
Teoría de categorías en MQL5 (Parte 13): Eventos del calendario con esquemas de bases de datos
Introducción
En el anterior artículo de esta serie, vimos cómo la teoría de órdenes puede combinarse con la teoría de categorías, analizamos cómo los conceptos de esta combinación pueden implementarse en MQL5, y también vimos un ejemplo de un sistema comercial que utiliza algunos de estos conceptos.
Nuestro último artículo lo dedicamos a dos conceptos de la teoría de órdenes: los órdenes no estrictos y lineales. Recordemos que los órdenes no estrictos son métodos de clasificación establecidos que constituyen un tipo especial de órdenes previos con antisimetría. En relación con esto, también se diferencian por su reflexividad y transitividad. Por otro lado, los órdenes lineales son una forma distinta de los órdenes no estrictos, ya que además exigen comparabilidad, lo cual significa que no se permiten relaciones indefinidas.
En este artículo, en lugar de introducir nuevos conceptos, daremos un paso atrás para repasar los temas que ya hemos tratado con el fin de integrarlos en un clasificador lingüístico que use esquemas de bases de datos.
Necesidad de clasificar eficazmente los eventos del calendario
Los eventos del calendario se crean casi a diario, y la mayoría se anuncian con antelación, incluso varios meses antes. Los eventos se publican en el Calendario Económico de MetaTrader y muestran indicadores monetarios y macroeconómicos de China, EE.UU., Japón, Alemania, UE, Reino Unido, Corea del Sur, Singapur, Suiza, Canadá, Nueva Zelanda, Australia y Brasil. La lista es dinámica, por lo que posiblemente se añadan nuevos países en el futuro. Estos indicadores suelen tener (aunque no siempre es así) valores numéricos que contienen básicamente un valor previsto, un valor real y un valor anterior. El formato de los indicadores numéricos varía significativamente de un indicador a otro. Muchos indicadores son intrínsecamente incomparables entre sí, y esto, en cierto modo, supone el planteamiento de nuestro problema.
Para usar las lecturas de los indicadores de estas divisas y economías, los tráders necesitan leer de forma fiable y coherente los valores numéricos y/o interpretar con precisión el texto publicado. Veamos algunos eventos típicos del calendario.
![]()
![]()
![]()
![]()
Arriba mostramos cuatro eventos (para China, EE.UU., Japón y Alemania) que representan el índice, el porcentaje de rendimiento, las cantidades en efectivo y el valor incierto, respectivamente. Como mostramos a continuación, esta información se puede obtener en MQL5 usando métodos sencillos.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void SampleRetrieval(string Currency) { MqlCalendarValue _value[]; datetime _stop_date=datetime(__start_date+int(PeriodSeconds(__stop_date_increment))); //--- get events MqlCalendarEvent _event[]; int _events=CalendarEventByCurrency(Currency,_event); printf(__FUNCSIG__+" for Currency: "+Currency+" events are: "+IntegerToString(_events)); // for(int e=0;e<_events;e++) { int _values=CalendarValueHistoryByEvent(_event[e].id, _value, __start_date, _stop_date); // for(int v=0;v<_values;v++) { // printf(__FUNCSIG__+" Calendar Event code: "+_event[e].event_code+", for value: "+TimeToString(_value[v].period)+" on: "+TimeToString(_value[v].time)+", has... "); // if(_value[v].HasPreviousValue()) { printf(__FUNCSIG__+" Previous value: "+DoubleToString(_value[v].GetPreviousValue())); } if(_value[v].HasForecastValue()) { printf(__FUNCSIG__+" Forecast value: "+DoubleToString(_value[v].GetForecastValue())); } if(_value[v].HasActualValue()) { printf(__FUNCSIG__+" Actual value: "+DoubleToString(_value[v].GetActualValue())); } } } }
Tras extraer un valor, se nos plantea el problema de cómo organizarlo y clasificarlo para su uso en el análisis. Si nuestros valores numéricos fueran estándar, es decir, entre 0 y 100, como un índice, la comparación relativa entre eventos del calendario sería sencilla, dada la posibilidad de determinar fácilmente la importancia relativa de cada uno de ellos. En realidad, sin embargo, el análisis debe realizarse a través de un "tercero" que use la correlación entre cada evento individual y el movimiento del precio de una acción o divisa concreta.
Algunos eventos no tienen ningún valor numérico comparable, como el discurso de un miembro del consejo del Bundesbank, mostrado en la captura de pantalla anterior.
Mención especial merece la descripción textual del evento en sí, que, supuestamente, representa la forma en que el tráder identifica este. Por ejemplo, al analizar la pareja EURUSD, lo ideal sería tener en cuenta los eventos en EUR y los eventos comparables en USD. Pero cómo trabajar con eventos como este, por ejemplo:

Con sus homólogos aparentemente comparables en el lado del USD:
![]()
También:
![]()
Al trabajar con el euro, ¿tendremos en cuenta el sentimiento del euro o el sentimiento de Alemania? ¿O deberíamos usar ambos con la ayuda de la ponderación? Y de ser así, ¿qué pesos utilizaríamos? En cuanto al USD, ¿qué valores de Michigan o Filadelfia debemos usar?
