知っておくべきMQL5ウィザードのテクニック(第26回):移動平均とハースト指数
はじめに
MQL5ウィザードを使ったテクニックについての連載を続けます。引き続き、トレーダーに役立つ金融時系列分析の代替手法に焦点を当てます。この記事では ハースト指数(英語)について考察します。この指標は、時系列が時系列データが長期間にわたって高い正の自己相関を持っているか、負の自己相関を持っているかを示すものです。この測定の応用範囲は非常に広いです。どのように使用するのでしょうか。まず、ハースト指数を計算し、市場がトレンド相場(通常0.5より大きい値)のか、平均回帰/急激に変動しているのか(その場合は0.5未満の値)を判定します。今回は、前々回および前回に引き続き「移動平均線を見る季節」というテーマに沿って、ハースト指数の情報と現在の価格が移動平均線に対してどの位置にあるかを関連づけてみます。移動平均線に対する価格の相対的な位置は、価格の次の方向性を示すことができますが、1つ大きな注意点があります。
市場がトレンドにあるのか、それともレンジ相場(平均回帰相場)なのかを知る必要があるのです。この質問にはハースト指数を使用すれば答えられるので、単純に価格が平均に対してどの位置にあるかを見るだけで、取引の判断材料になります。しかし、これでもまだ少し急ぎすぎかもしれません。レンジ相場は、長期間のトレンド相場よりも短期間で見た方が明確にわかる傾向があるためです。このような理由から、確実な判断を下す前に、価格の相対的な位置を評価するために2本の移動平均線を使用することが有効です。これらは、レンジ相場や平均回帰相場では速い移動平均となり、トレンド相場では遅い移動平均となり、ハースト指数によって決定されます。つまり、Exponentによって設定された各市場タイプは、それぞれ独自の移動平均を持つことになります。そこでこの記事では、ハースト指数をを推定する手段として、再スケーリングされたレンジ分析を検討します。推定プロセスを一歩ずつ進め、最終的にはこのExponentを実装したExpertSignalクラスを紹介します。
時系列の分割
ウィキペディア(英語)によると、ハースト指数の公式は次のように示されます。
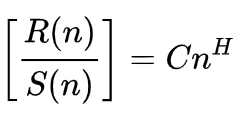
ここで
- nは分析サンプルのサイズ
- R()はサンプルの再スケーリングされた範囲
- S()はサンプルの標準偏差
- Cは定数
- Hはハースト指数
この式は本質的に2つの未知数を提示します。定数Cと私たちが求める指数Hの両方を見つけるために、これを回避する作業は、サンプリングされたセットの複数のセグメントを回帰することです。Hは、算術的にはHを解くために方程式の両辺に対数をとるべき乗であり、以下で説明するようにこれが最後のステップです。したがって、最初のステップは、サンプリングされたデータ内のセグメントを特定または定義することです。
どのサンプルからも得られる最小のセグメント数は2です。サンプルから得られる最大値はサンプルサイズに依存し、初歩的な公式はサンプルサイズを2で割ったものです。つまり、最小の2つの方程式が成り立つように、2つ以上の点が必要なのです。標本から生成できる方程式または点の組の数は、標本サイズの半分から1を引いた値で与えられます。したがって、4点のデータサンプルサイズでは、回帰のための1組の点しか生成されず、ハースト指数とC定数を求めるには明らかに不十分です。
しかし、6つのデータポイントを持つサンプルは、指数と定数を推定するために使用することができる最小の2つのポイントのペアを生成することができます。実際には、定義で述べたように、ハースト指数は「長期的」な特性であるため、サンプルサイズはできるだけ大きくします。また、上で紹介したウィキペディアの公式は、nが無限大に向かうにつれてサンプルに適用されます。したがって、より代表的なハースト指数を推定するためには、サンプルサイズをできるだけ大きくすることが重要です。
サンプルをセグメントに分割し、各分割/セグメントセットが1組の点を生成することが、まさに「最初のステップ」です。「最初のステップ」としたのは、この記事で使用しているアプローチでは、以下のソースコードに示されているように、データを一方的に分割し、すべてのセグメントを一度に定義してから次のステップに進むのではなく、分割ごとに、そのサンプルの分割からマッピングされるポイントのペアを計算するからです。これを実行するソースコードの一部を以下に示します。
//+------------------------------------------------------------------+ // Function to Estimate Hurst Exponent & Constant C //+------------------------------------------------------------------+ void CSignalHurst::Hurst(vector &Data, double &H, double &C) { matrix _points; double _std = Data.Std(); if(_std == 0.0) { printf(__FUNCSIG__ + " uniform sample with no standard