
ニューラルネットワークが簡単に(第59回):コントロールの二分法(DoC)

はじめに
金融市場業界は複雑で多面的な環境です。あらゆる出来事や行動は、経済の基本的なプロセスに根ざしています。ある出来事の理由は、ニュース、地政学的な出来事、さまざまな技術的側面、その他多くの要因に見出すことができます。多くの場合、このような依存関係は起こってから気づくものです。市場の状況を分析しながら、私たちが観察しているのはこれらの要因のごく一部だけです。一般的に、金融市場は分析するにはかなり難しい環境です。しかし、それでもなお、主要な傾向を検出できる最も重要なツールのいくつかを強調します。その他の要因は、環境の確率に起因します。
このような複雑な環境において、強化学習は金融市場における戦略開発のための強力なツールとなります。しかし、Decision Transformerのような既存の手法は、確率の高い環境では十分な適応力を発揮できない可能性があります。これは、前回の記事の実践編で観察したことです。
覚えていらっしゃるかもしれませんが、従来の方法とは異なり、Decision Transformerは、望ましい報酬の自己回帰モデルの文脈で行動シーケンスをモデル化します。モデルを訓練する間に、一連の状態、行動、望ましい報酬、そして環境から得られる実際の結果の間に関係が構築されます。しかし、多くの無作為な要因が、訓練された戦略と望ましい未来の結果との間に不一致をもたらす可能性があります。
強化学習など多くの手法が同様の問題に直面しています。2022年10月、グーグルチームはこの問題を解決する選択肢の1つとして、Dichotomy of Controlという方法を提示しました。
1. DoCメソッドの基本
DoC(dichotomy of control、コントロールの二分法)は、ストイシズムの論理的基礎です。それが意味しているのは、私たちの周りに存在するすべてのものは、2つの部分に分けることができるという理解です。最初の部分は私たちに従うもので、完全に私たちのコントロール下にあります。私たちは2つ目の部分をコントロールすることはできません。私たちの行動に関係なく、出来事は起こります。
私たちは前者の分野に取り組みながら、後者の分野を当然のこととして考えています。
「Dichotomy of Control」の著者たちも、同様の仮定をアルゴリズムに組み込んでいます。DoCによって、戦略のコントロール下にあるもの(行動方針)とコントロールできないもの(環境確率)を分けることができます。
しかし、その方法を研究する前に、DTでどのように軌跡を表現したかを思い出してください。
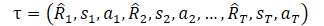
ここでR1(Return to go)は私たちの願望を表し、最初のS0状態とは関係ありません。訓練されたモデルは、訓練セットで望ましい結果をもたらした行動を選択します。しかし、現在の状態から望みの報酬を得られる確率は非常に小さく、エージェントの行動は最適とは程遠いものになるかもしれません。
さあ、目を見開いて世界を見ましょう。この文脈では、「Return to go」はエージェントに行動戦略を選択するよう指示することです。階層モデルのスキルやGCRLの目標指定に似ていると思いませんか?おそらく同じような考えがDoC法の作者たちを襲い、ある種の隠された状態z(τ)を使用することを提案したのでしょう。しかし、ご存知のように、概念を置き換えても本質は変わりません。z(τ)の潜在状態を表現するために訓練モデルが導入されます。
この手法の著者の重要な観測は、zには環境確率に関連する情報が含まれてはならないということです。この履歴には、前回の履歴の時点では未知の、未来のRtとSt+1に関する情報は含まれていないはずです。したがって、zと各RtとSt+1のペアとの間の相互情報の条件付き制約が、未来のゴールに追加されます。 この相互情報制約を満たすために、コントラスト訓練法を用います。
次に、fエネルギー関数をパラメータとする条件付き分布ω(rt|τ0:t-1,st,at)を導入します。
これをラグランジュ比によって組み合わせると、DoCの最終目標を最小化することによってπとz(τ)を訓練することができます。
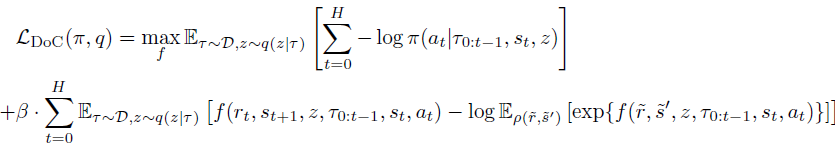
Decision Transformer法に適用する場合、DoCで訓練された方策は適切なz条件を必要とします。期待報酬の高いZを選択するために、この方法の著者はこう提案します。
- Z値の候補を多数選択する
- それぞれのzの値に対する期待報酬を見積もる
- 期待報酬が最も高いzを選択し、方策に渡す
運用段階でこのような手順を確保するため、メソッドの定式化には2つの要素が追加されています。まず、事前分布p(z|s0)から多数のz値を選択します。第二に、V(z)値関数で、これは潜在的なz値をランク付けするのに使用されます。これらのコンポーネントは、以下の目的を最小化することによって訓練されます。
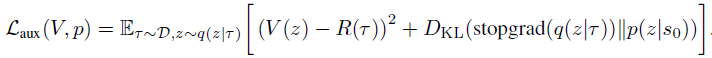
事前分布に対するqの正則化を避けるため、pを訓練する際にq(z|τ)にストップグラディエントを使用することに注意。
「Dichotomy of Control:WhatYouCanControlfromWhatYouCannot"は、様々な確率的環境において、提案された方法が非常に優れていることを示す多くの例を取り上げています。
これはなかなか興味深い点で、私はこのアプローチで問題を解決できる可能性を実際に試してみようと思います。
2.MQL5を使用した実装
この記事の実践編では、MQL5を使用したコントロールの二分法アルゴリズムの実装について考えます。直ちに、問題の実装が提案された方法の個人的な解釈であるという事実に注意を喚起したいと思います。場合によっては、本来の解答からかなりかけ離れてしまうこともあるでしょう。
まず第一に、この実装は前回の記事のプログラムの論理的な続きです。我々は、モデルのパフォーマンスを最適化し、その効率を向上させるために、以前に作成されたDTコードに提案されたメカニズムを実装します。
さらに、基本的な考え方を維持しながらも、DoCアルゴリズムを少し簡略化してみます。
前述したように、この方法の著者は、RTGの代わりに潜在的な状態を導入しています。操作中、このような潜在状態のあるパッケージが事前分布p(z|s0)から標本化されます。これらの潜在状態は、その後V(z)値関数を用いて推定されます。実際には、訓練セットから最も類似した状態を抽出し、期待報酬が最も高い潜在表現を選択することを意味します。コントロール二分法の考え方に沿って、報酬の絶対値だけでなく、報酬を受け取る確率も考慮します。
当然ながら、毎回すべての訓練セットをやり直すわけではありません。その代わりに、訓練セットから対応する特徴を近似する、事前に訓練されたモデルを使用します。しかしいずれにせよ、多数の潜在表現を標本化してそれを推定するのは、かなり手間のかかる作業です。どうにか簡略化できないでしょうか。
これらの実体の本質を見てみましょう。意思決定Transformerコンテキストにおけるz潜在表現は、期待報酬です。つまり、価値関数V(z)は、zの潜在状態そのものを反映している可能性があります。価値関数をクラスとして除外し、潜在状態同士を直接比較することも考えられるが、ここではそのような措置はとりません。
これをさらに考えると、事前分布p(z|s0)は、特定の環境状態における特定の潜在的表現の使用の確率的分布として表すことができます。完全パラメータ化分位関数(FQF)を思い出してみましょう。確率分布と数量分布を組み合わせることができます。これが潜在表現生成モデルで使用するものです。
この解法によって、事前分布とコスト関数を組み合わせることができます。さらに、この方法であれば、潜在的な状態を一括して標本化し、それを推定することを避けることができます。
fエネルギー関数でパラメータ化されたω(rt|τ0:t-1,st,at)条件付き分布についても同様です。
どちらの場合も、潜在的な表現を生成していることに注意。リソースを節約するため、2つのモデルを作成し、1つを両方のケースで使用します。ここで、ω(rt|τ0:t-1,st,at)は軌道に依存することを忘れてはなりません。したがって、モデルを構築する際には、DTActorモデルと同様に自己回帰的な性質を考慮する必要があります。
両モデルのアーキテクチャは、CreateDescriptionsメソッドに記述されています。メソッドのパラメータには、モデルアーキテクチャを記述するための2つの動的配列へのポインタを渡します。モデルのアーキテクチャに大きな違いはないでしょう。しかし、彼らはまだ存在しています。だからこそ、共通のアーキテクチャではなく、2つの別々のアーキテクチャを作成するのです。まず、Actorモデルのアーキテクチャを作成します。前回の記事と同様に、ソースデータ層には環境状態の可変コンポーネント(1つのバーデータ)のみが含まれます。
bool CreateDescriptions(CArrayObj *agent, CArrayObj *rtg) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (NRewards + BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
次にバッチ正規化(batch normalization)層が登場し、生のソースデータを前処理します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
正規化されたデータは 埋め込み層を通過し、スタックに追加されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NActions,NRewards}; ArrayCopy(descr.windows,temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
スタックには、全分析期間のデータ埋め込みが含まれています。多頭でスパースなAttentionブロックを通過させます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count*5; descr.window = prev_wout; descr.step = 4; descr.window_out = 32; descr.layers = 8; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Attentionブロックの後、畳み込み層を使用してデータの次元を下げます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; }
次に、3つの全結合層からなる意思決定ブロックにデータを渡します。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
モデルの出力では、VAE潜在層を使用してエージェントの方策を確率的にします。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
以下は、潜在表現モデルのアーキテクチャの説明です。上述したように、このモデルのアーキテクチャは前回のものと非常によく似ています。しかし、分析するデータ量は少ないです。理論的な部分で示した説明からわかるように、条件付き分布関数ω(rt|τ0:t-1,st,at)は、現在の状態、エージェントの行動、以前の軌跡に基づいて潜在的な表現を生成します。その結果得られた潜在的な状態をエージェントの入力に供します。第2のモデルの入力には、潜在状態の大きさ分だけ少ないデータを供給します。
//--- RTG if(!rtg) { rtg = new CArrayObj(); if(!rtg) return false; } //--- rtg.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
生のソースデータもバッチ正規化層で一次処理を受けます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
次はデータの埋め込みです。ここで、ソースデータの構造にも変化が見られます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NActions}; ArrayCopy(descr.windows,temp); } prev_wout = descr.window_out = EmbeddingSize; if(!rtg.Add(descr)) { delete descr; return false; }
以下、スパースなAttentionブロックの構造を繰り返します。シーケンス内の分析要素数の減少に注意を払います。エージェントは各バーに5つのエンティティを分析しましたが、このモデルでは4つしかありません。この時点で各バーの要素数を手動で制御するのを避けるために、前の手順で、埋め込み層のソースデータのウィンドウの配列のサイズを別の変数に設定することができます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count=descr.count = prev_count*4; descr.window = prev_wout; descr.step = 4; descr.window_out = 32; descr.layers = 8; descr.probability = Sparse; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
前のモデルと同様に、スパースなAttention層の後に、畳み込み層を使用して分析データの次元を減らします。そして、受信したデータを意思決定ブロックに送信します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
さて、決定ブロックの出力では、上述したように、完全にパラメータ化された分位関数の層を使用します。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NRewards; descr.window_out = 32; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- return true; }
モデルのアーキテクチャを説明した後、環境とのインタラクションのためのEAと、モデル「\DoC\Research.mq5」を訓練するための一次データ収集の作業に移ります。二分化制御法を用いることの特徴は、訓練データを収集する際にも顕著に現れます。これまで同様のEAでは、エージェントモデルのみを使用し、他のモデルは訓練段階でのみ接続していたが、今回は、一次データの収集から訓練済みモデルのテストまで、すべての段階で両方のモデルを使用します。結局のところ、2つ目のモデルによって生成された潜在状態は、エージェントの初期データの一部です。
ここでは、EAのコード全体を詳細に検討することはしません。その手法のほとんどは、以前の記事から変わることなく受け継がれています。主なデータ収集処理が配置されているOnTickティック処理メソッドにだけ注目してみましょう。
手法の最初に、いつものように、新しいバーのオープニングイベントの発生を確認し、必要に応じて、価格の動きと分析指標の指標の履歴データを更新します。
私たちのEAのすべての操作は、新しいバーが開いたときにのみ実行されることを忘れないでください。私たちのモデルのアルゴリズムは、各ティックの変化を制御していません。すべての訓練済みモデルは、H1時間枠の履歴データで動作します。しかし、時間枠の選択は純粋に主観的な決定であり、モデルアーキテクチャによって制限されるものではありません。私たちが遵守しなければならないのは、同じ時間枠で、同じ器械を使用して、モデルの訓練と操作をおこなうという条件だけです。以前に別の時間枠および/または別の金融商品で訓練したモデルを使用する前に、対象の時間枠および金融商品で追加訓練する必要があります。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
次に、ソースデータバッファを準備します。まず、銘柄の値動きの履歴データと分析指標のパラメータを設定します。
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
次に、現在の口座状況と未決済ポジションに関する情報を追加します。
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
ここではタイムスタンプも追加します。
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
そしてエージェントの最後の行動が、現在の環境状態をもたらしました。最初のバーを処理するとき、このベクトルはゼロ値で満たされます。
//--- Prev action
bState.AddArray(AgentResult);
次に、エージェントにRTGという形で目標指定を追加します。しかし、DoCアルゴリズムの中では、まだ潜在状態を生成しなければなりません。しかし、収集されたデータは潜在状態生成モデルが機能するのに十分なものであり、我々はそれを通してフォワードパスを実行します。
//--- Return to go if(!RTG.feedForward(GetPointer(bState))) return;
モデルのフォワードパスに成功したら、結果の潜在表現を読み込み、ソースデータバッファに追加します。
RTG.getResults(Result); bState.AddArray(Result);
この時点で、エージェントモデルの入力データの完全なパッケージが生成され、前に学習した方策に従って最適な行動を生成するためにフォワードパス法を呼び出すことができます。いつものことですが、作戦の実行をコントロールすることを忘れてはなりません。
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
ここで現在のバーでのモデルの仕事は終わり、環境との相互作用が始まります。まず、エージェントの作業結果を前処理し、復号化します。以前の記事では、一方向にのみオープンポジションがあると定義した。したがって、まず最初にすることは、エージェントの結果から出来高デルタを決定することです。その差額を、最大出来高のある方向に取っておきます。第二の方向性は、作戦量をリセットすることです。
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } AgentResult = temp;
次に、金融商品を購入するための取引の必要性を確認します。ここでは、エージェントによって生成された操作の量と停止レベルを確認します。取引量が可能な最小ポジションより少ない場合、またはストップロス/テイクプロフィットレベルが証券会社の最小要件を満たしていない場合、これはロングポジションを建てるべきでないシグナルです。この時点で、以前に建てたロングポジションがあればすべて決済します。
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
エージェントの決定により、ロングポジションを持つ必要がある場合、口座の現状に応じてオプションが可能です。
- ポジションがすでにオープンしており、その出来高がエージェントによって指定された出来高を超える場合、必要に応じて残りのポジションのストップレベルを調整しながら、過剰な出来高をクローズします。
- オープンポジションのレベルは、エージェントによって指定されたレベルと同じです。
- オープンポジションがないか、その出来高が指定より少ない-足りない出来高をオープンし、ストップレベルを調整します。
else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
ショートポジションについても同様の操作を繰り返します。
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
環境と相互作用した後、私たちがしなければならないのは、それまでの操作の結果をデジタル化し、そのデータを経験再生バッファに保存することだけです。
//--- int shift=BarDescr*(NBarInPattern-1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift+1]-1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
これで、環境と相互作用し、訓練データ例を収集するためのEAに関する私たちの研究は終わりです。EAの完全なコードとそのすべての機能は添付ファイルにあります。
モデル訓練用EA「˶DoCStudy.mq5」に移ります。OnInitEAの初期化メソッドでは、まず訓練セットのロードを試みます。オフラインでモデルを訓練するため、この訓練セットが唯一のデータ源となります。したがって、訓練データの読み込みにエラーがあった場合、EAをそれ以上実行しても意味がないので、プログラムの初期化エラーの結果を返します。まず、エラーIDとともにログにメッセージを送信します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
次の手順は、事前に訓練されたモデルをロードすることです。存在しない場合は、新しいモデルが作成され、初期化されます。
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTG.Load(FileName + "RTG.nnw", dtStudied, true)) { Print("Init new models"); CArrayObj *agent = new CArrayObj(); CArrayObj *rtg = new CArrayObj(); if(!CreateDescriptions(agent,rtg)) { delete agent; delete rtg; return INIT_FAILED; } if(!Agent.Create(agent) || !RTG.Create(rtg)) { delete agent; delete rtg; return INIT_FAILED; } delete agent; delete rtg; }
一方のモデルの読み込みにエラーがあった場合、両方のモデルが作成され、初期化されることにご注意ください。これはモデルの互換性を維持するためです。
次はモデルアーキテクチャを確認するブロックです。ここでは、オリジナルの層サイズと両モデルの結果の整合性を確認します。まず、エージェントのアーキテクチャを確認してください。
//--- Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the agent does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Agent doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; }
次に、潜在表現モデルの手順を繰り返します。
RTG.getResults(Result); if(Result.Total() != NRewards) { PrintFormat("The scope of the RTG does not match the rewards count (%d <> %d)", NRewards, Result.Total()); return INIT_FAILED; } //--- RTG.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of RTG doesn't match state description (%d <> %d)", Result.Total(), (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } RTG.SetUpdateTarget(1000000);
ここで注目すべきは、潜在表現モデルを訓練する過程で、FQFアーキテクチャが提供する目標モデルを使用する予定はないということです。そのため、すぐに目標モデルの更新周期をかなり大きく設定します。この方法によって、モデルを訓練する過程で無駄な操作を省くことができます。
以上の操作をすべて成功させたら、あとは訓練の開始イベントを生成し、EAの初期化メソッドを完了させるだけです。
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
OnDeinitEAの初期化解除メソッドに、潜在表現モデルの保存を追加します。オリンピックの格言「勝つことではなく、参加すること」とは異なり、私たちに必要なのは結果であって、訓練の過程ではありません。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Agent.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); RTG.Save(FileName + "RTG.nnw", TimeCurrent(), true); delete Result; }
Trainモデルの訓練方法に移りましょう。メソッド本体では、経験再生バッファにロードされた軌跡の数を決定し、ティックカウンタの現在の状態をローカル変数に保存して、モデル訓練プロセス中の時間を制御します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
さらに、前回同様、ループのシステムをアレンジします。外側のループは、モデルの訓練バッチ数をカウントします。その本体では、経験再生バッファから無作為に軌道を選択し、この軌道上の状態を訓練の開始点とします。すぐに両モデルのスタックをクリアし、エージェントの最後の行動のベクトルをリセットします。これらの操作は、自己回帰モデルを訓練する際に不可欠であり、モデルを訓練するために、軌道の新しいセグメントに移行するたびに、その前に実行しなければなりません。
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; } Actions = vector<float>::Zeros(NActions); Agent.Clear(); RTG.Clear();
自己回帰モデルを訓練する場合、訓練過程における操作の順序を維持することが重要な役割を果たします。この要件を満たすために、ネストされたループを作成します。このループでは、環境と相互作用する際に発生する時系列順に、モデルの入力に初期データを供給します。これにより、エージェントの行動を可能な限り正確に再現し、最適な訓練プロセスを構築することができます。
for(int state = i; state < MathMin(Buffer[tr].Total - 2,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
最も正しい訓練プロセスを設定するためには、スタックバッファがシリアルデータで完全に埋まっていることを確認する必要があります。結局のところ、このモデルがかなり長期間にわたって使用されれば、まさにこうなります。そのため、分析データのスタックの長さの3倍の反復回数の入れ子ループを設定します。しかし、保存された軌跡データ配列で境界外エラーが発生するのを防ぐため、軌跡の完了確認を追加します。
次に、ループの本体で、訓練例を収集する過程で記録されたデータの順序に従って、ソースデータバッファを埋めます。ここで注目すべきは、これらの処理は、 埋め込み層を記述する際にモデルアーキテクチャで指定したソースデータの構造に対応していなければならないということです。
まず、金融商品の値動きに関する履歴データと、分析対象の指標をバッファに追加します。データ収集の過程では、端末からデータをダウンロードしていたが、今回は経験再生バッファの対応する配列から、出来上がったデータを使用することができます。
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
口座状態の説明とタイムスタンプの作成は、訓練データ収集EAでほぼ完全に同様の処理を繰り返します。
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
次に、前の手順のエージェント行動ベクトルをバッファに追加し、潜在状態生成モデルのフォワードパス法を呼び出します。操作の結果を必ず確認します。
//--- Prev action State.AddArray(Actions); //--- Return to go if(!RTG.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
潜在状態生成モデルのフォワードパス法の実行に成功したら、すぐにそのパラメータを更新することができます。未来の報酬を予測するモデルを訓練します。このアプローチはDTアルゴリズムと矛盾せず、DoCアルゴリズムとも矛盾しません。
Result.AssignArray(Buffer[tr].States[state+1].rewards); if(!RTG.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
この段階で、結果ベクトルの誤差勾配の方向を調整するCAGrad法の使用を断念しました。これは、報酬の絶対値に加え、FQF層の深さにおける報酬の確率的分布を学習することに努めているためです。誤差勾配の方向を最適化するために目標値を調整すると、望ましい分布が歪む可能性があります。
潜在表現モデルのパラメータを最適化した後、エージェントの方策モデルの訓練に移ります。次の状態に移るために実際に受け取った報酬を初期データバッファに加えます。これはまさに、Decision Transformerエージェント方策を訓練するときにおこなったことです。さらに、エージェントの方策の訓練に関しては、Decision Transformerアルゴリズムを完全に繰り返します。結局のところ、Decision Transformerアルゴリズムとまったく同じように、個々の状態からの完了した行動と期待される報酬を比較するようにエージェントを訓練する必要があります。コントロールの二分法アルゴリズムの主な貢献は2つ目のモデルによって形成される潜在的表現の形で、正しい目標指定を作成することです。
//--- Policy Feed Forward State.AddArray(Buffer[tr].States[state+1].rewards); if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
次の手順は、Agentのモデルのパラメータを更新して、Agentの入力データで指定された実際の報酬をもたらす実際の行動を目標として生成することです。
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
今回はすでにCAGrad法を用いて誤差勾配ベクトルの方向を最適化し、モデルの収束速度を高めています。
両方のモデルのパラメータをうまく更新できたら、あとは訓練の進捗状況をユーザーに知らせ、次の訓練反復に移るだけです。
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "RTG", iter * 100.0 / (double)(Iterations), RTG.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
ループシステムのすべての反復が完了したら、訓練は完了したとみなします。チャートのコメント欄を消去します。訓練プロセスの結果をログに送信し、EAの終了を開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "RTG", RTG.getRecentAverageError()); ExpertRemove(); //--- }
以上で、モデル訓練用EA\DoC\Study.mq5」のレビューを終了します。この記事で使用されているすべてのプログラムの完全なコードを添付ファイルでご覧ください。訓練済みモデルをテストするためのEA「\DoC\Test.mq5」もあります。そのコードは、環境と相互作用し、訓練データを収集するためのEAをほぼ完全に再現しています。したがって、その方法について考察することに今はこだわりません。この記事のフォーラムスレッドで、ありとあらゆる質問に喜んでお答えします。
3.テスト
私たちのビジョンである「コントロールの二分法」アルゴリズムを実装したEAの作成作業を終えたので、その作業をテストする段階に進みます。この段階では、訓練データを収集し、モデルを訓練し、訓練サンプル期間外でその結果を確認します。モデルのテストに新しいデータを使用することで、モデルのテストを可能な限り実際の状況に近づけることができます。結局のところ、私たちの目標は、予見可能な未来において金融市場で実際に利益を生み出すことができるモデルを手に入れることです。
いつものように、モデルは2023年の最初の7ヶ月間の過去データで訓練されています。すべてのテストでは、最もボラティリティの高い金融商品の1つであるEURUSD H1を使用しています。すべての分析指標のパラメータは、連載当初から変更されておらず、デフォルトで使用されています。
モデル訓練プロセスは反復的で、訓練データの収集とモデルの訓練を何度か繰り返すことで構成されています。
訓練データの収集とモデルの訓練という一連の作業を繰り返す必要性を、改めて強調したいと思います。もちろん、まず訓練例の膨大なデータベースを収集し、その上でモデルを長時間訓練することもできますが、リソースには限りがあります。行動と相互報酬の空間を完全にカバーできるような例のデータベースを集めることは物理的に不可能です。さらに、行動の連続空間を扱います。それに加えて、研究対象の環境が非常に確率的であることも考慮しなければなりません。つまり、訓練の過程で、モデルが未探索の空間に行き着く可能性が高いということです。環境についての知識を深めるには、さらに相互作用を繰り返す必要があります。
もう1つの重要な点は、訓練データの最初の収集の間、各エージェントは無作為な方策を使用することです。これにより、可能な限り完全に環境を探索することができます。ご存知のように、強化学習の主な課題の1つは、探索と利用のバランスを見つけることです。明らかに、私たちはここで100%研究を見ています。環境と再び対話し、訓練データを収集する際、エージェントは事前に訓練された方策を使用します。研究対象は、訓練された方策の確率性の範囲に絞られます。
環境との相互作用を何度も繰り返せば繰り返すほど、モデルの確率領域の狭まり方は滑らかになります。タイムリーなフィードバックは、訓練の方向性を調整することができます。これにより、全域的な最大期待報酬を達成する可能性が高まります。
オフライン訓練の間隔が長い場合、モデルの行動の確率性を可能な限り低下させ、モデルの訓練の方向性を調整することなく、局所的な極限に達してしまう危険性があります。
また、私たちのモデルではスパースなAttentionブロックを使用しており、その訓練は二重に複雑で長いプロセスであることにも注意すべきです。まず、複雑な構造を持つSelf-Atentionブロックがあります。複雑な構造であればあるほど、長期にわたる入念な訓練が必要となります。
2つ目のポイントは、スパースなAttentionの使用です。したがって、ドロップアウトと同様に、すべてのニューロンが訓練の各反復で完全に使用されるわけではありません。その結果、ある瞬間には勾配がニューロンに届かず、訓練から脱落してしまいます。訓練によるニューロンの損失は、かなり確率的に起こります。モデルを完全に訓練するには、さらに多くの反復が必要です。
同時に、スパースなAttentionブロックを使用することで、訓練反復あたりの時間を短縮し、モデルをより柔軟にすることができます。
しかし、モデルの訓練とテストの結果に戻りましょう。訓練済みモデルをテストするために、2023年8月からの過去データを使用しました。EURUSD H1。8月は訓練期間の直後の月です。前述したように、このようにして、モデルの日常的な運用にできるだけ近い形でモデルをテストする条件を作り出します。このモデルをテストした結果、まだいくばくかの利益を上げることができました。覚えていらっしゃるかもしれませんが、同様の条件下で前回の記事では、Decision Transformerアルゴリズムを使用して訓練されたモデルは利益を上げることができありませんでした。DoCのアプローチを加えることで、ほとんど同じモデルを質的に異なるレベルに引き上げることができます。


しかし、利益を得ているにもかかわらず、モデルの結果は完璧ではありません。訓練済みモデルをテストする際のバランスグラフを見ると、次のような傾向が見られます。
- 月初めの10日間で、残高が20%ほど急増しました。
- 2番目の10年間では、達成された結果の領域における均衡のレベルに変動が見られます。不採算の時期が続くと、むしろ急上昇します。変動の振幅はバランスの10%に達します。
- 3番目の10年間は、不採算取引が続きます。
その結果、全訓練期間を通じて、約43%の利益を上げることができました。この場合、最大利益の取引は最大損失の2倍以上です。平均利益は平均損失より1/3高くなります。その結果、プロフィットファクターは1.01に固定され、リカバリーファクターは0.03となります。
DoCの原則を使用した場合と使用しなかった場合のモデルをテストした結果を比較すると、どちらの場合も月の最初の10日間の残高が急激に増加していることに気づきます。DoCアプローチの使用により、月の後半10日間も達成した結果を維持することができました。DoCを使用しなければ、すぐに採算の合わない取引が始まりました。
このことから、自己回帰的アプローチは、短期間ではありますが、かなり良い結果を得ることができるというのが私の主観的な意見です。同時に、DoCの使用は、いくつかの方法の修正によって有益な効果の期間を延ばすことができることを示しています。つまり、可能性と創造性の余地があるということです。
結論
この記事では、大きな可能性を秘めた非常に興味深いDoC(dichotomy of control、コントロールの二分法)アルゴリズムを紹介しました。このアルゴリズムは、確率的環境を扱う際のモデルの効率を改善する手段として、グーグルチームによって導入されました。DoCの主な原則は、観測可能なすべての要因と結果を、エージェントの方策に依存するものと依存しないものに分けることです。従って、モデルを訓練する際には、エージェントの行動に依存する要素には注意を向けず、環境の確率的な影響を考慮に入れて、結果を最大化することを目的とした方策を構築します。
この記事の一部として、以前に作成したDecision TransformerのモデルにDoCの原則を追加しました。その結果、テストサンプルにおけるモデルのパフォーマンスが向上しました。達成された結果は、まだ完璧とは言い難いです。しかし、前向きな変化ははっきりと目に見えており、「コントロールの二分法」の原則を実践することの効率性に気づくことができます。
リンク
- Decision Transformer:Reinforcement Learning via Sequence Modeling
- Dichotomy of Control:Separating What You Can Control from What You Cannot
- ニューラルネットワークが簡単に(第34回):完全にパラメータ化された分位数関数
- ニューラルネットワークが簡単に(第58回):Decision Transformer (DT)
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 5 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 6 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13551
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索