Por lo tanto, necesitamos un método adicional para clasificar nuestros eventos más allá de los que ya ofrece MQL5, que nos ayude no solo a comparar fácilmente valores numéricos en diferentes economías y divisas, sino también a realizar operaciones.
Los métodos de clasificación existentes son demasiado simples. Entre ellos tenemos: la selección de eventos por ID, la selección de eventos por país y la selección de eventos por divisa. Existen otras categorías que consideran el valor de estos eventos, pero no difieren mucho de estas clasificaciones. Además, la selección por país y divisa crea ambigüedad, en gran parte debido a EUR. No existen aspectos básicos para determinar si un evento es retrospectivo, como un índice, o prospectivo, como el sentimiento del mercado. Además, la necesidad de comparar distintas divisas para el mismo evento no está en algunos casos tan claramente definida, como mostramos más arriba para EURUSD.
Conceptos de teoría de categorías y esquemas de bases de datos
En los artículos anteriores de la serie, vimos las unidades básicas de la teoría de categorías: los conjuntos (en los artículos anteriores, un conjunto se denominaba dominio), luego los morfismos con sus tipos y, por último, la composición con sus numerosas formas y propiedades.
Las imágenes, que suponen una aproximación de grafos y demuestran un concepto que se corresponde con los datos, sin considerar hasta ahora los datos de las tablas, son lo que podemos llamar esquemas de bases de datos. Las bases de datos son herramientas de almacenamiento indexadas que ofrecen integridad referencial y evitan la duplicación de datos.
