取引における機械学習に関する記事
AIベースの取引ロボットの作成: ネイティブPythonとの統合、行列とベクトル、数学と統計のライブラリなど
取引に機械学習を使用する方法をご覧ください。ニューロン、パーセプトロン、畳み込みネットワークと再帰型ネットワーク、予測モデルなどの基本から始めて、独自のAIの開発に取り組みます。金融市場でのアルゴリズム取引のためにニューラル ネットワークを訓練して適用する方法を学びます。
新しい記事を追加

取引の機会を逃しています。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
モデル解釈をマスターする:機械学習モデルからより深い洞察を得る
機械学習は複雑で、経験を問わず誰にとってもやりがいのある分野です。この記事では、構築されたモデルを動かす内部メカニズムに深く潜り込み、複雑な特徴、予測、そしてインパクトのある決断の世界を探求し、複雑さを解きほぐし、モデルの解釈をしっかりと把握します。トレードオフをナビゲートし、予測を強化し、確実な意思決定をおこないながら特徴の重要性をランク付けする技術を学びます。この必読書は、機械学習モデルからより多くのパフォーマンスを引き出し、機械学習手法を採用することでより多くの価値を引き出すのに役立ちます。

MQL5入門(第1部):アルゴリズム取引入門ガイド
この初心者向けMQL5プログラミングガイドで、魅力的なアルゴリズム取引の世界へ飛び込みましょう。MetaTrader 5を動かす言語であるMQL5のエッセンスを発見し、自動売買の世界を解明します。基本を理解することからコーディングの第一歩を踏み出すことまで、この記事はプログラミングの知識がなくてもアルゴリズム取引の可能性を解き放つ鍵となります。MQL5のエキサイティングな宇宙で、一緒に、シンプルさと洗練が出会う旅に出ましょう。

母集団最適化アルゴリズム:Mind Evolutionary Computation (MEC)アルゴリズム
この記事では、Simple Mind Evolutionary Computation(Simple MEC, SMEC)アルゴリズムと呼ばれる、MECファミリーのアルゴリズムを考察します。このアルゴリズムは、そのアイデアの美しさと実装の容易さで際立っています。

母集団最適化アルゴリズム:Shuffled Frog-Leaping (SFL) アルゴリズム
本稿では、Shuffled Frog-Leaping (SFL)アルゴリズムの詳細な説明と、最適化問題を解く上でのその能力を紹介します。SFLアルゴリズムは、自然環境におけるカエルの行動から着想を得ており、関数最適化への新しいアプローチを提供します。SFLアルゴリズムは、効率的で柔軟なツールであり、様々な種類のデータを処理し、最適解を得ることができます。

ニューラルネットワークが簡単に(第58回):Decision Transformer (DT)
強化学習の手法を引き続き検討します。この記事では、一連の行動を構築するパラダイムでエージェントの方策を考慮する、少し異なるアルゴリズムに焦点を当てます。

データサイエンスと機械学習(第15回):SVM、すべてのトレーダーのツールボックスの必須ツール
取引の未来を形作るサポートベクターマシン(SVM)の不可欠な役割をご覧ください。この包括的なガイドブックでは、SVMがどのように取引戦略を向上させ、意思決定を強化し、金融市場における新たな機会を解き放つことができるかを探求しています。実際のアプリケーション、ステップバイステップのチュートリアル、専門家の洞察でSVMの世界に飛び込みましょう。現代の複雑な取引をナビゲートするのに不可欠なツールを装備してください。SVMはすべてのトレーダーのツールボックスの必需品です。

ニューラルネットワークが簡単に(第57回):Stochastic Marginal Actor-Critic (SMAC)
今回は、かなり新しいStochastic Marginal Actor-Critic (SMAC)アルゴリズムを検討します。このアルゴリズムは、エントロピー最大化の枠組みの中で潜在変数方策を構築することができます。

時系列マイニング用データラベル(第3回):ラベルデータの利用例
この連載では、ほとんどの人工知能モデルに適合するデータを作成できる、いくつかの時系列のラベル付け方法を紹介します。ニーズに応じて的を絞ったデータのラベル付けをおこなうことで、訓練済みの人工知能モデルをより期待通りの設計に近づけ、モデルの精度を向上させ、さらにはモデルの質的飛躍を助けることができます。

独自のLLMをEAに統合する(第2部):環境展開例
今日の人工知能の急速な発展に伴い、言語モデル(LLM)は人工知能の重要な部分となっています。私たちは、強力なLLMをアルゴリズム取引に統合する方法を考える必要があります。ほとんどの人にとって、これらの強力なモデルをニーズに応じて微調整し、ローカルに展開して、アルゴリズム取引に適用することは困難です。本連載では、この目標を達成するために段階的なアプローチをとっていきます。

