市場現象 - ページ 33 1...262728293031323334353637383940...75 新しいコメント Vladimir Paukas 2011.07.20 13:39 #321 joo: 間違っているわけではありません。そう、「安く買って高く売る」という表現と同じくらいに正しい。重要なのは正しさだけでなく、形式化可能性です。市場原理に近い巧妙な哲学的構築物を作っても、それ(構築物)がヤギの乳のようなものであれば意味がない。 損失を出した後のタイムラグを公式化するのは難しいと思いますか?それとも他の何か? khorosh 2011.07.20 13:54 #322 paukas: 損失を受け入れた後の時間経過は、形式化しにくいと思いますか?あるいは、何が違うのでしょうか? はい、もちろん問題なくできます。また、ボラティリティが低い時の取引を禁止することもできます。 Alexey Burnakov 2011.07.21 06:05 #323 gpwr: ありがとうございます。SOMについては、これからゆっくり考えていきたいと思います。 リンク先の記事では、時系列の セグメンテーション手法の概要が紹介されています。どれもだいたい同じようなことをやっています。SOMがFXに最適な手法というわけではありませんが、最悪でもない、それが事実です )) http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.115.6594&rep=rep1&type=pdf Сергей 2011.10.21 09:07 #324 私の同僚は、残念ながら、私は取引に多くの時間を与えることはできませんが、私はいくつかの時間を見つけ、尋ねることにしました(私自身の利益のために、私はそれを忘れないように :o, ので、私はより自由な時間があるとき、後で戻ってくるでしょう)。 現象の本質を この現象の本質を思い起こさせてください。これは、「ロングテール」が将来の価格乖離に与える影響を分析した結果、発見されたものです。ロングテールを分類し、ロングテールのない時系列を 見ると、ほとんどすべてのシンボルに固有の不思議な現象が観察される。この現象の本質は、ある意味「ニューラル」的なアプローチに基づく、非常に特殊な分類である。実はこの分類は、生データ、つまり見積もりプロセスそのものを「分解」して、従来は「アルファ」「ベタ」と呼ばれていた2つのサブプロセスに分類するものです。一般に、最初のプロセスは、より多くのサブプロセスに分解することができます。 ランダムな構造を持つシステム この現象は、ランダムな構造を持つシステムにも非常によく当てはまります。モデル自体は非常にシンプルに見えるでしょう。では、その一例を見てみましょう。初期EURUSD シリーズ M15(我々は長いサンプル、および可能な限り小さなフレームが必要です)、いくつかの "今 "から。 ステップ1:分類 分類が行われ、2つの処理「α」「β」が得られる。制御プロセスのパラメータを定義する(見積書の最終的な「組み立て」を行うプロセス)。 ステップ2 識別 各サブプロセスについて、ボルテリネットワークに基づくモデルを定義しています。 ああ、識別するのが面倒だなあ。 ステップ3 サブプロセス予測 各処理について100カウント(15分、つまり1日強)の予測を行う。 ステップ4:シミュレーション・モデリング シミュレーションモデルを構築し、将来の実装のx.o.数を生成します。その仕組みはシンプルです。 3つのランダム化:各モデルの誤差とプロセス遷移条件。以下は、リアライゼーションそのものです(ゼロから)。 ステップ5:トレーディングソリューション これらのリアライゼーションのバイアス解析を行う。これはさまざまな方法で行うことができます。目視では、大量の軌道がずれていることがわかります。事実を見よう。 <> 予備テスト ランダムに約70回「測定」(数えるのに時間がかかる)。システムが検出した偏差の70%くらいは正しいので、まだ何も言ってきませんが、2ヶ月後にはこのトラックに戻したいと思っています、まだメインプロジェクトの作業は終わっていませんが :o( Илья 2011.10.21 14:59 #325 多分、全く正しくない:どのような原理で分類し、実際にどのようなプロセスに分解することを意図しているのでしょうか? Сергей 2011.10.24 06:07 #326 富士山に登る Может не совсем корректно: по какому принципу производится классификация и, собственно, разложение на какие процессы предполагается? いいえ、すべて正しいです。このスレッドの数十ページにわたる議論の主題の一つであった。しかし、残念ながら、この話題をさらに発展させる時間はない。それに、特にこの現象は、面白いけれども、あまり期待できない。ロングテール」という現象は、長いホライズン、つまり軌道の乖離が大きいところに現れるが、そのためには、α過程とβ過程(およびその他の過程)を遠くまで予測することが必要である。そして、これは不可能なことなのです。 そんな技術はない...。 :о( すべて 仲間たちよ、私が答えていない投稿があることが判明したのだ。許してくれ、今更動いても仕方がない。 Artemka 2012.01.14 09:58 #327 Prohwessor Fransfort, どのプログラムを使って研究しているか答えてください。 また、http://originlab.com/ (OriginPro 8.5.1)のロシア語のマニュアルやルシファーがあれば、教えてください。 Sceptic Philozoff 2012.01.14 14:04 #328 Matlabは、私の記憶違いでなければ。 anonymous 2012.01.14 17:01 #329 Farnsworth:ファットテイル」の研究において、より本格的な「フラクタル」数学に到達できることを期待しています。もう少し時間がかかると思いますが、とりあえず、科学的な研究に近いものがあり、考えさせられたので掲載します。 モデルの前提条件このように、いくつかの工程を経て、コットに座っていると考えられるので、それを見つけたいのです。メインとなる「運ぶプロセス」は、ある種の増加/減少トレンドであり、それがある種の確率的アルゴリズムによって別のプロセス(またはプロセス)に割り込むと考えられている。アイデアは簡単で、理論的には「ファットテール」(または他のサブプロセス)に属する増分を削除して、何が起こるかを見ることです。まず、最も簡単な分類方法は、±LAMBDAの内側にあるものをすべて「フィルタリング」することです。Open(n)-Open(n-1)刻みで、M15、EURUSD。0.0001から0.025刻みでLAMBDAを調べ、特定の±LAMBDAチャンネルに該当するものだけを残して合計し、各LAMBDAの線形回帰決定係数を決定するのです。そう、抜けがあるのは明らかなのですが(私はそれをゼロと数えます)、今はただ、プロセスそのものに目を向けたいだけなのです。決定係数(CD)/LAMBDACoDとは、簡単に言うと、データがどれだけモデルを説明しているかを示す一定の割合のことであることを思い出してほしい。LAMBDA = 0.0006のとき、最大値(0.97)に達する。フィルタリングされた増分を足すと2つの処理ができる。0.0006という値は、インクリメンタルプロセスのRMSよりもわずかに小さい。比較のために、LAMBDA値が0.0023(約3RMS)の2番目の局所極値を見ることができます。このような「傾向」は、すべての商材で確認することができ、あるものは(そしてそのほとんどは)上昇し、あるものは下降している。この方法が科学的でないことは明らかだが、一方で、ランダムな構造を持つシステムの代替表現として、いくつかのアイデアを与えてくれた。 興味深い結果です。 この現象は、ヒストリカルデータがBid価格であることに起因しているのでしょうか?(実験でのラムダはスプレッドと同程度)。 時間の関数として見た場合、断片的な定数係数を持つ線形回帰を用いて、結果として得られる「トレンド」プロセスの質を検証する方が理にかなっているとは思いませんか? Artemka 2012.01.15 10:57 #330 プロフ、22ページの図2のチャートは、ユーロドルの月足チャートと 非常によく似ていますね。 フィルタリングの刻みを足すと、2つの処理になるんです。 1...262728293031323334353637383940...75 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
間違っているわけではありません。そう、「安く買って高く売る」という表現と同じくらいに正しい。重要なのは正しさだけでなく、形式化可能性です。市場原理に近い巧妙な哲学的構築物を作っても、それ(構築物)がヤギの乳のようなものであれば意味がない。
損失を受け入れた後の時間経過は、形式化しにくいと思いますか?あるいは、何が違うのでしょうか?
ありがとうございます。SOMについては、これからゆっくり考えていきたいと思います。
リンク先の記事では、時系列の セグメンテーション手法の概要が紹介されています。どれもだいたい同じようなことをやっています。SOMがFXに最適な手法というわけではありませんが、最悪でもない、それが事実です ))
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.115.6594&rep=rep1&type=pdf
私の同僚は、残念ながら、私は取引に多くの時間を与えることはできませんが、私はいくつかの時間を見つけ、尋ねることにしました(私自身の利益のために、私はそれを忘れないように :o, ので、私はより自由な時間があるとき、後で戻ってくるでしょう)。
現象の本質を
この現象の本質を思い起こさせてください。これは、「ロングテール」が将来の価格乖離に与える影響を分析した結果、発見されたものです。ロングテールを分類し、ロングテールのない時系列を 見ると、ほとんどすべてのシンボルに固有の不思議な現象が観察される。この現象の本質は、ある意味「ニューラル」的なアプローチに基づく、非常に特殊な分類である。実はこの分類は、生データ、つまり見積もりプロセスそのものを「分解」して、従来は「アルファ」「ベタ」と呼ばれていた2つのサブプロセスに分類するものです。一般に、最初のプロセスは、より多くのサブプロセスに分解することができます。
ランダムな構造を持つシステム
この現象は、ランダムな構造を持つシステムにも非常によく当てはまります。モデル自体は非常にシンプルに見えるでしょう。では、その一例を見てみましょう。初期EURUSD シリーズ M15(我々は長いサンプル、および可能な限り小さなフレームが必要です)、いくつかの "今 "から。
ステップ1:分類
分類が行われ、2つの処理「α」「β」が得られる。制御プロセスのパラメータを定義する(見積書の最終的な「組み立て」を行うプロセス)。
ステップ2 識別
各サブプロセスについて、ボルテリネットワークに基づくモデルを定義しています。
ああ、識別するのが面倒だなあ。
ステップ3 サブプロセス予測
各処理について100カウント(15分、つまり1日強)の予測を行う。
ステップ4:シミュレーション・モデリング
シミュレーションモデルを構築し、将来の実装のx.o.数を生成します。その仕組みはシンプルです。
3つのランダム化:各モデルの誤差とプロセス遷移条件。以下は、リアライゼーションそのものです(ゼロから)。
ステップ5:トレーディングソリューション
これらのリアライゼーションのバイアス解析を行う。これはさまざまな方法で行うことができます。目視では、大量の軌道がずれていることがわかります。事実を見よう。
<>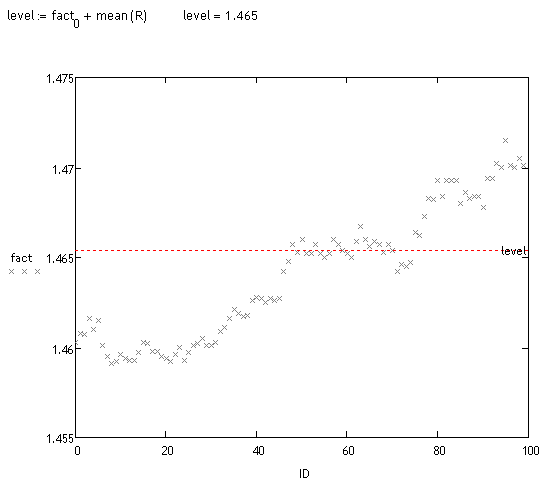
予備テスト
ランダムに約70回「測定」(数えるのに時間がかかる)。システムが検出した偏差の70%くらいは正しいので、まだ何も言ってきませんが、2ヶ月後にはこのトラックに戻したいと思っています、まだメインプロジェクトの作業は終わっていませんが :o(
富士山に登る
Может не совсем корректно: по какому принципу производится классификация и, собственно, разложение на какие процессы предполагается?
いいえ、すべて正しいです。このスレッドの数十ページにわたる議論の主題の一つであった。しかし、残念ながら、この話題をさらに発展させる時間はない。それに、特にこの現象は、面白いけれども、あまり期待できない。ロングテール」という現象は、長いホライズン、つまり軌道の乖離が大きいところに現れるが、そのためには、α過程とβ過程(およびその他の過程)を遠くまで予測することが必要である。そして、これは不可能なことなのです。 そんな技術はない...。
:о(
すべて
仲間たちよ、私が答えていない投稿があることが判明したのだ。許してくれ、今更動いても仕方がない。
Prohwessor Fransfort, どのプログラムを使って研究しているか答えてください。
また、http://originlab.com/ (OriginPro 8.5.1)のロシア語のマニュアルやルシファーがあれば、教えてください。
興味深い結果です。
この現象は、ヒストリカルデータがBid価格であることに起因しているのでしょうか?(実験でのラムダはスプレッドと同程度)。
時間の関数として見た場合、断片的な定数係数を持つ線形回帰を用いて、結果として得られる「トレンド」プロセスの質を検証する方が理にかなっているとは思いませんか?
フィルタリングの刻みを足すと、2つの処理になるんです。