Una sinergia potencial entre la teoría de categorías y los esquemas de bases de datos supone que las composiciones de la teoría de categorías pueden transferir algunas de sus propiedades a los esquemas de las bases de datos. Así, si empezamos por categorizar los eventos de nuestro calendario usando una base de datos sencilla, podremos observar fácilmente el esquema a través de diferentes "lentes", ya sean recuentos, gráficos, órdenes, etc. A continuación le mostramos una representación esquemática de las tablas que pueden definir los eventos de nuestro calendario.
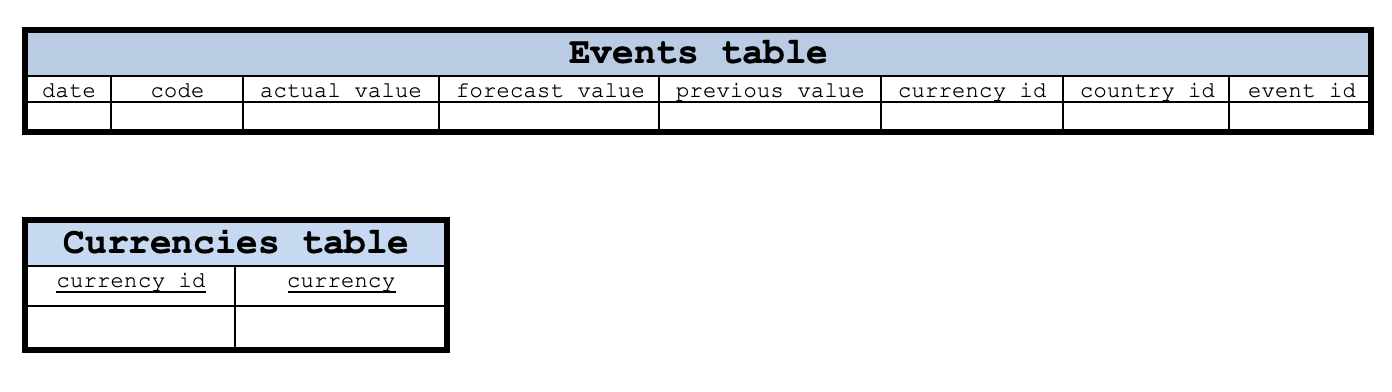
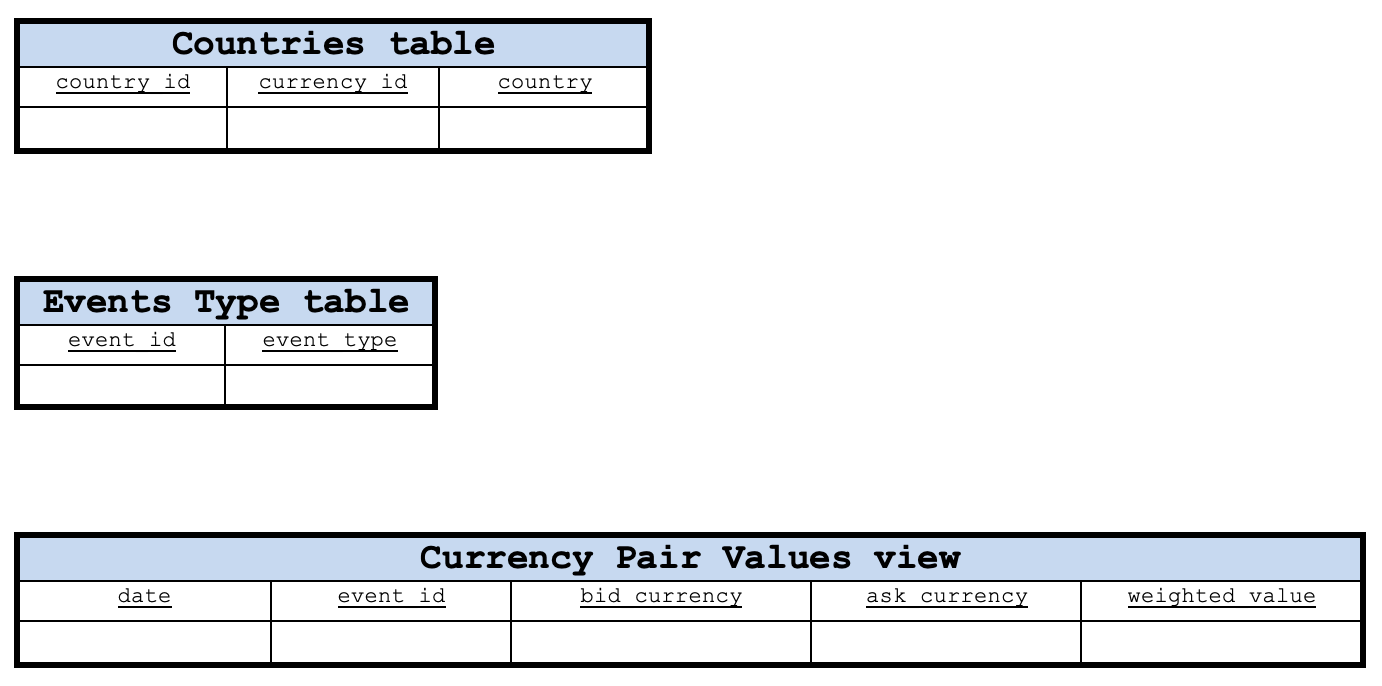
Con este diseño básico, la tabla de eventos tendrá una columna de fecha y un código como clave primaria. La columna de código contiene los datos del código de evento leídos de los eventos del calendario. Las tablas Currencies (divisas), Countries (países) y Events (eventos) pueden tener sus claves primarias como columnas currency_id, countries_id y event_id, respectivamente. No obstante, la tabla de valores de las parejas de divisas tendrá que combinar las columnas date y event_id para su clave primaria.
Lo anteriormente mencionado no supone un esquema porque no se especifican las relaciones entre las tablas. Solo serán tablas en nuestra base de datos. A continuación le mostramos parte del esquema.
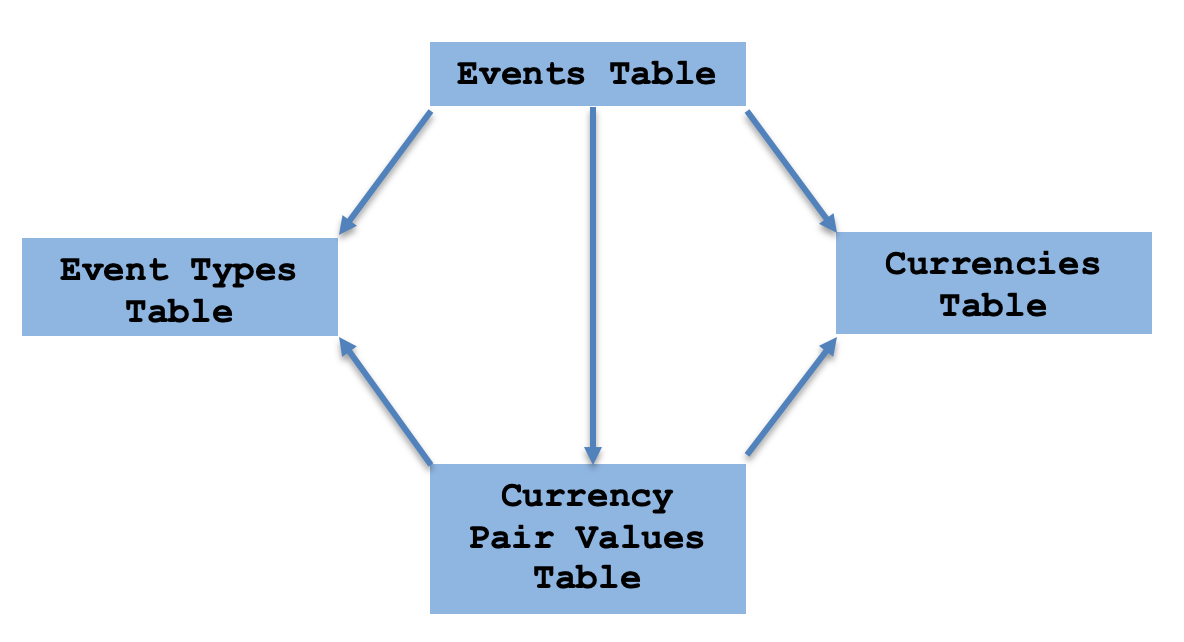
Esta estructura esquemática se puede entender fácilmente como el producto de la teoría de categorías. Esto significa que tenemos una propiedad universal entre nuestra tabla de eventos y la vista de los valores de las parejas de divisas.