独自のLLMをEAに統合する(第1部):ハードウェアと環境の導入
今日の人工知能の急速な発展に伴い、言語モデル(LLM)は人工知能の重要な部分となっています。私たちは、強力なLLMをアルゴリズム取引に統合する方法を考える必要があります。ほとんどの人にとって、これらの強力なモデルをニーズに応じて微調整し、ローカルに展開して、アルゴリズム取引に適用することは困難です。本連載では、この目標を達成するために段階的なアプローチをとっていきます。

知っておくべきMQL5ウィザードのテクニック(第07回):樹状図
分析や予測を目的としたデータの分類は、機械学習の中でも非常に多様な分野であり、数多くのアプローチや手法があります。この作品では、そのようなアプローチのひとつである「凝集型階層分類」を取り上げます。

ONNXをマスターする:MQL5トレーダーにとってのゲームチェンジャー
機械学習モデルを交換するための強力なオープン標準形式であるONNXの世界に飛び込んでみましょう。ONNXを活用することでMQL5のアルゴリズム取引にどのような変革がもたらされ、トレーダーが最先端のAIモデルをシームレスに統合し、戦略を新たな高みに引き上げることができるようになるかがわかります。クロスプラットフォーム互換性の秘密を明らかにし、MQL5取引の取り組みでONNXの可能性を最大限に引き出す方法を学びましょう。ONNXをマスターするためのこの包括的なガイドで取引ゲームを向上させましょう。

MQL5の圏論(第23回):二重指数移動平均の別の見方
この記事では、前回に引き続き、日常的な取引指標を「新しい」視点で見ていくことをテーマとします。今回は、自然変換の水平合成を取り扱いますが、これに最適な指標は、今回取り上げた内容を拡大したもので、二重指数移動平均(DEMA)です。
MQL5の圏論(第22回):移動平均の別の見方
この記事では、最も一般的で、おそらく最も理解しやすい指標を1つだけ取り上げて、連載で扱った概念の説明の簡略化を試みます。移動平均です。そうすることで、垂直的自然変換の意義と可能な応用について考えます。

MQL5の圏論(第21回):LDAによる自然変換
連載21回目となるこの記事では、自然変換と、線形判別分析を使ったその実装方法について引き続き見ていきます。前回同様、シグナルクラス形式でその応用例を紹介します。
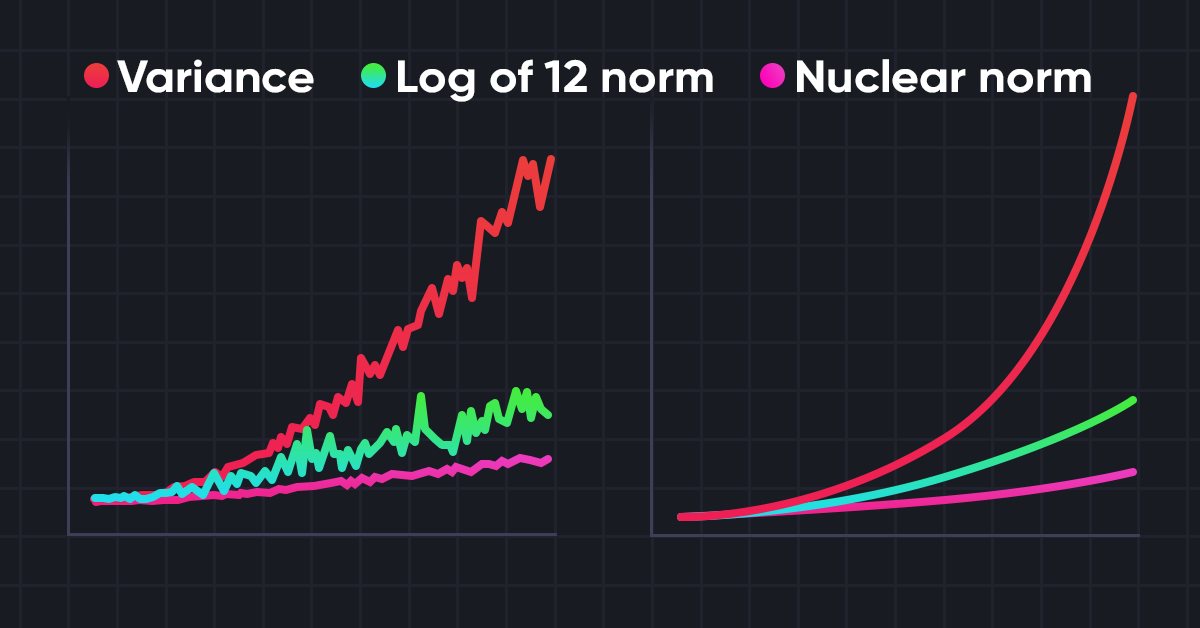
ニューラルネットワークが簡単に(第56回):核型ノルムを研究の推進力に
強化学習における環境の研究は喫緊の課題です。いくつかのアプローチについてすでに見てきました。この記事では、核型ノルムの最大化に基づくもう一つの方法について見てみましょう。これにより、エージェントは新規性と多様性の高い環境状態を特定することができます。
ニューラルネットワークが簡単に(第55回):対照的内発制御(Contrastive intrinsic control、CIC)
対照訓練は、教師なしで表現を訓練する方法です。その目標は、データセットの類似点と相違点を強調するためにモデルを訓練することです。この記事では、対照訓練アプローチを使用してさまざまなActorスキルを探究する方法について説明します。

