O que alimentar a entrada da rede neural? Suas ideias... - página 30
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Uma rede normal classificará os dados necessários e desnecessários por si só.
O principal é o que ensinar!
Aprender com um professor não é uma boa opção aqui. As redes com propagação de erros para trás são simplesmente inúteis.
Existe uma compreensão de como o mecanismo deve ser treinado? Basicamente, analisamos os pesos, ajustando-os a um gráfico, mas, ao mesmo tempo, há outro conjunto de pesos, um conjunto que não é ajustado apenas a esse gráfico, mas "ajustado" ao próximo, e ao próximo, e ao próximo, e assim por diante.
Aqui, o aprendizado é apresentado como a descoberta da diferença entre um conjunto de conjuntos que não funcionam e aqueles que funcionam.
E, além disso, a rede treinada não precisa de mais nenhum "ajuste fino", ela já edita os números de pesos por si só. Que outras ideias existem sobre como é o aprendizado de máquina e como ele é apresentado?
Uma rede normal classificará os dados necessários e desnecessários por si só.
O principal é o que ensinar!
Aprender com um professor não é uma boa opção aqui. As redes com propagação de erros para trás são simplesmente inúteis.
A rede não classificará nada - a rede selecionará as variáveis que melhor se ajustam à amostra de treinamento.
Um grande número de variáveis é um grande mal
A rede não classificará nada - a rede selecionará as variáveis que melhor se ajustam à amostra de treinamento.
Umgrande número de variáveis é o principal problema
Para memorizar o caminho - o melhor Para aprender (no entendimento atual) - o mais ruim.
treinar duas grades - uma somente para compra e outra para venda.
ligue as duas :-)
em seguida, adicione uma rede de resolução de colisões (ou apenas alg.) para que elas não negociem em direções diferentes ao mesmo tempo.
Estive pensando, você poderia criar um script da marcação. Anote todas as datas em que ocorre a entrada e o fechamento. Se o otimizador definir pesos que emitam um sinal fora dessas datas, abriremos com o lote máximo a perder. Ou não abrimos de jeito nenhum.
Acontece que esse será um método com um professor, mas por forças do MT5
A rede neural pode funcionar mesmo com um valor de uma característica, se você selecionar os parâmetros
mas precisamos de condições essenciais (dts) com quase nenhuma propagação. Acredito que qualquer TS funcionará em tais condições :)
Existe alguma maneira de descrever a exigência de que a máquina abra uma posição quando achar necessário? Como explicaríamos isso: fazemos com que a própria rede neural abra posições... "se, então". Especificamos quando abrir "Se a saída da rede neural for maior que 0,6", "se dos dois neurônios de saída, o de cima tiver o valor mais alto".
"Se - então, se - então." E assim por diante. E aqui, para que não haja limites de abertura, condições. Há entradas, há pesos. Dentro da rede neural, há algum tipo de mistura se formando.
É possível descrever de alguma forma para a máquina, com base em seu trabalho com entradas e pesos (a serem pesquisados no otimizador), a abertura de posições quando ela decidir fazê-lo? Como essa condição pode ser prescrita? Para que ela escolha quando abrir posições.
UPD Adicionar uma segunda rede neural.
Então, como vinculá-la... Ou várias redes neurais.
Ou existe alguma outra maneira de descrever essa tarefa?
UPD Adicionar um bloco de experiência.
Então, acaba sendo um tipo de tabela q. E precisamos que tudo esteja dentro da rede neural.
... Como faço para definir essa condição? Para que ele escolha quando abrir....
Posso ajudá-lo aqui: dê sinais de compra e venda ao mesmo tempo, e o neurônio decidirá para onde ir. Não me agradeça...
Pela primeira vez, consegui obter um conjunto no topo por um funcionário. Além disso, um trabalhador por até 3 anos à frente.
Treinamento por 9 anos, de 2012 a 2021
Adiantamento 2021
Para frente 2022
Avanço 2023
Todos os 3 anos de avanço 2021-2023.12.13.
É verdade que tivemos de usar todo o potencial do MT5: o número máximo de pesos de parâmetros otimizáveis.
Se fosse possível otimizar mais parâmetros, seria mais interessante conhecer os resultados. Estou perplexo com essa inscrição "64 bits to long" ou algo do gênero. Se o algoritmo genético permitir otimizar ainda mais, seria interessante saber como contornar essa limitação
se mais parâmetros pudessem ser otimizados
Como o MT5 é limitado no número de parâmetros otimizáveis, mudei para o NeuroPro 1999, com base no artigo aqui - Neural Networks for Free and Easy - Connecting NeuroPro and MetaTrader 5.
Aumentei a arquitetura em quantidade: no MT5 era 5-5-5-5, e aqui é 10-10-10, e o treinamento já é real (para ser mais preciso - padrão, pelo método de retropropagação de erros e outros recursos internos do programa.


O autor do programa cuspiu nele e nem sequer vai atualizar a raridade - com base em suas respostas às minhas perguntas, ele não tem interesse em desenvolver o NeoroPro, introduzir multithreading, métodos modernos etc.). Surpreendentemente, o programa pode produzir resultados semelhantes aos do MT5. Mas é fácil interromper o avanço - adicione outro neurônio/adicione outra camada/reduza o tamanho dos dados em um mês e tudo se tornará aleatório.
Ou seja, precisamos encontrar uma média de ouro entre o treinamento excessivo e o treinamento insuficiente. Além disso, após o treinamento, o modelo ainda não funciona. Precisamos de pós-otimização dos parâmetros do MT5 - limites de abertura para COMPRA e VENDA. Algo semelhante foi feito pela NeuroMachine, dos criadores do MeGatrader, em sua época.
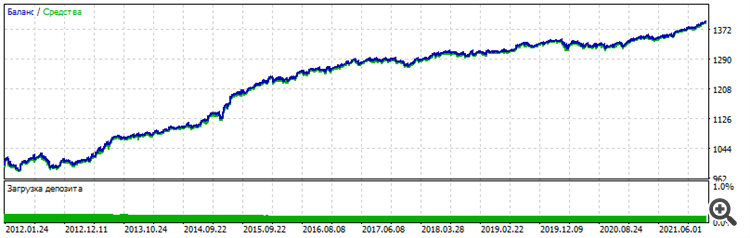
Ou seja, algum tipo de pós-processamento. Sem isso, o gráfico de equilíbrio mal se move para cima no período ensinado e se esvai no período avançado. As condições mudaram: 6 entradas já, EURUSD H1, a preços de abertura, 10 anos de ensino de 2012 a 2022.
Adiantamento - últimos dois anos 2022-2023-12-16
Gráfico geral - você pode ver que a estabilidade é semelhante, o caráter é idêntico, não parece sorte
Vou tentar outros pares e aumentar a arquitetura para excluir completamente o fator sorte e confirmar o desempenho do método. Bem, e o mais importante - pós-otimização - o conjunto de trabalho estava no topo da classificação pelo parâmetro "Recovery factor". Se isso não acontecer em uma data posterior, não haverá confirmação. Novamente, ficarei preso ao acaso, à sorte, à sorte.
O método de cutucada criativa me levou a uma ideia: uma camada de neurônios no sentido clássico é um amontoado de mal-estar.
Especialmente a primeira camada, que recebe dados de entrada.
A camada mais importante. A entrada é de dados heterogêneos. Ou homogêneos - não importa. Cada dígito, cada número é uma representação de forma, conteúdo, dependência - no original.
É como uma fonte, como um filme, como uma fotografia. E imagine que uma rede neural comum pega cada número, cada atributo - e estupidamente os soma, multiplicados adicionalmente pelo peso, em uma pilha de lixo, chamada de somador. É como borrar uma foto e tentar restaurar a imagem - nada funcionará. É isso mesmo. A fonte está perdida, apagada. Ela se foi. Toda restauração é reduzida a uma coisa: desenho adicional. É assim que as redes neurais modernas funcionam para restaurar fotos antigas, ou para melhorá-las, aprimorá-las - elas simplesmente as desenham. Apenas o trabalho criativo da rede neural não tem fonte, ela extrai o que já teve em seu banco de dados de imagens, algo semelhante, mesmo que em 99%, mas não a fonte.
Assim, alimentamos preços, incrementos de preços, preços transformados, dados de indicadores, números nos quais alguma figura, algum estado no gráfico está codificado - e ele pega e estupidamente apaga a singularidade de cada número, jogando todos os números em um único poço e tirando uma conclusão (saída) com base nesse enorme lixo, no qual é impossível distinguir o que é o quê. Esse número de somador de agora em diante será idêntico a figuras diferentes, com números diferentes. Ou seja, temos duas figuras - elas são exibidas em uma sequência diferente de números. O conteúdo dessas figuras é diferente, mas o volume pode ser o mesmo. O volume é numérico. E então, no somador, esse heap-mala pode significar tanto uma figura quanto outra. Nunca saberemos qual é exatamente - nesse estágio, apagamos a informação única.
Nós a espalhamos, jogamos em uma panela e agora é uma sopa. E se a entrada for um lixo? Então, com 1000% de probabilidade, o primeiro somador transformará esse lixo em lixo ao quadrado. E, com 1000% de probabilidade, essa rede neural jamais selecionará algo desse lixo, jamais o encontrará, jamais o extrairá. Porque, nesse caso, ela não apenas escava o lixo, mas também o quebra em um moedor de carne chamado "próximas camadas".
Minha abordagem de leigo me diz que precisamos mudar a maneira como abordamos as arquiteturas e a maneira como tratamos as entradas. Como prova, meus gráficos acima. Uma entrada, duas entradas, três entradas - um neurônio, dois neurônios, três neurônios.
É isso, o próximo passo é o retreinamento - memorizar o caminho em vez de trabalhar com novos dados. A segunda confirmação é o próprio retreinamento. Quanto mais neurônios, mais camadas, pior para os novos dados. Ou seja, com cada nova camada, com cada novo neurônio, transformamos os dados originais em lixo ao quadrado, e tudo o que resta à rede neural é simplesmente memorizar o caminho.
O que ela faz perfeitamente bem durante o retreinamento. Um pequeno voo de fantasia.