Recordemos que la propiedad de coproducto, normalmente universal, resulta útil cuando se trata de curvas fragmentadas. Tomemos, por ejemplo, un experimento en el que la temperatura registrada en dos regiones A y B varía lineal y cuadráticamente, respectivamente. Para estudiar el perfil de temperatura de la región fusionada, la propiedad de coproducto universal de A y B permitiría pegar los perfiles de temperatura individuales de cada región en una única función que, basándose en los datos de la curva, supondría un indicador razonable de lo que cabría esperar si alguien decidiera viajar a esa región sin un itinerario bien definido.
Para nuestros propósitos como tráders, la composición anterior resulta bastante útil porque los valores de los eventos de cada divisa individual nunca se publican al mismo tiempo. Así, si los datos sobre el sentimiento del euro se publican, por ejemplo, hoy, los indicadores del dólar pueden aparecer quince días después. Podríamos utilizar valores antiguos (recientes) de USD para obtener el valor de una pareja de divisas, pero usando la teoría de categorías podemos utilizar la propiedad universal para anticipar o predecir el valor de una divisa que no se haya actualizado desde que se movió el gráfico.
Implementación usando MQL5
Como nuestra teoría de categorías y el esquema se pueden representar en MQL5 como un desplazamiento cuadrado, podemos modificar ligeramente la clase CSquareCommute de los artículos anteriores de la forma que sigue:
//+------------------------------------------------------------------+ //| Square Commute Class to illustrate Universal Property | //+------------------------------------------------------------------+ template <typename TA,typename TB,typename TC,typename TD> class CCommuteSquare { public: CHomomorphism<TA,TB> ab; CHomomorphism<TA,TC> ac; CHomomorphism<TD,TB> db; CHomomorphism<TD,TC> dc; CHomomorphism<TD,TA> da; //universal property virtual void SquareAssert() { ab.domain=ac.domain; ab.codomain=db.codomain; dc.domain=db.domain; dc.codomain=ac.codomain; da.domain=db.domain; da.codomain=ac.domain; } CCommuteSquare(){}; ~CCommuteSquare(){}; };
Lo que hemos añadido al original es solo un homomorfismo adicional de propiedad universal. Así que, después de esto, el siguiente punto clave será identificar los elementos de cada conjunto que recogen los datos relevantes. Esto puede hacerse para un conjunto de eventos (mostrados como una tabla de eventos), como describimos a continuación:
//sample constructor for event set CElement<string> _e_event;_e_event.Cardinality(7); //
Una vez definido este elemento, el tráder puede rellenarlo fácilmente con datos utilizando el listado 1 anterior o cualquier otra opción adecuada. Puede que usted encuentre un método más adecuado a su estrategia. Una vez el elemento se ha rellenado con datos, podemos añadirlo fácilmente al dominio correspondiente de la clase de desplazamiento mostrada anteriormente, tal y como se ha descrito en artículos anteriores. También podemos crear valores de evento e incluso elementos de divisa múltiples, como se muestra a continuación:
//sample constructor for type set CDomain<string> _d_type;_d_type.Cardinality(_types); //data population CElement<string> _e_type;_e_type.Cardinality(1);
//sample constructor for currency set CDomain<string> _d_currency;_d_currency.Cardinality(_currencies); //data population CElement<string> _e_currency;_e_currency.Cardinality(1);
Esto conduce a los elementos de valor de la pareja de divisas. Este conjunto combina las divisas en una pareja comerciada común que posee un gráfico de precios al ser seleccionada desde la Observación de Mercado con la adición de un nuevo valor numérico, que es el valor efectivo de la pareja resultante de combinar los dos valores de evento de cada divisa. Así, por ejemplo, si tenemos los valores de ventas al por menor para la zona del euro, que se emparejarán con EUR, y las ventas al por menor para EE.UU., que se emparejarán con USD, el conjunto de valores de parejas de divisas incluirá EURUSD con su valor efectivo de ventas al por menor. A continuación le mostramos el listado para crear su elemento:
//sample constructor for values set CDomain<string> _d_values;_d_values.Cardinality(_values); //data population CElement<string> _e_values;_e_values.Cardinality(4);
Quizá se pregunte por qué resulta tan importante el rendimiento de una pareja de divisas. Este combina los valores de los eventos de dos divisas especificadas en el calendario de eventos en un único valor para una pareja de divisas de esas dos divisas. Este valor único puede, por ejemplo, formar entonces una serie temporal que abra oportunidades para el estudio posterior de, digamos, la serie temporal de precios de una pareja o cualquier otra serie de indicadores de dicha pareja.
