
Разрабатываем мультивалютный советник (Часть 18): Автоматизация подбора групп с учётом форвард-периода
Введение
В одной из предыдущих частей цикла статей (в части 7) мы рассматривали подбор группы одиночных экземпляров торговых стратегий с целью улучшения результатов при их совместной работе. Для подбора мы применяли два подхода. В первом подходе подбор группы происходил при использовании результатов оптимизации, полученных на всём временном интервале оптимизации. В группу мы старались брать те одиночные экземпляры, которые показали наилучшие результаты на интервале оптимизации. Во втором подходе из временного интервала оптимизации выделялся небольшой кусок, на котором оптимизация одиночных экземпляров не проводилась. Выделенный кусок временного интервала затем использовался при подборе группы: мы старались брать в группу те одиночные экземпляры, которые показывали хорошие (но не самые лучшие) результаты на интервале оптимизации и при этом показывали примерно такие же результаты на выделенном куске временного интервала.
В итоге результаты оказались такими:
- Явного преимущества отбора первым способом перед вторым способом мы не увидели. Возможно, это было связано с коротким временным интервалом истории, на котором мы сравнивали результаты двух способов. Всё-таки три месяца маловато для оценки стратегии, которая может иметь и более длительные периоды топтания на месте.
- Второй способ показал, что на выделенном куске временного интервала результаты оказываются лучше, если мы применяем отбор в группу по описанному в статье алгоритму нахождения близких по результатам одиночных экземпляров торговых стратегий. Если же отбирать их просто по максимально хорошим результатам на интервале оптимизации (как в первом способе, но только на более коротком интервале), то результаты отобранной группы были заметно хуже.
- Возможно комбинирование обоих способов, то есть построение двух групп отобранных разными способами и затем объединение двух полученных групп в одну группу.
В части 13 мы реализовали автоматизацию второго этапа оптимизации, в рамках которого как раз происходил отбор в группу одиночных экземпляров торговых стратегий, полученных на первом этапе. Мы применяли простой поиск с использованием генетического алгоритма штатного оптимизатора в тестере стратегий. Никакой предварительной кластеризации одиночных экземпляров (рассмотренной в части 6) мы пока не выполняли. Таким образом мы автоматизировали подбор групп первым способом. До реализации подбора групп вторым способом тогда дело не дошло, а теперь самое время вернуться к этому вопросу. Попробуем в рамках данной статьи добиться возможности автоматизированного отбора одиночных экземпляров торговых стратегий в группы с учётом поведения их на форвард-периоде.
Намечаем путь
Как всегда, посмотрим в начале на то, что у нас уже есть, и чего не хватает для решения поставленной задачи. Мы можем поставить задачу провести оптимизацию торговой стратегии на любом нужном интервале времени. Слова "поставить задачу" следует воспринимать буквально: для этого мы создаём нужные записи в таблице задач (tasks) нашей базе данных. Соответственно, сделать вначале оптимизацию на одном интервале времени (например, с 2018 по 2022 годы включительно), а затем на другом интервале (например за 2023 год) мы можем.
Но при таком подходе мы не можем использовать полученные результаты желаемым образом. На каждом из двух временных интервалов оптимизация будет проводиться независимо, поэтому сравнивать между собой будет нечего: проходы второй оптимизации не будут повторять проходы первой по значениям входных параметров. Сказанное справедливо для генетической оптимизации, которой мы пользуемся. Понятно, что для полной оптимизации это не верно, но ею мы ещё ни разу не пользовались и, скорее всего, не будем пользоваться и в дальнейшем из-за большого количество комбинаций оптимизируемых параметров.
Поэтому придётся задействовать запуск процесса оптимизации с указанным форвард-периодом. В этом случае на форвард-периоде тестер будет использовать те же самые комбинации входных параметров, что и на основном периоде. Но мы пока не пробовали запускать автоматизированную оптимизацию с форвард-периодом, и не знаем, как эти результаты будут попадать в нашу базу данных. Сможем ли мы потом отличить проходы в рамках основного периода от проходов на форвард-периоде? Это надо будет проверить.
После того как мы будем уверены в наличии в базе данных всей необходимой информации о проходах и для основного, и для форвард-периода, можно приступать к следующему этапу. В статье 7 после получения этих результатов мы вручную выполняли их анализ и отбор, используя для этих целей Excel. Однако в контексте автоматизации его использование представляется неэффективным. Всё-таки мы стараемся уйти от каких-либо ручных манипуляций с данными в процессе получения итогового советника. К счастью, все действия, которые мы выполняли в Excel (пересчёт некоторых результатов, вычисление отношений показателей проходов за разные периоды тестирования, нахождение итоговой оценки для каждой группы стратегий и сортировку по ней) можно выполнить в программе MQL5 через SQL-запросы к нашей базе данных или запуска скрипта на Python.
Выполнив сортировку по итоговой оценке, возьмём в итоговый советник только самую верхнюю группу. Подобные действия выполним для всех комбинаций выбранных символов и таймфреймов. После нормировки общей группы, включающей лучшие группы для всех пар символ-таймфрейм, итоговый советник будет готов.
Приступим к реализации, но сначала исправим ошибку, которая была обнаружена.
Исправление ошибки сохранения
Когда мы разрабатывали советник для автоматизации первого этапа (оптимизации одиночных экземпляров торговых стратегий), то использовали только одну базу данных. Поэтому не возникало вопроса из какой базы данных мы должны получать или в какую сохранять данные. На втором этапе оптимизации была добавлена новая вспомогательная база данных, которая содержала минимально необходимую выжимку из основной базы данных. Именно такой сокращённый вариант базы данных рассылался агентам тестирования в рамках второго этапа оптимизации.
Но из-за уже выбранного подхода при реализации статического класса работы с базой данных нам пришлось применять несколько неудобное решение, позволяющее менять имя базы данных при необходимости. Причём после смены имени все дальнейшие вызова метода подключения к базе данных использовали уже новое имя. Отсюда и возникала ошибка при добавлении результатов прохода на втором и третьем этапах. Причина была в отсутствии переключения обратно на основную базу во всех местах, где это необходимо.
Для исправления мы добавили в советник каждого этапа и в советник автоматической оптимизации проектов дополнительный входной параметр, в котором задаётся имя основной базы данных. Помимо устранения ошибки, это полезно ещё тем, что мы можем лучше разделять базы данных, которые используются в разных статьях. Например, в этой части была использована новая основная база, так как состав задач оптимизации мы решили сократить, но не хотелось очищать уже имевшуюся базу данных:
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ sinput string fileName_ = "database683.sqlite"; // - Файл с основной базой данных
В функции OnInit() советника второго этапа SimpleVolumesStage2.mq5 внутри вызова функции LoadParams() происходило подключение к вспомогательной базе данных, так как данные о входных параметрах одиночных экземпляров торговых стратегий для соединения в группу надо брать именно из неё. После завершения прохода вызывалась функция OnTester(), в которой сохранение результатов прохода группы должно было выполняться уже в основную базу данных. Но так как обратного переключения на основную базу данных не происходило, то полные результаты прохода (48 столбцов) пытались вставиться в таблицу во вспомогательной базе данных (2 столбца).
