
MQL5の圏論(第20回):セルフアテンションとTransformerへの回り道
はじめに
圏論と自然変換をテーマにしながら、この連載を続け、チャットGPTという「部屋の中の象」に触れないのは、不謹慎なことだと思います。今では誰もが、何らかの形で、chatGPTや他のAIプラットフォームのホストに精通しており、transformerニューラルネットワークが私たちの研究を容易にするだけでなく、単純なタスクから非常に必要な時間を削減する可能性があることを目の当たりにし、できれば理解しているはずです。そこで、この連載から回り道をして、圏論での自然変換が、Open AIが取り組んでいるGPTアルゴリズムにとって何らかの鍵になるのかという疑問に取り組んでみました。
「変換」の文言と同義語がないかチェックすることに加えて、MQL5のGPTアルゴリズムコードの一部を確認し、証券価格系列の予備分類で検証してみるのも面白いと思います。
論文『Attention Is All You Need』で紹介されたTransformerは、話し言葉の翻訳(例えばイタリア語からフランス語)に使われるニューラルネットワークの技術革新で、回帰型ニューラルネットワークと畳み込みニューラルネットワーク を取り除くことを提案しました。その提案とはセルフアテンションです。現在使用されている多くのAIプラットフォームは、この初期の取り組みから生まれたものであることは理解されています。
オープンAIが実際に使用しているアルゴリズムは確かに非公開ですが、単語の埋め込み、位置符号化(英語)、セルフアテンション、Feed-Forwardネットワーク(英語)、Decoder-only Transformerのスタックの一部を使用していることは分かっています。いずれも確証があるわけではないので、私の言葉を鵜呑みにしてはいけません。そしてはっきりさせておきたいのは、この言及はアルゴリズムの単語/言語翻訳部分に関するものだということです。たしかに、chatGPTの入力のほとんどはテキストなので、それはアルゴリズムにおいて重要な、ほとんど基礎的な役割を形成していますが、chatGPTはテキストを解釈する以上のことをすることがわかっています。例えば、エクセルファイルをアップロードすれば、それを開いて内容を読むだけでなく、グラフをプロットしたり、提示された統計について意見を述べたりすることもできます。ここで重要なのは、chatGPT アルゴリズムがここで完全に示されているわけではなく、理解されているものの一部だけであることです。
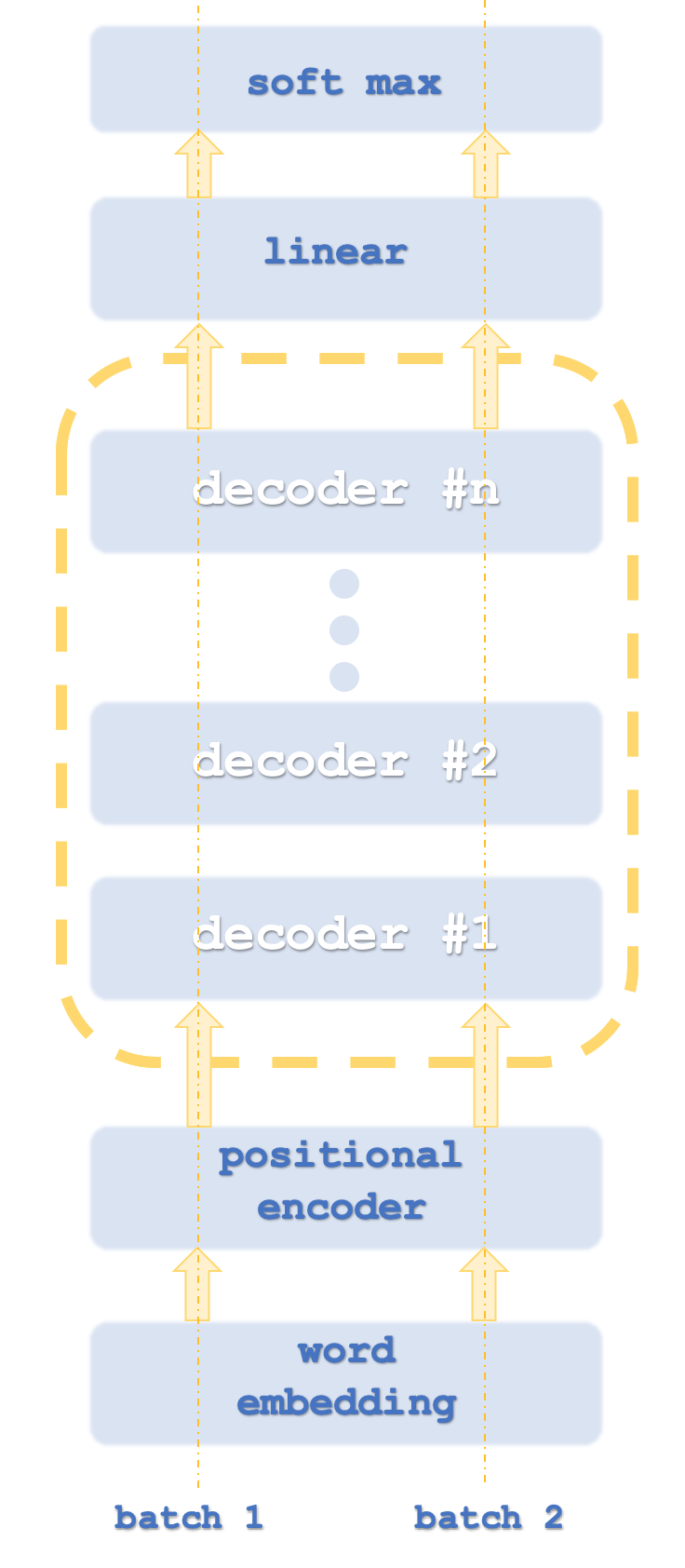
Transformerは通常、ネットワークインスタンスを並行して実行するため、バッチ1と2はコンピューターのスレッドに似ています。
ここでは数字を分類しているので、単語を埋め込む必要はありません。位置符号化は、文中の各単語の絶対的な重要性をその位置によって捉えることを意味します。このアルゴリズムは単純で、各単語(別名トークン)は、異なる周波数の正弦波の配列から、正弦波の読み取り値を割り当てます。各波の読みが加算され、そのトークンの位置エンコードが得られます。この値はベクトルにすることができ、複数の周波数の配列の値を合計することを意味します。
そして、それはセルフアテンションへとつながります。これは、文中の各単語の、その文中でその前に現れる単語に対する相対的な重要度を計算するものです。この一見些細な努力は、とりわけ「it」という単語が典型的に登場する文章では重要です。例えば、