Para resumir lo que hemos tratado hasta ahora, podemos destacar que las fases de diseño e implementación de dicha clasificación consisten principalmente en clasificar los eventos originales del calendario en un esquema de base de datos. Así se identificará el texto repetido y se podrán utilizar los índices. Para este proyecto, podemos utilizar un esquema sencillo en el que la tabla de eventos esté vinculada a todas las demás tablas.
Utilizando este diseño, podemos implementar un ciclo con los eventos del calendario que se extraen fácilmente, como se muestra en nuestro listado 1 anterior, y rellenar los valores de nuestra base de datos. Para evitar reinventar la rueda, una clase para nuestra base de datos con tablas asociadas representadas como estructuras podría tener este aspecto:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CDatabase { public: STableEvents events; STableEventTypes event_types; STableCountries countries; STableCurrencies currncies; CDatabase(void); ~CDatabase(void); };
La diferencia entre este enfoque y SQL es que los datos se almacenan en la RAM, que es temporal, mientras que SQL suele almacenar los datos en el disco duro. Sin embargo, esta clase nos permite exportarlos a una base de datos existente, y como MQL5 IDE posee ciertas capacidades de las bases de datos, podemos terminar leyendo estos valores de la base de datos física en lugar de leer de la RAM, ahorrando así recursos computacionales.
Una vez tengamos una base de datos, organizaremos nuestro desplazamiento cuadrado partiendo de la clase anterior. Este proceso consiste simplemente en definir conjuntos de ángulos como se muestra en la figura siguiente. Para cada conjunto, definimos su estructura de elementos. Ya hemos publicado su lista anteriormente. Una vez definidos los elementos, se rellenan con los datos de nuestra base de datos y se añaden a un ejemplar de la clase de desplazamiento cuadrado.
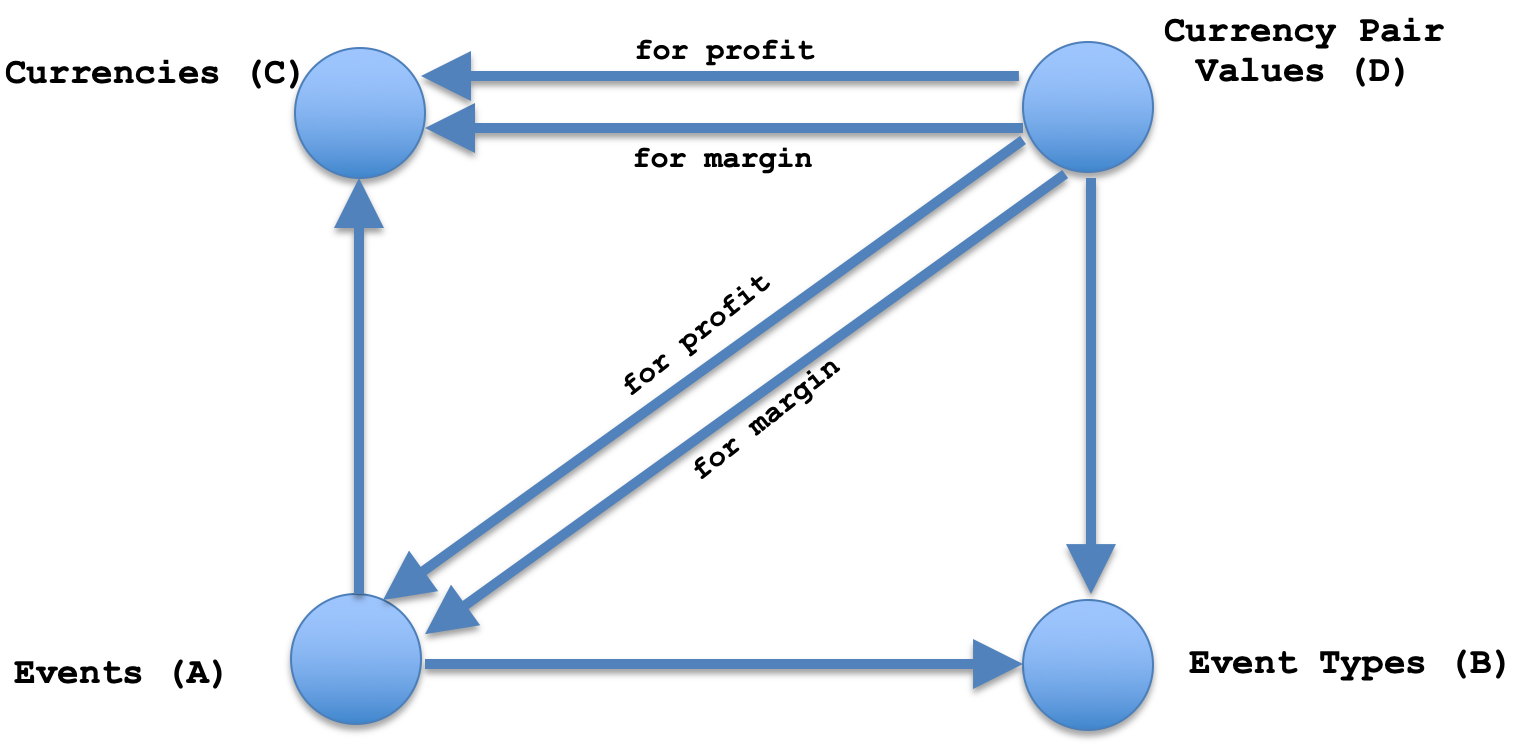
Una vez tenemos conjuntos, pasamos a la parte más interesante: definir los homomorfismos entre estos conjuntos. Un homomorfismo de un conjunto de eventos respecto a un conjunto de tipos de eventos simplemente comparará los eventos con su tipo, lo cual desde una perspectiva de diseño de la base de datos significa que solo podremos tener una columna de índice de tipo en la tabla de eventos, mientras que los tipos reales con sus índices estarán en la tabla de tipos de eventos. La relación de clave externa entre ellos sería equivalente a nuestro homomorfismo. Como no se trata de una base de datos, en el conjunto de tipos tendremos todos los tipos que ya figuran como parte del conjunto de eventos, pero sin repetición, lo cual significa que nuestro conjunto de eventos supone un dominio, mientras que los tipos de eventos suponen un codominio. Así, un homomorfismo puede definirse fácilmente mediante el siguiente listado:
//ab homomorphisms CHomomorphism<string,string> _ab; CElement<string> _e; for(int s=0;s<_sc.ab.domain.Cardinality();s++) { _e.Let(); if(_sc.ab.domain.Get(s,_e)) { string _s=""; if(_e.Get(0,_s)) { CMorphism<string,string> _m; _m.Morph(_sc.ab.domain,_sc.ab.codomain,s,EventType(_s)); _ab.Morphisms(_ab.Morphisms()+1); _ab.Set(_ab.Morphisms()-1,_m); } } }
Del mismo modo, el homomorfismo de eventos y divisas supone un mapeo directo que puede implementarse usando el listado que aparece a continuación:
//ac homomorphisms CHomomorphism<string,string> _ac; for(int s=0;s<_sc.ac.domain.Cardinality();s++) { _e.Let(); if(_sc.ac.domain.Get(s,_e)) { string _s=""; if(_e.Get(1,_s)) { CMorphism<string,string> _m; int _c=EventCurrency(_s); if(_c!=-1) { _m.Morph(_sc.ac.domain,_sc.ac.codomain,s,_c); _ac.Morphisms(_ac.Morphisms()+1); _ac.Set(_ac.Morphisms()-1,_m); } } } }
No obstante, la esencia reside en los tres homomorfismos restantes: el mapeo respecto al conjunto de tipos de eventos a partir del conjunto de valores de parejas de divisas; el mapeo respecto al conjunto de divisas a partir del conjunto de valores de parejas de divisas y, por último, el mapeo respecto a la propiedad universal con los valores de parejas de divisas a partir del conjunto de eventos. Si desempaquetamos esta estructura empezando por las dos primeras, que son relativamente sencillas, tendremos un mapeo de valores de parejas de divisas respecto a los tipos de eventos, y un mapeo de valores de parejas de divisas respecto a las divisas, lo que hace que nuestra composición sea un producto. Cabe señalar que, según las reglas fundamentales de los homomorfismos, un elemento del dominio de una definición solo puede corresponder a un elemento del dominio de un codominio. Por lo tanto, esto significa que al considerar múltiples divisas, no podremos realizar un mapeo hacia atrás, ya que esto conllevaría mapear valores de eventos respecto a múltiples parejas siempre que una pareja se refiera a su valor. En el caso de las divisas, el mapeo a partir de ahí con conjuntos de valores de parejas de divisas implicaría un problema de repetición similar. Así, la implementación del mapeo respecto a valores de eventos puede tener el siguiente aspecto:
//db homomorphisms CHomomorphism<string,string> _db; for(int s=0;s<_values;s++) { _e.Let(); if(_sc.db.domain.Get(s,_e)) { string _s=""; if(_e.Get(3,_s)) { int _t=TypeToInt(_s); CMorphism<string,string> _m; // _m.Morph(_sc.db.domain,_sc.db.codomain,s,_t); _db.Morphisms(_db.Morphisms()+1); _db.Set(_db.Morphisms()-1,_m); } } }
Del mismo modo, el mapeo de divisas podría tener el siguiente aspecto:
//dc homomorphisms CHomomorphism<string,string> _dc; for(int s=0;s<_values;s++) { _e.Let(); if(_sc.dc.domain.Get(s,_e)) { string _s=""; if(_e.Get(0,_s))//morphisms for margin currency only { int _c=EventCurrency(_s); CMorphism<string,string> _m; // _m.Morph(_sc.dc.domain,_sc.dc.codomain,s,_c); _dc.Morphisms(_dc.Morphisms()+1); _dc.Set(_dc.Morphisms()-1,_m); } } }
Conviene señalar aquí los parámetros de ponderación de las divisas de la demanda y de los márgenes. Esto puede lograrse gracias a la optimización o respecto a la ponderación de los tipos de interés de referencia o las tasas de inflación de cada economía (esta lista no es exhaustiva). El tráder tendrá que elegir según su estrategia y sus perspectivas de mercado. El homomorfismo final de valores de las parejas de divisas derivadas de los eventos se corresponderá con un elemento de valores de pareja de divisas y dos entradas en el conjunto de eventos. Basándonos en las ponderaciones utilizadas para los dos mapeos anteriores, el mapeo de propiedades universales quedaría como se muestra a continuación:
//da homomorphisms CHomomorphism<string,string> _da; for(int s=0;s<_values;s++) { _e.Let(); if(_sc.da.domain.Get(s,_e)) { string _s_c="",_s_t=""; if(_e.Get(0,_s_c) && _e.Get(3,_s_t))// for margin currency { for(int ss=0;ss<_sc.ac.domain.Cardinality();ss++) { CElement<string> _ee; if(_sc.da.codomain.Get(ss,_ee)) { string _ss_c="",_ss_t=""; if(_ee.Get(1,_ss_c) && _ee.Get(6,_ss_t))// for margin currency { if(_ss_c==_s_c && _ss_t==_s_t) { CMorphism<string,string> _m; // _m.Morph(_sc.da.domain,_sc.da.codomain,s,ss); _da.Morphisms(_da.Morphisms()+1); _da.Set(_da.Morphisms()-1,_m); _sc.da=_da; _sc.SquareAssert(); break; } } } } } } } _da.domain=_sc.da.domain; _da.codomain=_sc.da.codomain; _sc.da=_da; _sc.SquareAssert();
Este sería, por tanto, el último paso para determinar las ponderaciones efectivas de una pareja de divisas basándonos en los eventos del calendario de las divisas individuales.
Clasificación de los eventos del calendario
A la hora de elaborar una tabla de tipos de eventos, puede ser prudente seguir una metodología rigurosa que considere la masa crítica de datos antes de pasar a los tipos de eventos. Como se indica en el enunciado del problema, la clasificación de los eventos es importante, por lo que una posible metodología para clasificar dichos eventos en tipos comparables podría incluir: recopilación de datos, antes hemos descrito la extracción básica de datos mediante las clases incorporadas en MQL5. A continuación se agruparán los eventos, cosa para la que podemos usar grupos estándar como índices, indicadores de sentimiento, rendimientos de los bonos del Tesoro, indicadores de inflación, etc. Después se extraerán características, ya que cada evento se analizará en busca de palabras clave para determinar a qué grupo pertenece. Luego entrenaremos el modelo y evaluaremos nuestra clasificación de objetos; para ello, crearemos conjuntos de datos de entrenamiento y de prueba y comenzaremos con el entrenamiento del modelo. A continuación, probaremos el modelo en un conjunto de datos de prueba para comprobar cómo de bien clasifica nuestros eventos. Por último, el postanálisis y la mejora iterativa completarán el proceso, buscando formas de afinar nuestro modelo sin sobreajustarlo.
Una vez creados los tipos de eventos, los introduciremos en la tabla event_types que se muestra en el esquema anterior. Esto significa que la columna ID de tipo de evento en la tabla de eventos se actualizará para todos los eventos para asignar su grupo. El procedimiento almacenado, que inserta nuevas filas o actualiza estas, puede ayudar a implementar nuestro modelo descrito anteriormente.
Esta adición al conjunto de eventos, significará que el único cambio significativo en nuestra composición anterior será el homomorfismo de eventos respecto a los valores de eventos, ya que el tipo de datos del elemento es un array de filas donde cada índice del array sirve para una columna de datos. En lugar de incluir solo los valores cuyo texto descriptivo sea idéntico en todas las divisas, como "ventas al por menor", ahora incluiremos una gama más amplia de eventos.
Información sobre las decisiones comerciales
Por lo tanto, la creación de un dominio de valores de parejas de divisas a partir de nuestra(s) composición(es) anterior(es) implica que tendremos valores de parejas de divisas con marca temporal. Esta marca temporal nos permitirá comparar la magnitud (y en algunos casos la dirección) de estos valores con los posibles cambios en los precios. Un proceso de análisis exhaustivo que incluya múltiples datos de entrenamiento y de prueba nos permitirá ver cómo se correlaciona cada tipo de evento con la posible acción del precio y en qué medida.
Utilizando estos datos sobre la correlación de los valores de los eventos con la acción posterior de los precios, no solo podremos establecer las reglas para colocar transacciones y abrir posiciones largas o cortas según los resultados del análisis, sino también fijar el tamaño de la posición en función de la magnitud de la correlación.
La precisión de un sistema que utiliza valores ponderados de parejas de divisas para determinar la posible acción del precio puede mejorarse si se combinan varios eventos en una media ponderada y luego se correlaciona este "indicador" con la posible acción del precio. Esto plantea la cuestión de qué ponderaciones se aplicarán a cada evento. Esta pregunta puede responderse usando la optimización. La comprensión de la macroeconomía por parte del tráder también puede servir de guía en este proceso. Sea cual sea el método elegido, un enfoque más holístico ofrecerá predicciones más precisas.
Ejemplo: implementación y evaluación en MQL5
Para mayor brevedad, no hablaremos de un sistema comercial completo, sino solo de las partes iniciales del mismo que tengan en cuenta nuestra composición de cuatro conjuntos: eventos, tipo, divisas y valores. En lugar de usar nuestra clase de base de datos, obtendremos los datos del evento del calendario directamente; así, rellenaremos un ejemplar de la clase de desplazamiento cuadrado y consideraremos qué homomorfismos podemos generar. Una vez más, se tratará solo de un primer paso destinado a demostrar el potencial. Para ello, nuestros datos de entrada incluirán: el tipo de evento en el que nos centraremos, una ponderación para la divisa de compra (bid)/margen y una ponderación para la divisa de venta (ask)/beneficio. Como ya hemos mencionado, estas ponderaciones estarán diseñadas para combinar los valores de calendario de dos divisas en una sola. Para este estudio, solo tendremos en cuenta los eventos del PMI (índice de actividad empresarial) y solo consideraremos las divisas EUR, GBP, USD, CHF y JPY, así como los valores de las parejas EURUSD, GBPUSD, USDCHF y USDJPY únicamente. El código completo se adjunta al final del artículo. Al imprimir el homomorfismo de propiedades universales, deberíamos obtener las siguientes entradas:
2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) void OnStart() d to a homomorphisms are... 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) {(EUR,USD,45.85000000,TYPE_PMI),(GBP,USD,47.00000000,TYPE_PMI),(USD,CHF,45.05000000,TYPE_PMI),(USD,JPY,48.75000000,TYPE_PMI)} 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) | 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) (EUR,USD,45.85000000,TYPE_PMI)|----->(markit-manufacturing-pmi,EUR,44.60000000,44.60000000,44.80000000,2023.06.01 11:00,TYPE_PMI) 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) | 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) {(markit-manufacturing-pmi,EUR,44.60000000,44.60000000,44.80000000,2023.06.01 11:00,TYPE_PMI),(markit-manufacturing-pmi,EUR,44.80000000,44.20000000,43.60000000,2023.06.23 11:00,TYPE_PMI),(markit-services-pmi,EUR,55.90000000,55.90000000,55.10000000,2023.06.05 11:00,TYPE_PMI),(markit-services-pmi,EUR,55.10000000,55.50000000,52.40000000,2023.06.23 11:00,TYPE_PMI),(markit-composite-pmi,EUR,53.30000000,53.30000000,52.80000000,2023.06.05 11:00,TYPE_PMI),(markit-composite-pmi,EUR,52.80000000,53.00000000,50.300000
Utilizando únicamente los datos del PMI y las divisas y parejas preseleccionados anteriormente, obtendremos un único morfismo para la divisa marginal, que en este caso será EUR. Nuestro valor añadido ha sido superior al valor de entrada de EUR simplemente porque el valor del PMI equivalente para USD era superior, mientras que el valor impreso para la pareja EURUSD era simplemente una media ponderada. En esta prueba concreta, hemos utilizado ponderaciones iguales para EUR y USD.
Conclusión
No hemos ofrecido un ejemplo de cómo se puede aplicar esta clasificación en un sistema comercial, porque el artículo resultaría demasiado largo, pero creo que hay suficiente código y material en este artículo para que los lectores implementen una aplicación de este tipo por sí mismos. Resumiendo, hoy hemos visto cómo la teoría de categorías y los esquemas de bases de datos pueden unirse para ayudar no solo a categorizar los eventos del calendario, sino también para ayudar a identificar composiciones tales como productos con propiedades universales que desempeñen un papel importante en la cuantificación del impacto de los eventos del calendario en la acción del precio.
La ventaja de esto, además de la categorización estándar de los eventos, que permite combinar fácilmente los valores de parejas de divisas, es el uso del axioma de propiedades universales de la teoría de categorías, que ayuda a definir un homomorfismo que se pueda representar directamente a partir de los eventos establecidos en un conjunto de valores de parejas de divisas (sin utilizar conjuntos angulares de valores de eventos o divisas). Como hemos mencionado antes, esto permite predecir el valor de una pareja de divisas cuando solo un valor de un evento de las divisas es nuevo y el otro todavía se espera dentro de unos días o semanas.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/12950
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso