Artículos sobre análisis de datos y estadísticas en MQL5
Los artículos sobre los modelos matemáticos y leyes de probabilidades serán interesantes para muchos operadores. Es que las matemáticas han sido puestas como base de los indicadores, y el conocimiento de las estadísticas es necesario para el análisis de los resultados del trading y el desarrollo de las estrategias.
Lea sobre la lógica difusa, filtros digitales, perfil del mercado, mapas de Kohonen, gas neuronal y muchas otras herramientas que pueden ser utilizadas para el trading.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
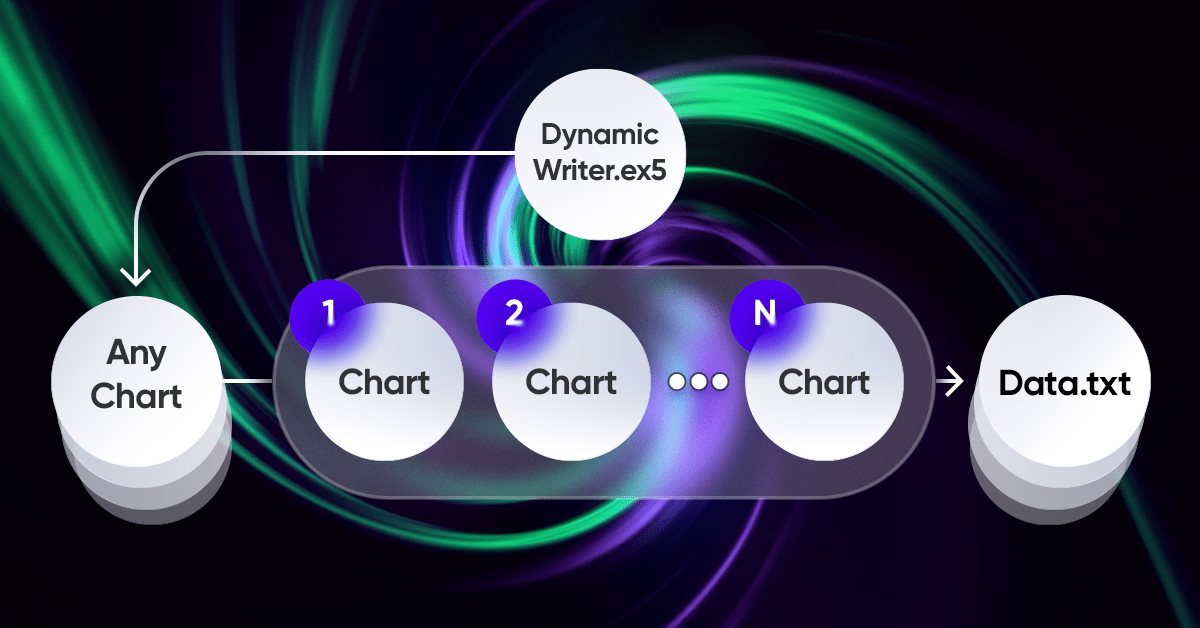
Aproximación por fuerza bruta a la búsqueda de patrones (Parte VI): Optimización cíclica
En este artículo mostraremos la primera parte de las mejoras que nos permitieron no solo cerrar toda la cadena de automatización para comerciar en MetaTrader 4 y 5, sino también hacer algo mucho más interesante. A partir de ahora, esta solución nos permitirá automatizar completamente tanto el proceso de creación de asesores como el proceso de optimización, así como minimizar el gasto de recursos a la hora de encontrar configuraciones comerciales efectivas.

Pruebas de permutación de Monte Carlo en MetaTrader 5
En este artículo echaremos un vistazo a cómo podemos realizar pruebas de permutación sobre la base de datos de ticks barajados en cualquier asesor experto utilizando solo MetaTrader 5.

