O que alimentar a entrada da rede neural? Suas ideias... - página 31
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Como confirmação, meus gráficos acima. Uma entrada, duas entradas, três entradas - um neurônio, dois neurônios, três neurônios. É isso, o próximo passo é o retreinamento - memorizar o caminho, não trabalhar com novos dados.
Da mesma forma, com modelos de madeira. Com 3 a 5 (talvez até 10, mas é mais provável que sejam até 5) entradas/características, o modelo ainda pode mostrar lucro no avanço; se for mais, já é aleatório ou ameixa.
Essas 3 a 5 melhores fichas foram obtidas por meio de uma pesquisa completa de pares, trios etc., treinando modelos sobre elas e selecionando as melhores no forward de avaliação.
I van Butko #:
E imagine que uma rede neural comum pega cada número, cada recurso - e estupidamente o soma, multiplicado adicionalmente pelo peso, em uma pilha de lixo, chamada de somador.
As árvores também usam a média das folhas; se for uma floresta, ela faz a média com outras árvores; se for um arbusto, ela resume com as árvores de refinamento. Ou seja, a situação é a mesma com as redes neurais e com os modelos de árvores. Tudo é uma média. Quando há muito ruído, é possível treinar normalmente apenas com 3 a 5 chips.
A média com ruído é o retreinamento com ruído. P.S. Em vez do NeuroPro de mais de 20 anos, você pode usar algo mais novo. R, Python ou, se for difícil lidar com eles, use o EXE do Catbusta, como aquihttps://www.mql5.com/ru/articles/8657. Você pode executar automaticamente o EXE diretamente do EA, ou seja, automatizar totalmente o processo.
Exemplo https://www.mql5.com/ru/forum/86386/page3282#comment_49771059 P.P.S. É melhor dormir à noite. Não é possível comprar sua saúde, mesmo que você ganhe milhões nessas redes.
Da mesma forma, com modelos de madeira. Com 3 a 5 (talvez até 10, mas mais provavelmente até 5) entradas/características, o modelo ainda pode mostrar lucro no forward; se mais, então já é aleatório ou ameixa.
Essas 3 a 5 melhores fichas foram obtidas por meio de uma pesquisa completa de pares, trios etc., treinando modelos com elas e selecionando as melhores no jacking forward.
As árvores também usam o valor médio das folhas; se for uma floresta, ela faz a média com outras árvores; se for um arbusto, ela faz a soma com as árvores de refinamento. Ou seja, a situação é a mesma com as redes neurais e com os modelos de árvores. Todas as médias. Quando há muito ruído, é possível treinar normalmente apenas com 3 a 5 chips.
A média com ruído é o retreinamento com ruído. P.S. Em vez do NeuroPro de mais de 20 anos, você pode usar algo mais novo. R, Python ou, se for difícil lidar com eles, use o EXE do Catbusta, como aquihttps://www.mql5.com/ru/articles/8657. Você pode executar automaticamente o EXE diretamente do EA, ou seja, automatizar totalmente o processo.
Exemplo https://www.mql5.com/ru/forum/86386/page3282#comment_49771059 P.P.S. É melhor dormir à noite. Não é possível comprar sua saúde, mesmo que você ganhe milhões nessas redes.
Obrigado pela postagem
Não vejo o graal na soma, mas na divisão do número
UPD
E a tarefa dos neurônios não é obter um conjunto de números, mas obter um número como entrada. Multiplique-o por um peso e alimente-o por meio de uma função não linear.
Ou seja, há um número (valor de entrada ou saída do neurônio), e esse número é dividido por dois ou mais neurônios da próxima camada.
Eles devem ser independentes dos outros neurônios. Esse é um departamento que faz suas próprias coisas. Então, todos esses departamentos devem se reportar a um chefe - o neurônio de saída. Ele faz uma inferência com base nas saídas de todos os neurônios finais. Com seus próprios pesos.
Dessa forma, reduzimos a distorção das informações e aumentamos sua leitura.
O objetivo que vejo não é a soma, mas a divisão de números
Bem, as folhas são obtidas pela divisão dos dados, mesmo em 1000000 partes/folhas diferentes.
Mas o resultado/resposta de uma folha é a média dos exemplos/linhas incluídos nela. Portanto, a divisão existe, mas a soma também. Você pode dividir para 1 exemplo em uma folha, mas isso é 100% de treinamento excessivo com ruído. As árvores, também sob ruído, não devem se dividir profundamente, para um bom avanço (é assim que o número de neurônios é melhor - pequeno).