「The dish washer partly cleaned the glass and it cracked it.」
という文章で、「it」は何を指すのでしょうか。人間にとっては簡単なことですが、学習している機械にとってはそうではありません。この問題は一見平凡に見えますが、この単語の相対的な重要性を定量化する能力こそが、Transformerニューラルネットを立ち上げる上で重要であったことは間違いません。Transformerニューラルネットは、その前身である回帰型ネットワークや畳み込みネットワークよりも並列処理が可能で、訓練に要する時間が大幅に短いことが判明しています。
従って、この記事では、セルフアテンションがシグナルクラスのテストの核となります。しかし興味深いことに、セルフアテンションアルゴリズムは、単語が互いに関連し合うという点で、ある圏に似ています。相対的な重要性(類似性)を定量化するために使われる単語関係は、単語そのものがオブジェクトを形成する射と考えることができます。実際、各単語は自分自身との類似性や重要性を計算する必要があるため、この関係は少し不気味です。これは恒等射によく似ているのです!さらに、射とオブジェクトを推論する以外に、後の記事で見たように、関手と圏をそれぞれ関連づけることもできます。
Transformerデコーダーを理解する
通常、Transformerネットワ。ークは、エンコードスタックとデコードスタックの両方を含み、各スタックはセルフアテンションネットワークとフィードフォワードネットワークの繰り返しを表します。以下のようなものに似ているかもしれません。
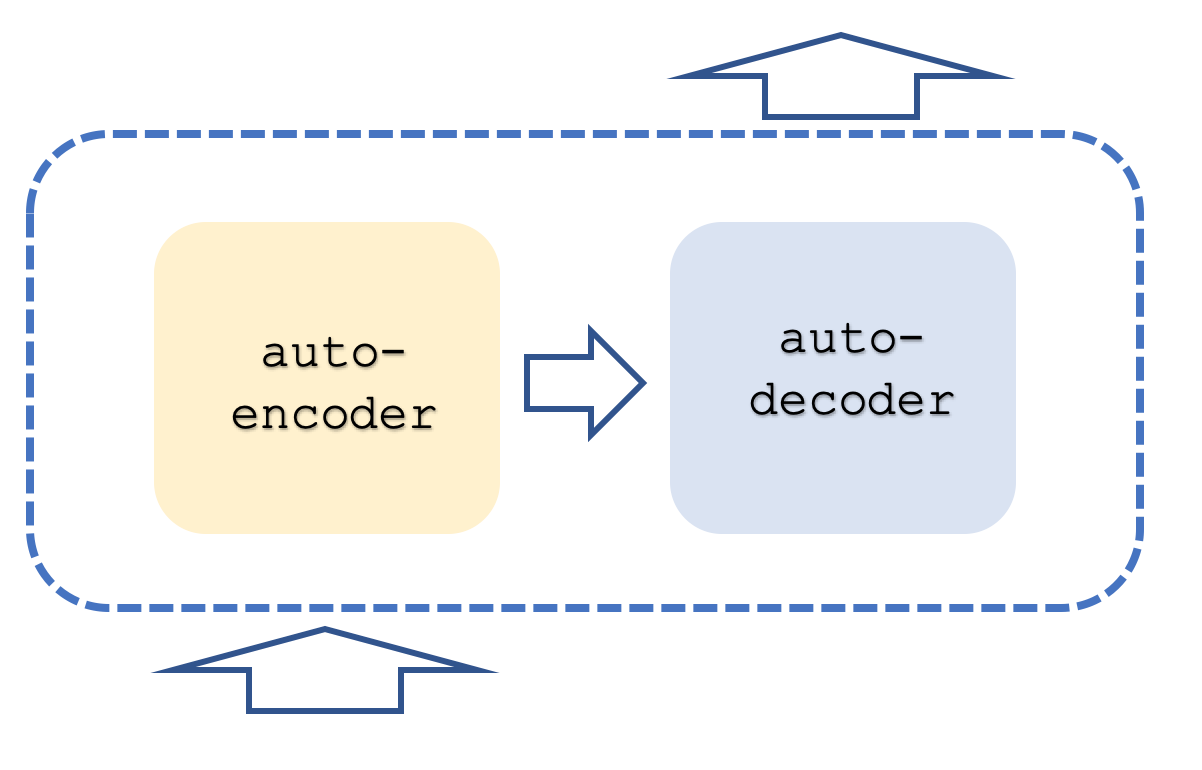
その上、各手順は並列の「スレッド」で実行されます。つまり、たとえばセルフアテンションとフィードフォワードの手順が多層パーセプトロンで表現できる場合、Transformerが8つのスレッドを持っていれば、各ステージに8つの多層パーセプトロンが存在することになります。これは明らかにリソースを大量に消費しますが、このリソースを使ってもなお、前身である複雑なネットワークよりも効率的であるため、このアプローチに優位性を与えています。
Open AIが採用しているアプローチは、デコードのみという点で、この変形であると理解されています。その手順は、最初の図に大まかに示した通りです。デコードのみであることは、明らかにモデルの精度には影響しませんが、Transformerの「半分」しか処理されないため、性能は確実に向上します。ここで、エンコード時のセルフアテンションマッピングはデコード時のマッピングとは異なり、エンコード時には文中の相対的な位置に関係なく、すべての単語の相対的な重要度が計算されることを指摘しておくとよいでしょう。デコーダー側で述べたように、セルフアテンション(類似度計算)は各単語に対してのみおこなわれ、文中ではその前に来る単語に対してのみおこなわれるため、これは明らかにさらにリソースを消費します。位置符号化の必要性を否定する議論もあるでしょうが、今回の目的ではソースに含めることにします。したがって、このデコードのみのアプローチに焦点を当てます。
Transformer手順内のセルフアテンションネットワークとフィードフォワードネットワークの役割は、位置符号化または前のスタック出力を受け取り、スタックに応じて、次のデコーダー手順の入力の線形ソフトマックス手順の入力を生成することです。
位置符号化は、ここでのシグナルクラスや記事にとってはやり過ぎだと感じる方もいっらしゃるかもしれませんが、ここでは情報提供のために含まれています。入力された価格バー情報の絶対的な順序は、文中の単語の順序と同じくらい重要かもしれません。ここでは、各入力価格ポイントの「座標」として機能する二重値の4桁ベクトルを返す単純なアルゴリズムを使用しています。
なぜ各入力に単純なインデックスを使わないのかという意見もあるでしょう。これにより、ネットワークを訓練するときに勾配が消失したり爆発したりするため、揮発性の低い正規化された形式が必要になることがわかりました。これは、暗号化されるものに関係なく、標準的な長さ、たとえば128の暗号化キーと同じだと考えることができます。確かに、隠し鍵の解読は難しくなりますが、鍵の生成と保管をより効率的におこなうことができます。
そこで、異なる周波数の4つの正弦波を使用します。このように4つの周波数があるにもかかわらず、2つの単語が同じ「座標」を持つことがありますが、そのようなことが起きても、このわずかな異常を否定するために多くの単語(私たちの場合は価格帯)が使用されているので、問題になることはありません。これらの座標値は、入力ベクトルの4つの価格ポイントに追加されます。この4つの価格ポイントは、単語埋め込みから得られるはずのものですが、すでに証券価格という形で数字を扱っているため、追加されません。このシグナルクラスは価格変動を利用します。また、位置符号化を「正規化」するために、位置符号化値は+5.0から-5.0、時にはそれ以上に変動することがありますが、価格変動に加算される前に、当該証券のポイントサイズに掛け合わされます。
上記の共有ハイパーリンクからお分かりのように、セルフアテンションメカニズムは、3つのベクトル、すなわちクエリベクトル、キーベクトル、バリューベクトルを決定する役割を担っています。これらのベクトルは、位置符号化出力ベクトルと重みの行列を掛け合わせることで得られます。この重みはどうやって手に入れたのでしょうか。バックプロパゲーションからです。しかし、私たちの目的では、これらの重みを初期化して訓練するために、多層パーセプトロンクラスのインスタンスを使用します。一層のみです。この重要な段階におけるプロセスを図式化すると、次のようになります。
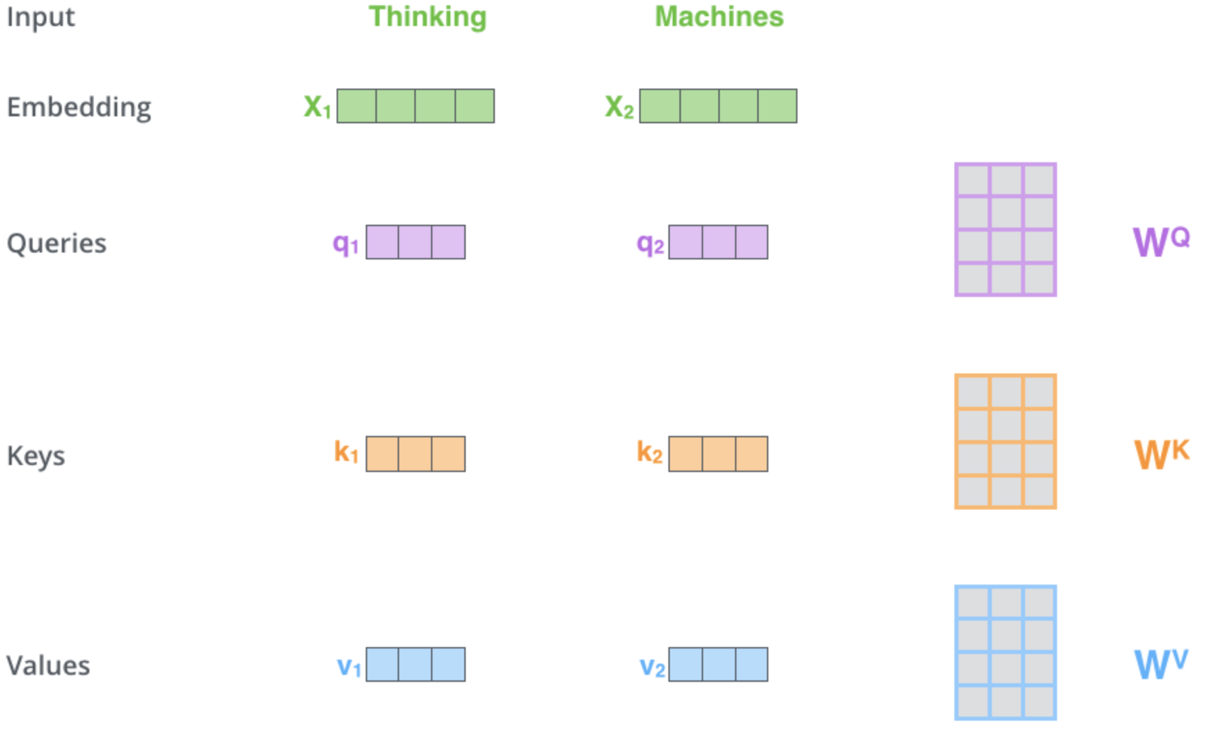
この図版および本記事中のトーキングポイントの一部の出典はweb-pageです。上の画像は2つの単語(「Thinking」と「Machines」)を入力として表しています。埋め込み(数値ベクトルへの変換)では、緑色のベクトルに変換されます。右側の行列は、前述したように多層パーセプトロンによって得られる重みを表しています。
そこで、ネットワークがフォワードパスを実行し、クエリ、キー、バリューのベクトルを得たら、クエリとキーの内積をとり、この結果をキーベクトルの基数の平方根で割ると、その結果がクエリベクトルを持つプライスポイントとキーベクトルを持つプライスポイントの類似度となります。これらの掛け算は、価格帯を自分自身とその前の価格帯とだけ比較するセルフアテンションマッピングに沿うように、すべての価格帯でおこなわれます。そのため、ソフトマックス関数を使って確率分布に正規化しています。これらの確率の重みの合計は、予想通り1になります。事実上の重み調整です。最後の手順では、各重みがそれぞれのベクトル値と掛け合わされ、これらの積が合計されて1つのベクトルとなり、セルフアテンション層の出力となります。
フィードフォワードネットワークは、セルフアテンションからの出力ベクトルを多層パーセプトロンで処理し、セルフアテンションの入力ベクトルと同じ大きさの別のベクトルを出力します。
MQL5でTransformerデコーダーを実装するための理論的枠組みは、EAではなく、単純なシグナルクラスを経由します。今のところ、このテーマは少々複雑です。というのも、これらのアイデアの中には、まだ10年も経っていないものもあるからです。もちろん、読者はこれらの考えを自由に取り入れ、いつ取り入れても構わない。
MQL5シグナルクラス:セルフアテンションとフィードフォワードネットワークへの一瞥
この記事に添付されているシグナルクラスでは、1つのスタックと1つのスレッドしか持たないTransformerデコーダーを使って、価格変動を予測することに挑戦している!添付のコードは、「__DECODERS」定義パラメータを調整することで、スタック数を増やすことができます。前述したように、スタックは通常複数であり、マルチスレッド設定であることが多い。実際、通常はデコーダー内で複数のスタックを使用するため、接続が必要となります。これもまた、、グラデーションが爆発する問題を避けるためです。だから、私たちはシンプルな骨組みのトランスを使って、それが何ができるかを見ています。読者はここから、自分の実装ニーズに合わせてさらにカスタマイズすることができます。
位置符号化は、単純に入力の大きさが与えられた座標のベクトルを返すだけなので、おそらく列挙した関数の中で最も単純なものでしょう。このリストは以下の通り:
//+------------------------------------------------------------------+ //| Positional Encoding vector given length. | //+------------------------------------------------------------------+ vector CSignalCT::PositionalEncoding(int Positions) { vector _positions; _positions.Init(Positions);_positions.Fill(0.0); for(int i=0;i<Positions;i++) { for(int ii=0;ii<Positions;ii++) { _positions[i]+=MathSin((((ii+1)/Positions)*(i+1))*__PI); } } return(_positions); }
つまり、このシグナルクラスは多くの関数を参照しているわけですが、その中でも最も重要なのは、以下にソースを示すデコード関数である:
//+------------------------------------------------------------------+ //| Decode Function. | //+------------------------------------------------------------------+ void CSignalCT::Decode(int &DecoderIndex,matrix &Input,matrix &Sum,matrix &Output) { Input.ReplaceNan(0.0); // //output matrices Sum.Init(1,int(Input.Cols()));Sum.Fill(0.0); Ssimilarity _s[]; ArrayResize(_s,int(Input.Cols())); for(int i=int(Input.Rows())-1;i>=0;i--) { matrix _i;_i.Init(1,int(Input.Cols())); for(int ii=0;ii<int(Input.Cols());ii++) { _i[0][ii]=Input[i][ii]; } // SelfAttention(DecoderIndex,_i,_s[i].queries,_s[i].keys,_s[i].values); } for(int i=int(Input.Cols())-1;i>=0;i--) { for(int ii=i;ii>=0;ii--) { matrix _similarity=DotProduct(_s[i].queries,_s[ii].keys); Sum+=DotProduct(_similarity,_s[i].values); } } // Sum.ReplaceNan(0.0); // FeedForward(DecoderIndex,Sum,Output); }
ご覧のように、これはセルフアテンション機能とフィードフォワード機能の両方を呼び出し、またこれら両方の層機能に必要な入力データを準備します。
セルフアテンション関数は、クエリ、キー、値のベクトルを得るために、実際の行列の重み計算をおこないます。シグナルクラスの目的では1行の行列を使うことになりますが、実際には複数のベクトルをネットワークに通したり、重みの行列系にかけたりして、クエリ、キー、値の行列を得ることが多いため、これらの「ベクトル」を行列として表現しました。そのソースは以下の通りです。
//+------------------------------------------------------------------+ //| Self Attention Function. | //+------------------------------------------------------------------+ void CSignalCT::SelfAttention(int &DecoderIndex,matrix &Input,matrix &Queries,matrix &Keys,matrix &Values) { Input.ReplaceNan(0.0); // Queries.Init(int(Input.Rows()),int(Input.Cols()));Queries.Fill(0.0); Keys.Init(int(Input.Rows()),int(Input.Cols()));Keys.Fill(0.0); Values.Init(int(Input.Rows()),int(Input.Cols()));Values.Fill(0.0); for(int i=0;i<int(Input.Rows());i++) { double _x_inputs[],_q_outputs[],_k_outputs[],_v_outputs[]; vector _i=Input.Row(i);ArrayResize(_x_inputs,int(_i.Size())); for(int ii=0;ii<int(_i.Size());ii++){ _x_inputs[ii]=_i[ii]; } m_base_q[DecoderIndex].MLPProcess(m_mlp_q[DecoderIndex],_x_inputs,_q_outputs); m_base_k[DecoderIndex].MLPProcess(m_mlp_k[DecoderIndex],_x_inputs,_k_outputs); m_base_v[DecoderIndex].MLPProcess(m_mlp_v[DecoderIndex],_x_inputs,_v_outputs); for(int ii=0;ii<int(_q_outputs.Size());ii++){ if(!MathIsValidNumber(_q_outputs[ii])){ _q_outputs[ii]=0.0; }} for(int ii=0;ii<int(_k_outputs.Size());ii++){ if(!MathIsValidNumber(_k_outputs[ii])){ _k_outputs[ii]=0.0; }} for(int ii=0;ii<int(_v_outputs.Size());ii++){ if(!MathIsValidNumber(_v_outputs[ii])){ _v_outputs[ii]=0.0; }} for(int ii=0;ii<int(Queries.Cols());ii++){ Queries[i][ii]=_q_outputs[ii]; } Queries.ReplaceNan(0.0); for(int ii=0;ii<int(Keys.Cols());ii++){ Keys[i][ii]=_k_outputs[ii]; } Keys.ReplaceNan(0.0); for(int ii=0;ii<int(Values.Cols());ii++){ Values[i][ii]=_v_outputs[ii]; } Values.ReplaceNan(0.0); } }
フィードフォワード関数は、多層パーセプトロンのストレートな処理であり、デコードTransformerに特有なものは何もありません。もちろん、他の実装では、複数の隠れ層や、ボルツマンマシンのような異なるタイプのネットワークなど、ここでカスタム設定をすることもできますが、ここでの目的では、これは単純な単一隠れ層ネットワークです。
ドット積関数は、2つの行列を乗算するカスタム実装だという点でちょっと面白いものです。主に1行行列(別名ベクトル)の乗算に使っていますが、スケーラブルで、内蔵の行列乗算関数の予備テストでは今のところバグが見つかっているので、臨機応変に対応できるでしょう。
ソフトマックスは、ウィキにあるものの実装です。私たちがやっていることは、値の入力配列が与えられたときに、確率のベクトルを返すことです。出力ベクトルはすべての値が正で、合計が1になります。
つまり、このシグナルクラスは、USDJPYの2020.01.01から2023.08.01までの価格データをロードします。日足の時間枠では、単純に終値の直近4回の変化である4つの価格ポイントのベクトルを位置符号化関数に入力します。この関数は、前述のように、各価格変動の座標を取得し、USDJPYのポイントサイズに乗じることで正規化し、入力された価格変動に加算します。
この出力ベクトルは、ベクトル内の4つの入力それぞれについて、クエリ、キー、値ベクトルを計算するデコード関数に供給されます。セルフマッピングでは、各価格ポイントについて、それ自身とそれ以前の価格変動との類似性のみが確認されるため、4つのベクトル値から、ソフトマックスによる正規化が必要な10個のベクトル値が得られます。
これをソフトマックスにかけると、10個の重みの配列ができ、そのうち1個だけが最初の価格帯に属します。2個が2番目、3個が3番目、4個が4番目の価格帯に属します。各価格帯には、セルフアテンション関数で得た値ベクトルもあるので、このベクトルにソフトマックスから得たそれぞれの重みを掛け合わせ、これらのベクトルを合計して1つの出力ベクトルにします。設計上、トランススタックは順番に並んでいるので、その大きさは入力ベクトルの大きさと一致するはずです。また、多層パーセプトロンを使用しているため、各ネットワークで初期化される重みはランダムであり、バーを重ねるごとに学習される(したがって改善される)ことも重要です。
シグナルクラスをEAにコンパイルして、2023年の最初の5か月のために最適化し、2023.06.01から2023.08.01までウォークフォワードテストすると、以下のレポートが得られます。


これらのレポートは、ネットワーク重みの読み書き機能を持つエキスパートアドバイザー(EA)を使って作成されましたが、実装は読者次第であるため、添付のコードでは共有されていません。重みは初期化時に明確なソースから読み込まれるわけではないので、結果は実行ごとに異なることになります。
実世界での応用
Transformerデコーダーではなく、このシグナルクラスの潜在的な用途は、Transformerデコーダーで取引する潜在的な証券をスカウトすることでしょう。何十年という時間スパンで複数の証券のテストを実施すれば、追加テストやシステム開発でさらに調べる価値のあるものと、避けるべきものの感覚がつかめるかもしれません。
デコードTransformerのスタック内では、セルフアテンション層が重要であり、ここで使用されているフィードフォワードネットワークはかなり単純なので、我々の優位性をもたらすに違いません。そのため、相関関数は平均に注目するため簡単に見逃してしまうような方法で、各先行価格変動の相対的重要性を捉えることができます。クエリ、キー、バリューベクトルの重み行列を捕捉するために多層パーセプトロンを使用することは使用可能なアプローチの1つです。これを達成するための他の中間的な機械学習オプションが無数にあるためです。全体として、ネットワークの予測可能性に対するセルフアテンションの感度を理解することが鍵となるでしょう。
限界と欠点
シグナルクラスのネットワーク学習は、新しいバーごとにインクリメンタルにおこなわれ、事前に学習された重みを読み込む機能がないため、ランダムな結果が多く得られることになります。実際、このため、読者はシグナルクラスが実行されるたびに異なる結果が出ることを期待しなければなりません。
さらに、シグナルクラスの終了時に学習した重みを保存する機能もないため、ここで学習した内容を基に構築することはできません。
これらの限界は非常に重要であり、Transformerデコーダーを取引システムへと発展させる前に、対処する必要があると私は考えています。訓練済み重みを使用するだけではなく、訓練済み重みを保存し、システムを配備する前に、訓練済み重みでサンプル外のデータをテストする必要があります。
結論
では、質問に答えると、chatGPTアルゴリズムは自然変換に関連しているのでしょうか。そうかもしれません。というのも、デコーダーTransformerのスタックを圏と見なせば、スレッド(Transformerを通過する並列処理)は関手になるからです。このアナロジーでは、各操作の最終結果の差は、自然変換に相当します。
私たちのデコーダTransformerは、適切な重み記録や読み取りがなくても、いくつかの可能性を示しています。これは確かに興味深いシステムであり、スキル磨きのために、さらに発展させ、ツールキットに加えることもできるでしょう。
結論として、セルフアテンションアルゴリズムはトークン(transformerの入力)間の相対的類似性を定量化することに長けています。私たちの場合、これらのトークンは、異なるが連続した時点における価格変動でした。他のモデルでは、これは複数の経済指標、ニュースイベント、投資家のセンチメント値などであったかもしれませんが、プロセスは同じであったでしょう。しかし、これらの異なる入力による結果は、これらの入力値の複雑でダイナミックな関係を明らかにし、モデル化することになります。これにより長期的には、Transformerは新しい訓練セッションごとに、入力トークンから適応的に関連する特徴を抽出するようになります。そのため、多くのニュースが飛び交う不安定な状況でも、モデルはホワイトノイズをふるい落とし、より弾力的になるはずです。
また、セルフアテンションアルゴリズムは、添付のシグナルクラスで検討したように、異なる時点のラグや入力データに直面した場合、これらの異なる期間の相対的な重要性を定量化するのに役立ち、その結果、長期的な依存関係を捉えることができます。これは、トレーダーにとってもう1つの利点である、異なる時間軸での予測に対応する能力につながります。つまり、トークン入力の相対的な重み付けをまとめると、入力となりうるさまざまな経済指標だけでなく、ラグ付き時間指標(または価格)を使用する場合は、さまざまな時間枠についてもトレーダーに洞察を与えるはずです。
その他のリソース
参考文献は、ほとんどがウィキからのものです(リンクは記事内)が、コーネル大学のコンピューター サイエンスに関する出版物、Stack Exchange、Webサイトを含みます。
著者ノート
この記事で共有されているソースコードは、chatGPTで使用されているコードではありません。これは単にデコードのみのTransformerの実装です。これはシグナルクラス形式であるため、ユーザーはこれをMQL5ウィザードでコンパイルし、テスト可能なEAを形成する必要があります。それについてはここにガイドがあります。さらに、学習したネットワークの重みを読み込んだり保存したりするための、読み取りと書き込みのメカニズムを実装する必要があります。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/13348
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
掲載記事MQL5におけるカテゴリー理論(第20回):自己アテンションとトランスフォーマー
著者:Stephen Njuki