Teoría de categorías en MQL5 (Parte 15): Funtores con grafos
El artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5, analizando los funtores como un puente entre grafos y conjuntos. Volveremos nuevamente a los datos del calendario y, a pesar de sus limitaciones en el uso de un simulador de estrategias, justificaremos el uso de funtores para predecir la volatilidad mediante la correlación.
Aproximación por fuerza bruta a la búsqueda de patrones (Parte V): Una mirada desde el otro lado
En este artículo mostraré al lector un enfoque del trading algorítmico completamente distinto al que he tenido que llegar después de bastante tiempo. Obviamente, todo esto está relacionado con mi programa de fuerza bruta, que ha sufrido una serie de cambios que le permiten resolver varios problemas al mismo tiempo. No obstante, el artículo ha resultado lo más general y sencillo posible, por lo que también resultará apto para quienes no conocen el tema o simplemente están de paso.

El modelo de movimiento de precios y sus principales disposiciones (Parte 3): Cálculo de parámetros óptimos en el juego bursátil
En el marco del presente enfoque de ingeniería desarrollado por el autor, basado en la teoría de la probabilidad, se encuentran las condiciones para abrir una posición rentable, y también se calculan los valores óptimos (que maximizan las ganancias) para el stop loss y el take profit.

Transformada discreta de Hartley
En este artículo nos familiarizaremos con uno de los métodos de análisis espectral y de procesamiento de señales: la transformada discreta de Hartley. Con ella podremos filtrar señales, analizar su espectro y mucho más. Las capacidades de la DHT no son inferiores a las de la transformada discreta de Fourier. Sin embargo, a diferencia de este, la DHT utiliza solo números reales, lo cual la hace más cómoda de implementar en la práctica y los resultados de su aplicación resultan más visuales.

Teoría de categorías en MQL5 (Parte 13): Eventos del calendario con esquemas de bases de datos
El artículo analiza cómo se pueden incluir esquemas de bases de datos para la clasificación en MQL5. Vamos a repasar brevemente cómo los conceptos de esquema de base de datos pueden combinarse con la teoría de categorías para identificar información textual (cadenas) relevante para el comercio. La atención se centrará en los eventos del calendario.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 23): FOREX (IV)
La creación ahora se realiza en el mismo punto en el que convertimos los ticks en barras. Así, si algo va mal durante la conversión, nos daremos cuenta del error enseguida. Esto se debe a que el mismo código que coloca las barras de 1 minuto en el gráfico cuando avanzamos rápidamente también se utiliza para el sistema de posicionamiento y para colocar las barras durante el avance normal. En otras palabras, el código responsable de esta tarea ya no se duplica en ningún lugar. De esta manera, tenemos un sistema mucho más adecuado tanto para el mantenimiento como para las mejoras.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 22): FOREX (III)
Para aquellos que aún no han comprendido la diferencia entre el mercado de acciones y el mercado de divisas (forex), a pesar de que este ya es el tercer artículo en el que abordo esto, debo dejar claro que la gran diferencia es el hecho de que en forex no existe, o mejor dicho, no se nos informa acerca de algunas cosas que realmente ocurrieron en la negociación.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 21): FOREX (II)
Vamos a continuar el armado del sistema para cubrir el mercado FOREX. Entonces, para resolver este problema, primero necesitaríamos declarar la carga de los ticks antes de cargar las barras previas. Esto soluciona el problema, pero al mismo tiempo obliga al usuario a seguir un tipo de estructura en el archivo de configuración que, en mi opinión, no tiene mucho sentido. La razón es que, al desarrollar la programación responsable de analizar y ejecutar lo que está en el archivo de configuración, podemos permitir que el usuario declare las cosas en cualquier orden.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 20): FOREX (I)
La intención inicial de este artículo no será cubrir todas las características de FOREX, sino más bien adaptar el sistema de manera que puedas realizar al menos una repetición del mercado. La simulación quedará para otro momento. Sin embargo, en caso de que no tengas los ticks y solo tengas las barras, con un poco de trabajo, puedes simular posibles transacciones que podrían haber ocurrido en FOREX. Esto será hasta que te muestre cómo adaptar el simulador. El hecho de intentar trabajar con datos provenientes de FOREX dentro del sistema sin modificarlo conlleva errores de rango.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 19): Ajustes necesarios
Lo que vamos a hacer aquí es preparar el terreno para que, cuando sea necesario agregar nuevas funciones al código, esto se haga de manera fluida y sencilla. El código actual aún no puede cubrir o manejar algunas cosas que serán necesarias para un progreso significativo. Necesitamos que todo se construya de manera que el esfuerzo de implementar algunas cosas sea lo más mínimo posible. Si esto se hace adecuadamente, tendremos la posibilidad de tener un sistema realmente muy versátil. Capaz de adaptarse muy fácilmente a cualquier situación que deba ser cubierta.

Desarrollo de un factor de calidad para los EAs
En este artículo, te explicaremos cómo desarrollar un factor de calidad que tu Asesor Experto (EA) pueda mostrar en el simulador de estrategias. Te presentaremos dos formas de cálculo muy conocidas (Van Tharp y Sunny Harris).
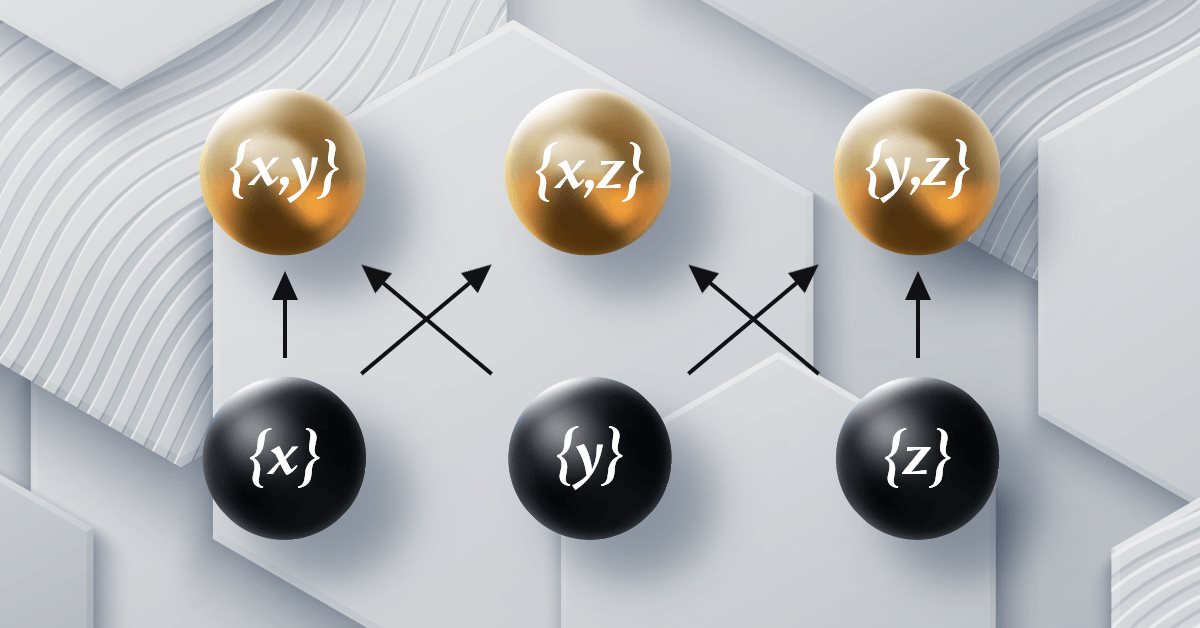
Teoría de categorías en MQL5 (Parte 12): Orden
El artículo forma parte de una serie sobre la implementación de grafos utilizando la teoría de categorías en MQL5 y está dedicado a la relación de orden (Order Theory). Hoy analizaremos dos tipos básicos de orden y exploraremos cómo los conceptos de relación de orden pueden respaldar conjuntos monoides en las decisiones comerciales.

Teoría de categorías en MQL5 (Parte 11): Grafos
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. Aquí veremos cómo podemos integrar la teoría de grafos con los monoides y otras estructuras de datos al desarrollar una estrategia de cierre del sistema comercial.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 18): Ticks y más ticks (II)
En este caso, es extremadamente claro que las métricas están muy lejos del tiempo ideal para la creación de barras de 1 minuto. Entonces, lo primero que realmente corregiremos es precisamente esto. Corregir la cuestión de la temporización no es algo complicado. Por más increíble que parezca, en realidad es bastante simple de hacer. Sin embargo, no realicé la corrección en el artículo anterior porque allí el objetivo era explicar cómo llevar los datos de los ticks que se estaban utilizando para generar las barras de 1 minuto en el gráfico a la ventana de observación del mercado.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 17): Ticks y más ticks (I)
Aquí vamos a empezar a ver cómo implementar algo realmente interesante y curioso. Pero al mismo tiempo, es extremadamente complicado debido a algunas cuestiones que muchos confunden. Y lo peor que puede pasar es que algunos operadores que se autodenominan profesionales no tienen idea de la importancia de estos conceptos en el mercado de capitales. Sí, a pesar de que el enfoque aquí es la programación, comprender algunas cuestiones relacionadas con las operaciones en los mercados es de suma importancia para lo que vamos a empezar a implementar aquí.

Posibilidades de ChatGPT de OpenAI en el marco de desarrollo de MQL4 y MQL5
En este artículo, experimentaremos y analizaremos la inteligencia artificial ChatGPT de OpenAI para comprender sus capacidades y reducir el tiempo y la intensidad del trabajo en el desarrollo de nuestros asesores, indicadores y scripts. Asimismo, repasaremos rápidamente esta tecnología e intentaremos ver cómo usarla correctamente para programar en MQL4 y MQL5.
Comprensión y uso eficaz del simulador de estrategias MQL5
Para los desarrolladores de MQL5 resulta imperativo dominar herramientas importantes y valiosas. Una de esas herramientas es el simulador de estrategias. El presente artículo es una guía práctica para utilizar el simulador de estrategias MQL5.
Previsión usando modelos ARIMA en MQL5
En este artículo, continuaremos el desarrollo de la clase CArima para construir modelos ARIMA añadiendo métodos de predicción intuitivos.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 16): Un nuevo sistema de clases
Precisamos organizarnos mejor. El código está creciendo y si no lo organizamos ahora, será imposible hacerlo después. Así que vamos a dividir para conquistar. El hecho de que MQL5 nos permita usar clases nos ayudará en esta tarea. Pero para hacerlo, es necesario que tengas algún conocimiento sobre algunas cosas relacionadas con las clases. Y tal vez lo que más confunde a los aspirantes y principiantes es la herencia. Así que en este artículo, te mostraré de manera práctica y sencilla cómo usar estos mecanismos.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 15): Nacimiento del SIMULADOR (V) - RANDOM WALK
En este artículo, vamos a finalizar la fase en la que estamos desarrollando el simulador para nuestro sistema. El propósito principal aquí será ajustar el algoritmo visto en el artículo anterior. Este algoritmo tiene como objetivo crear el movimiento de RANDOM WALK. Por lo tanto, es fundamental comprender el contenido de los artículos anteriores para seguir lo que se explicará aquí. Si no has seguido el desarrollo del simulador, te aconsejo que veas esta secuencia desde el principio. De lo contrario, podrías perderte en lo que se explicará aquí.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 14): Nacimiento del SIMULADOR (IV)
En este artículo, continuaremos con la fase de desarrollo del simulador. Sin embargo, ahora veremos cómo crear efectivamente un movimiento del tipo "RANDOM WALK" (paseo aleatorio). Este tipo de movimiento es bastante intrigante, ya que sirve de base para todo lo que sucede en el mercado de capitales. Además, comenzarás a comprender algunos conceptos esenciales para quienes realizan análisis de mercado.

Teoría de categorías (Parte 9): Acciones de monoides
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. En este artículo examinaremos las acciones de los monoides como un medio de transformación de los monoides descritos en el artículo anterior para aumentar sus aplicaciones.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 13): Nacimiento del SIMULADOR (III)
Aquí optimizaremos un poco las cosas para facilitar lo que haremos en el próximo artículo. Y también te explicaré cómo puedes visualizar lo que está generando el simulador en términos de aleatoriedad.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 12): Nacimiento del SIMULADOR (II)
Desarrollar un simulador puede resultar mucho más interesante de lo que parece. Así que demos algunos pasos más en esta dirección, porque las cosas están empezando a ponerse interesantes.

Representaciones en el dominio de la frecuencia de series temporales: El espectro de potencia
En este artículo, veremos métodos asociados con el análisis de series temporales en el dominio de la frecuencia. También prestaremos atención a los beneficios del estudio de las funciones espectrales de series temporales al construir modelos predictivos. Además, analizaremos algunas perspectivas prometedoras para el análisis de series temporales en el dominio de la frecuencia utilizando la transformada discreta de Fourier (DFT).

Algoritmo de recompra: simulación del comercio multidivisa
En este artículo crearemos un modelo matemático para simular la formación de precios multidivisa y completaremos el estudio del principio de diversificación en la búsqueda de mecanismos para aumentar la eficiencia del trading que inicié en el artículo anterior con cálculos teóricos.

Redes neuronales: así de sencillo (Parte 41): Modelos jerárquicos
El presente artículo describe modelos de aprendizaje jerárquico que ofrecen un enfoque eficiente para resolver problemas complejos de aprendizaje automático. Los modelos jerárquicos constan de varios niveles; cada uno de ellos es responsable de diferentes aspectos del problema.

Características del Wizard MQL5 que debe conocer (Parte 6): Transformada de Fourier
La transformada de Fourier, introducida por Joseph Fourier, es un medio para descomponer puntos de datos de ondas complejos en componentes de ondas simples. Esta característica puede resultar útil para los tráders, así que hablaremos de ella en este artículo.

Redes neuronales: así de sencillo (Parte 40): Enfoques para utilizar Go-Explore con una gran cantidad de datos
Este artículo analizará el uso del algoritmo Go-Explore durante un largo periodo de aprendizaje, ya que la estrategia de elección aleatoria puede no conducir a una pasada rentable a medida que aumenta el tiempo de entrenamiento.
Implementando el algoritmo de aprendizaje ARIMA en MQL5
En este artículo, implementaremos un algoritmo que aplica un modelo autorregresivo de media móvil integrada (modelo Box-Jenkins) utilizando el método de minimización de la función de Powell. Box y Jenkins argumentaron que la mayoría de las series temporales se pueden modelar con una o ambas estructuras.

Redes neuronales: así de sencillo (Parte 39): Go-Explore: un enfoque diferente sobre la exploración
Continuamos con el tema de la exploración del entorno en los modelos de aprendizaje por refuerzo. En este artículo, analizaremos otro algoritmo: Go-Explore, que permite explorar eficazmente el entorno en la etapa de entrenamiento del modelo.

Redes neuronales: así de sencillo (Parte 38): Exploración auto-supervisada por desacuerdo (Self-Supervised Exploration via Disagreement)
Uno de los principales retos del aprendizaje por refuerzo es la exploración del entorno. Con anterioridad, hemos aprendido un método de exploración basado en la curiosidad interior. Hoy queremos examinar otro algoritmo: la exploración mediante el desacuerdo.

Teoría de categorías en MQL5 (Parte 8): Monoides
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. Aquí presentamos los monoides como un dominio (conjunto) que distingue la teoría de categorías de otros métodos de clasificación de datos al incluir reglas y un elemento de identidad.


Desarrollo de un sistema de repetición — Simulación de mercado (Parte 10): Sólo datos reales para la repetición
Aquí veremos cómo se pueden utilizar datos más fiables (ticks negociados) en el sistema de repetición, sin tener que preocuparnos necesariamente de si están ajustados o no.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 09): Eventos personalizados
Aquí veremos cómo accionar eventos personalizados y mejorar la cuestión de cómo el indicador informa del estado del servicio de repetición/simulación.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 08): Bloqueo del indicador
En este artículo te mostraré cómo bloquear un indicador, simplemente utilizando el lenguaje MQL5, de una forma muy interesante y sorprendente.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 07): Primeras mejoras (II)
En el artículo anterior realizamos correcciones en algunos puntos y agregamos pruebas a nuestro sistema de repetición para garantizar la mayor estabilidad posible. Asimismo, comenzamos a crear y utilizar un archivo de configuración para dicho sistema.

Algoritmo de recompra: un modelo matemático para aumentar la eficiencia
En este artículo, usaremos el algoritmo de recompra como guía en un mundo con una mayor comprensión de la efectividad de los sistemas comerciales y comenzaremos a trabajar en los principios generales para mejorar la eficiencia comercial usando las matemáticas y la lógica; también aplicaremos los métodos menos comunes para aumentar la eficiencia en el contexto del uso de cualquier sistema comercial.