deviation! "); return; } int _t = Fraction(Data.Size(), 2); if(_t < 3) { printf(__FUNCSIG__ + " too small sample size, cannot generate minimum 2 regression points! "); return; } _points.Init(_t - 1, 2); _points.Fill(0.0); for (int t = 2; t <= _t; t++) { matrix _segments; int _rows = Fraction(Data.Size(), t); _segments.Init(_rows, t); int _r = 0, _c = 0; for(int s = 0; s < int(Data.Size()); s++) { _segments[_r][_c] = Data[s]; _c++; if(_c >= t) { _c = 0; _r++; if(_r >= _rows) { break; } } } ... } ... }
そこで、データサンプルから重複しないセグメントをログに記録するために、各ステップで行列を使用します。全体的な反復では、最小のセグメントサイズ2から始めて、データサンプルの半分のサイズまで上げていきます。そのため、データのサンプルサイズの検証ステップを設け、半分のサイズが少なくとも3かどうかを確認します。もしそれが3より小さければ,最後のステップで回帰に必要な少なくとも2組のポイントを得ることができないので,ハースト指数を計算する意味がありません。
データサンプルに対しておこなうもう1つの検証ステップは、データ間にばらつきがあることを確認することです。これは、標準偏差がゼロの場合、有効な数値が得られなかったり、除算がゼロになったりするからです。
平均調整
ある反復(反復の合計回数はサンプルサイズの半分を上限とする)でセグメントのセットが得られたら、各セグメントの平均を求める必要があります。セグメントは行ごとに行列になっているので、各行はベクトルとして取り出すことができます。各行のベクトルで武装すれば、ベクトル内蔵の平均関数のおかげで簡単に平均を求めることができ、不必要なコーディングを省くことができます。その後、各セグメントの平均が、それぞれのセグメントの各データポイントから差し引かれます。これが平均調整と呼ばれるものです。レンジリスケールの分析プロセスで重要なのは、いくつかの理由があります。
まず、各セグメントの全データを正規化することで、セグメント内の各データポイントの絶対値に振り回されることなく、平均値の変動に焦点を当てた分析をおこなうことができます。第二に、この正規化は、より代表的なレンジスケールへの到達を妨げる可能性のある歪みや外れ値への偏りを減らすという目的を果たします。
さらに、この正規化によって、すべてのセグメントで一貫性が確保され、この正規化なしで絶対値を考慮する場合よりも比較しやすくなります。この調整はMQL5内で以下のソースコードを使用しておこないます。
//+------------------------------------------------------------------+ // Function to Estimate Hurst Exponent & Constant C //+------------------------------------------------------------------+ void CSignalHurst::Hurst(vector &Data, double &H, double &C) { matrix _points; ... _points.Init(_t - 1, 2); _points.Fill(0.0); for (int t = 2; t <= _t; t++) { ... vector _means; _means.Init(_rows); _means.Fill(0.0); for(int r = 0; r < _rows; r++) { vector _row = _segments.Row(r); _means[r] = _row.Mean(); } ... } ... }
行列とベクトルのデータ型は、平均を求めるだけでなく、正規化のスピードアップにも欠かせません。
累積偏差
平均値を調整したセグメントができたら、各セグメントの平均値からの偏差を合計して、各セグメントの累積偏差を求める必要があります。これは、レンジスケール分析の基礎となる次元削減の一形態と捉えることができます。これをソースコード内で次のように実行します。
//+------------------------------------------------------------------+ // Function to Estimate Hurst Exponent & Constant C //+------------------------------------------------------------------+ void CSignalHurst::Hurst(vector &Data, double &H, double &C) { matrix _points; ... _points.Init(_t - 1, 2); _points.Fill(0.0); for (int t = 2; t <= _t; t++) { matrix _segments; ... matrix _deviations; _deviations.Init(_rows, t); for(int r = 0; r < _rows; r++) { for(int c = 0; c < t; c++) { _deviations[r][c] = _segments[r][c] - _means[r]; } } vector _cumulations; _cumulations.Init(_rows); _cumulations.Fill(0.0); for(int r = 0; r < _rows; r++) { for(int c = 0; c < t; c++) { _cumulations[r] += _deviations[r][c]; } } ... } ... }
つまり、簡単にまとめると、各t値に対して、データサンプルを分割するセグメント群を作成します。各サンプルから平均を求め、それぞれのセグメント内のデータポイントから平均を引きます。この減算は一種の正規化として機能し、それが終わると、基本的に、各行が元のデータサンプルのセグメントであるデータポイントの行列ができます。セグメントの次元を小さくする方法として、それぞれの平均値からの偏差を合計し、多次元のセグメントが単一の値を示すようにします。これは、行列に対して偏差キュムレーションを実行した後、総和のベクトルが残ることを意味し、このベクトルは上記のソースでは「_cumulations」とラベル付けされています。
リスケーリングされた範囲と対数-対数プロット
ベクトル内のすべてのセグメントにわたる偏差の累積が得られたら、次のステップは、最大合計偏差と最小合計偏差の差である範囲を見つけることだけです。上のセグメントで各データポイントの偏差を記録したとき、絶対値を記録していないことに留意してください。単純にセグメント値からセグメントの平均値を引いたものを記録しました。これは、累積がゼロになるのが非常に簡単であることを意味します。実際、これはハースト指数の計算を進める前に検証確認を受けるべきものです。無効な結果につながる可能性が高くなるからです。この検証は添付のソースコードではおこなわれていないので、読者は自由に調整することができます。この最後のステップを以下のコードで実行します。
//+------------------------------------------------------------------+ // Function to Estimate Hurst Exponent & Constant C //+------------------------------------------------------------------+ void CSignalHurst::Hurst(vector &Data, double &H, double &C) { matrix _points; ... _points.Init(_t - 1, 2); _points.Fill(0.0); for (int t = 2; t <= _t; t++) { ... ... _points[t - 2][0] = log((_cumulations.Max() - _cumulations.Min()) / _std); _points[t - 2][1] = log(t); } LinearRegression(_points, H, C); }
上のソースコード部分からわかるように、ここでは指数(べき乗)を求めており、対数は指数を解くのに役立つため、累積範囲とその自然対数を得ることができます。上の式から、サンプルサイズは方程式の片側にあるため、その自然対数も得ることができます。これがy軸となり、x軸はデータサンプルの標準偏差で割ったスケール範囲の自然対数となります。これらの点のペア、xとyは、各セグメントサイズに固有です。データサンプル内の異なるセグメントサイズは、別のx-y点のペアを表し、これらの数が多ければ多いほど、より代表的なハースト指数となります。そして前述のように、x-y点の可能なペアの総数は、データサンプルのサイズの半分が上限となります。
つまり、この_points行列は、再スケーリングされたレンジ分析で見られる対数対数プロットを表しています。このプロットが線形回帰計算の入力となります。
線形回帰
線形回帰は、ハースト法とは別の関数によって実行されます。そのシンプルなコードを以下に紹介します。