ニューラルネットワークが簡単に(第54回):ランダムエンコーダを使った効率的な研究(RE3)
強化学習手法を検討するときは常に、環境を効率的に探索するという問題に直面します。この問題を解決すると、多くの場合、アルゴリズムが複雑になり、追加モデルの訓練が必要になります。この記事では、この問題を解決するための別のアプローチを見ていきます。

ニューラルネットワークが簡単に(第53回):報酬の分解
報酬関数を正しく選択することの重要性については、すでに何度かお話ししました。報酬関数は、個々の行動に報酬またはペナルティを追加することでエージェントの望ましい行動を刺激するために使用されます。しかし、エージェントによる信号の解読については未解決のままです。この記事では、訓練されたエージェントに個々のシグナルを送信するという観点からの報酬分解について説明します。

ニューラルネットワークが簡単に(第52回):楽観論と分布補正の研究
経験再現バッファに基づいてモデルが訓練されるにつれて、現在のActor方策は保存されている例からどんどん離れていき、モデル全体としての訓練効率が低下します。今回は、強化学習アルゴリズムにおけるサンプルの利用効率を向上させるアルゴリズムについて見ていきます。

MQL5の圏論(第20回):セルフアテンションとTransformerへの回り道
ちょっと寄り道して、chatGPTのアルゴリズムの一部について考えてみたいとおもいます。自然変換から借用した類似点や概念はあるのでしょうか。シグナルクラス形式のコードを用いて、これらの疑問やその他の質問に楽しく答えようと思います。

時系列マイニングのためのデータラベル(第2回):Pythonを使ってトレンドマーカー付きデータセットを作成する
この連載では、ほとんどの人工知能モデルに適合するデータを作成できる、いくつかの時系列のラベル付け方法を紹介します。ニーズに応じて的を絞ったデータのラベル付けをおこなうことで、訓練済みの人工知能モデルをより期待通りの設計に近づけ、モデルの精度を向上させ、さらにはモデルの質的飛躍を助けることができます。

MQL5の圏論(第19回):自然性の正方形の帰納法
自然性の正方形の帰納法を考えることで、自然変換について考察を続けます。MQL5ウィザードで組み立てられたエキスパートアドバイザー(EA)の多通貨の実装には若干の制約があるため、スクリプトでデータ分類能力を紹介しています。主な用途は、価格変動の分類とその予測です。

時系列マイニングのためのデータラベル(第1回):EA操作チャートでトレンドマーカー付きデータセットを作成する
この連載では、ほとんどの人工知能モデルに適合するデータを作成できる、いくつかの時系列のラベル付け方法を紹介します。ニーズに応じて的を絞ったデータのラベル付けをおこなうことで、訓練済みの人工知能モデルをより期待通りの設計に近づけ、モデルの精度を向上させ、さらにはモデルの質的飛躍を助けることができます。

ニューラルネットワークが簡単に(第51回):Behavior-Guided Actor-Critic (BAC)
最後の2つの記事では、エントロピー正則化を報酬関数に組み込んだSoft Actor-Criticアルゴリズムについて検討しました。このアプローチは環境探索とモデル活用のバランスをとりますが、適用できるのは確率モデルのみです。今回の記事では、確率モデルと確定モデルの両方に適用できる代替アプローチを提案します。

ニューラルネットワークが簡単に(第50回):Soft Actor-Critic(モデルの最適化)
前回の記事では、Soft Actor-Criticアルゴリズムを実装しましたが、有益なモデルを訓練することはできませんでした。今回は、先に作成したモデルを最適化し、望ましい結果を得ます。

ニューラルネットワークが簡単に(第49回):Soft Actor-Critic
連続行動空間の問題を解決するための強化学習アルゴリズムについての議論を続けます。この記事では、Soft Actor-Critic (SAC)アルゴリズムについて説明します。SACの主な利点は、期待される報酬を最大化するだけでなく、行動のエントロピー(多様性)を最大化する最適な方策を見つけられることです。

ニューラルネットワークが簡単に(第48回):Q関数値の過大評価を減らす方法
前回は、連続的な行動空間でモデルを学習できるDDPG法を紹介しました。しかし、他のQ学習法と同様、DDPGはQ関数値を過大評価しやすくなります。この問題によって、しばしば最適でない戦略でエージェントを訓練することになります。この記事では、前述の問題を克服するためのいくつかのアプローチを見ていきます。


ニューラルネットワークが簡単に(第46回):目標条件付き強化学習(GCRL)
今回は、もうひとつの強化学習アプローチを見てみましょう。これはGCRL(goal-conditioned reinforcement learning、目標条件付き強化学習)と呼ばれます。このアプローチでは、エージェントは特定のシナリオでさまざまな目標を達成するように訓練されます。
ニューラルネットワークが簡単に(第45回):状態探索スキルの訓練
明示的な報酬関数なしに有用なスキルを訓練することは、階層的強化学習における主な課題の1つです。前回までに、この問題を解くための2つのアルゴリズムを紹介しましたが、環境調査の完全性についての疑問は残されています。この記事では、スキル訓練に対する異なるアプローチを示します。その使用は、システムの現在の状態に直接依存します。

ニューラルネットワークが簡単に(第44回):ダイナミクスを意識したスキルの習得
前回は、様々なスキルを学習するアルゴリズムを提供するDIAYN法を紹介しました。習得したスキルはさまざまな仕事に活用できます。しかし、そのようなスキルは予測不可能なこともあり、使いこなすのは難しくなります。この記事では、予測可能なスキルを学習するアルゴリズムについて見ていきます。

ニューラルネットワークが簡単に(第43回):報酬関数なしでスキルを習得する
強化学習の問題は、報酬関数を定義する必要性にあります。それは複雑であったり、形式化するのが難しかったりします。この問題に対処するため、明確な報酬関数を持たずにスキルを学習する、活動ベースや環境ベースのアプローチが研究されています。

ニューラルネットワークが簡単に (第42回):先延ばしのモデル、理由と解決策
強化学習の文脈では、モデルの先延ばしにはいくつかの理由があります。この記事では、モデルの先延ばしの原因として考えられることと、それを克服するための方法について考察しています。

ニューラルネットワークが簡単に(第41回):階層モデル
この記事では、複雑な機械学習問題を解決するための効果的なアプローチを提供する階層的訓練モデルについて説明します。階層モデルはいくつかのレベルで構成され、それぞれがタスクの異なる側面を担当します。

ニューラルネットワークが簡単に(第40回):大量のデータでGo-Exploreを使用する
この記事では、長い訓練期間に対するGo-Exploreアルゴリズムの使用について説明します。訓練時間が長くなるにつれて、ランダムな行動選択戦略が有益なパスにつながらない可能性があるためです。

ニューラルネットワークが簡単に(第39回):Go-Explore、探検への異なるアプローチ
強化学習モデルにおける環境の研究を続けます。この記事では、モデルの訓練段階で効果的に環境を探索することができる、もうひとつのアルゴリズム「Go-Explore」を見ていきます。

ニューラルネットワークが簡単に(第38回):不一致による自己監視型探索
強化学習における重要な問題のひとつは、環境探索です。前回までに、「内因性好奇心」に基づく研究方法について見てきました。今日は別のアルゴリズムを見てみましょう。不一致による探求です。

MQL5の圏論(第18回):ナチュラリティスクエア(自然性の四角形)
この記事では、圏論の重要な柱である自然変換を紹介します。一見複雑に見える定義に注目し、次に本連載の「糧」であるボラティリティ予測について例と応用を掘り下げていきます。

MQL5の圏論(第17回):関手とモノイド
関手を題材にしたシリーズの最終回となる今回は、圏としてのモノイドを再考します。この連載ですでに紹介したモノイドは、多層パーセプトロンとともに、ポジションサイジングの補助に使われます。