Tropecei em algo como spread e comissão.
Eles quebram a rede neural rapidamente. Obrigado MT5, você sabe como ficar sóbrio. Eu deveria ter trocado o MT4 por você há muito tempo
@ Andrey Dik estava certo há muitos anos - o graal ainda está em torno do spread e da comissão. Assim que você os remove, a rede neural continua em frente.
Bem, as folhas são obtidas dividindo os dados em 1000000 partes/folhas diferentes.
Mas o resultado/resposta de uma folha é a média dos exemplos/linhas incluídos nela. Portanto, há divisão, mas também há sumarização. Você pode dividir para 1 exemplo em uma folha, mas isso é 100% de treinamento excessivo com ruído. As árvores, também sob ruído, não devem se dividir profundamente, para um bom avanço (é assim que o número de neurônios é melhor - pequeno).
Cara, que tópico vasto. Agora vou pesquisar folhas no Google. Em cerca de 5 anos, chegarei ao ramo MO, mas não o relerei
Mudei da Toyota para um carro esportivo antigo Como o MT5 é limitado no número de parâmetros otimizáveis, mudei para o NeuroPro 1999, do artigo aqui -Neural Networks for free and easy - connecting NeuroPro and MetaTrader 5.
Aumentei a arquitetura em quantidade: no MT5 era 5-5-5-5, e aqui é 10-10-10, e o treinamento já é real (para ser mais preciso - padrão, pelo método de retropropagação de erros e outros recursos internos do programa. Seu autor não se importa com isso e nem mesmo atualizará a raridade - com base em suas respostas às minhas perguntas, ele não tem interesse em desenvolver o NeoroPro, introduzindo multithreading, métodos modernos, etc.
Tropecei em algo como spread e comissão.
Eles quebram a rede neural rapidamente. Obrigado MT5, você sabe como ficar sóbrio. Eu deveria ter trocado o MT4 por vocês há muito tempo
@ Andrey Dik estava certo há muitos anos: o graal ainda está em torno do spread e da comissão. Assim que você os remove, a rede neural segue em frente.
Fenômeno curioso: o treinamento na arquitetura de "extensão", quando a primeira camada consiste em 1 neurônio, depois a segunda camada de 2, a terceira camada de 3, etc., deu um conjunto engraçado e curioso: os resultados do conjunto no período de otimização do EURUSD são exatamente os mesmos em outros pares de dólares: Otimização para 2021 no EURUSD
Teste no GBPUSD para 2021
Teste no AUDUSD para 2021
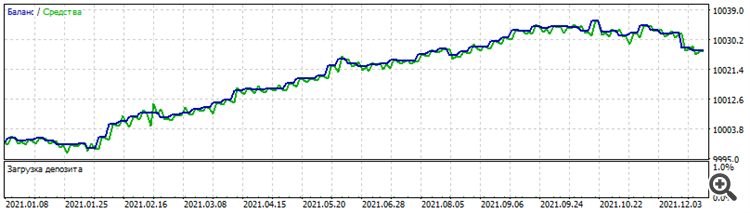

Teste no NZDUSD para 2021
Por que somente os curiosos? Porque é um dead set, não funciona nem antes nem depois. Mas o próprio fato de funcionar em vários pares de dólares no mesmo período, já que , embora haja alguma correlação entre eles, o preço de cada par ainda édiferente.
Fenômeno curioso: o treinamento na arquitetura de "extensão", quando a primeira camada consiste em 1 neurônio, depois a segunda camada de 2, a terceira camada de 3, etc., deu um conjunto engraçado e curioso: os resultados do conjunto no período de otimização do EURUSD são exatamente os mesmos em outros pares de dólares: Otimização para 2021 no EURUSD
Teste em GBPUSD para 2021
Teste no AUDUSD para 2021 Teste no NZDUSD para 2021 Por que só os curiosos? Sim, porque é um dead set, não funciona nem antes nem depois. Mas o próprio fato de funcionar em vários pares de dólares no mesmo período, já que , embora haja alguma correlação entre eles, o preço de cada par ainda édiferente.
Não, é diferente.
Em todos eles, com exceção do euro, um terço do saldo no final está no mesmo lugar.