//+------------------------------------------------------------------+ // Function to perform linear regression //+------------------------------------------------------------------+ void CSignalHurst::LinearRegression(matrix &Points, double &Slope, double &Intercept) { double _sum_x = 0.0, _sum_y = 0.0, _sum_xy = 0.0, _sum_xx = 0.0; for (int r = 0; r < int(Points.Rows()); r++) { _sum_x += Points[r][0]; _sum_y += Points[r][1]; _sum_xy += (Points[r][0] * Points[r][1]); _sum_xx += (Points[r][0] * Points[r][0]); } Slope = ((Points.Rows() * _sum_xy) - (_sum_x * _sum_y)) / ((Points.Rows() * _sum_xx) - (_sum_x * _sum_x)); Intercept = (_sum_y - (Slope * _sum_x)) / Points.Rows(); }
線形回帰は,与えられた点の集合のy = mx + c方程式の主要な係数を求めるプロセスです。提供された係数は、これらの入力x-y点の最良適応線に対する方程式を定義します。この式が重要なのは、このベストフィットの直線の傾きがハースト指数であり、y切片が定数Cとなるからです。このため、LinearRegression関数は、ハースト指数とC定数プレースホルダーとして機能する2 つのdouble値を参照入力として受け取り、Hurst関数と同様にvoidを返します。
この記事の主な目的はハースト指数を計算することですが、すでに述べたように、このプロセスから得られる出力の一部はC定数です。では、このC定数は何のためにあるのでしょうか。データサンプルのばらつきを表す指標です。2つの株式の価格系列が同じハースト指数を持ちますが、C定数は異なり、一方はCが7で、もう一方はCが21であるというシナリオを考えてみましょう。
すなわち、両者のハースト指数が0.5以下であれば、両者の株式は平均的に大きく回帰する傾向があり、0.5以上であれば、両者は長期的に大きくトレンドする傾向があります。しかし、同じような値動きであるにもかかわらず、両者のC定数は明らかに異なるリスクプロファイルを示しています。これは、C定数がボラティリティの代用として理解できるからです。C定数が大きい株式は、C定数が小さい株式とは異なり、その平均値における価格変動幅が大きくなります。このことは、他のすべての要因が一定であるにもかかわらず、2つの株式で異なるポジションサイジング体制を意味する可能性があります。
シグナルクラスへのコンパイル
生成されたハースト指数を使用して、カスタムシグナルクラス内の取引銘柄のロングとショートの条件を決定します。ハースト指数は非常に長期的なトレンドを捉えるものであり、そのため定義上、サンプル数が無限大になるほど精度が高くなる傾向があります。しかし、実用的な目的のためには、過去の証券価格の明確な規模から測定する必要があります。ロング/ショート条件を評価する際に、2つの異なる移動平均のうちの1つを検討するため、ハースト指数の計算に使用される明確な履歴サイズは、これら2つの平均の計算に使用される2つの期間の合計とみなされます。
なぜなら、すでに述べたように、データサンプル期間が長ければ長いほど、ハースト指数は定義上、より信頼性が高くなるからです。したがって、読者は、自分の見通しにより代表的なヒストリーサイズを得るために、必要に応じてこれを修正することができます。いつものように、完全なソースコードを添付します。そこで、それぞれの条件関数(ロングとショート)について、まず、データサンプルの大きさまで、終値をベクトルにコピーします。データのサンプルサイズは、長期と短期の合計です。
これが終わったら、Hurst関数を呼び出してハースト指数を計算し、返された値を評価して0.5と比較します。この実装のバリエーションとして、0.5以上の値と0.5未満の値に閾値を追加し、エントリポイントや決定ポイントを絞ることもできます。ハーストが0.5以上であれば、持続性があり、したがって、長期的な条件として、低速期(長期)の移動平均を上回っているかどうかを確認します。もしそうなら、強気ポジションを示す可能性があります。同様に、ショートの場合は、遅行移動平均線を下回っているかどうかを確認し、下回っていれば、ショートポジションを持つことになります。
ハースト指数が0.5を下回る場合、レンジ相場または平均回帰相場にあることを意味します。この場合、現在の買値を高速移動平均と比較します。ロングポジションの場合、価格が高速移動平均線より下にあれば強気ポジションを示し、逆にショートポジションの場合、価格が高速移動平均線より上にあればショートポジションの開始を示します。この2つの条件の実装を以下に紹介します。
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalHurst::LongCondition(void) { int result = 0; vector _data; if(_data.CopyRates(m_symbol.Name(), m_period, 8, 0, m_fast_period + m_slow_period)) { double _hurst = 0.0, _c = 0.0; Hurst(_data, _hurst, _c); vector _ma; if(_hurst > 0.5) { if(_ma.CopyRates(m_symbol.Name(), m_period, 8, 0, m_slow_period)) { if(m_symbol.Bid() > _ma.Mean()) { result = int(round(100.0 * ((m_symbol.Bid() - _ma.Mean())/(fabs(m_symbol.Bid() - _ma.Mean()) + fabs(_ma.Max()-_ma.Min()))))); } } } else if(_hurst < 0.5) { if(_ma.CopyRates(m_symbol.Name(), m_period, 8, 0, m_fast_period)) { if(m_symbol.Bid() < _ma.Mean()) { result = int(round(100.0 * ((_ma.Mean() - m_symbol.Bid())/(fabs(m_symbol.Bid() - _ma.Mean()) + fabs(_ma.Max()-_ma.Min()))))); } } } } return(result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalHurst::ShortCondition(void) { int result = 0; vector _data; if(_data.CopyRates(m_symbol.Name(), m_period, 8, 0, m_fast_period + m_slow_period)) { double _hurst = 0.0, _c = 0.0; Hurst(_data, _hurst, _c); vector _ma; if(_hurst > 0.5) { if(_ma.CopyRates(m_symbol.Name(), m_period, 8, 0, m_slow_period)) { if(m_symbol.Bid() < _ma.Mean()) { result = int(round(100.0 * ((_ma.Mean() - m_symbol.Bid())/(fabs(m_symbol.Bid() - _ma.Mean()) + fabs(_ma.Max()-_ma.Min()))))); } } } else if(_hurst < 0.5) { if(_ma.CopyRates(m_symbol.Name(), m_period, 8, 0, m_fast_period)) { if(m_symbol.Bid() > _ma.Mean()) { result = int(round(100.0 * ((m_symbol.Bid() - _ma.Mean())/(fabs(m_symbol.Bid() - _ma.Mean()) + fabs(_ma.Max()-_ma.Min()))))); } } } } return(result); }
戦略テストとレポート
GBPCHFペアの4時間足で2023年のテストをおこない、以下の結果を得ました:


上記のテストでは、4時間の時間枠で多くの取引はおこなわれておらず、これは判別可能なEAを指し示す良い兆候である可能性があります。ただし、EAの有効性について何らかの決定を下す前に、常に長期間にわたるテスト、特に前方歩行でのテストが必須となります。
コントロールとしての生の自己相関
ハースト指数は、自己相関指標として機能することで、系列が永続的な特徴(0.5以上の値)を持つか、反永続的な特徴(0.5未満の値)を持つかを評価できると主張しています。しかし、この指数を計算する労力をかけずに、単純にデータ系列の相関関係を測定し、相関関係を実際に測定した結果を市場の状況を評価するために使用したとしたら、EAのパフォーマンスはどのように変わるでしょうか。
このようなカスタムシグナルクラスは、予想されるように関数が少なく、まず単純に長い(遅い)平均化期間にわたって正の相関があるかどうかを評価します。このような正の相関がある場合、この遅い期間の移動平均は、この平均より上の価格が強気で、下の価格が弱気であるトレンドフォローの設定を評価するために使用されます。しかし、より長い期間で正の相関が存在しない場合は、より短い(より速い)平均化期間で負の相関を求めます。この場合、移動平均線より下なら強気、上なら弱気となるような、平均回帰の設定を探すことになります。買い条件と売り条件のコードは以下の通りです。
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalAC::LongCondition(void) { int result = 0; vector _new,_old; if(_new.CopyRates(m_symbol.Name(), m_period, 8, 0, m_slow_period) && _old.CopyRates(m_symbol.Name(), m_period, 8, m_slow_period, m_slow_period)) { vector _ma; if(_new.CorrCoef(_old) >= m_threshold) { if(_ma.CopyRates(m_symbol.Name(), m_period, 8, 0, m_slow_period)) { if(m_symbol.Bid() > _ma.Mean()) { result = int(round(100.0 * ((m_symbol.Bid() - _ma.Mean())/(fabs(m_symbol.Bid() - _ma.Mean()) + fabs(_ma.Max()-_ma.Min()))))); } } } else if(_new.CopyRates(m_symbol.Name(), m_period, 8, 0, m_fast_period) && _old.CopyRates(m_symbol.Name(), m_period, 8, m_fast_period, m_fast_period)) { if(_new.CorrCoef(_old) <= -m_threshold) { if(_ma.CopyRates(m_symbol.Name(), m_period, 8, 0, m_fast_period)) { if(m_symbol.Bid() < _ma.Mean()) { result = int(round(100.0 * ((_ma.Mean() - m_symbol.Bid())/(fabs(m_symbol.Bid() - _ma.Mean()) + fabs(_ma.Max()-_ma.Min()))))); } } } } } return(result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalAC::ShortCondition(void) { int result = 0; vector _new,_old; if(_new.CopyRates(m_symbol.Name(), m_period, 8, 0, m_slow_period) && _old.CopyRates(m_symbol.Name(), m_period, 8, m_slow_period, m_slow_period)) { vector _ma; if(_new.CorrCoef(_old) >= m_threshold) { if(_ma.CopyRates(m_symbol.Name(), m_period, 8, 0, m_slow_period)) { if(m_symbol.Bid() < _ma.Mean()) { result = int(round(100.0 * ((_ma.Mean() - m_symbol.Bid())/(fabs(m_symbol.Bid() - _ma.Mean()) + fabs(_ma.Max()-_ma.Min()))))); } } } else if(_new.CopyRates(m_symbol.Name(), m_period, 8, 0, m_fast_period) && _old.CopyRates(m_symbol.Name(), m_period, 8, m_fast_period, m_fast_period)) { if(_new.CorrCoef(_old) <= -m_threshold) { if(_ma.CopyRates(m_symbol.Name(), m_period, 8, 0, m_fast_period)) { if(m_symbol.Bid() > _ma.Mean()) { result = int(round(100.0 * ((m_symbol.Bid() - _ma.Mean())/(fabs(m_symbol.Bid() - _ma.Mean()) + fabs(_ma.Max()-_ma.Min()))))); } } } } } return(result); }
同じペアのGBPCHFについて、4時間足で2023年についてほぼ同様のテストをおこない、最良の結果を以下に示します。


このシグナルとハースト指数シグナルの間には、明らかに性能の飛躍や違いがあります。
結論
ハースト指数は、前世紀の初めに、大量の水位データセットを利用して、ナイル川の水位変動を予測するためのツールとして開発されました。それ以来、この指標は金融時系列分析など、幅広い用途で活用されています。この記事でカスタムシグナルクラスを作成するにあたって、トレンド相場と平均回帰相場をより正確に区別するために、時系列指数を移動平均線と組み合わせました。
先に実施した最初のテストでは一定のポテンシャルが示されたものの、まだ生の自己相関信号と比較した際に、その使用を正当化するには疑問が残ります。この手法は計算負荷が高く、取引を過度にフィルタリングしてしまい、最良の実行でもドローダウンが大きすぎます。特に、比較的小さいテストウィンドウでの結果であることを考えると、これは懸念材料です。いつもと同じように、独自にテストをおこなえば、より有望な結果が得られる可能性があります。添付されたソースコードのEAへのアセンブリとコンパイルについては、こちらおよび こちらのガイドラインに従ってください。これらのさらなるテストには、ブローカーのリアルティックデータを用い、健全な年数にわたっておこなうことをお勧めします。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/15222
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索