
知っておくべきMQL5ウィザードのテクニック(第28回):学習率に関する入門書によるGANの再検討
はじめに
以前の記事で検討したニューラルネットワークの形式を、特定のハイパーパラメータに焦点を当てて再検討します。学習率(英語)です。生成的敵対的ネットワークとは、2つ1組で動作するニューラルネットワークのことで、一方のネットワークは伝統的に真実を見分けるように訓練され、もう一方のネットワークは偽画像と実際の画像を区別するように訓練されます。この二重性は、伝統的に訓練されたネットワーク(前者)が後者を騙そうとしていることを意味します。これは事実ですが、2つのネットワークは「同じチーム」であり、両者を同時に訓練することで、最終的にはジェネレーターネットワークがトレーダーにとってより有用になります。この記事では、学習率に注目することで、訓練の過程を掘り下げていきます。
いつものように、この記事の目的は、シグナルクラス、トレーリングクラス、マネーマネージメントクラスなど、ライブラリにプリインストールされていないが、トレーダーの既存のストラテジーと何らかの形で互換性のあるものを紹介することです。特にMQL5ウィザードは、エキスパートアドバイザー(EA)の一般的な取引機能を最小限のコーディング要件でシームレスに組み立て、テストすることができます。ここから得られるのは、ウィザードアセンブリが容易にこれを可能にするため、組み立てられたEAとして独立して、あるいは他のウィザードクラスと並行してテストできるカスタムクラスです。ウィザードの組み立て工程を初めてご覧になる方は、こちらおよび こちらの記事をご参照ください。
そこで本稿では、単純な生成的敵対的ネットワークにおいて、学習率がパフォーマンスに与える影響があるのかどうかを検証します。「パフォーマンス」そのものは非常に主観的な言葉であり、厳密に言えば、テストはこれらの記事で検討しているよりもはるかに長い期間にわたって実施されるべきです。従って、私たちの目的からすれば、「パフォーマンス」とは、回収率を考慮した上での総利益ということになります。これから検討する学習率タイプ(またはスケジュール)にはいくつかあります。特にそれらが他の手法とは明らかに異なる場合、すべてについて徹底的なテストをおこなうよう努力します。
この記事の形式は、これまでの記事とは多少異なります。それぞれの学習率形式を提示する際には、その戦略テストレポートが添付されます。これは、これまでのように記事の最後、結論の前にレポートが掲載されていたのとは少し対照的です。つまりこれは、学習率が機械学習アルゴリズム、より具体的にはGANの性能に及ぼす可能性の有無について、オープンマインドを保つ探索的な形式なのです。私たちは複数の学習率の種類と形式を見ているため、統一されたテスト指標を持つことが重要です。すべての学習率の種類を通して単一の銘柄、時間枠、テスト期間を使用するのはそのためです。
これに基づいて、銘柄はEURJPY、時間枠は日足、テスト期間は2023年とします。GANでテストしており、そのデフォルトのアーキテクチャが要因であることは確かです。各層の数やサイズに関して、より精巧な設計が最重要であるという議論は常にありますが、それらはすべて重要な考慮事項である一方で、ここで注目するのは学習率です。そのため、GANは1つの隠れ層を含む3層だけの比較的シンプルなものとします。それぞれの全体的なサイズは、入力から出力に向かって5-8-1となります。これらの設定は添付のコードに示されており、読者が別の設定を使用したい場合は簡単に変更することができます。
買い条件と売り条件を生成するために、MQL5におけるカスタムシグナルクラスとしてのGANの使用を検討した前述の記事でおこなったのと同じ方法で、すべての異なる学習率形式を実装しています。そのソースコードはいつものように添付されていますが、念のため以下に紹介します。
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalCGAN::LongCondition(void) { int result = 0; double _gen_out = 0.0; bool _dis_out = false; GetOutput(_gen_out, _dis_out); _gen_out *= 100.0; if(_dis_out && _gen_out > 50.0) { result = int(_gen_out); } //printf(__FUNCSIG__ + " generator output is: %.5f, which is backed by discriminator as: %s", _gen_out, string(_dis_out));return(0); return(result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalCGAN::ShortCondition(void) { int result = 0; double _gen_out = 0.0; bool _dis_out = false; GetOutput(_gen_out, _dis_out); _gen_out *= 100.0; if(_dis_out && _gen_out < 50.0) { result = int(fabs(_gen_out)); } //printf(__FUNCSIG__ + " generator output is: %.5f, which is backed by discriminator as: %s", _gen_out, string(_dis_out));return(0); return(result); }
固定学習率
まず初めに、機械学習アルゴリズムを初めて使う人の多くが使うのは、最もシンプルな固定学習率でしょう。アルゴリズムの重みとバイアスが学習反復ごとに調整される標準的な基準で、異なる学習エポックを通してまったく変わりません。
固定学習率の利点は、そのシンプルさにあります。すべてのエポックを通じて使用する浮動小数点値が1つであるため、実装が非常に簡単で、訓練のダイナミクスをより予測しやすくなり、プロセス全体の理解やデバッグに役立ちます。加えて、これは再現性を確保します。多くのニューラルネットワーク、特にランダムな重みで初期化されたニューラルネットワークでは、与えられたテスト実行の結果は再現できないことがあります。私たちの場合、すべての異なる学習率形式を通して、標準的な初期重み0.1と初期バイアス0.01を使用しています。このような値を固定することで、テストの結果を再現しやすくなります。
また、固定学習率は、他の多くの学習率形式の場合のように、学習率が低下したり、後期に減少したりすることがないため、初期の訓練過程における安定性をもたらします。テスト実行の後半に遭遇したデータは、最も古いデータと同程度に重視されます。これにより、学習率ではない別のハイパーパラメータに対してネットワークを微調整する場合、ベンチマークや比較が容易におこなわれるようになります。これは例えば、ニューラルネットワークが使用する初期重みです。一定の学習率を持つことで、このような最適化探索はより迅速に意味のある結果を導き出すことができます。
固定学習率の主な問題は、最適な収束が得られにくいことです。訓練の際、勾配降下が極小値にはまり、最適に収束しないことが懸念されます。これは、理想的な固定学習率が確立される前に特に重要です。また、連続した訓練エポックに遭遇すると、「学習する」必要性が変わらないという一般的なコンセンサスに従った適応不良の可能性も議論されています。一般的な見方では、訓練の後半でパフォーマンスが低下する傾向があります
しかし、これらの長所と短所を踏まえて、2023年のEURJPYを日足で試算すると、以下のようになります。


ステップ減衰
次はステップ減衰学習率です。これは実際には固定学習率に近いですが、後続の各エポックで初期の固定学習率がどのように減少するかを制御する 2 つの追加パラメータのみを備えています。これはMQL5では以下のように実装されています。
if(m_learning_type == LEARNING_STEP_DECAY) { int _epoch_index = int(MathFloor((m_epochs - i) / m_decay_epoch_steps)); _learning_rate = m_learning_rate * pow(m_decay_rate, _epoch_index); }
そのため、各エポックでの学習率を決定するプロセスは2段階です。まず、エポックインデックスを取得する必要があります。これは単純に、訓練セッション中、エポックを通じてどの程度進んでいるかを測定する指標です。この値は、2番目の入力パラメータである「m_decay_epoch_steps」に大きく影響されます。ここのforループは、通常のようにインクリメントするのではなく、デクリメントしているため、総エポック数から現在のi値を引き、次にこの2番目の入力に対してMath-Floor除算を実行します。この結果を丸めた整数がエポックインデックスとなり、現在のエポックでの初期学習率をどれだけ下げる必要があるかを決定するために使われます。ステップサイズ(2番目の入力値)が5であれば、5エポックごとに学習率を下げます。ステップサイズが10であれば、10エポック後、といった具合です。
ステップ減衰の全体的な戦略は、最小値を超えないようにようにこの学習率を徐々に下げ、効率的に最適解に到達することです。初期学習の速さと後々の微調整のバランスの良さが特徴です。これは、損失ランドスケープにおける極小値や鞍点から脱出するのに役立ち、(固定学習率とは異なり)学習率の削減を通じてより良い汎化をもたらすことが多く、過剰学習を回避するのに効果があります。
2023年のEURJPYを日足で上記のように計算すると、以下のようになります。


指数関数的減衰
指数関数的減衰学習率は、ステップ減衰学習率とは異なり、学習率の減少がよりスムーズです。上記で、エポックインデックスが増加したとき、またはあらかじめ定義されたエポックステップ数の後にのみ、ステップ減衰学習率が減少することを見ました。指数関数的減衰の場合、学習率の低下は常に新しいエポックごとに起こります。これは以下の式で表されます。
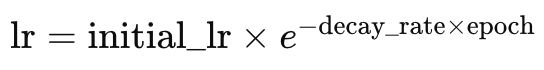
ここで
- lrは学習率
- initial_lrは初期学習率
- eはオイラー定数
- decay_rateとepochはそれぞれの名前
これはMQL5では次のようにコーディングされます。
else if(m_learning_type == LEARNING_EXPONENTIAL_DECAY) { _learning_rate = m_learning_rate * exp(-1.0 * m_decay_rate * (m_epochs - i + 1)); }
指数関数的減衰は、新しいエポックごとに減衰係数を乗じることで学習率を下げることができます。これにより、上記の段階的アプローチと比較して、より緩やかな学習率の低下が保証されます。漸進的なアプローチの利点は、学習率を下げるという一般的なアプローチと一致する傾向があります。これらはすでにステップ減衰法で共有されています。指数関数的減衰に欠けているのは、学習プロセスを不安定にする学習率の急激な低下の回避です。
2023年のEURJPYを日足で上記のようにテストすると、以下のような結果が得られます。


指数関数的減衰は、各エポックで学習率を修正することで、学習率をよりスムーズかつ緩やかに減少させることができます。しかし、すべての減少ステップが同じ大きさになるわけではありません。学習開始時の学習率の低下は著しく、学習が最後のエポックに進むにつれて減少幅は次第に小さくなっていきます。
多項式減衰
これも指数関数的減衰と同様、訓練が進むにつれて学習率が低下します。指数関数的減衰との主な違いは、多項式減衰はゆっくりと学習率を下げることから始まることです。訓練がプロセスの後半のエポックに近づくにつれて、減少率は最終的に増加します。これを式で表すと次のようになります。
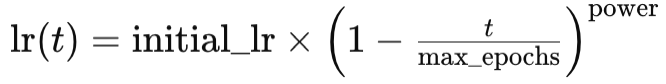
ここで
- lr(t)はエポックtにおける学習率
- initial_lrは初期学習率
- tはエポックのインデックス
- max_epochsとpowerはそれぞれ名前を表す
従って、実装は以下のようになります。
else if(m_learning_type == LEARNING_POLYNOMIAL_DECAY) { _learning_rate = m_learning_rate * pow(1.0 - ((m_epochs - i) / m_epochs), m_polynomial_power); }
多項式減衰では、シグナルクラスに「power」入力パラメータを導入します。すべての学習率形式は、入力パラメータで特定の学習率を選択できるように、ひとつのシグナルクラスファイルにまとめられています。このコードファイルは記事の下に添付されています。入力される多項式パワーは、上式に示すように、エポックに応じて学習率を低下させるために使用する係数への定数指数です。
多項式減衰、指数減衰、ステップ減衰はいずれも学習率を減少させる方法ですが、多項式減衰が他と異なる点は、訓練の終盤に学習率が急速に低下することです。この急速な減少により、学習率をできるだけ長く高く維持し、最終エポックに近づいた時点で大幅に減少させる「微調整」が可能となります。この微調整は、訓練プロセスに最適な多項式の次数を設定することで達成され、適切に設定されれば、より効果的な学習プロセスが期待できます。
多項式減衰の利点は、他の学習率減衰方法と同様に、漸進的かつスムーズな学習率の減少を提供する点です。学習率の微調整は、エポックを通じて理想的な学習率を決定することに加え、学習プロセスにかかる時間の制御も可能にします。多項式の次数を大きく設定すれば学習が速く進み、逆に小さくすれば学習速度が緩やかになります。
EURJPYの日足時間枠で2023年にかけてテストをおこなったところ、以下のような結果が得られました。


逆時間減衰
逆時間減衰はまた、時間減衰と呼ばれるものによって、エポックごとの学習率を低下させます。上記では、指数関数的減衰による学習率の急激な初期低下と、多項式減衰による学習率の緩慢な初期低下について検討しましたが、時間減衰は学習率をさらに緩やかに低下させるため、非常に大規模な学習データセットを扱う場合には多項式減衰よりも適しています。
逆時間減衰の公式はこうなります。
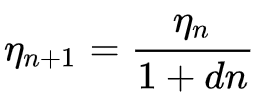
ここで
- ηn+1はエポックn+1における学習率
- ηn はエポックnにおける事前学習率
- dは減衰率
- nはエポックインデックス
MQL5では次のように実装しています。
else if(m_learning_type == LEARNING_INVERSE_TIME_DECAY) { _learning_rate = m_prior_learning_rate / (1.0 + (m_decay_rate * (m_epochs - i))); m_prior_learning_rate = _learning_rate; }
このアルゴリズムは、学習率の低下速度が非常に遅いため、非常に大きな訓練データセットに理想的です。すでに述べた利点のほとんどを他の学習率形式と共有しています。同じ銘柄、時間枠、テスト期間でテストした場合、他の学習率形式との比較結果を示すために、ここにテスト結果を掲載しました。完全なソースが添付されているので、より詳細なテストをおこなうために変更を加えてみてください。これまで使ってきた設定に従ってテストを行った結果、次のようになりました。


Cosine Annealing
また、Cosine Annealing率スケジューラーは、コサイン関数に従うことで、あらかじめ設定された最小値に向かって学習率を徐々に下げていきます。学習率削減の目標は上記の形式と似ていますが、cosine annealingでは目標の最小値があり、すべてのエポックが使い果たされるまで、最小学習率に達するたびにプロセスが再開され続けます。
その計算式は次のようになります。
![]()
ここで
- lr(t)はエポックtにおける学習率
- initial_lrは初期学習率
- tはエポックのインデックス
- Tは総エポック数
- min_lrは最小学習率
MQL5での実装は以下のようになります。
else if(m_learning_type == LEARNING_COSINE_ANNEALING) { _learning_rate = m_min_learning_rate + (0.5 * (m_learning_rate - m_min_learning_rate) * (1.0 + MathCos(((m_epochs - i) * M_PI) / m_epochs))); }
cosine annealingは、逆時間減衰よりも大規模なデータセットに適しています。逆時間減衰が学習率の大きな低下を最後の学習エポックに向けて十分に先送りするのに対し、cosine annealingは、あらかじめ設定された最小学習率に達すると、学習率を初期値に戻す「リセット」を可能にするからです。これは、「ウォームリスタート」と呼ばれる、あらかじめ設定された学習サイクルで学習率を初期値に戻す手法と似ているが異なります。
ウォームリスタートは、これまで考えてきたシングルバッチアプローチとは対照的に、各バッチがエポックに分割されるようなバッチ/サイクルが使用される、非常に大規模な学習シナリオに適しています。バッチを使用する場合、学習率のリセットまたは元の値への復元は、所定のバッチの終了時に自動的に実行されます。
cosine annealingのシングルバッチ形式でテストした結果、次のようなレポートが得られました。


さらに、cosine annealingでは、最小学習率という追加入力パラメータがあるため、微調整も可能です。この率に割り当てる値によって、訓練の質と徹底度をコントロールできるだけでなく、全エポックを通しての訓練の持続時間を決定することもできます。つまり、扱う訓練データの大きさによっては、これは非常に大きな意味を持ちます。
この目的のために、cosine annealingは探索と利用のバランスを提供するとよく議論されます。探索とは、特に最小学習率の調整と微調整を通じて、理想的な学習率を探索することです。一方、探索とは、最もよく知られている学習率を利用しながら、最適なネットワークの重みとバイアスを採取することを指します。その結果、 一般化(英語)が向上する傾向にあります。
周期的学習率
周期的学習率は、ここまで見てきた形式とは異なり、学習率を上げることから始め、最終的には最小値に戻します。これは周期的なパターンで起こります。したがって、訓練は常に各サイクルで最小の学習率から開始されます。それは以下の公式によって導かれます。
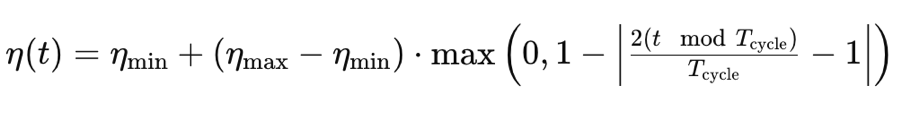
ここで
- η(t) はエポック t における学習率
- ηminは最小学習率
- ηmaxは最大学習率
- Tcycleは、あるバッチまたはサイクルにおけるエポックの総数(テストはシングルサイクルのみ)
- (t modTcycle)は、1サイクルのエポック数をエポックのインデックスで割った余り。この値に2を掛ける。
MQL5では次のように実装しています。
else if(m_learning_type == LEARNING_CYCLICAL) { double _x = fabs(((2.0 * fmod(m_epochs - i, m_epochs))/m_epochs) - 1.0); _learning_rate = m_min_learning_rate + ((m_learning_rate - m_min_learning_rate) * fmax(0.0, (1.0 - _x))); }
この学習率で、上記で使用したのと同じ銘柄、時間枠、テスト期間の設定にこだわりながらテスト実行をおこなうと、このような結果が得られます。


「triangular-2」と呼ばれる周期的学習率の別の実装があり、ここでも最初は学習率が増加し、その後最小になります。ただし、ここで上で見てきたものとの違いは、最大学習率の値が、各サイクルごとに減少し続けることです。
次回は、この学習率の形式と、それ自体がさまざまな形式を備えているため比較的幅広い適応学習率を含む追加形式、ウォームリスタート、シングルサイクルレートを検討します。
結論
結論として、生成的敵対的ネットワークのような機械学習アルゴリズムにおいて、学習率だけを変更することで、いかに無数の異なる結果が得られるかを見てきました。明らかに、学習率は非常に敏感なハイパーパラメータです。学習率のように単純すぎると思われるものの主な目的は、より具体的で求められているネットワークの重みとバイアスに到達することですが、一定の時間とリソース内でテストする場合、これらの重みとバイアスに到達するために選択されるパスは、使用する学習率に応じて大幅に異なる可能性があることは明らかです。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/15349
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索