL5\include\Expert\Signal\, а файл ct_16.mqh - в MQL5\include\.
Возможно, вам также будут полезны рекомендации, приведенные здесь, о том, как собрать советник с помощью Мастера. Как указано в статье, я не использовал трейлинг-стоп и фиксированную маржу для управления капиталом. Обе составляющие являются частью библиотеки MQL5. Как всегда, цель статьи – не представить вам Грааль, а скорее, предложить идею, которую вы можете адаптировать к своей собственной стратегии.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/13116
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования