¿Qué alimentar a la entrada de la red neuronal? Tus ideas... - página 53
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Algunos resúmenes:
- La red neuronal sólo es aplicable a patrones estacionarios y estáticos que no tienen nada que ver con la fijación de precios
Mi imho, como yo lo veoEn series estacionarias todo funciona y entonces no hace falta MO para nada.
Bueno, todo está de vuelta a donde el hilo MO comenzó en 2016 - series no estacionarias no contienen características estadísticas estables. por lo que todos NS son sólo conjeturas.
Recuerdo que cuando escribí esto Dimitrievski correteaba por el hilo chillando y exigiendo que le enseñaran esto en los libros de texto....
En filas fijas todo funciona y entonces no necesitas MO en absoluto.
Bueno, todo está de vuelta a donde el hilo MO comenzó en 2016 - series no estacionarias no contienen características estadísticas estables. por lo tanto, todos NS son sólo conjeturas.
Recuerdo que cuando escribí esto Dimitrievski correteaba por el hilo chillando y exigiendo que le enseñaran esto en los libros de texto....
Los intentos de ajustar los pesos a la historia están destinados al fracaso. Entrenamiento, optimización. Da igual.
Cualquier intervención como el ajuste directo es un camino a ninguna parte. Y parece que la dirección correcta es el ajuste....
La base para ello: Cuando los datos de entrada toman la forma de 0 a 1 o -1 a 1, tenemos un cierto rango de posibles valores de números, que está limitado de arriba a abajo.
La parte inferior es el número de deci males. No podemos limitar y dejar los números reales como son, y la limitación será sólo técnica - es el número máximo de decimales según los terminales MT4/MT5. O podemos limitarlo manualmente, por ejemplo medianteNormalizeDouble o funciones de redondeo.
Y entonces tendremos un rango aún más estrecho. Como resultado, podemos simplemente buscar todos los valores en el optimizador, asignar uno de tres valores a cada número: abrir posición, cerrar, saltar, esperar, etc. Este método da una optimización absoluta o un reentrenamiento absoluto, o tiende a ellos.
Es decir, como en una tabla de aprendizaje Q, también registramos en ella el resultado de cada patrón, y luego elegimos qué hacer a continuación basándonos en las evaluaciones "pasadas". El resultado de este enfoque es una ruptura del equilibrio, una caída en picado del avance, etc.
Añadir ruido artificial reduciendo la arquitectura (reduciendo el número de neuronas, capas, etc.) u otros métodos no es más que una muletilla. Una especie de medida a medias. Y mirando el resultado del siguiente optimizador en el gráfico, donde un MLP normal era el sujeto de prueba, me rasqué la cabeza y no pude entender: ¿por qué?
¿Por qué un maldito MLP funciona mejor que el sobreentrenamiento absoluto? En la ciencia del aprendizaje automático existe una definición y un término para este fenómeno (cuando se produce un drenaje expresivo en el avance tras la sobreoptimización absoluta o el sobreentrenamiento). Pero no es de eso de lo que estamos hablando ahora.
Cuando un puto MLP abre una posición, una posición atascada, tardía, sobre servida, inadvertidamente se pierde ... las zonas de ciruela del gráfico. Es decir, la posición perdedora media 50/50 se solapa con la parte del gráfico donde podría haberse producido la ciruela si se hubiera abierto al revés. Una buena ciruela.
Y el modelo reentrenado está seguro de abrir allí. Es decir, MLP no sólo promedia los pesos para todas las situaciones en el gráfico, sino que esencialmente suaviza todos los casos de fuerza mayor, lo que hace que parezca más convincente en el forward. De ahí la conclusión: la optimización debe hacerse de tal manera que haya tanto promediado como reentrenado.
Es decir, todavía tenemos que extraer partes de rangos numéricos y etiquetarlos, pero al mismo tiempo - para echarlos a la caldera, manchar, difuminar. Desde fuera parece que estoy diciendo cosas obvias, pero yo, por ejemplo, ahora tengo MLP en una forma pervertida, y muestra mejores resultados que el MLP habitual, pero tiene un módulo casero de sobreentrenamiento absoluto parcial.
UPD
Como opción.
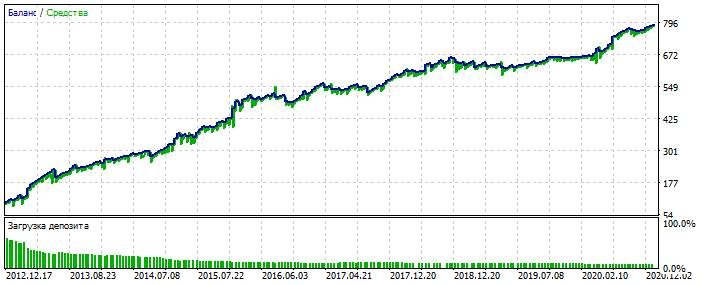
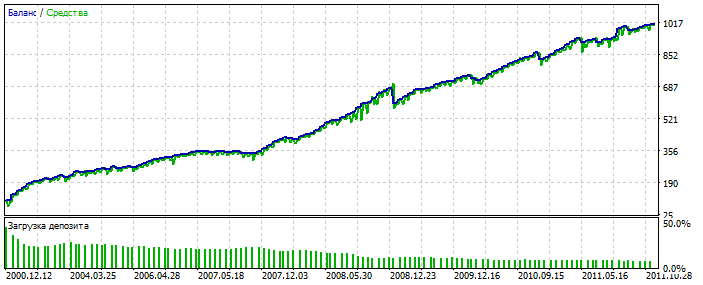
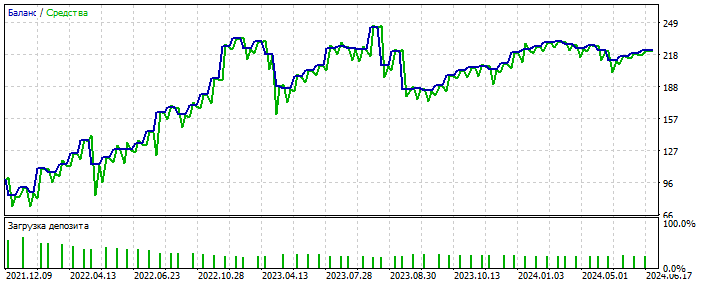
Sobreoptimización en el gráfico del EURUSD 2012-2021. Se puede ver que el gráfico de equilibrio está demasiado pulido, sin asimetría severa. Un signo de sobre-optimización.
Para MLP es con 3 neuronas. Bektest 2000-2012 Por alguna razón es más bonito que la optimización.
Probablemente ha detectado una anomalía. Forward 2021-2025 Las correcciones son pocas, pero aquí no estamos hablando de pulir el sistema. La esencia es importante. Y se puede llenar el vacío en el número de tratos añadiendo 28 pares de divisas más y el número de los primeros se incrementará en 20 veces. De nuevo - no es el punto.
Y lo más importante es que tal sistema no necesita datos cualitativos de entrada.
Funciona en casi todo: incrementos, osciladores, zigzags, patrones, precios, cualquiera. Sigo avanzando en esta dirección.
Y lo más importantees que un sistema de este tipo no necesita datos de entrada de alta calidad.
Funciona en casi todo: incrementos, osciladores, zigzags, patrones, precios, cualquier. Me estoy moviendo en esta dirección por ahora.
¿Te entrenas seleccionando los pesos de la red en MT5-optimiser?
Sí. De vez en cuando recurro al aprendizaje real a través de la retropropagación de errores
Sí. De vez en cuando recurro al aprendizaje real a través de la retropropagación de errores.
¿Cuál es la relación entre el optimizador de mt5 y la retropropagación de error????
Cool Bypassing MT5 limitations is like optimising a pair of layers of 10 neurons - a regular MT5 optimizer will complain about the 64bit limitation.
Conclusiones que te mereces :)
Entre otro conjunto de palabras, sólo señalaría que cuantas menos transacciones (observaciones), más fácil es hacer curwafitting (ajuste a la historia) incluyendo nuevos datos. Esa es una característica del curwafitting basada en estadística, no en avanzar. 🫠