Поэтому мы добавили недостающее переключение на основную базу данных в функции OnInit() советника второго этапа SimpleVolumesStage2.mq5:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Загружаем наборы параметров стратегий string strategiesParams = LoadParams(indexes); // Подключаемся к основной базе данных DB::Connect(fileName_); DB::Close(); ... // Создаем эксперта, работающего с виртуальными позициями expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
В советниках оптимизации первого и третьего этапа, на которых не используется вспомогательная база данных мы добавили в первый вызов метода подключения к базе данных имя базы, взятое из нового входного параметра советника:
DB::Connect(fileName_)
Ещё один обнаруженный вид ошибок возникал, когда после завершения мы хотели запустить один из понравившихся проходов отдельно. Проход запускался и выполнялся нормально, но его результаты не попадали в базу данных. Причина оказалась в том, что при таком запуске идентификатор задачи оставался равным 0, а в базе данных в таблицу проходов (passes) можно записать только строку идентификатором существующей задачи в таблице задач (tasks).
Исправить это можно было либо сделав так, чтобы идентификатор задачи брал значение из входных параметров советника (откуда он берётся при оптимизации), либо добавив в базу данных фиктивную задачу с идентификатором 0. В итоге мы выбрали второй вариант, чтобы наши запущенные вручную одиночные проходы не считались проходами, выполненными в рамках какой-то конкретной задачи оптимизации. Для добавленной фиктивной задачи необходимо было указать любой идентификатор существующей работы, чтобы не нарушать ограничений для внешних ключей и статус 'Done', чтобы эта задача не запускалась при автоматической оптимизации.
После внесения этих исправлений вернёмся к основной поставленной задаче.
Подготовка кода и базы данных
Возьмём копию существующей базы данных, очистим её от данных о проходах, задачах и работах. Затем модифицируем данные первого этапа, добавив в них дату начала форвард-периода. Второй этап из таблицы этапов (stages) можно удалить. Создадим для первого этапа одну запись в таблице работ (jobs), указав в ней символ и период (EURGBP H1) и параметры для тестера стратегий. В них включим оптимизацию только по одному параметру, чтобы количество проходов было небольшим. Это позволит нам быстрее получить результаты. Для созданной работы в таблице задач (tasks) добавим одну задачу с комплексным критерием оптимизации.
Запустим советник автоматической оптимизации проектов, указав созданную базу данных во входном параметре. После первого запуска выяснилось, что советник автоматической оптимизации нуждается в доработке, так как информацию из базы данных о необходимости использования форвард-периода он не получал. После дополнений код функции получения очередной задачи оптимизации из базы данных стал выглядеть так (добавленные строки выделены цветом):
//+------------------------------------------------------------------+ //| Получение очередной задачи оптимизации из очереди | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Результат ulong res = 0; // Запрос на получение очередной задачи оптимизации из очереди string query = "SELECT s.expert," " s.optimization," " s.from_date," " s.to_date," " s.forward_mode," " s.forward_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Processing')" " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // Открываем базу данных if(DB::Connect()) { // Выполняем запрос int request = DatabasePrepare(DB::Id(), query); // Если нет ошибки if(request != INVALID_HANDLE) { // Структура данных для чтения одной строки результата запроса struct Row { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Читаем данные из первой строки результата if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(row.expert), row.symbol, row.period, row.optimization, row.from_date, row.to_date, row.forward_mode, row.forward_date, row.optimization_criterion, row.id_task, fileName_, row.tester_inputs ); res = row.id_task; } else { // Сообщаем об ошибке при необходимости PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Сообщаем об ошибке при необходимости PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Закрываем базу данных DB::Close(); } return res; }
Мы также добавили функцию получения пути к файлу оптимизируемого советника из текущей папки относительно корневой папки экспертов терминала:
//+------------------------------------------------------------------+ //| Получение пути к файлу оптимизируемого советника из текущей | //| папки относительно корневой папки советников терминала | //+------------------------------------------------------------------+ string GetProgramPath(string name) { string path = MQLInfoString(MQL_PROGRAM_PATH); string programName = MQLInfoString(MQL_PROGRAM_NAME) + ".ex5"; string terminalPath = TerminalInfoString(TERMINAL_DATA_PATH) + "\\MQL5\\Experts\\"; path = StringSubstr(path, StringLen(terminalPath), StringLen(path) - (StringLen(terminalPath) + StringLen(programName))); return path + name; }
Это позволило в базе данных в таблице этапов указывать только имя файла оптимизируемого советника без перечисления имён папок, в которые он вложен относительно корневой папки советников \MQL5\Experts\.
Следующие запуски советника автоматической оптимизации проектов показали, что результаты форвард-проходов успешно добавляются в таблицу passes наряду с результатами обычных проходов. Однако после завершения этапа различать какие проходы к какому периоду (основному или форвард) относятся достаточно сложно. Можно, конечно, воспользоваться тем, что проходы форвард-периода всегда идут после обычных проходов, но это перестаёт работать, если в таблице passes появятся результаты нескольких задач оптимизации с форвард-периодом. Поэтому добавим столбец is_forward в таблицу passes, чтобы отличать обычные проходы от форвард-проходов. А чтобы можно было легко отличать обычные проходы от проходов, выполненных в рамках оптимизации добавим заодно и столбец is_optimzation.
Попутно была обнаружена неточность: при формировании строки SQL-запроса на вставку данных с результатами прохода мы подставляли номер прохода как знаковое целое, используя спецификатор %d. Однако номер прохода является беззнаковым длинным целым, поэтому для корректной подстановки его значения в строку следует использовать спецификатор %I64u.
Добавим значение соответствующей функции определения признака форвард-периода в код формирования SQL-запроса на вставку данных прохода:
string CTesterHandler::GetInsertQuery(string values, string inputs, ulong pass) { return StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %I64u, %d, %s,\n'%s',\n'%s') RETURNING rowid;", s_idTask, pass, (int) MQLInfoInteger(MQL_FORWARD), values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); }
Однако выяснилось, что это не будет работать так, как хотелось бы. Дело в том, что данная функция вызывается из советника, запущенного в главном терминале в режиме сбора фреймов данных. Поэтому для него результат вызова MQLInfoInteger(MQL_FORWARD) всегда возвращает false.
Поэтому признак форвард-периода надо получать в коде, который работает на агентах тестирования, а не в главном терминале на графике, то есть в обработчике события завершения прохода тестирования. Рядом добавили и признак оптимизации.
//+------------------------------------------------------------------+ //| Обработка завершения прохода тестера для агента | //+------------------------------------------------------------------+ void CTesterHandler::Tester(double custom, // Пользовательский критерий string params // Описание параметров советника в текущем проходе ) { ... // Формируем строку с данными о проходе data = StringFormat("%d, %d, %s,'%s'", MQLInfoInteger(MQL_OPTIMIZATION), MQLInfoInteger(MQL_FORWARD), data, params); ... }
После внесения таких правок и перезапуска советника автоматической оптимизации, мы, наконец-то, увидели желаемую картину в таблице проходов:
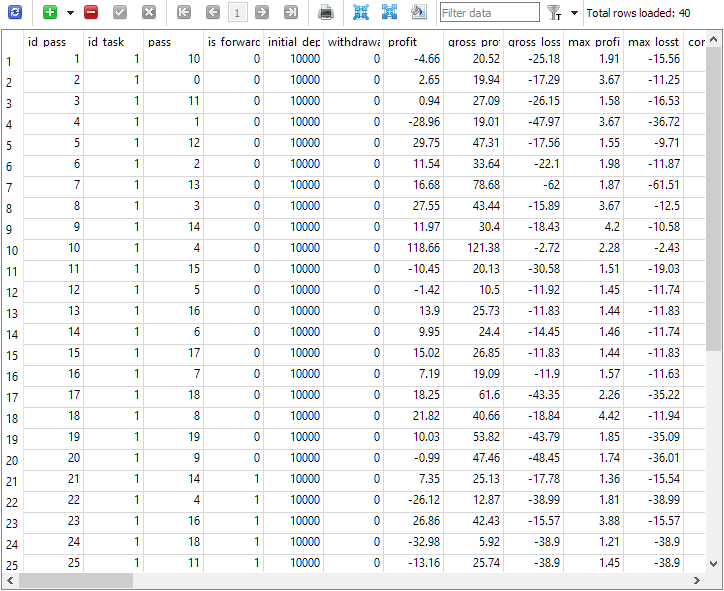
Рис. 1. Таблица проходов passes после выполнения задачи оптимизации с форвард-периодом
Как видно, в рамках выполнения задачи оптимизации с id_task = 1 было выполнено всего 40 проходов. Из них 20 были обычными (первые 20 строк с is_forward = 0), а остальные 20 - проходами на форвард-периоде (is_forward = 1). Номера проходов тестера в столбце pass принимают значения от 1 до 20 и каждое встречается ровно 2 раза (один раз для основного периода, второй раз - для форвард-периода).
Подготовка к запуску полной оптимизации
Проверив, что в базу данных теперь корректно попадают результаты проходов, совершаемых с использованием форвард-периода, проведём более приближенный к реальным условиям тест работы автоматической оптимизации. Для этого в чистую базу данных добавим уже два этапа. На первом будет оптимизироваться одиночный экземпляр торговой стратегии, но только на одном символе и периоде (EURGBP H1) на промежутке 2018 - 2023 годов. Форвард-период на этом этапе использоваться не будет. На втором этапе будет оптимизироваться группа из хороших одиночных экземпляров, полученных на первом этапе. Теперь форвард период уже будет использоваться: под него отводится весь 2023 год.

Рис. 2. Таблица этапов stages с двумя этапами
Для каждого этапа в таблице работ jobs создадим работы, которые будут выполняться в рамках данного этапа. В этой таблице, помимо символа и периода указываются входные параметры для оптимизируемых советников с диапазонами и шагом изменения.
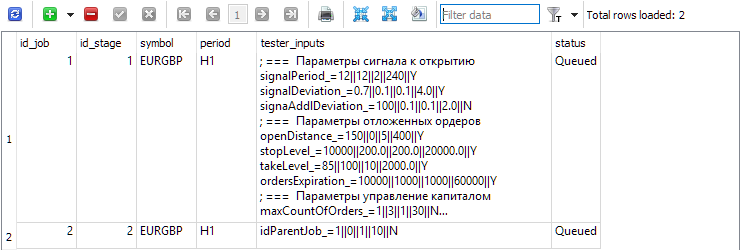
Рис. 3. Таблица работ jobs с двумя работами для первого и второго этапа соответственно
Для первой работы (id_job = 1) мы создадим несколько задач оптимизации, которые будут отличаться значением критерия оптимизации (optimization_criterion = 0 ... 7) . Переберём все критерии по очереди, а комплексный критерий будем использовать дважды: в начале и в конце первой работы (optimization_criterion = 7). Для задачи, выполняемой в рамках второй работы (id_job = 2), будем использовать пользовательский критерий оптимизации (optimization_criterion = 6)
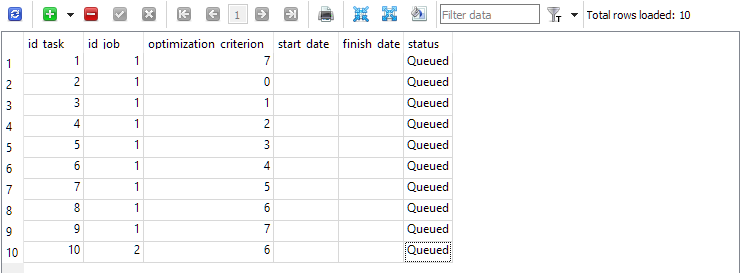
Рис. 4. Таблица задач tasks с задачами для первой и второй работы
Запустим советник автоматической оптимизации на любом графике терминала и дождёмся окончания выполнения всех поставленных задач. На имеющихся агентах процесс занял суммарно около 4 часов.
Предварительный анализ результатов
В рамках прошедшей автоматической оптимизации у нас была только одна задача оптимизации, в которой использовался форвард-период. Критерием оптимизации в неё выступал наш пользовательский критерий, рассчитывающий нормированную среднегодовую прибыль для данного прохода. Посмотрим на облако точек со значениями этого критерия на основном периоде.
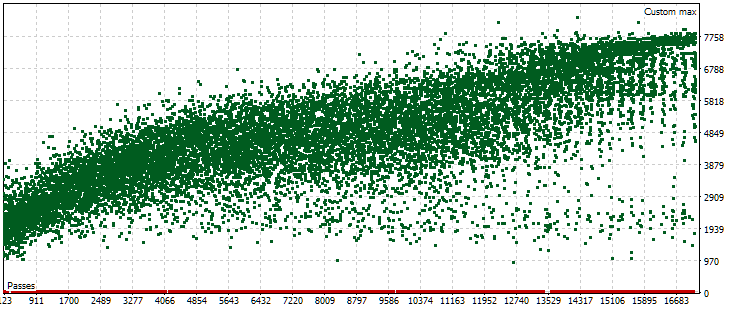
Рис. 5. Облако точек со значениями нормированной среднегодовой прибыли для разных проходов на основном периоде
На графике видно, что значение нашего критерия находится в диапазоне от $1000 до $8000. Красные точки, соответствующие значению 0, возникают из-за того, что в некоторых комбинациях индексов одиночных экземпляров во входных параметрах возникают повторяющиеся значения. Такие входные параметры считаются некорректными группами стратегий, и результатов данных проходов не будет. Заметна общая тенденция на возрастание нормированной среднегодовой прибыли в более поздних проходах. В среднем, лучшие достигнутые результаты примерно в два раза превышают результаты первых проходов, в которых параметры выбираются почти случайно.
Теперь посмотрим на облако точек с результатами проходов на форвард-периоде. Их будет меньше (около 13000 вместо 17000) из-за выбывших на основном этапе комбинаций параметров, признанных некорректными.
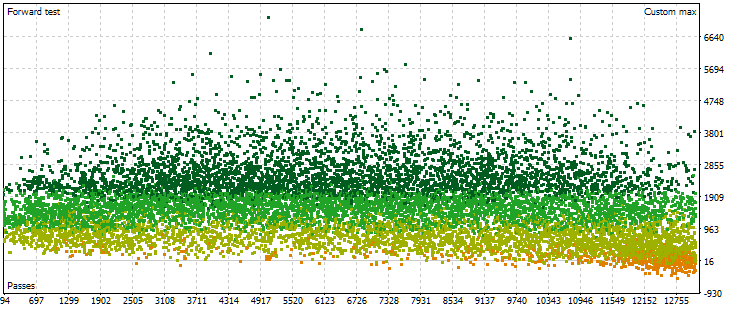
Рис. 6. Облако точек со значениями нормированной среднегодовой прибыли для разных проходов на форвард-периоде
Здесь картина расположения точек уже другая. Нет выраженного возрастания получаемых результатов с возрастанием номера прохода. Наоборот, мы видим, что ростом номера прохода результаты сначала достигают более высоких значений, чем вначале, а потом тенденция меняется на противоположную. При дальнейшем увеличении номера прохода его результаты в среднем начинают уменьшаться, причём скорость уменьшения возрастает при приближении к правой границе номеров.
Однако, как выяснилось, такая картина будет не всегда. При других настройках диапазонов перебираемых при оптимизации параметров облака точек для проходов на основном и форвард-периоде могут выглядеть и так:
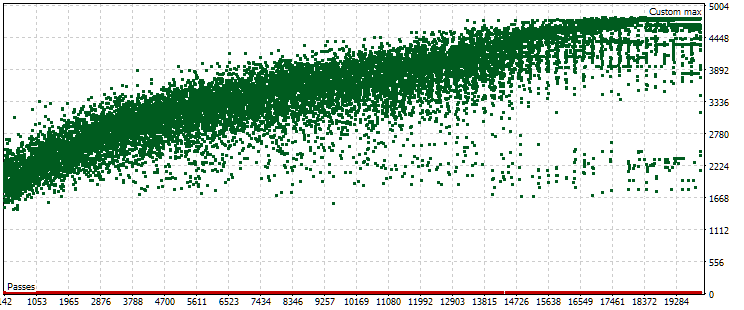
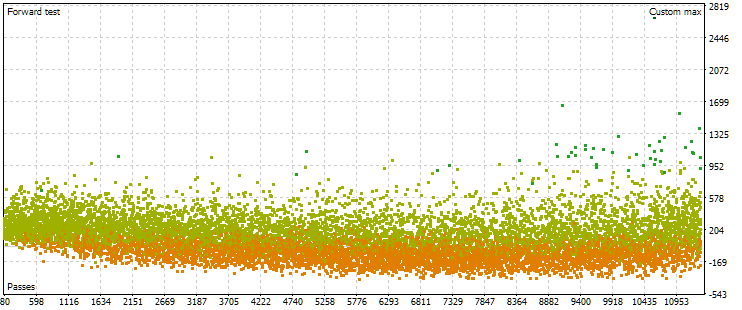
Рис. 7. Облако точек со значениями нормированной среднегодовой прибыли на основном и форвард-периоде при других настройках оптимизации
Как видно, на основном периоде картина примерно такая же, только диапазон критерия теперь немного другой: от $1500 до $5000. Однако на форвард-периоде характер облака совершенно другой. Максимальные значения достигаются не на тех проходах, которые встретились примерно в середине процесса оптимизации, а только ближе к концу. Также в среднем значения критерия на форвард-периоде меньше примерно в 10 раз вместо 3 раз, как в первом процессе оптимизации.
Интуиция подсказывала, что для повышения устойчивости получаемых результатов на разных периодах нам надо выбрать такую группу, у которой результаты на основном и форвард-периоде примерно одинаковые. Однако полученные результаты заставили сильно засомневаться, что так мы сможем получить что-то полезное. Особенно в том случае, когда даже максимальное значение критерия на форвард-периоде заметно меньше даже не особо хороших значений критерия на основном периоде. Тем не менее попробуем. Поищем условно "близкие" проходы на основном и форвард-периоде и посмотрим на их результаты на основном, форвард-периоде и 2024 году.
Выбор проходов
Давайте вспомним, каким образом мы выбирали лучшую группу с учётом результатов на форвард-периоде в части 7. Вот краткое изложение алгоритма с небольшими поправками:
- Скорректируем значение нормированной среднегодовой прибыли для проходов на форвард-периоде, взяв для расчёта максимальную просадку из двух значений: на основном и форвард-периоде. Получим величину OOS_ForwardResultCorrected.
- В объединённой таблице результатов оптимизации за 2018-2022 (основной период) и за 2023 (форвард-период) вычислим для всех показателей отношение их значений на основном и форвард-периоде.
Например, для количества сделок: TradesRatio = OOS_Trades / IS_Trades, а для нормированной среднегодовой прибыли: ResultRatio = OOS_ForwardResultCorrected / IS_BackResult.
Чем ближе к 1 будут эти отношения, тем более одинаковы оказались значения данных показателей на двух периодах. - Рассчитаем для всех этих отношений сумму их отклонений от единицы. Эта величина будет нашей мерой отличия результатов каждой группы на основном и форвард-периоде:
SumDiff = |1 - ResultRatio| + ... + |1 - TradesRatio|. -
Учтём, что на основном и форвард-периоде для каждого прохода просадка могла быть разной. Выберем максимальную просадку из двух периодов и по ней рассчитаем коэффициент масштабирования размеров открываемых позиций для достижения нормированной просадки 10%:
Scale = 10 / MAX(OOS_EquityDD, IS_EquityDD).
-
Теперь нам желательно выбрать наборы, где SumDiff будет поменьше, а Scale — побольше. Для этого вычислим последний показатель:
Res = Scale / SumDiff.
-
Отсортируем все группы по рассчитанной на предыдущем шаге величине Res по убыванию. Тогда вверху таблицы окажутся те группы, у которых результаты на основном и форвард-периоде были более похожими, и просадка на обоих периодах была поменьше.
Дальше мы предлагали повторять несколько раз отбор групп, предварительно удаляя те, которые содержат номера одиночных экземпляров торговых стратегий уже вошедших во взятые группы. Но этот шаг будет актуален при предварительной кластеризации одиночных экземпляров, чтобы разным индексам соответствовали непохожие между собой по результатам экземпляры. Поскольку пока что до кластеризации при автоматической оптимизации мы ещё не дошли, то пропустим этот шаг.
Зато вместо него мы можем добавить второй уровень группировки по разным таймфреймам для каждого символа и третий уровень по разным символам.
Приведённый алгоритм мы немного доработаем. Начнём с того, что по сути мы хотим понять насколько далеко друг от друга находятся два набора результатов прохода в пространстве с размерностью, равной количеству сравниваемых результатов (признаков). Для этого мы использовали норму первого порядка с некоторым масштабным коэффициентом для нахождения расстояния от точки с координатами отношений сравниваемых результатов от фиксированной точки с единичными координатами. Однако среди этих отношений могут быть как близкие к 1, так и очень далёкие. Последние могут необоснованно ухудшать общую оценку расстояния. Поэтому попробуем заменить предложенный ранее вариант на вычисление обычного евклидова расстояния между двумя векторами результатов, для которых мы предварительно применим мин-макс масштабирование.
Нам потребуется написать в итоге довольно сложный SQL-запрос (хотя, могут быть и гораздо более сложные запросы). Давайте посмотрим на процесс создания требуемого запроса подробнее. Мы начнём с простых запросов и будем их постепенно усложнять. Часть результатов мы будем помещать во временные таблицы, которые будут использоваться в дальнейших запросах. После каждого запроса будем показывать, как выглядят его результаты.
Итак, исходные данные, из которых нам нужно что-то получить, находятся в основном в таблице passes. Убедимся, что они там действительно есть, и сделаем сразу отбор только тех проходов, которые выполнялись в рамках нужной задачи оптимизации. В нашем конкретном случае идентификатор задачи id_task, соответствующий оптимизации второго этапа для EURGBP H1 имел значение 10. Поэтому будем его использовать в тексте запроса:
-- Запрос 1
SELECT *
FROM passes p0
WHERE p0.id_task = 10; 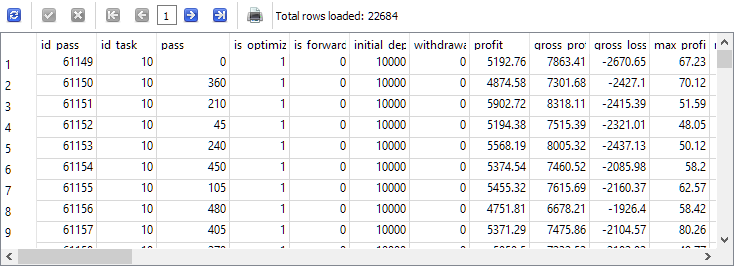
Видим, что записи в таблице passes для данной задачи с id_task=10 присутствуют в количестве более 22 тысяч штук.
Следующим шагом соединим в одну строку результаты из двух строк этого набора данных, соответствующие одинаковым номерам проходов тестера, но разным периодам: основному и форвард-периоду. Временно ограничим количество показываемых в результате столбцов. Оставим только те, по которым можно проверить корректность отбора строк. Дадим названия получаемым столбцам по такому правилу: к имени столбца будем добавлять префикс "I_" для основного периода (In-Sample) и префикс "O_" для форвард-периода (Out-Of-Sample):
-- Запрос 2 SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, p0.custom_ontester AS I_custom_ontester, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, p1.custom_ontester AS O_custom_ontester FROM passes p0 JOIN passes p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 WHERE p0.id_task = 10 AND p1.id_task = 10
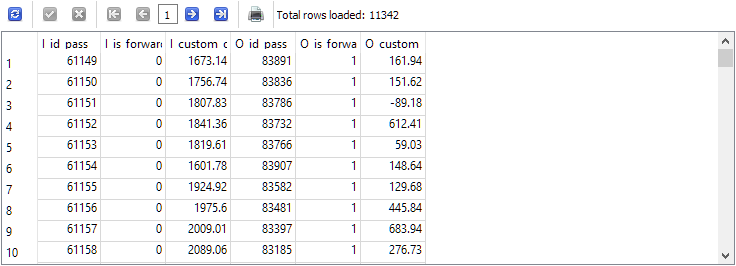
Количество строк в результате уменьшилось ровно в два раза, то есть для каждого прохода на основном периоде в таблице passes был ровно один проход на форвард-периоде и наоборот.
Теперь вернёмся к первому запросу для проведения нормировки. Если мы оставим нормировку на более позднее время, когда у нас уже будут отдельные столбцы для одного и того же параметра на основном и форвард-периоде, то нам будет сложнее вычислить минимальное и максимальное значение для обоих сразу. Выберем сначала небольшое количество параметров, по которым мы будем оценивать "расстояние" между результатами на основном и форвард-периоде. Например, потренируемся сначала на вычислении расстояния для трёх параметров: custom_ontester, equity_dd_relative, profit_factor.
Нам необходимо превратить столбцы со значениями этих параметров в столбцы со значениями, находящимися в диапазоне от 0 до 1. Воспользуемся оконными функциями для получения значений минимальных и максимальных значений по столбцам внутри запроса. Для имён столбцов с масштабированными значениями добавим префикс "s_" к имени исходных столбцов. На основе результатов, возвращаемых этим запросом, мы создадим и заполним новую таблицу используя команду
CREATE TABLE ... AS SELECT ... ;
И посмотрим на содержимое созданной и заполненной новой таблицы:
-- Запрос 3
DROP TABLE IF EXISTS t0;
CREATE TABLE t0 AS
SELECT id_pass,
pass,
is_forward,
custom_ontester,
(custom_ontester - MIN(custom_ontester) OVER () ) / (MAX(custom_ontester) OVER () - MIN(custom_ontester) OVER () ) AS s_custom_ontester,
equity_dd_relative,
(equity_dd_relative - MIN(equity_dd_relative) OVER () ) / (MAX(equity_dd_relative) OVER () - MIN(equity_dd_relative) OVER () ) AS s_equity_dd_relative,
profit_factor,
(profit_factor - MIN(profit_factor) OVER () ) / (MAX(profit_factor) OVER () - MIN(profit_factor) OVER () ) AS s_profit_factor
FROM passes
WHERE id_task=10;
SELECT * FROM t0; 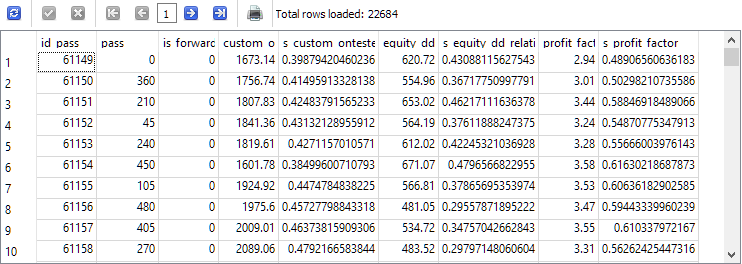
Как видно, рядом с каждым оцениваемым параметром появился новый столбец со значением этого параметра, приведённого к диапазону от 0 до 1.
Реформируем теперь немного текст второго запроса, чтобы он брал данные из новой таблицы t0 вместо passes и помещал результаты в новую таблицу t1. Будем брать уже масштабированные значения и округлять их для удобства. Ещё оставим только те строки, где значения нормированной прибыли на основном и форвард-периоде положительны:
-- Запрос 4 DROP TABLE IF EXISTS t1; CREATE TABLE t1 AS SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, ROUND(p0.s_custom_ontester, 4) AS I_custom_ontester, ROUND(p0.s_equity_dd_relative, 4) AS I_equity_dd_relative, ROUND(p0.s_profit_factor, 4) AS I_profit_factor, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, ROUND(p1.s_custom_ontester, 4) AS O_custom_ontester, ROUND(p1.s_equity_dd_relative, 4) AS O_equity_dd_relative, ROUND(p1.s_profit_factor, 4) AS O_profit_factor FROM t0 p0 JOIN t0 p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 AND p0.custom_ontester > 0 AND p1.custom_ontester > 0; SELECT * FROM t1;
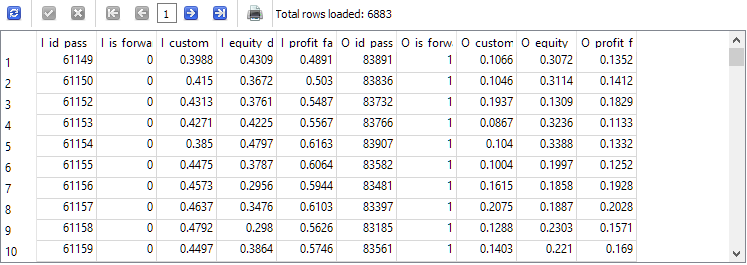
Количество строк сократилось примерно на треть по сравнению со вторым запросом, но теперь у нас остались только такие проходы, в которых и на основном, и на форвард-периоде достигалась прибыль.
Наконец-то мы подошли к последнему шагу в процессе разработки запроса. Осталось только вычислить расстояние между комбинациями параметров для основного и форвард-периода в каждой строке таблицы t1 и отсортировать их по возрастанию расстояния:
-- Запрос 5 SELECT ROUND(POW((I_custom_ontester - O_custom_ontester), 2) + POW( (I_equity_dd_relative - O_equity_dd_relative), 2) + POW( (I_profit_factor - O_profit_factor), 2), 4) AS dist, * FROM t1 ORDER BY dist ASC;
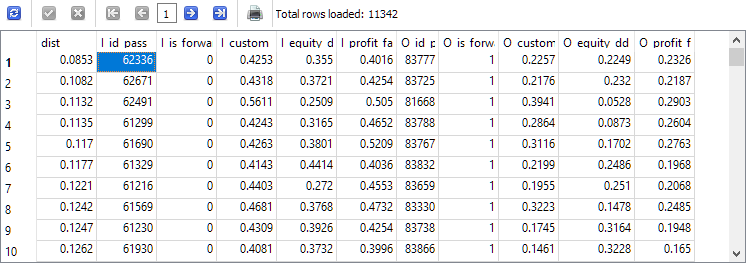
Идентификатор прохода I_id_pass из верхней строки полученных результатов будет соответствовать проходу с наименьшим расстоянием между значениями результатов на основном и форвард-периоде.
Возьмём его и идентификатор лучшего прохода по нормированной прибыли на основном периоде. Они не совпадают, поэтому сделаем из них библиотеку параметров для итогового советника, как это было описано в прошлой статье. Нам пришлось внести небольшие правки в файлы, добавленные в прошлой статье, чтобы обеспечить возможность указания конкретной базы данных при создании и экспорте библиотеки наборов параметров.
Результаты
Итак, у нас есть в библиотеке два варианта настроек. Первый вариант назван "Best for dist(IS, OS) (2018-2023)" — это лучший проход оптимизации с наименьшим расстоянием между значениями параметров. Второй вариант назван "Best on IS (2018-2022)" — это лучший проход оптимизации по нормированной прибыли на основном периоде с 2018 по 2022 годы.
Рис. 8. Выбор группы настроек из библиотеки в итоговом советнике
Посмотрим на результаты этих двух групп на периоде 2018-2023 годов, который полностью участвовал в оптимизации.
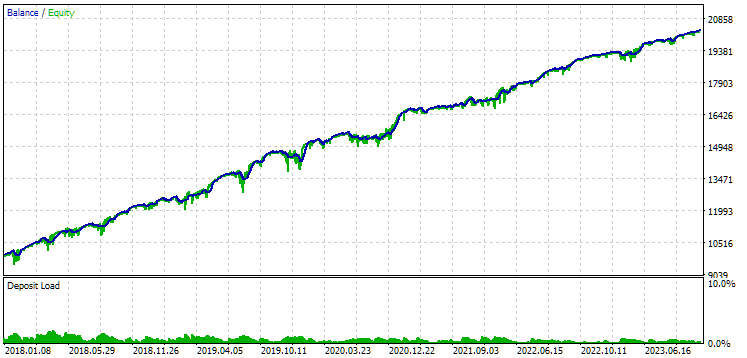
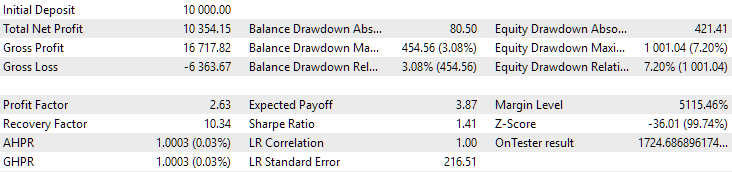
Рис. 9. Результаты первой группы (лучшая по расстоянию) на периоде 2018-2023
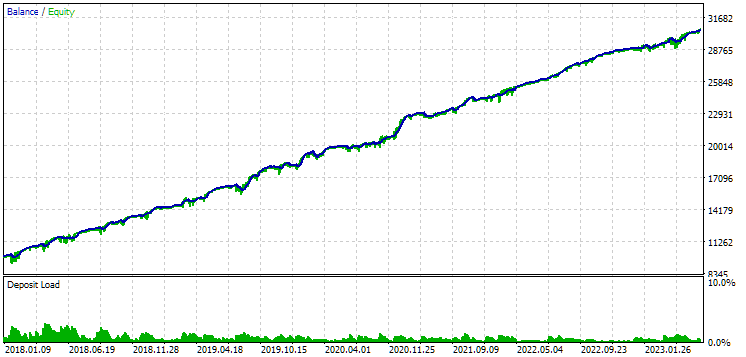
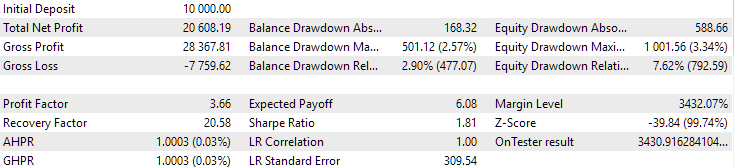
Рис. 10. Результаты второй группы (лучшая по прибыли) на периоде 2018-2023
Видим, что обе группы хорошо нормированы на данном периоде времени (максимальная просадка составляет $1000 в обоих случаях). Однако у первой среднегодовая прибыль примерно в два раза меньше, чем у второй ($1724 против $3430). Здесь преимуществ первой группы пока не видно.
Посмотрим теперь на результаты этих двух групп на 2024 году (до октября), который не участвовал в оптимизации.
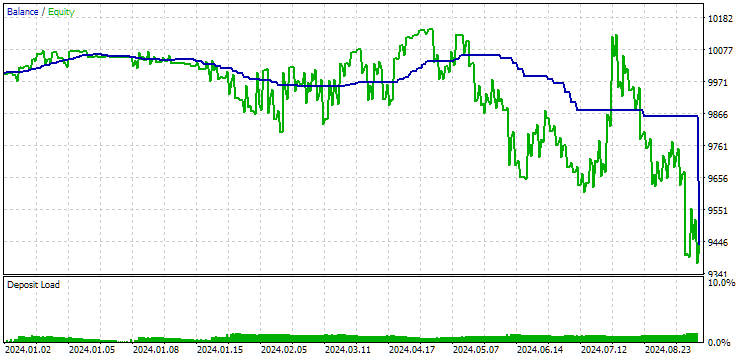
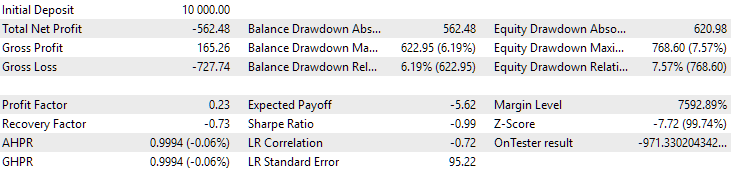
Рис. 11. Результаты первой группы (лучшая по расстоянию) на периоде 2024 года
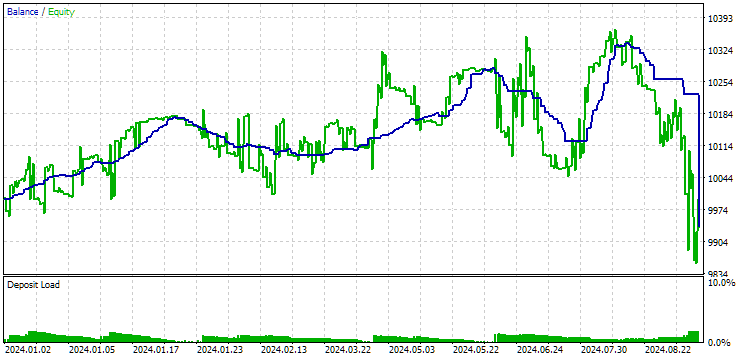
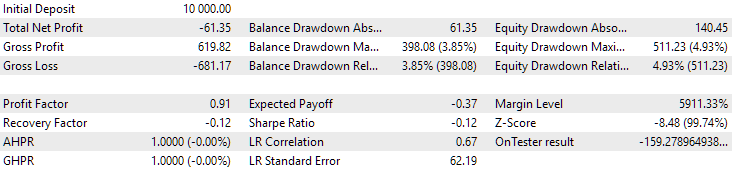
Рис. 12. Результаты второй группы (лучшая по прибыли) на периоде 2024 года
На этом периоде оба результата отрицательные, но второй по-прежнему выглядит лучше первого. Стоит отметить, что максимальная просадка на этом периоде была всегда меньше $1000.
Что ж, раз уж 2024 год выдался для этого символа не особо успешным, то давайте посмотрим какие результаты будут на периоде, расположенном не после, а до периода оптимизации. Возьмем его более длинным, раз у нас есть такая возможность (три года с 2015 по 2017).
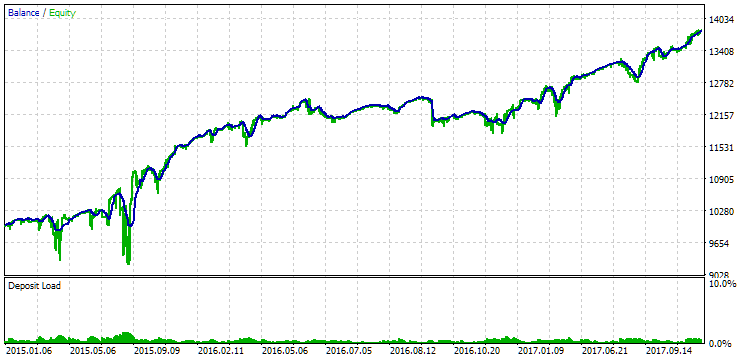
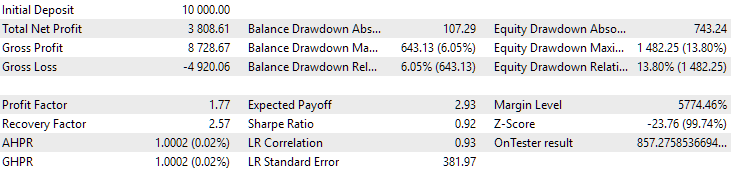
Рис. 13. Результаты первой группы (лучшая по расстоянию) на периоде 2015-2017 годов
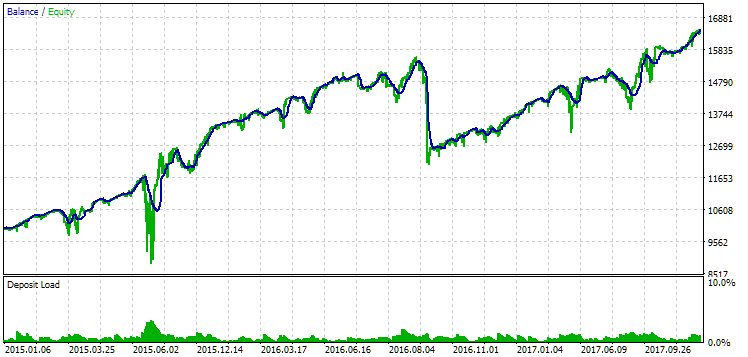
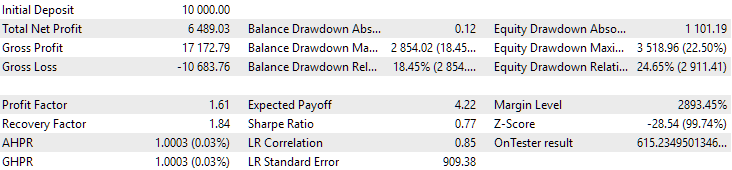
Рис. 14. Результаты второй группы (лучшая по прибыли) на периоде 2015-2017 годов
На этом периоде просадка уже превысила допустимую расчётную. В первом варианте она была примерно в 1.5 раза больше, а во втором - примерно в 3.5 раза. В этом отношении первый вариант несколько лучше, так как превышение просадки заметно меньше, чем во втором и в целом не очень большое. Также в первом варианте нет заметного провала графика в середине, как во втором варианте. То есть первый вариант показал лучшую по сравнению со вторым вариантом приспосабливаемость к неизвестному периоду истории. Однако по показателю нормированной среднегодовой прибыли разница между этими двумя вариантами не такая уж большая ($857 против $615). Но эту величину для неизвестного периода мы заранее посчитать, к сожалению, не можем.
Поэтому на этом периоде предпочтение будет всё-таки на стороне перового варианта. Давайте подведём итоги.
Заключение
Итак, мы реализовали автоматизацию второго этапа оптимизации с использованием форвард-периода. В этот раз тоже явных преимуществ не выявлено. Задача оказалась сильно шире и потребовала больших временных затрат, чем мы изначально рассчитывали. В процессе работы возникло много новых вопросов, которые ещё ждут своей очереди.
Мы смогли увидеть, что если форвард-период удачно попадает на неудачный период работы советника, то мы, похоже, не сможем с его помощью выбрать хорошие комбинации параметров.
Если продолжительность сделок велика, то результаты прохода с прерыванием на границе основного и форвард-периода могут заметно отличаться от результатов непрерывного прохода. Это тоже ставит под сомнение целесообразность использования форвард-периода в таком виде. Не вообще форвард-периода, а именно как способа автоматически выбрать такие параметры, которые с большей вероятностью будут показывать сравнимые результаты и в будущем.
Сейчас мы использовали один простой способ расчёта расстояния между результатами проходов. Возможно, что усложнение этого способа позволит улучшить результаты. Также мы пока не стали писать реализацию автоматического выбора лучшего прохода для включения в группу наборов для разных символов и таймфреймов. Для неё почти всё готово, достаточно будет из советника вызвать те SQL-запросы, которые мы разработали. Но так как в них, по всей видимости, ещё будут вноситься изменения, то отложим эту автоматизацию на будущее.
Спасибо за внимание, до встречи!
Важное предупреждение
Все результаты, изложенные в этой статье и всех предшествующих статьях цикла, основываются только на данных тестирования на истории и не являются гарантией получения хоть какой-то прибыли в будущем. Работа в рамках данного проекта носит исследовательский характер. Все опубликованные результаты могут быть использованы всеми желающими на свой страх и риск.
Содержание архива
| # | Имя | Версия | Описание | Последние изменения |
|---|---|---|---|---|
| MQL5/Experts/Article.15683 | ||||
| 1 | Advisor.mqh | 1.04 | Базовый класс эксперта | Часть 10 |
| 2 | Database.mqh | 1.05 | Класс для работы с базой данных | Часть 18 |
| 3 | database.sqlite.schema.sql | — | Схема базы данных | Часть 18 |
| 4 | ExpertHistory.mqh | 1.00 | Класс для экспорта истории сделок в файл | Часть 16 |
| 5 | ExportedGroupsLibrary.mqh | — | Генерируемый файл с перечислением имён групп стратегий и массивом их строк инициализации | Часть 17 |
| 6 | Factorable.mqh | 1.01 | Базовый класс объектов, создаваемых из строки | Часть 10 |
| 7 | GroupsLibrary.mqh | 1.01 | Класс для работы с библиотекой отобранных групп стратегий | Часть 18 |
| 8 | HistoryReceiverExpert.mq5 | 1.00 | Советник воспроизведения истории сделок с риск-менеджером | Часть 16 |
| 9 | HistoryStrategy.mqh | 1.00 | Класс торговой стратегии воспроизведения истории сделок | Часть 16 |
| 10 | Interface.mqh | 1.00 | Базовый класс визуализации различных объектов | Часть 4 |
| 11 | LibraryExport.mq5 | 1.01 | Советник, сохраняющий строки инициализации выбранных проходов из библиотеки в файл ExportedGroupsLibrary.mqh | Часть 18 |
| 12 | Macros.mqh | 1.02 | Полезные макросы для операций с массивами | Часть 16 |
| 13 | Money.mqh | 1.01 | Базовый класс управления капиталом | Часть 12 |
| 14 | NewBarEvent.mqh | 1.00 | Класс определения нового бара для конкретного символа | Часть 8 |
| 15 | Optimization.mq5 | 1.02 | Советник, управляющей запуском задач оптимизации | Часть 18 |
| 16 | Receiver.mqh | 1.04 | Базовый класс перевода открытых объемов в рыночные позиции | Часть 12 |
| 17 | SimpleHistoryReceiverExpert.mq5 | 1.00 | Упрощённый советник воспроизведения истории сделок | Часть 16 |
| 18 | SimpleVolumesExpert.mq5 | 1.20 | Советник для параллельной работы нескольких групп модельных стратегий. Параметры будут браться из встроенной библиотеки групп. | Часть 17 |
| 19 | SimpleVolumesStage1.mq5 | 1.17 | Советник оптимизации одиночного экземпляра торговой стратегии (Этап 1) | Часть 18 |
| 20 | SimpleVolumesStage2.mq5 | 1.01 | Советник оптимизации группы экземпляров торговых стратегий (Этап 2) | Часть 18 |
| 21 | SimpleVolumesStage3.mq5 | 1.01 | Советник, сохраняющий сформированную нормированную группу стратегий в библиотеку групп с заданным именем. | Часть 18 |
| 22 | SimpleVolumesStrategy.mqh | 1.09 | Класс торговой стратегии с использованием тиковых объемов | Часть 15 |
| 23 | Strategy.mqh | 1.04 | Базовый класс торговой стратегии | Часть 10 |
| 24 | TesterHandler.mqh | 1.04 | Класс для обработки событий оптимизации | Часть 18 |
| 25 | VirtualAdvisor.mqh | 1.07 | Класс эксперта, работающего с виртуальными позициями (ордерами) | Часть 18 |
| 26 | VirtualChartOrder.mqh | 1.01 | Класс графической виртуальной позиции | Часть 18 |
| 27 | VirtualFactory.mqh | 1.04 | Класс фабрики объектов | Часть 16 |
| 28 | VirtualHistoryAdvisor.mqh | 1.00 | Класс эксперта воспроизведения истории сделок | Часть 16 |
| 29 | VirtualInterface.mqh | 1.00 | Класс графического интерфейса советника | Часть 4 |
| 30 | VirtualOrder.mqh | 1.04 | Класс виртуальных ордеров и позиций | Часть 8 |
| 31 | VirtualReceiver.mqh | 1.03 | Класс перевода открытых объемов в рыночные позиции (получатель) | Часть 12 |
| 32 | VirtualRiskManager.mqh | 1.02 | Класс управления риском (риск-менеждер) | Часть 15 |
| 33 | VirtualStrategy.mqh | 1.05 | Класс торговой стратегии с виртуальными позициями | Часть 15 |
| 34 | VirtualStrategyGroup.mqh | 1.00 | Класс группы торговых стратегий или групп торговых стратегий | Часть 11 |
| 35 | VirtualSymbolReceiver.mqh | 1.00 | Класс символьного получателя | Часть 3 |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
 Введение в MQL5 (Часть 7): Руководство для начинающих по созданию советников и использованию кода от ИИ в MQL5
Введение в MQL5 (Часть 7): Руководство для начинающих по созданию советников и использованию кода от ИИ в MQL5
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована новая статья Разработка мультивалютных сделок советника (часть 18): рассматриваем автоматический выбор группы для форвардов:
By Yuriy Bykov