O que alimentar a entrada da rede neural? Suas ideias... - página 37
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Acho que esse é o resultado sem filtros, por exemplo, por tempo?
É claro que não testei com filtros, mas a questão é que as negociações são de médio prazo ou intraday.
A influência do filtro de tempo não parece ser forte, mas, de qualquer forma, é possível, é claro.
Mas a questão é que as negociações são de médio prazo ou intraday.
A influência do filtro de tempo não parece ser forte. Mas, de qualquer forma, você pode, é claro.
Um fenômeno interessante:
Se você usar a mesma arquitetura (qualquer arquitetura), então, no EURUSD, ao usar o Softmax, a otimização sempre fornece conjuntos superiores em que a COMPRA não é usada de forma alguma. Tudo fica apenas com SELL e HOLD.
Observo o gráfico de 12 anos - ele é descendente. Ou seja, o otimizador MT5 ajusta os pesos no nível macro para se adequar ao longo prazo.
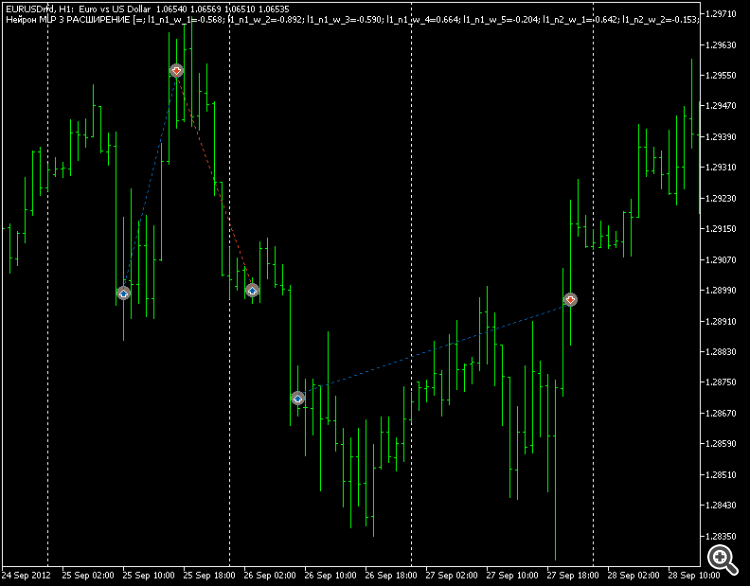
Como resultado, as áreas de tendência ascendente BUY-eval permanecem "não negociadas" adequadamente, mas se você usar uma tangente regular como saída, não haverá problemas.
Os conjuntos superiores negociam tanto na compra quanto na venda. Portanto, abandonei esse softmax e agora estou me aprofundando em arquiteturas e entradas somente com a tangente. UPD Outra coisa - negociações para cima e para baixo.
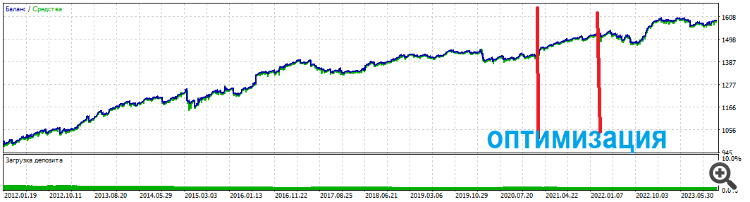
E os conjuntos superiores se mantêm por um longo tempo
Fenômeno interessante:
...
E os conjuntos superiores duram muito tempo
Arquitetura MLP? Presumo que os pesos sejam otimizados pelo otimizador interno? Qual é o critério de otimização, se não for secreto? E se for a mesma malha, mas com algum algoritmo de backprope, todas as outras coisas sendo iguais?
Arquitetura MLP? Pelo que entendi, os pesos são otimizados pelo otimizador interno? Qual é o critério de otimização, se não for secreto? E se a mesma grade, mas com algum algoritmo de backprope, for usada com todas as outras coisas sendo iguais?
E os conjuntos superiores duram muito tempo
E se, além disso, você treinar o segundo modelo novamente?
E se você treinar demais o segundo modelo novamente?
Por favor, esclareça no contexto de um otimizador MT5 comum e de um EA comum. Como seria isso: pegar dois conjuntos da lista de otimização (não correlacionados), combiná-los e executá-los? Ou há algo mais em mente?
Muitas palavras inteligentes
Os especialistas do ramo de MO afirmam que: 1. Não é possível procurar um extremo global em uma função de aptidão.
2. os algoritmos de otimização de busca global (o GA padrão é um deles) não são adequados para redes neurais; você deve usar todos os tipos de retropropagação de gradiente para essa finalidade.
Em resumo, pelo que parece, você está fazendo tudo errado (de acordo com as ideias dos especialistas do ramo de MO).
Os especialistas do ramo de MO argumentam que: 1. Não é possível procurar um extremo global na função de aptidão.
2. os algoritmos de otimização de busca global (inclusive o GA padrão) não são adequados para redes neurais; para isso, deve-se usar todos os tipos de retropropagação de gradiente.
Em resumo, pelo que parece, você está fazendo tudo errado (de acordo com as ideias dos especialistas do ramo de MO).
Portanto, vencerei essa batalha
Então, vencerei essa batalha